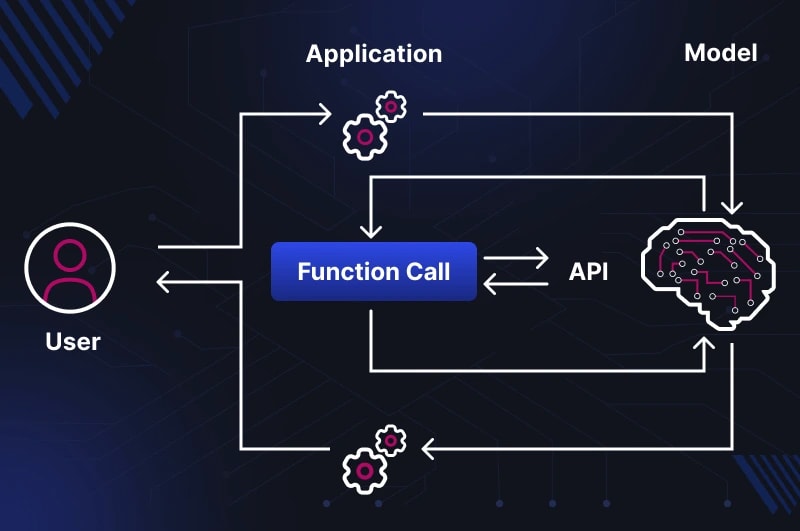
Cuando un desarrollador ve por primera vez cómo un LLM "llama a una función", surge un error intuitivo:
parece que el modelo ha realizado la consulta a la base de datos o a la API por sí mismo.
Esto no es así, y es precisamente este error el que genera toda una clase de errores arquitectónicos.
Spoiler: El LLM solo devuelve un JSON estructurado con el nombre de la función y sus argumentos;
toda la ejecución ocurre en tu código.
⚡ En resumen
- ✅ El LLM es un orquestador, no un ejecutor: el modelo genera la solicitud JSON, tu código la ejecuta
- ✅ Function Calling = Tool Use: nombres diferentes de OpenAI y Anthropic para la misma mecánica
- ✅ tool_choice: auto — el modelo decide; required — llamada forzada; none — solo texto
- ✅ RAG y Tool Use — diferentes niveles de abstracción: RAG puede ser una de las herramientas en un sistema de Tool Use
- 🎯 Obtendrás: una comprensión clara de la mecánica de function calling y dónde se cruza con tu pipeline de RAG
- 👇 A continuación — explicaciones detalladas, ejemplos de código y tablas
📚 Contenido del artículo
⸻
¿Qué es Function Calling — el modelo como orquestador, no como ejecutor
El principio básico que se confunde constantemente:
el LLM no ejecuta la función por sí mismo.
Solo analiza el contexto, determina qué función llamar y con qué argumentos —
y devuelve una solicitud JSON estructurada. La ejecución ocurre en tiempo de ejecución de tu aplicación.
Para entender por qué es así, hay que mirar la arquitectura desde el ángulo correcto.
Un LLM es un transformador de texto sin estado. No tiene sockets, no puede abrir una conexión a una base de datos,
no puede hacer una solicitud HTTP. Todo lo que hace es recibir tokens de entrada y generar tokens de salida.
Function calling es simplemente un acuerdo sobre el formato de estos tokens de salida:
en lugar de texto natural, el modelo genera un JSON estructurado,
que tu código interpreta como una instrucción para actuar.
Ciclo de llamada completo
Symflower (2025)
lo describe así: el LLM pide a Agent Scaffolding que ejecute una llamada a una herramienta en su nombre.
Comet (2026)
detalla el ciclo a través del patrón TAO — Thought → Action → Observation (Pensamiento → Acción → Observación):
1. Mensaje del usuario → LLM
↓
2. El LLM analiza el contexto (Pensamiento)
→ devuelve un JSON con el nombre de la función y los argumentos
↓
3. Agent Scaffolding analiza el JSON (Acción)
→ ejecuta la función en tu código
→ obtiene el resultado
↓
4. El resultado se devuelve al LLM como resultado de la herramienta (Observación)
↓
5. El LLM genera la respuesta final al usuario
Nota: entre el paso 2 y el paso 4, el LLM no está involucrado en absoluto.
"Espera" a que tu código realice el trabajo y devuelva el resultado.
Es precisamente por eso que los errores en las llamadas a herramientas suelen ocurrir no en el modelo,
sino entre los pasos 3 y 4 — en tu código de procesamiento de resultados.
Esta arquitectura se llama Agent Scaffolding — una capa entre el LLM y el mundo exterior,
que gestiona el ciclo de llamadas. En casos simples, son unas pocas líneas de Python.
En casos complejos, son frameworks completos como LangGraph o AutoGen.
Pero el principio sigue siendo el mismo: el modelo decide qué hacer, el código ejecuta.
Referencia terminológica: Function Calling vs Tool Use
Ambos términos describen la misma mecánica, pero desde diferentes puntos de vista:
-
Function Calling — término original de OpenAI (apareció en GPT-4, junio de 2023).
El enfoque está en que el modelo "llama a una función" — de ahí el nombre.
El modelo devuelve un objeto con
function.name y function.arguments.
-
Tool Use — término más amplio de Anthropic y estándar de la industria 2024-2025.
El enfoque está en que el modelo "usa una herramienta" — enfatiza que es solo uno de los medios,
y no un fin en sí mismo. Incluye funciones personalizadas + herramientas integradas (intérprete de código, búsqueda web, lectura de archivos).
Como señala
Martin Fowler (2025):
"tool calling" es un término más general y moderno; ambos términos coexisten por razones históricas.
También cabe destacar: en la documentación de Anthropic, en lugar de required se usa any,
y las descripciones de las herramientas se pasan a través de input_schema en lugar de parameters —
diferencias sintácticas menores con lógica idéntica.
¿Por qué el modelo es capaz de hacer esto?
Function calling no es una "habilidad" integrada del LLM en sentido de hardware.
Es el resultado de un fine-tuning en ejemplos sintéticos donde la respuesta correcta es JSON, no texto.
Como describe
Simplicity is SOTA (2025),
los proveedores generan miles de ejemplos de prompt → tool call con un rastro de razonamiento Chain-of-Thought,
donde el modelo aprende no solo a generar JSON,
sino a justificar por qué esa herramienta específica es necesaria en ese contexto específico.
La calidad de tool calling depende directamente de la calidad de la descripción de las herramientas.
El modelo está entrenado para reconocer la intención a través de la descripción — si la descripción es vaga o falta,
el modelo no llamará a la herramienta o llamará a la incorrecta.
Detalles sobre esto — en Cómo el modelo LLM decide cuándo buscar — la mecánica de la toma de decisiones.
Llamadas paralelas: cuando una herramienta no es suficiente
Los modelos modernos admiten llamadas a herramientas paralelas en una sola vuelta —
cuando se necesitan varias fuentes independientes simultáneamente para la respuesta.
Por ejemplo, la solicitud "compara las condiciones de los contratos A y B" puede provocar dos llamadas paralelas
a search_documents con diferentes parámetros en lugar de dos secuenciales.
# Respuesta del modelo con llamadas a herramientas paralelas:
{
"tool_calls": [
{
"id": "call_001",
"function": {
"name": "search_documents",
"arguments": "{\"query\": \"condiciones del contrato A\", \"top_k\": 3}"
}
},
{
"id": "call_002",
"function": {
"name": "search_documents",
"arguments": "{\"query\": \"condiciones del contrato B\", \"top_k\": 3}"
}
}
]
}
Tu código debe procesar ambos resultados y pasarlos de nuevo en el siguiente mensaje
como dos bloques tool_result separados.
Si devuelves solo uno, el modelo recibirá un contexto incompleto y podría alucinar la segunda parte de la respuesta.
⚠️ Trampa #1: error invisible entre el paso 3 y 4
El error más común en la arquitectura: el desarrollador cree que el modelo "ha ejecutado la consulta a la base de datos",
cuando en realidad solo ha formado una solicitud JSON, y la ejecución podría no haber ocurrido en absoluto
debido a un error en el código de procesamiento de la llamada a la herramienta.
El LLM recibe un resultado vacío o erróneo — y continúa generando una respuesta
como si nada hubiera pasado, a menudo alucinando en lugar de reconocer el problema.
Lista de verificación mínima para un ciclo fiable:
- Registra todo el ciclo: solicitud de llamada a herramienta → ejecución → resultado → respuesta del modelo
- Verifica que los
arguments se hayan deserializado correctamente con json.loads() antes de la ejecución
- Maneja excepciones si la función devolvió un error — y pasa explícitamente ese error de vuelta al LLM
- En llamadas paralelas — siempre devuelve los resultados para todos los
tool_call.id
Cómo se ve una llamada técnicamente: JSON schema, tool_choice auto/required/none
Para que el modelo conozca las herramientas, deben describirse en formato JSON Schema y pasarse en la solicitud API.
La sintaxis difiere según el proveedor — y esta diferencia es práctica:
el código escrito para OpenAI no funcionará con Anthropic API sin modificar un campo clave.
Sintaxis OpenAI vs Anthropic: dónde se rompe el código
La principal diferencia: OpenAI usa la clave parameters,
Anthropic — input_schema. El resto de la estructura es idéntica.
# OpenAI / API compatible con OpenAI
tools = [
{
"type": "function",
"function": {
"name": "search_documents",
"description": "Busca fragmentos relevantes en la base de conocimiento corporativa",
"parameters": { # ← OpenAI: "parameters"
"type": "object",
"properties": {
"query": {
"type": "string",
"description": "Texto de la consulta de búsqueda"
},
"top_k": {
"type": "integer",
"description": "Número de fragmentos (por defecto 5)"
}
},
"required": ["query"]
}
}
}
]
# Anthropic Claude API (nativo)
tools = [
{
"name": "search_documents",
"description": "Busca fragmentos relevantes en la base de conocimiento corporativa",
"input_schema": { # ← Anthropic: "input_schema", sin el envoltorio "function"
"type": "object",
"properties": {
"query": {
"type": "string",
"description": "Texto de la consulta de búsqueda"
},
"top_k": {
"type": "integer",
"description": "Número de fragmentos (por defecto 5)"
}
},
"required": ["query"]
}
}
]
Si usas LiteLLM o LangChain — ellos abstraen esta diferencia
y convierten el formato automáticamente. Al trabajar directamente con Anthropic SDK — solo input_schema.
Qué devuelve el modelo y cómo pasar el resultado de vuelta
La mayoría de los tutoriales se detienen en cómo el modelo devuelve una llamada a herramienta.
Pero lo más frecuente es que los desarrolladores se atasquen en el siguiente paso —
cómo pasar correctamente el resultado de la ejecución de vuelta en el siguiente mensaje.
Paso 1. El modelo devuelve una llamada a herramienta en lugar de texto:
# Respuesta del modelo (stop_reason: "tool_use")
{
"content": [
{
"type": "tool_use",
"id": "toolu_01XFDUDYJgAACTvYkLMeDRVQ", # ← id necesario para el siguiente paso
"name": "search_documents",
"input": {
"query": "condiciones de rescisión del contrato",
"top_k": 5
}
}
],
"stop_reason": "tool_use"
}
Nota: en la API de Anthropic, el campo se llama input (ya es un objeto),
y no arguments (una cadena como en OpenAI). La deserialización a través de json.loads()
solo es necesaria al trabajar con el formato de OpenAI.
Paso 2. Tu código ejecuta la función y forma la siguiente solicitud:
import anthropic, json
client = anthropic.Anthropic()
# Primera solicitud
response = client.messages.create(
model="claude-opus-4-6",
max_tokens=1024,
tools=tools,
messages=[{"role": "user", "content": "¿Cuáles son las condiciones de rescisión del contrato?"}]
)
# Obtenemos la llamada a herramienta de la respuesta
tool_use_block = next(b for b in response.content if b.type == "tool_use")
tool_result = search_documents(**tool_use_block.input) # tu función
# Segunda solicitud — pasamos el resultado de vuelta
follow_up = client.messages.create(
model="claude-opus-4-6",
max_tokens=1024,
tools=tools,
messages=[
{"role": "user", "content": "¿Cuáles son las condiciones de rescisión del contrato?"},
{"role": "assistant", "content": response.content}, # ← toda la respuesta del modelo
{
"role": "user",
"content": [
{
"type": "tool_result",
"tool_use_id": tool_use_block.id, # ← id del paso 1
"content": json.dumps(tool_result, ensure_ascii=False)
}
]
}
]
)
Tres detalles críticos de este ciclo:
-
El
tool_use_id en el resultado debe coincidir exactamente con el id de la llamada a herramienta —
de lo contrario, la API devolverá un error de validación.
-
En
messages se pasa toda la respuesta del modelo (response.content),
no solo el texto — el modelo debe ver su propia llamada a herramienta en el contexto.
-
En llamadas paralelas (varias llamadas a herramientas en una respuesta) —
es necesario devolver un
tool_result para cada id,
de lo contrario, la siguiente solicitud devolverá un error.
Parámetro tool_choice
El parámetro tool_choice controla el modo de toma de decisiones sobre la llamada a una herramienta.
Documentación oficial de Anthropic
define cuatro opciones:
| Valor |
Comportamiento |
Cuándo usar |
⚠️ Trampa |
auto |
El modelo decide por sí mismo: texto o llamada a herramienta |
Escenario conversacional típico. Por defecto si se pasan herramientas. |
El modelo puede no llamar a una herramienta si la descripción es poco clara o si "confía" en la respuesta de su propio conocimiento — incluso si los datos están desactualizados |
any / required |
El modelo está obligado a llamar al menos a una herramienta |
Salida estructurada, registro obligatorio, consulta forzada a una API externa |
Llama a una herramienta incluso ante un "Hola" — tokens y latencia innecesarios. Incompatible con extended thinking en Claude (HTTP 400) |
none |
El modelo no llama a ninguna herramienta, solo genera texto |
Respuesta exclusivamente del contexto proporcionado; paso final después de recibir todos los resultados |
Si se pasa none junto con tool_result en messages — la API devolverá un error: las definiciones de herramientas deben estar presentes |
{"type": "tool", "name": "..."} |
Llamada forzada a una herramienta específica |
Prueba de una herramienta individual, pipeline determinista |
Incompatible con extended thinking. El modelo no genera texto antes de la llamada a la herramienta — incluso si se solicita explícitamente |
Nota sobre la terminología: OpenAI usa required,
Anthropic — any para indicar "obligatorio llamar al menos a una herramienta".
LiteLLM convierte entre formatos automáticamente.
Esta no es solo una diferencia conceptual: es una diferencia en quién controla el flujo.
En un pipeline RAG, la decisión de buscar está codificada en la arquitectura.
En Tool Use, el modelo es un participante activo en esta decisión.
Comprender esta distinción determina qué problemas encontrará en producción y dónde buscarlos.
RAG clásico: un pipeline determinista
Consulta del usuario
→ Embedding de la consulta ← conversión de texto a vector
→ Búsqueda en la base de datos vectorial (siempre, sin condiciones)
→ Reordenamiento de resultados
→ Formación del contexto (relleno de prompt)
→ Envío a LLM
→ Respuesta
Cada paso ocurre independientemente del contenido de la consulta.
Si el usuario pregunta "¿cuánto es 2+2?", el pipeline aún realizará el embedding,
irá a Qdrant, devolverá los 5 fragmentos principales y los enviará al contexto del modelo.
El modelo recibirá contexto innecesario y se verá obligado a ignorarlo.
El primer paso de este pipeline, el embedding, merece una atención especial:
es aquí donde el texto se convierte en un vector numérico que lleva significado semántico, no solo palabras clave.
Cómo funciona técnicamente:
Embeddings en palabras sencillas: cómo la IA entiende el significado, no solo las palabras
.
Más detalles sobre la mecánica completa del pipeline RAG, desde el chunking hasta el reordenamiento:
RAG en 2026: de PoC a Producción - Guía completa
.
Sobre la diferencia fundamental entre las capacidades de un LLM "puro" y un sistema RAG:
LLM vs RAG en 2026: por qué no son lo mismo
.
Esto no es un error, es un precio arquitectónico deliberado por la previsibilidad.
Tool Use: el modelo como agente activo
Consulta del usuario
→ El LLM analiza el contexto y las intenciones
→ Decisión: responder con su propio conocimiento / llamar a una herramienta / llamar a varias herramientas en paralelo
↓ si se llama a una herramienta
→ ¿Qué herramienta? ¿Con qué parámetros?
→ JSON → Agent Scaffolding → ejecución → resultado → LLM
→ Respuesta final
El modelo no solo genera texto, toma decisiones sobre el flujo.
Ante la pregunta "¿cuánto es 2+2?", responderá directamente sin tocar ninguna herramienta.
Ante la pregunta "¿cuáles son las condiciones de rescisión del contrato?", llamará a search_documents.
Ante la pregunta "¿compara los contratos A y B?", posiblemente dos llamadas paralelas a la misma herramienta
con diferentes parámetros.
Dónde está el límite real
Analogía clave: RAG es un bibliotecario que siempre va a la estantería antes de responder.
Tool Use es un consultor que primero piensa y luego decide si necesita consultar los documentos.
El consultor es más eficiente, pero su decisión es menos predecible.
| Característica |
Pipeline RAG |
Tool Use |
| Quién decide "buscar o no" |
Arquitectura - siempre busca |
Modelo - dependiendo del contexto |
| Número de fuentes de datos |
Generalmente una (base de datos vectorial) |
Cualquier número de herramientas |
| Previsibilidad del comportamiento |
Alta - el mismo camino siempre |
Menor - depende de la decisión del modelo |
| Latencia |
Estable y predecible |
Variable: de 0 a N llamadas a herramientas |
| Costo por consulta |
Fijo |
Depende del número de llamadas |
| Eficiencia en consultas simples |
Baja - recuperación innecesaria siempre |
Alta - el modelo omite lo innecesario |
| Complejidad de depuración |
Baja - un camino determinista |
Mayor - es necesario registrar todo el ciclo de decisiones |
| Riesgo de "no encontrar" lo necesario |
Solo si el recuperador es malo |
Además, si el modelo decide no buscar |
RAG dentro de Tool Use: qué aporta y qué cuesta
Un pipeline RAG puede implementarse como una de las herramientas en un sistema Tool Use,
es decir, search_knowledge_base(query) se convierte en una herramienta que el modelo llama cuando es necesario.
Esto ofrece una ventaja real: no se realizan consultas de embedding ni búsquedas innecesarias,
y no se gastan tokens en la formación del contexto en vano.
Pero tiene un precio:
-
Nuevos puntos de fallo.
En RAG clásico, la recuperación está garantizada. En Tool Use, el modelo puede decidir no buscar
en una consulta donde la búsqueda es críticamente necesaria. Es especialmente peligroso cuando el modelo está "seguro"
de la respuesta a partir de su propio conocimiento, pero este conocimiento está desactualizado.
-
La calidad de la descripción de la herramienta se vuelve crítica.
Si la
description es vaga o no cubre el escenario, el modelo no llamará a la herramienta.
En RAG clásico, la descripción no afecta en absoluto la decisión de búsqueda.
Detalles sobre cómo escribir descripciones: en TU-2.
-
La observabilidad es más compleja.
En un pipeline RAG, siempre hay un registro de la consulta de recuperación y el resultado.
En Tool Use, es necesario registrar por separado la decisión del modelo (llamó / no llamó),
los parámetros de la llamada y el resultado, para comprender dónde la respuesta salió mal.
Conclusión práctica: cuándo elegir qué
Quédate con RAG clásico si:
la única fuente de datos es una base de conocimiento corporativa,
todas las consultas requieren búsqueda,
la previsibilidad y la simplicidad de depuración son críticas,
el SLA de latencia es estricto.
Pasa a Tool Use si:
hay varias fuentes de datos diferentes (bases de datos + API + archivos),
parte de las consultas no requieren datos externos en absoluto,
se necesita la capacidad de realizar consultas paralelas a diferentes sistemas,
estás construyendo un sistema agentivo donde la recuperación es solo uno de los escenarios.
⚠️ Trampa
El escenario más peligroso en "RAG a través de Tool Use":
el modelo responde de manera segura y coherente, pero sin llamar a una herramienta,
porque decidió que conocía la respuesta.
En un contexto corporativo (contratos, precios, regulaciones), esto significa una respuesta
que puede ser correcta en forma pero desactualizada en contenido.
Siempre registre el stop_reason: si es "end_turn" sin un "tool_use" previo,
el modelo no buscó. Decida si esto es aceptable para su escenario.
Dónde RAG y Tool Use se cruzan — y dónde divergen
La sección anterior mostró la diferencia en la lógica arquitectónica.
Aquí, la práctica: cómo estos dos enfoques interactúan en sistemas reales,
qué patrones de combinación funcionan y dónde el límite entre ellos se difumina intencionadamente.
Tres patrones de combinación
Patrón 1: RAG como pipeline independiente (sin Tool Use)
El caso clásico. La recuperación (Retrieve) siempre ocurre, el modelo recibe el contexto automáticamente.
Adecuado cuando todas las consultas requieren búsqueda y la previsibilidad es más importante que la eficiencia.
AskYourDocs
en su configuración básica es precisamente este patrón.
Patrón 2: RAG como una de las herramientas en un sistema de Tool Use
El modelo recibe search_knowledge_base(query) como una herramienta y decide cuándo llamarla.
Consultas simples ("¿qué es PDF?", "hola") se procesan sin recuperación.
Las complejas o específicas activan la búsqueda.
Esto aumenta la eficiencia pero añade un nuevo punto de fallo: el modelo puede no llamar a la herramienta cuando es necesario.
Patrón 3: Varias herramientas especializadas + RAG como una de ellas
La opción más potente y más compleja.
El modelo tiene acceso a varias herramientas simultáneamente:
tools = [
search_knowledge_base(query), # RAG sobre documentos corporativos
get_contract_status(contract_id), # consulta a CRM/ERP
calculate_deadline(date, days), # cálculo de fechas
send_notification(user_id, text), # acción en sistema externo
]
Aquí, RAG ya no es todo el pipeline, sino una herramienta especializada entre otras.
El modelo decide la combinación: por ejemplo, primero search_knowledge_base
para encontrar las condiciones del contrato, luego get_contract_status para verificar el estado actual,
y finalmente generar una respuesta basada en ambos resultados.
Dónde se difumina el límite: RAG con lógica de selección interna
Hay una opción intermedia que a menudo se subestima:
un pipeline RAG clásico con enrutamiento pre-recuperación interno.
Antes de ir a la base de datos vectorial, un clasificador ligero o un prompt decide
si la recuperación es necesaria para esta consulta.
# Lógica simplificada de enrutamiento pre-recuperación
def should_retrieve(query: str) -> bool:
# Un clasificador heurístico simple
factual_keywords = ["contrato", "condiciones", "precio", "reglamento", "fecha límite"]
return any(kw in query.lower() for kw in factual_keywords)
def answer(query: str) -> str:
if should_retrieve(query):
context = retriever.search(query)
return llm.generate(query, context=context)
else:
return llm.generate(query) # sin recuperación
Esto no es "puro" Tool Use — la decisión la toma el código, no el modelo.
Pero tampoco es "puro" RAG — la recuperación no siempre ocurre.
Este híbrido proporciona la previsibilidad del pipeline clásico
más parte de la eficiencia del enfoque Tool Use.
El precio es el mantenimiento del clasificador y el riesgo de falsos positivos.
Comparación de patrones
| Patrón |
Quién decide la recuperación |
Complejidad |
Mejor para |
| Pipeline RAG |
Arquitectura (siempre) |
Baja |
Base de conocimiento única, todas las consultas requieren búsqueda |
| RAG + enrutamiento pre-recuperación |
Clasificador en código |
Media |
Consultas mixtas, se requiere previsibilidad |
| RAG como herramienta en Tool Use |
LLM (según contexto) |
Media |
Principalmente consultas documentales + un pequeño porcentaje de LLM "puras" |
| Varias herramientas + RAG como una |
LLM (según contexto) |
Alta |
Sistemas de agentes, múltiples fuentes de datos, flujos de trabajo complejos |
¿Dónde se cruzan específicamente: componentes comunes
Independientemente del patrón, ambos enfoques se basan en los mismos componentes básicos:
-
Modelo de Embedding — necesario en RAG para la búsqueda vectorial,
y puede ser necesario en Tool Use para la recuperación de herramientas cuando hay más de 50 herramientas.
Cómo los embeddings convierten el texto en un vector semántico —
Embeddings en palabras sencillas: cómo la IA entiende el significado, no solo las palabras
.
-
Base de datos vectorial — en RAG almacena fragmentos de documentos,
en sistemas Tool RAG almacena descripciones de herramientas para la búsqueda semántica en el registro de herramientas.
-
Reranker — en RAG reevalúa la relevancia de los fragmentos,
en Tool Use puede reevaluar la relevancia de las herramientas con un registro grande.
-
Capa de Observabilidad — en ambos casos es crucial registrar
qué se encontró/llamó y qué entró en el contexto del modelo.
⚠️ Piedra de tropiezo #3: la ilusión de la elección
El error arquitectónico más común al pasar de RAG a Tool Use:
el desarrollador está convencido de que "el modelo es inteligente y decidirá por sí mismo cuándo buscar" —
y no dedica tiempo a una description de herramienta de calidad.
Como resultado, el modelo o no llama a la herramienta en consultas donde es necesaria,
o la llama en consultas donde es innecesaria.
Una herramienta sin una descripción clara es una biblioteca sin catálogo:
técnicamente accesible, pero prácticamente inalcanzable.
Detalles sobre la mecánica de esta decisión y cómo escribir una descripción — en
TU-2: Cómo el modelo decide cuándo buscar.
Esta es una de las mezclas terminológicas más comunes en 2026. Al ver que un modelo llama a get_weather() o search_documents(), los desarrolladores dicen "he creado un agente". En realidad, han creado un LLM con una herramienta — es un paso importante, pero no es agencia.
¿Qué es realmente un agente?
Comet (2026) define un agente a través de tres componentes obligatorios:
- Bucle (Loop): un agente no hace una sola llamada y se detiene. Trabaja en un bucle: piensa → actúa → observa → vuelve a pensar. El número de pasos no está predefinido.
- Memoria (Memory): un agente recuerda lo que ya ha hecho, qué resultados ha obtenido, y lo utiliza para futuras decisiones. No solo el historial del diálogo, sino también los resultados intermedios de la ejecución.
- Planificación (Planning): un agente puede dividir un objetivo complejo en subtareas, determinar el orden de las acciones, cambiar el plan si algo sale mal.
Tool Use sin estos tres componentes es simplemente LLM con llamadas RPC. Técnicamente, no es diferente de cómo un programa normal llama a una función. La diferencia es solo quién decide qué función llamar: el programador (código) o el modelo (prompt).
Espectro de complejidad: de una simple llamada a un agente real
La agencia no es una propiedad binaria (o agente / o no), sino un espectro. Es útil pensar en términos de "grado de agencia":
| Nivel | Qué puede hacer | Ejemplo | ¿Es un agente? |
| L0: Llamada a Herramienta Única | Una llamada, un resultado, luego la respuesta | "¿Qué tiempo hace en Kiev?" → get_weather → respuesta | ❌ No, uso de herramientas normal |
| L1: Llamadas Secuenciales a Herramientas | Varias llamadas en secuencia, sin retroalimentación entre ellas | "Encuentra el documento A y el documento B" → dos llamadas una tras otra | ❌ No, solo un pipeline |
L2: Llamadas Condicionales a Herramientas | El resultado de la primera llamada afecta a la segunda | "Encuentra el contrato → si está activo, entonces verifica las condiciones" | ⚠️ Parcialmente — hay indicios de planificación |
| L3: Agente estilo ReACT | Bucle completo: Pensamiento → Acción → Observación → repetir | "Programa una reunión: encuentra franjas horarias libres → elige la mejor → envía la invitación" | ✅ Sí, agente clásico |
| L4: Agente Autónomo | Como L3 + memoria a largo plazo + planificación autónoma de subtareas | "Prepara el informe mensual" → decide por sí mismo qué datos recopilar, en qué orden, y lo hace | ✅ Sí, agente completo |
Conclusión clave: Tool Use aparece en el nivel L0. Pero solo en L3 aparece la verdadera agencia — el bucle + la planificación.
¿Por qué es importante entender esto?
Los desarrolladores que confunden tool use con agentes cometen tres errores típicos:
- No añaden un bucle. Hacen una llamada, obtienen un resultado — y creen que es un agente. Pero si se necesitan dos herramientas para responder, el sistema falla.
- No pasan el contexto de ejecución. Un agente debe recibir no solo el resultado de la función, sino también metainformación: si se ejecutó con éxito, cuánto tiempo tardó, qué errores ocurrieron. Sin esto, el agente está "ciego".
- Esperan magia. "¿Añadí herramientas — por qué el modelo no construye un plan complejo por sí mismo?" Porque la planificación es una capacidad separada que requiere o un prompting adecuado, o frameworks especiales (LangGraph, AutoGen, CrewAI).
Así se ve un ciclo de agente mínimo
Aquí está la diferencia fundamental entre una llamada a herramienta única y un agente cíclico:
# ❌ Esto NO es un agente — es tool use response = client.messages.create( tools=[search_documents], messages=[{"role": "user", "content": "busca documentos sobre el contrato"}] ) result = execute_tool(response.tool_call) final = client.messages.create( messages=[..., tool_result] ) # ✅ Esto es un agente MÍNIMO — con un bucle max_iterations = 5 while iterations < max_iterations and not finished: response = client.messages.create( tools=tools, messages=conversation_history ) if response.stop_reason == "tool_use": for tool_call in response.tool_calls: result = execute_tool(tool_call) conversation_history.append(tool_result(tool_call.id, result)) continue # ← ¡bucle! volvemos al modelo con el resultado # stop_reason == "end_turn" — el agente decidió que la respuesta está lista finished = True return response.content
La diferencia está en una línea — continue. Pero es precisamente esta línea la que crea el bucle, permitiendo al modelo dar varios pasos, ver los resultados de sus acciones y tomar decisiones posteriores basándose en lo que ha visto. Sin un bucle — es solo RPC. Con un bucle — el embrión de un agente.
⚠️ Piedra de tropiezo #4: un agente no siempre es bueno
Los agentes suenan geniales. Pero tienen un precio real:
- Número impredecible de llamadas. Una consulta puede generar 1 llamada a herramienta, o 10 — dependiendo de la complejidad y la calidad de los prompts. Los costos de tokens y la latencia se vuelven no deterministas.
- Riesgo de bucle infinito. Sin mecanismos de protección, un agente puede caer en un bucle infinito: llama a una herramienta → recibe un error → llama de nuevo → de nuevo un error. Siempre añada
max_iterations y detección de patrones repetidos. - Dificultad de depuración. En el tool use normal, usted sabe: hubo una llamada → recibió una respuesta. En un agente — una cadena de N pasos, cada uno de los cuales podría haber salido mal. Las herramientas de observabilidad (langfuse, helicone, arize) se convierten no en una opción, sino en una necesidad.
Consejo práctico: empiece con L0 (llamada a herramienta única) o L1 (secuencial). Añada bucle y planificación solo cuando un pipeline simple realmente se enfrente a limitaciones. Un agente es una herramienta para tareas complejas, no una arquitectura por defecto.
En resumen: recuerde la fórmula
Tool Use = LLM decide qué herramienta llamar.
Agente = Tool Use + bucle + memoria + planificación.
Si solo tiene la primera línea — no tiene un agente. Y eso está bien. La mayoría de las tareas no requieren agencia completa. Pero nombrar las cosas correctamente es importante para construir expectativas adecuadas en el equipo y los stakeholders.
De RAG pipeline a Tool Use: ¿qué sigue?
Si vienes del
RAG-hub
,
tu stack actual se ve aproximadamente así: documentos → chunking → embed → Qdrant → BM25 + rerank → LLM.
Este es un pipeline RAG clásico — determinista, predecible, bien depurado.
Tool Use Hub, que estás leyendo ahora, describe lo que sucede alrededor de este pipeline:
- Cómo el modelo decide cuándo iniciar la búsqueda → Cómo el modelo LLM decide cuándo buscar — mecánica de toma de decisiones
AskYourDocs
— un ejemplo concreto de producto donde el pipeline RAG es una de las herramientas en un sistema más amplio:
búsqueda híbrida en documentos corporativos, aislamiento total de datos en el servidor del cliente,
sin vendor lock-in a nivel de proveedor de LLM.
❓ Preguntas frecuentes
¿Cuál es la diferencia entre Function Calling y Tool Use?
Function Calling es el término original de OpenAI. Tool Use es un término más amplio de Anthropic,
que también abarca herramientas integradas (búsqueda web, intérprete de código).
La mecánica es la misma: el modelo devuelve JSON, tu código lo ejecuta.
¿El LLM ejecuta la función por sí mismo?
No. El modelo forma una solicitud JSON estructurada con el nombre de la función y los argumentos.
La ejecución siempre está del lado de tu aplicación.
¿En qué se diferencia RAG de Tool Use?
RAG es un pipeline determinista donde la recuperación ocurre siempre.
Tool Use es un mecanismo donde el modelo decide por sí mismo si es necesaria la llamada a una herramienta.
RAG puede implementarse como una de las herramientas en un sistema de Tool Use.
¿Cuándo usar tool_choice: required?
Solo en pipelines deterministas — salida estructurada, registro obligatorio.
En modo conversacional, esto conduce a llamadas a herramientas innecesarias y gastos de tokens.
Además: required / any son incompatibles con el pensamiento extendido en Claude.
✅ Conclusiones
- Function Calling y Tool Use son la misma mecánica, nombres diferentes. El modelo forma JSON, tu código ejecuta.
tool_choice ofrece tres modos de control: auto (por defecto), required (forzado), none (solo texto).- Los pipelines RAG y Tool Use existen en diferentes niveles de abstracción — el primero es determinista, el segundo es adaptativo.
- RAG puede ser una herramienta en un sistema de Tool Use — pero esto aumenta la imprevisibilidad y requiere una descripción precisa de la herramienta.
- El RAG clásico sigue siendo la mejor opción para productos con una única base de conocimiento y estrictos requisitos de previsibilidad.
El siguiente paso: cómo exactamente el modelo toma la decisión de llamar a una herramienta o no —
y cómo la descripción de la herramienta influye en esto — lo analizamos en
TU-2: Cómo el modelo decide cuándo buscar.
Fuentes
Symflower — Function calling in LLM agents (2025) ·
Martin Fowler — Function calling using LLMs (2025) ·
Anthropic Docs — How to implement tool use ·
Prompt Engineering Guide — Function Calling with LLMs ·
Simplicity is SOTA — How LLMs are trained for function calling (2025) ·
Berkeley BFCL V4 (2025) ·
Comet — Agent Orchestration (2026)