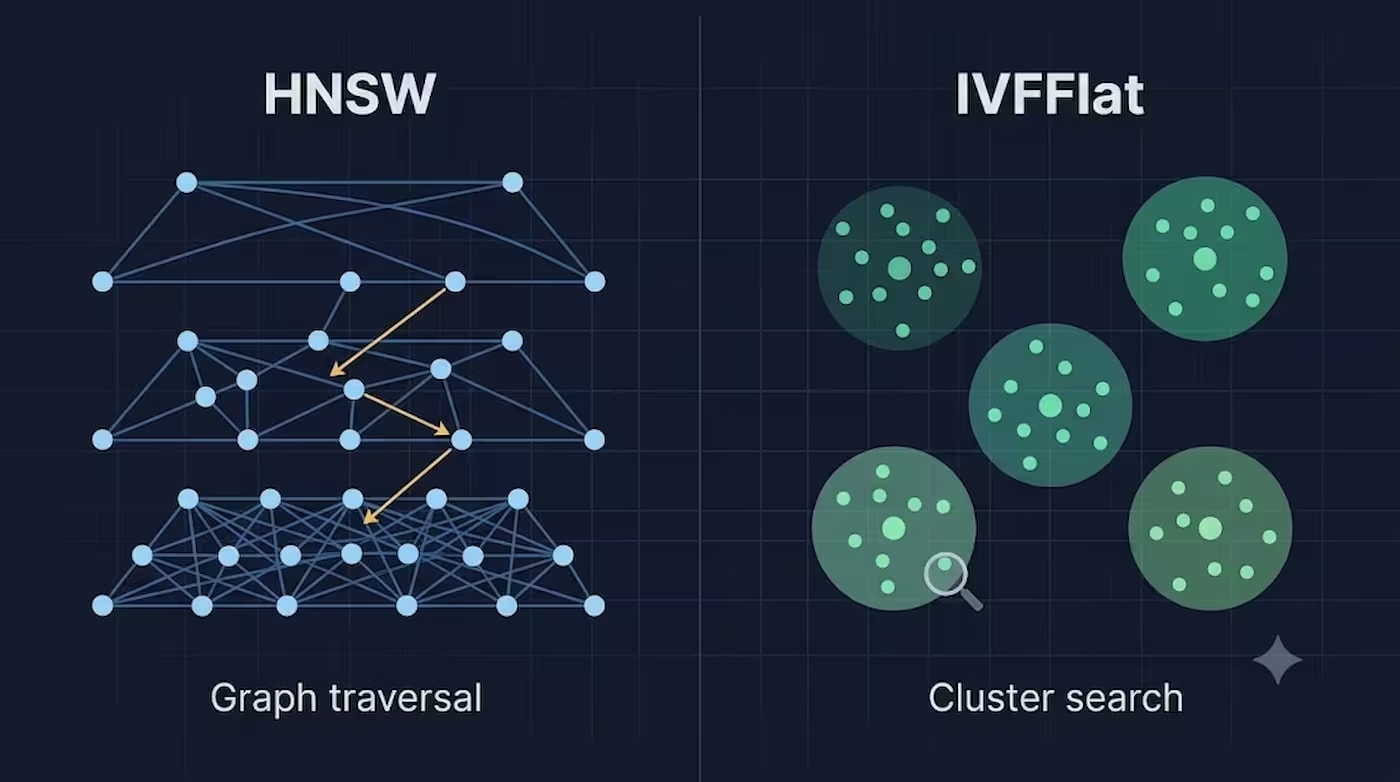
HNSW vs IVFFlat у pgvector: коли вам справді потрібен індекс
У нас в продакшені 10 852 вектори в одній таблиці vector_store — і ми досі не використовуємо ні HNSW, ні IVFFlat. Це не недогляд. Спойлер: для більшості блогів і невеликих RAG-проєктів індекс взагалі не потрібен аж до десятків тисяч рядків — а коли він знадобиться, неправильний вибір між HNSW і IVFFlat може тихо зламати точність пошуку на тижні, перш ніж ви це помітите.
⚡ Коротко
✅ До ~50 000 векторів: brute-force пошук (index-type=none) майже завжди швидший і простіший, ніж підтримка індексу
✅ HNSW: кращий recall, стабільна якість незалежно від порядку вставки даних, але +2-5x пам'яті та повільніша побудова
✅ IVFFlat: швидша побудова, менше пам'яті, але вимагає даних ДО створення індексу і періодичного REINDEX
🎯 Ви отримаєте: конкретні пороги переходу, реальні конфіги Spring AI, та два кейси — блог на 800 статей і сервіс на десятки тисяч документів
👇 Детальніше читайте нижче — з цифрами, SQL та поясненням чому третій індекс (DiskANN) теж існує
Що таке ANN-пошук і чому brute-force — це не завжди погано
Коли ви шукаєте найближчі вектори до запиту в pgvector, є два шляхи. Перший — порівняти запит з кожним рядком таблиці (exact nearest neighbor, точний пошук). Другий — використати індекс, який приблизно знаходить найближчих сусідів, не перевіряючи всі рядки (Approximate Nearest Neighbor, ANN).
Brute-force підхід (без індексу, index-type=none у Spring AI) масштабується лінійно — O(n). На 10 000 рядків це мілісекунди. На 10 мільйонів — вже секунди на запит, що неприйнятно для будь-якого продакшену з трафіком.
pgvector підтримує два основні типи ANN-індексів — HNSW і IVFFlat — а з версії 0.8.2 (лютий 2026) додатково існує розширення DiskANN через окремий пакет pgvectorscale для дуже великих датасетів, що виходять за межі shared_buffers(dbi-services, березень 2026). У цій статті фокус — на HNSW та IVFFlat, бо саме з ними стикається 95% проєктів.
Як працює HNSW
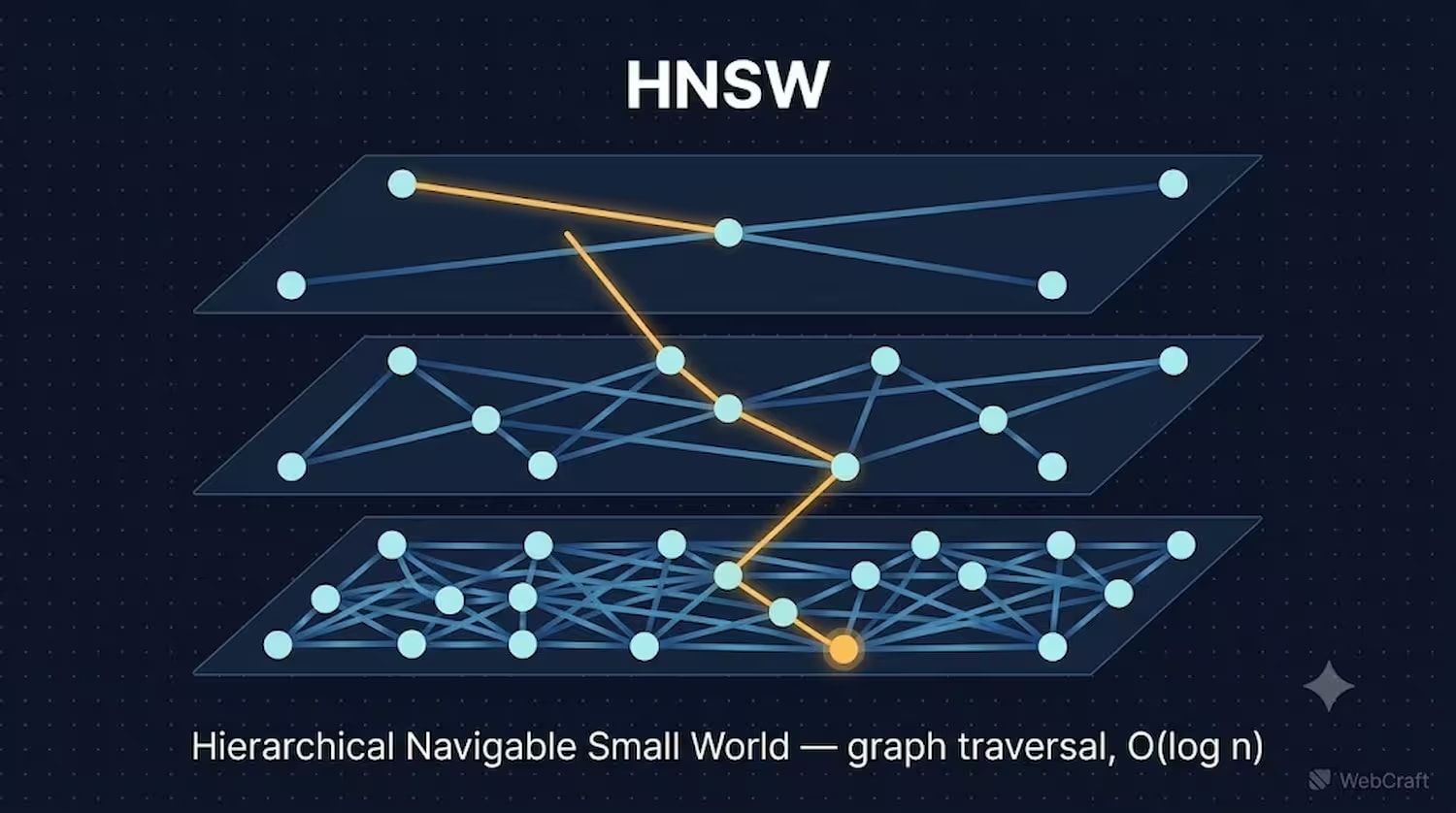
HNSW (Hierarchical Navigable Small World) будує багаторівневий граф зв'язків між векторами. Верхні рівні графа містять рідкі "магістральні" з'єднання для швидких далеких переходів, нижні — щільні локальні зв'язки для точного фінального пошуку. Запит входить на верхньому рівні та "спускається" вниз, звужуючи пошук до найближчих сусідів.
Аналогія, яка добре пояснює суть: уявіть пошук адреси в незнайомому місті. Замість того, щоб обходити кожну вулицю по черзі (це і є brute-force), ви спочатку виходите на швидкісну трасу (верхній рівень графа — далекі "магістральні" зв'язки), доїжджаєте до потрібного району, а потім переходите на місцеві вулиці (нижній рівень — щільні локальні зв'язки), щоб знайти точну адресу. Кожен "поверх" графа звужує простір пошуку, тому й виходить логарифмічна складність.
Завдяки цій структурі час пошуку зростає логарифмічно — O(log n) — і не залежить від порядку, в якому дані були завантажені (Philip McClarence, Medium, квітень 2026). HNSW можна будувати навіть на порожній таблиці — індекс адаптується по мірі вставки нових векторів.
Приклад створення індексу:
CREATE INDEX ON vector_store
USING hnsw (embedding vector_cosine_ops)
WITH (m = 16, ef_construction = 64);
Тут m — максимальна кількість зв'язків на вузол графа (більше зв'язків = вищий recall, але більше пам'яті), а ef_construction — наскільки широко алгоритм "оглядається" під час побудови індексу, шукаючи кандидатів для зв'язків. На етапі пошуку є симетричний параметр ef_search — він керує тим, скільки кандидатів розглядається під час самого запиту:
SET hnsw.ef_search = 40;
SELECT id, content
FROM vector_store
ORDER BY embedding <=> '[0.012, -0.034, ...]'
LIMIT 10;
Дефолтні значення (m=16, ef_construction=64, ef_search=40) — це не випадкові числа, а ретельно підібрана відправна точка. Більшість скарг типу "pgvector повільний" виникають саме тому, що ці параметри ніколи не підлаштовувалися під конкретний датасет (Nerd Level Tech, травень 2026).
Плата за якість пошуку — пам'ять і час побудови. Емпіричне правило для оцінки об'єму пам'яті під час побудови індексу: N × D × 4 байти × 2 (множник 2 враховує накладні витрати на сам граф) (DEV Community, березень 2026). Для 5 мільйонів векторів з 1536 вимірами це означає 8-16 ГБ робочої пам'яті лише на побудову.
Готовий індекс теж займає багато місця: приблизне правило — 6-8 ГБ RAM на кожен мільйон векторів з 1536 вимірами для HNSW у пам'яті (Groovyweb, 2026). Варто зауважити: розмірність вектора (1536 проти, наприклад, 3072) прямо пропорційно впливає на цю цифру — детальніше про те, коли більша розмірність embeddings дійсно виправдана, ми розбирали в статті «1536 vs 3072: порівняння embeddings для пошуку по документах та RAG».
Реальні цифри пам'яті: чому HNSW "їсть" більше, ніж здається
Багато хто бачить цифру "6-8 ГБ на 1M векторів" і думає, що це і є вартість HNSW. Насправді це сума двох окремих складових, і саме друга — головний недолік HNSW, який легко недооцінити.
Приклад: 1 мільйон векторів × 1536 вимірів
Складова
Розрахунок
Обсяг
Самі вектори (heap-таблиця)
1 000 000 × 1536 × 4 байти
≈ 6 ГБ
HNSW-індекс (граф зв'язків)
залежить від m, в середньому +20-50% від обсягу векторів
+1-3 ГБ
Разом
7-9 ГБ RAM
Ось у чому головний недолік, який часто упускають: ці 6 ГБ під самі вектори потрібні в будь-якому випадку — навіть з index-type=none, навіть з IVFFlat. Це базова вартість зберігання даних. А додаткові 1-3 ГБ — це чистий накладний витрат саме на структуру графа HNSW: масив зв'язків (neighbors) для кожного вузла на кожному рівні графа, який потрібно тримати в пам'яті для швидкого обходу.
На практиці це означає: якщо ваш Postgres-інстанс ледь вміщує самі дані (ті базові 6 ГБ), додавання HNSW-індексу може штовхнути загальне споживання пам'яті за межі доступного shared_buffers, і частина графа почне витискатися на диск — а це саме той сценарій, де пошук стає повільнішим, а не швидшим, всупереч теоретичній перевазі O(log n)(dbi-services, березень 2026).
IVFFlat у цьому сенсі чесніший: він не додає окремої структури зв'язків поверх даних, а лише зберігає номер кластера для кожного вектора — тому й займає суттєво менше пам'яті понад базові 6 ГБ.
Практичний наслідок параметра maintenance_work_mem: якщо його значення замале (дефолт у Postgres зазвичай 64 МБ), побудова HNSW-індексу "переливається" на диск і виконується в 10-50 разів повільніше (DEV Community, березень 2026). Перед побудовою індексу на великому датасеті варто тимчасово підняти цей параметр:
SET maintenance_work_mem = '2GB';
CREATE INDEX ON vector_store
USING hnsw (embedding vector_cosine_ops);
-- після побудови можна повернути дефолт
RESET maintenance_work_mem;
Як працює IVFFlat
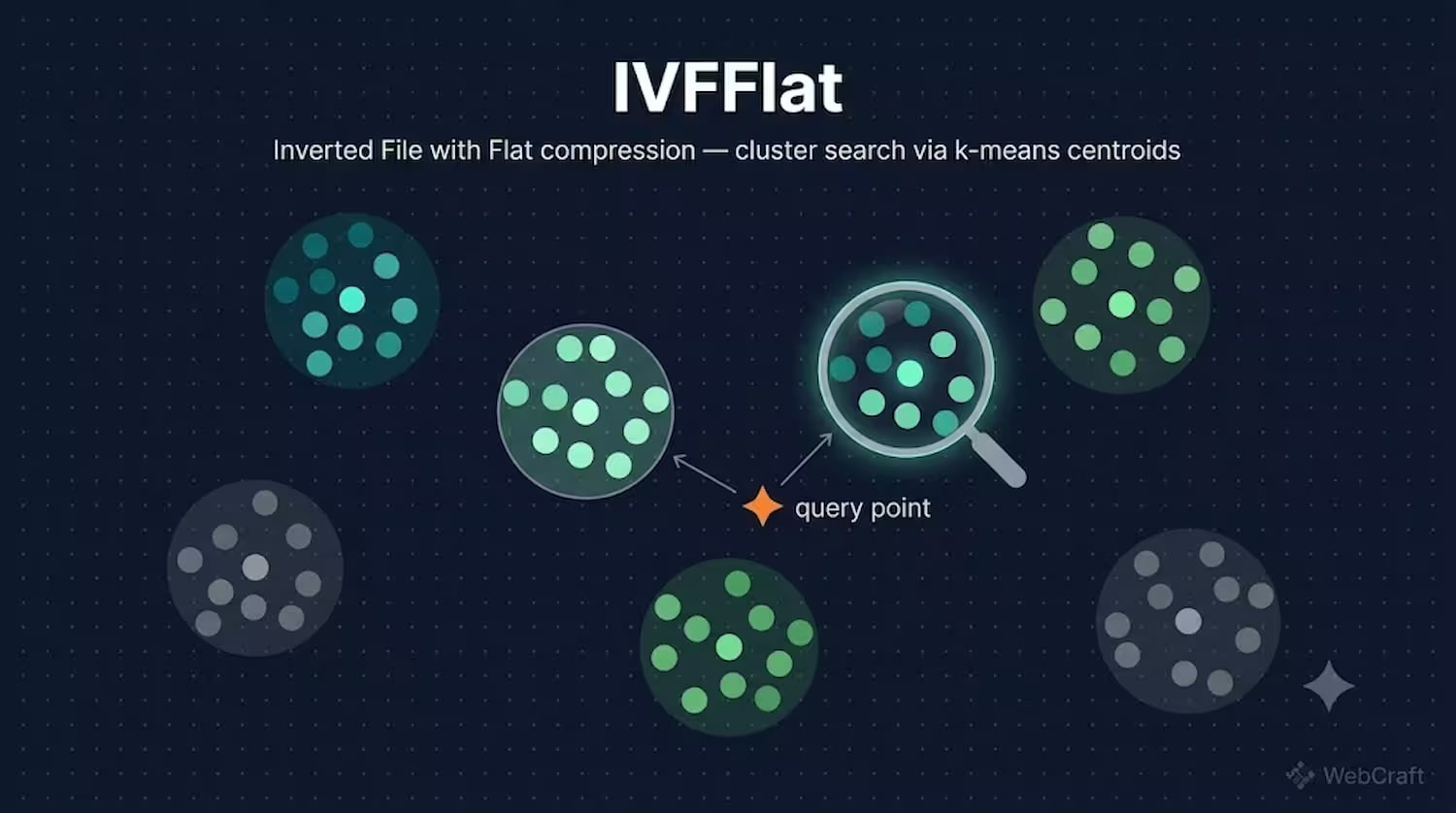
IVFFlat (Inverted File with Flat compression) йде іншим шляхом: розбиває весь простір векторів на кластери (Voronoi-клітини) за допомогою k-means, кожен зі своєю центроїдою. При пошуку спочатку визначаються кластери, найближчі до вектора запиту (кількість контролюється параметром probes), а потім пошук відбувається лише всередині цих кластерів.
Аналогія: уявіть бібліотеку, де книги розкладені не за алфавітом, а за тематичними розділами — фантастика, історія, кулінарія. Замість того, щоб переглядати кожну книгу в бібліотеці (brute-force), ви спочатку йдете до потрібного розділу (найближча центроїда), а потім шукаєте конкретну книгу лише серед тих, що там стоять (пошук всередині кластера). Якщо книга випадково лежить не у "своєму" розділі — ви її просто не знайдете, скільки б розділів не переглядали. Це і є фундаментальне обмеження IVFFlat: якість пошуку залежить від того, наскільки вдало k-means розклав вектори по кластерах.
-- Для 10 000 векторів: lists = sqrt(10000) ≈ 100
CREATE INDEX ON vector_store
USING ivfflat (embedding vector_cosine_ops)
WITH (lists = 100);
На етапі пошуку керує точністю параметр probes — скільки найближчих кластерів перевіряти. Чим більше probes, тим вищий recall, але повільніший пошук (бо доводиться сканувати більше кластерів):
SET ivfflat.probes = 10;
SELECT id, content
FROM vector_store
ORDER BY embedding <=> '[0.012, -0.034, ...]'
LIMIT 10;
За замовчуванням probes = 1 — перевіряється лише один найближчий кластер. Це швидко, але якщо вектор запиту опинився близько до межі між двома кластерами, релевантний результат може лежати в "сусідньому" кластері, який так і не буде перевірений. Підняти probes до 5-10 — звичний компроміс між швидкістю і точністю.
IVFFlat будується швидше і споживає менше пам'яті, ніж HNSW — але має нижчий recall, особливо на високовимірних даних або великих датасетах. Тут варто пригадати, що сама розмірність вектора (наприклад, 1536 проти 3072) впливає не лише на якість семантики, а й на те, наскільки "розмитими" стають межі кластерів при k-means — детальніше про вибір розмірності embeddings ми писали в статті «1536 vs 3072: порівняння embeddings для пошуку по документах та RAG».
Найважливіший нюанс: IVFFlat вимагає, щоб дані вже були в таблиці ДО побудови індексу — алгоритму потрібно "вивчити" центри кластерів на реальному розподілі даних. HNSW цього обмеження не має.
Є ще один практичний аспект, який легко недооцінити: якість самих векторів, що потрапляють у кластери, напряму залежить від того, як текст був розбитий на чанки перед індексацією. Занадто дрібні чанки дають "шумні" embeddings, які k-means складно розкласти по чітких кластерах; занадто великі — змішують кілька тем в одному векторі, що теж розмиває межі кластерів. Ми розбирали це детальніше в статті «Chunking strategies в RAG 2026: як правильно розбивати дані для production».
Окреме незалежне дослідження на реальних датасетах (10-25 мільйонів векторів — SIFT, OpenAI, Cohere embeddings) показує, що оптимізації типу half-precision (halfvec) дають практично однакову швидкість пошуку (QPS) при вдвічі меншому розмірі індексу, а агресивніша бінарна квантизація з пере-ранжуванням стискає індекс у 11-12 разів — але вже з помітним падінням точності на деяких типах даних (дослідження "Filter-Agnostic Vector Search on PostgreSQL", 2026). Це актуально, якщо HNSW-індекс впритул наближається до обсягу shared_buffers — компроміс "трохи менша точність заради вдвічі меншої пам'яті" часто виправданий саме на цьому етапі, а не раніше.
Підсумок з незалежного бенчмарку Instaclustr: «Обирайте HNSW, коли точність і швидкість пошуку важливіші за час побудови індексу чи використання пам'яті. IVFFlat — розумний вибір для застосунків з низькою латентністю, де час побудови або компактність важливіші за найвищий recall»(Instaclustr, лютий 2026).
Пастка IVFFlat: стейл-центроїди
Це найпоширеніша і найдорожча помилка з pgvector — і вона легко відтворюється в Spring AI-проєктах саме через initialize-schema=true.
Сценарій: команда створює індекс CREATE INDEX ... USING ivfflat при першому старті застосунку — коли таблиця vector_store ще порожня або має лише кілька тестових рядків. K-means центроїди обчислюються на основі цих нерепрезентативних даних.
Що відбувається технічно: алгоритм k-means дивиться на ті кілька векторів, що є на момент побудови індексу, і розкладає весь майбутній простір на кластери навколо них. Якщо на той момент у таблиці лежало, скажімо, 5 тестових рядків — центроїди "застигають" у формі, що відповідає цим п'яти точкам. Коли далі завантажуються тисячі реальних документів, вони фізично потрапляють у простір векторів, але логічна структура кластерів вже не відповідає новому розподілу даних. Частина нових векторів опиняється "далеко" від своєї найближчої центроїди просто тому, що жодна центроїда насправді не була розрахована з урахуванням їхнього існування.
Результат — усі подальші пошуки виконуються проти індексу зі "застарілими" центроїдами. Recall тихо деградує: запит, який мав би знайти релевантний документ, не знаходить його, бо документ потрапив у "невдалий" кластер, який ніколи не перевіряється при стандартному probes = 1. Команда місяцями вважає, що проблема в якості embedding-моделі чи в стратегії чанкінгу, хоча корінь — один рядок у миграції бази (Philip McClarence, Medium, квітень 2026).
Найгірше в цій помилці — її непомітність. Немає винятку, немає помилки в логах, немає падіння застосунку. Пошук просто працює — але гірше, ніж міг би. RAG-чат продовжує відповідати, просто частіше каже "не знайшов релевантної інформації" або підтягує менш точний контекст. Це саме той тип проблеми, де відсутність сигналу тривоги — і є тривожний сигнал.
Від себе скажу: коли ми вперше зіткнулися з помилкою bad SQL grammar при спробі Spring AI автоматично створити HNSW-індекс на старті застосунку (через застарілу версію розширення pgvector на хостингу), перше, що спадає на думку — просто переключити index-type на ivfflat замість none і піти далі. І саме тут легко непомітно потрапити в цю ж пастку: initialize-schema=true в Spring AI означає, що індекс створюється одразу при старті — а на той момент таблиця майже завжди порожня. Якби ми тоді не зупинилися і не розібралися, чому саме HNSW впав з помилкою, а просто "на автоматі" підставили IVFFlat як заміну — ми б отримали робочий застосунок із непомітно зламаним пошуком, і дізналися про це лише тоді, коли користувачі почали б скаржитися, що чат-бот "не розуміє" прості питання.
Рекомендація з того ж джерела: «IVFFlat-індекси не належать у схемні міграції. Вони належать у пост-завантажувальні скрипти. HNSW — безпечний дефолт для застосунків до 1M рядків». Це не просто стилістична порада — це розмежування за призначенням: схемна миграція описує структуру бази, а не її вміст, тоді як IVFFlat за своєю природою прив'язаний саме до вмісту.
Кейс 1: блог на 800 статей — чому ми не використовуємо жодного індексу
Наш блог webscraft.org має ~800 статей (оригінали українською + переклади EN/DE/ES) і RAG-чат на базі Spring AI + pgvector. Поточний стан таблиці vector_store:
Чесна історія: index-type=none не було архітектурним рішенням з самого початку. На managed Postgres-хостингу при першому деплої Spring AI спробував автоматично виконати:
CREATE INDEX IF NOT EXISTS spring_ai_vector_index
ON public.vector_store USING HNSW (embedding vector_cosine_ops)
і впав з помилкою bad SQL grammar — версія розширення pgvector на хостингу була застарілою і не підтримувала синтаксис HNSW (доданий лише в pgvector 0.5.0, серпень 2023). Швидким рішенням стало index-type=none, і саме воно лишилося в проді — тому що подальший аналіз показав: на 10 852 рядках це не лише "працює", а є оптимальним рішенням.
Чому: поріг, коли ANN-індекс реально починає себе оправдовувати — приблизно 50 000 векторів (на менших обсягах brute-force scan виконується за мілісекунди, а накладні витрати на побудову й підтримку HNSW/IVFFlat — навпаки, додають складності без вимірюваної вигоди). При темпі росту 3-4 статті на тиждень досягнення цього порогу — питання кількох років, не місяців.
Кейс 2: сервіс на десятки тисяч документів — чому там доречний IVFFlat
Інший наш проєкт, askyourdocs.org, спроєктований інакше: це self-hosted сервіс із принципом single-tenant per deployment — кожен клієнт отримує власний, повністю ізольований інстанс із окремою базою даних (окремий деплой на Railway, окремі ENV-змінні). Дані одного клієнта фізично не знаходяться в одній таблиці з даними іншого. Архітектурно очікується ріст до десятків тисяч документів в межах однієї такої бази — масштаб, де brute-force вже не варіант. Конфігурація:
IVFFlat тут обраний свідомо: документи завантажуються пакетами (клієнт один раз завантажує набір файлів, потім переважно лише читає/шукає), що відповідає сценарію "дані завантажені один раз, запитуються часто" — саме той кейс, де IVFFlat є розумним вибором за оцінкою PE Collective (квітень 2026).
Важливий архітектурний нюанс саме для такої моделі розгортання: оскільки кожен клієнт має свою окрему базу, k-means центроїди для IVFFlat будуються виключно на основі документів цього конкретного клієнта — без "шуму" від чужих даних, який був би проблемою в shared multi-tenant таблиці з фільтрацією за userId. Це знімає клас проблем із filtered search, але натомість додає інший нюанс: момент, коли клієнт завантажує свій перший пакет документів, є водночас моментом, коли база переходить від "порожньої" до "реальної" — і саме тут initialize-schema=true при першому деплої легко створює IVFFlat-індекс на порожній таблиці, ще до завантаження жодного документа.
Практичний висновок для такої архітектури: IVFFlat треба будувати або перебудовувати після початкового завантаження репрезентативного обсягу документів конкретного клієнта (не одразу при деплої через initialize-schema=true), і періодично робити REINDEX по мірі того, як клієнт продовжує завантажувати нові документи — інакше центроїди застарівають саме так, як описано в розділі про пастку вище. Для self-hosted моделі це означає: крок "перебудувати індекс після першого завантаження" варто зробити частиною онбордингу нового клієнта, а не одноразовим налаштуванням на рівні всього застосунку.
Практична рекомендація: як моніторити момент переходу
Не потрібно вгадувати, коли переходити на індекс. У себе на блозі ми звели це до двох простих метрик, які перевіряємо раз на квартал — без жодної автоматизації чи дашбордів, просто нагадування в календарі.
-- 1. Розмір таблиці vector_store
SELECT COUNT(*) FROM vector_store;
Цей запит ми виконуємо вручну через PgAdmin за хвилину. На момент написання цієї статті в нас 10 852 рядки — і ми свідомо не поспішаємо нічого змінювати, бо до орієнтовного порогу переходу лишається ще багато часу при нашому темпі росту (3-4 статті на тиждень).
Якщо у вас вже є логування RAG-запитів (у нас це окрема таблиця з admin-панеллю — ми описували її в розділі про обробку запитів), другий сигнал — тривалість пошуку (durationMs) у часі. Зростання цього показника — раніший і точніший індикатор, ніж сам розмір таблиці, бо залежить також від навантаження сервера. Ми звертаємо на нього увагу не як на точну метрику, а як на тренд: якщо середній durationMs за тиждень помітно росте з тижня в тиждень — це сигнал придивитися уважніше, навіть якщо абсолютна кількість рядків ще не виглядає загрозливою.
Розмір vector_store
Дія
До ~30 000-40 000 рядків
Залишити index-type=none, не втручатися
~40 000-50 000 рядків
Почати моніторити durationMs у RAG-логах щотижня
50 000+ рядків або помітне зростання durationMs
Переходити на HNSW (не IVFFlat) — через непередбачуваний, інкрементальний характер росту даних HNSW безпечніший, бо не вимагає REINDEX і не залежить від порядку вставки
Чесно кажучи, найважче в цьому підході — не сама перевірка, а дисципліна її робити регулярно, коли все й так працює нормально. Легко відкласти "до наступного кварталу" і забути. Саме тому ми обрали найпростіший можливий запит і найменшу можливу кількість метрик (всього дві) — складніший моніторинг ми просто не стали б підтримувати на постійній основі для проєкту такого масштабу.
Часті питання (FAQ)
Чи можна просто завжди ставити HNSW "на всякий випадок"?
Можна, але на малих датасетах (до ~30-50К рядків) це не дає вимірюваної вигоди в швидкості, водночас споживаючи пам'ять і додаючи час на побудову/перебудову індексу при кожній масовій переіндексації даних.
Що робити, якщо на хостингу стара версія pgvector і HNSW не підтримується?
Перевірте версію: SELECT extversion FROM pg_extension WHERE extname = 'vector';. Якщо хостинг дозволяє — оновіть розширення. Якщо ні, і обсяг даних малий — index-type=none є цілком робочим рішенням, не тимчасовим хаком.
Чи існує щось краще за HNSW для дуже великих датасетів?
Так — DiskANN (через розширення pgvectorscale), який тримає компактну навігаційну структуру в пам'яті, а самі вектори — на диску, звертаючись до них лише для фінального уточнення кандидатів. Корисний, коли HNSW-індекс перевищує обсяг shared_buffers(dbi-services, березень 2026).
Яких помилок з HNSW/IVFFlat найлегше припуститися?
Я б виділив чотири, з якими стикався сам або бачив у чужих проєктах:
Помилка №1 — використовувати HNSW на 50 000 документів.
Сам колись думав, що "більший і кращий" індекс не може зашкодити. На практиці на такому обсязі додаткова пам'ять і час побудови HNSW не дають жодної відчутної переваги в швидкості порівняно з простим index-type=none — ви просто платите складністю за вигоду, якої ще немає на цьому масштабі.
Помилка №2 — створювати IVFFlat до завантаження даних.
Це саме та пастка зі стейл-центроїдами, яку я детально розбирав вище — і це не теоретична проблема, я сам наступав на цю граблю через initialize-schema=true у Spring AI. Якщо індекс будується на порожній або майже порожній таблиці, він залишається зламаним, поки ви явно не зробите REINDEX після реального завантаження даних.
Помилка №3 — ставити lists = 10 на мільйон векторів.
Тут я б порадив завжди тримати в голові правило sqrt(N): для мільйона векторів це приблизно 1000 кластерів, а не 10. Замало кластерів означає, що кожен з них містить величезну кількість векторів, і пошук всередині такого "кластера-гіганта" вже мало відрізняється від brute-force по всій таблиці — ви втрачаєте всю вигоду від IVFFlat, але платите складністю його підтримки.
Помилка №4 — не робити ANALYZE.
Цю помилку найлегше забути, бо вона не пов'язана прямо з самим індексом. Після масової вставки чи видалення даних статистика планувальника Postgres застаріває, і він може просто не обрати ваш індекс під час виконання запиту, навіть якщо індекс ідеально побудований. Я взяв за звичку запускати ANALYZE vector_store; одразу після будь-якої масової переіндексації — це займає секунди, але рятує від ситуації "індекс є, а Postgres ним не користується".
Висновки
Підсумкова шпаргалка: HNSW vs IVFFlat в одній таблиці
Операція
HNSW
IVFFlat
Search (пошук)
Швидше
Повільніше
Insert (вставка)
Повільніше
Швидше
Build Index (побудова індексу)
Довго
Швидко
RAM (пам'ять)
Висока
Низька
Якщо звести все обговорене до одного речення: HNSW міняє швидкість вставки та пам'ять на швидкість і точність пошуку, IVFFlat — навпаки. Який бік цього компромісу важливіший — залежить виключно від вашого паттерна навантаження, а не від того, який індекс "кращий" в абстрактному сенсі.
Індекс (HNSW чи IVFFlat) — це оптимізація для масштабу, а не обов'язковий компонент будь-якого pgvector-проєкту.
На обсягах до ~30-50 тисяч векторів brute-force пошук (index-type=none) зазвичай швидший за накладні витрати на підтримку індексу.
HNSW — безпечніший дефолт для даних, що змінюються непередбачувано (новий контент, що додається поступово): не залежить від порядку вставки, не потребує REINDEX.
IVFFlat доречний, коли дані завантажуються великими пакетами одноразово і запитуються часто — але вимагає побудови індексу після завантаження репрезентативного обсягу даних і періодичного REINDEX по мірі росту.
Найдорожча помилка — створення IVFFlat-індексу на порожній таблиці через автоматичну ініціалізацію схеми. Recall деградує тихо, і це легко сплутати з проблемами embedding-моделі.