La mayoría de las reseñas de herramientas RAG son catálogos. Listas con nombres, estrellas en GitHub y la frase "adecuado para diversas tareas". No responden a la pregunta principal: ¿qué debo elegir exactamente para mi tarea, con mis limitaciones?
He construido deliberadamente este artículo de manera diferente a la mayoría de las reseñas. Cada sección es una solución, no una descripción. Para cada herramienta, doy un escenario específico: cuándo usarla y cuándo evitarla, sin vagos "depende de la tarea". Al final, hay pilas listas para cinco tareas típicas y antipatrones que he visto personalmente una y otra vez: le cuestan a los equipos semanas de refactorización y, por lo general, no se mencionan en los tutoriales.
Frameworks de orquestación: LangChain, LlamaIndex, DSPy, Haystack — tabla de compensaciones
Un framework de orquestación es el "cerebro" de tu pipeline RAG. Conecta el modelo, la base de datos vectorial, los documentos y la lógica de consulta. Una buena elección te permite construir un pipeline en días; una mala, refactorizarlo en un mes cuando los requisitos crezcan.
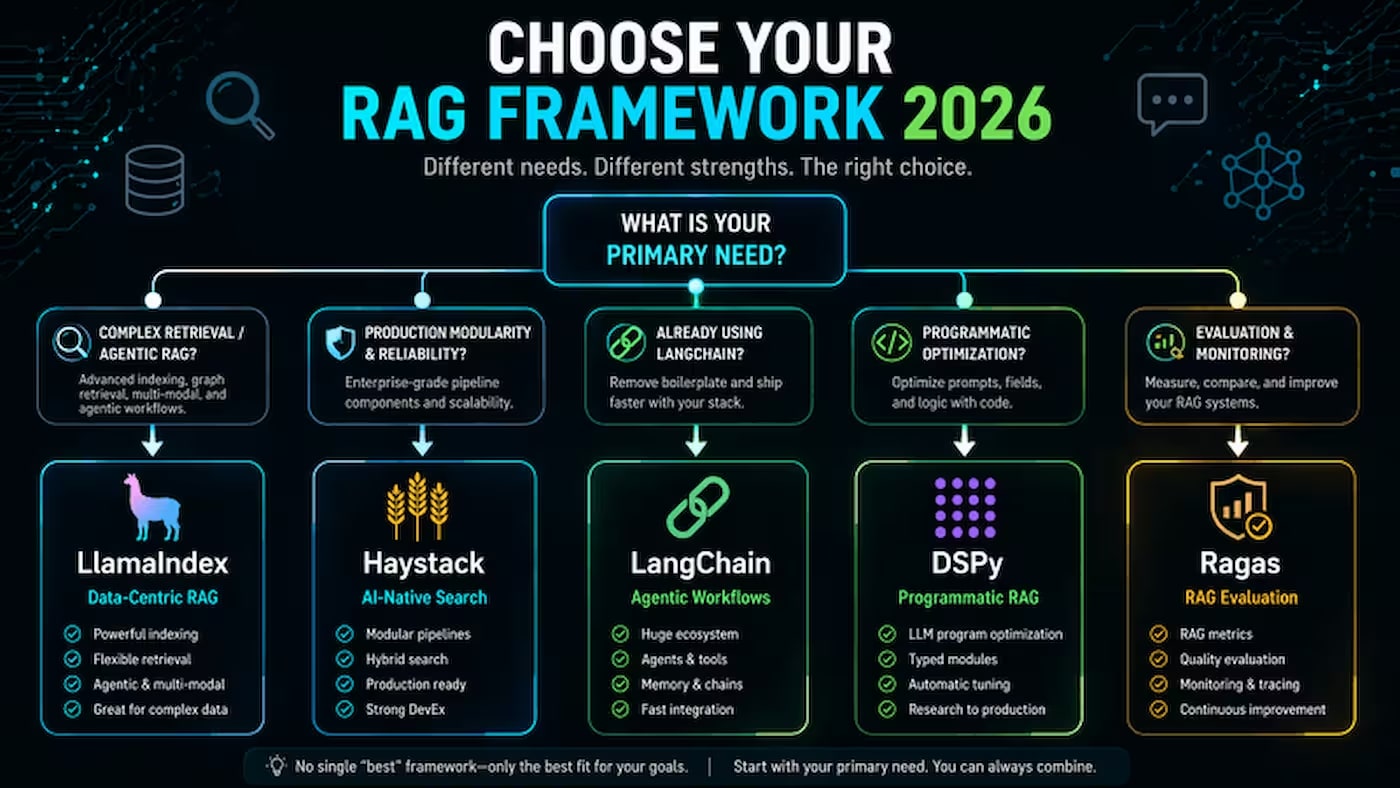
En mi opinión, hay dos filosofías fundamentalmente diferentes aquí. LangChain y Haystack son orquestadores universales: adecuados para una amplia gama de tareas, pero no optimizados para ninguna en particular. LlamaIndex y DSPy son herramientas especializadas con una clara especialización: LlamaIndex para la recuperación, DSPy para la optimización automática de prompts. Recomendaría comenzar por comprender esta división, ya que inmediatamente reduce la elección a la mitad.
✅ Elige si: estás construyendo sistemas multiagente complejos con herramientas, memoria y bucles; necesitas la máxima flexibilidad de integración; el equipo crecerá y es importante que los nuevos desarrolladores encuentren rápidamente respuestas en la documentación y Stack Overflow.
❌ Evita si: la tarea principal es Q&A sobre un gran archivo de documentos (LlamaIndex es más preciso); el presupuesto de tiempo es limitado y necesitas un inicio rápido sin luchar contra las abstracciones; la previsibilidad del pipeline es críticamente importante (los frecuentes cambios disruptivos en LangChain son un problema conocido).
⚠️ Error común: elegir LangChain "porque todos lo hacen", pero si el 80% de la tarea es la recuperación de documentos, es una complejidad excesiva. Un análisis comparativo de 2026 muestra: LlamaIndex ofrece un 35% mejor recuperación y es un 40% más rápido que LangChain en tareas de documentos.
LlamaIndex
GitHub — más de 44.000 estrellas, más de 300 conectores de datos a través de LlamaHub.
❌ Evita si: necesitas un sistema agente complejo con bucles y lógica ramificada (LangGraph es mejor); el equipo busca la mayor cantidad de tutoriales y ejemplos listos para usar disponibles públicamente.
💡 Desde mi experiencia: LlamaIndex y LangChain rara vez compiten, se usan juntos con más frecuencia. LlamaIndex se encarga de la capa de recuperación, LangGraph (parte del ecosistema LangChain) — de la orquestación de agentes. Veo este patrón como uno de los más comunes en sistemas de producción de 2026, y si estás construyendo algo más serio que un simple chatbot Q&A, deberías considerar esta combinación.
GitHub — más de 20.000 estrellas. Un framework de deepset construido alrededor de pipelines modulares.
✅ Elige si: el equipo valora una arquitectura limpia y predecible por encima del tamaño del ecosistema; la tarea es un sistema de producción en un entorno regulado (finanzas, medicina, sector legal), donde la auditabilidad y la estabilidad de la API son importantes; ya tienes experiencia con NLP empresarial y necesitas madurez, no "magia".
❌ Evita si: estás comenzando un nuevo proyecto y necesitas muchos ejemplos y soluciones listas para usar; la tarea es RAG con agentes y planificación dinámica (Haystack es más débil que LangGraph en esto).
DSPy (Stanford NLP)
GitHub — más de 23.000 estrellas. En lugar de escribir prompts manualmente, DSPy los optimiza automáticamente para una tarea y métrica específicas.
✅ Elige si: tienes un conjunto de datos etiquetado de preguntas y respuestas para optimizar; la tarea está bien definida y necesitas extraer la máxima calidad de un corpus específico; estás dispuesto a invertir tiempo en una curva de aprendizaje pronunciada.
❌ Evita si: necesitas un prototipo rápido; no tienes un conjunto de datos etiquetado para la optimización; el equipo no tiene experiencia en aprendizaje automático — DSPy es el más complejo de esta lista.
Tabla de compensaciones: frameworks
Framework
GitHub ⭐
Calidad de recuperación
Agentes
Umbral de entrada
Mejor escenario
LangChain
119.000+
Buena (~85%)
⭐⭐⭐⭐⭐ (LangGraph)
Medio
Sistemas multiagente, cadenas complejas
LlamaIndex
44.000+
Excelente (~92%)
⭐⭐⭐
Bajo
Q&A sobre documentos, bases de conocimiento corporativas
Haystack
20.000+
Buena
⭐⭐
Medio
Producción empresarial, industrias reguladas
DSPy
23.000+
Máxima (con dataset)
⭐⭐
Muy alto
Optimización de calidad en una tarea específica
Bases de datos vectoriales: comparación de Qdrant, Milvus, Weaviate, pgvector, ChromaDB
Una base de datos vectorial es el corazón de RAG, y estoy convencido de que es aquí donde los equipos toman decisiones equivocadas con más frecuencia. Almacena embeddings y es responsable de la velocidad y calidad de la búsqueda, pero generalmente se elige por el número de estrellas en GitHub, no por lo que realmente importa. En mi opinión, tres criterios lo resuelven todo: la escala de tu corpus, la necesidad de búsqueda híbrida y las capacidades operativas del equipo. Si respondes honestamente a estas tres preguntas, la elección se vuelve obvia sin necesidad de benchmarks.
Antes de profundizar en las bases de datos específicas, familiarízate con cómo funciona la búsqueda vectorial internamente: Búsqueda vectorial para principiantes.
Qdrant
GitHub — más de 20.000 estrellas. Escrito en Rust. La base de datos vectorial open-source más rápida en producción.
✅ Elige si: necesitas un sistema de producción para una colección de 1M a ~100M de vectores; la velocidad máxima es importante — Qdrant es un 10-25% más rápido que Weaviate y Milvus en cargas de trabajo típicas, latencia p99 con 10M de vectores ~12ms frente a 16ms en Weaviate y 18ms en Milvus; necesitas búsqueda híbrida (sparse + dense) y filtrado flexible por metadatos; el equipo quiere autoalojamiento sin vendor lock-in.
❌ Evita si: ya utilizas PostgreSQL y la colección es inferior a 5M de vectores — pgvector es más simple; necesitas una escala superior a mil millones de vectores (Milvus es mejor).
Milvus
GitHub — más de 33.000 estrellas. Arquitectura distribuida, Go/C++, nativo de Kubernetes.
✅ Elige si: el conjunto de datos crecerá a cientos de millones o miles de millones de vectores; tienes un equipo de ingeniería de datos que puede asumir la complejidad operativa; necesitas escalabilidad horizontal con almacenamiento en niveles (caliente/tibio/frío).
GitHub — más de 11.000 estrellas. Go, API GraphQL, módulos de vectorización integrados.
✅ Elige si: la búsqueda híbrida (vectores + palabras clave + filtros estructurales) es el requisito principal; necesitas una API GraphQL para consultas complejas; estás construyendo un producto SaaS y necesitas multi-tenancy con aislamiento de datos entre clientes.
❌ Evita si: el equipo es nuevo en bases de datos vectoriales — Weaviate tiene una curva de aprendizaje más pronunciada debido a su modelo de esquema y sistema modular; los recursos son limitados — el autoalojamiento de Weaviate requiere más RAM que Qdrant con el mismo conjunto de datos.
pgvector
GitHub — más de 13.000 estrellas. Extensión para PostgreSQL. La versión 0.9 (2026) añadió vectores sparse y HNSW mejorado.
✅ Elige si: ya utilizas PostgreSQL y quieres una complejidad arquitectónica mínima; la colección es inferior a 5-10M de vectores; necesitas consistencia transaccional entre datos vectoriales y relacionales. Yo mismo a menudo elijo esta opción, especialmente cuando un proyecto ya se basa en PostgreSQL y añadir un servicio separado solo para la búsqueda vectorial simplemente no tiene sentido. pgvector resuelve la tarea de manera elegante y sin infraestructura adicional en tales casos.
GitHub — más de 16.000 estrellas. Almacenamiento en memoria o local, pip install y listo.
✅ Elige si: estás prototipando, aprendiendo, probando una hipótesis. ChromaDB es el inicio más rápido: de cero a la primera consulta RAG en 15 minutos.
❌ Evita en producción: no tiene HA, snapshots, ni monitorización de grado de producción. Si empiezas con Chroma, planifica inmediatamente la migración a Qdrant o Weaviate.
Tabla de compensaciones: bases de datos vectoriales
BD
Idioma
Búsqueda Híbrida
Escala Óptima
Autoalojada
Cuándo usarla
Qdrant
Rust
✅ Nativo
1M – 100M vectores
Fácil
Producción con búsqueda híbrida, crítica en velocidad
Milvus
Go/C++
✅ Nativo
100M – miles de millones
Difícil (K8s)
Escala empresarial, aceleración GPU
Weaviate
Go
✅ BM25 + dense
1M – 50M vectores
Medio
Multi-tenancy SaaS, API GraphQL
pgvector
C (ext. PostgreSQL)
⚠️ Parcial
hasta 5–10M vectores
Si ya tienes PostgreSQL
Ya tienes Postgres, escala pequeña
ChromaDB
Python
❌
hasta 100K vectores
Trivial
Solo prototipos y aprendizaje
⚠️ Error común de la sección: elegir Milvus "porque es el más complejo y, por lo tanto, el mejor". Con una colección de menos de 50M de vectores, la complejidad operativa de Milvus es una pérdida pura de tiempo sin mejora en la calidad. Qdrant cubre el 90% de los escenarios de producción con una configuración mínima.
Plataformas todo en uno: RAGFlow, Dify, LightRAG, AnythingLLM
Las plataformas todo en uno no son frameworks para desarrolladores, sino productos listos para usar. Se encargan de todo el pipeline: carga de documentos, chunking, embedding, base de datos vectorial, generación. El precio es menor flexibilidad. Si tu tarea es lanzar RAG rápidamente sin escribir código, esta es la elección correcta.
Dify
GitHub — más de 90.000 estrellas. El proyecto de IA de más rápido crecimiento de 2025.
✅ Elige si: tienes un equipo sin experiencia en ML, necesitas un MVP rápido o un chatbot interno; quieres un editor visual de arrastrar y soltar para pipelines sin código; necesitas soporte para más de 100 proveedores de LLM "listos para usar".
❌ Evita si: necesitas un control profundo sobre el chunking y la recuperación (RAGFlow es mejor); la máxima precisión en documentos complejos (PDF con tablas, contratos legales) es crítica.
RAGFlow
GitHub — más de 48.000 estrellas. Se especializa en la comprensión profunda de documentos.
✅ Elige si: el corpus son archivos PDF complejos (tablas, fórmulas, marcado mixto); necesitas una visualización transparente de cómo se divide el documento en chunks; quieres un RAG autoalojado con control total y una API REST para la integración.
❌ Evita si: los recursos son limitados — RAGFlow requiere Elasticsearch + Infinity DB, el consumo de RAM es considerable; la tarea es un prototipo rápido, no la calidad del análisis.
GitHub — más de 14.600 estrellas. De la Universidad de Hong Kong. Combina grafos de conocimiento y búsqueda vectorial.
✅ Elige si: los documentos están llenos de relaciones entre entidades (documentación médica, actos legales, especificaciones técnicas); necesitas un framework ligero sin infraestructura pesada — se instala a través de pip install lightrag-hku; el soporte para la actualización incremental del índice es importante.
❌ Evita si: la tarea principal es un simple Q&A sobre un gran archivo de documentos del mismo tipo sin relaciones complejas entre entidades.
AnythingLLM
Sitio web. Aplicación de escritorio para RAG local con integración de Ollama.
✅ Elige si: quieres un RAG completamente privado sin ninguna API en la nube; configuras una base de conocimiento personal en un portátil con modelos locales (DeepSeek-R1, Qwen3); el equipo no es técnico y necesita una UI sencilla.
❌ Evita si: necesitas escalabilidad, una API para sistemas externos o trabajo en equipo — AnythingLLM está diseñado para uso individual.
Búsqueda orientada a grafos, relaciones entre entidades
AnythingLLM
—
✅ UI de escritorio
Básica
Mínimos
RAG local, privacidad, uso individual
⚠️ Error típico: lanzar Dify para una solución corporativa seria y sorprenderse de que la precisión de la recuperación en PDF complejos con tablas sea baja. Dify está optimizado para un inicio rápido, no para una calidad de análisis máxima. Si la calidad de la recuperación es la métrica clave, empieza con RAGFlow o un analizador de documentos independiente.
Evaluación de la calidad RAG: RAGAS, DeepEval, Langfuse
Mi consejo: no repitas el error que veo en casi todos los equipos: construyen RAG, lo lanzan y ahí termina todo. Ninguna métrica de evaluación. Es exactamente lo mismo que desarrollar un producto sin métricas ni análisis — simplemente no sabes qué se rompió cuando algo salió mal, y no puedes demostrar que mejoró después de la optimización. Siempre digo: la evaluación no es el paso final, es parte del pipeline desde el primer día.
GitHub — más de 5.000 estrellas. Enfoque "pytest para LLM". Más de 50 métricas, incluyendo seguridad y sesgo.
✅ Elige para: puerta de calidad CI/CD — bloquea la fusión de PR si la calidad RAG cae por debajo del umbral; pruebas sistemáticas a nivel de pruebas unitarias; equipos que construyen no solo RAG, sino también agentes, sistemas multi-turno.
❌ Limitaciones: más complejo de configurar que RAGAS; integración más estrecha con frameworks RAG "listos para usar".
Langfuse
GitHub. Observabilidad de LLM de código abierto: tracing, dashboards, monitorización de producción. Autoalojado o en la nube gestionada.
✅ Elige para: monitorización en tiempo real de RAG en producción — ves cada solicitud, latencia, coste, puntuación de calidad; almacenamiento y análisis de traces de RAGAS y DeepEval en un solo lugar.
⚠️ Error típico de la sección: omitir la evaluación por completo. "Vemos que las respuestas son buenas" — esto no es una métrica. Sin RAGAS, no sabes qué mejoró después de cambiar el tamaño del chunk, y no notas la degradación después de actualizar el modelo de embedding. Como mínimo, ejecuta RAGAS en 50-100 consultas de prueba una vez a la semana.
Pilas listas para 5 escenarios: de PoC a enterprise
En lugar de "recomendamos LangChain + Qdrant", pilas específicas para limitaciones específicas. Donde sea necesario, con alternativas.
Escenario 1: Primer prototipo / prueba de hipótesis
Tarea: en 1-2 días, verificar si RAG es adecuado para su corpus de documentos.
Framework: LlamaIndex o Dify
Base de datos vectorial: ChromaDB (en memoria)
Embedding: text-embedding-3-small o nomic-embed-text (Ollama)
LLM: GPT-4o-mini o Qwen3:8b localmente
Evaluación: verificación manual de 20-30 consultas
Escenario 5: Escala empresarial (>1 millón de documentos, SLA de producción)
Tarea: gran sistema corporativo, decenas de millones de vectores, requisitos de latencia y tiempo de actividad.
Framework: LangChain + LangGraph (para lógica de agente) o Haystack (para industrias reguladas)
Base de datos vectorial: Milvus (>100 millones de vectores) o Qdrant (hasta 100 millones)
Embedding: Qwen3-Embedding-8B (autoalojado, Apache 2.0) — mejor MTEB en 2026
Recuperación: híbrida + reranking de dos etapas obligatorio
Evaluación: DeepEval en CI, RAGAS como trabajo cron, Langfuse para tracing
Observabilidad: Langfuse o LangSmith
Lo que no se menciona en las revisiones: anti-patrones y errores comunes
La mayoría de las revisiones describen el camino feliz. Aquí está lo que realmente rompe los sistemas RAG, y de lo que no se habla en los tutoriales.
Anti-patrón 1: Empezar la optimización con la elección de la herramienta, no con la calidad de los datos
El error más caro. El equipo pasa un mes comparando LangChain y LlamaIndex, elige Qdrant en lugar de Weaviate, y la recuperación sigue siendo mala porque los PDF de entrada están escaneados, los artefactos de OCR distorsionan los embeddings.
ChromaDB es una excelente herramienta para prototipos. Pero los equipos la dejan regularmente en producción "porque funciona". Sí, hasta 100K documentos, funciona. Con 1 millón de documentos y varias consultas paralelas, se enfrentará a una degradación del rendimiento y a la falta de HA. La migración posterior es dolorosa. Planifíquela desde el primer día.
Anti-patrón 3: Recuperación densa pura sin híbrida
Anti-patrón 4: "Un modelo de embedding más grande resolverá el problema de recuperación"
Pasar de text-embedding-3-small (1536) a text-embedding-3-large (3072) da un aumento de ~8.5% en MTEB Retrieval y cuesta 6.5 veces más por API + el doble por almacenamiento. Al mismo tiempo, agregar recuperación híbrida y reranker sin cambiar el modelo da un Recall de +39%. Invierta en la arquitectura de recuperación, no en la dimensionalidad del vector. Justificación detallada: 1536 vs 3072: comparación para RAG.
Anti-patrón 5: Ignorar la evaluación de la calidad hasta el primer incidente
"Lanzamos RAG y las respuestas se ven bien", una postura común hasta el primer caso en que el sistema dio una alucinación segura en una consulta importante del cliente. Sin RAGAS o DeepEval, no conoce el nivel de fidelidad, precisión del contexto y relevancia de la respuesta. Configure una evaluación mínima antes del lanzamiento, no después del incidente. El costo de la evaluación básica con GPT-4o-mini es de ~$0.001-0.003 por caso de prueba. Es el seguro más barato contra errores graves.
Anti-patrón 6: Milvus para colecciones pequeñas
Milvus es la elección correcta para cientos de millones de vectores y la presencia de un equipo de ingeniería de datos. Para colecciones de hasta 50 millones de vectores, esta complejidad operativa es una carga innecesaria sin un beneficio medible en calidad. Qdrant en un solo servidor cubre la mayoría de los escenarios de producción con una configuración mínima.
Resumen: cómo tomar una decisión
Quiero terminar honestamente: la elección de una pila RAG no es la búsqueda de la "mejor herramienta en general". Tal cosa no existe. Es una respuesta a cinco preguntas específicas de su proyecto. He visto equipos que pasaban semanas comparando frameworks y obtenían malos resultados porque no respondieron a estas preguntas antes de empezar a elegir.
¿Cuál es la calidad de los datos de entrada? Esto es lo primero que compruebo siempre. Si los PDF están escaneados, el texto está sucio después del OCR, los documentos carecen de estructura, ningún framework lo arreglará. LlamaIndex no salvará un mal análisis. Empiece por la calidad de los datos de entrada, no por la elección de la herramienta.
¿Cuál es la escala de su corpus? Esta es una pregunta técnica con una respuesta clara. Hasta 10 millones de vectores: pgvector o Qdrant, y esto es más que suficiente. Más de 100 millones: solo Milvus. Entre estos valores, Qdrant cubre la mayoría de las tareas sin complejidad operativa innecesaria.
¿Necesita búsqueda híbrida? Si su corpus contiene términos exactos, números de artículo, nombres de métodos, valores numéricos, la búsqueda híbrida es obligatoria. Entonces Weaviate o Qdrant. ChromaDB no es adecuado para esto en absoluto, y le recomiendo que no intente adaptarlo.
¿Cuál es la experiencia en ML del equipo? Esta es una pregunta que la gente se avergüenza de hacer, pero lo resuelve todo. Si el equipo no es técnico o necesita un inicio rápido, Dify o AnythingLLM darán resultados en un día. Si hay ingenieros experimentados y la tarea es seria, LlamaIndex con Qdrant y búsqueda híbrida darán una calidad significativamente mejor.
¿Mide la calidad del sistema? Si no, deténgase. No elija un nuevo framework, no cambie el modelo de embedding. El primer paso debe ser RAGAS con 50-100 consultas de prueba. Sin mediciones, no sabe qué mejorar, y cualquier optimización se convierte en una adivinanza.
Mi enfoque personal: siempre empiezo con la pila más simple que cubre la tarea actual, mido la calidad a través de RAGAS, y solo cuando hay un déficit medible específico, agrego complejidad. La peor decisión es construir inmediatamente una pila empresarial para una tarea que se resuelve con LlamaIndex y pgvector durante el fin de semana.
Más detalles sobre cada capa del pipeline en los artículos correspondientes de la serie: