RAG для PDF: як задавати питання по документах
Ви хочете задавати питання по своєму PDF — договору, звіту чи документації. Копіюєте код із туторіалу, запускаєте — і отримуєте беззмістовні відповіді або помилки.
Проблема майже ніколи не в LLM. Вона виникає ще на першому кроці — під час витягування тексту з PDF.
⚡ Коротко
- ✅ PDF бувають трьох типів: текстовий, сканований, гібрид — і кожен потребує свого підходу до парсингу
- ✅ PyPDF — найпопулярніший, але найгірший: для таблиць і складних макетів використовуйте PyMuPDF або pdfplumber
- ✅ 90% проблем з якістю відповідей — до LLM: парсинг, структура тексту, розмір чанків
- 🎯 Ви отримаєте: робочий Q&A по PDF — два варіанти: швидкий (OpenAI API) і локальний (Ollama)
- 👇 Нижче — діагностика вашого PDF, порівняння парсерів, повний код і чеклист
📚 Зміст статті
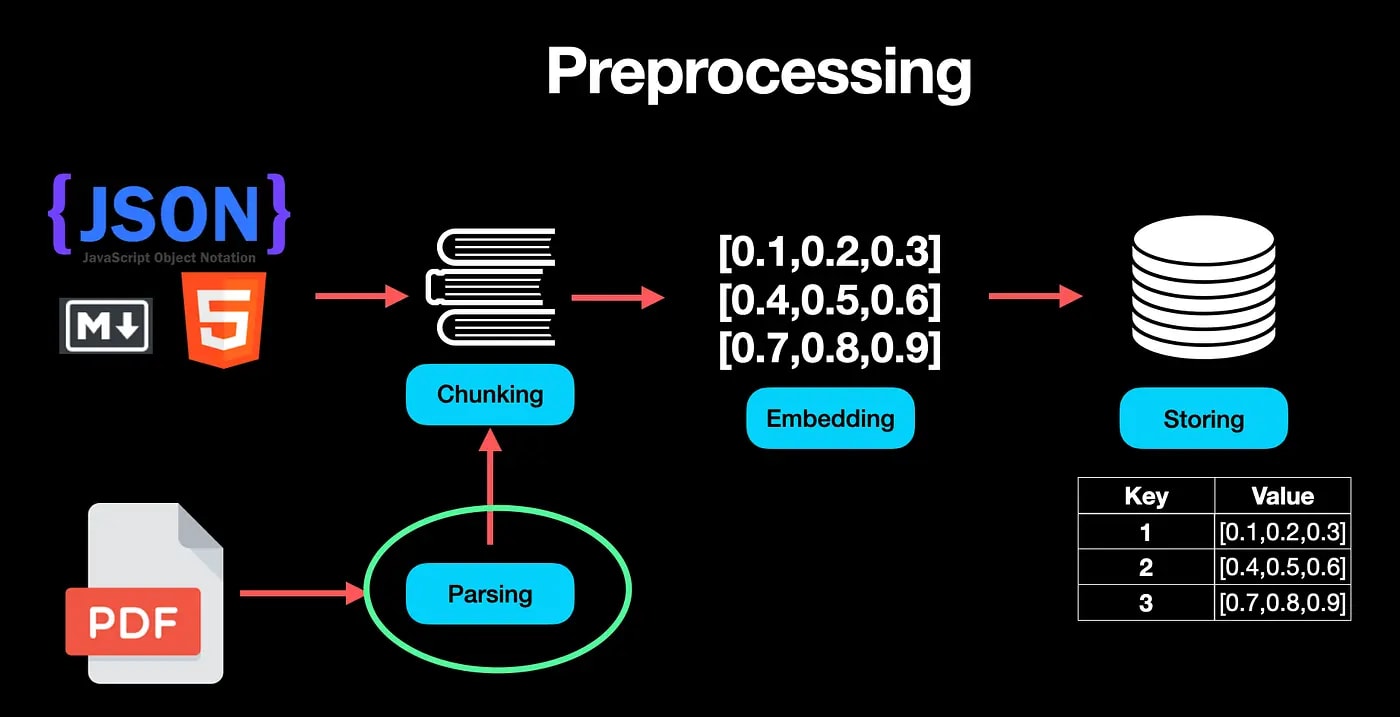
🎯 Як працює RAG для PDF: пайплайн від файлу до відповіді
LLM не читає ваш PDF цілком. Вона відповідає тільки на основі того фрагменту, який ви їй підсунули. Якість відповіді = якість витягнутого тексту + якість пошуку.
Ось як виглядає повний пайплайн:
PDF-файл
↓
[1. ПАРСИНГ] → витягуємо текст (PyMuPDF / pdfplumber / OCR)
↓
[2. CHUNKING] → ділимо на фрагменти по 500–1000 символів
↓
[3. EMBEDDINGS] → кожен фрагмент → числовий вектор
↓
[4. VECTOR DB] → зберігаємо вектори (ChromaDB / Qdrant)
↓
[5. ЗАПИТ] → ваше питання → теж перетворюємо на вектор
↓
[6. ПОШУК] → знаходимо топ-3..5 найближчих фрагментів
↓
[7. LLM] → передаємо питання + фрагменти → отримуємо відповідь
Де найчастіше ламається пайплайн
На практиці кроки embeddings і LLM (OpenAI, Cohere, Ollama) зазвичай працюють стабільно. Основні проблеми виникають значно раніше — на етапі парсингу PDF.
Якщо на вході ви отримали "кашу" замість тексту (злиплі слова, втрачені абзаци, зламані таблиці), жоден пошук чи LLM це вже не виправить. Саме тому ця стаття починається з діагностики PDF, а не з вибору моделі.
Висновок: якість Q&A по PDF визначається на етапі парсингу, а не на етапі генерації відповіді.
📌 Розділ 2. Який у вас PDF? Діагностика за 2 хвилини
Типи PDF у 2026 році
PDF бувають чотирьох основних типів: текстовий (є текстовий шар — парситься легко), сканований (тільки зображення — потрібен OCR), гібридний (суміш тексту та зображень) і складний (з таблицями, багатоколонковою версткою, діаграмами).
Перш ніж обирати інструмент — правильно визначте тип, бо від цього залежить якість усього RAG-пайплайну.
🔍 Швидка діагностика — 3 кроки:
- Спробуйте виділити текст мишкою у PDF-рідері (Adobe Acrobat, браузер, Preview). Якщо текст виділяється нормально — є текстовий шар. Якщо ні — це скан або зображення.
- Перевірте наявність таблиць і складного макету. Багатоколонкові тексти, вкладені таблиці, діаграми — сигнал, що потрібен потужніший парсер.
- Подивіться на розмір файлу. Сканований PDF на 10 сторінок A4 зазвичай важить 3–8 MB. Чистий текстовий — 100–400 KB.
| Тип PDF |
Ознака |
Рекомендований інструмент (2026) |
| Текстовий (native) |
Текст легко виділяється, файл легкий |
PyMuPDF (найшвидший) або Docling |
| Сканований (image-only) |
Текст не виділяється, тільки зображення |
LlamaParse або Docling (з вбудованим OCR) / Tesseract + EasyOCR |
| Гібридний |
Частина сторінок текстова, частина — сканована |
PyMuPDF + selective OCR або LlamaParse / Docling (автоматично обробляє все) |
| З таблицями / складним макетом |
Таблиці, колонки, діаграми, форми |
LlamaParse (найкраща структура) або Docling / pdfplumber (для простих випадків) |
Якщо не впевнені — перевірте програмно. Ось швидкий тест з PyMuPDF:
import fitz # PyMuPDF
doc = fitz.open("your_file.pdf")
text = doc[0].get_text()
print(f"Символів на першій сторінці: {len(text)}")
# Якщо < 100–150 символів → ймовірно скан або порожній текстовий шар
Висновок 2026: 5 хвилин на правильну діагностику типу PDF заощаджують десятки годин на дебагінг і значно підвищують точність відповідей RAG. Для простих документів вистачить класичних інструментів, але для реальних бізнес-документів (звіти, контракти, наукові статті) сучасні AI-powered парсери (LlamaParse та Docling) часто дають набагато кращий результат «з коробки».
📌 Три парсери: PyPDF vs pdfplumber vs PyMuPDF + сучасні AI-powered альтернативи
Який парсер обрати у 2026 році
Для простих текстових PDF — PyMuPDF (fitz) залишається одним з найкращих за швидкістю та надійністю.
Для документів з таблицями — pdfplumber добре справляється на базовому рівні.
Але якщо у вас складні документи (фінансові звіти, наукові статті, контракти, багатоколонкова верстка, діаграми) — класичні бібліотеки вже часто недостатньо. У 2026 році рекомендується починати з сучасних AI-powered парсерів: LlamaParse або Docling.
PyPDF досі встановлюється в тисячах старих туторіалів як "стандарт". Але за якістю витягнутого тексту та збереженням структури він стабільно програє і класичним, і тим більше сучасним AI-інструментам. Це безпосередньо впливає на точність відповідей вашого RAG.
Детальне порівняння (оновлено 2026)
| Критерій |
PyPDF |
pdfplumber |
PyMuPDF (fitz) |
LlamaParse |
Docling (IBM) |
| Швидкість |
Середня |
Повільна |
⚡ Найшвидша |
Середня (API) |
Середня / Повільна (з GPU швидше) |
| Якість тексту |
❌ Слабка |
✅ Добра |
✅ Відмінна |
🌟 Відмінна (LLM-based) |
🌟 Відмінна |
| Таблиці та структура |
❌ Ламається |
✅ Найкраще серед класичних |
⚠️ Базово |
🌟 Найкраще збереження |
🌟 Відмінна точність |
| Складний макет (колонки, діаграми) |
❌ Губить порядок |
✅ Добре |
✅ Добре |
🌟 Відмінно |
🌟 Відмінно |
| Мультимодальність (зображення, формули) |
Ні |
Обмежено |
Частково |
✅ Добре |
✅ Відмінно |
| Вартість / Ліцензія |
Безкоштовно |
Безкоштовно |
Безкоштовно |
Freemium (платно після ліміту) |
Повністю відкритий |
| Установка / Використання |
pip install pypdf |
pip install pdfplumber |
pip install pymupdf |
Через LlamaIndex (API ключ) |
pip install docling |
Чому класичні парсери часто вже недостатньо
PDF — це не текстовий файл, а набір об’єктів з координатами. Класичні бібліотеки (PyPDF, PyMuPDF, pdfplumber) добре працюють на простих документах, але погано справляються зі складною версткою, вкладеними таблицями, діаграмами та змішаним контентом.
Сучасні AI-powered парсери (LlamaParse, Docling) використовують візійні моделі та LLM, щоб розуміти документ так, як це робить людина. Вони повертають чистий Markdown або структурований JSON, що значно покращує якість retrieval у RAG.
Коли який парсер використовувати у 2026 році
- ✔️ Простий текстовий PDF (звіти, книги, контракти без складних таблиць): PyMuPDF — швидко і безкоштовно.
- ✔️ PDF з простими таблицями: pdfplumber або Docling.
- ✔️ Складні документи (фінанси, наука, багатоколонка, діаграми): LlamaParse (найкраща структура) або Docling (відкритий, точний).
- ✔️ Максимальна сумісність і немає бюджету: починайте з PyMuPDF + pdfplumber, але будьте готові до ручного доопрацювання.
Висновок :
Замінити PyPDF на PyMuPDF — найпростіша швидка перемога.
Але для серйозного RAG з високою точністю відповідей переходьте на LlamaParse або Docling — це дає найбільший приріст якості на складних PDF без величезних зусиль з боку розробника.
Порада: Я зазвичай починаю з діагностики PDF (див. Розділ 2). Якщо документ простий — використовую класику. Якщо є таблиці, колонки або бачу «розірваний» текст — одразу тестую LlamaParse або Docling.
📌 Скановані PDF і OCR: коли потрібен і як визначити
OCR для сканованих PDF
OCR потрібен тільки якщо ваш PDF — це скановане зображення без текстового шару. Перевірте це перед установкою: якщо PyMuPDF повертає менше 100 символів зі сторінки — швидше за все потрібен OCR. Для простих кейсів підійде Tesseract, для кращої якості на складних документах — EasyOCR.
Не встановлюйте OCR "про всяк випадок". Tesseract додає складність пайплайну і збільшує час обробки в 5–20 разів порівняно з текстовим парсингом.
Як визначити, чи потрібен OCR
import fitz
def needs_ocr(pdf_path, threshold=100):
doc = fitz.open(pdf_path)
chars_per_page = []
for page in doc:
chars_per_page.append(len(page.get_text()))
avg = sum(chars_per_page) / len(chars_per_page)
return avg < threshold
# Використання:
if needs_ocr("my_document.pdf"):
print("→ Потрібен OCR (Tesseract або EasyOCR)")
else:
print("→ Текстовий PDF, OCR не потрібен")
Tesseract vs EasyOCR: коли який
|
Tesseract |
EasyOCR |
| Швидкість |
Швидший |
Повільніший |
| Якість на чистих сканах |
✅ Добра |
✅ Відмінна |
| Рукописний текст |
❌ |
⚠️ Частково |
| Установка |
Системна залежність + pytesseract |
pip install easyocr |
Мінімальний приклад з Tesseract (офіційна документація Tesseract):
from pdf2image import convert_from_path
import pytesseract
pages = convert_from_path("scanned.pdf", dpi=300)
full_text = ""
for page in pages:
full_text += pytesseract.image_to_string(page, lang="ukr+eng")
print(full_text[:500])
⚠️ Важливо: OCR на складних документах (таблиці, діаграми, мішана розмітка) дає значно гіршу якість. Для таких кейсів — дивіться статтю
1.5 Advanced ETL, де розглядаються LlamaParse і Docling.
Висновок: OCR потрібен рідше, ніж здається — спочатку перевірте наявність текстового шару, потім вирішуйте.
📌 Таблиці в PDF: чому звичайний парсер ламається
таблиці в PDF
PDF не має нативного поняття "таблиця" — це просто набір текстових об'єктів з координатами. Звичайний парсер витягує їх у довільному порядку, втрачаючи структуру рядок-колонка. Для таблиць використовуйте pdfplumber з методом extract_table().
Якщо ваш PDF містить таблиці — половина туторіалів на Medium вам не підходять. Вони показують результат на статичному тексті.
Що отримує PyPDF з таблиці
Уявіть таблицю: Назва | Ціна | Кількість. PyPDF часто повертає:
"НазваЦінаКількість Продукт А 500 10 Продукт Б 750 5"
Замість структурованого тексту — каша. LLM намагатиметься відповісти на ваше питання "яка ціна продукту Б?" — і помилиться.
Як правильно витягти таблицю через pdfplumber
import pdfplumber
with pdfplumber.open("report.pdf") as pdf:
for page in pdf.pages:
tables = page.extract_tables()
for table in tables:
for row in table:
# Перетворюємо рядок таблиці на читабельний текст
row_text = " | ".join([cell or "" for cell in row])
print(row_text)
Це дає вам структурований текст у форматі Продукт Б | 750 | 5, який LLM розуміє правильно. Детальніше про роботу з таблицями, діаграмами та складними документами — у статті 1.5 Advanced ETL: мультимодальний ingestion.
Висновок: таблиці — найпоширеніша причина поганих відповідей у RAG; pdfplumber вирішує проблему для більшості кейсів.
💼 Практичний туторіал: PDF → Q&A (два варіанти)
Що ви побудуєте
Два повних пайплайни: варіант A — швидкий старт через OpenAI API (займає ~10 хвилин, коштує ~$0.01 на тест), варіант B — локальний через Ollama (безкоштовно, конфіденційно, але потребує 8+ GB RAM).
👉 Детально про локальний RAG з Ollama:
повний гайд від пайплайну до продакшну
Встановлення залежностей
pip install pymupdf chromadb openai langchain-openai langchain-community
Для локального варіанту додатково — встановіть Ollama і завантажте модель:
ollama pull nomic-embed-text # embedding модель
ollama pull qwen2.5:7b # або llama3.2, mistral
Варіант A: Fast Start (OpenAI)
import fitz # PyMuPDF
import chromadb
import os
from chromadb.utils import embedding_functions
from langchain_openai import ChatOpenAI
from langchain.text_splitter import RecursiveCharacterTextSplitter
# --- Крок 1: Витягуємо текст ---
def extract_text(pdf_path):
doc = fitz.open(pdf_path)
return "\n".join(page.get_text() for page in doc)
# --- Крок 2: Розбиваємо на чанки ---
def split_text(text):
splitter = RecursiveCharacterTextSplitter(
chunk_size=800, # символів у чанку
chunk_overlap=100, # перекриття між чанками
separators=["\n\n", "\n", ". ", " "]
)
return splitter.split_text(text)
# --- Крок 3: Зберігаємо у vector DB ---
def build_index(chunks, collection_name="pdf_rag"):
client = chromadb.Client()
# Використовуємо функцію ембеддінгів OpenAI для Chroma
openai_ef = embedding_functions.OpenAIEmbeddingFunction(
api_key=os.environ["OPENAI_API_KEY"],
model_name="text-embedding-3-small"
)
collection = client.create_collection(
name=collection_name,
embedding_function=openai_ef
)
# Додаємо тексти (Chroma сама векторизує їх через API)
collection.add(
documents=chunks,
ids=[f"chunk_{i}" for i in range(len(chunks))]
)
return collection
# --- Крок 4: Q&A ---
def ask(question, collection, top_k=4):
# Пошук виконується через query_texts (база сама зробить ембеддінг питання)
results = collection.query(query_texts=[question], n_results=top_k)
context = "\n---\n".join(results["documents"][0])
llm = ChatOpenAI(model="gpt-4o-mini", api_key=os.environ["OPENAI_API_KEY"])
prompt = f"""Відповідай ТІЛЬКИ на основі наданого контексту.
Якщо відповіді немає в контексті — скажи про це чесно.
Контекст:
{context}
Питання: {question}"""
return llm.invoke(prompt).content
# --- Запуск ---
text = extract_text("your_document.pdf")
chunks = split_text(text)
print(f"Чанків: {len(chunks)}, перший: {chunks[0][:100]}...")
collection = build_index(chunks)
answer = ask("Яка загальна сума договору?", collection)
print(answer)
Варіант B: Локально через Ollama (приватно та безкоштовно)
import fitz
import chromadb
from chromadb.utils import embedding_functions
from langchain_community.llms import Ollama
from langchain.text_splitter import RecursiveCharacterTextSplitter
# Витягування тексту — те саме, що у варіанті A
def extract_text(pdf_path):
doc = fitz.open(pdf_path)
return "\n".join(page.get_text() for page in doc)
def split_text(text):
splitter = RecursiveCharacterTextSplitter(
chunk_size=800, chunk_overlap=100,
separators=["\n\n", "\n", ". ", " "]
)
return splitter.split_text(text)
# Ollama-embeddings (локально)
def build_index_local(chunks, collection_name="pdf_rag_local"):
client = chromadb.Client()
ollama_ef = embedding_functions.OllamaEmbeddingFunction(
model_name="nomic-embed-text",
url="http://localhost:11434/api/embeddings",
)
collection = client.create_collection(
name=collection_name,
embedding_function=ollama_ef
)
collection.add(
documents=chunks,
ids=[f"chunk_{i}" for i in range(len(chunks))]
)
return collection
def ask_local(question, collection, top_k=4):
results = collection.query(query_texts=[question], n_results=top_k)
context = "\n---\n".join(results["documents"][0])
llm = Ollama(model="qwen2.5:7b") # або llama3.2, mistral
prompt = f"""Відповідай ТІЛЬКИ на основі наданого контексту.
Якщо відповіді немає — скажи про це чесно.
Контекст:
{context}
Питання: {question}"""
return llm.invoke(prompt)
# --- Запуск ---
text = extract_text("your_document.pdf")
chunks = split_text(text)
collection_local = build_index_local(chunks)
answer = ask_local("Яка загальна сума договору?", collection_local)
print(answer)
⚠️ Chunking у цьому туторіалі: chunk_size=800 і chunk_overlap=100 — робочі значення для більшості текстових PDF. Якщо відповіді неточні — спробуйте 400–600 символів (більша деталізація) або 1000–1200 (більше контексту). Детальна логіка підбору параметрів — у статті
1.3 Chunking Strategies.
Висновок: обидва варіанти — робочий baseline. Якщо відповіді погані — переходьте до debugging нижче, а не змінюйте модель.
💼 Розділ 7. Debugging: чому відповіді погані
Як я діагностую проблему
Перед тим як звинувачувати LLM, я зазвичай перевіряю чанки самостійно. Друкую перші 5 чанків і читаю їх очима. Якщо вони виглядають нечитабельно — проблема у парсингу, а не в моделі.
Золоте правило дебагінгу RAG: якщо LLM бачить сміття — вона генерує сміття. Garbage in, garbage out.
Симптом → Причина → Рішення
| Симптом |
Найімовірніша причина |
Рішення |
| "Я не знайшов інформації" |
Парсинг повернув порожній або спотворений текст |
Надрукуйте extract_text(), перевірте output |
| Відповідь є, але неправильна |
Не той чанк потрапив у контекст |
Надрукуйте results["documents"][0], перевірте релевантність |
| Плутає числа з таблиць |
Таблиця спаршена з помилками |
Перейти на pdfplumber з extract_table() |
| Відповідь обривається / неповна |
Чанки занадто малі, інфо розбита між ними |
Збільшити chunk_size до 1000–1200 або chunk_overlap до 150–200 |
| Текст виглядає як "FiRsT PaGe HeAdEr 2 3 4" |
PDF зі сканованими сторінками або нестандартним кодуванням |
OCR (Tesseract) або PyMuPDF з flags=fitz.TEXT_PRESERVE_LIGATURES |
| Колонтитули та номери сторінок потрапляють у чанки |
PDF не розмежовує контент і службові елементи |
Фільтрувати короткі рядки: if len(line) > 40 |
Швидка перевірка якості чанків
# Запустіть це ПЕРЕД побудовою індексу
chunks = split_text(text)
print(f"Кількість чанків: {len(chunks)}")
print(f"Середня довжина: {sum(len(c) for c in chunks) / len(chunks):.0f} символів")
print("\n--- Перші 3 чанки ---")
for i, chunk in enumerate(chunks[:3]):
print(f"\n[Чанк {i}]:\n{chunk[:300]}\n{'='*40}")
# Якщо чанки виглядають нормально — проблема в пошуку або LLM
# Якщо виглядають як каша — проблема в парсингу
Висновок: у 80% випадків проблема з якістю відповідей вирішується на рівні парсингу або розміру чанків, без зміни LLM.
💼 Розділ 8. Чеклист "PDF готовий для RAG"
що перевірити перед запуском
Пройдіться по чеклисту після парсингу і до побудови індексу. Це заощадить час на дебагінг після того, як все вже побудовано.
Парсинг
- ☐ Визначив тип PDF (текстовий / сканований / гібрид)
- ☐ Обрав правильний парсер (PyMuPDF для тексту, pdfplumber для таблиць)
- ☐ Переглянув перші 500 символів витягнутого тексту — виглядає читабельно
- ☐ Якщо є таблиці — перевірив
extract_table() на pdfplumber
- ☐ Якщо сканований — OCR запущений, результат перевірений
Чанки
- ☐ Надрукував перші 3–5 чанків, прочитав їх очима
- ☐ Середня довжина чанку: 500–1000 символів (не 50, не 3000)
- ☐ Чанки не починаються і не закінчуються посередині речення (або це прийнятно для вашого кейсу)
- ☐ Колонтитули, номери сторінок, службові символи відфільтровані або не заважають
Пошук (retrieval)
- ☐ Зробив тестовий запит і надрукував результати —
results["documents"][0]
- ☐ Перевірив, що знайдені чанки справді відповідають питанню
- ☐ top_k = 3–5 (не 1 — занадто мало контексту, не 15 — зашум)
Відповідь
- ☐ Промпт містить інструкцію "відповідай тільки на основі контексту"
- ☐ Протестував 5–10 питань вручну
- ☐ Перевірив поведінку на питання, відповіді на яке немає в документі
❓ Часті питання (FAQ)
Яка різниця між RAG для PDF і "Chat with PDF" сервісами на кшталт ChatPDF?
ChatPDF, Adobe AI, Notion AI — це готові продукти, які роблять те саме під капотом: парсинг → embeddings → retrieval → LLM. Будуючи RAG самостійно, ви контролюєте кожен крок, можете використовувати локальні моделі для конфіденційних документів і підлаштовувати параметри під свій тип PDF.
Скільки коштує обробити один PDF через OpenAI?
Для документа на 50 сторінок (~25 000 слів): embedding через text-embedding-3-small — менше $0.01. Кожне питання (4 чанки по 800 символів + відповідь через gpt-4o-mini) — ~$0.001–0.003. Тобто 100 питань по одному документу коштують менше $0.30.
Чи можна обробити одночасно кілька PDF?
Так. Просто обробляйте кожен файл у циклі і зберігайте всі чанки в одну колекцію ChromaDB. Для кращого пошуку додайте metadata з назвою файлу: collection.add(..., metadatas=[{"source": filename}]). Так ви зможете фільтрувати відповіді по конкретному документу.
Чому Ollama дає гірші відповіді, ніж GPT-4o?
Локальні моделі (Qwen 2.5 7B, Llama 3.2, Mistral 7B) дають 60–75% якості від GPT-4o на більшості RAG-задач. Це нормально: менша модель = менші можливості інструювання. Якщо якість критична — використовуйте OpenAI або Anthropic API. Якщо критична приватність — Ollama. Детальне порівняння: RAG з Ollama.
Мій PDF захищений паролем — що робити?
PyMuPDF підтримує розшифрування: doc.authenticate("password") перед витяганням тексту. Якщо пароль невідомий — парсинг неможливий без спеціалізованих інструментів.
✅ Висновки
- 🔹 Визначте тип вашого PDF (текстовий / сканований / з таблицями) — від цього залежить вибір парсера
- 🔹 Замініть PyPDF на PyMuPDF для тексту або pdfplumber для таблиць — це найпростіше покращення якості
- 🔹 Перед побудовою індексу завжди перевіряйте чанки очима — 5 хвилин діагностики заощаджують години дебагінгу
- 🔹 Для швидкого старту — OpenAI API; для приватності та безкоштовно — Ollama з nomic-embed-text
- 🔹 Якщо відповіді погані — спочатку перевірте парсинг і чанки, а не замінюйте LLM
Головна думка: RAG для PDF — це не магія LLM, а інженерія витягування тексту; побудуйте правильний парсинг — і якість відповідей з'явиться сама собою.
👉 Якщо хочете глибше зрозуміти, як працює сама LLM (токени, трансформери, embeddings):
детальне пояснення тут
Пов'язані статті:
1.3 Chunking Strategies ·
1.4 Embedding Models ·
RAG від PoC до production ·
1.1 RAG з Ollama ·
Ollama: що це таке ·
Vector Search для початківців: як RAG знаходить потрібну інформацію