HNSW vs IVFFlat in pgvector: Wann Sie wirklich einen Index benötigen
Wir haben 10.852 Vektoren in einer Tabelle vector_store in Produktion – und wir verwenden immer noch weder HNSW noch IVFFlat. Das ist kein Versehen. Spoiler: Für die meisten Blogs und kleinen RAG-Projekte ist ein Index bis zu Zehntausenden von Zeilen überhaupt nicht erforderlich – und wenn er benötigt wird, kann die falsche Wahl zwischen HNSW und IVFFlat die Suchgenauigkeit wochenlang leise beeinträchtigen, bevor Sie es bemerken.
⚡ Kurz gesagt
✅ Bis zu ~50.000 Vektoren: Brute-Force-Suche (index-type=none) ist fast immer schneller und einfacher als die Wartung eines Index
✅ HNSW: Bessere Recall-Werte, stabile Qualität unabhängig von der Einfügereihenfolge der Daten, aber +2-5x Speicher und langsamere Erstellung
✅ IVFFlat: Schnellere Erstellung, weniger Speicher, erfordert aber Daten VOR der Indexerstellung und periodisches REINDEX
🎯 Sie erhalten: Konkrete Übergangsschwellenwerte, reale Spring AI-Konfigurationen und zwei Anwendungsfälle – ein Blog mit 800 Artikeln und ein Dienst mit Zehntausenden von Dokumenten
👇 Lesen Sie weiter unten mehr – mit Zahlen, SQL und einer Erklärung, warum der dritte Index (DiskANN) auch existiert
Was ist ANN-Suche und warum Brute-Force nicht immer schlecht ist
Wenn Sie in pgvector nach den Vektoren suchen, die einem Abfragevektor am nächsten liegen, gibt es zwei Wege. Der erste besteht darin, die Abfrage mit jeder Zeile der Tabelle zu vergleichen (exakte Nächste-Nachbarn-Suche). Der zweite besteht darin, einen Index zu verwenden, der ungefähr die nächsten Nachbarn findet, ohne alle Zeilen zu prüfen (Approximate Nearest Neighbor, ANN).
Der Brute-Force-Ansatz (ohne Index, index-type=none in Spring AI) skaliert linear – O(n). Bei 10.000 Zeilen sind das Millisekunden. Bei 10 Millionen sind es bereits Sekunden pro Abfrage, was für jeden produktiven Betrieb mit Traffic inakzeptabel ist.
pgvector unterstützt zwei Haupttypen von ANN-Indizes – HNSW und IVFFlat – und seit Version 0.8.2 (Februar 2026) gibt es zusätzlich die Erweiterung DiskANN über das separate Paket pgvectorscale für sehr große Datensätze, die über die shared_buffers hinausgehen (dbi-services, März 2026). Dieser Artikel konzentriert sich auf HNSW und IVFFlat, da 95 % der Projekte mit diesen konfrontiert sind.
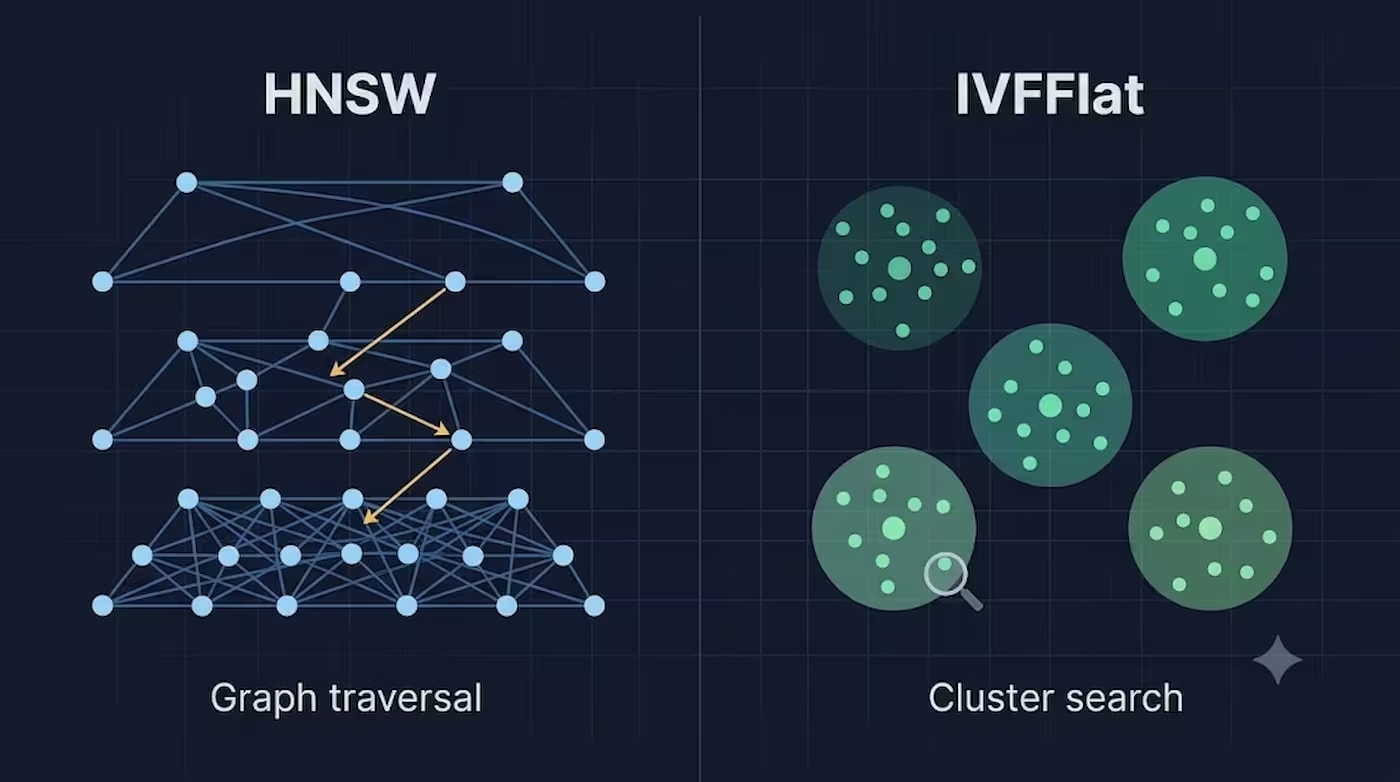
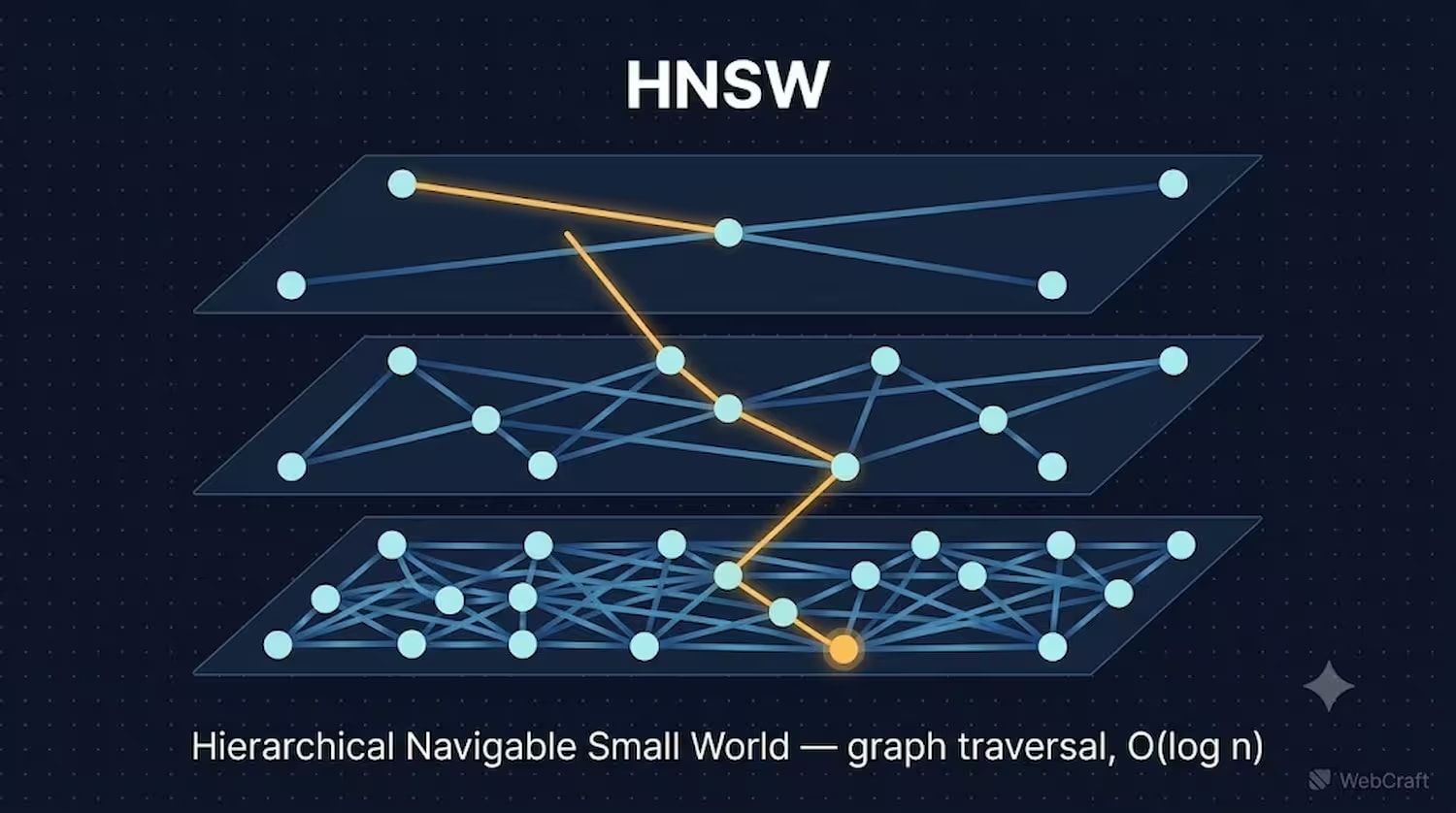
Wie HNSW funktioniert
HNSW (Hierarchical Navigable Small World) baut einen mehrstufigen Graphen von Verbindungen zwischen Vektoren auf. Die oberen Ebenen des Graphen enthalten spärliche "Haupt"-Verbindungen für schnelle Fernübertragungen, die unteren Ebenen dichte lokale Verbindungen für die präzise Endsuche. Eine Abfrage tritt auf der obersten Ebene ein und "steigt" nach unten ab, wodurch die Suche auf die nächsten Nachbarn eingegrenzt wird.
Eine Analogie, die das Wesen gut erklärt: Stellen Sie sich vor, Sie suchen eine Adresse in einer unbekannten Stadt. Anstatt jede Straße einzeln abzugehen (das ist Brute-Force), fahren Sie zuerst auf eine Schnellstraße (obere Ebene des Graphen – ferne "Haupt"-Verbindungen), fahren zum gewünschten Viertel und wechseln dann zu den lokalen Straßen (untere Ebene – dichte lokale Verbindungen), um die genaue Adresse zu finden. Jede "Ebene" des Graphen verengt den Suchraum, daher die logarithmische Komplexität.
Dank dieser Struktur wächst die Suchzeit logarithmisch – O(log n) – und ist unabhängig von der Reihenfolge, in der die Daten eingefügt wurden (Philip McClarence, Medium, April 2026). HNSW kann auch auf einer leeren Tabelle erstellt werden – der Index passt sich an, während neue Vektoren eingefügt werden.
Beispiel für die Indexerstellung:
CREATE INDEX ON vector_store
USING hnsw (embedding vector_cosine_ops)
WITH (m = 16, ef_construction = 64);
Hier ist m die maximale Anzahl von Verbindungen pro Knoten im Graphen (mehr Verbindungen = höherer Recall, aber mehr Speicher), und ef_construction gibt an, wie weit der Algorithmus während der Indexerstellung "blickt", um Kandidaten für Verbindungen zu finden. Während der Suche gibt es einen symmetrischen Parameter ef_search – er steuert, wie viele Kandidaten während der Abfrage selbst betrachtet werden:
SET hnsw.ef_search = 40;
SELECT id, content
FROM vector_store
ORDER BY embedding <=> '[0.012, -0.034, ...]'
LIMIT 10;
Die Standardwerte (m=16, ef_construction=64, ef_search=40) sind keine Zufallszahlen, sondern ein sorgfältig ausgewählter Ausgangspunkt. Die meisten Beschwerden wie "pgvector ist langsam" entstehen gerade deshalb, weil diese Parameter nie an den spezifischen Datensatz angepasst wurden (Nerd Level Tech, Mai 2026).
Der Preis für die Suchqualität sind Speicher und Erstellungszeit. Eine Faustregel zur Schätzung des Speicherbedarfs während der Indexerstellung: N × D × 4 Bytes × 2 (der Faktor 2 berücksichtigt den Overhead für den Graphen selbst) (DEV Community, März 2026). Für 5 Millionen Vektoren mit 1536 Dimensionen bedeutet dies 8-16 GB Arbeitsspeicher allein für die Erstellung.
Ein fertiger Index beansprucht ebenfalls viel Platz: Eine Faustregel lautet 6-8 GB RAM pro Million Vektoren mit 1536 Dimensionen für HNSW im Speicher (Groovyweb, 2026). Es ist erwähnenswert: Die Vektordimension (1536 vs. z. B. 3072) beeinflusst diese Zahl direkt proportional – mehr Details darüber, wann eine höhere Embedding-Dimension wirklich gerechtfertigt ist, haben wir im Artikel „1536 vs 3072: Vergleich von Embeddings für die Dokumentensuche und RAG“ behandelt.
Reale Speicherzahlen: Warum HNSW mehr "frisst", als man denkt
Viele sehen die Zahl "6-8 GB pro 1 Mio. Vektoren" und denken, das seien die Kosten von HNSW. Tatsächlich ist dies die Summe zweier separater Komponenten, und die zweite ist der Hauptnachteil von HNSW, der leicht unterschätzt werden kann.
Beispiel: 1 Million Vektoren × 1536 Dimensionen
Komponente
Berechnung
Volumen
Die Vektoren selbst (Heap-Tabelle)
1.000.000 × 1536 × 4 Bytes
≈ 6 GB
HNSW-Index (Verbindungsgraph)
abhängig von m, im Durchschnitt +20-50% des Vektorvolumens
+1-3 GB
Gesamt
7-9 GB RAM
Hier liegt der Hauptnachteil, der oft übersehen wird: Diese 6 GB für die Vektoren selbst werden in jedem Fall benötigt – auch mit index-type=none, auch mit IVFFlat. Das sind die grundlegenden Kosten für die Datenspeicherung. Die zusätzlichen 1-3 GB sind reine Overhead-Kosten für die Graphstruktur von HNSW: ein Array von Verbindungen (neighbors) für jeden Knoten auf jeder Ebene des Graphen, das für eine schnelle Durchquerung im Speicher gehalten werden muss.
In der Praxis bedeutet dies: Wenn Ihre Postgres-Instanz kaum die Daten selbst aufnehmen kann (die grundlegenden 6 GB), kann das Hinzufügen eines HNSW-Index den gesamten Speicherverbrauch über die verfügbaren shared_buffers hinaus erhöhen, und ein Teil des Graphen beginnt, auf die Festplatte ausgelagert zu werden – und genau in diesem Szenario wird die Suche langsamer, nicht schneller, entgegen dem theoretischen Vorteil von O(log n)(dbi-services, März 2026).
IVFFlat ist in dieser Hinsicht ehrlicher: Er fügt keine separate Verbindungsstruktur über die Daten hinaus hinzu, sondern speichert nur die Cluster-Nummer für jeden Vektor – daher beansprucht er erheblich weniger Speicher über die grundlegenden 6 GB hinaus.
Praktische Auswirkung des Parameters maintenance_work_mem: Wenn sein Wert zu niedrig ist (Standard in Postgres ist normalerweise 64 MB), "fließt" die Erstellung eines HNSW-Index auf die Festplatte und dauert 10-50 Mal länger (DEV Community, März 2026). Vor der Indexerstellung auf einem großen Datensatz sollten Sie diesen Parameter vorübergehend erhöhen:
SET maintenance_work_mem = '2GB';
CREATE INDEX ON vector_store
USING hnsw (embedding vector_cosine_ops);
-- Nach der Erstellung können Sie den Standardwert wiederherstellen
RESET maintenance_work_mem;
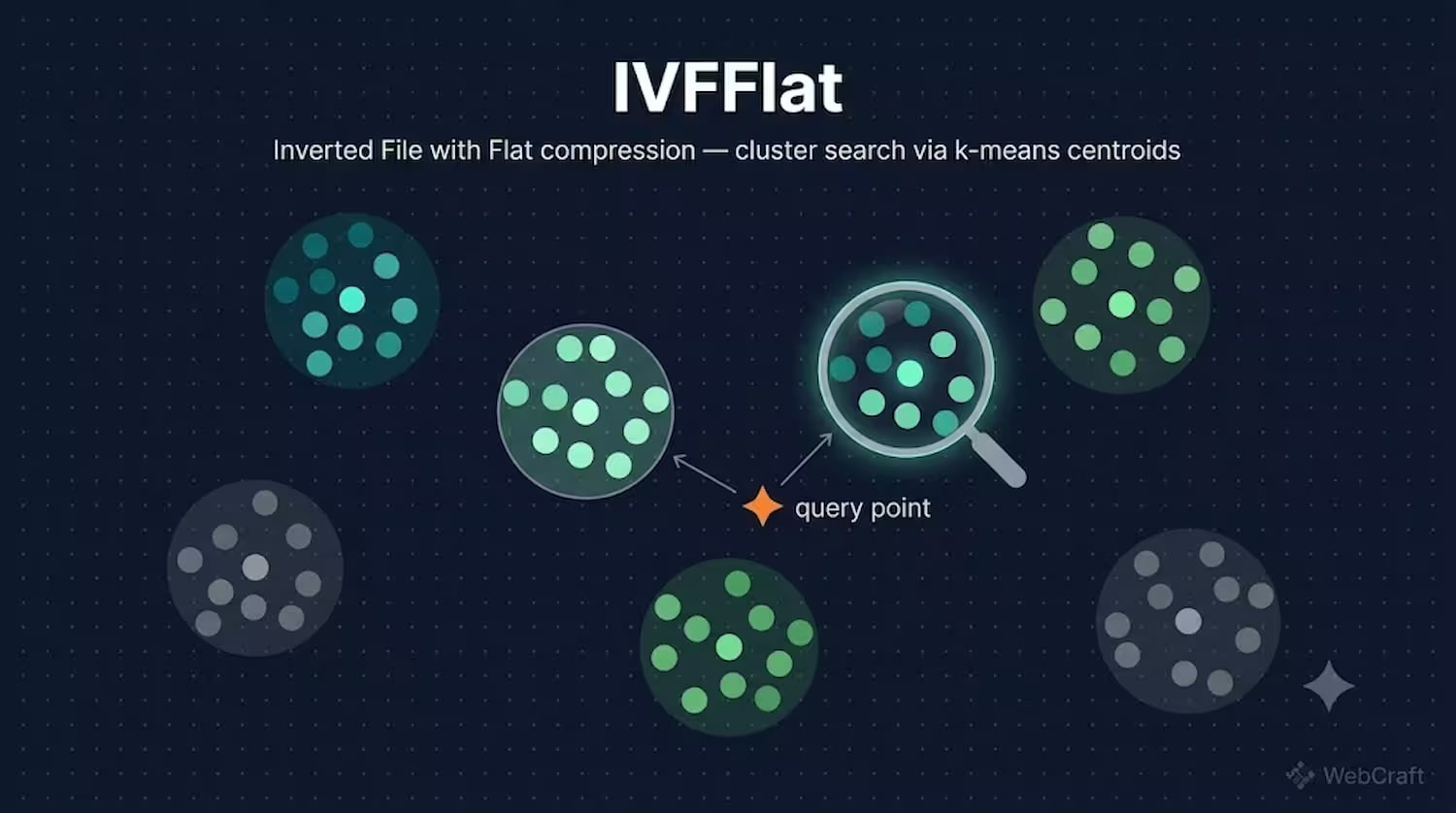
Wie IVFFlat funktioniert
IVFFlat (Inverted File with Flat compression) geht einen anderen Weg: Er teilt den gesamten Vektorraum in Cluster (Voronoi-Zellen) mithilfe von k-means auf, jeder mit seinem eigenen Zentroiden. Bei der Suche werden zuerst die Cluster bestimmt, die dem Abfragevektor am nächsten liegen (die Anzahl wird durch den Parameter probes gesteuert), und dann wird die Suche nur innerhalb dieser Cluster durchgeführt.
Analogie: Stellen Sie sich eine Bibliothek vor, in der die Bücher nicht alphabetisch, sondern nach Themenbereichen sortiert sind – Science-Fiction, Geschichte, Kochen. Anstatt jedes Buch in der Bibliothek durchzugehen (Brute-Force), gehen Sie zuerst zum gewünschten Bereich (nächster Zentroid) und suchen dann nur nach dem spezifischen Buch unter denen, die dort stehen (Suche innerhalb des Clusters). Wenn ein Buch zufällig nicht in seinem "eigenen" Bereich liegt – Sie werden es einfach nicht finden, egal wie viele Bereiche Sie durchsuchen. Das ist die grundlegende Einschränkung von IVFFlat: Die Suchqualität hängt davon ab, wie gut k-means die Vektoren in Cluster aufgeteilt hat.
Die wichtigste praktische Regel für die Anzahl der Cluster (lists): sqrt(N) für N Vektoren (PE Collective, April 2026).
Beispiel für die Indexerstellung:
-- Für 10.000 Vektoren: lists = sqrt(10000) ≈ 100
CREATE INDEX ON vector_store
USING ivfflat (embedding vector_cosine_ops)
WITH (lists = 100);
Während der Suche steuert der Parameter probes die Genauigkeit – wie viele der nächsten Cluster überprüft werden. Je mehr probes, desto höher der Recall, aber desto langsamer die Suche (da mehr Cluster gescannt werden müssen):
SET ivfflat.probes = 10;
SELECT id, content
FROM vector_store
ORDER BY embedding <=> '[0.012, -0.034, ...]'
LIMIT 10;
Standardmäßig ist probes = 1 – nur der nächste Cluster wird überprüft. Das ist schnell, aber wenn der Abfragevektor nahe an der Grenze zwischen zwei Clustern liegt, kann ein relevantes Ergebnis im "benachbarten" Cluster liegen, der nicht überprüft wird. Das Erhöhen von probes auf 5-10 ist ein üblicher Kompromiss zwischen Geschwindigkeit und Genauigkeit.
IVFFlat wird schneller erstellt und verbraucht weniger Speicher als HNSW – hat aber einen niedrigeren Recall, insbesondere bei hochdimensionalen Daten oder großen Datensätzen. Hier sollte man sich daran erinnern, dass die Vektordimension selbst (z. B. 1536 vs. 3072) nicht nur die semantische Qualität beeinflusst, sondern auch, wie "verschwommen" die Clustergrenzen bei k-means werden – mehr Details zur Wahl der Embedding-Dimension haben wir im Artikel „1536 vs 3072: Vergleich von Embeddings für die Dokumentensuche und RAG“ geschrieben.
Der wichtigste Punkt: IVFFlat erfordert, dass die Daten bereits in der Tabelle sind, BEVOR der Index erstellt wird – der Algorithmus muss die Clusterzentren auf der realen Datenverteilung "lernen". HNSW hat diese Einschränkung nicht.
Es gibt noch einen praktischen Aspekt, der leicht unterschätzt wird: Die Qualität der Vektoren, die in die Cluster gelangen, hängt direkt davon ab, wie der Text vor der Indexierung in Chunks aufgeteilt wurde. Zu kleine Chunks ergeben "rauschende" Embeddings, die k-means schwer in klare Cluster aufteilen kann; zu große vermischen mehrere Themen in einem Vektor, was ebenfalls die Clustergrenzen verwischt. Wir haben dies im Artikel „Chunking-Strategien in RAG 2026: Wie man Daten für die Produktion richtig aufteilt“ detaillierter behandelt.
Eine separate unabhängige Studie auf realen Datensätzen (10-25 Millionen Vektoren — SIFT, OpenAI, Cohere embeddings) zeigt, dass Optimierungen wie Half-Precision (halfvec) praktisch die gleiche Suchgeschwindigkeit (QPS) bei halber Indexgröße ergeben, während aggressivere binäre Quantisierung mit Re-Ranking den Index um das 11-12-fache komprimiert — allerdings mit einem spürbaren Genauigkeitsverlust bei einigen Datentypen (Studie "Filter-Agnostic Vector Search on PostgreSQL", 2026). Dies ist relevant, wenn der HNSW-Index das Volumen von shared_buffers fast erreicht — ein Kompromiss "etwas geringere Genauigkeit für halben Speicherbedarf" ist oft gerade in dieser Phase gerechtfertigt, nicht früher.
Fazit aus einem unabhängigen Instaclustr-Benchmark: „Wählen Sie HNSW, wenn Genauigkeit und Suchgeschwindigkeit wichtiger sind als Indexaufbauzeit oder Speicherverbrauch. IVFFlat ist eine sinnvolle Wahl für Anwendungen mit geringer Latenz, bei denen Aufbauzeit oder Kompaktheit wichtiger sind als der höchste Recall“(Instaclustr, Februar 2026).
Die IVFFlat-Falle: veraltete Zentroiden
Dies ist der häufigste und teuerste Fehler mit pgvector — und er ist in Spring AI-Projekten leicht reproduzierbar, gerade wegen initialize-schema=true.
Szenario: Ein Team erstellt einen Index CREATE INDEX ... USING ivfflat beim ersten Start der Anwendung — wenn die Tabelle vector_store noch leer ist oder nur wenige Testzeilen enthält. Die K-Means-Zentroiden werden auf Basis dieser nicht repräsentativen Daten berechnet.
Was technisch passiert: Der K-Means-Algorithmus betrachtet die wenigen Vektoren, die zum Zeitpunkt des Indexaufbaus vorhanden sind, und teilt den gesamten zukünftigen Raum in Cluster um diese herum auf. Wenn zu diesem Zeitpunkt beispielsweise 5 Testzeilen in der Tabelle lagen — "frieren" die Zentroiden in einer Form ein, die diesen fünf Punkten entspricht. Wenn später Tausende von echten Dokumenten geladen werden, gelangen sie physisch in den Vektorraum, aber die logische Struktur der Cluster entspricht nicht mehr der neuen Datenverteilung. Ein Teil der neuen Vektoren landet "weit entfernt" von seiner nächsten Zentroiden, einfach weil keine Zentroiden tatsächlich unter Berücksichtigung ihrer Existenz berechnet wurden.
Das Ergebnis — alle nachfolgenden Suchen werden gegen einen Index mit "veralteten" Zentroiden ausgeführt. Der Recall verschlechtert sich leise: Eine Anfrage, die ein relevantes Dokument finden sollte, findet es nicht, weil das Dokument in einen "unglücklichen" Cluster geraten ist, der bei einem Standard-probes = 1 nie überprüft wird. Das Team glaubt monatelang, dass die Qualität des Embedding-Modells oder die Chunking-Strategie das Problem ist, obwohl die Wurzel eine einzige Zeile in der Datenbankmigration ist (Philip McClarence, Medium, April 2026).
Das Schlimmste an diesem Fehler ist seine Unauffälligkeit. Es gibt keine Ausnahme, keinen Fehler in den Logs, keinen Absturz der Anwendung. Die Suche funktioniert einfach — aber schlechter, als sie könnte. Ein RAG-Chat antwortet weiterhin, sagt aber häufiger "keine relevanten Informationen gefunden" oder zieht weniger präzisen Kontext heran. Dies ist genau die Art von Problem, bei der das Fehlen eines Alarmsignals ein Alarmsignal ist.
Von meiner Seite: Als wir zum ersten Mal auf den Fehler bad SQL grammar stießen, als Spring AI versuchte, beim Anwendungsstart automatisch einen HNSW-Index zu erstellen (wegen einer veralteten pgvector-Erweiterungsversion auf dem Hosting), war das Erste, was uns einfiel, einfach index-type von none auf ivfflat umzustellen und weiterzumachen. Und genau hier gerät man leicht unbemerkt in dieselbe Falle: initialize-schema=true in Spring AI bedeutet, dass der Index sofort beim Start erstellt wird — und zu diesem Zeitpunkt ist die Tabelle fast immer leer. Hätten wir damals nicht innegehalten und uns gefragt, warum genau HNSW mit einem Fehler abgestürzt ist, sondern einfach "automatisch" IVFFlat als Ersatz eingesetzt — hätten wir eine funktionierende Anwendung mit einer unbemerkt kaputten Suche erhalten und es erst erfahren, wenn die Benutzer sich beschweren, dass der Chatbot einfache Fragen "nicht versteht".
Empfehlung aus derselben Quelle: „IVFFlat-Indizes gehören nicht in Schema-Migrationen. Sie gehören in Post-Load-Skripte. HNSW ist eine sichere Standardwahl für Anwendungen bis zu 1 Million Zeilen.“ Dies ist nicht nur ein stilistischer Ratschlag — es ist eine Abgrenzung nach Zweck: Eine Schema-Migration beschreibt die Struktur der Datenbank, nicht ihren Inhalt, während IVFFlat von Natur aus an den Inhalt gebunden ist.
Fall 1: Blog mit 800 Artikeln — warum wir keinen Index verwenden
Unser Blog webscraft.org hat ca. 800 Artikel (Originale auf Ukrainisch + Übersetzungen EN/DE/ES) und einen RAG-Chat basierend auf Spring AI + pgvector. Aktueller Stand der Tabelle vector_store:
Ehrliche Geschichte: index-type=none war von Anfang an keine architektonische Entscheidung. Auf verwaltetem Postgres-Hosting versuchte Spring AI beim ersten Deployment automatisch Folgendes auszuführen:
CREATE INDEX IF NOT EXISTS spring_ai_vector_index
ON public.vector_store USING HNSW (embedding vector_cosine_ops)
und stürzte mit dem Fehler bad SQL grammar ab — die Version der pgvector-Erweiterung auf dem Hosting war veraltet und unterstützte die HNSW-Syntax nicht (erst in pgvector 0.5.0, August 2023 hinzugefügt). Die schnelle Lösung war index-type=none, und diese blieb in Produktion — weil die weitere Analyse zeigte: bei 10.852 Zeilen ist dies nicht nur "funktional", sondern die optimale Lösung.
Warum: Die Schwelle, ab der ein ANN-Index sich wirklich lohnt, liegt bei etwa 50.000 Vektoren (bei kleineren Mengen ist ein Brute-Force-Scan in Millisekunden erledigt, während die Overhead-Kosten für Aufbau und Wartung von HNSW/IVFFlat im Gegenteil Komplexität ohne messbaren Nutzen hinzufügen). Bei einer Wachstumsrate von 3-4 Artikeln pro Woche ist das Erreichen dieser Schwelle eine Frage von Jahren, nicht von Monaten.
Fall 2: Dienst mit Zehntausenden von Dokumenten — warum IVFFlat hier angebracht ist
Ein weiteres Projekt von uns, askyourdocs.org, ist anders konzipiert: Es ist ein Self-Hosted-Dienst mit dem Prinzip Single-Tenant per Deployment — jeder Kunde erhält eine eigene, vollständig isolierte Instanz mit einer separaten Datenbank (separates Deployment auf Railway, separate ENV-Variablen). Die Daten eines Kunden befinden sich physisch nicht in derselben Tabelle wie die Daten eines anderen. Architektonisch wird ein Wachstum auf Zehntausende von Dokumenten innerhalb einer solchen Datenbank erwartet — ein Maßstab, bei dem Brute-Force keine Option mehr ist. Konfiguration:
IVFFlat wurde hier bewusst gewählt: Dokumente werden in Paketen geladen (der Kunde lädt einmal eine Reihe von Dateien, dann liest/sucht er hauptsächlich) — dies entspricht dem Szenario "Daten einmal geladen, häufig abgefragt" — genau der Fall, in dem IVFFlat eine sinnvolle Wahl ist, laut PE Collective (April 2026).
Ein wichtiger architektonischer Nuance gerade für dieses Bereitstellungsmodell: Da jeder Kunde seine eigene separate Datenbank hat, werden die K-Means-Zentroiden für IVFFlat ausschließlich auf Basis der Dokumente dieses spezifischen Kunden aufgebaut — ohne den "Rausch" fremder Daten, der in einer gemeinsam genutzten Multi-Tenant-Tabelle mit Filterung nach userId ein Problem wäre. Dies beseitigt eine Klasse von Problemen mit gefilterten Suchen, fügt aber stattdessen eine andere Nuance hinzu: Der Moment, in dem ein Kunde sein erstes Dokumentenpaket lädt, ist gleichzeitig der Moment, in dem die Datenbank von "leer" zu "echt" wechselt — und genau hier erstellt initialize-schema=true beim ersten Deployment leicht einen IVFFlat-Index auf einer leeren Tabelle, noch bevor ein einziges Dokument geladen wurde.
Praktische Schlussfolgerung für eine solche Architektur: IVFFlat muss nach dem anfänglichen Laden eines repräsentativen Volumens von Dokumenten eines bestimmten Kunden aufgebaut oder neu aufgebaut werden (nicht sofort beim Deployment über initialize-schema=true), und es muss periodisch REINDEX durchgeführt werden, während der Kunde weiterhin neue Dokumente lädt — andernfalls veralten die Zentroiden genau so, wie im Abschnitt über die Falle beschrieben. Für das Self-Hosted-Modell bedeutet dies: Der Schritt "Index nach dem ersten Laden neu aufbauen" sollte Teil des Onboardings eines neuen Kunden sein, nicht eine einmalige Konfiguration auf Anwendungsebene.
Praktischer Rat: Wie man den Übergangspunkt überwacht
Sie müssen nicht raten, wann Sie zu einem Index wechseln sollen. Auf unserem eigenen Blog haben wir dies auf zwei einfache Metriken reduziert, die wir einmal im Quartal überprüfen – ohne jegliche Automatisierung oder Dashboards, nur eine Kalendererinnerung.
-- 1. Größe der Tabelle vector_store
SELECT COUNT(*) FROM vector_store;
Diese Abfrage führen wir manuell über PgAdmin in einer Minute aus. Zum Zeitpunkt der Erstellung dieses Artikels haben wir 10.852 Zeilen – und wir beeilen uns bewusst, nichts zu ändern, da wir bei unserem Wachstumstempo (3-4 Artikel pro Woche) noch viel Zeit bis zum ungefähren Übergangsschwellenwert haben.
Wenn Sie bereits RAG-Abfragen protokollieren (bei uns ist das eine separate Tabelle mit einem Admin-Panel – wir haben sie im Abschnitt zur Abfrageverarbeitung beschrieben), ist das zweite Signal die Suchdauer (durationMs) im Laufe der Zeit. Ein Anstieg dieses Indikators ist ein früherer und genauerer Indikator als die Tabellengröße selbst, da er auch von der Serverauslastung abhängt. Wir achten darauf nicht als exakte Metrik, sondern als Trend: Wenn die durchschnittliche durationMs pro Woche von Woche zu Woche merklich ansteigt – ist das ein Signal, genauer hinzuschauen, auch wenn die absolute Anzahl der Zeilen noch nicht bedrohlich wirkt.
Größe von vector_store
Aktion
Bis ca. 30.000-40.000 Zeilen
index-type=none beibehalten, nicht eingreifen
Ca. 40.000-50.000 Zeilen
Beginnen Sie, durationMs in den RAG-Protokollen wöchentlich zu überwachen
50.000+ Zeilen oder deutlicher Anstieg von durationMs
Wechseln Sie zu HNSW (nicht IVFFlat) – aufgrund der unvorhersehbaren, inkrementellen Natur des Datenwachstums ist HNSW sicherer, da es keine REINDEX erfordert und nicht von der Einfügungsreihenfolge abhängt
Ehrlich gesagt, das Schwierigste an diesem Ansatz ist nicht die Überprüfung selbst, sondern die Disziplin, sie regelmäßig durchzuführen, wenn alles andere normal funktioniert. Es ist leicht, sie auf "nächstes Quartal" zu verschieben und zu vergessen. Deshalb haben wir die einfachste mögliche Abfrage und die geringstmögliche Anzahl von Metriken (nur zwei) gewählt – komplexeres Monitoring hätten wir für ein Projekt dieser Größenordnung einfach nicht dauerhaft aufrechterhalten können.
Häufig gestellte Fragen (FAQ)
Kann man einfach immer HNSW "für den Fall der Fälle" verwenden?
Man kann, aber bei kleinen Datensätzen (bis ca. 30-50K Zeilen) bringt dies keine messbaren Geschwindigkeitsvorteile, verbraucht aber Speicher und erhöht die Zeit für den Aufbau/Umbau des Index bei jeder Massenreindizierung von Daten.
Was tun, wenn das Hosting eine alte Version von pgvector hat und HNSW nicht unterstützt wird?
Überprüfen Sie die Version: SELECT extversion FROM pg_extension WHERE extname = 'vector';. Wenn das Hosting es zulässt – aktualisieren Sie die Erweiterung. Wenn nicht, und die Datenmenge gering ist – ist index-type=none eine voll funktionsfähige Lösung, kein temporärer Hack.
Gibt es etwas Besseres als HNSW für sehr große Datensätze?
Ja – DiskANN (über die Erweiterung pgvectorscale), die eine kompakte Navigationsstruktur im Speicher hält und die Vektoren selbst auf der Festplatte speichert, wobei nur zur endgültigen Verfeinerung der Kandidaten darauf zugegriffen wird. Nützlich, wenn der HNSW-Index das Volumen von shared_buffers überschreitet (dbi-services, März 2026).
Welche Fehler mit HNSW/IVFFlat sind am einfachsten zu machen?
Ich würde vier hervorheben, mit denen ich selbst konfrontiert war oder die ich in Projekten anderer gesehen habe:
Fehler Nr. 1 – HNSW bei 50.000 Dokumenten verwenden.
Ich selbst dachte früher, dass ein "größerer und besserer" Index nicht schaden kann. In der Praxis bringt bei dieser Menge der zusätzliche Speicher und die Aufbauzeit von HNSW keinen spürbaren Geschwindigkeitsvorteil im Vergleich zu einfachem index-type=none – Sie zahlen einfach Komplexität für einen Vorteil, der in diesem Maßstab noch nicht vorhanden ist.
Fehler Nr. 2 – IVFFlat vor dem Laden der Daten erstellen.
Das ist genau die Falle mit den Steil-Zentroiden, die ich oben ausführlich behandelt habe – und das ist kein theoretisches Problem, ich bin selbst in diese Falle getappt wegen initialize-schema=true in Spring AI. Wenn der Index auf einer leeren oder fast leeren Tabelle erstellt wird, bleibt er kaputt, bis Sie explizit REINDEX ausführen, nachdem die Daten tatsächlich geladen wurden.
Fehler Nr. 3 – lists = 10 auf eine Million Vektoren setzen.
Hier würde ich empfehlen, immer die Regel sqrt(N) im Hinterkopf zu behalten: für eine Million Vektoren sind das ungefähr 1000 Cluster, nicht 10. Zu wenige Cluster bedeuten, dass jeder von ihnen eine riesige Anzahl von Vektoren enthält, und die Suche innerhalb eines solchen "Riesen-Clusters" unterscheidet sich kaum von einem Brute-Force über die gesamte Tabelle – Sie verlieren alle Vorteile von IVFFlat, zahlen aber die Komplexität seiner Wartung.
Fehler Nr. 4 – Kein ANALYZE durchführen.
Dieser Fehler ist am leichtesten zu vergessen, da er nicht direkt mit dem Index selbst zusammenhängt. Nach dem Masseneinfügen oder Löschen von Daten veraltet die Statistik des Postgres-Planers, und er wählt Ihren Index möglicherweise einfach nicht während der Ausführung einer Abfrage aus, selbst wenn der Index perfekt aufgebaut ist. Ich habe es mir zur Gewohnheit gemacht, ANALYZE vector_store; sofort nach jeder Massenreindizierung auszuführen – das dauert Sekunden, rettet aber vor der Situation "der Index ist da, aber Postgres benutzt ihn nicht".
Schlussfolgerungen
Zusammenfassende Spickzettel: HNSW vs IVFFlat in einer Tabelle
Operation
HNSW
IVFFlat
Suche
Schneller
Langsamer
Einfügen
Langsamer
Schneller
Index aufbauen
Lang
Schnell
RAM (Speicher)
Hoch
Niedrig
Wenn man alles Besprochene in einem Satz zusammenfasst: HNSW tauscht Einfügegeschwindigkeit und Speicher gegen Suchgeschwindigkeit und Genauigkeit, IVFFlat umgekehrt. Welche Seite dieses Kompromisses wichtiger ist – hängt ausschließlich von Ihrem Lastmuster ab, nicht davon, welcher Index abstrakt "besser" ist.
Ein Index (HNSW oder IVFFlat) ist eine Optimierung für Skalierbarkeit, kein obligatorischer Bestandteil jedes pgvector-Projekts.
Bei Mengen bis ca. 30-50 Tausend Vektoren ist die Brute-Force-Suche (index-type=none) normalerweise schneller als der Overhead für die Indexwartung.
HNSW ist eine sicherere Standardeinstellung für sich unvorhersehbar ändernde Daten (neuer Inhalt, der schrittweise hinzugefügt wird): er ist unabhängig von der Einfügungsreihenfolge, benötigt kein REINDEX.
IVFFlat ist sinnvoll, wenn Daten in großen Stapeln auf einmal geladen und häufig abgefragt werden – erfordert aber den Aufbau des Index *nach* dem Laden eines repräsentativen Datenvolumens und periodisches REINDEX im Zuge des Wachstums.
Der teuerste Fehler ist die Erstellung eines IVFFlat-Index auf einer leeren Tabelle durch automatische Schema-Initialisierung. Der Recall verschlechtert sich leise, und das kann leicht mit Problemen des Embedding-Modells verwechselt werden.