Ви коли-небудь дивувались, чому ChatGPT знаходить зв'язок між "автомобілем" і "машиною" — хоча це різні слова? Або чому RAG-система знаходить потрібний документ навіть якщо у запиті немає жодного слова з тексту? Спойлер: за цим стоїть одна технологія — embedding. Це спосіб перетворити будь-який текст у набір чисел так, щоб схожі за змістом тексти мали схожі числа.
⚡ Коротко
- ✅ Embedding — це не слово, а число: кожне слово або речення перетворюється на вектор із сотень чисел, що кодує його сенс
- ✅ Схожий сенс = схожі числа: "кіт" і "кошеня" мають близькі вектори, "кіт" і "ракета" — далекі
- ✅ Без embeddings немає RAG, семантичного пошуку і рекомендацій: це фундамент більшості сучасних AI-систем
- 🎯 Ви отримаєте: чітке розуміння що таке embedding, як він навчається, де використовується і коли не підходить
- 👇 Нижче — пояснення з аналогіями, схеми і практичні висновки без зайвої теорії
📚 Зміст статті
- 📌 Розділ 1. Від токенів до чисел: чому AI не може працювати зі словами напряму
- 📌 Розділ 2. Embedding = координати у просторі сенсу
- 📌 Розділ 3. Звідки беруться ці числа? Як модель навчилась кодувати сенс
- 📌 Розділ 4. Розмірність: чому 768 ≠ 1536 і що це означає на практиці
- 📌 Розділ 5. Де embeddings використовуються: 5 реальних застосувань
- 📌 Розділ 6. Обмеження embeddings: коли вони не допоможуть
- 💼 Розділ 7. Моделі 2026: з чого почати
- ❓ Часті питання (FAQ)
- ✅ Висновки
🎯 Від токенів до чисел: чому AI не може працювати зі словами напряму
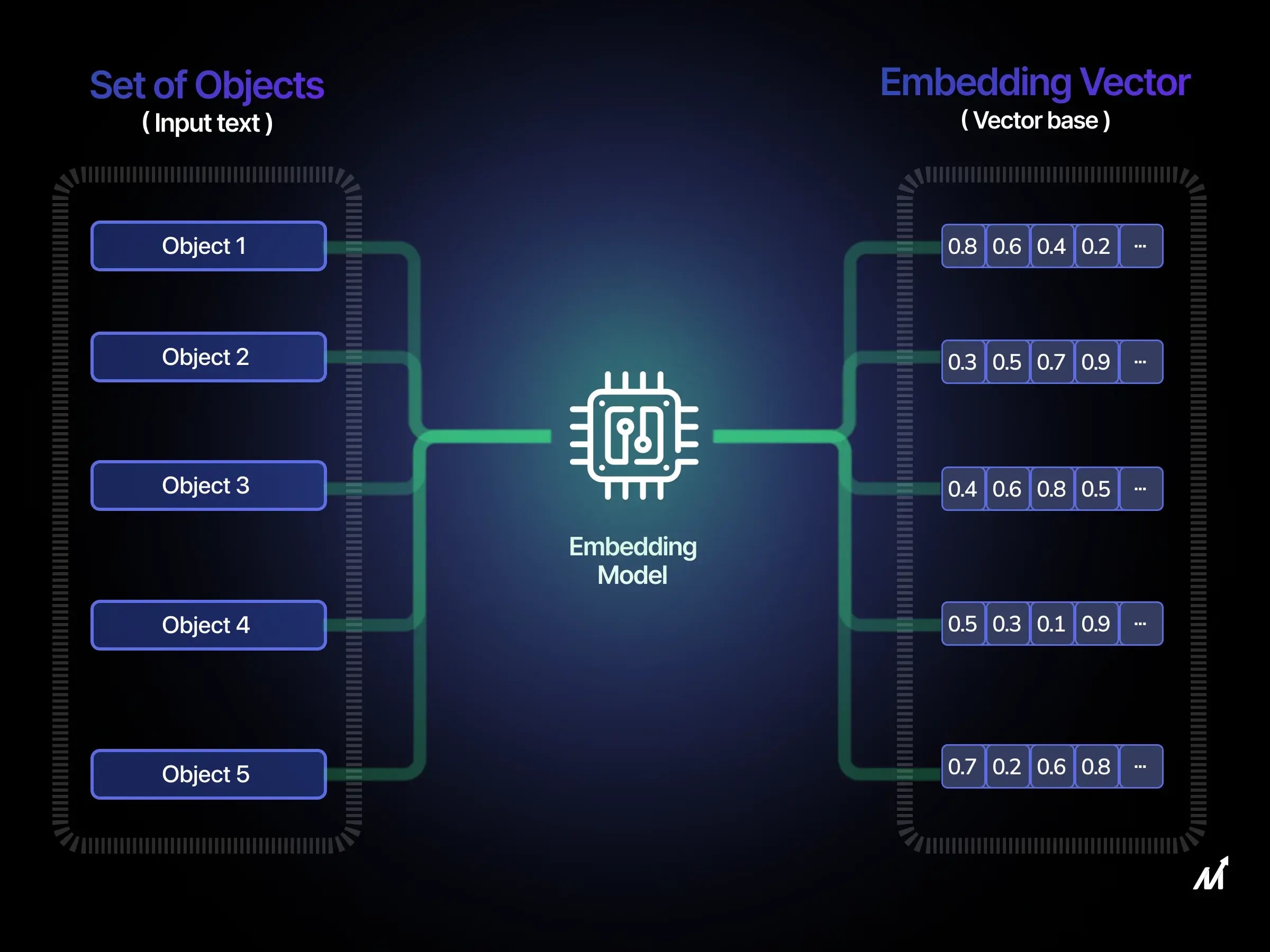
Нейронна мережа — це математична функція. Вона не може обробляти слова як такі, бо не знає що таке "кіт" чи "договір". Вона вміє тільки множити, складати і трансформувати числа. Тому кожне слово (або токен) потрібно спочатку перетворити на числовий вектор — і саме це робить embedding-модель.
Токен — це одиниця тексту, яку бачить AI. Embedding — це те, що цей токен означає, записане у вигляді чисел.
Якщо ви читали статтю про токени, то знаєте: AI ділить текст на фрагменти (токени) — це можуть бути цілі слова, частини слів або навіть окремі символи. Але токен — це ще не значення. Це просто одиниця розбиття.
Embedding — наступний крок. Кожен токен отримує свій унікальний числовий "відбиток" — вектор. Цей вектор кодує не написання слова, а його сенс у контексті мови. Саме тому "автомобіль" і "машина" — різні токени, але їх вектори будуть дуже близькими.
Аналогія: словник vs карта міста
Уявіть два способи описати слово. Перший — словник: "кіт — домашня тварина родини котячих". Це корисно для людини, але марно для математики. Другий — карта: у місті понять "кіт" стоїть поряд з "кошеням", "лапою", "муркотінням" — і далеко від "ракети" чи "бухгалтерії". Embedding — це саме карта, де позиція кожного слова визначається його сенсовим оточенням. документації OpenAI Embeddings як перетворення тексту на числовий вектор у просторі високої розмірності.
- ✔️ Токен = одиниця тексту (що написано)
- ✔️ Embedding = числовий вектор (що це означає)
- ✔️ Без перетворення тексту в числа — жодна нейронна мережа не може з ним працювати
Висновок: Embedding — це обов'язковий місток між текстом, який розуміє людина, і числами, з якими працює AI.
Чому різні моделі дають різний результат: порівняльна таблиця
| Параметр | OpenAI text-embedding-3-small | BGE-M3 (BAAI) | E5-large (Microsoft) |
|---|---|---|---|
| Training signal (на чому навчалась) |
Синтетичні пари згенеровані GPT-4 + NLI-датасети + веб-корпус. Закритий датасет, деталі не розкриті | Відкритий датасет: 1.2M пар з 570+ джерел — MS MARCO, NLI, паралельні переклади 100+ мов, код | Веб-корпус + NLI-датасети Microsoft. Instruction-tuning: перед кожним запитом додається інструкція типу "query: " або "passage: " |
| Контекстне вікно (макс. токенів) |
8 191 токенів — достатньо для довгих статей і документів | 8 192 токени — аналогічно, плюс підтримка довгих запитів при hybrid search | 512 токенів — обмеження для довгих документів, потрібен chunking |
| Архітектура | Transformer encoder, деталі закриті. Підтримує Matryoshka (MRL): можна обрізати до 256 вимірів | XLM-RoBERTa як базова модель. Унікальність: одночасно генерує dense + sparse + ColBERT вектори | Transformer encoder на базі DeBERTa. Instruction-aware: результат залежить від prefix-інструкції |
| Розмірність вектора | 1 536 (або менше через MRL) | 1 024 | 1 024 |
| Метрика схожості | Cosine Similarity (або Dot Product після нормалізації) | Cosine Similarity для dense, inner product для sparse | Cosine Similarity — але обов'язково додавати prefix, інакше якість падає |
| Мультимовність | Підтримує, але якість на кирилиці нижча ніж на латиниці | 100+ мов, однакова якість — лідер мультимовних бенчмарків MTEB | Переважно англійська. Мультимовна версія — окрема модель multilingual-e5 |
| Hybrid search | Тільки dense вектори — для hybrid потрібен окремий BM25 | Native hybrid: dense + sparse в одній моделі без додаткових інструментів | Тільки dense — hybrid через окремий BM25 або Elasticsearch |
| Ціна | $0.02 / 1M токенів через API | Безкоштовно — self-hosted, потрібен GPU для швидкості | Безкоштовно — self-hosted через HuggingFace |
| Коли обирати | Швидкий старт, англомовний або змішаний контент, мінімум інфраструктури | Мультимовний контент, кирилиця, hybrid search, конфіденційні дані | Англомовний retrieval, є GPU, потрібна висока якість на англійських бенчмарках |
Чому той самий текст дає різний результат у різних моделях
Три головні причини розходження результатів між моделями:
1. Різний training signal. OpenAI навчала модель на синтетичних парах від GPT-4 — це дає хорошу загальну якість, але деталі датасету закриті. BGE-M3 навчалась на відкритих 1.2M парах з явним мультимовним сигналом — тому краще на кирилиці. E5 використовує instruction-tuning: модель очікує prefix "query: " перед запитом і "passage: " перед документом. Якщо prefix не додати — якість падає на 5–15% навіть на англійському контенті.
2. Різне контекстне вікно. E5-large обробляє лише 512 токенів — довгий документ буде обрізаний, і хвостова частина просто зникне з вектора. OpenAI і BGE-M3 обробляють до 8K токенів, що дозволяє ембедити цілі статті без втрати інформації. Якщо ваші документи довші за 400 слів і ви використовуєте E5 — обов'язково потрібен chunking.
3. Різна геометрія простору. Кожна модель будує свій власний векторний простір. Вектор слова "договір" від OpenAI і вектор того ж слова від BGE-M3 — несумісні числа в несумісних просторах. Саме тому не можна змішувати вектори від різних моделей в одній Vector DB і не можна порівнювати їх між собою. Детально про це — у MTEB Leaderboard, де моделі порівнюються на стандартизованих бенчмарках.
📌 Embedding = координати у просторі сенсу
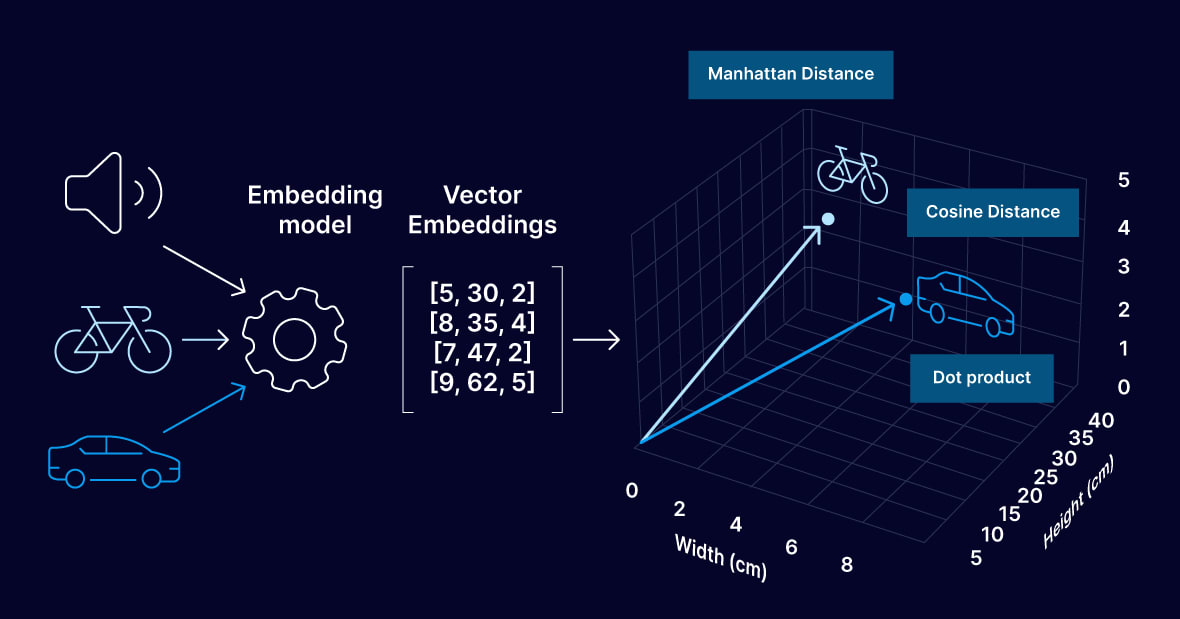
Embedding — це список чисел, наприклад: [0.21, -0.84, 0.03, 0.67, ...] — від 384 до 3072 чисел залежно від моделі. Кожен набір чисел — це точка у багатовимірному просторі. Слова зі схожим сенсом опиняються поруч у цьому просторі, слова з різним сенсом — далеко одне від одного.
Якщо звичайний GPS-координат — це дві числа (широта і довгота), то embedding — це GPS у просторі з тисячами вимірів, де кожна "координата" кодує якийсь аспект сенсу.
Давайте уявимо дуже спрощений простір — лише два виміри. Вісь X — наскільки слово пов'язане з живим світом. Вісь Y — наскільки воно пов'язане з рухом. Тоді:
- "юрист" → висока X (людина), низька Y (не про рух) → координата [0.9, 0.1]
- "кур'єр" → висока X, висока Y → [0.9, 0.8]
- "автомобіль" → низька X, висока Y → [0.1, 0.9]
- "ракета" → низька X, дуже висока Y → [0.05, 0.95]
У реальності вимірів не два, а сотні або тисячі — кожен кодує якийсь тонший аспект: емоційне забарвлення, синтаксичну роль, тематичну приналежність тощо. Ми не можемо їх інтерпретувати поодинці, але математика відстаней між точками у цьому просторі — працює бездоганно.
Як вимірюється схожість між векторами: Cosine Similarity
Відстань між двома векторами вимірюється не по прямій (евклідова відстань), а через кут між ними — так звана cosine similarity. Чим менший кут між двома векторами, тим більш семантично схожі слова або речення. "Договір" і "угода" дивляться майже в один бік у просторі сенсу — кут між ними малий, similarity висока. "Договір" і "ракета" — майже перпендикулярні, similarity близька до нуля.
Cosine similarity — стандарт де факто для більшості моделей і vector DB. Але є важливий нюанс, який я бачу в помилках на production: деякі моделі оптимізовані під іншу метрику — Dot Product (скалярний добуток). Наприклад, Gemini Embedding 2 від Google і частина моделей Cohere в певних режимах очікують саме Dot Product, а не Cosine. Якщо виставити невірну метрику у вашій Vector DB — результати пошуку будуть гіршими навіть при правильній моделі. Завжди перевіряйте документацію моделі перед налаштуванням distance у ChromaDB, Qdrant або pgvector.
Лайфхак: нормалізація векторів пришвидшує пошук
Є практичний трюк, який варто знати. Якщо нормалізувати вектори до одиничної довжини (unit length) — тобто привести кожен вектор до норми рівної 1 — то Cosine Similarity стає математично еквівалентна Dot Product. А Dot Product обчислюється швидше: це просто сума добутків елементів, без додаткового ділення на норми. Багато vector DB (Qdrant, pgvector з vector_cosine_ops) роблять це автоматично — але якщо ви використовуєте власний пошук або FAISS, нормалізуйте вектори перед збереженням і отримаєте приріст швидкості без жодної втрати якості.
Детально про те, як cosine similarity і Dot Product використовуються у пошуку на практиці — у статті Vector Search для початківців.
- ✔️ Embedding — список чисел від 384 до 3072 значень
- ✔️ Схожість вимірюється кутом між векторами (Cosine Similarity) — але перевіряйте документацію моделі: деякі оптимізовані під Dot Product
- ✔️ Нормалізовані вектори: Cosine = Dot Product → швидший пошук без втрати якості
Висновок: Embedding перетворює абстрактний "сенс" на конкретну геометрію — і саме це дозволяє AI порівнювати значення текстів математично. Але правильний вибір метрики схожості — не менш важливий ніж сама модель.
📌 Розділ 3. Звідки беруться ці числа? Як модель навчилась кодувати сенс
Embedding-модель навчається на мільярдах текстових пар методом контрастного навчання: речення зі схожим сенсом отримують близькі вектори, речення з різним сенсом — далекі. Ніхто не вказує моделі вручну що "розірвання договору" схоже на "припинення угоди" — вона сама виводить це зі статистики мільярдів реальних текстів.
Модель не читає словник і не знає граматики. Вона читає мільярди речень — і вчиться, які слова і фрази живуть поруч, а які ніколи не зустрічаються разом.
За цим стоїть ідея дистрибутивної семантики, сформульована лінгвістом Джоном Ферсом ще у 1957 році: "Слово визначається компанією, в якій воно зустрічається." Якщо два слова постійно з'являються в схожих контекстах — вони, скоріш за все, мають схожий сенс. Саме цей принцип став основою для Word2Vec (Google, 2013) — першої масштабної моделі, що перетворила слова на вектори через статистику контекстів, а не через ручну розмітку. Оригінальна стаття Mikolov et al., 2013 — arXiv:1301.3781 .
Від Word2Vec до сучасного контрастного навчання
Word2Vec навчався просто: для кожного слова — передбачити сусідні слова у вікні з 5–10 токенів. Якщо "юрист" і "адвокат" часто зустрічаються в схожих реченнях — їхні вектори зближуються. Це вже працювало. Але у Word2Vec кожне слово мало один вектор незалежно від контексту: слово "ключ" отримувало однаковий вектор у реченні "ключ від замка" і "ключ до успіху" — хоча сенси різні.
Сучасні моделі (BERT від Google, 2018) вирішили цю проблему: вектор тепер залежить від усього речення, а не від статичного словника. Слово "ключ" отримує різний вектор залежно від того, що стоїть поруч. Це стало можливим завдяки архітектурі трансформерів і механізму self-attention. BERT: Pre-training of Deep Bidirectional Transformers — arXiv:1810.04805 .
Як виглядає контрастне навчання на практиці
Сучасний стандарт навчання embedding-моделей — контрастне навчання (contrastive learning), зокрема підхід SimCSE і його похідні. Модель отримує три речення одночасно:
- Anchor (якір): "Як скасувати підписку на сервіс?"
- Positive (позитивний приклад): "Інструкція з відмови від тарифного плану" — має бути близько до anchor
- Negative (негативний приклад): "Рецепт традиційного борщу" — має бути далеко від anchor
Функція втрат (contrastive loss або InfoNCE loss) штрафує модель якщо вектор positive далекий від anchor — або якщо вектор negative занадто близький. Через мільярди таких трійок модель навчається будувати простір, де семантична близькість відображається геометричною близькістю. SimCSE: Simple Contrastive Learning of Sentence Embeddings — arXiv:2104.08821 .
Де беруть пари для навчання? Переважно з трьох джерел: природні пари питання–відповідь (NLI-датасети, Stack Overflow, Reddit), паралельні переклади (для мультимовних моделей) і синтетичні пари згенеровані LLM. Наприклад, для навчання text-embedding-3-small OpenAI використовував синтетичні дані, згенеровані GPT-4, як описано у блозі OpenAI про нові embedding-моделі .
Що модель реально кодує у векторі
Дослідники з'ясували, що різні виміри вектора кодують різні аспекти сенсу — але не так прямолінійно як хотілось би. Один вимір може відповідати за "юридичний контекст", інший — за "емоційний тон", третій — за "синтаксичну роль у реченні". Але виміри не ізольовані: сенс кодується розподілено по всіх числах одночасно. Це означає що жодне окреме число у векторі не має людськи-інтерпретованого значення — тільки вся комбінація разом.
Відомий приклад з Word2Vec, який зберігся і в сучасних моделях: вектор("король") − вектор("чоловік") + вектор("жінка") ≈ вектор("королева"). Арифметика сенсів працює у просторі векторів — це одне з найяскравіших підтверджень того що модель справді вловила структуру мови, а не просто запам'ятала слова.
Чому мультимовні моделі розуміють "договір" і "contract" як одне
Мультимовні embedding-моделі (Cohere embed-v4, BGE-M3, multilingual-e5) навчались одночасно на текстах десятками мовами і на паралельних корпусах перекладів. Через це "договір" (українська) і "contract" (англійська) опиняються у суміжних точках одного простору — бо вони зустрічались у схожих контекстах і були зв'язані через переклади.
Це відкриває cross-lingual search: запит українською знаходить документи англійською без жодного перекладу. На практиці — якщо ваша база знань наповнена переважно англійськими документами, а користувачі пишуть українською, якісна мультимовна модель закриє цей розрив. У нашому кейсі з WebsCraft це була реальна проблема: частина контенту існує тільки однією мовою, а запити приходять іншою. BGE-M3 справляється з цим значно краще за OpenAI small, де якість на кирилиці помітно нижча ніж на латиниці — що підтверджують і результати MTEB Multilingual Leaderboard .
- ✔️ Дистрибутивна семантика: сенс = контекст співіснування
- ✔️ Контрастне навчання: позитивні пари зближуються, негативні — розходяться
- ✔️ Сучасні моделі (BERT і далі): вектор залежить від контексту, а не статичний
- ✔️ Мультимовні моделі: переклади в одному просторі → cross-lingual пошук без перекладача
Висновок: Числа у векторі — не довільні і не запрограмовані вручну. Вони є результатом навчання на мільярдах прикладів і відображають реальну статистичну структуру мови — саме тому вони так добре вловлюють сенс.