Haben Sie sich jemals gefragt, warum ChatGPT eine Verbindung zwischen "Auto" und "Wagen" findet – obwohl es unterschiedliche Wörter sind? Oder warum ein RAG-System das richtige Dokument findet, auch wenn die Anfrage kein einziges Wort aus dem Text enthält? Spoiler: Dahinter steckt eine Technologie – Embedding. Es ist eine Methode, jeden Text in eine Reihe von Zahlen umzuwandeln, sodass Texte mit ähnlicher Bedeutung ähnliche Zahlen haben.
⚡ Kurz gesagt
- ✅ Embedding ist kein Wort, sondern eine Zahl: Jedes Wort oder jeder Satz wird in einen Vektor aus Hunderten von Zahlen umgewandelt, der seine Bedeutung kodiert
- ✅ Ähnliche Bedeutung = ähnliche Zahlen: "Katze" und "Kätzchen" haben ähnliche Vektoren, "Katze" und "Rakete" – weit entfernte
- ✅ Ohne Embeddings gibt es kein RAG, keine semantische Suche und keine Empfehlungen: Sie sind das Fundament der meisten modernen KI-Systeme
- 🎯 Sie erhalten: ein klares Verständnis davon, was Embedding ist, wie es trainiert wird, wo es verwendet wird und wann es nicht geeignet ist
- 👇 Unten finden Sie Erklärungen mit Analogien, Diagrammen und praktischen Schlussfolgerungen ohne unnötige Theorie
📚 Inhalt des Artikels
- 📌 Abschnitt 1. Von Tokens zu Zahlen: Warum KI nicht direkt mit Wörtern arbeiten kann
- 📌 Abschnitt 2. Embedding = Koordinaten im Bedeutungsraum
- 📌 Abschnitt 3. Woher kommen diese Zahlen? Wie das Modell gelernt hat, Bedeutung zu kodieren
- 📌 Abschnitt 4. Dimensionalität: Warum 768 ≠ 1536 und was das in der Praxis bedeutet
- 📌 Abschnitt 5. Wo Embeddings verwendet werden: 5 reale Anwendungen
- 📌 Abschnitt 6. Grenzen von Embeddings: Wann sie nicht helfen
- 💼 Abschnitt 7. Modelle 2026: Wo man anfangen soll
- ❓ Häufig gestellte Fragen (FAQ)
- ✅ Schlussfolgerungen
🎯 Von Tokens zu Zahlen: Warum KI nicht direkt mit Wörtern arbeiten kann
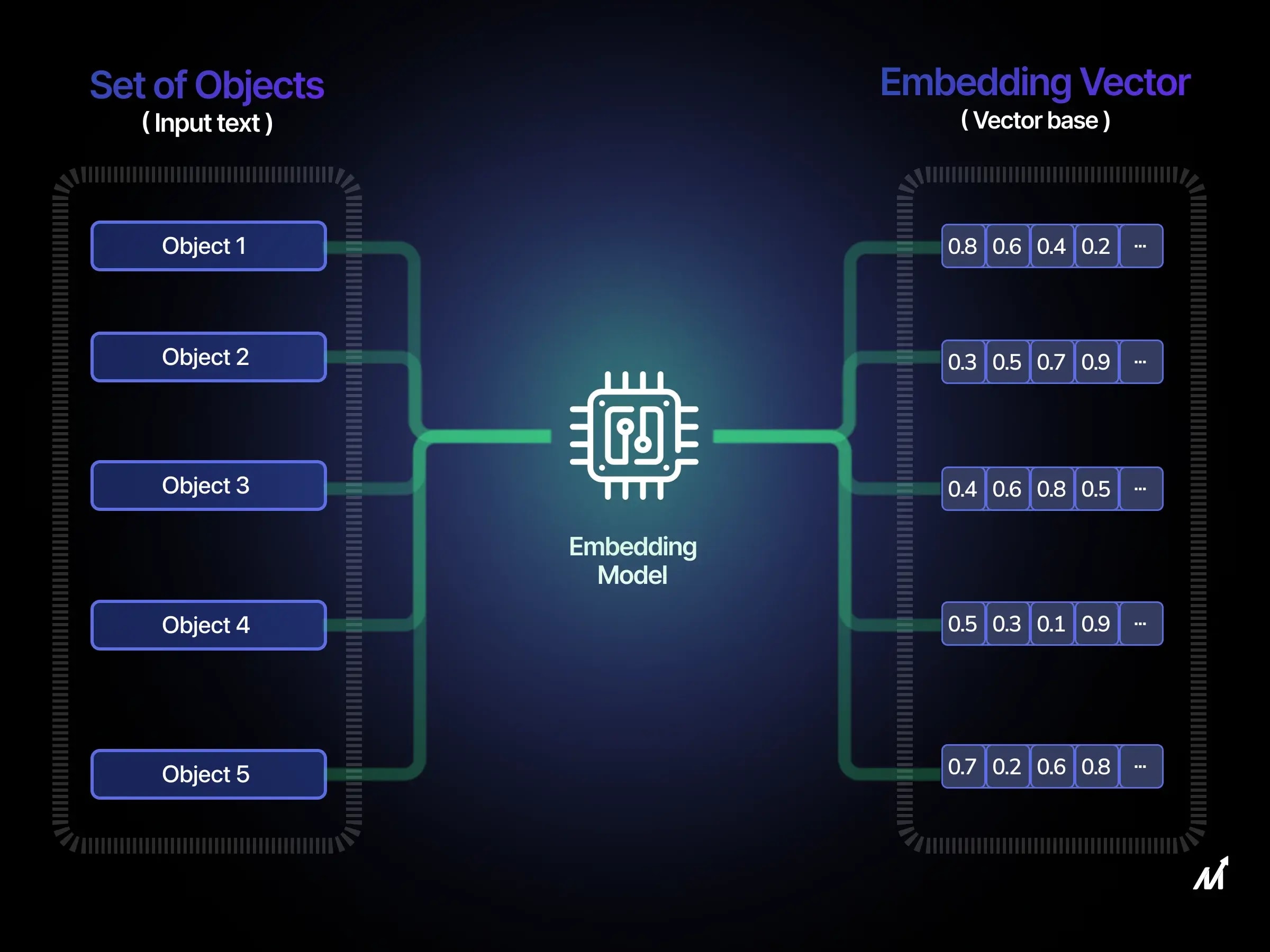
Ein neuronales Netz ist eine mathematische Funktion. Es kann keine Wörter als solche verarbeiten, weil es nicht weiß, was "Katze" oder "Vertrag" bedeutet. Es kann nur Zahlen multiplizieren, addieren und transformieren. Deshalb muss jedes Wort (oder Token) zuerst in einen numerischen Vektor umgewandelt werden – und genau das macht ein Embedding-Modell.
Ein Token ist eine Texteinheit, die die KI sieht. Ein Embedding ist das, was dieses Token *bedeutet*, in Zahlen ausgedrückt.
Wenn Sie den Artikel über Tokens gelesen haben, wissen Sie: KI teilt Text in Fragmente (Tokens) auf – das können ganze Wörter, Wortteile oder sogar einzelne Zeichen sein. Aber ein Token ist noch keine Bedeutung. Es ist nur eine Aufteilungseinheit.
Embedding ist der nächste Schritt. Jedes Token erhält seinen einzigartigen numerischen "Fingerabdruck" – einen Vektor. Dieser Vektor kodiert nicht die Schreibweise des Wortes, sondern seine Bedeutung im Kontext der Sprache. Deshalb sind "Auto" und "Wagen" unterschiedliche Tokens, aber ihre Vektoren werden sehr nah beieinander liegen.
Analogie: Wörterbuch vs. Stadtplan
Stellen Sie sich zwei Möglichkeiten vor, ein Wort zu beschreiben. Die erste – ein Wörterbuch: "Katze – ein Haustier aus der Familie der Feliden". Das ist nützlich für Menschen, aber nutzlos für die Mathematik. Die zweite – eine Karte: In der Stadt der Konzepte steht "Katze" neben "Kätzchen", "Pfote", "Schnurren" – und weit weg von "Rakete" oder "Buchhaltung". Ein Embedding ist genau wie eine Karte, auf der die Position jedes Wortes durch sein semantisches Umfeld bestimmt wird. Dokumentation von OpenAI Embeddings beschreibt, wie Text in einen numerischen Vektor in einem hochdimensionalen Raum umgewandelt wird.
- ✔️ Token = Texteinheit (was geschrieben ist)
- ✔️ Embedding = numerischer Vektor (was es bedeutet)
- ✔️ Ohne die Umwandlung von Text in Zahlen kann kein neuronales Netz damit arbeiten
Fazit: Embedding ist die unverzichtbare Brücke zwischen dem Text, den ein Mensch versteht, und den Zahlen, mit denen eine KI arbeitet.
Warum verschiedene Modelle unterschiedliche Ergebnisse liefern: Vergleichstabelle
| Parameter | OpenAI text-embedding-3-small | BGE-M3 (BAAI) | E5-large (Microsoft) |
|---|---|---|---|
| Training signal (worauf trainiert) |
Synthetische Paare, generiert von GPT-4 + NLI-Datensätze + Web-Korpus. Geschlossener Datensatz, Details nicht offengelegt | Offener Datensatz: 1,2 Mio. Paare aus über 570 Quellen – MS MARCO, NLI, parallele Übersetzungen von 100+ Sprachen, Code | Web-Korpus + NLI-Datensätze von Microsoft. Instruction-Tuning: Vor jeder Anfrage wird eine Anweisung wie "query: " oder "passage: " hinzugefügt |
| Kontextfenster (max. Tokens) |
8.191 Tokens – ausreichend für lange Artikel und Dokumente | 8.192 Tokens – ähnlich, plus Unterstützung für lange Anfragen bei Hybrid-Suche | 512 Tokens – Beschränkung für lange Dokumente, Chunking erforderlich |
| Architektur | Transformer-Encoder, Details nicht offengelegt. Unterstützt Matryoshka (MRL): kann auf 256 Dimensionen gekürzt werden | XLM-RoBERTa als Basismodell. Einzigartig: Generiert gleichzeitig dichte + spärliche + ColBERT-Vektoren | Transformer-Encoder auf Basis von DeBERTa. Instruction-aware: Ergebnis hängt vom Prefix-Befehl ab |
| Vektor-Dimensionalität | 1.536 (oder weniger durch MRL) | 1.024 | 1.024 |
| Ähnlichkeitsmetrik | Cosine Similarity (oder Dot Product nach Normalisierung) | Cosine Similarity für dense, Inner Product für sparse | Cosine Similarity – aber unbedingt Prefix hinzufügen, sonst sinkt die Qualität |
| Multilingualität | Unterstützt, aber die Qualität auf Kyrillisch ist niedriger als auf Lateinisch | 100+ Sprachen, gleiche Qualität – führend in den multilingualen MTEB-Benchmarks | Hauptsächlich Englisch. Multilinguale Version – separates Modell multilingual-e5 |
| Hybrid-Suche | Nur dichte Vektoren – für Hybrid wird ein separates BM25 benötigt | Native Hybrid: dichte + spärliche Vektoren in einem Modell ohne zusätzliche Tools | Nur dichte – Hybrid über separates BM25 oder Elasticsearch |
| Preis | 0,02 $/1 Mio. Tokens über API | Kostenlos – Self-hosted, GPU für Geschwindigkeit erforderlich | Kostenlos – Self-hosted über HuggingFace |
| Wann wählen | Schneller Start, englisch- oder gemischtsprachiger Inhalt, minimale Infrastruktur | Multilinguale Inhalte, Kyrillisch, Hybrid-Suche, vertrauliche Daten | Englischsprachiges Retrieval, GPU vorhanden, hohe Qualität bei englischen Benchmarks erforderlich |
Warum derselbe Text bei verschiedenen Modellen unterschiedliche Ergebnisse liefert
Drei Hauptgründe für die Abweichung der Ergebnisse zwischen den Modellen:
1. Unterschiedliches Trainingssignal. OpenAI hat das Modell auf synthetischen Paaren von GPT-4 trainiert – das liefert eine gute Gesamtqualität, aber die Details des Datensatzes sind nicht offengelegt. BGE-M3 wurde auf offenen 1,2 Mio. Paaren mit einem expliziten multilingualen Signal trainiert – daher besser auf Kyrillisch. E5 verwendet Instruction-Tuning: Das Modell erwartet den Prefix "query: " vor der Anfrage und "passage: " vor dem Dokument. Wenn der Prefix nicht hinzugefügt wird, sinkt die Qualität um 5–15 % selbst bei englischsprachigen Inhalten.
2. Unterschiedliches Kontextfenster. E5-large verarbeitet nur 512 Tokens – ein langes Dokument wird abgeschnitten, und der hintere Teil verschwindet einfach aus dem Vektor. OpenAI und BGE-M3 verarbeiten bis zu 8K Tokens, was es ermöglicht, ganze Artikel ohne Informationsverlust zu embedden. Wenn Ihre Dokumente länger als 400 Wörter sind und Sie E5 verwenden, ist Chunking unbedingt erforderlich.
3. Unterschiedliche Raumgeometrie. Jedes Modell baut seinen eigenen Vektorraum auf. Der Vektor des Wortes "Vertrag" von OpenAI und der Vektor desselben Wortes von BGE-M3 sind inkompatible Zahlen in inkompatiblen Räumen. Deshalb dürfen Vektoren verschiedener Modelle nicht in derselben Vektor-DB gemischt und nicht miteinander verglichen werden. Mehr dazu – im MTEB Leaderboard, wo Modelle auf standardisierten Benchmarks verglichen werden.
📌 Embedding = Koordinaten im Bedeutungsraum
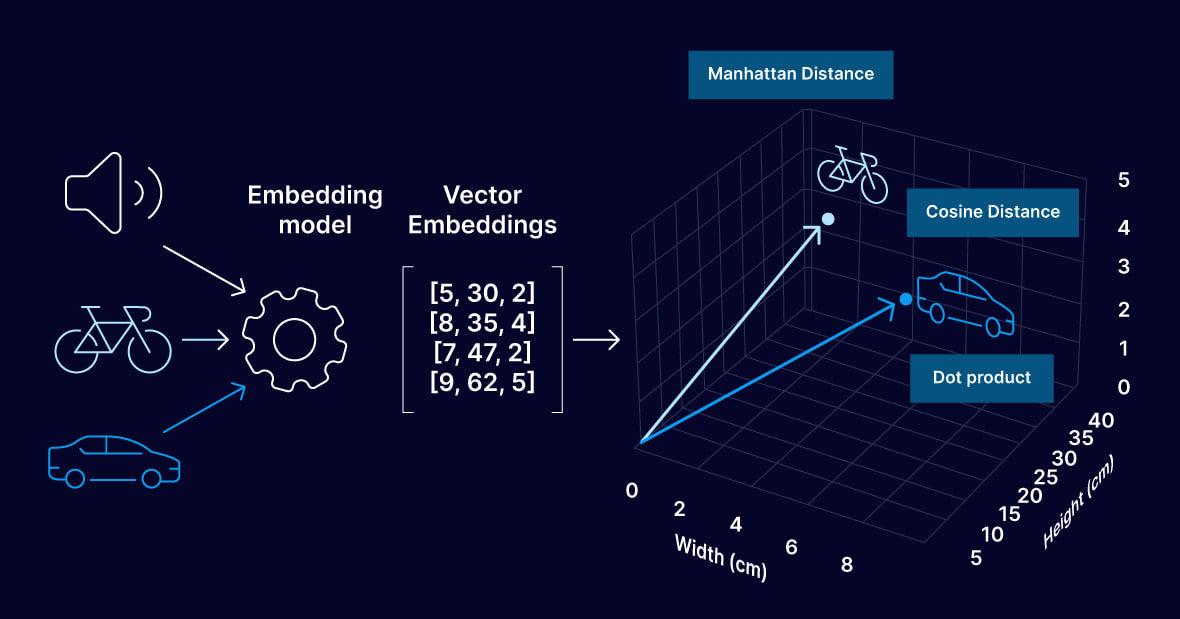
Ein Embedding ist eine Liste von Zahlen, z. B.: [0,21, -0,84, 0,03, 0,67, ...] – von 384 bis 3.072 Zahlen, je nach Modell. Jede Zahlenkombination ist ein Punkt in einem mehrdimensionalen Raum. Wörter mit ähnlicher Bedeutung liegen in diesem Raum nahe beieinander, Wörter mit unterschiedlicher Bedeutung – weit voneinander entfernt.
Wenn eine normale GPS-Koordinate zwei Zahlen sind (Breite und Länge), dann ist ein Embedding ein GPS in einem Raum mit Tausenden von Dimensionen, wobei jede "Koordinate" einen Aspekt der Bedeutung kodiert.
Stellen wir uns einen sehr vereinfachten Raum vor – nur zwei Dimensionen. Die X-Achse – wie stark das Wort mit der lebendigen Welt verbunden ist. Die Y-Achse – wie stark es mit Bewegung verbunden ist. Dann:
- "Anwalt" → hohes X (Mensch), niedriges Y (nicht über Bewegung) → Koordinate [0,9, 0,1]
- "Kurier" → hohes X, hohes Y → [0,9, 0,8]
- "Auto" → niedriges X, hohes Y → [0,1, 0,9]
- "Rakete" → niedriges X, sehr hohes Y → [0,05, 0,95]
In Wirklichkeit gibt es nicht zwei, sondern Hunderte oder Tausende von Dimensionen – jede kodiert einen feineren Aspekt: emotionale Färbung, syntaktische Rolle, thematische Zugehörigkeit usw. Wir können sie nicht einzeln interpretieren, aber die Mathematik der Abstände zwischen den Punkten in diesem Raum funktioniert einwandfrei.
Wie die Ähnlichkeit zwischen Vektoren gemessen wird: Cosine Similarity
Der Abstand zwischen zwei Vektoren wird nicht geradlinig (euklidischer Abstand) gemessen, sondern über den Winkel zwischen ihnen – die sogenannte Cosine Similarity. Je kleiner der Winkel zwischen zwei Vektoren ist, desto semantisch ähnlicher sind die Wörter oder Sätze. "Vertrag" und "Vereinbarung" zeigen im Bedeutungsraum fast in die gleiche Richtung – der Winkel zwischen ihnen ist klein, die Similarity hoch. "Vertrag" und "Rakete" – fast senkrecht, die Similarity liegt nahe Null.
Cosine Similarity ist der De-facto-Standard für die meisten Modelle und Vektor-Datenbanken. Aber es gibt einen wichtigen Punkt, den ich bei Fehlern in der Produktion sehe: einige Modelle sind für eine andere Metrik optimiert – Dot Product (Skalarprodukt). Zum Beispiel erwarten Gemini Embedding 2 von Google und einige Cohere-Modelle in bestimmten Modi genau Dot Product und nicht Cosine. Wenn Sie die falsche Metrik in Ihrer Vektor-Datenbank einstellen, werden die Suchergebnisse schlechter, selbst bei einem korrekten Modell. Überprüfen Sie immer die Dokumentation des Modells, bevor Sie distance in ChromaDB, Qdrant oder pgvector einstellen.
Lifehack: Vektornormalisierung beschleunigt die Suche
Es gibt einen praktischen Trick, den man kennen sollte. Wenn man Vektoren auf Einheitslänge (unit length) normalisiert – also jeden Vektor auf eine Norm von 1 bringt –, dann wird die Cosine Similarity mathematisch äquivalent zum Dot Product. Und Dot Product wird schneller berechnet: Es ist einfach die Summe der Produkte der Elemente, ohne zusätzliche Division durch die Normen. Viele Vektor-Datenbanken (Qdrant, pgvector mit vector_cosine_ops) machen das automatisch – aber wenn Sie eine eigene Suche oder FAISS verwenden, normalisieren Sie die Vektoren vor dem Speichern und erhalten einen Geschwindigkeitszuwachs ohne Qualitätsverlust.
Mehr darüber, wie Cosine Similarity und Dot Product in der Praxis bei der Suche verwendet werden – im Artikel Vector Search für Anfänger.
- ✔️ Embedding – eine Zahlenliste von 384 bis 3.072 Werten
- ✔️ Ähnlichkeit wird durch den Winkel zwischen Vektoren gemessen (Cosine Similarity) – aber prüfen Sie die Dokumentation des Modells: einige sind für Dot Product optimiert
- ✔️ Normalisierte Vektoren: Cosine = Dot Product → schnellere Suche ohne Qualitätsverlust
Fazit: Embedding wandelt abstrakte "Bedeutung" in konkrete Geometrie um – und genau das ermöglicht es der KI, die Bedeutung von Texten mathematisch zu vergleichen. Aber die richtige Wahl der Ähnlichkeitsmetrik ist nicht weniger wichtig als das Modell selbst.
📌 Abschnitt 3. Woher kommen diese Zahlen? Wie das Modell gelernt hat, Bedeutung zu kodieren
Ein Embedding-Modell wird auf Milliarden von Textpaaren durch kontrastives Lernen trainiert: Sätze mit ähnlicher Bedeutung erhalten nahe Vektoren, Sätze mit unterschiedlicher Bedeutung – weit entfernte. Niemand sagt dem Modell manuell, dass "Vertragsauflösung" ähnlich wie "Vereinbarungsbeendigung" ist – es leitet dies selbst aus der Statistik von Milliarden realer Texte ab.
Das Modell liest kein Wörterbuch und kennt keine Grammatik. Es liest Milliarden von Sätzen – und lernt, welche Wörter und Phrasen nebeneinander existieren und welche niemals zusammen vorkommen.
Dahinter steckt die Idee der distributiven Semantik, die der Linguist John Firth bereits 1957 formulierte: "Ein Wort wird durch die Gesellschaft definiert, in der es vorkommt." Wenn zwei Wörter häufig in ähnlichen Kontexten vorkommen – haben sie wahrscheinlich eine ähnliche Bedeutung. Genau dieser Grundsatz wurde zur Grundlage von Word2Vec (Google, 2013) – dem ersten groß angelegten Modell, das Wörter durch die Statistik von Kontexten und nicht durch manuelle Annotation in Vektoren umwandelte. Originalartikel von Mikolov et al., 2013 – arXiv:1301.3781 .
Von Word2Vec zu modernem kontrastivem Lernen
Word2Vec wurde einfach trainiert: Für jedes Wort – benachbarte Wörter in einem Fenster von 5–10 Tokens vorhersagen. Wenn "Anwalt" und "Rechtsanwalt" oft in ähnlichen Sätzen vorkommen – nähern sich ihre Vektoren an. Das funktionierte bereits. Aber bei Word2Vec hatte jedes Wort einen *einzigen* Vektor unabhängig vom Kontext: das Wort "Schlüssel" erhielt den gleichen Vektor im Satz "Schlüssel zum Schloss" und "Schlüssel zum Erfolg" – obwohl die Bedeutungen unterschiedlich sind.
Moderne Modelle (BERT von Google, 2018) lösten dieses Problem: Der Vektor hängt nun vom gesamten Satz ab, nicht von einem statischen Wörterbuch. Das Wort "Schlüssel" erhält einen anderen Vektor, je nachdem, was daneben steht. Dies wurde durch die Transformer-Architektur und den Self-Attention-Mechanismus ermöglicht. BERT: Pre-training of Deep Bidirectional Transformers – arXiv:1810.04805 .
Wie kontrastives Lernen in der Praxis aussieht
Der moderne Standard für das Training von Embedding-Modellen ist kontrastives Lernen (contrastive learning), insbesondere der Ansatz SimCSE und seine Derivate. Das Modell erhält drei Sätze gleichzeitig:
- Anchor (Anker): "Wie kann ich mein Abonnement für den Dienst kündigen?"
- Positive (positives Beispiel): "Anleitung zur Kündigung des Tarifplans" – sollte dem Anker nahe sein
- Negative (negatives Beispiel): "Rezept für traditionellen Borschtsch" – sollte weit vom Anker entfernt sein
Die Verlustfunktion (contrastive loss oder InfoNCE loss) bestraft das Modell, wenn der Vektor des positiven Beispiels weit vom Anker entfernt ist – oder wenn der Vektor des negativen Beispiels zu nah ist. Durch Milliarden solcher Tripletts lernt das Modell, einen Raum aufzubauen, in dem semantische Nähe durch geometrische Nähe dargestellt wird. SimCSE: Simple Contrastive Learning of Sentence Embeddings – arXiv:2104.08821 .
Woher kommen die Paare für das Training? Hauptsächlich aus drei Quellen: natürliche Frage-Antwort-Paare (NLI-Datensätze, Stack Overflow, Reddit), parallele Übersetzungen (für mehrsprachige Modelle) und synthetische Paare, die von LLMs generiert wurden. Zum Beispiel verwendete OpenAI für das Training von text-embedding-3-small synthetische Daten, die von GPT-4 generiert wurden, wie im Blog von OpenAI über neue Embedding-Modelle beschrieben.
Was das Modell tatsächlich im Vektor kodiert
Forscher haben herausgefunden, dass verschiedene Dimensionen des Vektors verschiedene Aspekte der Bedeutung kodieren – aber nicht so geradlinig, wie man es sich wünschen würde. Eine Dimension kann für den "juristischen Kontext" zuständig sein, eine andere – für den "emotionalen Ton", eine dritte – für die "syntaktische Rolle im Satz". Aber die Dimensionen sind nicht isoliert: Die Bedeutung wird verteilt über alle Zahlen gleichzeitig kodiert. Das bedeutet, dass keine einzelne Zahl im Vektor eine menschlich interpretierbare Bedeutung hat – nur die gesamte Kombination zusammen.
Ein bekanntes Beispiel aus Word2Vec, das auch in modernen Modellen erhalten geblieben ist: Vektor("König") − Vektor("Mann") + Vektor("Frau") ≈ Vektor("Königin"). Die Arithmetik der Bedeutungen funktioniert im Vektorraum – das ist einer der deutlichsten Beweise dafür, dass das Modell die Struktur der Sprache wirklich erfasst hat und nicht nur Wörter auswendig gelernt hat.
Warum mehrsprachige Modelle "Vertrag" und "contract" als dasselbe verstehen
Mehrsprachige Embedding-Modelle (Cohere embed-v4, BGE-M3, multilingual-e5) wurden gleichzeitig auf Texten in Dutzenden von Sprachen und auf parallelen Übersetzungskorpora trainiert. Dadurch landen "Vertrag" (Ukrainisch) und "contract" (Englisch) in benachbarten Punkten desselben Raumes – weil sie in ähnlichen Kontexten vorkamen und durch Übersetzungen verbunden waren.
Dies ermöglicht Cross-Lingual Search: Eine Anfrage auf Ukrainisch findet Dokumente auf Englisch, ohne dass eine Übersetzung erforderlich ist. In der Praxis – wenn Ihre Wissensbasis hauptsächlich aus englischen Dokumenten besteht und Benutzer auf Ukrainisch schreiben, schließt ein qualitativ hochwertiges mehrsprachiges Modell diese Lücke. In unserem Fall mit WebsCraft war dies ein echtes Problem: Ein Teil des Inhalts existiert nur in einer Sprache, und Anfragen kommen in einer anderen. BGE-M3 bewältigt dies deutlich besser als OpenAI small, wo die Qualität auf Kyrillisch merklich niedriger ist als auf Lateinisch – was auch die Ergebnisse des MTEB Multilingual Leaderboard bestätigen.
- ✔️ Distributive Semantik: Bedeutung = Koexistenzkontext
- ✔️ Kontrastives Lernen: positive Paare nähern sich an, negative – entfernen sich
- ✔️ Moderne Modelle (BERT und weiter): Vektor hängt vom Kontext ab, nicht statisch
- ✔️ Mehrsprachige Modelle: Übersetzungen in einem Raum → Cross-Lingual-Suche ohne Übersetzer
Fazit: Die Zahlen im Vektor sind nicht willkürlich und nicht manuell programmiert. Sie sind das Ergebnis des Trainings auf Milliarden von Beispielen und spiegeln die tatsächliche statistische Struktur der Sprache wider – deshalb erfassen sie die Bedeutung so gut.