LM Studio на 8GB RAM: які моделі реально працюють у 2026
8GB Mac і LM Studio: чесний розбір яких моделей реально вистачить — Phi-4-mini, Gemma 4 E4B, налаштування Metal і контексту, і чому AI-поради іноді помиляються.
Nützliche Artikel zu Java, Spring, SEO, Frontend und modernen Technologien. Tipps, Beispiele und Lifehacks für Entwickler

8GB Mac і LM Studio: чесний розбір яких моделей реально вистачить — Phi-4-mini, Gemma 4 E4B, налаштування Metal і контексту, і чому AI-поради іноді помиляються.

LM Studio пояснений простими словами: MCP, MLX на Apple Silicon, чим відрізняється від Ollama і ChatGPT, і коли обрати саме LM Studio для локального AI на Mac.

Ти більше не програміст — ти просто пишеш промпти? Чому Vibe Coding втрачає силу і які навички будуть потрібні розробникам у 2026 році.

Чи варто RAG у 2026, коли контекст сягнув 2 млн токенів? Економіка інференсу, lost in the middle, безпека мультитенантних даних — розбір з реальними цифрами.

Q4_K_M, Q8_0, IQ4_XS — що означають суфікси GGUF та яке квантування вибрати для Ollama. Таблиця RAM для 7B–70B + формула розрахунку пам'яті.

Після 30 повідомлень бот починає забувати початок розмови. Розповідаю як я вирішив це через кілька шарів пам'яті — без росту витрат на токени.
Реальний досвід встановлення Cline через Ollama: помилки Node >=22, EACCES, PATH після Homebrew і запуск Kanban Board на 127.0.0.1:3484.
Ollama анонсувала ollama launch cline — AI-агент одним рядком у терміналі. Локальні і хмарні моделі, Kanban Board, порівняння з Cursor і Claude Code.

Google випустила DiffusionGemma — відкриту diffusion-модель на 26B параметрів, яка генерує текст у 4 рази швидше за GPT, Llama та Qwen. Що це означає
LangChain чи LlamaIndex? Qdrant чи pgvector? Порівняння 12 open-source RAG-інструментів з trade-off таблицями, 5 готових стеків і антипатерни.

Anthropic випустила Claude Fable 5 — першу публічну модель класу Mythos. Розбираємо бенчмарки, ціни, обмеження та причину релізу після місяців мовчання
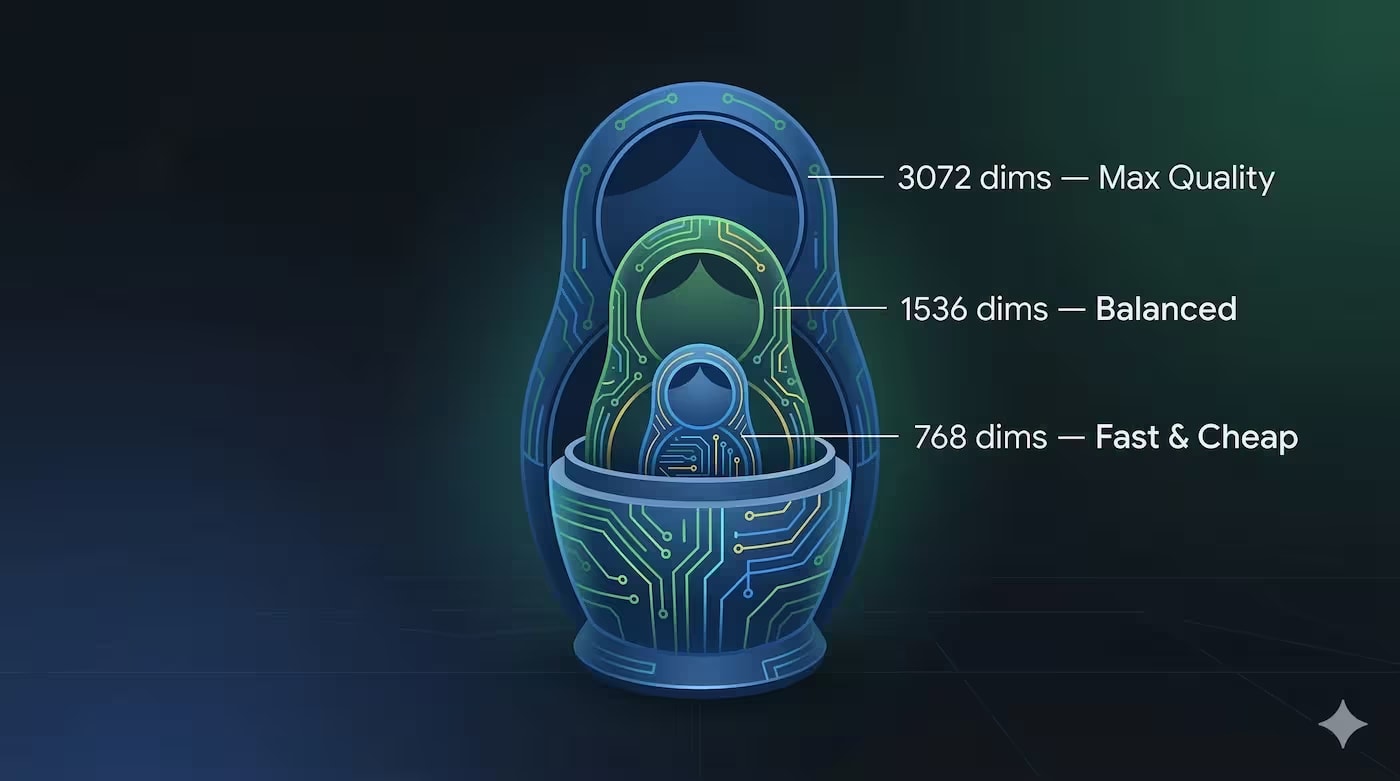
Порівняння text-embedding-3-small (1536) і text-embedding-3-large (3072) для RAG 2026. RAM, вартість, MTEB-бенчмарки, reranking як альтернатива. Матриця вибору

Порівняння OCR-first і Vision-first архітектур для обробки документів у RAG-системах 2026. GPT-4o, Gemini, Qwen2.5-VL, olmOCR, Docling — trade-offs по якості
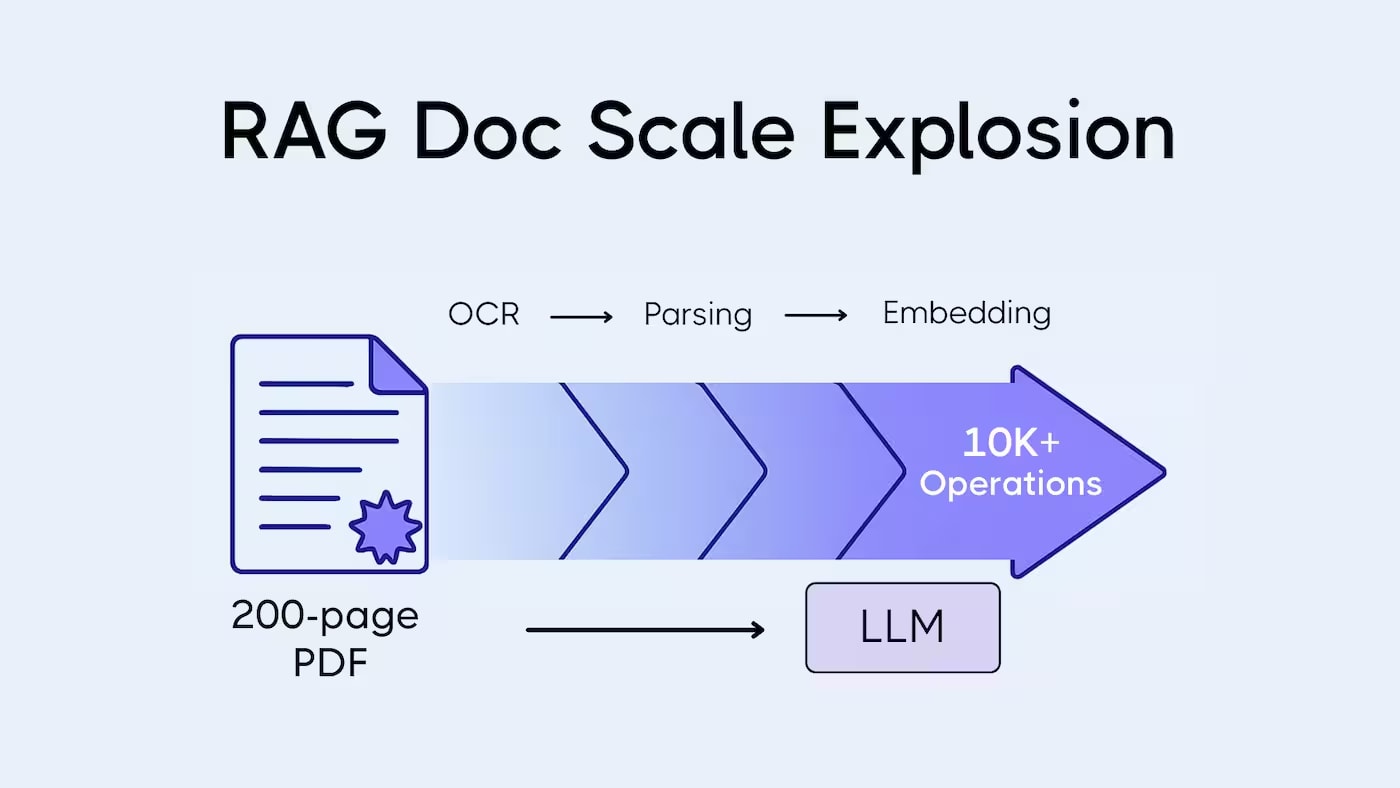
Технічний розбір того, як OCR-помилки руйнують chunking, спотворюють embeddings і знижують recall у RAG-пайплайні. З реальними прикладами артефактів

Покроковий гайд: завантаження GGUF з Hugging Face, створення Modelfile, ollama create і run, перевірка tool calling і типові помилки. З реальними командами

Огляд оновлення Ollama 0.30: підтримка GGUF з Hugging Face, Vulkan за замовчуванням, прискорення на NVIDIA, інтеграція з llama.cpp і ollama launch.

Чому 70–80% корпоративних документів недоступні для AI без OCR. Як розпізнавання тексту вписується в RAG-пайплайн і коли потрібен Vision OCR.

SWE-bench, Terminal-Bench, GPQA, long-context — розбираємо всі бенчмарки Claude Opus 4.8 з цифрами. Де Anthropic попереду, де поступається GPT-5.5

Як один інструмент WebPageTool мало не зруйнував економіку AI-агента. 11 повторних викликів, проблема з токенами, відмінності локальних і хмарних моделей

Anthropic випустила Claude Opus 4.8 — нову версію флагманської моделі з акцентом на чесність, надійність та agentic workflows. Розбираємо, що змінилося

NVIDIA відкрила доступ до 100+ AI-моделей безкоштовно через NIM API. Розбираємо архітектуру inference layer, порівняння з Groq та Together AI і обмеження в prod
Tavily, Brave, Exa, SerpAPI, Serper — чесне порівняння з актуальними цінами 2026. Таблиця рішень по сценаріях і типові помилки архітектури search tools.

Як керувати контекстом AI агента у довгих сесіях: sliding window, rolling summary, critical facts і compression — архітектура з реальними цифрами і кодом.

In-context, episodic, RAG і semantic memory для AI агентів на Spring Boot. Реальний ContextService з production, decision tree і код з pgvector.

Grok Build від xAI: Plan Mode, 2M токенів контексту, паралельні субагенти. Технічний огляд early beta CLI-агента. Порівняння з Claude Code та Codex CLI.