Die meisten RAG-Tool-Reviews sind Kataloge. Listen mit Namen, GitHub-Sternen und der Zeile „für verschiedene Aufgaben geeignet“. Sie beantworten nicht die Hauptfrage: Was genau soll ich für meine Aufgabe mit meinen Einschränkungen wählen?
Ich habe diesen Artikel bewusst anders aufgebaut als die meisten Reviews. Jeder Abschnitt ist eine Lösung, keine Beschreibung. Für jedes Tool gebe ich ein konkretes Szenario an: wann man es verwenden sollte und wann man es vermeiden sollte – ohne vage „kommt auf die Aufgabe an“. Am Ende gibt es fertige Stacks für fünf typische Aufgaben und Anti-Patterns, die ich persönlich schon oft gesehen habe: Sie kosten Teams Wochen an Nacharbeit und werden normalerweise nicht in Tutorials erwähnt.
Ein Orchestrierungs-Framework ist das „Gehirn“ Ihrer RAG-Pipeline. Es verbindet das Modell, die Vektor-Datenbank, Dokumente und die Abfragelogik. Eine gute Wahl ermöglicht es Ihnen, eine Pipeline in Tagen zu erstellen; eine schlechte – sie in einem Monat neu zu erstellen, wenn die Anforderungen steigen.
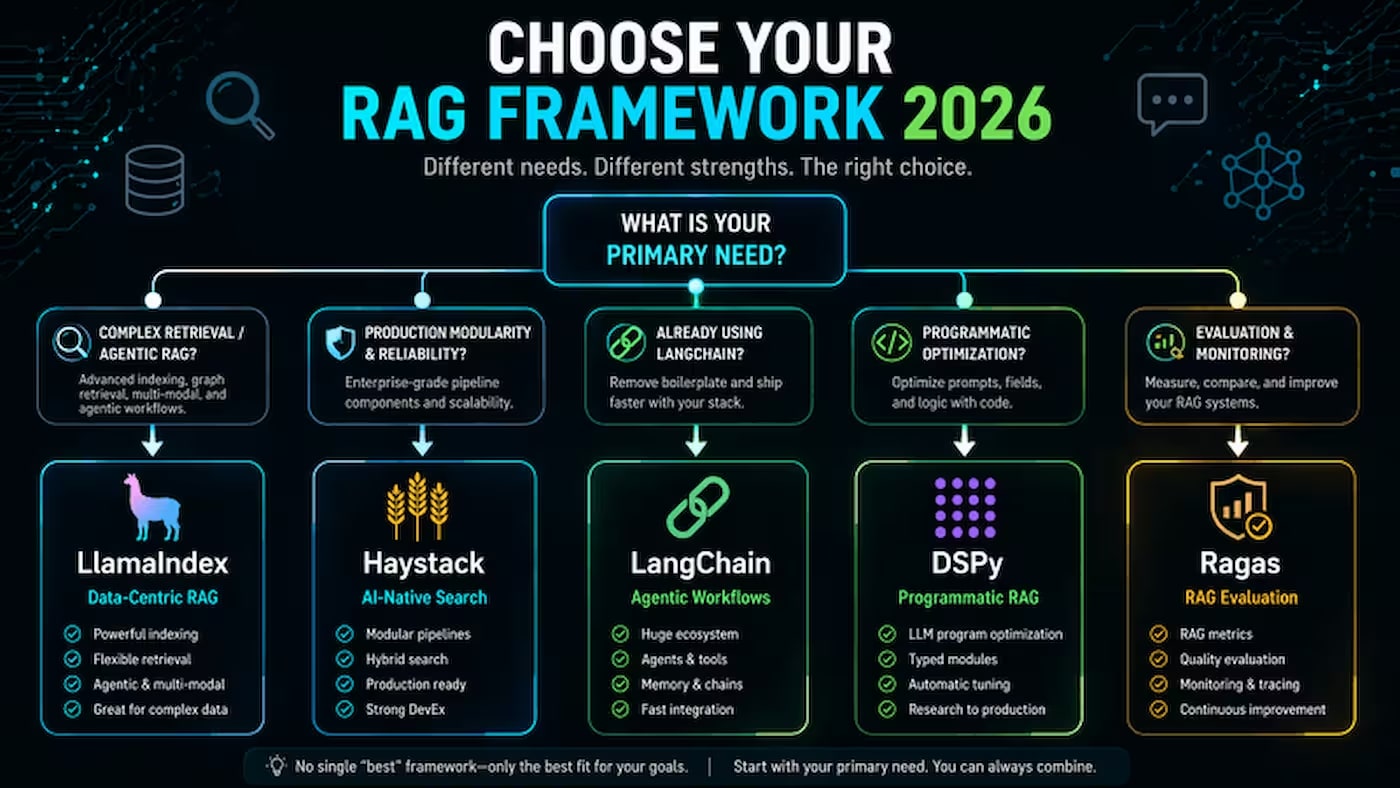
Meiner Meinung nach gibt es hier zwei grundlegend unterschiedliche Philosophien. LangChain und Haystack sind universelle Orchestratoren: Sie eignen sich für eine breite Palette von Aufgaben, sind aber nicht auf eine bestimmte spezialisiert. LlamaIndex und DSPy sind spezialisierte Tools mit klarer Spezialisierung: LlamaIndex für Retrieval, DSPy für die automatische Optimierung von Prompts. Ich würde empfehlen, mit dem Verständnis dieser Aufteilung zu beginnen – sie reduziert die Auswahl sofort um die Hälfte.
LangChain
GitHub – 119.000+ Sterne, 500+ Integrationen. Das größte Ökosystem unter allen RAG-Frameworks.
✅ Wählen Sie, wenn: Sie komplexe Multi-Agenten-Systeme mit Tools, Speicher und Schleifen aufbauen; maximale Flexibilität bei Integrationen benötigen; das Team wächst und es wichtig ist, dass neue Entwickler schnell Antworten in der Dokumentation und auf Stack Overflow finden.
❌ Vermeiden Sie, wenn: die Hauptaufgabe Q&A über ein großes Dokumentenarchiv ist (LlamaIndex ist genauer); das Zeitbudget begrenzt ist und ein schneller Start ohne Kampf mit Abstraktionen benötigt wird; die Vorhersagbarkeit der Pipeline kritisch ist (häufige Breaking Changes in LangChain sind ein bekanntes Problem).
⚠️ Typischer Fehler: LangChain wird gewählt, „weil es alle tun“, aber wenn 80% der Aufgabe das Retrieval von Dokumenten sind, ist dies eine übermäßige Komplexität. Eine vergleichende Analyse von 2026 zeigt: LlamaIndex liefert bei Dokumentenaufgaben 35% besseres Retrieval und ist 40% schneller als LangChain.
LlamaIndex
GitHub – 44.000+ Sterne, 300+ Datenkonnektoren über LlamaHub.
❌ Vermeiden Sie, wenn: ein komplexes Agentensystem mit Schleifen und verzweigter Logik benötigt wird (LangGraph ist besser); das Team nach vielen Tutorials und fertigen Beispielen im öffentlichen Bereich sucht.
💡 Aus meiner Erfahrung: LlamaIndex und LangChain konkurrieren selten – sie werden häufiger zusammen verwendet. LlamaIndex übernimmt die Retrieval-Schicht, LangGraph (Teil des LangChain-Ökosystems) – die Agenten-Orchestrierung. Ich sehe dieses Muster als eines der häufigsten in Produktionssystemen von 2026 an, und wenn Sie etwas Ernsthafteres als einen einfachen Q&A-Chatbot aufbauen, sollten Sie diese Kombination in Betracht ziehen.
GitHub – 20.000+ Sterne. Ein Framework von deepset, das um modulare Pipelines aufgebaut ist.
✅ Wählen Sie, wenn: das Team eine saubere, vorhersehbare Architektur mehr schätzt als die Größe des Ökosystems; die Aufgabe ein Produktionssystem in einer regulierten Umgebung ist (Finanzen, Medizin, Recht), wo Auditierbarkeit und API-Stabilität wichtig sind; bereits Erfahrung mit Enterprise NLP vorhanden ist und Reife statt „Magie“ benötigt wird.
❌ Vermeiden Sie, wenn: Sie ein neues Projekt beginnen und viele fertige Beispiele und Lösungen benötigen; die Aufgabe ein Agenten-RAG mit dynamischer Planung ist (Haystack ist darin schwächer als LangGraph).
DSPy (Stanford NLP)
GitHub – 23.000+ Sterne. Anstatt Prompts manuell zu schreiben, optimiert DSPy sie automatisch für die spezifische Aufgabe und Metrik.
✅ Wählen Sie, wenn: ein annotierter Datensatz von Fragen und Antworten zur Optimierung vorhanden ist; die Aufgabe gut definiert ist und maximale Qualität aus einem bestimmten Korpus herausgeholt werden soll; Sie bereit sind, Zeit in eine steile Lernkurve zu investieren.
❌ Vermeiden Sie, wenn: ein schneller Prototyp benötigt wird; kein annotierter Datensatz zur Optimierung vorhanden ist; das Team keine Erfahrung mit maschinellem Lernen hat – DSPy ist das schwierigste in dieser Liste.
Trade-off-Tabelle: Frameworks
Framework
GitHub ⭐
Retrieval-Qualität
Agenten
Einstiegsschwelle
Bester Anwendungsfall
LangChain
119.000+
Gut (~85%)
⭐⭐⭐⭐⭐ (LangGraph)
Mittel
Multi-Agenten-Systeme, komplexe Ketten
LlamaIndex
44.000+
Ausgezeichnet (~92%)
⭐⭐⭐
Niedrig
Q&A über Dokumente, Unternehmenswissensdatenbanken
Haystack
20.000+
Gut
⭐⭐
Mittel
Enterprise-Produktion, regulierte Branchen
DSPy
23.000+
Maximal (mit Datensatz)
⭐⭐
Sehr hoch
Qualitätsoptimierung für eine bestimmte Aufgabe
Vektor-Datenbanken: Vergleich von Qdrant, Milvus, Weaviate, pgvector, ChromaDB
Eine Vektor-Datenbank ist das Herzstück von RAG, und ich bin überzeugt, dass Teams hier am häufigsten eine falsche Entscheidung treffen. Sie speichert Embeddings und ist für die Geschwindigkeit und Qualität der Suche verantwortlich – aber sie wird normalerweise nach der Anzahl der GitHub-Sterne ausgewählt, nicht nach dem, was wirklich wichtig ist. Meiner Meinung nach entscheiden drei Kriterien über alles: der Umfang Ihres Korpus, die Notwendigkeit von Hybrid Search und die operativen Fähigkeiten des Teams. Wenn Sie diese drei Fragen ehrlich beantworten – wird die Wahl offensichtlich, ohne jegliche Benchmarks.
Bevor Sie sich mit spezifischen Datenbanken befassen – machen Sie sich damit vertraut, wie Vektor-Suche von innen funktioniert: Vektor-Suche für Anfänger.
Qdrant
GitHub – 20.000+ Sterne. Geschrieben in Rust. Die schnellste Open-Source-Vektor-Datenbank in der Produktion.
✅ Wählen Sie, wenn: ein Produktionssystem für eine Sammlung von 1 Mio. bis ca. 100 Mio. Vektoren benötigt wird; maximale Geschwindigkeit wichtig ist – Qdrant ist bei typischen Lasten 10-25% schneller als Weaviate und Milvus, p99 Latenz bei 10 Mio. Vektoren ~12ms gegenüber 16ms bei Weaviate und 18ms bei Milvus; Hybrid Search (Sparse + Dense) und flexible Filterung nach Metadaten benötigt wird; das Team Self-Hosting ohne Vendor Lock-in wünscht.
❌ Vermeiden Sie, wenn: Sie bereits PostgreSQL verwenden und die Sammlung kleiner als 5 Mio. Vektoren ist – pgvector ist einfacher; ein Umfang von über einer Milliarde Vektoren benötigt wird (Milvus ist besser).
✅ Wählen Sie, wenn: der Datensatz auf Hunderte Millionen oder Milliarden von Vektoren anwächst; ein Data-Engineering-Team vorhanden ist, das die operative Komplexität übernehmen kann; horizontale Skalierbarkeit mit gestaffeltem Speicher (Hot/Warm/Cold) benötigt wird.
✅ Wählen Sie, wenn: Hybrid Search (Vektoren + Schlüsselwörter + strukturierte Filter) die Hauptanforderung ist; eine GraphQL API für komplexe Abfragen benötigt wird; ein SaaS-Produkt aufgebaut wird und Multi-Tenancy mit Datenisolierung zwischen Kunden benötigt wird.
❌ Vermeiden Sie, wenn: das Team neu bei Vektor-Datenbanken ist – Weaviate hat eine steilere Lernkurve aufgrund des Schema-Modells und des modularen Systems; die Ressourcen begrenzt sind – das Self-Hosting von Weaviate erfordert mehr RAM als Qdrant bei gleichem Datensatz.
pgvector
GitHub – 13.000+ Sterne. Eine Erweiterung für PostgreSQL. Version 0.9 (2026) fügte Sparse-Vektoren und verbessertes HNSW hinzu.
✅ Wählen Sie, wenn: Sie bereits PostgreSQL verwenden und minimale architektonische Komplexität wünschen; die Sammlung kleiner als 5–10 Mio. Vektoren ist; transaktionale Konsistenz zwischen Vektor- und relationalen Daten benötigt wird. Ich selbst wähle oft diese Option – besonders wenn ein Projekt bereits auf PostgreSQL läuft und es einfach keinen Sinn macht, einen separaten Dienst für die Vektorsuche hinzuzufügen. pgvector löst in solchen Fällen die Aufgabe elegant und ohne unnötige Infrastruktur.
GitHub – 16.000+ Sterne. In-Memory oder lokaler Speicher, pip install und fertig.
✅ Wählen Sie, wenn: Sie Prototypen erstellen, lernen, Hypothesen testen. ChromaDB ist der schnellste Start: von Null bis zur ersten RAG-Abfrage in 15 Minuten.
❌ Vermeiden Sie in der Produktion: kein HA, kein Snapshot, keine Produktions-Monitoring. Wenn Sie mit Chroma beginnen – planen Sie sofort eine Migration zu Qdrant oder Weaviate.
Trade-off-Tabelle: Vektor-Datenbanken
DB
Sprache
Hybrid Search
Optimaler Umfang
Self-hosted
Wann zu wählen
Qdrant
Rust
✅ Nativ
1M – 100M Vektoren
Einfach
Produktion mit Hybrid Search, geschwindigkeitskritisch
Milvus
Go/C++
✅ Nativ
100M – Milliarden
Schwierig (K8s)
Enterprise-Umfang, GPU-Beschleunigung
Weaviate
Go
✅ BM25 + Dense
1M – 50M Vektoren
Mittel
SaaS Multi-Tenancy, GraphQL API
pgvector
C (PostgreSQL Ext.)
⚠️ Teilweise
bis 5–10M Vektoren
Wenn PostgreSQL vorhanden
Bereits Postgres vorhanden, kleiner Umfang
ChromaDB
Python
❌
bis 100K Vektoren
Trivial
Nur Prototypen und Lernen
⚠️ Typischer Fehler des Abschnitts: Milvus wird gewählt, „weil er am kompliziertesten ist und das bedeutet, dass er der beste ist“. Bei einer Sammlung von weniger als 50 Mio. Vektoren ist die operative Komplexität von Milvus reine Zeitverschwendung ohne Qualitätssteigerung. Qdrant deckt 90% der Produktionsszenarien mit minimalen Einstellungen ab.
All-in-one Plattformen sind keine Frameworks für Entwickler, sondern fertige Produkte. Sie übernehmen die gesamte Pipeline: Dokumenten-Upload, Chunking, Embedding, Vektorspeicher, Generierung. Der Preis dafür ist geringere Flexibilität. Wenn Ihre Aufgabe darin besteht, RAG schnell und ohne Code zu starten, ist dies die richtige Wahl.
Dify
GitHub — 90.000+ Sterne. Das am schnellsten wachsende KI-Projekt des Jahres 2025.
✅ Wählen Sie, wenn: Ihr Team keine ML-Erfahrung hat, Sie einen schnellen MVP oder einen internen Chatbot benötigen; Sie einen visuellen Drag-and-Drop-Editor für No-Code-Pipelines wünschen; Sie Unterstützung für über 100 LLM-Anbieter "out of the box" benötigen.
❌ Vermeiden Sie, wenn: Sie eine tiefe Kontrolle über Chunking und Retrieval benötigen (RAGFlow ist besser); maximale Genauigkeit bei komplexen Dokumenten (PDFs mit Tabellen, Rechtsverträge) kritisch ist.
RAGFlow
GitHub — 48.000+ Sterne. Spezialisiert auf tiefes Dokumentenverständnis.
✅ Wählen Sie, wenn: Ihr Korpus aus komplexen PDF-Dateien besteht (Tabellen, Formeln, gemischte Formatierung); Sie eine transparente Visualisierung wünschen, wie ein Dokument in Chunks aufgeteilt wird; Sie ein Self-hosted RAG mit voller Kontrolle und einer REST-API für die Integration wünschen.
❌ Vermeiden Sie, wenn: Ihre Ressourcen begrenzt sind – RAGFlow benötigt Elasticsearch + Infinity DB und hat einen hohen RAM-Bedarf; Ihre Aufgabe ein schneller Prototyp ist und nicht die Qualität des Parsings.
GitHub — 14.600+ Sterne. Von der Universität Hongkong. Kombiniert Wissensgraphen und Vektorsuche.
✅ Wählen Sie, wenn: Ihre Dokumente reich an Verbindungen zwischen Entitäten sind (medizinische Dokumentation, Rechtsakte, technische Spezifikationen); Sie ein leichtgewichtiges Framework ohne schwere Infrastruktur benötigen – Installation über pip install lightrag-hku; die Unterstützung für inkrementelle Indexaktualisierungen wichtig ist.
❌ Vermeiden Sie, wenn: Ihre Hauptaufgabe eine einfache Q&A über ein großes Archiv von gleichartigen Dokumenten ohne komplexe Verbindungen zwischen Entitäten ist.
AnythingLLM
Website. Desktop-Anwendung für lokales RAG mit Ollama-Integration.
✅ Wählen Sie, wenn: Sie ein vollständig privates RAG ohne jegliche Cloud-API wünschen; Sie eine persönliche Wissensdatenbank auf Ihrem Laptop mit lokalen Modellen (DeepSeek-R1, Qwen3) einrichten möchten; Ihr Team nicht-technisch ist und eine einfache Benutzeroberfläche benötigt.
❌ Vermeiden Sie, wenn: Sie Skalierbarkeit, eine API für externe Systeme oder Teamarbeit benötigen – AnythingLLM ist für den individuellen Gebrauch konzipiert.
Graph-basierte Suche, Verbindungen zwischen Entitäten
AnythingLLM
—
✅ Desktop UI
Grundlegend
Minimal
Lokales RAG, Datenschutz, individueller Gebrauch
⚠️ Typischer Fehler: Dify für eine ernsthafte Unternehmenslösung einsetzen und sich wundern, dass die Retrieval-Genauigkeit bei komplexen PDFs mit Tabellen gering ist. Dify ist für einen schnellen Start optimiert, nicht für maximale Parsing-Qualität. Wenn die Retrieval-Qualität die wichtigste Metrik ist, beginnen Sie mit RAGFlow oder einem separaten Dokumentenparser.
Bewertung der RAG-Qualität: RAGAS, DeepEval, Langfuse
Mein Rat: Wiederholen Sie nicht den Fehler, den ich in fast jedem Team sehe: Sie bauen RAG, starten es und das war's. Keine Bewertungssysteme. Das ist dasselbe, als würde man ein Produkt ohne Metriken und Analysen entwickeln – man weiß einfach nicht, was kaputtgegangen ist, wenn etwas schiefgeht, und kann nicht beweisen, dass es nach der Optimierung besser geworden ist. Ich sage immer: Evaluation ist nicht der letzte Schritt, sie ist von Anfang an Teil der Pipeline.
GitHub — 5.000+ Sterne. Der "pytest für LLMs"-Ansatz. Über 50 Metriken, einschließlich Sicherheit und Bias.
✅ Wählen Sie für: CI/CD Quality Gate – blockiert das Mergen von PRs, wenn die RAG-Qualität unter einen Schwellenwert fällt; systematische Tests auf Unit-Test-Ebene; Teams, die nicht nur RAG, sondern auch Agenten und Multi-Turn-Systeme bauen.
❌ Einschränkungen: Komplexer in der Einrichtung als RAGAS; engere Integration mit RAG-Frameworks "out of the box".
Langfuse
GitHub. Open-Source LLM-Observability: Tracing, Dashboards, Produktions-Monitoring. Self-hosted oder Managed Cloud.
✅ Wählen Sie für: Echtzeit-Monitoring von Produktions-RAG – Sie sehen jede Anfrage, Latenz, Kosten, Qualitätsbewertung; Speicherung und Analyse von Traces von RAGAS und DeepEval an einem Ort.
⚠️ Typischer Fehler dieses Abschnitts: Die Bewertung wird überhaupt übersprungen. "Wir sehen, dass die Antworten gut sind" ist keine Metrik. Ohne RAGAS wissen Sie nicht, was sich nach einer Änderung der chunk_size verbessert hat, und bemerken keine Verschlechterung nach einem Update des Embedding-Modells. Mindestens: Führen Sie RAGAS einmal pro Woche mit 50-100 Testanfragen aus.
Fertige Stacks für 5 Szenarien: von PoC bis Enterprise
Anstelle von „Wir empfehlen LangChain + Qdrant“ – konkrete Stacks für spezifische Einschränkungen. Wo nötig – mit Alternativen.
Szenario 1: Erster Prototyp / Hypothesentest
Aufgabe: In 1-2 Tagen prüfen, ob RAG für Ihren Dokumentenkorpus überhaupt geeignet ist.
Framework: LlamaIndex oder Dify
Vektordatenbank: ChromaDB (in-memory)
Embedding: text-embedding-3-small oder nomic-embed-text (Ollama)
LLM: GPT-4o-mini oder Qwen3:8b lokal
Bewertung: manuelle Überprüfung von 20-30 Anfragen
Bewertung: DeepEval in CI, RAGAS als Cron-Job, Langfuse für Tracing
Observability: Langfuse oder LangSmith
Was in Übersichten nicht erwähnt wird: Antipatterns und typische Fehler
Die meisten Übersichten beschreiben den Happy Path. Hier ist, was RAG-Systeme wirklich zum Scheitern bringt – und worüber in Tutorials nicht geschrieben wird.
Antipattern 1: Mit der Optimierung der Tool-Auswahl beginnen, nicht mit der Datenqualität
Der teuerste Fehler. Ein Team vergleicht einen Monat LangChain und LlamaIndex, wählt Qdrant statt Weaviate – und die Abfrage ist trotzdem schlecht, weil die Eingabe-PDFs gescannt sind, OCR-Artefakte die Embeddings verzerren.
ChromaDB ist ein hervorragendes Werkzeug für Prototypen. Aber Teams lassen es regelmäßig in der Produktion „weil es ja funktioniert“. Ja, bis zu 100.000 Dokumente – es funktioniert. Bei 1 Million Dokumenten und mehreren parallelen Anfragen stoßen Sie auf Leistungseinbußen und fehlende Hochverfügbarkeit. Die Migration ist später schmerzhaft. Planen Sie sie vom ersten Tag an.
Antipattern 4: „Ein größeres Embedding-Modell löst das Abfrageproblem“
Der Wechsel von text-embedding-3-small (1536) zu text-embedding-3-large (3072) bringt etwa 8,5% mehr Leistung bei MTEB Retrieval und kostet 6,5-mal mehr pro API-Aufruf + doppelt so viel Speicherplatz. Gleichzeitig bringt die Hinzufügung von Hybrid-Abfrage und Reranker ohne Modellwechsel +39% Recall. Investieren Sie in die Abfragearchitektur, nicht in die Vektor-Dimension. Detaillierte Begründung: 1536 vs 3072: Vergleich für RAG.
Antipattern 5: Qualitätsbewertung bis zum ersten Vorfall ignorieren
„Wir haben RAG gestartet und die Antworten sehen gut aus“ – eine verbreitete Haltung bis zum ersten Fall, in dem das System eine überzeugende Halluzination auf eine wichtige Kundenanfrage liefert. Ohne RAGAS oder DeepEval kennen Sie nicht das Niveau von Faithfulness, Context Precision und Answer Relevancy. Richten Sie eine minimale Bewertung vor der Veröffentlichung ein, nicht danach. Die Kosten einer grundlegenden Bewertung mit GPT-4o-mini betragen ca. 0,001-0,003 $ pro Testfall. Dies ist die billigste Versicherung gegen schwerwiegende Fehler.
Antipattern 6: Milvus für kleine Sammlungen
Milvus ist die richtige Wahl bei Hunderten von Millionen von Vektoren und der Verfügbarkeit eines Data-Engineering-Teams. Für Sammlungen bis zu 50 Millionen Vektoren ist dieser operative Aufwand eine unnötige Belastung ohne messbaren Qualitätsgewinn. Qdrant auf einem einzigen Server deckt die meisten Produktionsszenarien mit minimaler Konfiguration ab.
Fazit: Wie man eine Entscheidung trifft
Ich möchte ehrlich sein: Die Wahl eines RAG-Stacks ist keine Suche nach dem „besten Werkzeug überhaupt“. So etwas gibt es nicht. Es ist die Antwort auf fünf spezifische Fragen Ihres Projekts. Ich habe Teams gesehen, die Wochen mit dem Vergleich von Frameworks verbracht haben – und schlechte Ergebnisse erzielt haben, weil sie diese Fragen vor Beginn der Auswahl nicht beantwortet haben.
Wie ist die Qualität der Eingabedaten? Das ist das Erste, was ich immer überprüfe. Wenn PDFs gescannt sind, der Text nach OCR unsauber ist, die Dokumente keine Struktur haben – kein Framework kann das beheben. LlamaIndex rettet kein schlechtes Parsing. Beginnen Sie mit der Qualität der Eingabedaten, nicht mit der Wahl des Werkzeugs.
Wie groß ist Ihr Korpus? Das ist eine technische Frage mit einer klaren Antwort. Bis zu 10 Millionen Vektoren – pgvector oder Qdrant, und das ist mehr als genug. Über 100 Millionen – nur Milvus. Dazwischen deckt Qdrant die meisten Aufgaben ohne unnötigen operativen Aufwand ab.
Benötigen Sie Hybrid Search? Wenn Ihr Korpus exakte Begriffe, Artikelnummern, Methodennamen, numerische Werte enthält – ist Hybrid Search unerlässlich. Dann Weaviate oder Qdrant. ChromaDB ist dafür überhaupt nicht geeignet, und ich rate davon ab, es anzupassen.
Welche ML-Expertise hat das Team? Das ist eine Frage, die man ungern stellt – aber sie entscheidet über alles. Wenn das Team nicht technisch ist oder ein schneller Start benötigt wird – Dify oder AnythingLLM liefern Ergebnisse in einem Tag. Wenn erfahrene Ingenieure vorhanden sind und die Aufgabe ernst ist – LlamaIndex mit Qdrant und Hybrid Search liefert deutlich bessere Qualität.
Messen Sie die Systemqualität? Wenn nicht – hören Sie auf. Wählen Sie kein neues Framework, ändern Sie kein Embedding-Modell. Der erste Schritt sollte RAGAS mit 50-100 Testanfragen sein. Ohne Messung wissen Sie nicht, was Sie verbessern sollen – und jede Optimierung wird zum Raten.
Mein persönlicher Ansatz: Ich beginne immer mit dem einfachsten Stack, der die aktuelle Aufgabe erfüllt, messe die Qualität über RAGAS – und erst wenn es einen konkreten, messbaren Mangel gibt, füge ich Komplexität hinzu. Die schlechteste Entscheidung ist, sofort einen Enterprise-Stack für eine Aufgabe zu bauen, die mit LlamaIndex und pgvector an einem Wochenende gelöst werden kann.
Mehr Details zu jeder Schicht der Pipeline – in den entsprechenden Artikeln der Serie: