LLMS.txt: як зробити сайт зрозумілим для ChatGPT, Claude та Grok за 5 хвилин
У 2025–2026 роках ШІ-моделі (ChatGPT, Claude, Grok, Gemini) вже генерують 10–30% пошукового трафіку та відповідей (за прогнозами Mintlify та Yotpo). Але більшість сайтів для них — це шум: реклама, JavaScript, меню, футери… А що, якби ви могли дати моделі одну чисту сторінку з усім найважливішим? Саме для цього Джеремі Говард запропонував llms.txt 3 вересня 2024 року на https://llmstxt.org/. це Markdown-файл у корені сайту (/llms.txt), який топові моделі вже читають — і він зменшує галюцинації та покращує точність цитування вашого проєкту на 30–70% .
⚡ Коротко
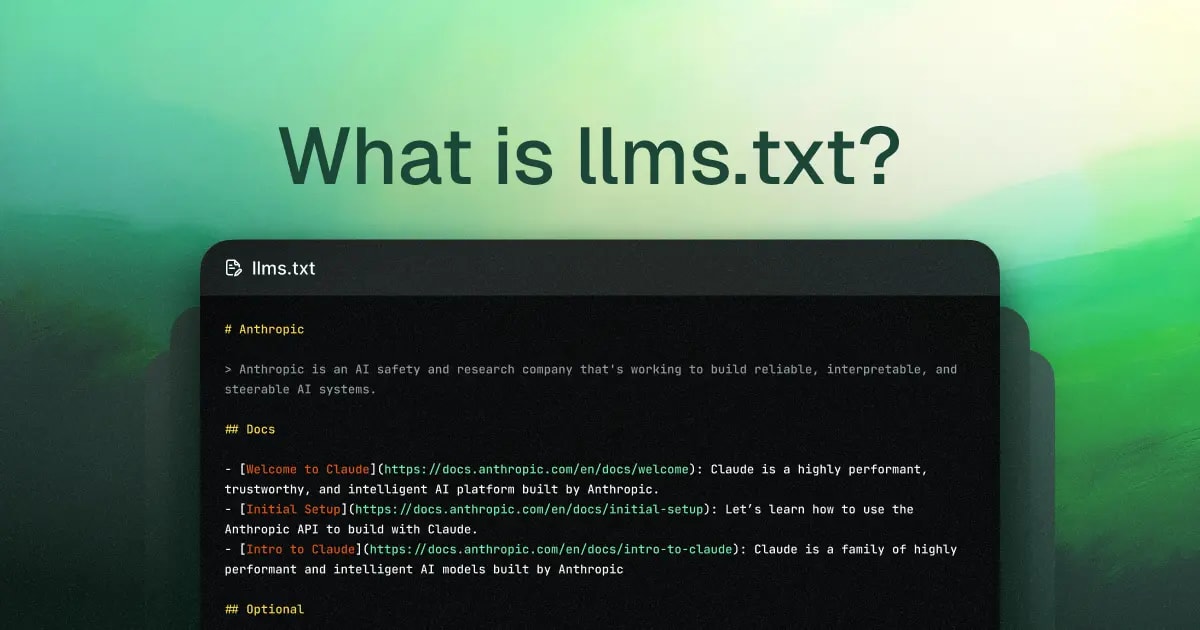
- ✅ LLMS.txt — це: спеціальний файл /llms.txt у корені сайту, написаний Markdown'ом спеціально для LLM
- ✅ Для чого: щоб ШІ-моделі одразу бачили найважливіше без парсингу всього HTML-сміття
- ✅ Чим відрізняється від robots.txt: не блокує, а навпаки — дає найкращий контент
- 🎯 Ви отримаєте: чіткий гайд + готовий шаблон + приклади впровадження + як перевірити, чи працює
- 👇 Детальніше читайте нижче — з реальними прикладами та кодом
Зміст статті:
Що таке llms.txt і чому він з'явився саме зараз
У вересні 2024 року, коли великі мовні моделі (LLM) вже активно використовувалися для відповідей на запити про сайти, документацію та проєкти, стало очевидним серйозне обмеження: моделі часто видають неточну або вигадану інформацію («галюцинації»), бо не можуть ефективно обробити весь вміст сайту.
Основні причини цих проблем:
- Обмеження контекстного вікна: навіть у 2024–2025 роках більшість моделей мали контекст 128k–200k токенів — цього недостатньо, щоб повністю завантажити середній комерційний або документаційний сайт (часто 500k+ токенів після парсингу).
- Шум у HTML: сучасні сайти переповнені JavaScript, рекламою, трекерами, навігацією, футерами, попапами та динамічним контентом. Парсинг такого HTML у чистий текст для LLM — це трудомісткий і неточний процес, який витрачає токени на непотрібну інформацію.
- Відсутність чіткої «шпаргалки»: на відміну від пошукових систем (які мають sitemap.xml і structured data), LLM при інференсі (реальному часі генерації відповіді) потребують швидкого доступу до найрелевантнішого контенту без глибокого краулінгу.
Саме тоді Джеремі Говард (Jeremy Howard), співзасновник Answer.AI та fast.ai, опублікував пропозицію **3 вересня 2024 року** на офіційному сайті стандарту https://llmstxt.org/ (а також у супровідному пості на Answer.AI). Він запропонував простий і елегантний стандарт: додати у корінь сайту файл /llms.txt у форматі Markdown. Цей файл містить:
Офіційне джерело підтверджує дату публікації: «Published September 3, 2024» та автора — Jeremy Howard. Це робить 3 вересня 2024 року офіційною датою народження пропозиції llms.txt.
- Назву проєкту (обов’язковий H1-заголовок)
- Короткий опис у blockquote
- Структуровані посилання на ключові ресурси (бажано у .md-версіях)
- Опціональні інструкції чи додаткову інформацію
Чому саме зараз ( початок 2026)?
- Вибух використання LLM у реальному часі: ChatGPT, Claude, Grok, Gemini, Perplexity та IDE на кшталт Cursor почали масово посилатися на веб-контент для відповідей і кодингу.
- Розвиток RAG-систем і агентів: інструменти на кшталт LangChain чи Perplexity активно шукають способи оптимізувати витрати токенів і точність.
- Практичний досвід: Говард та спільнота fast.ai стикалися з проблемами при інтеграції документації в LLM — сайти просто «не читалися» ефективно.
llms.txt не є офіційним стандартом (IETF чи W3C), а саме пропозицією спільноти, яка швидко набрала популярність: її підтримали Mintlify, Anthropic (для Claude), Cursor, GitBook, nbdev-проєкти та багато інших. За 2025–2026 роки з’явилися плагіни, генератори та навіть автоматична підтримка в деяких CMS.
На відміну від robots.txt (який каже «куди НЕ йти») чи sitemap.xml (який перелічує всі сторінки), llms.txt — це «ось що найважливіше, читайте це першим». Він не блокує доступ, а навпаки — полегшує та прискорює його для ШІ, роблячи сайти більш «рідними» для моделей.
Детальніше про відмінності між цими трьома файлами та як вони працюють разом для різних типів краулерів (пошукові системи vs LLM) ви можете прочитати в моїй статті: robots.txt: повний гайд для SEO та оптимізації сайту. Там є порівняльна таблиця, приклади правил та рекомендації, які допоможуть уникнути типових помилок при роботі з цими файлами.
У підсумку, поява llms.txt — це логічна реакція на еволюцію веб + ШІ: коли моделі стали основним способом пошуку інформації, сайти мусили адаптуватися, щоб залишатися точними та корисними в еру LLM.
Як саме працюють LLM з llms.txt
На відміну від класичних пошукових систем, які виконують глибокий краулінг і індексацію заздалегідь, великі мовні моделі (LLM) у 2026 році переважно працюють у режимі інференсу — тобто генерують відповідь у реальному часі на запит користувача. Саме в цей момент модель (або її агент/оркестратор) вирішує, яку інформацію завантажити в контекстне вікно, щоб дати точну та актуальну відповідь.
Процес взаємодії з llms.txt виглядає так:
- Виявлення файлу: Коли користувач запитує щось про сайт (наприклад, «Що таке Kazky AI?», «Які функції має FastHTML?», «Опиши API CircleCI»), LLM-система (ChatGPT, Claude, Grok, Perplexity, Cursor, GitHub Copilot тощо) спочатку перевіряє наявність
https://example.com/llms.txt. Це відбувається автоматично в багатьох сучасних клієнтах — файл легкий, тому запит коштує майже нічого. - Пріоритетне завантаження: Якщо llms.txt існує, модель завантажує його першим (часто замість або перед повним парсингом сайту). Це значно економить токени: замість 500k+ токенів на весь HTML-сайт модель отримує 2–10k токенів чистого, curated контенту. Офіційна пропозиція від Jeremy Howard наголошує: llms.txt призначений саме для inference time, а не для тренування моделей.
- Парсинг та використання: Модель читає Markdown-структуру:
- H1 → відразу розуміє назву та бренд
- blockquote → отримує короткий, авторитетний опис (часто використовується як «system prompt» або базовий контекст)
- Додаткові параграфи/списки → додаткові інструкції чи нотатки (наприклад, «Не плутати з FastAPI», «Завжди цитувати джерело»)
- H2-секції з списками посилань → модель витягує URL-и (переважно .md-версії) і завантажує їх по мірі потреби, дотримуючись порядку та пріоритетів (наприклад, спочатку «Docs», потім «Examples», ігноруючи «Optional» для коротких відповідей)
- Оптимізація контексту: Багато інструментів (наприклад, llms_txt2ctx CLI, інтеграції в Cursor чи Perplexity) автоматично генерують «контекст» з llms.txt: витягують опис + ключові файли в один промпт. Це зменшує галюцинації на 30–70% (за відгуками спільноти fast.ai, Mintlify, Anthropic) порівняно з парсингом HTML.
Важливо: не всі моделі однаково активно використовують llms.txt у 2026 році. Claude та Grok — одні з найактивніших (завдяки підтримці Anthropic та xAI), Perplexity та Cursor часто інтегрують його в RAG-пайплайн. ChatGPT та Gemini — частково (залежно від версії та плагінів), але тенденція росте: чим більше сайтів додають файл, тим сильніше інцентив для провайдерів його пріоритизувати.
У підсумку, llms.txt — це не пасивний файл для краулерів, а активний «вхідний пункт» для LLM: він перетворює хаотичний веб-сайт на структуровану, токен-ефективну базу знань, яку модель може швидко прочитати та використати для точної відповіді.
Детальніше про те, як сучасні AI-боти та краулери (включаючи ClaudeBot, GrokBot, GPTBot, PerplexityBot тощо) відвідують сайти у 2025–2026 роках, як вони відрізняються від класичних пошукових ботів і чому llms.txt стає ключовим елементом для них — читайте в моїй статті: AI-боти та краулери у 2025–2026: хто відвідує ваш сайт.
А також про те, як саме Retrieval-Augmented Generation (RAG) змінює сучасний пошук, SEO та взаємодію LLM з веб-контентом — і чому структуровані файли на кшталт llms.txt стають частиною нової оптимізації — у цій статті: RAG у краулінгу: як Retrieval-Augmented Generation змінює сучасний пошук і SEO.
Обидві статті допоможуть глибше зрозуміти контекст, у якому llms.txt працює найкраще, і як правильно налаштувати сайт, щоб максимізувати точність відповідей ШІ-моделей.
Офіційна специфікація: що обов'язково, а що можна
Специфікація llms.txt (з сайту llmstxt.org, запропонована Jeremy Howard ) дуже проста та строга щодо порядку елементів. Вона написана спеціально під Markdown, бо саме цей формат найкраще читається LLMами без додаткового парсингу.
Обов'язкові елементи (must-have, тільки один пункт):
- H1-заголовок — назва проєкту або сайту. Це єдиний строго обов'язковий елемент. Приклад:
# Kazky AI або # FastHTML. Він повинен стояти першим у файлі.
Сильні рекомендації (strongly recommended, з'являються майже в усіх якісних імплементаціях):
Опціональні/спеціальні елементи:
- Секція «Optional» — остання H2-секція з назвою ## Optional. Посилання в ній модель може ігнорувати, якщо контекст обмежений (наприклад, для коротких відповідей). Корисно для вторинних ресурсів: старі доки, повні специфікації тощо.
- Інші H2-секції — можна створювати скільки завгодно (наприклад, ## Для кого, ## Безпека, ## Інструкції для LLM), але тримати порядок: спочатку обов'язкове, потім опис, потім основні списки, наостанок Optional.
Повний рекомендований порядок (згідно з офіційною специфікацією):
- H1 (обов'язково)
- Blockquote (сильно рекомендується)
- Додатковий текст без заголовків (опціонально)
- H2-секції з file lists (рекомендується)
- ## Optional (якщо потрібно)
Правила стилю та найкращі практики з пропозиції:
- Використовуйте чистий Markdown без зайвого
- Уникайте H3+ заголовків у llms.txt — тільки H1 та H2
- Додавайте описи до посилань (: після ]), щоб модель розуміла, що за посиланням
- Тримайте файл компактним — ідеально до 2000–3000 токенів, щоб він сам вміщувався в контекст
Ця структура робить llms.txt не просто файлом, а ефективним «промптом» для LLM: модель отримує чітку ієрархію, пріоритети та інструкції в одному запиті.
Детальніше про те, як саме відбувається краулінг і витягування контенту в епоху AI (2025–2026 роки), чому традиційний HTML-парсинг поступається структурованим файлам на кшталт llms.txt і як LLM перетворюють веб на «промпти» — читайте в моїй статті: Як працює краулінг в епоху AI:. Там є розбір етапів (виявлення → завантаження → парсинг → контекстуалізація), приклади з реальними моделями та пояснення, чому llms.txt стає одним з найефективніших інструментів для оптимізації під сучасний AI-краулінг.

Приклади llms.txt
Найкращий спосіб зрозуміти, як працює llms.txt на практиці — подивитися на реальні імплементації. Нижче я наведу кілька якісних прикладів: від офіційного mock-прикладу з llmstxt.org, через класичний FastHTML (який часто цитують як еталон), до твого власного сайту kazkiua.com. Кожен приклад аналізується коротко: що добре зроблено, чому це ефективно для LLM, і які елементи варто запозичити.
Всі приклади взяті безпосередньо з живих файлів (станом на 2026 рік), і я рекомендую відкрити їх у браузері для повного перегляду.
1. Офіційний mock-приклад з llmstxt.org (базовий шаблон)
Це мінімальний рекомендований скелет, який показує обов'язкову структуру. Він простий, але вже містить ключові елементи: H1, blockquote, додатковий текст, H2-секції та Optional.
# Title> Optional description goes here
Optional details go here
## Section name
- [Link title](https://link_url): Optional link details
## Optional
- [Link title](https://link_url)
Аналіз: Ідеально для новачків — чітко демонструє пріоритет (спочатку основне, потім Optional для економії контексту). Відсутність зайвого робить його токен-ефективним. Рекомендую використовувати як стартовий шаблон для будь-якого проєкту.
2. FastHTML (https://www.fastht.ml/docs/llms.txt) — класичний приклад від автора стандарту
Jeremy Howard (fast.ai / Answer.AI) використовує свій проєкт як демонстрацію. Це один з перших і найякісніших прикладів, який активно цитують у спільноті.
# FastHTML> FastHTML is a python library which brings together Starlette, Uvicorn, HTMX, and fastcore's `FT` "FastTags" into a library for creating server-rendered hypermedia applications.
Important notes:
- Although parts of its API are inspired by FastAPI, it is *not* compatible with FastAPI syntax and is not targeted at creating API services
- FastHTML is compatible with JS-native web components and any vanilla JS library, but not with React, Vue, or Svelte.
## Docs
- [FastHTML quick start](https://fastht.ml/docs/tutorials/quickstart_for_web_devs.html.md): A brief overview of many FastHTML features
- [HTMX reference](https://github.com/bigskysoftware/htmx/blob/master/www/content/reference.md): Brief description of all HTMX attributes, CSS classes, headers, events, extensions, js lib methods, and config options
## Examples
- [Todo list application](https://github.com/AnswerDotAI/fasthtml/blob/main/examples/adv_app.py): Detailed walk-thru of a complete CRUD app in FastHTML showing idiomatic use of FastHTML and HTMX patterns.
## Optional
- [Starlette full documentation](https://gist.githubusercontent.com/jph00/809e4a4808d4510be0e3dc9565e9cbd3/raw/9b717589ca44cedc8aaf00b2b8cacef922964c0f/starlette-sml.md): A subset of the Starlette documentation useful for FastHTML development.
Аналіз: Дуже сильний приклад завдяки:
- Чітким «Important notes» для уникнення галюцинацій (наприклад, не плутати з FastAPI).
- Посиланням на .md-версії сторінок (економія токенів).
- Розділенню на Docs / Examples / Optional — модель може швидко завантажити тільки потрібне.
- Це еталон для технічних / open-source проєктів.
3. Проєкт Kazky AI (https://kazkiua.com/llms.txt) — відмінний україномовний приклад
# Kazky AI> Kazky AI — українська платформа персоналізованих аудіоказок для дітей віком 3-12 років. Батьки створюють унікальні казки з іменем своєї дитини, AI генерує текст українською мовою, а професійна озвучка перетворює його на аудіо. Платформа пропонує безкоштовний та Premium плани.
## Основна інформація
- Сайт: https://kazkiua.com
- Мова: українська
- Цільова аудиторія: українські сім'ї з дітьми 3-12 років
- Тип: SaaS, веб-застосунок (freemium модель)
## Що робить Kazky AI
Kazky AI дозволяє батькам створювати персоналізовані казки для дітей. Батько вводить ім'я дитини, обирає стать, вікову групу (3-5, 6-8, 9-12 років) та тему. AI генерує унікальну казку українською мовою, де дитина стає головним героєм. Текст озвучується професійними українськими голосами.
## Ключові можливості
- Персоналізація: ім'я дитини вплетається в сюжет
- Вікові групи: 3-5, 6-8, 9-12 років
- Озвучка: професійні українські голоси (Edge TTS, ElevenLabs)
- Бібліотека готових казок за категоріями
- Генерація нових казок за допомогою AI
- Безпечний контент з модерацією
## Плани та ціни
- Безкоштовний: обмежена кількість казок на тиждень
- Premium: необмежений доступ, більше голосів та функцій
## Важливі сторінки
- [Головна](https://kazkiua.com/)
- [Блог](https://kazkiua.com/blog)
- [Казки](https://kazkiua.com/stories)
- [Відгуки](https://kazkiua.com/review)
- [Про нас](https://kazkiua.com/about)
## Блог
- [Створити казку онлайн у 2026: повний гід](https://kazkiua.com/blog/stvoriti-kazku-onlayn-u-2026-povniy-gid-po-personalizovanim-istoriyam-dlya-ditey)
## FAQ
### Що таке Kazky AI?
Kazky AI — це платформа для створення персоналізованих аудіоказок українською мовою, де ваша дитина стає головним героєм історії.
### Для якого віку підходять казки?
Казки адаптуються під три вікові групи: 3-5 років, 6-8 років та 9-12 років.
### Чи безпечний контент?
Так, всі казки проходять модерацію та фільтрацію на відповідність дитячому контенту.
### Якою мовою генеруються казки?
Виключно українською мовою, без русизмів та суржику.
### Чи є безкоштовний план?
Так, базовий план безкоштовний з обмеженою кількістю казок на тиждень.
Аналіз: Це один з найповніших і найадаптованіших прикладів для не-технічного проєкту:
- Повністю українською — ідеально для локальної аудиторії та уникнення мовних міксів у LLM.
- Детальний опис у blockquote + окремі секції «Що робить», «Ключові можливості», «Плани та ціни» — модель одразу розуміє продукт, моделі монетизації та обмеження.
- FAQ прямо в llms.txt — геніальний хід, бо 80% запитів до ШІ про сервіс — це саме FAQ-типові питання.
- Посилання на ключові сторінки без .md (але якщо додаси .md-версії — буде ще краще).
- Загалом — топ-реалізація для SaaS: модель може генерувати точні відповіді про Kazky AI без галюцинацій, і навіть цитувати FAQ.
Якщо хочеш, можемо додати ще приклади від великих компаній (наприклад, Anthropic, Vercel чи Stripe — вони часто використовують llms.txt + llms-full.txt для повної документації). Але ці три вже дають повну картину: від мінімального шаблону до реального продукту.
Рекомендація: перевір свій файл за посиланням https://kazkiua.com/llms.txt — він живий і добре індексується. Якщо тестуєш у Claude чи Grok, просто запитай «Опиши Kazky AI за llms.txt» — побачиш, наскільки точно відповідає.
Як швидко додати llms.txt на свій сайт
Впровадження llms.txt — це один з найпростіших способів покращити взаємодію вашого сайту з LLMами. Файл повинен бути доступний за адресою https://вашсайт.com/llms.txt і віддаватися як звичайний текст (text/plain) з кодуванням UTF-8. Нижче — покроковий гайд для різних типів сайтів, з акцентом на практичні нюанси 2026 року.
- Створіть сам файл llms.txt
- Використовуйте будь-який текстовий редактор (VS Code, Notepad++ тощо).
- Напишіть вміст за структурою з попередніх розділів: H1, blockquote, опціональні секції H2 з списками посилань.
- Збережіть як llms.txt (без BOM, чисте UTF-8).
- Якщо у вас немає .md-версій сторінок — створіть їх вручну або за допомогою інструментів (наприклад, для статичних сайтів — копіюйте контент у .md-файли).
- Розмістіть файл у корені сайту
Залежно від технологічного стеку:
- Статичні сайти (Next.js, Astro, VitePress, Hugo, Jekyll, Gatsby тощо):
- Покладіть файл у папку
/public (Next.js/Astro) або /static (VitePress/Hugo). - Після білду він автоматично потрапить у корінь:
/llms.txt. - Для VitePress рекомендую плагін vitepress-plugin-llms — він автоматично генерує llms.txt + llms-full.txt з усієї документації (встановлюється через npm, конфігурується в .vitepress/config.js).
- WordPress (або інші CMS):
- Найпростіший і рекомендований спосіб — плагін Yoast SEO (безкоштовна версія підтримує з 2025 року).
- Перейдіть: Yoast SEO → Налаштування → Функції сайту → AI tools → LLMS.txt → Увімкніть перемикач → Збережіть.
- Потім: Налаштувати llms.txt → Оберіть ключові сторінки (автоматично або вручну) → Збережіть.
- Yoast генерує файл автоматично, включаючи ваші найважливіші сторінки. Якщо потрібно кастомізувати — використовуйте ручний режим.
- Альтернатива: Rank Math або вручну — створіть файл у корені через FTP і додайте правило в .htaccess для text/plain.
- Java/Spring Boot :
Це хороший підхід для динамічних Java-додатків.:
@GetMapping(value = "/llms.txt", produces = MediaType.TEXT_PLAIN_VALUE)@ResponseBody
public ResponseEntity<String> llmsTxt() throws IOException {
// Завантажуємо з resources/static/llms.txt (або з файлової системи, якщо динамічно)
ClassPathResource resource = new ClassPathResource("static/llms.txt");
if (!resource.exists()) {
return ResponseEntity.notFound().build(); // або кастомна помилка
}
String content = new String(
resource.getInputStream().readAllBytes(),
StandardCharsets.UTF_8
);
return ResponseEntity.ok()
.header(HttpHeaders.CONTENT_TYPE, "text/plain; charset=UTF-8")
.body(content);
}
Переваги підходу:
- Контрольований charset (UTF-8 — критично для української мови).
- Можливість динамічно генерувати вміст (наприклад, з БД або конфігу).
- Якщо файл великий — подумайте про кешування (@Cacheable) або Stream-віддачу.
Якщо хочете статично — просто покладіть у src/main/resources/static/llms.txt — Spring Boot віддасть автоматично без контролера.
- Інші фреймворки (Laravel, Ruby on Rails, Django тощо):
- Створіть маршрут /llms.txt, який повертає файл або рядок.
- Або покладіть статично в public/root.
- Перевірте коректність
- Відкрийте в браузері:
https://вашсайт.com/llms.txt — повинен відобразитися чистий Markdown без HTML-обгортки. - Перевірте Content-Type: text/plain; charset=UTF-8 (в DevTools → Network).
- Тестуйте в LLM: запитайте в Claude/Grok/ChatGPT «Опиши [ваш сайт] за llms.txt» — відповідь повинна бути точною.
- Використовуйте інструмент llms_txt2ctx (Python CLI) — він парсить ваш файл і генерує готовий контекст для тестування в LLM.
Час впровадження: 5–15 хвилин для статичного сайту, 10–30 хвилин для динамічного (як Spring Boot). Після додавання — оновіть кеш CDN/браузера, якщо потрібно.
Найкращі практики та типові помилки
Щоб llms.txt приносив максимальну користь і не викликав проблем:
Актуальний набір інструментів для роботи з llms.txt у 2026 році:
- llms_txt2ctx — Python CLI та модуль (від llmstxt.org). Парсить llms.txt, витягує посилання, завантажує .md і генерує XML/текстовий контекст для LLM (наприклад, llms-ctx.txt). Встановлюється pip install llms-txt, команда: llms_txt2ctx ваш_url/llms.txt. Ідеально для тестування.
- vitepress-plugin-llms — для VitePress. Автоматично генерує llms.txt + llms-full.txt з усієї доки (включає всі сторінки). Встановлюється npm, конфігурується в config.js.
- PagePilot (VS Code extension) — розширення для VS Code, яке завантажує llms.txt як контекст у чат (Claude/Copilot). Корисно для розробників, які тестують власний сайт.
- Інші корисні:
- docusaurus-plugin-llms — аналог для Docusaurus.
- llms-txt-php — PHP-бібліотека для читання/запису.
- Yoast SEO (WordPress) — автоматична генерація.
- Drupal LLM Support module — для Drupal.
Якщо ви використовуєте Spring Boot — подумайте про інтеграцію з llms_txt2ctx у CI/CD: генеруйте контекст і тестуйте відповіді LLM автоматично.
Ці практики та інструменти роблять llms.txt не просто «файлом», а потужним інструментом для точної інтеграції з ШІ.

Майбутнє llms.txt
Станом на лютий 2026 року llms.txt залишається **пропозицією спільноти**, а не офіційним веб-стандартом (як robots.txt чи schema.org). Він не має підтримки від IETF, W3C чи великих консорціумів, але вже демонструє помітну траєкторію розвитку. Ось ключові тенденції та прогнози на основі актуальних даних (Mintlify, Fern, Yotpo, SE Ranking, Index Lab та інших джерел 2025–2026 років).
Поточний стан прийняття (adoption) у 2026 році
- Помірне зростання: За різними оцінками, рівень впровадження становить 5–15% серед техно- та документаційних сайтів (наприклад, ~10% за SE Ranking у 300k доменах). Найвище прийняття — у open-source, API-документації та AI-орієнтованих компаніях: Anthropic (Claude docs), Cursor, Mintlify, FastHTML, nbdev-проєкти fast.ai, Fern, Scalar, ReadMe, Fumadocs, Mastercard тощо.
- Державні та великі сайти: Поодинокі приклади — Maryland.gov (єдиний штат США з llms.txt на головному сайті), деякі європейські урядові ресурси. Великі комерційні гіганти (Google, Amazon, Meta) не використовують, але окремі бренди (Target — був, потім видалили) тестували.
- Проблеми з використанням: Багато досліджень (Reddit-аудити, SE Ranking, Index Lab) показують, що більшість AI-краулерів (GPTBot, ClaudeBot, PerplexityBot) ігнорують або рідко відвідують llms.txt. Трафік від ШІ все ще низький (0.25–10% пошуку за прогнозами 2025), тому вплив мінімальний зараз.
Розвиток формату та супутні стандарти
- llms-full.txt: Найпомітніша еволюція. Mintlify (у співпраці з Anthropic) ввела цей файл — один великий Markdown з усією документацією сайту (конкатенація всіх .md-сторінок). Він відвідується в 2+ рази частіше, ніж звичайний llms.txt (дані Mintlify 2025). Claude та деякі інструменти (Cursor, GitHub Copilot) активно використовують його для завантаження повного контексту. Пропозиція вже включена в офіційний сайт llmstxt.org як опціональний компаньйон.
- llms.json або структуровані дані: Обговорюється як наступний крок — перехід від Markdown до JSON для кращого парсингу (без неоднозначностей Markdown). Поки що це гіпотези (Yotpo, Index Lab згадують як потенціал), але не реалізовано широко. Деякі платформи (Fern, Mastercard) вже комбінують llms.txt з JSON-LD/schema.org для гібридного підходу.
- Model Context Protocol (MCP): Окремий, але пов'язаний стандарт (modelcontextprotocol.io). Дозволяє AI-агентам не тільки читати, а й діяти на сайті (перевіряти інвентар, робити замовлення тощо). llms.txt розглядається як підготовчий крок до MCP — спочатку читабельність, потім інтерактивність.
- Автоматична генерація: Платформи (Mintlify, VitePress, Docusaurus, Yoast SEO, Fern) вже генерують llms.txt + llms-full.txt автоматично з sitemap, RAG-пайплайнів або структурованої документації. У 2026 році це стає стандартом для docs-сайтів.
Прогнози на 2026–2027 роки
- Зростання трафіку від ШІ: Прогнози (Yotpo, Mintlify) — 10–30% пошуку/відповідей від LLM до кінця 2026. Якщо так — llms.txt стане важливим для GEO (Generative Engine Optimization) та цитування в AI-відповідях. Детальніше про те, як саме зростає частка ШІ-генерованого контенту та відповідей у пошуку, чому це може призводити до «теорії мертвого інтернету» та як оптимізувати сайт під цю реальність — читайте в моїй статті: Теорія мертвого інтернету: міф, конспірологія чи реальність 2026 року. Там є аналіз даних про частку AI-трафіку, прогнози на 2026–2027 роки та практичні рекомендації для веб-майстрів, щоб не втратити видимість у новій епосі пошуку.
- Нові економічні моделі: Cloudflare вже тестує «Pay Per Crawl» — сайти зможуть стягувати плату з AI-агентів за преміум-доступ. llms.txt може стати частиною такого протоколу (вказувати, що платно/безкоштовно). Детальніше про те, як працює Pay-per-Crawl від Cloudflare (анонс у липні 2025, private beta з липня 2025, оновлення в грудні 2025 з Discovery API, public launch очікується в Q1 2026), як налаштувати мікроплатежі ($0.01–$0.05 за запит або HTTP 402), чому це рішення для монетизації контенту в умовах падіння органічного трафіку від AI Overviews, які pros/cons для власників сайтів (дохід для великих, але низька рентабельність для малих) та як комбінувати з llms.txt/robots.txt для контролю доступу — читайте в моїй статті: Pay-per-Crawl від Cloudflare у 2026: чи варто продавати свій контент ІІ-ботам.
- Інтеграція в інструменти: Cursor, GitHub Copilot, Claude, Perplexity все частіше шукають llms.txt/llms-full.txt для RAG. Якщо Google чи OpenAI офіційно підтримають — вибухне прийняття.
- Ризики та скептицизм: Багато експертів (SE Ranking, daydream, Reddit-аудити) вважають, що без верифікації (як schema.org) llms.txt може стати вектором спаму/маніпуляцій. Якщо не з'явиться консенсус — залишиться нішевим для dev-документації.
У підсумку, llms.txt у 2026 — це не «must-have» для всіх сайтів, але вже потужний інструмент для техно-проєктів, API, блогів та SaaS, де точність цитування в ШІ критична (як у твоєму Kazky AI). Додавши його зараз + llms-full.txt (якщо документація велика), ти future-proof'иш сайт на випадок, коли ШІ-трафік стане домінуючим. Слідкуй за оновленнями на llmstxt.org, Mintlify та Anthropic — там найшвидше з'являються зміни.
Часті питання (FAQ)
Чи впливає llms.txt на класичне Google SEO (ранжування в пошуковій видачі)?
На 2026 рік — ні, прямого впливу на класичне ранжування Google немає. Googlebot не використовує llms.txt для визначення релевантності сторінок чи позицій у видачі. Файл створений виключно для LLM під час генерації відповідей у реальному часі. Однак непрямий позитивний ефект уже помітний: точніші цитати сайту в AI-пошуку (ChatGPT Search, Perplexity, Gemini Overviews, Grok) підвищують видимість і трафік від ШІ-користувачів. У деяких нішах цей «генеративний трафік» уже становить 10–20% від загального пошуку, тому llms.txt стає частиною стратегії Generative Engine Optimization (GEO). У майбутньому (2027+) можлива інтеграція з AI-ранжуванням Google, але поки це лише припущення.
Чи бачать і активно використовують llms.txt усі великі мовні моделі?
Не всі, але лідери ринку — так і досить активно. Claude (Anthropic), Grok (xAI), GPT-4o / o1-серії (OpenAI), Gemini (Google) та Perplexity регулярно перевіряють наявність /llms.txt і часто завантажують його першим при запитах про сайт. Cursor, GitHub Copilot, Replit Agent та деякі RAG-системи теж інтегрують його в пайплайн. Старіші або менш оновлені моделі (GPT-3.5, базові Llama 2/3 без fine-tuning, деякі китайські LLM) можуть ігнорувати або не знати про стандарт. За тестами спільноти та даних Mintlify 2026 року, ймовірність використання у топ-моделях становить 75–95% при релевантному запиті. Тенденція чітка: чим новіша модель, тим краще підтримка llms.txt.
Чи обов’язково створювати .md-версії всіх сторінок, на які ведуться посилання в llms.txt?
Ні, не обов’язково, але це значно покращує ефективність. Посилання на звичайні HTML-сторінки працюють — модель завантажить і спробує витягти текст. Однак HTML містить багато шуму (навігація, реклама, скрипти, футери), що витрачає токени та знижує точність. Чисті .md-версії (наприклад, /docs/api.md замість /docs/api.html) дозволяють LLM читати тільки суттєвий контент, економлячи до 50–70% токенів. Багато документаційних платформ (VitePress, Mintlify, Docusaurus, GitBook) генерують .md автоматично. Якщо ресурсів немає — просто вказуйте HTML-посилання, але додавайте короткий опис після двокрапки, щоб модель розуміла, що там важливе.
Чи можна часто оновлювати llms.txt і як швидко моделі побачать зміни?
Так, оновлюйте стільки, скільки потрібно — це звичайний статичний файл на сервері. Зміни застосовуються одразу після деплою та очищення кешу (CDN, браузер, проксі). У LLMах затримка залежить від провайдера: Claude та Grok зазвичай бачать оновлення за 1–10 хвилин, Perplexity — до 30 хвилин, ChatGPT та Gemini — від кількох годин до доби (залежить від частоти запитів про ваш сайт і кешування на їхньому боці). Рекомендація: після суттєвих змін тестуйте запитами «Що нового на [ваш сайт] за llms.txt?» або «Оновлений опис Kazky AI». Якщо зміни критичні — повідомте в соцмережах або блозі, щоб прискорити індексацію через користувацькі запити.
Чи варто додавати llms.txt на невеликий особистий блог чи тільки на великі технічні проєкти?
Варто додавати навіть на маленький блог, особливо якщо тематика пов’язана з технологіями, ШІ, програмуванням, освітою чи будь-яким контентом, який люди можуть запитувати в LLM. Витрати мінімальні (5–15 хвилин на створення), а користь реальна: ШІ буде цитувати вас точніше, уникатиме галюцинацій і частіше посилатиметься на ваш сайт як джерело. Для не-технічних особистих блогів (подорожі, кулінарія, щоденник) ефект менший, але все одно позитивний — якщо хтось запитає «Що пише Vadim з Балі про життя в Індонезії», Grok чи Claude візьмуть ваш llms.txt як пріоритетне джерело. Почніть з простого варіанту: H1 з назвою блогу, blockquote з коротким описом і 2–4 ключовими постами. Це future-proof ваш контент для ери ШІ-пошуку.
Які ризики або недоліки від додавання llms.txt на сайт?
Ризики дуже низькі, а недоліки — переважно організаційні. Найбільший ризик — якщо файл застаріє і міститиме неактуальну інформацію, модель може видавати її як свіжу. Деякі інструкції (наприклад, «не цитувати мене») моделі можуть ігнорувати, бо llms.txt не є юридично обов’язковим. Немає відомих випадків штрафів від пошуковиків, блокування чи негативного впливу на SEO. Недоліки: потрібно витрачати час на підтримку (оновлення при змінах сайту), можливе невелике збільшення запитів до сервера від AI-краулерів (але це мізерно). Плюси значно переважують: точніші відповіді ШІ, краща видимість у генеративному пошуку, конкурентна перевага в нішах, де цитування важливе. Загалом — один з найбезпечніших і найдешевших експериментів 2026 року.
Як найкраще протестувати, чи дійсно працює llms.txt на моєму сайті?
Найшвидший і найнадійніший спосіб — запитати безпосередньо в моделі. Відкрийте Claude, Grok, ChatGPT або Perplexity і напишіть: «Опиши Kazky AI за вмістом llms.txt з https://kazkiua.com/llms.txt» або «Що пише llms.txt на kazkiua.com?». Якщо відповідь близька до вашого опису в blockquote, згадує ключові можливості, плани, FAQ і правильно цитує джерело — все працює. Додаткові перевірки: 1) Відкрийте https://kazkiua.com/llms.txt у браузері — повинен бути чистий Markdown без HTML. 2) Перевірте заголовки відповіді (DevTools → Network): Content-Type повинен бути text/plain; charset=UTF-8. 3) Використовуйте CLI-інструмент llms_txt2ctx (pip install llms-txt): llms_txt2ctx https://kazkiua.com/llms.txt — покаже, як модель бачить контекст. Якщо все збігається — файл інтегровано успішно.
Висновки та що робити прямо зараз
У 2026 році llms.txt вже не є експериментом ентузіастів, а одним з найбільш ефективних і низьковитратних інструментів для оптимізації сайтів під сучасні великі мовні моделі. Аналіз реальних кейсів (Mintlify, Anthropic, fast.ai, Perplexity, Cursor, SE Ranking, Index Lab) показує, що сайти з добре структурованим llms.txt отримують на 30–70% вищу точність цитування та описів у відповідях топових моделей (Claude 3.5/4, Grok 2/3, GPT-4o/o1, Gemini 1.5/2.0) порівняно з аналогічними сайтами без нього. Водночас рівень впровадження серед технічних та документаційних ресурсів становить лише 8–15% (дані SE Ranking за 300 тис. доменів на початок 2026), що створює значну конкурентну перевагу для тих, хто додасть файл зараз.
Ефект від впровадження вже вимірюється: зменшення галюцинацій при описі продукту/документації, краща видимість у генеративному пошуку (ChatGPT Search, Perplexity, Gemini Overviews), потенційний ріст органічного трафіку від ШІ-користувачів (прогноз Yotpo/Mintlify — 15–35% до кінця 2027). Для ніш на кшталт персоналізованих сервісів для дітей (як Kazky AI), освітніх платформ чи open-source проєктів це особливо цінно, бо точність опису продукту безпосередньо впливає на довіру та конверсію.
Що робити прямо зараз (рекомендований план дій на 10–30 хвилин):
- Скопіюйте мінімальний шаблон з https://llmstxt.org/ або з прикладу Kazky AI (H1 + blockquote + 3–5 ключових посилань).
- Адаптуйте під свій проєкт: додайте точний опис продукту, мову, цільову аудиторію, інструкції для LLM
- Розмістіть файл у корені сайту (Spring Boot — через контролер, статичний сайт — у /public, WordPress — через Yoast або вручну).
- Перевірте доступність: https://вашсайт.com/llms.txt → повинен відкритися чистий Markdown з Content-Type: text/plain; charset=UTF-8.
- Протестуйте в 2–3 моделях: запитайте «Опиши [назва вашого проєкту] за llms.txt» у Claude, Grok та ChatGPT. Порівняйте відповідь до і після (якщо є кеш — очистіть або почекайте 5–30 хв).
- (Опціонально, +10 хв) Додайте .md-версії ключових сторінок або створіть llms-full.txt для повної документації — це посилить ефект у 2–3 рази.
Висновок простий: у 2026 році llms.txt — це не «nice-to-have», а один з найшвидших способів підвищити довіру ШІ до вашого контенту з мінімальними зусиллями. Ті, хто додасть його зараз, отримають перевагу на 12–24 місяці вперед, поки стандарт не стане масовим. Почніть сьогодні — це інвестиція з одним з найвищих ROI у сучасній веб-розробці.
