HNSW vs IVFFlat en pgvector: cuándo realmente necesitas un índice
Tenemos 10 852 vectores en producción en una tabla llamada vector_store, y todavía no usamos ni HNSW ni IVFFlat. Esto no es un descuido. Spoiler: para la mayoría de los blogs y pequeños proyectos RAG, un índice no es necesario hasta decenas de miles de filas, y cuando lo sea, la elección incorrecta entre HNSW e IVFFlat puede romper silenciosamente la precisión de la búsqueda durante semanas antes de que te des cuenta.
⚡ En resumen
✅ Hasta ~50 000 vectores: la búsqueda por fuerza bruta (index-type=none) es casi siempre más rápida y sencilla que mantener un índice
✅ HNSW: mejor recall, calidad estable independientemente del orden de inserción de datos, pero +2-5x de memoria y construcción más lenta
✅ IVFFlat: construcción más rápida, menos memoria, pero requiere datos ANTES de crear el índice y un REINDEX periódico
🎯 Obtendrás: umbrales de transición específicos, configuraciones reales de Spring AI y dos casos: un blog de 800 artículos y un servicio con decenas de miles de documentos
👇 Lee más abajo, con cifras, SQL y una explicación de por qué existe un tercer índice (DiskANN)
¿Qué es la búsqueda ANN y por qué la fuerza bruta no siempre es mala
Cuando buscas los vectores más cercanos a una consulta en pgvector, hay dos caminos. El primero es comparar la consulta con cada fila de la tabla (búsqueda exacta del vecino más cercano, exact nearest neighbor). El segundo es usar un índice que encuentra aproximadamente los vecinos más cercanos sin verificar todas las filas (búsqueda aproximada del vecino más cercano, Approximate Nearest Neighbor, ANN).
El enfoque de fuerza bruta (sin índice, index-type=none en Spring AI) escala linealmente — O(n). Con 10 000 filas, son milisegundos. Con 10 millones, ya son segundos por consulta, lo cual es inaceptable para cualquier producción con tráfico.
pgvector soporta dos tipos principales de índices ANN — HNSW y IVFFlat — y desde la versión 0.8.2 (febrero de 2026) existe adicionalmente la extensión DiskANN a través de un paquete separado pgvectorscale para conjuntos de datos muy grandes que exceden los shared_buffers(dbi-services, marzo de 2026). En este artículo, nos centramos en HNSW e IVFFlat, ya que son con los que se enfrenta el 95% de los proyectos.
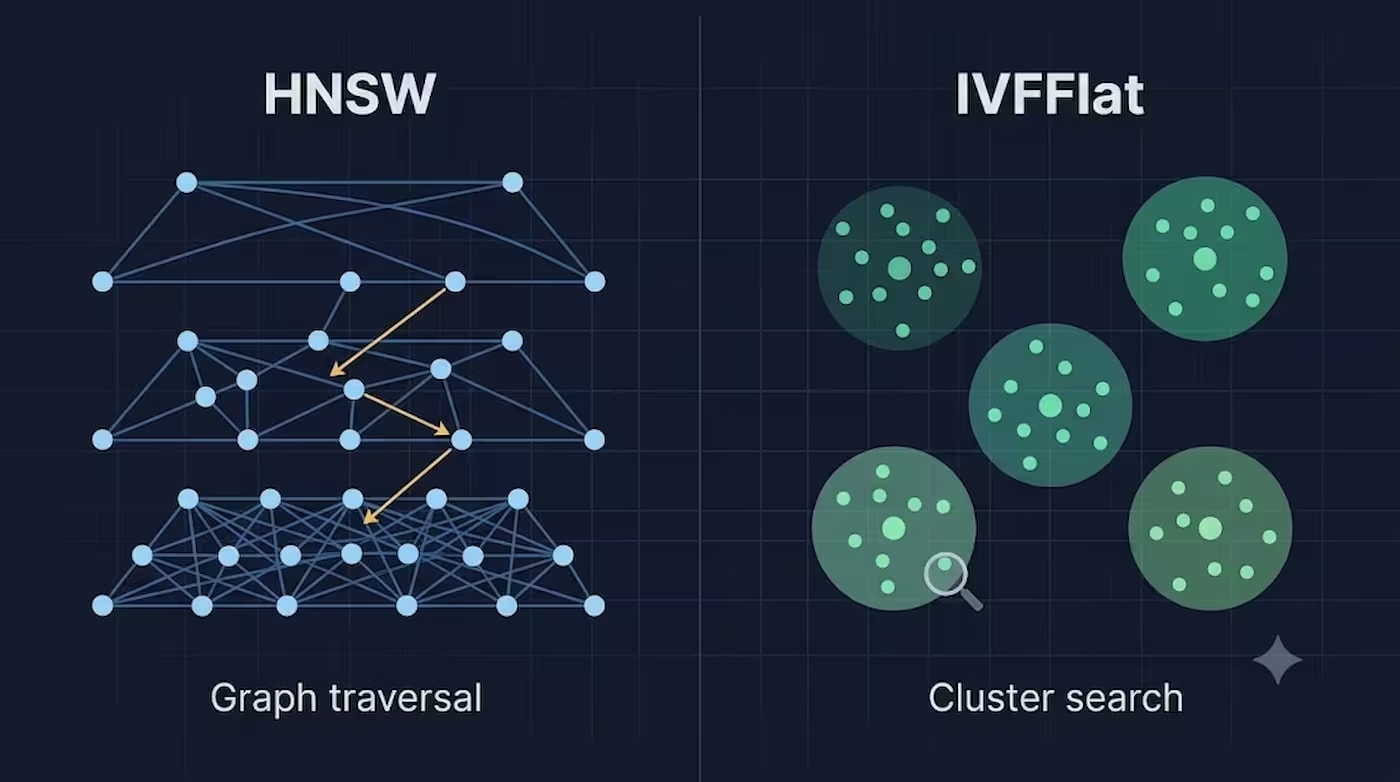
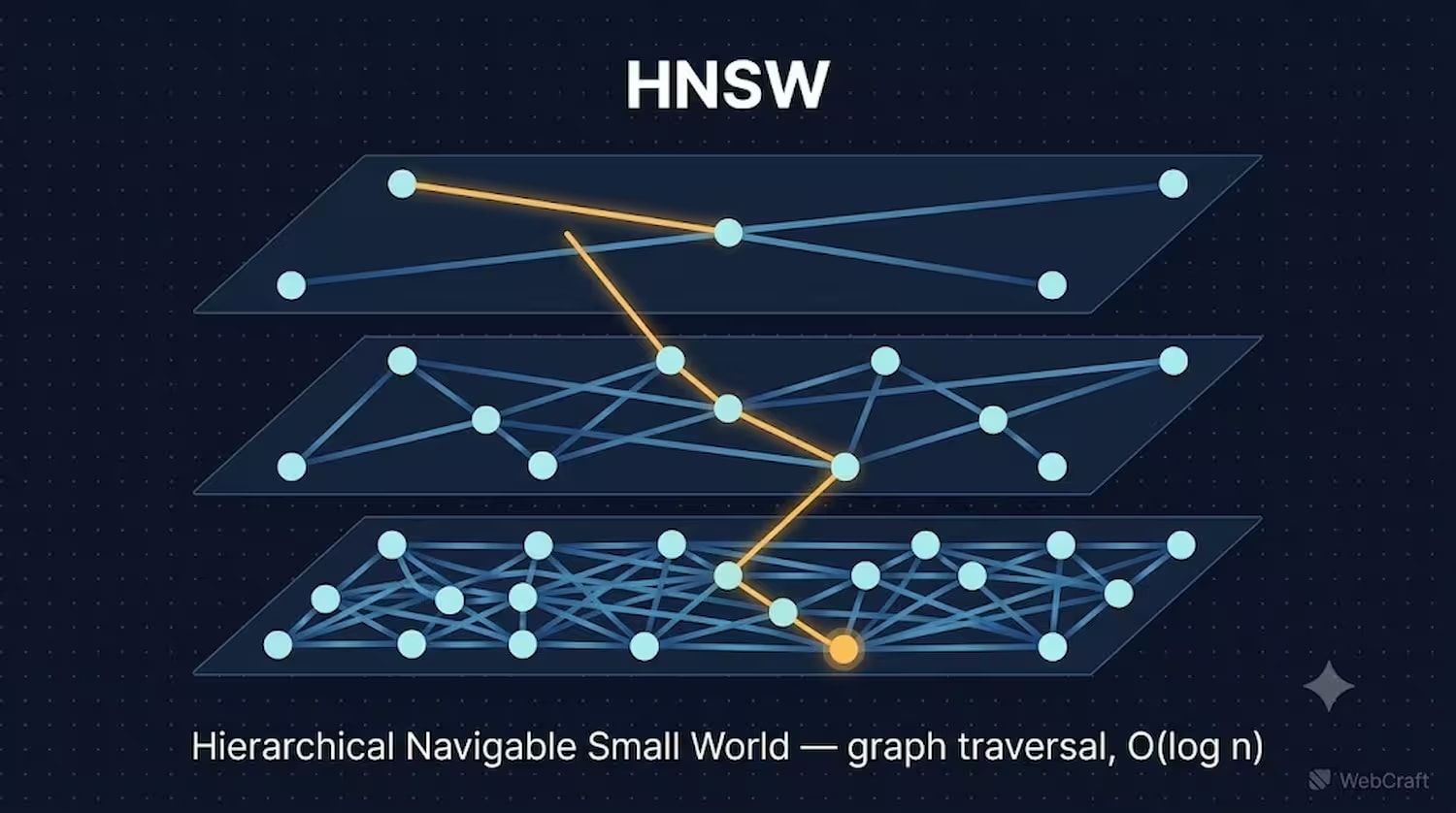
Cómo funciona HNSW
HNSW (Hierarchical Navigable Small World) construye un grafo de conexiones multinivel entre vectores. Los niveles superiores del grafo contienen conexiones "troncales" dispersas para transiciones rápidas a larga distancia, y los inferiores, conexiones locales densas para una búsqueda final precisa. Una consulta entra en el nivel superior y "desciende", reduciendo la búsqueda a los vecinos más cercanos.
Una analogía que explica bien la esencia: imagina buscar una dirección en una ciudad desconocida. En lugar de recorrer cada calle una por una (eso es fuerza bruta), primero sales a una autopista (nivel superior del grafo — conexiones "troncales" a larga distancia), llegas al distrito deseado y luego cambias a calles locales (nivel inferior — conexiones locales densas) para encontrar la dirección exacta. Cada "piso" del grafo reduce el espacio de búsqueda, de ahí la complejidad logarítmica.
Gracias a esta estructura, el tiempo de búsqueda aumenta logarítmicamente — O(log n) — y no depende del orden en que se cargaron los datos (Philip McClarence, Medium, abril de 2026). HNSW se puede construir incluso sobre una tabla vacía; el índice se adapta a medida que se insertan nuevos vectores.
Ejemplo de creación de índice:
CREATE INDEX ON vector_store
USING hnsw (embedding vector_cosine_ops)
WITH (m = 16, ef_construction = 64);
Aquí, m es el número máximo de conexiones por nodo del grafo (más conexiones = mayor recall, pero más memoria), y ef_construction es cuán ampliamente el algoritmo "explora" durante la construcción del índice, buscando candidatos para las conexiones. En la etapa de búsqueda, hay un parámetro simétrico ef_search, que controla cuántos candidatos se consideran durante la consulta en sí:
SET hnsw.ef_search = 40;
SELECT id, content
FROM vector_store
ORDER BY embedding <=> '[0.012, -0.034, ...]'
LIMIT 10;
Los valores predeterminados (m=16, ef_construction=64, ef_search=40) no son números aleatorios, sino un punto de partida cuidadosamente seleccionado. La mayoría de las quejas del tipo "pgvector es lento" surgen precisamente porque estos parámetros nunca se ajustaron al conjunto de datos específico (Nerd Level Tech, mayo de 2026).
El precio de la calidad de la búsqueda es la memoria y el tiempo de construcción. Una regla empírica para estimar el volumen de memoria durante la construcción del índice es: N × D × 4 bytes × 2 (el multiplicador 2 tiene en cuenta los gastos generales de la propia estructura del grafo) (DEV Community, marzo de 2026). Para 5 millones de vectores con 1536 dimensiones, esto significa 8-16 GB de memoria de trabajo solo para la construcción.
Un índice listo también ocupa mucho espacio: una regla aproximada es 6-8 GB de RAM por cada millón de vectores con 1536 dimensiones para HNSW en memoria (Groovyweb, 2026). Cabe destacar que la dimensionalidad del vector (1536 frente a, por ejemplo, 3072) influye directamente en esta cifra; analizamos con más detalle cuándo una mayor dimensionalidad de embeddings está realmente justificada en el artículo «1536 vs 3072: comparación de embeddings para búsqueda por documentos y RAG».
Cifras reales de memoria: por qué HNSW "come" más de lo que parece
Muchos ven la cifra "6-8 GB por 1M de vectores" y piensan que ese es el costo de HNSW. En realidad, es la suma de dos componentes separados, y es el segundo el principal inconveniente de HNSW que se subestima fácilmente.
Ejemplo: 1 millón de vectores × 1536 dimensiones
Componente
Cálculo
Volumen
Los propios vectores (tabla heap)
1 000 000 × 1536 × 4 bytes
≈ 6 GB
Índice HNSW (grafo de conexiones)
depende de m, en promedio +20-50% del volumen de vectores
+1-3 GB
Total
7-9 GB RAM
Aquí radica la principal desventaja que a menudo se pasa por alto: estos 6 GB para los propios vectores son necesarios en cualquier caso, incluso con index-type=none, incluso con IVFFlat. Este es el costo base de almacenar datos. Y los 1-3 GB adicionales son gastos generales puros de la estructura del grafo HNSW: una matriz de conexiones (neighbors) para cada nodo en cada nivel del grafo, que debe mantenerse en memoria para un recorrido rápido.
En la práctica, esto significa que si tu instancia de Postgres apenas puede albergar los datos (esos 6 GB base), agregar un índice HNSW puede empujar el consumo total de memoria más allá de los shared_buffers disponibles, y parte del grafo comenzará a ser desalojado al disco, y este es precisamente el escenario en el que la búsqueda se vuelve más lenta, no más rápida, a pesar de la ventaja teórica de O(log n)(dbi-services, marzo de 2026).
IVFFlat, en este sentido, es más honesto: no agrega una estructura de conexiones separada sobre los datos, sino que solo almacena el número de clúster para cada vector, por lo que consume significativamente menos memoria además de los 6 GB base.
Una consecuencia práctica del parámetro maintenance_work_mem: si su valor es demasiado bajo (el predeterminado en Postgres suele ser 64 MB), la construcción del índice HNSW se "desborda" al disco y se ejecuta 10-50 veces más lento (DEV Community, marzo de 2026). Antes de construir un índice en un conjunto de datos grande, vale la pena aumentar temporalmente este parámetro:
SET maintenance_work_mem = '2GB';
CREATE INDEX ON vector_store
USING hnsw (embedding vector_cosine_ops);
-- después de la construcción, puedes devolver el valor predeterminado
RESET maintenance_work_mem;
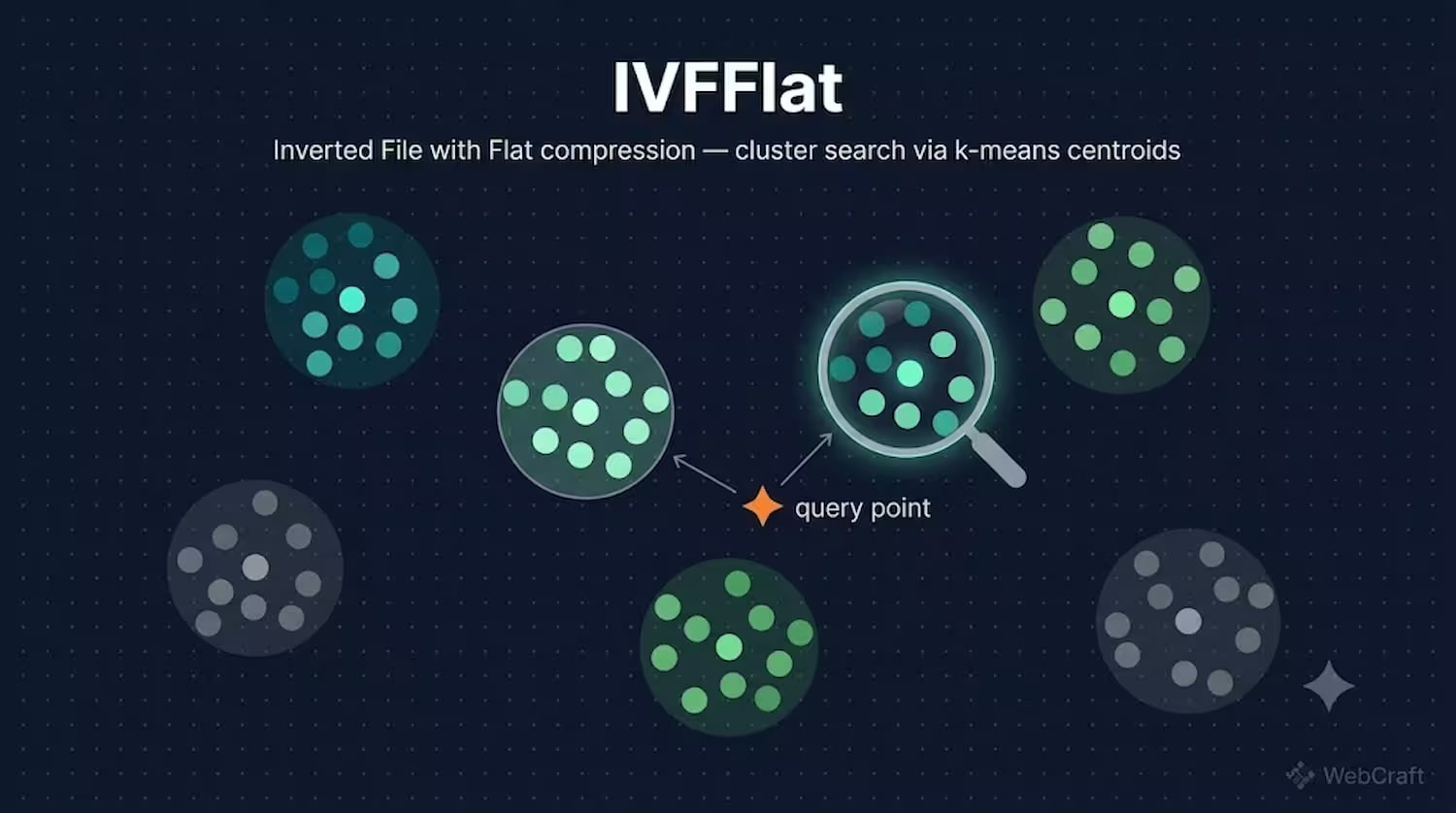
Cómo funciona IVFFlat
IVFFlat (Inverted File with Flat compression) toma un camino diferente: divide todo el espacio de vectores en clústeres (celdas de Voronoi) usando k-means, cada uno con su propio centroide. Al buscar, primero se determinan los clústeres más cercanos al vector de consulta (la cantidad se controla con el parámetro probes), y luego la búsqueda se realiza solo dentro de estos clústeres.
Analogía: imagina una biblioteca donde los libros no están ordenados alfabéticamente, sino por secciones temáticas: fantasía, historia, cocina. En lugar de revisar cada libro de la biblioteca (fuerza bruta), primero vas a la sección correcta (centroide más cercano) y luego buscas el libro específico solo entre los que están allí (búsqueda dentro del clúster). Si un libro está accidentalmente en la sección "equivocada", simplemente no lo encontrarás, sin importar cuántas secciones revises. Esta es la limitación fundamental de IVFFlat: la calidad de la búsqueda depende de cuán exitosamente k-means haya distribuido los vectores en los clústeres.
-- Para 10 000 vectores: lists = sqrt(10000) ≈ 100
CREATE INDEX ON vector_store
USING ivfflat (embedding vector_cosine_ops)
WITH (lists = 100);
En la etapa de búsqueda, el parámetro probes controla la precisión: cuántos clústeres más cercanos se verifican. Cuanto mayor sea probes, mayor será el recall, pero más lenta será la búsqueda (ya que hay que escanear más clústeres):
SET ivfflat.probes = 10;
SELECT id, content
FROM vector_store
ORDER BY embedding <=> '[0.012, -0.034, ...]'
LIMIT 10;
Por defecto, probes = 1: solo se verifica el clúster más cercano. Esto es rápido, pero si el vector de consulta está cerca del límite entre dos clústeres, el resultado relevante podría estar en el clúster "vecino", que nunca se verificará. Aumentar probes a 5-10 es un compromiso habitual entre velocidad y precisión.
IVFFlat se construye más rápido y consume menos memoria que HNSW, pero tiene un recall más bajo, especialmente en datos de alta dimensionalidad o conjuntos de datos grandes. Aquí vale la pena recordar que la dimensionalidad del vector en sí (por ejemplo, 1536 frente a 3072) no solo afecta la calidad de la semántica, sino también cuán "difusos" se vuelven los límites de los clústeres con k-means; analizamos con más detalle la elección de la dimensionalidad de los embeddings en el artículo «1536 vs 3072: comparación de embeddings para búsqueda por documentos y RAG».
El matiz más importante: IVFFlat requiere que los datos ya estén en la tabla ANTES de construir el índice; el algoritmo necesita "aprender" los centros de los clústeres a partir de la distribución real de los datos. HNSW no tiene esta limitación.
Hay otro aspecto práctico que se subestima fácilmente: la calidad de los propios vectores que caen en los clústeres depende directamente de cómo se dividió el texto en fragmentos antes de la indexación. Fragmentos demasiado pequeños dan embeddings "ruidosos" que k-means tiene dificultades para distribuir en clústeres claros; fragmentos demasiado grandes mezclan varios temas en un solo vector, lo que también difumina los límites de los clústeres. Analizamos esto con más detalle en el artículo «Estrategias de fragmentación en RAG 2026: cómo dividir correctamente los datos para producción».
Un estudio independiente separado en conjuntos de datos reales (10-25 millones de vectores — SIFT, OpenAI, Cohere embeddings) muestra que las optimizaciones como la media precisión (halfvec) proporcionan una velocidad de búsqueda (QPS) prácticamente idéntica con la mitad del tamaño del índice, y la cuantificación binaria más agresiva con re-ranking comprime el índice 11-12 veces — pero ya con una caída notable en la precisión en algunos tipos de datos (estudio "Filter-Agnostic Vector Search on PostgreSQL", 2026). Esto es relevante si el índice HNSW se acerca al volumen de shared_buffers — una compensación de "un poco menos de precisión a cambio de la mitad de memoria" a menudo se justifica en esta etapa, no antes.
Resumen de un benchmark independiente de Instaclustr: «Elija HNSW cuando la precisión y la velocidad de búsqueda sean más importantes que el tiempo de construcción del índice o el uso de memoria. IVFFlat es una opción sensata para aplicaciones de baja latencia donde el tiempo de construcción o la compacidad son más importantes que el recall más alto»(Instaclustr, febrero de 2026).
La trampa de IVFFlat: centroides estancadas
Este es el error más común y costoso con pgvector, y se reproduce fácilmente en proyectos Spring AI precisamente por initialize-schema=true.
Escenario: el equipo crea un índice CREATE INDEX ... USING ivfflat al inicio de la aplicación — cuando la tabla vector_store aún está vacía o tiene solo unas pocas filas de prueba. Los centroides k-means se calculan basándose en estos datos no representativos.
Lo que sucede técnicamente: el algoritmo k-means mira los pocos vectores que existen en el momento de la construcción del índice y divide todo el espacio futuro en clústeres a su alrededor. Si en ese momento la tabla contenía, digamos, 5 filas de prueba — los centroides se "congelan" en una forma que corresponde a esos cinco puntos. Cuando luego se cargan miles de documentos reales, entran físicamente en el espacio de vectores, pero la estructura lógica de los clústeres ya no corresponde a la nueva distribución de los datos. Parte de los nuevos vectores terminan "lejos" de su centroide más cercano simplemente porque ningún centroide fue realmente calculado teniendo en cuenta su existencia.
El resultado es que todas las búsquedas posteriores se realizan contra un índice con centroides "obsoletas". El recall se degrada silenciosamente: una consulta que debería encontrar un documento relevante no lo encuentra, porque el documento ha caído en un clúster "fallido" que nunca se verifica con el probes = 1 estándar. El equipo cree durante meses que el problema está en la calidad del modelo de embedding o en la estrategia de chunking, aunque la raíz es una línea en la migración de la base de datos (Philip McClarence, Medium, abril de 2026).
Lo peor de este error es su invisibilidad. No hay una excepción, no hay un error en los logs, no hay una caída de la aplicación. La búsqueda simplemente funciona — pero peor de lo que podría. El chat RAG continúa respondiendo, simplemente dice con más frecuencia "no encontré información relevante" o extrae contexto menos preciso. Este es precisamente el tipo de problema donde la ausencia de una señal de alarma — es una señal de alarma.
Por mi parte diré: cuando nos encontramos por primera vez con el error bad SQL grammar al intentar que Spring AI cree automáticamente un índice HNSW al inicio de la aplicación (debido a una versión obsoleta de la extensión pgvector en el hosting), lo primero que se nos ocurre es simplemente cambiar index-type a ivfflat en lugar de none y seguir adelante. Y es aquí donde es fácil caer inadvertidamente en la misma trampa: initialize-schema=true en Spring AI significa que el índice se crea inmediatamente al inicio — y en ese momento la tabla casi siempre está vacía. Si no nos hubiéramos detenido y no hubiéramos investigado por qué HNSW falló con un error, sino que simplemente hubiéramos sustituido IVFFlat como reemplazo "automáticamente" — habríamos obtenido una aplicación funcional con una búsqueda imperceptiblemente rota, y solo nos habríamos enterado de ello cuando los usuarios comenzaran a quejarse de que el chatbot "no entiende" preguntas sencillas.
Recomendación de la misma fuente: «Los índices IVFFlat no pertenecen a las migraciones de esquema. Pertenecen a los scripts de carga posterior. HNSW es una opción predeterminada segura para aplicaciones de hasta 1 millón de filas». Esto no es solo un consejo estilístico — es una delimitación por propósito: la migración de esquema describe la estructura de la base de datos, no su contenido, mientras que IVFFlat por su naturaleza está intrínsecamente ligado al contenido.
Caso 1: blog con 800 artículos — por qué no usamos ningún índice
Nuestro blog webscraft.org tiene ~800 artículos (originales en ucraniano + traducciones EN/DE/ES) y un chat RAG basado en Spring AI + pgvector. El estado actual de la tabla vector_store:
Historia honesta: index-type=none no fue una decisión arquitectónica desde el principio. En el hosting gestionado de Postgres, al primer despliegue, Spring AI intentó ejecutar automáticamente:
CREATE INDEX IF NOT EXISTS spring_ai_vector_index
ON public.vector_store USING HNSW (embedding vector_cosine_ops)
y falló con el error bad SQL grammar — la versión de la extensión pgvector en el hosting estaba obsoleta y no soportaba la sintaxis HNSW (añadida solo en pgvector 0.5.0, agosto de 2023). La solución rápida fue index-type=none, y así se quedó en producción — porque el análisis posterior mostró: en 10,852 filas, no solo "funciona", sino que es la solución óptima.
Por qué: el umbral en el que un índice ANN realmente comienza a justificarse es aproximadamente 50,000 vectores (en volúmenes menores, un escaneo brute-force se realiza en milisegundos, y los gastos generales de construcción y mantenimiento de HNSW/IVFFlat, por el contrario, añaden complejidad sin un beneficio medible). Con un ritmo de crecimiento de 3-4 artículos por semana, alcanzar este umbral es cuestión de años, no de meses.
Caso 2: servicio con decenas de miles de documentos — por qué IVFFlat es apropiado allí
Otro de nuestros proyectos, askyourdocs.org, está diseñado de manera diferente: es un servicio auto-alojado con el principio de single-tenant por despliegue — cada cliente recibe su propia instancia completamente aislada con una base de datos separada (despliegue separado en Railway, variables de entorno separadas). Los datos de un cliente no se encuentran físicamente en la misma tabla que los datos de otro. Arquitectónicamente, se espera un crecimiento hasta decenas de miles de documentos dentro de una de estas bases de datos — una escala donde el brute-force ya no es una opción. Configuración:
IVFFlat se elige aquí conscientemente: los documentos se cargan en lotes (el cliente carga un conjunto de archivos una vez, luego principalmente solo lee/busca), lo que se ajusta al escenario "datos cargados una vez, consultados con frecuencia" — precisamente el caso en el que IVFFlat es una opción sensata según la evaluación de PE Collective (abril de 2026).
Un matiz arquitectónico importante precisamente para este modelo de despliegue: dado que cada cliente tiene su propia base de datos separada, los centroides k-means para IVFFlat se construyen exclusivamente basándose en los documentos de ese cliente específico — sin el "ruido" de datos ajenos que sería un problema en una tabla multi-tenant compartida con filtrado por userId. Esto elimina una clase de problemas de búsqueda filtrada, pero a cambio añade otro matiz: el momento en que el cliente carga su primer lote de documentos es también el momento en que la base de datos pasa de "vacía" a "real" — y es aquí donde initialize-schema=true al primer despliegue crea fácilmente un índice IVFFlat en una tabla vacía, antes de que se cargue ningún documento.
Conclusión práctica para esta arquitectura: IVFFlat debe ser construido o reconstruido después de la carga inicial de un volumen representativo de documentos de un cliente específico (no inmediatamente al desplegar a través de initialize-schema=true), y periódicamente hacer REINDEX a medida que el cliente continúa cargando nuevos documentos — de lo contrario, los centroides envejecen tal como se describe en la sección sobre la trampa anterior. Para el modelo auto-alojado, esto significa: el paso de "reconstruir el índice después de la carga inicial" debe ser parte del onboarding de un nuevo cliente, no una configuración única a nivel de toda la aplicación.
Recomendación práctica: cómo monitorizar el momento de la transición
No es necesario adivinar cuándo cambiar a un índice. En nuestro propio blog, lo hemos reducido a dos métricas sencillas que comprobamos trimestralmente, sin ninguna automatización ni panel de control, solo recordatorios en el calendario.
-- 1. Tamaño de la tabla vector_store
SELECT COUNT(*) FROM vector_store;
Ejecutamos esta consulta manualmente a través de PgAdmin en un minuto. En el momento de escribir este artículo, tenemos 10.852 filas, y conscientemente no tenemos prisa por cambiar nada, porque todavía queda mucho tiempo hasta el umbral de transición aproximado a nuestro ritmo de crecimiento (3-4 artículos por semana).
Si ya tiene un registro de consultas RAG (en nuestro caso, es una tabla separada con un panel de administración, la describimos en la sección sobre procesamiento de consultas), la segunda señal es la duración de la búsqueda (durationMs) a lo largo del tiempo. El aumento de este indicador es un indicador más temprano y preciso que el tamaño de la tabla en sí, ya que también depende de la carga del servidor. Le prestamos atención no como una métrica exacta, sino como una tendencia: si el durationMs promedio por semana aumenta notablemente de semana en semana, es una señal para observar más de cerca, incluso si la cantidad absoluta de filas aún no parece alarmante.
Tamaño de vector_store
Acción
Hasta ~30 000-40 000 filas
Dejar index-type=none, no intervenir
~40 000-50 000 filas
Empezar a monitorizar durationMs en los logs RAG semanalmente
50 000+ filas o un aumento notable de durationMs
Cambiar a HNSW (no IVFFlat) — debido a la naturaleza impredecible e incremental del crecimiento de datos, HNSW es más seguro porque no requiere REINDEX y no depende del orden de inserción
Sinceramente, lo más difícil de este enfoque no es la comprobación en sí, sino la disciplina para hacerlo regularmente cuando todo funciona bien. Es fácil posponerlo "hasta el próximo trimestre" y olvidarse. Por eso elegimos la consulta más simple posible y la menor cantidad posible de métricas (solo dos); simplemente no mantendríamos un monitoreo más complejo de forma continua para un proyecto de esta escala.
Preguntas frecuentes (FAQ)
¿Se puede simplemente usar siempre HNSW "por si acaso"?
Se puede, pero en conjuntos de datos pequeños (hasta ~30-50K filas) no proporciona un beneficio medible en velocidad, al tiempo que consume memoria y aumenta el tiempo de construcción/reconstrucción del índice en cada reindexación masiva de datos.
¿Qué hacer si el hosting tiene una versión antigua de pgvector y HNSW no es compatible?
Compruebe la versión: SELECT extversion FROM pg_extension WHERE extname = 'vector';. Si el hosting lo permite, actualice la extensión. Si no, y el volumen de datos es pequeño, index-type=none es una solución completamente funcional, no un hack temporal.
¿Existe algo mejor que HNSW para conjuntos de datos muy grandes?
Sí, DiskANN (a través de la extensión pgvectorscale), que mantiene una estructura de navegación compacta en memoria, y los vectores en sí en disco, accediendo a ellos solo para la refinación final de los candidatos. Es útil cuando el índice HNSW excede el volumen de shared_buffers(dbi-services, marzo de 2026).
¿Qué errores con HNSW/IVFFlat son los más fáciles de cometer?
Destacaría cuatro, con los que me he encontrado personalmente o he visto en proyectos ajenos:
Error nº 1: usar HNSW en 50.000 documentos.
Yo mismo pensaba que un índice "más grande y mejor" no podía hacer daño. En la práctica, con este volumen, la memoria adicional y el tiempo de construcción de HNSW no proporcionan ninguna ventaja de velocidad perceptible en comparación con un simple index-type=none; simplemente paga complejidad por un beneficio que aún no existe a esta escala.
Error nº 2: crear IVFFlat antes de cargar los datos.
Esta es precisamente la trampa de los centroides estancados que desglosé detalladamente anteriormente, y no es un problema teórico; yo mismo caí en esta trampa debido a initialize-schema=true en Spring AI. Si el índice se construye sobre una tabla vacía o casi vacía, permanece roto hasta que explícitamente haga REINDEX después de la carga real de los datos.
Error nº 3: establecer lists = 10 para un millón de vectores.
Aquí recomendaría tener siempre en mente la regla sqrt(N): para un millón de vectores, son aproximadamente 1000 clústeres, no 10. Muy pocos clústeres significan que cada uno de ellos contiene una gran cantidad de vectores, y la búsqueda dentro de un "clúster gigante" así apenas se diferencia de una búsqueda bruta en toda la tabla; pierde todo el beneficio de IVFFlat, pero paga la complejidad de su mantenimiento.
Error nº 4: no hacer ANALYZE.
Este error es el más fácil de olvidar, ya que no está directamente relacionado con el índice en sí. Después de una inserción o eliminación masiva de datos, las estadísticas del planificador de Postgres quedan obsoletas y puede que simplemente no elija su índice durante la ejecución de la consulta, incluso si el índice está perfectamente construido. Me he acostumbrado a ejecutar ANALYZE vector_store; inmediatamente después de cualquier reindexación masiva; esto lleva segundos, pero salva de la situación "el índice existe, pero Postgres no lo usa".
Conclusiones
Hoja de trucos final: HNSW vs IVFFlat en una tabla
Operación
HNSW
IVFFlat
Search (búsqueda)
Más rápido
Más lento
Insert (inserción)
Más lento
Más rápido
Build Index (construcción de índice)
Largo
Rápido
RAM (memoria)
Alta
Baja
Si reducimos toda la discusión a una sola frase: HNSW cambia la velocidad de inserción y la memoria por la velocidad y precisión de la búsqueda, IVFFlat, por el contrario. Qué lado de este compromiso es más importante depende exclusivamente de su patrón de carga, y no de qué índice es "mejor" en un sentido abstracto.
Un índice (HNSW o IVFFlat) es una optimización para la escala, no un componente obligatorio de cualquier proyecto pgvector.
En volúmenes de hasta ~30-50 mil vectores, la búsqueda bruta (index-type=none) suele ser más rápida que los gastos generales de mantenimiento del índice.
HNSW es una opción predeterminada más segura para datos que cambian de forma impredecible (nuevo contenido que se añade gradualmente): no depende del orden de inserción, no requiere REINDEX.
IVFFlat es apropiado cuando los datos se cargan en grandes lotes de una sola vez y se consultan con frecuencia, pero requiere la construcción del índice *después* de cargar un volumen de datos representativo y un REINDEX periódico a medida que crece.
El error más costoso es crear un índice IVFFlat en una tabla vacía a través de la inicialización automática del esquema. El recall se degrada silenciosamente y es fácil confundirlo con problemas del modelo de embedding.