Більшість оглядів RAG-інструментів — це каталоги. Списки з назвами, зірочками на GitHub і рядком «підходить для різних задач». Вони не відповідають на головне запитання: що саме вибрати мені, під мою задачу, з моїми обмеженнями?
Я спеціально побудував цю статтю інакше, ніж більшість оглядів. Кожен розділ — це рішення, а не опис. Для кожного інструменту я даю конкретний сценарій: коли брати, а коли уникати — без розмитих «залежить від задачі». В кінці — готові стеки під п'ять типових задач і антипаттерни, на які я особисто дивився не раз: вони коштують команді тижні переробки, і про них зазвичай не пишуть у туторіалах.
Якщо ви ще не визначились з підходом до RAG загалом — читайте спочатку повний гайд: RAG від пайплайну до продакшену. Якщо вже знаєте, що таке чанкінг і ембедінги — ця стаття для вас.
Фреймворк оркестрації — це «мозок» вашого RAG-пайплайну. Він з'єднує модель, векторну базу, документи і логіку запитів. Хороший вибір дозволяє збудувати пайплайн за дні; поганий — переробляти його через місяць, коли вимоги виростуть.
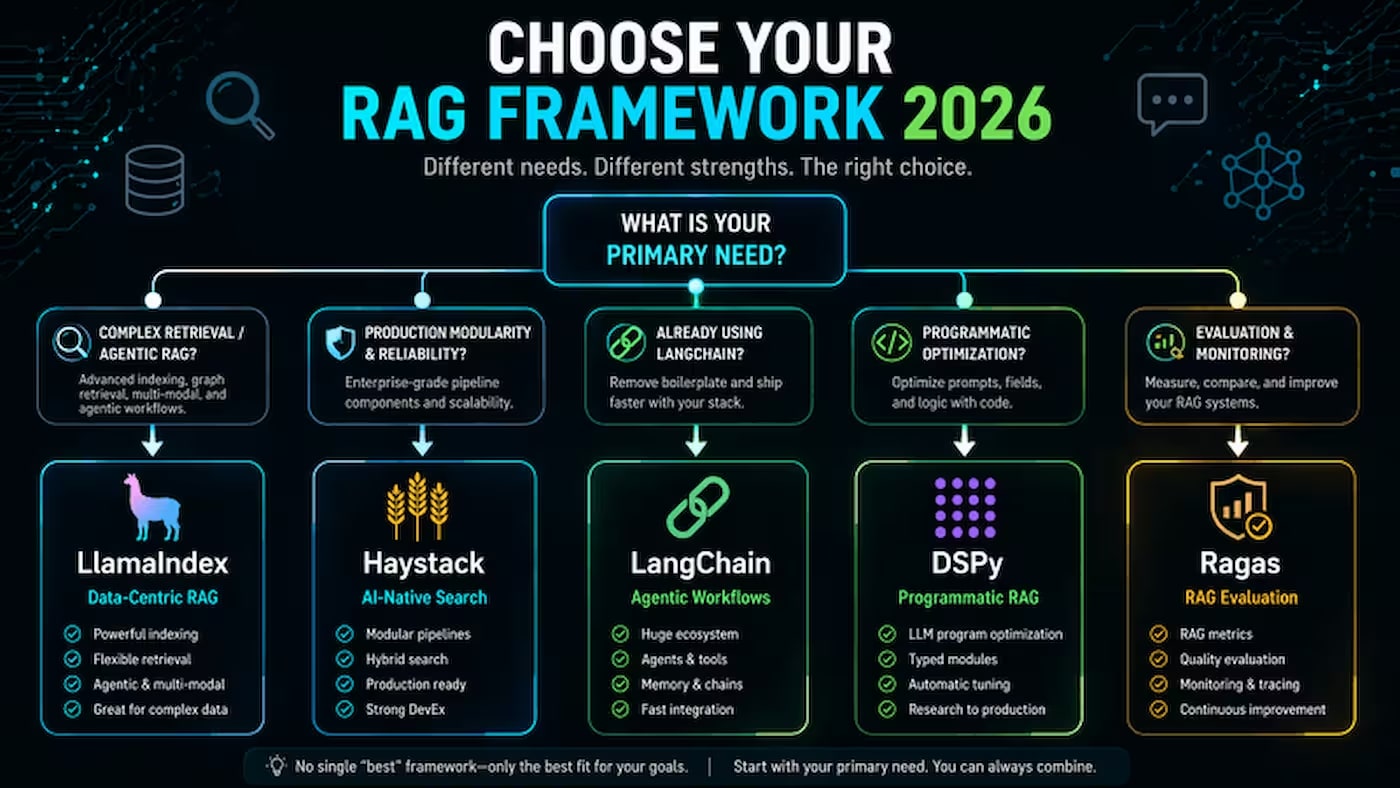
На мій погляд, тут є дві принципово різні філософії. LangChain і Haystack — це універсальні оркестратори: підходять для широкого кола задач, але не заточені під жодну конкретну. LlamaIndex і DSPy — спеціалізовані інструменти з чіткою спеціалізацією: LlamaIndex для retrieval, DSPy для автоматичної оптимізації промптів. Я б радив починати саме з розуміння цього поділу — він одразу звужує вибір вдвічі.
LangChain
GitHub — 119 000+ зірок, 500+ інтеграцій. Найбільша екосистема серед усіх RAG-фреймворків.
✅ Вибирай, якщо: будуєш складні мультиагентні системи з інструментами, пам'яттю і циклами; потрібна максимальна гнучкість інтеграцій; команда зростатиме і важливо, щоб нові розробники швидко знайшли відповіді в документації і Stack Overflow.
❌ Уникай, якщо: головна задача — Q&A по великому архіву документів (LlamaIndex точніший); бюджет часу обмежений і потрібен швидкий старт без боротьби з абстракціями; критично важлива передбачуваність пайплайну (часті breaking changes у LangChain — відома проблема).
⚠️ Типова помилка: обирають LangChain «бо всі так роблять», але якщо 80% задачі — це retrieval по документах, це надлишкова складність. Порівняльний аналіз 2026 показує: LlamaIndex дає на 35% кращий retrieval і на 40% швидше, ніж LangChain на документних задачах.
LlamaIndex
GitHub — 44 000+ зірок, 300+ data connectors через LlamaHub.
❌ Уникай, якщо: потрібна складна агентна система з циклами і розгалуженою логікою (LangGraph краще); команда шукає максимум туторіалів і готових прикладів у відкритому доступі.
💡 З мого досвіду: LlamaIndex і LangChain рідко конкурують — їх частіше використовують разом. LlamaIndex бере на себе retrieval-шар, LangGraph (частина екосистеми LangChain) — агентну оркестрацію. Я бачу цей патерн як один з найпоширеніших у production-системах 2026 року, і якщо ви будуєте щось серйозніше за простий Q&A чат-бот — варто розглянути саме таку комбінацію.
GitHub — 20 000+ зірок. Фреймворк від deepset, побудований навколо модульних пайплайнів.
✅ Вибирай, якщо: команда цінує чисту, передбачувану архітектуру більше за розмір екосистеми; задача — production-система в regulated-середовищі (фінанси, медицина, юридична сфера), де важлива аудитабельність і стабільність API; вже є досвід з enterprise NLP і потрібна зрілість, а не "магія".
❌ Уникай, якщо: починаєш новий проект і потрібно багато готових прикладів і рішень; задача — агентний RAG з динамічним плануванням (Haystack слабший за LangGraph у цьому).
DSPy (Stanford NLP)
GitHub — 23 000+ зірок. Замість ручного написання промптів DSPy автоматично їх оптимізує під конкретну задачу і метрику.
✅ Вибирай, якщо: є розмічений датасет запитань-відповідей для оптимізації; задача добре визначена і потрібно вичавити максимальну якість з конкретного корпусу; готовий інвестувати час у стрімку криву навчання.
❌ Уникай, якщо: потрібен швидкий прототип; немає розміченого датасету для оптимізації; команда не має досвіду з машинним навчанням — DSPy найскладніший у цьому списку.
Trade-off таблиця: фреймворки
Фреймворк
GitHub ⭐
Retrieval-якість
Агенти
Поріг входу
Найкращий сценарій
LangChain
119 000+
Добра (~85%)
⭐⭐⭐⭐⭐ (LangGraph)
Середній
Мультиагентні системи, складні ланцюги
LlamaIndex
44 000+
Відмінна (~92%)
⭐⭐⭐
Низький
Q&A по документах, корпоративні бази знань
Haystack
20 000+
Добра
⭐⭐
Середній
Enterprise production, регульовані галузі
DSPy
23 000+
Максимальна (з датасетом)
⭐⭐
Дуже високий
Оптимізація якості на конкретній задачі
Векторні бази даних: порівняння Qdrant, Milvus, Weaviate, pgvector, ChromaDB
Векторна база — серце RAG, і я переконаний, що саме тут команди найчастіше приймають невдале рішення. Вона зберігає ембедінги і відповідає за швидкість та якість пошуку — але вибирають її зазвичай за кількістю зірок на GitHub, а не за тим, що реально важливо. На мій погляд, три критерії вирішують все: масштаб вашого корпусу, потреба в hybrid search і операційні можливості команди. Якщо відповісти чесно на ці три питання — вибір стає очевидним без жодних бенчмарків.
Перед тим, як розбиратись у конкретних БД — ознайомтесь з тим, як vector search працює зсередини: Vector Search для початківців.
Qdrant
GitHub — 20 000+ зірок. Написаний на Rust. Найшвидша open-source векторна БД у production.
✅ Вибирай, якщо: потрібна production-система на колекції від 1M до ~100M векторів; важлива максимальна швидкість — Qdrant на 10-25% швидший за Weaviate і Milvus на типових навантаженнях, p99 latency при 10M векторах ~12ms проти 16ms у Weaviate і 18ms у Milvus; потрібен hybrid search (sparse + dense) і гнучка фільтрація по метаданих; команда хоче self-hosted без vendor lock-in.
❌ Уникай, якщо: вже використовуєш PostgreSQL і колекція менша за 5M векторів — pgvector простіше; потрібен масштаб понад мільярд векторів (Milvus кращий).
✅ Вибирай, якщо: датасет виросте до сотень мільйонів або мільярдів векторів; є data engineering команда, яка може взяти на себе операційну складність; потрібне горизонтальне масштабування з tiered storage (hot/warm/cold).
✅ Вибирай, якщо: hybrid search (вектори + ключові слова + структурні фільтри) — це основна вимога; потрібен GraphQL API для складних запитів; будуєш SaaS-продукт і потрібна multi-tenancy з ізоляцією даних між клієнтами.
❌ Уникай, якщо: команда нова у векторних БД — Weaviate має стрімкішу криву навчання через schema model і модульну систему; ресурси обмежені — самостійний хостинг Weaviate вимагає більше RAM, ніж Qdrant при тому ж датасеті.
pgvector
GitHub — 13 000+ зірок. Розширення для PostgreSQL. Версія 0.9 (2026) додала sparse-вектори і покращений HNSW.
✅ Вибирай, якщо: вже використовуєш PostgreSQL і хочеш мінімальну архітектурну складність; колекція менша за 5–10M векторів; потрібна транзакційна узгодженість між векторними і реляційними даними. Я сам часто обираю саме цей варіант — особливо коли проект вже стоїть на PostgreSQL і додавати окремий сервіс заради векторного пошуку просто не має сенсу. pgvector у таких випадках вирішує задачу елегантно і без зайвої інфраструктури.
GitHub — 16 000+ зірок. In-memory або локальне сховище, pip install і готово.
✅ Вибирай, якщо: прототипуєш, навчаєшся, перевіряєш гіпотезу. ChromaDB — найшвидший старт: від нуля до першого RAG-запиту за 15 хвилин.
❌ Уникай в production: немає HA, snapshot, production-grade моніторингу. Якщо починаєш на Chroma — одразу плануй міграцію на Qdrant або Weaviate.
Trade-off таблиця: векторні БД
БД
Мова
Hybrid Search
Оптимальний масштаб
Self-hosted
Коли брати
Qdrant
Rust
✅ Нативно
1M – 100M векторів
Легко
Production з hybrid search, speed-critical
Milvus
Go/C++
✅ Нативно
100M – мільярди
Складно (K8s)
Enterprise масштаб, GPU-прискорення
Weaviate
Go
✅ BM25 + dense
1M – 50M векторів
Середньо
SaaS multi-tenancy, GraphQL API
pgvector
C (PostgreSQL ext)
⚠️ Частково
до 5–10M векторів
Якщо є PostgreSQL
Вже маєш Postgres, малий масштаб
ChromaDB
Python
❌
до 100K векторів
Тривіально
Тільки прототипи і навчання
⚠️ Типова помилка розділу: вибирають Milvus «бо він найскладніший і значить найкращий». При колекції менше 50M векторів операційна складність Milvus — це чиста витрата часу без приросту якості. Qdrant закриває 90% production-сценаріїв з мінімальними налаштуваннями.
All-in-one платформи — це не фреймворки для розробника, а готові продукти. Вони беруть на себе весь пайплайн: завантаження документів, чанкінг, ембедінг, векторне сховище, генерацію. Ціна — менша гнучкість. Якщо ваша задача — швидко запустити RAG без написання коду, це правильний вибір.
Dify
GitHub — 90 000+ зірок. Найбільш швидкозростаючий AI-проект 2025 року.
✅ Вибирай, якщо: команда без ML-досвіду, потрібен швидкий MVP або внутрішній чат-бот; хочеш візуальний drag-and-drop редактор для пайплайнів без коду; потрібна підтримка 100+ LLM-провайдерів «з коробки».
❌ Уникай, якщо: потрібний глибокий контроль над chunking і retrieval (RAGFlow краще); критична максимальна точність на складних документах (PDF з таблицями, юридичні контракти).
RAGFlow
GitHub — 48 000+ зірок. Спеціалізується на глибокому розумінні документів.
✅ Вибирай, якщо: корпус — складні PDF-файли (таблиці, формули, змішана розмітка); потрібна прозора візуалізація того, як документ розбивається на чанки; хочеш self-hosted RAG з повним контролем і REST API для інтеграції.
❌ Уникай, якщо: ресурси обмежені — RAGFlow потребує Elasticsearch + Infinity DB, апетит до RAM значний; задача — швидкий прототип, а не якість парсингу.
GitHub — 14 600+ зірок. Від Гонконзького університету. Поєднує граф знань і векторний пошук.
✅ Вибирай, якщо: документи насичені зв'язками між сутностями (медична документація, юридичні акти, технічні специфікації); потрібний легкий фреймворк без важкої інфраструктури — встановлюється через pip install lightrag-hku; важлива підтримка інкрементального оновлення індексу.
❌ Уникай, якщо: основна задача — простий Q&A по великому архіву однотипних документів без складних зв'язків між сутностями.
AnythingLLM
Сайт. Desktop-додаток для локального RAG з Ollama-інтеграцією.
✅ Вибирай, якщо: хочеш повністю приватний RAG без будь-якого cloud API; налаштовуєш особисту базу знань на ноутбуці з локальними моделями (DeepSeek-R1, Qwen3); команда нетехнічна і потрібен простий UI.
❌ Уникай, якщо: потрібно масштабування, API для зовнішніх систем або командна робота — AnythingLLM заточений під індивідуальне використання.
Локальний RAG, приватність, індивідуальне використання
⚠️ Типова помилка: запускають Dify для серйозного корпоративного рішення і дивуються, що точність retrieval на складних PDF з таблицями низька. Dify оптимізований для швидкого старту, не для максимальної якості парсингу. Якщо якість retrieval — ключова метрика, починай з RAGFlow або окремого document-парсера.
Оцінка якості RAG: RAGAS, DeepEval, Langfuse
Моя порада — не повторюйте помилку, яку я бачу майже в кожній команді: будують RAG, запускають, і на цьому все. Жодної системи оцінки. Це рівно те саме, що розробляти продукт без метрик і аналітики — ви просто не знаєте, що зламалось, коли щось пішло не так, і не можете довести, що стало краще після оптимізації. Я завжди кажу: evaluation — це не фінальний крок, це частина пайплайну з першого дня.
GitHub — 5 000+ зірок. Підхід «pytest для LLM». 50+ метрик, включно з safety і bias.
✅ Вибирай для: CI/CD quality gate — блокує merge PR, якщо якість RAG впала нижче порогу; систематичного тестування рівня unit-тестів; команд, що будують не тільки RAG, але й агентів, multi-turn систем.
❌ Обмеження: складніший у налаштуванні, ніж RAGAS; вужча інтеграція з RAG-фреймворками «з коробки».
Langfuse
GitHub. Open-source LLM observability: трейсинг, дашборди, production monitoring. Self-hosted або managed cloud.
✅ Вибирай для: real-time моніторингу production RAG — бачиш кожен запит, latency, вартість, оцінку якості; зберігання і аналізу трейсів з RAGAS і DeepEval в єдиному місці.
⚠️ Типова помилка розділу: пропускають оцінку взагалі. «Ми бачимо, що відповіді хороші» — це не метрика. Без RAGAS ви не знаєте, що стало краще після зміни chunk_size, і не помічаєте деградацію після оновлення embedding-моделі. Мінімум — запусти RAGAS на 50-100 тест-запитах раз на тиждень.
Готові стеки під 5 сценаріїв: від PoC до enterprise
Замість «рекомендуємо LangChain + Qdrant» — конкретні стеки під конкретні обмеження. Де потрібно — з альтернативами.
Сценарій 1: Перший прототип / перевірка гіпотези
Задача: за 1-2 дні перевірити, чи RAG взагалі підходить для вашого корпусу документів.
Фреймворк: LlamaIndex або Dify
Векторна БД: ChromaDB (in-memory)
Embedding: text-embedding-3-small або nomic-embed-text (Ollama)
Сценарій 5: Enterprise масштаб (>1M документів, production SLA)
Задача: велика корпоративна система, десятки мільйонів векторів, вимоги до latency і uptime.
Фреймворк: LangChain + LangGraph (для агентної логіки) або Haystack (для регульованих галузей)
Векторна БД: Milvus (>100M векторів) або Qdrant (до 100M)
Embedding: Qwen3-Embedding-8B (self-hosted, Apache 2.0) — кращий MTEB у 2026
Retrieval: hybrid + two-stage reranking обов'язково
Оцінка: DeepEval у CI, RAGAS як cron-job, Langfuse для tracing
Observability: Langfuse або LangSmith
Що не вказано в оглядах: антипатерни і типові помилки
Більшість оглядів описують happy path. Ось що реально ламає RAG-системи — і про що не пишуть у туторіалах.
Антипатерн 1: Починати оптимізацію з вибору інструменту, а не з якості даних
Найдорожча помилка. Команда місяць порівнює LangChain і LlamaIndex, обирає Qdrant замість Weaviate — а retrieval все одно поганий, бо вхідні PDF зі скановані, OCR-артефакти спотворюють ембедінги.
ChromaDB — чудовий інструмент для прототипів. Але команди регулярно залишають його у production «бо і так працює». Так, до 100K документів — працює. При 1M документах і кількох паралельних запитах ви зіткнетесь з деградацією продуктивності і відсутністю HA. Міграція потім болюча. Плануй її з першого дня.
Перехід з text-embedding-3-small (1536) на text-embedding-3-large (3072) дає ~8.5% приросту за MTEB Retrieval і коштує в 6.5 разів дорожче за API + вдвічі більше за storage. При цьому додавання hybrid retrieval і reranker без зміни моделі дає +39% Recall. Інвестуй у retrieval-архітектуру, а не в розмірність вектора. Детальне обґрунтування: 1536 vs 3072: порівняння для RAG.
Антипатерн 5: Ігнорувати оцінку якості до першого інциденту
«Ми запустили RAG і відповіді виглядають непогано» — поширена позиція до першого випадку, коли система видала впевнену галюцинацію на важливий запит клієнта. Без RAGAS або DeepEval ви не знаєте рівень faithfulness, context precision і answer relevancy. Налаштуй мінімальну evaluation до релізу, а не після інциденту. Вартість базової оцінки з GPT-4o-mini — ~$0.001-0.003 на тест-кейс. Це найдешевша страховка від серйозних помилок.
Антипатерн 6: Milvus для невеликих колекцій
Milvus — правильний вибір при сотнях мільйонів векторів і наявності data engineering команди. Для колекцій до 50M векторів ця операційна складність — зайве навантаження без вимірюваного виграшу в якості. Qdrant на одному сервері закриває більшість production-сценаріїв з мінімальним налаштуванням.
Підсумок: як прийняти рішення
Я хочу закінчити чесно: вибір RAG-стека — це не пошук «найкращого інструменту взагалі». Такого не існує. Це відповідь на п'ять конкретних запитань вашого проекту. Я бачив команди, які витрачали тижні на порівняння фреймворків — і отримували поганий результат, бо не відповіли на ці питання до початку вибору.
Яка якість вхідних даних? Це перше, що я перевіряю завжди. Якщо PDF скановані, текст брудний після OCR, документи без структури — жоден фреймворк це не виправить. LlamaIndex не врятує поганий парсинг. Починайте з якості вхідних даних, а не з вибору інструменту.
Який масштаб вашого корпусу? Це технічне питання з чіткою відповіддю. До 10M векторів — pgvector або Qdrant, і цього більш ніж достатньо. Понад 100M — тільки Milvus. Між цими значеннями — Qdrant закриває більшість задач без зайвої операційної складності.
Чи потрібен hybrid search? Якщо у вашому корпусі є точні терміни, артикули, назви методів, числові значення — hybrid search обов'язковий. Тоді Weaviate або Qdrant. ChromaDB для цього не підходить взагалі, і я раджу не намагатися його адаптувати.
Яка ML-експертиза в команді? Це питання, яке соромляться ставити — але воно вирішує все. Якщо команда нетехнічна або потрібен швидкий старт — Dify або AnythingLLM дадуть результат за день. Якщо є досвідчені інженери і задача серйозна — LlamaIndex з Qdrant і hybrid search дадуть значно кращу якість.
Чи вимірюєте якість системи? Якщо ні — зупиніться. Не обирайте новий фреймворк, не міняйте embedding-модель. Першим кроком має бути RAGAS на 50–100 тест-запитах. Без вимірювання ви не знаєте, що покращувати — і будь-яка оптимізація стає угадуванням.
Мій особистий підхід: я завжди починаю з найпростішого стека, який закриває поточну задачу, вимірюю якість через RAGAS — і тільки тоді, коли є конкретний вимірюваний дефіцит, додаю складність. Найгірше рішення — це одразу будувати enterprise-стек для задачі, яка вирішується LlamaIndex і pgvector за вихідні.
Детальніше про кожен шар пайплайну — у відповідних статтях серії: