Have you ever wondered why ChatGPT finds a connection between "car" and "automobile" — even though they are different words? Or why a RAG system finds the right document even if the query doesn't contain a single word from the text? Spoiler: one technology stands behind it — embedding. It's a way to convert any text into a set of numbers so that texts with similar meanings have similar numbers.
⚡ TL;DR
- ✅ Embedding is not a word, but a number: each word or sentence is converted into a vector of hundreds of numbers that encodes its meaning
- ✅ Similar meaning = similar numbers: "cat" and "kitten" have close vectors, "cat" and "rocket" have distant ones
- ✅ No RAG, semantic search, or recommendations without embeddings: it's the foundation of most modern AI systems
- 🎯 You will get: a clear understanding of what embedding is, how it's trained, where it's used, and when it's not suitable
- 👇 Below is an explanation with analogies, diagrams, and practical takeaways without unnecessary theory
📚 Article Content
- 📌 Section 1. From tokens to numbers: why AI cannot work with words directly
- 📌 Section 2. Embedding = coordinates in the space of meaning
- 📌 Section 3. Where do these numbers come from? How the model learned to encode meaning
- 📌 Section 4. Dimensionality: why 768 ≠ 1536 and what it means in practice
- 📌 Section 5. Where embeddings are used: 5 real-world applications
- 📌 Section 6. Limitations of embeddings: when they won't help
- 💼 Section 7. Models of 2026: where to start
- ❓ Frequently Asked Questions (FAQ)
- ✅ Conclusions
🎯 From tokens to numbers: why AI cannot work with words directly
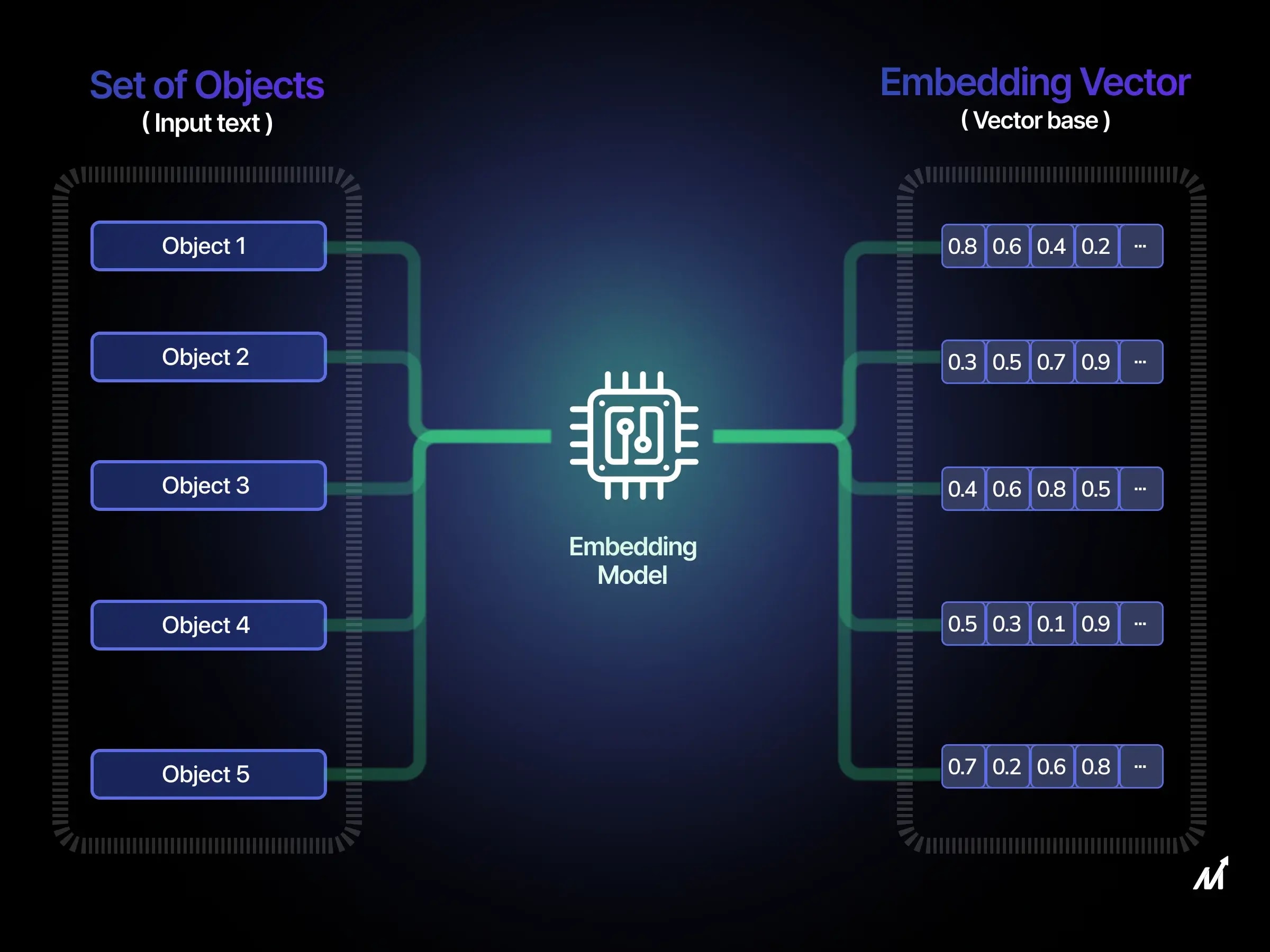
A neural network is a mathematical function. It cannot process words as they are, because it doesn't know what "cat" or "contract" means. It only knows how to multiply, add, and transform numbers. Therefore, each word (or token) must first be converted into a numerical vector — and this is exactly what an embedding model does.
A token is a unit of text that the AI sees. An embedding is what that token *means*, written in numbers.
If you've read the article about tokens, you know: AI divides text into fragments (tokens) — these can be whole words, parts of words, or even individual characters. But a token is not yet meaning. It's just a unit of segmentation.
Embedding is the next step. Each token gets its unique numerical "fingerprint" — a vector. This vector encodes not the spelling of the word, but its meaning in the context of language. That's why "car" and "automobile" are different tokens, but their vectors will be very close.
Analogy: dictionary vs. city map
Imagine two ways to describe a word. The first is a dictionary: "cat — a domestic animal of the feline family." This is useful for humans, but useless for mathematics. The second is a map: in the city of concepts, "cat" is located next to "kitten," "paw," "purring" — and far from "rocket" or "accounting." An embedding is precisely a map where the position of each word is determined by its semantic neighborhood. OpenAI Embeddings documentation on how to convert text into a numerical vector in a high-dimensional space.
- ✔️ Token = unit of text (what is written)
- ✔️ Embedding = numerical vector (what it means)
- ✔️ Without converting text to numbers — no neural network can work with it
Conclusion: Embedding is the essential bridge between text that humans understand and numbers that AI works with.
Why different models give different results: comparison table
| Parameter | OpenAI text-embedding-3-small | BGE-M3 (BAAI) | E5-large (Microsoft) |
|---|---|---|---|
| Training signal (what it was trained on) |
Synthetic pairs generated by GPT-4 + NLI datasets + web corpus. Closed dataset, details not disclosed | Open dataset: 1.2M pairs from 570+ sources — MS MARCO, NLI, parallel translations of 100+ languages, code | Web corpus + Microsoft NLI datasets. Instruction-tuning: an instruction like "query: " or "passage: " is added before each query |
| Context window (max tokens) |
8,191 tokens — enough for long articles and documents | 8,192 tokens — similarly, plus support for long queries in hybrid search | 512 tokens — limitation for long documents, requires chunking |
| Architecture | Transformer encoder, details closed. Supports Matryoshka (MRL): can be truncated to 256 dimensions | XLM-RoBERTa as a base model. Uniqueness: simultaneously generates dense + sparse + ColBERT vectors | Transformer encoder based on DeBERTa. Instruction-aware: the result depends on the prefix instruction |
| Vector dimensionality | 1,536 (or less via MRL) | 1,024 | 1,024 |
| Similarity metric | Cosine Similarity (or Dot Product after normalization) | Cosine Similarity for dense, inner product for sparse | Cosine Similarity — but a prefix must be added, otherwise quality drops |
| Multilingualism | Supported, but quality on Cyrillic is lower than on Latin | 100+ languages, same quality — leader of MTEB multilingual benchmarks | Primarily English. Multilingual version — separate model multilingual-e5 |
| Hybrid search | Dense vectors only — hybrid requires a separate BM25 | Native hybrid: dense + sparse in one model without additional tools | Dense only — hybrid via separate BM25 or Elasticsearch |
| Price | $0.02 / 1M tokens via API | Free — self-hosted, requires GPU for speed | Free — self-hosted via HuggingFace |
| When to choose | Quick start, English or mixed content, minimal infrastructure | Multilingual content, Cyrillic, hybrid search, confidential data | English retrieval, have GPU, need high quality on English benchmarks |
Why the same text yields different results in different models
There are three main reasons for discrepancies in results between models:
1. Different training signal. OpenAI trained the model on synthetic pairs from GPT-4 — this provides good general quality, but the dataset details are closed. BGE-M3 was trained on an open 1.2M pair dataset with an explicit multilingual signal — hence better on Cyrillic. E5 uses instruction-tuning: the model expects the prefix "query: " before the query and "passage: " before the document. If the prefix is not added — quality drops by 5–15% even on English content.
2. Different context window. E5-large processes only 512 tokens — a long document will be truncated, and the tail part will simply disappear from the vector. OpenAI and BGE-M3 process up to 8K tokens, allowing entire articles to be embedded without information loss. If your documents are longer than 400 words and you use E5 — chunking is definitely required.
3. Different space geometry. Each model builds its own vector space. The vector for the word "contract" from OpenAI and the vector for the same word from BGE-M3 are incompatible numbers in incompatible spaces. That's why you cannot mix vectors from different models in the same Vector DB and cannot compare them. More details on this are in the MTEB Leaderboard, where models are compared on standardized benchmarks.
📌 Embedding = coordinates in the space of meaning
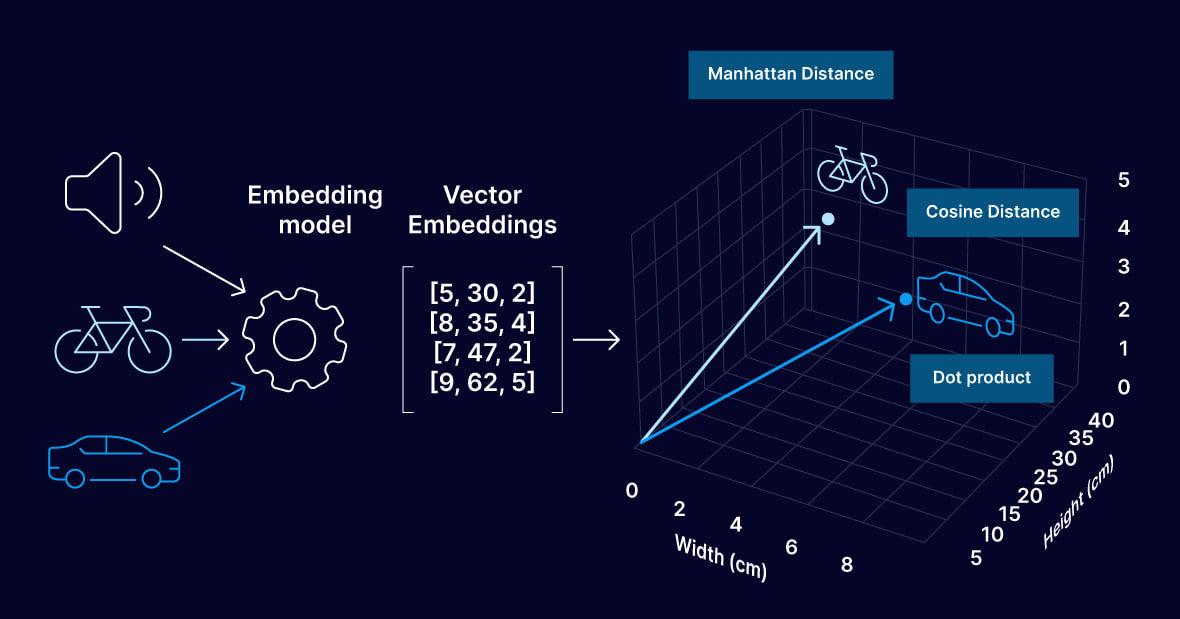
An embedding is a list of numbers, for example: [0.21, -0.84, 0.03, 0.67, ...] — from 384 to 3072 numbers depending on the model. Each set of numbers is a point in a multidimensional space. Words with similar meanings end up close in this space, words with different meanings are far apart.
If regular GPS coordinates are two numbers (latitude and longitude), then an embedding is a GPS in a space with thousands of dimensions, where each "coordinate" encodes some aspect of meaning.
Let's imagine a very simplified space — only two dimensions. The X-axis represents how much the word is related to the living world. The Y-axis represents how much it is related to movement. Then:
- "lawyer" → high X (human), low Y (not about movement) → coordinate [0.9, 0.1]
- "courier" → high X, high Y → [0.9, 0.8]
- "car" → low X, high Y → [0.1, 0.9]
- "rocket" → low X, very high Y → [0.05, 0.95]
In reality, there are not two, but hundreds or thousands of dimensions — each encodes some subtler aspect: emotional tone, syntactic role, thematic relevance, etc. We cannot interpret them individually, but the mathematics of distances between points in this space works flawlessly.
How similarity between vectors is measured: Cosine Similarity
The distance between two vectors is measured not by a straight line (Euclidean distance), but by the angle between them — the so-called cosine similarity. The smaller the angle between two vectors, the more semantically similar the words or sentences are. "Contract" and "agreement" point in almost the same direction in the space of meaning — the angle between them is small, similarity is high. "Contract" and "rocket" are almost perpendicular, similarity is close to zero.
Cosine similarity is the de facto standard for most models and vector DBs. But there is an important nuance that I see in production errors: some models are optimized for a different metric — Dot Product. For example, Google's Gemini Embedding 2 and some Cohere models in certain modes expect Dot Product, not Cosine. If you set the wrong metric in your Vector DB — search results will be worse even with the correct model. Always check the model's documentation before setting the distance in ChromaDB, Qdrant, or pgvector.
Lifehack: normalizing vectors speeds up search
There is a practical trick worth knowing. If you normalize vectors to unit length — that is, bring each vector to a norm of 1 — then Cosine Similarity becomes mathematically equivalent to Dot Product. And Dot Product is calculated faster: it's just the sum of element-wise products, without additional division by norms. Many vector DBs (Qdrant, pgvector with vector_cosine_ops) do this automatically — but if you use your own search or FAISS, normalize vectors before saving and you'll get a speed boost without any loss of quality.
More details on how cosine similarity and Dot Product are used in search in practice are in the article Vector Search for Beginners.
- ✔️ Embedding — a list of numbers from 384 to 3072 values
- ✔️ Similarity is measured by the angle between vectors (Cosine Similarity) — but check the model's documentation: some are optimized for Dot Product
- ✔️ Normalized vectors: Cosine = Dot Product → faster search without quality loss
Conclusion: Embedding transforms abstract "meaning" into concrete geometry — and this is precisely what allows AI to compare text meanings mathematically. But choosing the right similarity metric is no less important than the model itself.
📌 Section 3. Where do these numbers come from? How the model learned to encode meaning
An embedding model is trained on billions of text pairs using contrastive learning: sentences with similar meanings get close vectors, sentences with different meanings get distant ones. No one manually tells the model that "termination of contract" is similar to "cessation of agreement" — it deduces this itself from the statistics of billions of real texts.
The model doesn't read a dictionary and doesn't know grammar. It reads billions of sentences — and learns which words and phrases co-occur, and which never appear together.
Behind this lies the idea of distributional semantics, formulated by linguist John Firth back in 1957: "A word is characterized by the company it keeps." If two words consistently appear in similar contexts — they most likely have similar meanings. This very principle became the basis for Word2Vec (Google, 2013) — the first large-scale model that converted words into vectors through context statistics, rather than manual labeling. Original paper by Mikolov et al., 2013 — arXiv:1301.3781 .
From Word2Vec to modern contrastive learning
Word2Vec training was simple: for each word — predict neighboring words within a window of 5–10 tokens. If "lawyer" and "attorney" frequently appear in similar sentences — their vectors get closer. This already worked. But in Word2Vec, each word had *one* vector regardless of context: the word "key" received the same vector in the sentence "key to the lock" and "key to success" — even though the meanings are different.
Modern models (BERT by Google, 2018) solved this problem: the vector now depends on the entire sentence, not on a static dictionary. The word "key" gets a different vector depending on what is next to it. This became possible thanks to the transformer architecture and the self-attention mechanism. BERT: Pre-training of Deep Bidirectional Transformers — arXiv:1810.04805 .
What contrastive learning looks like in practice
The current standard for training embedding models is contrastive learning, specifically the SimCSE approach and its derivatives. The model receives three sentences simultaneously:
- Anchor: "How to cancel a service subscription?"
- Positive example: "Instructions for unsubscribing from a plan" — should be close to the anchor
- Negative example: "Recipe for traditional borscht" — should be far from the anchor
The loss function (contrastive loss or InfoNCE loss) penalizes the model if the positive vector is far from the anchor — or if the negative vector is too close. Through billions of such triplets, the model learns to build a space where semantic proximity is reflected by geometric proximity. SimCSE: Simple Contrastive Learning of Sentence Embeddings — arXiv:2104.08821 .
Where do they get pairs for training? Mostly from three sources: natural question-answer pairs (NLI datasets, Stack Overflow, Reddit), parallel translations (for multilingual models), and synthetic pairs generated by LLMs. For example, to train text-embedding-3-small, OpenAI used synthetic data generated by GPT-4, as described in OpenAI's blog on new embedding models .
What the model actually encodes in the vector
Researchers have found that different dimensions of the vector encode different aspects of meaning — but not as straightforwardly as one might wish. One dimension might be responsible for "legal context," another for "emotional tone," a third for "syntactic role in the sentence." But the dimensions are not isolated: meaning is encoded distributively across all numbers simultaneously. This means that no single number in the vector has a human-interpretable meaning — only the entire combination together.
A well-known example from Word2Vec, which has carried over to modern models: vector("king") − vector("man") + vector("woman") ≈ vector("queen"). The arithmetic of meanings works in the vector space — this is one of the most striking confirmations that the model has truly captured the structure of language, not just memorized words.
Why multilingual models understand "договір" and "contract" as the same
Multilingual embedding models (Cohere embed-v4, BGE-M3, multilingual-e5) were trained simultaneously on texts in dozens of languages and on parallel translation corpora. Because of this, "договір" (Ukrainian) and "contract" (English) end up in adjacent points in the same space — because they appeared in similar contexts and were linked through translations.
This enables cross-lingual search: a query in Ukrainian finds documents in English without any translation. In practice — if your knowledge base is filled mostly with English documents, and users query in Ukrainian, a high-quality multilingual model will bridge this gap. In our WebsCraft case, this was a real problem: some content exists only in one language, and queries come in another. BGE-M3 handles this significantly better than OpenAI small, where quality on Cyrillic is noticeably lower than on Latin — which is also confirmed by the MTEB Multilingual Leaderboard results .
- ✔️ Distributional semantics: meaning = co-occurrence context
- ✔️ Contrastive learning: positive pairs move closer, negative ones move apart
- ✔️ Modern models (BERT and beyond): vector depends on context, not static
- ✔️ Multilingual models: translations in the same space → cross-lingual search without a translator
Conclusion: The numbers in a vector are not arbitrary and not hardcoded. They are the result of training on billions of examples and reflect the real statistical structure of language — that's why they capture meaning so well.