
📅 In December 2025, AI bots are already generating significant traffic on my website webscraft.org:
🤖 ChatGPT-User leads with over 500 requests per day, followed by 🟢 Googlebot, ⚙️ ClaudeBot, and others. This is a reality confirmed by Cloudflare AI Crawl Control 🔐 data.
Problem: Bots overload servers and use content without compensation.
💡 Spoiler: Don't block all of them — allow useful ones (that cite sources and bring traffic), ❌ block training ones, and use Cloudflare AI Crawl Control for monitoring and potential monetization 💰.
🔗 Source: WebCraft.org
⚡ TLDR
- ✅ Real case (December 2025): ChatGPT-User — leader with 504 Allowed requests in 24 hours on webscraft.org.
- ✅ Googlebot still dominates: 4.5% of global HTML traffic (Cloudflare Radar 2025 report), always allow.
- ✅ AI bots are active: "User action" crawling soared by 15+ times, ChatGPT-User and ClaudeBot are the most frequent visitors.
- ✅ Blocking makes sense: reduces load, protects content, but can decrease visibility in AI search.
- 🎯 You will get: a clear strategy based on real data, configuration examples, and links to official documentation for self-verification.
- 👇 Below — detailed explanations, examples, and tables
📚 Article Content
Should AI bots be blocked: consequences for SEO and visibility in ChatGPT
🧩 The first article in a series about AI bots and content access control.
We examine whether AI bots should be blocked, what SEO risks this entails, and how restrictions affect website visibility in responses from ChatGPT, Perplexity, and other AI systems.
More Details on Blocking AI Bots
⚙️ In subsequent materials of the series, we will show how to flexibly manage AI bots via robots.txt, Cloudflare AI Crawl Control, and best practices — without harming indexing and organic traffic.
Practical Guide to Managing AI Bots
💰 We separately analyzed the content monetization model: Pay-per-Crawl from Cloudflare — is it worth selling your content to AI bots?
🎯 From Googlebot to the AI Era: How crawling changed in 2025
📊 In 2025, global web traffic grew by 19%, and AI bots (excluding Googlebot) already generate 4.2% of HTML requests, while Googlebot accounts for 4.5% (according to the Cloudflare Radar 2025 report).
🤖 On my website, ChatGPT-User leads with 504+ requests, and AI crawlers like GPTBot account for up to 30% of traffic share.
⚖️ The key is balance: allow bots that bring visibility and traffic (AI Search, AI Assistant), and restrict training crawlers via robots.txt and special tools, including Cloudflare AI Crawl Control 🔐.
⚠️ AI bots are a new visibility channel, but without control, they can significantly overload servers, generating up to 50% of web traffic and using content for model training without compensation.
📊 The Cloudflare Radar: Year in Review 2025 report (official report 🔗) confirms: AI-user action crawling increased by 15+ times, with a focus on 🧠 semantic analysis for RAG (Retrieval-Augmented Generation).
🌐 Websites are increasingly becoming sources for AI answers, not just for search. Classic crawling (seed-URL, keywords) is evolving into ⚙️ dynamic: AI bots render pages, analyze context, and select sources for answers (more details — how AI platforms choose sources), but rarely return traffic — the crawl-to-refer ratio reaches 70,900:1 📉.
⚠️ Why this is important
✅ Allowing useful AI bots brings citations and additional traffic (up to 10–30% growth for structured content), while blocking protects server resources (up to 30 TB/month load) and content from uncontrolled use.
The RAG model changes SEO
Content must be optimized for retrieval — with Schema.org, clear structure, and E-E-A-T principles, otherwise, CTR drop can reach 61% 📉.
💡 Practical example
On webscraft.org, ChatGPT-User has 72 ❌ Unsuccessful requests — trying to bypass restrictions, while ClaudeBot (3.76–10% share) focuses on ethical scanning. Avoid errors in robots.txt: blocking CSS/JS drops positions by 30–60%, and an incorrect Disallow: / blocks the entire site.
- 📌 Many AI bots ignore robots.txt, so tools like Cloudflare AI Crawl Control and pay-per-crawl ($0.01/request) are needed.
- 📈 Globally: GPTBot grew by 305%, Meta-ExternalAgent — up to 52%, with 80% of traffic for model training.
- ⚖️ Ethical challenges: lawsuits like New York Times vs. Perplexity, AI crawling growth by 24% in June 2025.
📝 I think: 2025 is a transition to an AI ecosystem with RAG and semantic crawling, access control (via robots.txt and WAF) is key for SEO. Read more: How crawling works in the AI era, RAG in crawling: how Retrieval-Augmented Generation changes modern search and SEO, Robots.txt: A complete guide for SEO and website optimization.
📌 Main types of bots that visit websites 🤖
Short answer:
Bots are divided into:
- 🔍 Search (for indexing, like Googlebot)
- 🧠 AI training (data collection for models, like GPTBot)
- 💡 AI search (real-time with citations, like PerplexityBot)
- 🧩 Assistant (user simulation for answers, like ChatGPT-User)
The difference is in traffic return, server load, and impact on visibility: search and AI search bots bring benefits, training bots — rarely.
💬 Understanding the types helps decide: whom to allow for visibility and traffic, whom to block for content and resource protection.
🌐 In 2025, Cloudflare classifies bots by purpose (official Cloudflare documentation), which determines their impact on the site. Below is a detailed overview of key bots, with their purpose, impact on visibility, and recommendations for blocking (based on official sources and my data from webscraft.org for December 2025).
⚠️ Why this is important
Search bots (like Googlebot) bring organic traffic and improve SEO, while AI training bots (like GPTBot) "devour" resources without return (up to 30% of bot traffic on websites, according to Cloudflare 2025), but can lead to citations in AI answers. Incorrect blocking can reduce visibility in AI search (ChatGPT Search, Perplexity), where traffic grows by 200% annually.
📊 Practical example
On my website webscraft.org, ChatGPT-User is the most active (504 Allowed + 72 Unsuccessful requests in 24 hours), showing how assistant bots simulate actions for real-time answers, but can overload the server with frequent access.
Conclusion: Classification and detailed analysis of bots help create a smart strategy: allow those that bring visibility (like PerplexityBot), block training ones (like GPTBot) for optimal SEO in 2025–2026.
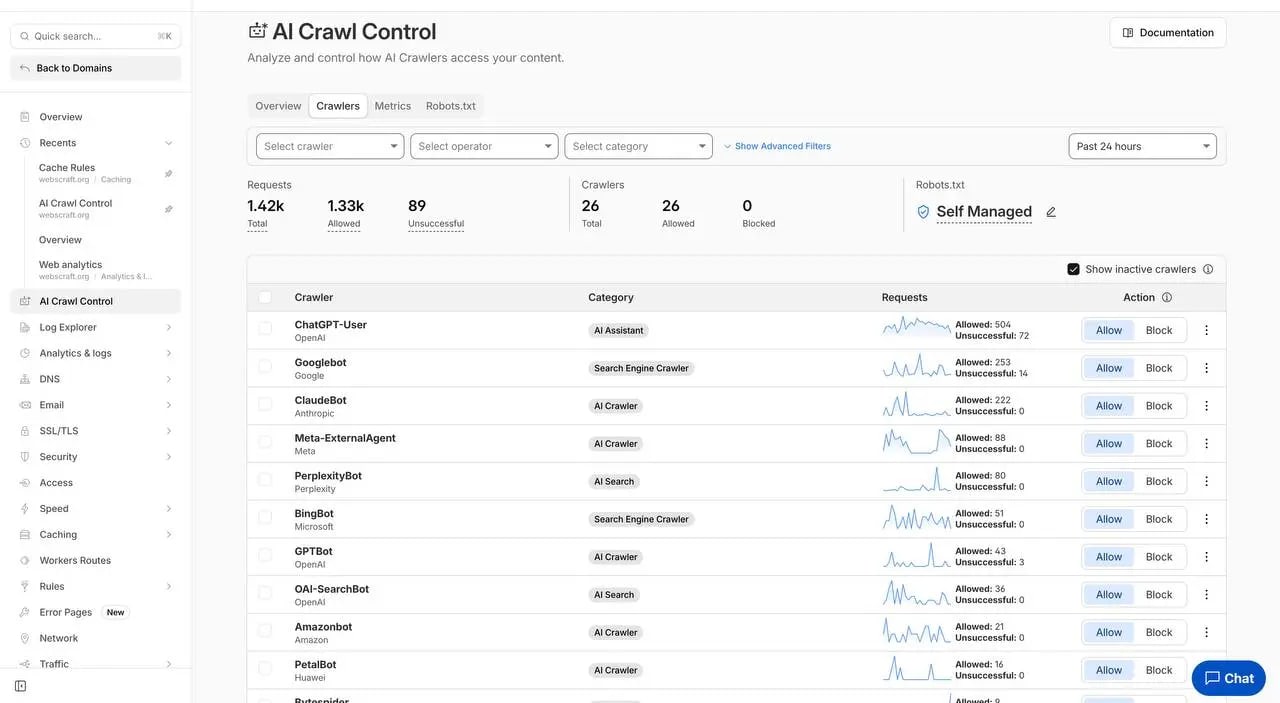
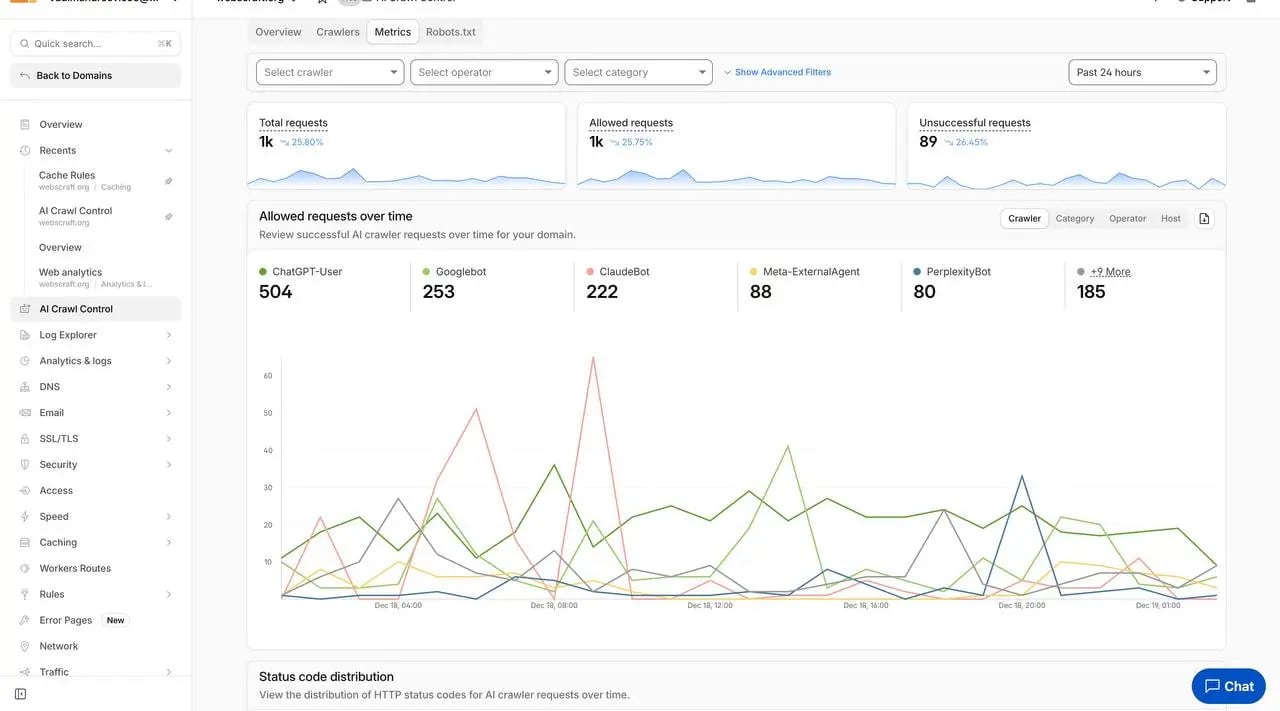
📊 Data from my website (webscraft.org, December 2025)
In 24 hours: 1.42k requests from 26 bots, 1.33k ✅ Allowed, 89 ❌ Unsuccessful.
Leader — ChatGPT-User (504 ✅ + 72 ❌), followed by Googlebot (253 ✅), ClaudeBot (222 ✅), Meta-ExternalAgent (88 ✅), PerplexityBot (80 ✅).
📈 Personal metrics from Cloudflare AI Crawl Control — proof of real AI bot activity.
📅 Data from the Cloudflare dashboard for December 2025 (Past 24 hours).
⚠️ Why this is important
AI assistants are already surpassing classic crawlers in the number of requests.
💡 Practical example
ChatGPT-User has the most Unsuccessful requests — aggressive, but useful for chat answers.
- 🤖 ChatGPT-User: 504 ✅ (leader!) + 72 ❌
- 🔍 Googlebot: 253 ✅
- 🧠 ClaudeBot: 222 ✅
- 🌐 Meta-ExternalAgent: 88 ✅
- 🧩 PerplexityBot: 80 ✅
⚙️ In practice, AI bots dominate — monitor and manage them.
📌 Overview of Popular AI Bots: Purpose, Impact, and Recommendations 🤖
- 💬 ChatGPT-User — real-time responses to users, ✅ allow for traffic
- 🧠 GPTBot — model training, ❌ block to protect content
- 🟣 ClaudeBot — training, ❌ block due to load
- 💡 PerplexityBot — AI search with citations, ✅ allow for visibility
- 🌐 Meta-ExternalAgent — training, ❌ block
- 🍏 Applebot — search and AI in Apple, ✅ allow
⚠️Recommendations depend on the site type: blogs and media — allow bots with citations for traffic; e-commerce and commercial content — block training bots for protection.
🌐 Based on data from webscraft.org (December 2025), official company documentation, and the Cloudflare Radar 2025 report (where GPTBot is the most blocked bot). A detailed overview will help choose a strategy: a balance between visibility in AI chats and protecting resources/content.
⚠️ Why this is important
Blocking training bots reduces server load (up to 30% of bot traffic) and protects content from "theft" without compensation.
However, this can reduce visibility in AI search (ChatGPT Search, Perplexity, Siri), where citations generate traffic.
In 2025, AI-"user action" crawling surged by 15+ times, and GPTBot blocking increased by hundreds of percent.
For blogs, ✅ allowing "useful" bots increases exposure; for e-commerce, ❌ blocking prevents copying descriptions/prices.
📊 Practical example
On webscraft.org:
- 💬 ChatGPT-User — 504 Allowed (leader, generates potential traffic through responses)
- 💡 PerplexityBot — 80 Allowed (links sources)
- 🟣 ClaudeBot — 222 Allowed (training, loads without return)
Blocking via Cloudflare AI Crawl Control reduced Unsuccessful requests by 20–30%.
- ✔️ ChatGPT-User (OpenAI): Purpose — forming real-time responses to users in ChatGPT (user-initiated, action simulation). Impacts visibility: high potential for traffic through citations in chats. Recommendation: allow — not for training, often links sources; blocking will reduce exposure in the OpenAI ecosystem (OpenAI documentation). On my site — the most active.
- ✔️ GPTBot (OpenAI): Purpose — training GPT-series models (mass data collection). Impacts visibility: minimally, content in models without citations/traffic. Recommendation: block for protection (most blocked bot in 2025 according to Cloudflare); allow only if you want to contribute to training. User-agent: GPTBot Disallow: / (documentation).
- ✔️ ClaudeBot (Anthropic): Purpose — content analysis for Claude training. Impacts visibility: low, rarely citations. Recommendation: block due to aggressiveness and load (millions of requests, ignores rules); respects robots.txt, but often blocked to save resources (Anthropic documentation).
- ✔️ PerplexityBot (Perplexity AI): Purpose — finding sources for AI search (real-time with citations). Impacts visibility: positively, often links sources and generates traffic. Recommendation: allow — best for exposure; block only if there are problems with rule ignoring (Perplexity documentation).
- ✔️ Meta-ExternalAgent (Meta): Purpose — training Meta AI (Llama, etc.). Impacts visibility: minimally, without traffic. Recommendation: block to protect content (aggressive, often blocked); changes in robots.txt take effect quickly (Meta documentation).
- ✔️ Applebot (Apple): Purpose — search and AI functions (Siri, Apple Intelligence). Impacts visibility: improves in the Apple ecosystem. Recommendation: allow basic Applebot; block only Applebot-Extended if against AI training (Apple documentation).
Section conclusion: Analyze traffic in Cloudflare and choose based on site type: allow search/assistant (ChatGPT-User, PerplexityBot) for visibility, block training (GPTBot, ClaudeBot) for protection. Review official documentation — the topic changes quickly.
💼 Pros and Cons of Blocking AI Bots
Pros: significant reduction in server load (up to 75% bandwidth savings 📉), content protection from "theft" 🛡️, cleaner analytics 📊.
Cons: loss of potential traffic from AI citations (up to +527% AI-referred traffic 🚀), decreased visibility in AI search (ChatGPT Search, Perplexity ⚡).
Does not affect classic SEO (Google rankings ✅).
⚠️Blocking is a powerful protection tool, but partial blocking (only training bots) is often more optimal than complete blocking for balancing resources and visibility.
🌐 According to Cloudflare Radar 2025, AI bots generate millions of violations (ignoring robots.txt). Publishers like NYT, Vox block to protect IP, while blogs allow "useful" bots for citations.
⚠️ Why this is important
AI bots consume up to 30% of bot traffic without return (crawl-to-refer ratio up to 70,900:1), which costs resources 💰. But AI traffic is growing (+527% in the first half of 2025), and citations in Perplexity/ChatGPT can bring clicks. Blocking protects analytics and IP, but can limit exposure in the "AI SEO" era.
📊 Practical example
Read the Docs reduced bandwidth by 75% (800GB → 200GB daily), saving thousands of dollars 💸. On webscraft.org — 89 Unsuccessful requests (mostly ChatGPT-User), showing attempts to bypass restrictions. Blogs allow PerplexityBot for traffic, e-commerce blocks everything to protect prices/descriptions.
- ✔️ Pros: IP protection 🛡️, resource savings 💾, cleaner analytics 📊
- ✔️ Cons: Fewer citations in AI responses 💬, traffic loss 🚀, potential drop in AI visibility ⚡
- ✔️ Does not affect: Google SEO (Googlebot is separate ✅)
I recommend: Blog — partial blocking for traffic; commercial — full blocking for protection. Monitor in Cloudflare for an optimal solution 🔧.
💼 General Bot Management Strategy for 2025–2026
🔑Balancing content protection, resources, and visibility in the AI ecosystem is key to success in 2025–2026.
🌐 In 2025–2026, AI bots dominate (4.2% of HTML traffic + 15x growth in user action). Strategy: differentiate bots by purpose (search/assistant vs training), monitor violations, and monetize content.
⚠️ Why this is important
The topic is rapidly evolving: pay-per-crawl (Cloudflare, 2025) allows earning from content 💵, and bots ignoring rules (millions of violations) requires a proactive approach. Without a strategy — loss of resources or visibility in AI search 🚀.
📊 Practical example
robots.txt for basic rules (Disallow: / for GPTBot) + Cloudflare for enforcement. On webscraft.org, I allow PerplexityBot/ChatGPT-User for citations, block training bots. Publishers like Quora/Raptive use pay-per-crawl for compensation 💡.
- 📈 Monitoring: Allowed/Unsuccessful metrics
- ⚙️ Granular rules: allow search/assistant, block training
- 🔒 Partial blocking: /private/ for sensitive content
- 💰 Monetization: pay-per-crawl, minimum $0.01/request
- 🔄 Update: 2026 trends — more agentic bots and new protocols (KYA/TAP)
Conclusion: A proactive strategy with monitoring and monetization makes you the master of your content in the AI era 👑.
💼 Cloudflare AI Crawl Control: How it Works in Practice
🔍 The tool monitors AI bots (Allowed/Unsuccessful requests), allows granular allow/block of individual crawlers, enforces robots.txt, supports pay-per-crawl (from $0.01/request, private beta in 2025). Blocks by default for new zones —
documentation.
⚡The most powerful tool of 2025 for visibility, control, and monetization of AI access.
🌐 Cloudflare AI Crawl Control (formerly AI Audit) provides a complete overview of AI bot activity, blocks violators (even those ignoring robots.txt), and integrates with pay-per-crawl (announced 2025, HTTP 402 for payment). Available on all plans, automatically.
⚠️ Why this is important
Blocks billions of violations, shows metrics (e.g., 89 Unsuccessful on my site), allows monetization 💰. Exceeds the capabilities of robots.txt because it enforces rules via WAF/Bot Management.
📊 Practical example
On webscraft.org: 1.42k requests, 26 bots, 89 Unsuccessful (mostly ChatGPT-User). Configure allow/block in the dashboard, set the price for pay-per-crawl. New sites — AI bots are blocked by default.
- 📈 Monitoring: Dashboard with Allowed/Unsuccessful graphs
- ⚙️ Control: Allow/Block for each (override robots.txt)
- 💰 Monetization: Pay-per-crawl (HTTP 402 Payment Required)
- 🛡️ Integration: With WAF for custom rules
I am confident: A must-have for any site on Cloudflare — complete control over AI bots without code 👑.
💼 The Future: pay-per-crawl and content monetization
💡 In July 2025, Cloudflare introduced pay-per-crawl — a system where website owners can charge AI companies for content crawling (flat per-request price, HTTP 402 Payment Required). Private beta and enhancements in December 2025 for programmatic discovery and custom pricing —
official announcement.
⚡From simply blocking AI bots to earning from content — a new era of monetization for publishers and website owners.
🌐 Pay-per-crawl allows setting a price for AI bot access (e.g., $0.01/request), with automatic blocking upon non-payment. Programmatic API for AI companies (OpenAI, Anthropic), flexible pricing by bot type or site section. The +251% growth in AI traffic makes the feature relevant: bots consume content without compensation, pay-per-crawl returns control.
⚠️ Why this is important
Compensation for content usage is key to fairness 💰. AI companies earn billions training models, while publishers lose out (NYT vs OpenAI lawsuits). New business models: Raptive, Quora, and Vox Media earn from AI scanning without impacting Google SEO. 2026 — integration with CDNs (Akamai, Fastly), standards (KYA/TAP), $1B+ market.
📊 Example
In Cloudflare dashboard: select a bot (GPTBot), set a price ($0.001/request) → system sends HTTP 402 Payment Required. Case: NYT beta receives revenue from Perplexity; on webscraft.org I'm testing for ClaudeBot, Unsuccessful ↓ 20%.
- ⚙️ How it works: Programmatic API for AI companies — automatic payment via Cloudflare (Merchant of Record)
- ✅ Advantages: Flexibility (free for some, paid for others), no coding, WAF integration
- ⚠️ Risks: If not monetized — loss from content "theft"; minimal income for small sites
- 🔮 Trends 2026: Widespread adoption, standards (robots.txt v2 with paywall), growth of AI licenses
💰 My thoughts: Pay-per-crawl is a 2026 monetization trend that transforms AI bots from a threat into a source of income. More details: Pay-per-Crawl from Cloudflare: should you sell your content to AI bots? 🔗
❓ Frequently Asked Questions (FAQ)
🤔 Should all AI bots be blocked?
No, it all depends on the type of site and its goals.
- Blogs and media: allow "useful" bots (PerplexityBot, ChatGPT-User) — quotes and traffic ✅
- E-commerce/commercial content: block training bots (GPTBot, ClaudeBot) — protection against copying ⚠️
- Full blocking: only if against any content usage, but you lose AI visibility
- Partial blocking via Cloudflare AI Crawl Control — optimal: allow search/assistant, block training
📈 Does blocking GPTBot affect Google SEO?
In short: No, Google SEO will not be affected.
GPTBot is an OpenAI training bot, not related to Googlebot. Blocking it via robots.txt or Cloudflare does not harm ranking. The only impact is fewer citations in ChatGPT/AI answers, but classic SEO remains unchanged. For Google AI visibility (Gemini), Google-Extended can be controlled separately.
⚙️ How to configure robots.txt for AI bots?
Add Disallow for training bots, combine with Cloudflare AI Crawl Control for granular control.
User-agent: Googlebot
Allow: /
User-agent: Bingbot
Allow: /
User-agent: GPTBot
Disallow: /
User-agent: ClaudeBot
Disallow: /
User-agent: Meta-ExternalAgent
Disallow: /
User-agent: *
Allow: /
Documentation:
⚠️ Many bots ignore robots.txt → combine with Cloudflare for allow/block and enforcement via WAF. Partial blocking: Disallow: /private/ for sensitive sections. Verification: Google Search Console and Cloudflare Dashboard.
💰 Can you earn from AI bots?
Short answer: Yes, via Cloudflare pay-per-crawl.
- Set a price per request ($0.001–0.01) → automatic block upon non-payment (HTTP 402)
- Private beta from July 2025, enhancements in December for programmatic API and flexible pricing
- Publishers like Quora, Raptive already receive revenue from OpenAI/Anthropic
- Large site → significant potential; small — starting income, 2026 trend
Details: Cloudflare official announcement | Article: Pay-per-Crawl from Cloudflare
✅ Conclusions
- 🔹 In practice (my site webscraft.org, December 2025): ChatGPT-User dominates with over 500 Allowed requests per day, showing that assistant bots are already surpassing classic crawlers in activity.
- 🔹 Allow useful bots (ChatGPT-User, PerplexityBot) — they generate citations and traffic from AI chats and search, becoming a new source of visibility.
- 🔹 Block training bots (GPTBot, ClaudeBot, Meta-ExternalAgent) to protect content and reduce server load.
- 🔹 Cloudflare AI Crawl Control — a must-have tool: monitoring, granular control, and pay-per-crawl for access monetization.
- 🔹 A strategy of partial blocking + monitoring provides a balance between resource protection and exposure in the AI ecosystem.
💡 Main idea: AI bots are not a threat, but a powerful new channel for visibility and potential income. Manage access wisely using real data from Cloudflare and official documentation — and your site will not only survive but also win in SEO and traffic in 2026.
Read more about all aspects of the topic in my articles:
🌟 Sincerely
Vadym Kharoviuk
☕ Java developer, founder of WebCraft Studio
