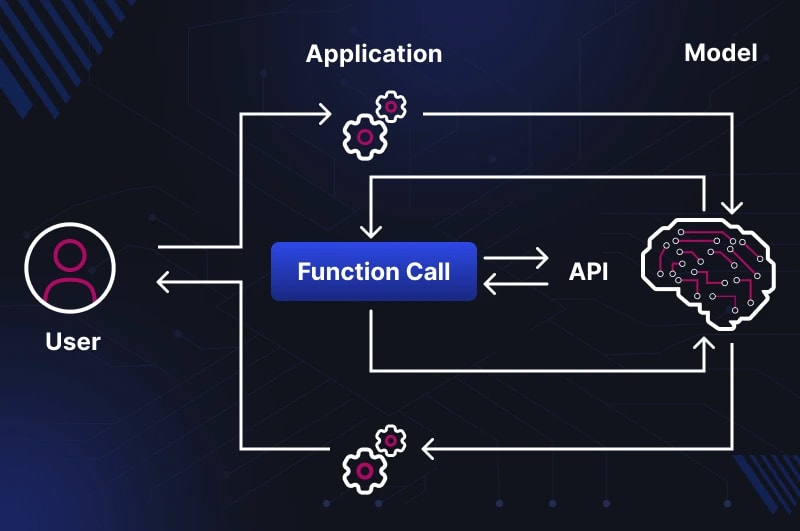
Коли розробник вперше бачить як LLM «викликає функцію» — виникає інтуїтивна помилка:
здається що модель сама виконала запит до бази або API.
Це не так, і саме ця помилка породжує цілий клас архітектурних багів.
Спойлер: LLM лише повертає структурований JSON з назвою функції та аргументами —
все виконання відбувається у вашому коді.
⚡ Коротко
- ✅ LLM — оркестратор, не виконавець: модель формує JSON-запит, ваш код його виконує
- ✅ Function Calling = Tool Use: різні назви від OpenAI і Anthropic для однієї механіки
- ✅ tool_choice: auto — модель вирішує сама; required — примусовий виклик; none — тільки текст
- ✅ RAG і Tool Use — різні рівні абстракції: RAG може бути одним з інструментів у системі Tool Use
- 🎯 Ви отримаєте: чітке розуміння механіки function calling і де вона перетинається з вашим RAG pipeline
- 👇 Нижче — детальні пояснення, приклади коду та таблиці
📚 Зміст статті
⸻
Що таке Function Calling — модель як оркестратор, не виконавець
Базовий принцип, який постійно плутають:
LLM не виконує функцію сама.
Вона лише аналізує контекст, визначає яку функцію викликати і з якими аргументами —
і повертає структурований JSON-запит. Виконання відбувається у runtime вашого застосунку.
Щоб зрозуміти чому так, треба подивитись на архітектуру з правильного кута.
LLM — це stateless text transformer. Вона не має сокетів, не може відкрити з'єднання до бази,
не може зробити HTTP-запит. Все що вона робить — приймає токени на вхід і генерує токени на виході.
Function calling — це просто домовленість про формат цих вихідних токенів:
замість природного тексту модель генерує структурований JSON,
який ваш код інтерпретує як інструкцію до дії.
Повний цикл виклику
Symflower (2025)
описує це так: LLM просить Agent Scaffolding виконати tool call від її імені.
Comet (2026)
деталізує цикл через патерн TAO — Thought → Action → Observation:
1. User message → LLM
↓
2. LLM аналізує контекст (Thought)
→ повертає JSON з назвою функції та аргументами
↓
3. Agent Scaffolding парсить JSON (Action)
→ виконує функцію у вашому коді
→ отримує результат
↓
4. Результат передається назад у LLM як tool result (Observation)
↓
5. LLM генерує фінальну відповідь користувачу
Зверніть увагу: між кроком 2 і кроком 4 — LLM взагалі не задіяна.
Вона «чекає» поки ваш код виконає роботу і поверне результат.
Саме тому помилки у tool call найчастіше виникають не у моделі,
а між кроками 3 і 4 — у вашому коді обробки результату.
Ця архітектура має назву Agent Scaffolding — прошарок між LLM і зовнішнім світом,
який керує циклом виклику. У простих випадках це кілька рядків Python.
У складних — повноцінні фреймворки на кшталт LangGraph або AutoGen.
Але принцип залишається однаковим: модель вирішує що робити, код виконує.
Термінологічна довідка: Function Calling vs Tool Use
Обидва терміни описують одну механіку — але з різних точок зору:
-
Function Calling — оригінальний термін OpenAI (з'явився у GPT-4, червень 2023).
Фокус на тому що модель «викликає функцію» — звідси і назва.
Модель повертає об'єкт з
function.name і function.arguments.
-
Tool Use — ширший термін Anthropic і загальноіндустрійний стандарт 2024–2025.
Фокус на тому що модель «використовує інструмент» — підкреслює що це лише один із засобів,
а не самоціль. Охоплює кастомні функції + вбудовані інструменти (code interpreter, web search, file reading).
Як зазначає
Martin Fowler (2025):
«tool calling» — більш загальний і сучасний термін; обидва терміни співіснують з історичних причин.
Також варто знати: у документації Anthropic замість required використовується any,
а самі описи інструментів передаються через input_schema замість parameters —
незначні синтаксичні відмінності при ідентичній логіці.
Чому модель взагалі вміє це робити
Function calling — не вбудована «здатність» LLM у хардварному сенсі.
Це результат fine-tuning на синтетичних прикладах де правильна відповідь — JSON, а не текст.
Як описує
Simplicity is SOTA (2025),
провайдери генерують тисячі прикладів запит → tool call з Chain-of-Thought reasoning trace,
де модель вчиться не просто генерувати JSON,
а обґрунтовувати навіщо цей конкретний інструмент потрібен у цьому конкретному контексті.
Якість tool calling прямо залежить від якості опису інструментів.
Модель навчена розпізнавати намір через description — якщо опис розмитий або відсутній,
модель або не викличе інструмент, або викличе не той.
Детально про це — у Як модель LLM вирішує коли шукати — механіка прийняття рішень.
Паралельні виклики: коли одного інструменту недостатньо
Сучасні моделі підтримують паралельні tool calls в одному повороті —
коли для відповіді потрібно кілька незалежних джерел одночасно.
Наприклад, запит «порівняй умови договорів A і B» може спровокувати два паралельних виклики
search_documents з різними параметрами замість двох послідовних.
# Відповідь моделі при паралельних tool calls:
{
"tool_calls": [
{
"id": "call_001",
"function": {
"name": "search_documents",
"arguments": "{\"query\": \"умови договору А\", \"top_k\": 3}"
}
},
{
"id": "call_002",
"function": {
"name": "search_documents",
"arguments": "{\"query\": \"умови договору Б\", \"top_k\": 3}"
}
}
]
}
Ваш код повинен обробити обидва результати і передати їх назад у наступному повідомленні
як два окремих tool_result блоки.
Якщо повернути тільки один — модель отримає неповний контекст і може галюцинувати другу частину відповіді.
⚠️ Підводний камінь #1: невидима помилка між кроком 3 і 4
Найпоширеніша помилка в архітектурі: розробник вважає що модель «виконала запит до бази даних»,
тоді як насправді вона лише сформувала JSON-запит, і виконання взагалі могло не відбутись
через помилку у коді обробки tool call.
LLM при цьому отримує порожній або помилковий результат — і продовжує генерувати відповідь
ніби нічого не сталось, часто галюцинуючи замість визнання проблеми.
Мінімальний checklist для надійного циклу:
- Логуйте весь цикл: tool call request → execution → result → model response
- Перевіряйте що
arguments успішно десеріалізовано через json.loads() до виконання
- Обробляйте виняток якщо функція повернула помилку — і явно передавайте цю помилку назад у LLM
- При паралельних викликах — завжди повертайте результати для всіх
tool_call.id
Як виглядає виклик технічно: JSON schema, tool_choice auto/required/none
Щоб модель знала про інструменти, їх треба описати у форматі JSON Schema і передати в API-запит.
Синтаксис відрізняється залежно від провайдера — і ця різниця практична:
код написаний під OpenAI не запрацює з Anthropic API без правки одного ключового поля.
Синтаксис OpenAI vs Anthropic: де ламається код
Головна відмінність: OpenAI використовує ключ parameters,
Anthropic — input_schema. Решта структури ідентична.
# OpenAI / OpenAI-сумісний API
tools = [
{
"type": "function",
"function": {
"name": "search_documents",
"description": "Шукає релевантні фрагменти у корпоративній базі знань",
"parameters": { # ← OpenAI: "parameters"
"type": "object",
"properties": {
"query": {
"type": "string",
"description": "Текст пошукового запиту"
},
"top_k": {
"type": "integer",
"description": "Кількість фрагментів (за замовчуванням 5)"
}
},
"required": ["query"]
}
}
}
]
# Anthropic Claude API (нативний)
tools = [
{
"name": "search_documents",
"description": "Шукає релевантні фрагменти у корпоративній базі знань",
"input_schema": { # ← Anthropic: "input_schema", без обгортки "function"
"type": "object",
"properties": {
"query": {
"type": "string",
"description": "Текст пошукового запиту"
},
"top_k": {
"type": "integer",
"description": "Кількість фрагментів (за замовчуванням 5)"
}
},
"required": ["query"]
}
}
]
Якщо використовуєте LiteLLM або LangChain — вони абстрагують цю різницю
і конвертують формат автоматично. При прямій роботі з Anthropic SDK — тільки input_schema.
Що повертає модель і як передати результат назад
Більшість туторіалів зупиняються на тому як модель повертає tool call.
Але найчастіше розробники застрягають на наступному кроці —
як правильно передати результат виконання назад у наступному повідомленні.
Крок 1. Модель повертає tool call замість тексту:
# Відповідь моделі (stop_reason: "tool_use")
{
"content": [
{
"type": "tool_use",
"id": "toolu_01XFDUDYJgAACTvYkLMeDRVQ", # ← id потрібен для наступного кроку
"name": "search_documents",
"input": {
"query": "умови розірвання договору",
"top_k": 5
}
}
],
"stop_reason": "tool_use"
}
Зверніть увагу: у Anthropic API поле називається input (вже об'єкт),
а не arguments (рядок як у OpenAI). Десеріалізація через json.loads()
потрібна тільки при роботі з OpenAI-форматом.
Крок 2. Ваш код виконує функцію і формує наступний запит:
import anthropic, json
client = anthropic.Anthropic()
# Перший запит
response = client.messages.create(
model="claude-opus-4-6",
max_tokens=1024,
tools=tools,
messages=[{"role": "user", "content": "Які умови розірвання договору?"}]
)
# Отримуємо tool call з відповіді
tool_use_block = next(b for b in response.content if b.type == "tool_use")
tool_result = search_documents(**tool_use_block.input) # ваша функція
# Другий запит — передаємо результат назад
follow_up = client.messages.create(
model="claude-opus-4-6",
max_tokens=1024,
tools=tools,
messages=[
{"role": "user", "content": "Які умови розірвання договору?"},
{"role": "assistant", "content": response.content}, # ← вся відповідь моделі
{
"role": "user",
"content": [
{
"type": "tool_result",
"tool_use_id": tool_use_block.id, # ← id з кроку 1
"content": json.dumps(tool_result, ensure_ascii=False)
}
]
}
]
)
Три критичних деталі цього циклу:
-
tool_use_id у результаті повинен точно співпадати з id з tool call —
інакше API поверне помилку валідації
-
У
messages передається вся відповідь моделі (response.content),
а не тільки текст — модель повинна бачити свій власний tool call у контексті
-
При паралельних викликах (кілька tool calls в одній відповіді) —
потрібно повернути
tool_result для кожного id,
інакше наступний запит поверне помилку
Параметр tool_choice
Параметр tool_choice контролює режим прийняття рішення про виклик інструменту.
Офіційна документація Anthropic
визначає чотири варіанти:
| Значення |
Поведінка |
Коли використовувати |
⚠️ Підводний камінь |
auto |
Модель сама вирішує: текст чи tool call |
Типовий conversational сценарій. Default якщо передані tools. |
Модель може не викликати tool якщо опис нечіткий або вона «впевнена» у відповіді з власних знань — навіть якщо дані застаріли |
any / required |
Модель зобов'язана викликати хоча б один інструмент |
Structured output, обов'язкове логування, примусовий запит до зовнішнього API |
Викликає інструмент навіть на «Привіт» — зайві токени і затримка. Несумісний з extended thinking у Claude (HTTP 400) |
none |
Модель не викликає жодного інструменту, генерує тільки текст |
Відповідь виключно з переданого контексту; фінальний крок після отримання всіх результатів |
Якщо передати none разом з tool_result у messages — API поверне помилку: tool definitions мають бути присутні |
{"type": "tool", "name": "..."} |
Форсований виклик конкретного інструменту |
Тестування окремого інструменту, детермінований pipeline |
Несумісний з extended thinking. Модель не генерує текст перед tool call — навіть якщо явно попросити |
Примітка щодо термінології: OpenAI використовує required,
Anthropic — any для позначення «обов'язково викликати хоча б один інструмент».
LiteLLM конвертує між форматами автоматично.
Це не просто концептуальна різниця — це різниця в тому хто контролює flow.
У RAG pipeline рішення про пошук закодовано в архітектурі.
У Tool Use — модель є активним учасником цього рішення.
Розуміння цієї межі визначає які проблеми ви отримаєте у production і де їх шукати.
Класичний RAG: детермінований pipeline
Запит користувача
→ Embedding запиту ← перетворення тексту у вектор
→ Пошук у векторній БД (завжди, без умов)
→ Reranking результатів
→ Формування контексту (prompt stuffing)
→ Передача в LLM
→ Відповідь
Кожен крок відбувається незалежно від змісту запиту.
Якщо користувач запитує «скільки буде 2+2» — pipeline все одно зробить embed,
піде у Qdrant, поверне топ-5 фрагментів і передасть їх у контекст моделі.
Модель отримає непотрібний контекст і змушена його ігнорувати.
Перший крок цього pipeline — embedding — заслуговує окремої уваги:
саме тут текст перетворюється на числовий вектор, який несе семантичний сенс, а не просто ключові слова.
Як це працює технічно —
Embeddings простими словами: як AI розуміє сенс, а не просто слова
.
Докладніше про повну механіку RAG pipeline від чанкінгу до rerank:
RAG у 2026: від PoC до Production — повний гайд
.
Про принципову різницю між можливостями «чистої» LLM і RAG-системи —
LLM vs RAG у 2026 році: чому це не одне й те саме
.
Це не баг — це свідома архітектурна ціна за передбачуваність.
Tool Use: модель як активний агент
Запит користувача
→ LLM аналізує контекст і наміри
→ Рішення: відповісти з власних знань / викликати tool / викликати кілька tools паралельно
↓ якщо tool call
→ Який інструмент? З якими параметрами?
→ JSON → Agent Scaffolding → виконання → результат → LLM
→ Фінальна відповідь
Модель не просто генерує текст — вона приймає рішення про flow.
На запит «скільки буде 2+2» відповість напряму, не торкаючись жодного інструменту.
На запит «які умови розірвання договору» — викличе search_documents.
На запит «порівняй договори А і Б» — можливо, два паралельних виклики одного інструменту
з різними параметрами.
Де проходить реальна межа
Ключова аналогія: RAG — це бібліотекар, який завжди іде до полиці перед відповіддю.
Tool Use — це консультант, який спочатку думає, і вже потім вирішує чи треба дивитись у документи.
Консультант ефективніший — але його рішення менш передбачуване.
| Характеристика |
RAG pipeline |
Tool Use |
| Хто вирішує «шукати чи ні» |
Архітектура — завжди шукає |
Модель — залежно від контексту |
| Кількість джерел даних |
Зазвичай одне (векторна БД) |
Будь-яка кількість інструментів |
| Передбачуваність поведінки |
Висока — однаковий шлях завжди |
Нижча — залежить від рішення моделі |
| Латентність |
Стабільна і прогнозована |
Варіативна: від 0 до N tool calls |
| Вартість на запит |
Фіксована |
Залежить від кількості викликів |
| Ефективність на простих запитах |
Низька — зайвий retrieve завжди |
Висока — модель пропускає зайве |
| Складність дебагінгу |
Низька — один детермінований шлях |
Вища — треба логувати весь цикл рішень |
| Ризик «не знайти» потрібне |
Тільки якщо поганий retriever |
Ще й якщо модель вирішила не шукати |
RAG всередині Tool Use: що це дає і що коштує
RAG pipeline може бути реалізований як один з інструментів у системі Tool Use —
тобто search_knowledge_base(query) стає tool, який модель викликає за потреби.
Це дає реальну перевагу: непотрібні embedding-запити і пошуки не відбуваються,
токени на формування контексту не витрачаються даремно.
Але є ціна:
-
Нові точки відмови.
У класичному RAG retrieve гарантований. У Tool Use — модель може вирішити не шукати
на запиті де пошук критично потрібний. Особливо небезпечно коли модель «впевнена»
у відповіді з власних знань, але ці знання застаріли.
-
Якість опису інструменту стає критичною.
Якщо
description розмитий або не покриває сценарій — модель не викличе tool.
У класичному RAG опис не впливає на рішення про пошук взагалі.
Детально про те як писати description — у TU-2.
-
Observability складніша.
У RAG pipeline завжди є лог retrieve запиту і результату.
У Tool Use треба окремо логувати рішення моделі (викликала / не викликала),
параметри виклику і результат — щоб розуміти де відповідь пішла не туди.
Практичний висновок: коли що обирати
Залишайтесь на класичному RAG якщо:
єдине джерело даних — корпоративна база документів,
всі запити потребують пошуку,
критична передбачуваність і простота дебагінгу,
SLA на latency жорсткий.
Переходьте до Tool Use якщо:
є кілька різних джерел даних (БД + API + файли),
частина запитів не потребує зовнішніх даних взагалі,
потрібна можливість паралельних запитів до різних систем,
будуєте agentic систему де retrieval — лише один зі сценаріїв.
⚠️ Підводний камінь
Найнебезпечніший сценарій у «RAG через Tool Use»:
модель відповідає впевнено і зв'язно, але без виклику інструменту —
тому що вирішила що знає відповідь сама.
У корпоративному контексті (договори, ціни, регламенти) це означає відповідь
яка може бути правильною за формою але неактуальною за змістом.
Завжди логуйте stop_reason: якщо він "end_turn" без попереднього
"tool_use" — модель не шукала. Вирішуйте чи це прийнятно для вашого сценарію.
Де RAG і Tool Use перетинаються — і де розходяться
Попередній розділ показав різницю в архітектурній логіці.
Тут — практика: як ці два підходи взаємодіють в реальних системах,
які патерни поєднання працюють, і де межа між ними розмивається навмисно.
Три патерни поєднання
Патерн 1: RAG як самостійний pipeline (без Tool Use)
Класичний варіант. Retrieve відбувається завжди, модель отримує контекст автоматично.
Підходить коли всі запити потребують пошуку і передбачуваність важливіша за ефективність.
AskYourDocs
у базовій конфігурації — саме цей патерн.
Патерн 2: RAG як один з інструментів у Tool Use системі
Модель отримує search_knowledge_base(query) як tool і вирішує коли його викликати.
Прості запити («що таке PDF?», «привіт») обробляються без retrieve.
Складні або специфічні — тригерять пошук.
Це підвищує ефективність але додає нову точку відмови: модель може не викликати tool коли треба.
Патерн 3: Кілька спеціалізованих інструментів + RAG як один з них
Найбільш потужний і найбільш складний варіант.
Модель має доступ до кількох інструментів одночасно:
tools = [
search_knowledge_base(query), # RAG по корпоративних документах
get_contract_status(contract_id), # запит до CRM/ERP
calculate_deadline(date, days), # обчислення дат
send_notification(user_id, text), # дія у зовнішній системі
]
Тут RAG — вже не весь pipeline, а один спеціалізований інструмент серед інших.
Модель сама вирішує комбінацію: наприклад, спочатку search_knowledge_base
щоб знайти умови договору, потім get_contract_status щоб перевірити поточний статус,
і нарешті згенерувати відповідь на основі обох результатів.
Де межа розмивається: RAG з внутрішньою логікою вибору
Є проміжний варіант який часто недооцінюють:
класичний RAG pipeline з pre-retrieval routing всередині.
Перед тим як іти у векторну БД, легкий класифікатор або промпт вирішує
чи взагалі потрібен retrieve для цього запиту.
# Спрощена логіка pre-retrieval routing
def should_retrieve(query: str) -> bool:
# Простий евристичний класифікатор
factual_keywords = ["договір", "умови", "ціна", "регламент", "дедлайн"]
return any(kw in query.lower() for kw in factual_keywords)
def answer(query: str) -> str:
if should_retrieve(query):
context = retriever.search(query)
return llm.generate(query, context=context)
else:
return llm.generate(query) # без retrieve
Це не «чистий» Tool Use — рішення приймає код, не модель.
Але і не «чистий» RAG — retrieve не завжди відбувається.
Такий гібрид дає передбачуваність класичного pipeline
плюс частину ефективності Tool Use підходу.
Ціна — підтримка класифікатора і ризик хибних спрацювань.
Порівняння патернів
| Патерн |
Хто вирішує retrieve |
Складність |
Найкраще для |
| RAG pipeline |
Архітектура (завжди) |
Низька |
Єдина база знань, всі запити потребують пошуку |
| RAG + pre-retrieval routing |
Класифікатор у коді |
Середня |
Змішані запити, потрібна передбачуваність |
| RAG як tool у Tool Use |
LLM (за контекстом) |
Середня |
Переважно документні запити + невеликий відсоток «чистих» LLM |
| Кілька tools + RAG як один |
LLM (за контекстом) |
Висока |
Агентні системи, кілька джерел даних, складні workflow |
Де конкретно перетинаються: спільні компоненти
Незалежно від патерну, обидва підходи спираються на одні й ті самі базові компоненти:
-
Embedding модель — потрібна у RAG для векторного пошуку,
і може бути потрібна у Tool Use для tool retrieval коли інструментів 50+
Як embeddings перетворюють текст у семантичний вектор —
Embeddings простими словами: як AI розуміє сенс, а не просто слова
.
-
Векторна БД — у RAG зберігає документні чанки,
у Tool RAG системах зберігає описи інструментів для семантичного пошуку по реєстру tools.
-
Reranker — у RAG переоцінює релевантність фрагментів,
у Tool Use може переоцінювати релевантність інструментів при великому реєстрі.
-
Observability шар — в обох випадках критично логувати
що було знайдено / викликано і що потрапило в контекст моделі.
⚠️ Підводний камінь #3: ілюзія вибору
Найчастіша архітектурна помилка при переході з RAG на Tool Use:
розробник переконаний що «модель розумна і сама вирішить коли шукати» —
і не витрачає час на якісний description інструменту.
У результаті модель або не викликає tool на запитах де він потрібний,
або викликає на запитах де він зайвий.
Інструмент без чіткого опису — це бібліотека без каталогу:
технічно доступна, але практично недосяжна.
Детально про механіку цього рішення і як писати опис — у
TU-2: Як модель вирішує коли шукати.
Це один з найпоширеніших термінологічних міксів у 2026 році. Побачивши як модель викликає get_weather() або search_documents(), розробники кажуть «я зробив агента». Насправді вони зробили LLM з інструментом — це важливий крок, але не агентність.
Що таке агент насправді
Comet (2026) визначає агента через три обов'язкові компоненти:
- Цикл (Loop): агент не робить один виклик і зупиняється. Він працює в циклі: думає → діє → спостерігає → думає знову. Кількість кроків не визначена наперед.
- Пам'ять (Memory): агент пам'ятає що він вже зробив, які результати отримав, і використовує це для наступних рішень. Не тільки діалогова історія — але й проміжні результати виконання.
- Планування (Planning): агент може розбивати складну ціль на підзадачі, визначати порядок дій, змінювати план якщо щось пішло не так.
Tool Use без цих трьох компонентів — це просто LLM з RPC-викликами. Технічно нічим не відрізняється від того, як звичайна програма викликає функцію. Різниця лише в тому, хто вирішує яку функцію викликати: програміст (код) чи модель (промпт).
Спектр складності: від простого виклику до справжнього агента
Агентність — це не бінарна властивість (або агент / або ні), а спектр. Зручно мислити в термінах «ступеня агентності»:
| Рівень | Що вміє | Приклад | Це агент? |
| L0: Single Tool Call | Один виклик, один результат, далі — відповідь | "Яка погода в Києві?" → get_weather → відповідь | ❌ Ні, звичайний tool use |
| L1: Sequential Tool Calls | Кілька викликів послідовно, без зворотного зв'язку між ними | "Знайди документ А і документ Б" → два виклики по черзі | ❌ Ні, просто pipeline |
| L2: Conditional Tool Calls | Результат першого виклику впливає на другий | "Знайди договір → якщо він активний, то перевір умови" | ⚠️ Частково — є зачатки планування |
| L3: ReACT-style Agent | Повний цикл: Thought → Action → Observation → повторювати | "Заплануй зустріч: знайди вільні слоти → обери найкращий → надішли запрошення" | ✅ Так, класичний агент |
| L4: Autonomous Agent | Як L3 + довготривала пам'ять + самостійне планування підзадач | "Підготуй звіт за місяць" → сам вирішує які дані зібрати, в якому порядку, і робить це | ✅ Так, повноцінний агент |
Ключовий висновок: Tool Use з'являється на рівні L0. Але тільки на L3 з'являється справжня агентність — цикл + планування.
Чому це важливо розуміти
Розробники, які плутають tool use з агентами, припускаються трьох типових помилок:
- Не додають цикл. Роблять один виклик, отримують результат — і думають що це агент. Але якщо для відповіді потрібно два інструменти, система падає.
- Не передають контекст виконання. Агент повинен отримувати назад не тільки результат функції, але й мета-інформацію: чи успішно виконано, скільки часу зайняло, які помилки сталися. Без цього агент «сліпий».
- Очікують магії. «Я додав інструменти — чому модель не будує складний план сама?» Тому що планування — це окрема здатність, яка потребує або правильного prompting, або спеціальних фреймворків (LangGraph, AutoGen, CrewAI).
Як виглядає мінімальний агентський цикл
Ось принципова різниця між одноразовим tool call і циклічним агентом:
# ❌ Це НЕ агент — це tool use response = client.messages.create( tools=[search_documents], messages=[{"role": "user", "content": "знайди документи про договір"}] ) result = execute_tool(response.tool_call) final = client.messages.create( messages=[..., tool_result] ) # ✅ Це МІНІМАЛЬНИЙ агент — з циклом max_iterations = 5 while iterations < max_iterations and not finished: response = client.messages.create( tools=tools, messages=conversation_history ) if response.stop_reason == "tool_use": for tool_call in response.tool_calls: result = execute_tool(tool_call) conversation_history.append(tool_result(tool_call.id, result)) continue # ← цикл! повертаємось до моделі з результатом # stop_reason == "end_turn" — агент вирішив що відповідь готова finished = True return response.content
Різниця в одному рядку — continue. Але саме він створює цикл, дозволяючи моделі робити кілька кроків, бачити результати своїх дій і приймати наступні рішення на основі побаченого. Без циклу — це просто RPC. З циклом — зародок агента.
⚠️ Підводний камінь #4: агент це не завжди добре
Агенти звучать круто. Але вони мають реальну ціну:
- Непередбачувана кількість викликів. Один запит може породити 1 tool call, а може 10 — залежно від складності і якості промптів. Витрати на токени і latency стають недетермінованими.
- Ризик зациклення. Без захисних механізмів агент може потрапити в нескінченний цикл: викликає інструмент → отримує помилку → викликає знову → знову помилка. Завжди додавайте
max_iterations і виявлення повторюваних патернів. - Складність дебагінгу. У звичайному tool use ви знаєте: був один виклик → отримали відповідь. У агента — ланцюжок з N кроків, кожен з яких міг піти не так. Інструменти спостережності (langfuse, helicone, arize) стають не опцією, а необхідністю.
Практична порада: починайте з L0 (single tool call) або L1 (sequential). Додавайте цикл і планування тільки коли простий pipeline дійсно впирається в обмеження. Агент — це інструмент для складних задач, а не дефолтна архітектура.
Коротко: запам'ятайте формулу
Tool Use = LLM вирішує який інструмент викликати.
Агент = Tool Use + цикл + пам'ять + планування.
Якщо у вас є тільки перший рядок — у вас не агент. І це нормально. Більшість задач не потребують повної агентності. Але називати речі своїми іменами важливо, щоб будувати правильні очікування у команди і стейкхолдерів.
Від RAG pipeline до Tool Use: що далі
Якщо ви прийшли з
RAG-хабу
,
ваш поточний стек виглядає приблизно так: документи → чанкінг → embed → Qdrant → BM25 + rerank → LLM.
Це класичний RAG pipeline — детермінований, передбачуваний, добре відлагоджений.
Tool Use Hub, який ви зараз читаєте, описує що відбувається навколо цього pipeline:
- Як модель вирішує коли взагалі запускати пошук → Як модель LLM вирішує коли шукати — механіка прийняття рішень
AskYourDocs
— конкретний приклад продукту, де RAG pipeline є одним з інструментів у ширшій системі:
гібридний пошук по корпоративних документах, повна ізоляція даних на сервері клієнта,
без vendor lock-in на рівні LLM провайдера.
❓ Часті питання
В чому різниця між Function Calling і Tool Use?
Function Calling — оригінальний термін OpenAI. Tool Use — ширший термін Anthropic,
що охоплює також вбудовані інструменти (web search, code interpreter).
Механіка однакова: модель повертає JSON, ваш код виконує.
Чи виконує LLM функцію сама?
Ні. Модель формує структурований JSON-запит з назвою функції та аргументами.
Виконання — завжди на стороні вашого застосунку.
Чим RAG відрізняється від Tool Use?
RAG — детермінований pipeline де retrieve відбувається завжди.
Tool Use — механізм де модель сама вирішує чи потрібен виклик інструменту.
RAG може бути реалізований як один з інструментів у системі Tool Use.
Коли використовувати tool_choice: required?
Тільки у детермінованих pipeline — structured output, обов'язкове логування.
У conversational режимі це призводить до зайвих tool calls і витрат токенів.
Також: required / any несумісні з extended thinking у Claude.
✅ Висновки
- Function Calling і Tool Use — одна механіка, різні назви. Модель формує JSON, ваш код виконує.
tool_choice дає три режими контролю: auto (за замовчуванням), required (примусово), none (тільки текст).- RAG pipeline і Tool Use існують на різних рівнях абстракції — перший детермінований, другий адаптивний.
- RAG може бути інструментом у системі Tool Use — але це підвищує непередбачуваність і вимагає точного опису інструменту.
- Класичний RAG залишається кращим вибором для продуктів з єдиною базою знань і жорсткими вимогами до передбачуваності.
Наступний крок: як саме модель приймає рішення викликати інструмент чи ні —
і як на це впливає опис tool — розбираємо у
TU-2: Як модель вирішує коли шукати.
Джерела
Symflower — Function calling in LLM agents (2025) ·
Martin Fowler — Function calling using LLMs (2025) ·
Anthropic Docs — How to implement tool use ·
Prompt Engineering Guide — Function Calling with LLMs ·
Simplicity is SOTA — How LLMs are trained for function calling (2025) ·
Berkeley BFCL V4 (2025) ·
Comet — Agent Orchestration (2026)
