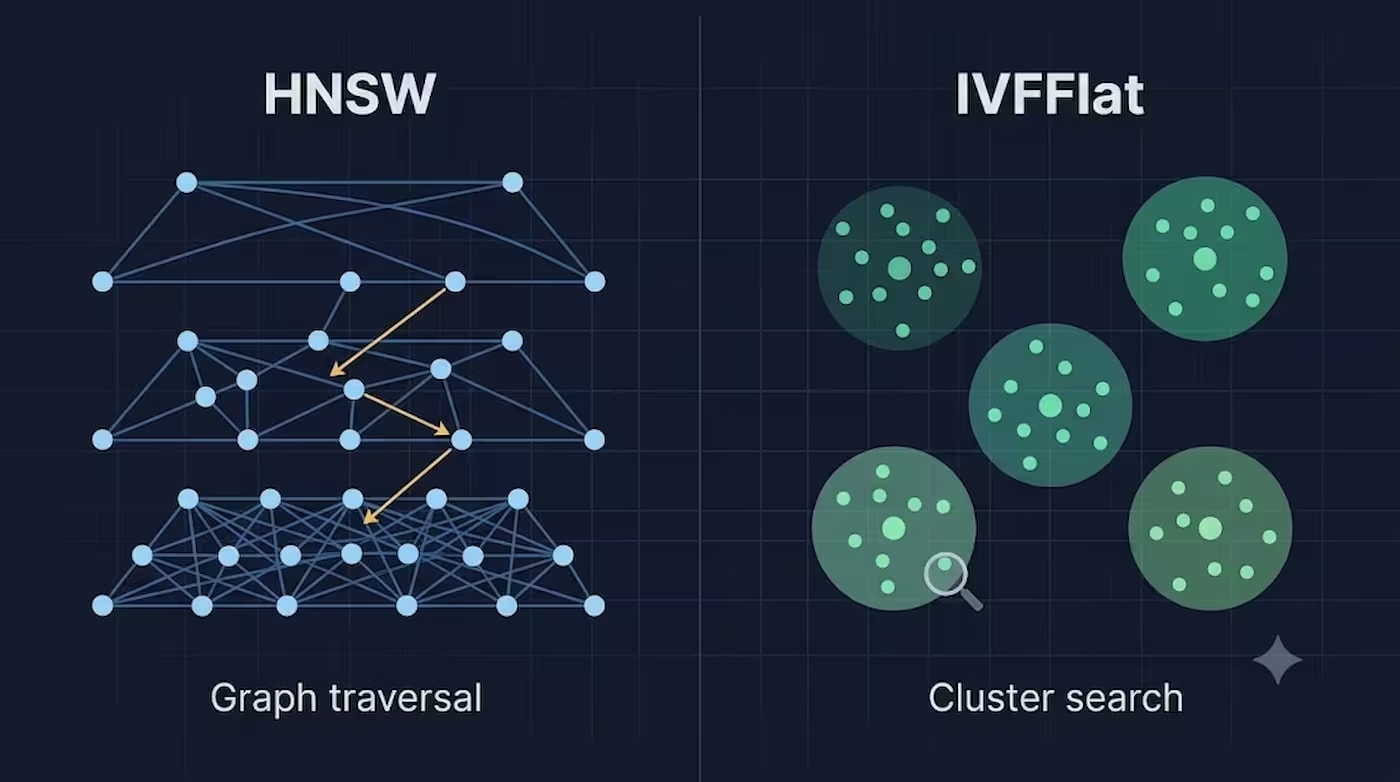
HNSW vs IVFFlat у pgvector: коли вам справді потрібен індекс
HNSW vs IVFFlat у pgvector: коли вам справді потрібен індекс У нас в продакшені 10 852 вектори в одній таблиці vector_store — і ми досі не використовуємо ні HNSW, ні IVFFlat. Це не недогляд. Спойлер: для більшості блогів і невеликих RAG-проєктів індекс взагалі не потрібен аж до десятків тисяч...