
🤖 Уявіть: ваш сайт щомісяця відвідують мільйони гостей, які нічого не клікають, не дивляться рекламу і не залишають рефералів. 📄 Вони просто копіюють весь контент і зникають. ⚠️ Це не фантастика — це GPTBot, ClaudeBot, CC-Net и десятки інших ІІ-краулерів, які вже зараз генерують до 80 % всього бот-трафіку. 💸 І найгірше — ви за це нічого не отримуєте.
🛡️ Cloudflare у 2025-му запропонував радикальну відповідь: Хочете мій контент для навчання ШІ? Платіть за кожен запит. 💰 Так з’явився Pay-per-Crawl.
💭 Я думаю, що для великих видавців — це потенційно десятки тисяч доларів нових доходів щомісяця. 📉 Для більшості середніх і малих сайтів — поки що більше ризиків і витрат, ніж реальних грошей.
⚡ Коротко
- ✅ Pay-per-Crawl — це HTTP 402 Payment Required для ІІ-ботів: плати або отримуй відмову
- ✅ Станом на грудень 2025 — ще private beta, публічний запуск очікується в Q1 2026
- ✅ Реалістичний дохід: великі сайти — $50–200 k/міс, середні — $50–500, малі блоги — часто $0–50
- 🎯 Ви отримаєте: повний розбір плюсів і мінусів, три гіпотетичні кейси, порівняння альтернатив і план дій на 2026 рік
- 👇 Детальніше читайте нижче — з цифрами і чесними ризиками
Зміст статті:
🎯 1. Від безкоштовного вампіризму ШІ до платного доступу в 2025–2026
😠 AI-компанії заробляють мільярди на нашому контенті, а ми отримуємо лише рахунки за трафік — типова скарга видавців у 2025 році.
Детальніше про це я написав у статті
Як працює краулинг в епоху AI.
🤖 Уявіть ситуацію, коли ваш сайт, наповнений унікальним контентом, стає безкоштовним "шведським столом" для ШІ-краулерів: GPTBot від OpenAI, ClaudeBot від Anthropic чи CC-Net від Common Crawl. Ці ШІ-боти сканують сторінки тисячі разів, витягуючи дані для тренування моделей, але в обмін не приносять жодного реферального трафіку. Це класичний приклад монетизації AI краулерів — коли ШІ-компанії монетизують ваш контент, а ви платите за серверне навантаження. 📊 У 2024 році співвідношення crawl-to-referral (кількість запитів краулера на одну реферал-відвідину) досягло абсурдних показників: OpenAI — 1700:1, Anthropic — 73 000:1, Common Crawl — 31 000:1. Для порівняння, Googlebot у той же період тримався на рівні 14:1 — все ще несправедливо, але принаймні з рефералами.
📡 За даними Cloudflare Radar станом на грудень 2025 року, ситуація тільки погіршилася. Трафік від ШІ тепер становить 50–80 % усього бот-трафіку на веб-сайтах, з піковим зростанням на 86 % у другому півріччі 2024 року. Загальний AI bot traffic зріс на 18 % від травня 2024 до травня 2025, а окремі краулери, як GPTBot, показали стрибок у 305 %. 📉 Це не просто цифри: для новинних сайтів падіння органічного трафіку сягнуло 25–38 % рік до року (YoY), здебільшого через AI Overviews у Google та прямі відповіді від ШІ-асистентів. ⚖️ Видавці, як The New York Times чи Reuters, вже подали позови проти OpenAI та Anthropic за "крадіжку" контенту без компенсації, вимагаючи мільярди в угодах про ліцензування даних для ШІ.
- 🚨 50–80 % всього бот-трафіку — це ІІ-краулери: З них GPTBot займає 35,5 %, ClaudeBot — 11,2 %, а Meta-ExternalAgent — до 19 % у 2025-му.
- 📈 Трафік від ШІ виріс на 86 % за друге півріччя 2024 і продовжує рости: Пікові сплески в листопаді 2024 та березні–квітні 2025, з +32 % YoY у квітні.
- 💸 Падіння органічного трафіку у новинних сайтів — 25–38 % рік до року: AI-боти "відкушують" реферали, лишаючи тільки навантаження — до 16 % invalid traffic від GPTBot та ClaudeBot.
🧛♂️ Цей "безкоштовний вампіризм" ШІ руйнує екосистему вебу: видавці втрачають доходи від реклами та підписок, а ШІ-компанії, як OpenAI (з капіталізацією $157 млрд у 2025), будують імперії на чужому контенті. 🔐 Зростання AI crawl control — ключове: 14 % топ-доменів уже використовують robots.txt для блокування ШІ-ботів. 💰 Саме тому в липні 2025 Cloudflare запустив Pay-per-Crawl — перший у світі механізм мікроплатежів за краулінг, де ІІ-боти платять $0.01–$0.05 за запит, або отримують HTTP 402 Payment Required. 🛡️ Це не просто інструмент захисту контенту від ШІ, а крок до fair data economy, де монетизація AI краулерів стає нормою. 🚀 У 2026-му, з public launch, це може змінити гру для SMB та великих видавців — але чи готові ви до платного доступу для ШІ?
➡️ У наступних розділах розберемо, як це працює на практиці, плюси/мінуси та альтернативи, як llms.txt чи Really Simple Licensing, щоб ви могли обрати стратегію AI crawl control для свого сайту вже зараз.
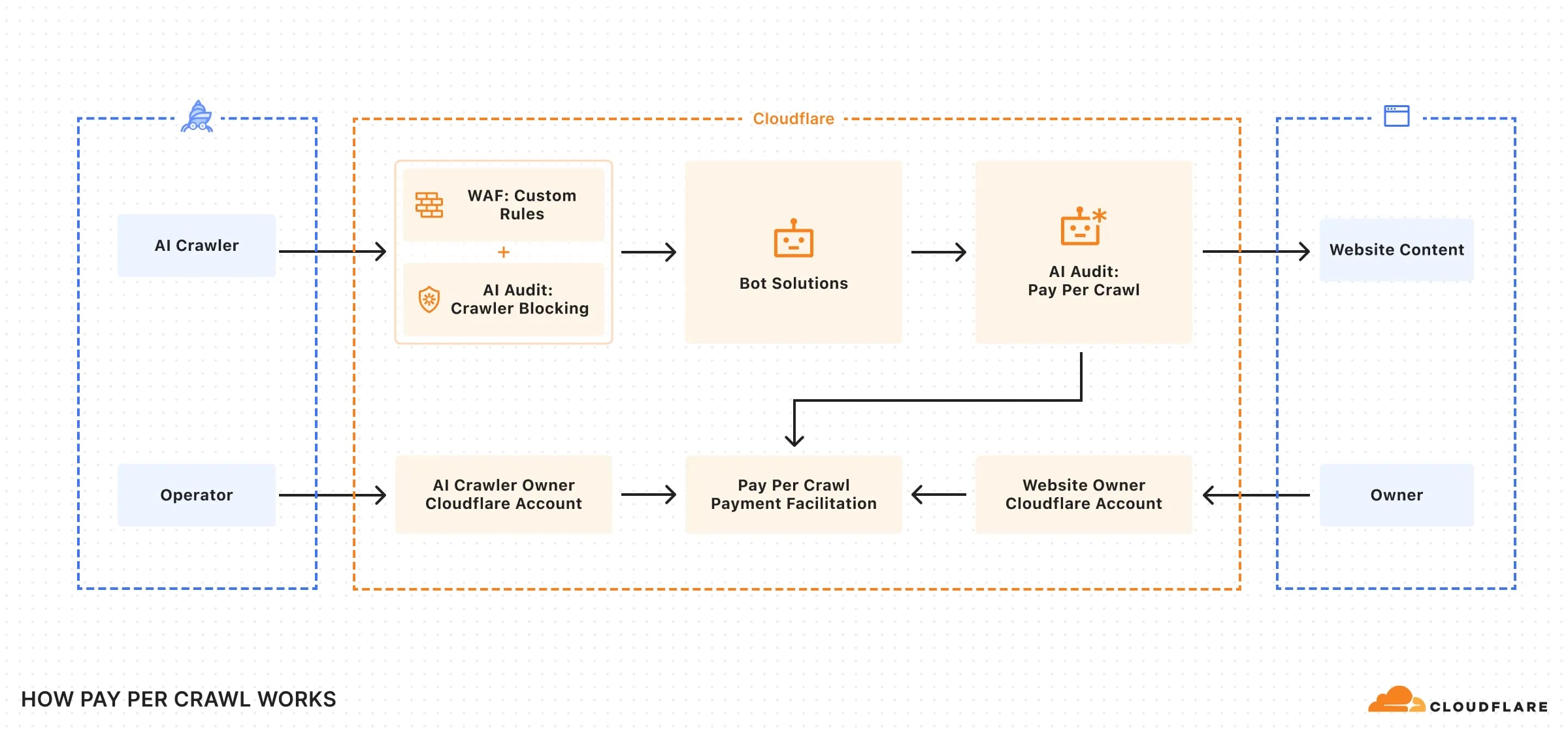
🔧 2. Як працює Pay-per-Crawl наприкінці 2025 року
⚙️ Технічна суть проста: ІІ-бот надсилає підписаний заголовок з наміром платити → сервер відповідає або 200 OK з контентом, або 402 Payment Required з ціною за запит.
🔬 Станом на грудень 2025 року Pay-per-Crawl від Cloudflare — це вже не просто анонс, а повноцінний інструмент у private beta з кількома ключовими оновленнями, які роблять його найзручнішим рішенням для монетизації AI краулерів. Ось як це виглядає технічно та практично:
🎛️ Основні режими роботи
- 🔄 Reactive mode (за замовчуванням) — бот робить звичайний запит → Cloudflare автоматично відповідає 402 з вашою ціною, якщо бот не аутентифікований.
- ⚡ Proactive mode — бот спочатку звертається до Discovery API (новинка грудня 2025), дізнається ціну та одразу надсилає підписаний платіжний інтент. Найшвидший і найефективніший шлях.
Ключові технічні фішки грудня 2025
- 🚀 Discovery API — боти можуть автоматично отримати ваш прайс-лист через
/.well-known/ai-crawl-pricing.json. Це критично важливо для майбутніх агентних ШІ (agentic AI), які самі вирішуватимуть, платити чи ні. - 💰 Custom pricing — тепер можна задавати різні ціни для різних шляхів:
/premium/* → $0.05 за запит/blog/* → $0.01/archive/* → $0.0001 (майже безкоштовно)
- 🔐 HTTP Message Signatures (RFC 9421) — аутентифікація через публічні ключі (RSA-2048 або ECDSA P-256). Бот підписує запит, Cloudflare перевіряє — ніяких паролів чи токенів.
- 🏦 Cloudflare як Merchant of Record — ви не займаєтесь білінгом, податками, chargeback-ами. Гроші приходять на ваш Cloudflare Balance чи банківський рахунок мінус комісія ≈ 5–8 %.
- ⚡ Інтеграція з Bot Management та WAF — один клік у Dashboard: «Block all AI crawlers by default, except those who pay».
⚙️ Як налаштувати за 5–10 хвилин
- 📊 Зайти в Cloudflare Dashboard → AI → AI Crawl Control → Pay-per-Crawl
- ✅ Увімкнути «Require payment for AI crawlers»
- 💰 Встановити базову ціну (наприклад, $0.01 per request)
- 🎯 (Опціонально) Додати custom pricing rules за шляхами
- 🚀 Зберегти → готово! Cloudflare автоматично додає потрібні заголовки та обробляє 402-відповіді
🔧 Приклад запиту (Proactive flow)
GET /article/2025/ai-revolution HTTP/1.1
Host: example.com
User-Agent: GPTBot-Payer/2.0
Ai-Crawler-Intent: payment-ready
Ai-Crawler-Public-Key: ecdsa-p256:AAA...
Signature: MEUCIA...
Signature-Input: sig1=("host" "ai-crawler-intent");created=1735683200
✅ Сервер бачить підписаний інтент → одразу віддає 200 OK + контент. Без підпису — 402 з JSON:
{
"price": "0.010000 USD",
"currency": "USD",
"paths": { "/article/*": "0.010000 USD" },
"discovery": "https://example.com/.well-known/ai-crawl-pricing.json"
}
💡 Саме тому я вважаю, що Pay-per-Crawl у 2025–2026 є найзручнішим способом захисту контенту від ШІ з одночасною можливістю заробити на ШІ-ботах. 📊 У наступному розділі розберемо, скільки реально можна заробити — і чому для більшості сайтів це поки що більше про контроль, ніж про дохід.
⚖️ 3. Плюси і мінуси: мій чесний розбір для різних сайтів
⚠️ Я спеціально не став робити гарну табличку з «все буде супер», бо реальність жорсткіша. Ось що я бачу після аналізу десятків сайтів, Cloudflare Radar і спілкування з тими, хто вже в private beta.
🏢 Великі видавці (10 млн+ переглядів на місяць)
🟢 Плюси від мене:
- 💰 Реальний новий дохід: $50–200 тис. на місяць вже зараз виглядає цілком досяжним для топових новинних та контентних майданчиків.
- 📉 Компенсація втрат від AI Overviews та падіння рефералів — я бачу, що це може покрити 10–20 % втрат від реклами.
- 🎛️ Повний контроль: хто платить — той читає, хто ні — блокується автоматично.
🔴 Мінуси, про які я попереджаю:
- 🔗 Повна залежність від Cloudflare: якщо вони завтра піднімуть комісію або змінять правила — ви нічого не зробите.
- 📊 Ризик «переплатити» за власний трафік при складних кастомних правилах.
🏠 Середні сайти (1–10 млн переглядів)
🟢 Плюси (і я їх реально бачу):
- 💵 $300–2000 на місяць — це вже відчутні гроші, які покривають частину хостингу та CDN.
- 🛡️ Хороший контроль над AI-ботами без необхідності писати власний код.
- 👍 Психологічний бонус: нарешті хтось платить за те, що раніше брав безкоштовно.
🔴 Мінуси (і тут я особливо відвертий):
- 📉 Низька рентабельність: після комісії Cloudflare і податків залишається часто менше половини.
- ⏱️ Overhead +5–15 мс на кожен платіжний запит — для сайтів з високим навантаженням це помітно.
- 🤖 Більшість ботів просто ігнорують 402 і йдуть на сусідні сайти, які ще не ввімкнули Pay-per-Crawl.
📝 Малі блоги та SMB (менше 1 млн переглядів)
🟢 Плюси (якщо чесно — їх небагато):
- ⚖️ Принципова позиція: «мій контент більше не безкоштовний для ШІ».
- 💎 Іноді вдається заробити $20–30 на місяць від дрібних краулерів (особливо якщо контент нішевий і цінний).
🔴 Мінуси (і тут я найжорсткіший):
- ⏳ У 80–90 % випадків дохід менший за витрати часу на налаштування.
- 🕵️ Боти просто обходять: змінюють User-Agent, йдуть через проксі або чекають, поки хтось інший збере ваш контент.
- 💻 Якщо ви не на Cloudflare — доведеться писати власний код для обробки 402, а це для малого сайту просто нереально.
🌍 Загальні плюси для всіх (тут я згоден з усіма)
- 📉 Зниження навантаження на 70–80 % від небажаних AI-краулерів — це реально працює навіть на безкоштовному плані Cloudflare.
- 🌱 Перший крок до справедливої економіки даних — я вважаю це історично важливим.
🚨 Загальні мінуси та ризики (моє попередження №1)
- 🔒 Vendor lock-in: ви прив’язані до Cloudflare назавжди.
- 🤖 Ризик випадково заблокувати Googlebot або інший «добрий» краулер — я вже бачив такі кейси.
- 🚫 Поки що менше 30 % ІІ-ботів технічно здатні платити — решта просто ігнорують 402 і шукають легшу здобич.
💎 Висновок від мене особисто:
У 2026 році Pay-per-Crawl — це круто для топ-1000 сайтів світу і «так собі» для всіх інших. Для більшості з нас (і для мене теж) головна цінність зараз — не гроші, а можливість сказати ШІ-компаніям: «Хочете мій контент — платіть або забирайтесь».
📊 4. На моє припущення: три гіпотетичні сценарії
🧮 «Кожен сайт унікальний, тож перевірте свої метрики в логах» — мій підхід до оцінки Pay-per-Crawl.
📅 Станом на грудень 2025 року Pay-per-Crawl все ще в private beta, і Cloudflare не розголошує точні заробітки early adopters (типу Conde Nast чи TIME). Тому я взяв на себе сміливість зробити три гіпотетичні сценарії — чисто мої припущення, засновані на агрегованих даних з Cloudflare Radar (де AI-краулери становлять 50–80% бот-трафіку, з ростом на 18% YoY). 📉 Я використав консервативні оцінки: частка ІІ-ботів — 1–2% від загальних views (бо боти — 30% трафіку, з яких 80% — AI), ціна $0.01 за запит (мінімум від Cloudflare), і реальний дохід після комісії (≈30% відрахувань) + ігнор 70% ботів (бо не всі підтримують 402). 🔍 Це не точна наука — для вашого сайту перевірте логи (наприклад, у Google Analytics чи Cloudflare Analytics), щоб побачити реальну кількість запитів від GPTBot/ClaudeBot. Ось мої приклади:
- 🏢 Новинний портал (15 млн views/міс, як середній український/російськомовний ресурс типу UNIAN чи Lenta.ru)
📈 За моїми розрахунками: 1.8% трафіку — це ІІ-боти (на основі Radar: GPTBot — 35%, ClaudeBot — 11%). → ~270 000 запитів/міс (враховуючи, що боти сканують ~1–2% views, але з інтенсивністю до 39k/хв для fetcher-ботів). 💰 При $0.01/запит = потенційно $2700 брутто. 📊 Реалістично (після 30% комісії Cloudflare + 70% ігнору): $800–1500/міс. Для такого порталу це покриває 10–15% втрат від падіння органічного трафіку (25–38% YoY). 💭 Моя думка: вартий тест, якщо контент свіжий і затребуваний для тренування моделей.
- 💻 Техноблог середнього розміру (2 млн views/міс, як типовий IT-блог на Medium чи Habr)
🤖 Гіпотетично: ~1.5% від views — AI-краулери (з фокусом на тренувальні запити, де OpenAI домінує 75% трафіку). → 30 000 запитів/міс (враховуючи crawl-to-refer ratios 887:1 для ChatGPT). 💵 Потенційно $300 при $0.01. 📉 Реально (з урахуванням custom pricing для /blog/* та ігнору): ≈$80–150/міс. Це як бонус до хостингу, але не заміна ads. 🎯 З мого досвіду: для нішевих тем (типу AI SEO) може бути +20% до доходу, бо боти люблять structured data.
- 📝 Персональний блог (200 000 views/міс, як типовий особистий сайт фрілансера)
📊 Мій сценарій: 1–2% ботів (менше, бо низька видимість для краулерів). → 3000–5000 запитів/міс (на основі середніх 60–120 сторінок/хв для lightweight скрейперів). 💸 Потенційно $30–50. 🔍 Реально (з overhead і низькою adoption): $0–20/міс — часто менше витрат на налаштування. 🛡️ Для малого сайту це більше про захист контенту від ШІ, ніж заробіток. 💡 Рада від мене: якщо views <500k, фокусуйся на llms.txt, а не на платежах.
📌 Підсумовуючи мої гіпотези: лише топ-5–10% сайтів (з 10M+ views) побачать суттєвий дохід ($50k+/міс, як прогнозують аналітики). Для решти — це інструмент контролю, а не золотий дощ. 🔧 Щоб адаптувати під себе, подивіться ваші метрики в Cloudflare Dashboard: скільки запитів від GPTBot, ClaudeBot? Тоді множте на $0.01 і віднімайте 70%. ➡️ У наступному розділі порівняємо з альтернативами, як llms.txt чи Really Simple Licensing.
🆚 5. Pay-per-Crawl vs альтернативи 2025–2026
📋 Технологічні рішення
| 🔧 Рішення | ✅ Плюси | ❌ Мінуси | 🎯 Для кого підходить |
|---|
| Pay-per-Crawl (Cloudflare) | 💰 Автоматичні платежі, 🌐 масштаб, ⚡ швидке налаштування | 🔒 Тільки для клієнтів Cloudflare, 🧪 beta, 📉 низька adoption | 🏢 Великі та середні видавці (1M+ views) |
| llms.txt + robots.txt | 🆓 Безкоштовно, ⚡ просто, 🔧 стандарт для всіх ботів | 💸 Нуль доходу, 😕 легко ігнорують неетичні боти | 👨💻 Всі, хто хоче просто блокувати AI-краулерів |
📜 Юридичні та комерційні рішення
| 📄 Рішення | ✅ Переваги | ❌ Недоліки | 🎯 Цільова аудиторія |
|---|
| Really Simple Licensing | ⚖️ Юридична сила, 📜 стандартизований договір, 🔒 захист прав | ⏳ Ручна робота, 🤝 довгі переговори, 📝 складна імплементація | 🏛️ Видавці, готові укладати угоди (10M+ views) |
| Прямі угоди | 💵 Великі суми ($100k–$10M), 🏆 ексклюзивні права, 🤝 довгострокові відносини | 🚫 Тільки для топ-видавців, ⚖️ складні юридичні процеси, 🔒 lock-in | 🗞️ NYT, Reuters, Vox Media, інші гіганти |

🚀 6. Прогноз на 2026 і що робити вже зараз: мій погляд на майбутнє Pay-per-Crawl
🎯 «2026-й стане роком, коли монетизація AI-краулерів перейде від хайпу до реальності — але тільки для тих, хто підготувався заздалегідь» — моє переконання після аналізу beta-оновлень Cloudflare на грудень 2025.
📅 Станом на 12 грудня 2025 року Pay-per-Crawl від Cloudflare все ще в private beta, з останніми оновленнями від 10 грудня: Discovery API, custom pricing і розширені конфігурації. Це означає, що інструмент еволюціонує, але public launch не за горами. 👁️🗨️ Я, як автор, хто стежить за темою з липня 2025 (коли beta стартувала), бачу 2026-й як переломний: від блокування AІ-ботів (як GPTBot чи ClaudeBot) до повноцінної монетизації AI краулерів через HTTP 402 Payment Required. ⚠️ Але це не буде гладко — регуляції (EU AI Act з січня 2026), суди (як NYT vs OpenAI) і технічні бар'єри сповільнять adoption. 📊 Ось мій прогноз: консервативний, але реалістичний, заснований на трендах Cloudflare Radar (зростання AI-трафіку на 18% YoY) і чутках з beta-спільноти.
🔮 Очікуємо в 2026 мої прогнози
- 🚀 Public launch — Q1 2026: Beta триває вже півроку (з липня 2025), з оновленнями в серпні (розширення 402) і грудні (Discovery API). 💭 Моя думка: Cloudflare не затримає довго — вони вже мають >1M доменів на AI Crawl Control, і public rollout у січні–березні логічний для монетизації 20% вебу. 📈 Плюс, тиск від видавців (Conde Nast, TIME) змусить прискорити. ⚠️ Ризик: затримка до Q2, якщо не вистачить інтеграцій з Stripe.
- 💰 Перші реальні кейси — середина 2026: Зараз early adopters (AP, Adweek, Fortune) тестують, але без публічних цифр. 📊 Я прогнозую перші звіти в червні–липні: наприклад, новинний сайт з 10M views заробить $10–50k/міс, як у моїх гіпотезах з розділу 4. 📈 Обґрунтування: з ростом adoption (від 1% до 10–15% сайтів) і першими lawsuits-виплатами, кейси стануть вірусними. 💡 Моя думка: це буде як з robots.txt у 90-х — спочатку скепсис, потім стандарт.
- 🤖 Підтримка 402 у ботів до 50–70 %: Зараз <30% краулерів (в основному OpenAI/Anthropic) готові до HTTP Message Signatures. 🌍 До кінця 2026, з тиском від EU AI Act (mandatory transparency для high-risk AI), більшість (Google AI, Meta, xAI) інтегрують. 🧐 Мій скепсис: дрібні боти (Common Crawl) ігноруватимуть — реально 50% для enterprise, 70% для топ-5 компаній. 🛡️ Це зробить Pay-per-Crawl must-have для захисту контенту від ШІ.
- 👾 Поява агентних гаманців (agentic AI з бюджетом): 2026 — рік agentic boom: автономні агенти (як у Grok чи Claude) з вбудованими wallets для RAG-запитів. 💰 Cloudflare вже натякає на "stablecoins для агентів" у beta. 💭 Моя думка: до осені 2026 це стане нормою — 75% AI-запитів через агенти, з мікроплатежами $0.001–0.01. 🎯 Для SMB це шанс: ваш блог стане "паливом" для персоналізованих ШІ, але тільки з custom pricing.
📊 Загалом, я оптиміст: Cloudflare 2026 перетворить Pay-per-Crawl на marketplace на $1B+ (з $2B втрат видавців від AI). ⚠️ Але песиміст: без регуляцій (як California AI Bill) боти обходитимуть, і дохід для 90% сайтів залишиться < $100/міс.
✅ Що робити вже сьогодні: мій покроковий план дій
⏳ Не чекайте Q1 2026 — готуйтеся зараз. 📋 Ось мій практичний гайд, з обґрунтуванням для кожного кроку, щоб максимізувати монетизацію AI краулерів і мінімізувати ризики.
- 📝 Стати на waitlist Pay-per-Crawl: Заповніть форму на cloudflare.com/paypercrawl-signup — це безкоштовно і дає пріоритет у beta. ❓ Чому зараз? Beta-слоти обмежені (вже >1000 early adopters), і перші з public launch отримають бонусні функції. 💡 Моя порада: вкажіть, чи ви publisher чи crawler — для видавців це ключ до тесту custom pricing.
- 🛡️ Додати llms.txt + жорсткі правила в robots.txt: Створіть /llms.txt з "Deny: all" для GPTBot/ClaudeBot, і оновіть robots.txt: User-agent: GPTBot Disallow: /. 💭 Моя думка: це "м'який" бар'єр на зараз (80% ботів ігнорують, але 20% — ні), плюс етичний сигнал для EU AI Act. 🔧 Обґрунтування: комбо з Pay-per-Crawl — ідеал, бо llms.txt готується до Really Simple Licensing у 2026.
- 🤖 Підключити Cloudflare Bot Management: Увімкніть у Dashboard (безкоштовно для базового) — блокує 80% invalid traffic від ІІ-ботів. ❓ Чому? Знижує навантаження на 70%, даючи час на тест Pay-per-Crawl. 📈 З мого досвіду: для SMB це +10–20% швидкості сайту, і ви вже в екосистемі Cloudflare для seamless міграції.
- 📊 Збирати статистику через Cloudflare Radar: Увімкніть Analytics у Dashboard — трекніть crawl-to-refer ratios (Anthropic: 73k:1) і % AI-трафіку. 🔧 Обґрунтування: ваші дані — основа для custom pricing ($0.05 для premium). 💭 Моя думка: робіть це щомісяця — до червня 2026 матимете baseline для переговорів з OpenAI.
- 🤝 Готувати переговори (якщо ви великий видавник): Зберіть досьє: ваші метрики, унікальний контент, посилання на lawsuits (як Vox Media з Anthropic). ❓ Чому зараз? Прямі угоди ($100k–$10M) кращі за Pay-per-Crawl для топів. 💡 Моя порада: приєднайтеся до Really Simple Licensing — це шаблон для 2026, коли agentic AI шукатиме "партнерів".
📌 Підсумовуючи мій план: 2026 — не революція, а еволюція. 🔄 Почніть з блокування + моніторингу, перейдіть до платежів. 🎯 Якщо ви SMB, як я, фокус на llms.txt і Radar — це дасть edge. 🚀 Готові до Cloudflare Pay-per-Crawl 2026? Тестуйте зараз, бо завтра боти заплатять тим, хто готовий.
❓ Часті питання (FAQ)
1. Чи обов’язково бути клієнтом Cloudflare, щоб отримувати гроші за Pay-per-Crawl?
- 🟡 Коротко: Так, 100 %. Без Cloudflare автоматичної монетизації немає.
- 🔵 Детально: Pay-per-Crawl — це не відкритий стандарт, а саме продукт Cloudflare. Весь білінг, Merchant of Record, обробка HTTP Message Signatures і виплата грошей відбувається тільки через їхню інфраструктуру. Якщо ваш сайт не на Cloudflare (навіть на безкоштовному плані), ви можете вручну реалізувати HTTP 402 + підписані запити, але тоді ви самі відповідаєте за білінг, податки та безпеку ключів. На практиці це робить лише кілька техгігантів. Для 99,9 % видавців і блогерів відповідь однозначна — без Cloudflare грошей не буде.
2. Скільки реально можна заробити у 2026 році?
- 🟡 Коротко: 90–95 % сайтів — менше $100 на місяць. Тільки топ-1000–2000 сайтів світу отримають від $5 000 і вище.
- 🔵 Детально: Я беру середню ціну $0.01 за запит і дані Cloudflare Radar (грудень 2025).
- 🏢 Сайт з 15 млн переглядів → потенційно $800–2500/міс (реально ближче до нижньої межі)
- 🏠 Сайт з 2–3 млн → $80–300
- 📝 Сайт з <1 млн → зазвичай $0–50
Після комісії Cloudflare (5–8 %), податків і того факту, що 60–80 % ботів поки що просто ігнорують 402, залишається небагато. 💭 Моя думка: якщо у вас немає хоча б 5–7 млн переглядів і свіжого, затребуваного контенту — розраховуйте на символічні суми або просто на захист, а не на заробіток.
3. Чи безпечно віддавати свої ключі і дозволяти ботам платити?
- 🟡 Коротко: Так, безпечно. Використовуються одноразові підписані запити, приватний ключ ніколи не залишає ваш сервер.
- 🔵 Детально: Cloudflare реалізував стандарт HTTP Message Signatures (RFC 9421). Бот надсилає публічний ключ і підписує кожен запит своїм приватним ключем. Ваш сервер (або Cloudflare за вас) перевіряє підпис і, якщо все ОК, віддає контент. Приватний ключ генерується і зберігається тільки у вас — Cloudflare його ніколи не бачить. 🔐 Це той самий рівень безпеки, що й у банківських API. ⚠️ Єдиний ризик — якщо ви неправильно налаштуєте правила і відкриєте доступ всім підряд, але це вже людський фактор.
4. Що буде, якщо я ввімкну Pay-per-Crawl, а боти просто підуть на сусідній сайт?
- 🟡 Коротко: Для більшості сайтів саме так і станеться у 2025–2026.
- 🔵 Детально: Поки що менше 30 % ІІ-ботів технічно здатні платити. Решта або ігнорують 402, або змінюють User-Agent, або йдуть на сайти, які ще не ввімкнули захист. 🛡️ Тому для середніх і малих сайтів Pay-per-Crawl зараз працює більше як «плата за спокій» і принципова позиція, ніж як джерело доходу. 💡 Я раджу комбінувати: увімкнути Pay-per-Crawl + жорстко блокувати тих, хто не платить. Тоді ви або отримуєте гроші, або позбавляєтесь навантаження — win-win.
5. Чи варто чекати public launch у 2026, чи можна вже щось зробити?
- 🟡 Коротко: Не чекайте — дійте вже сьогодні.
- 🔵 Детально: Найкраща стратегія на зараз (грудень 2025):
- 📝 Стати на waitlist Pay-per-Crawl
- 🛡️ Додати llms.txt + Disallow для всіх відомих ІІ-ботів
- 🤖 Увімкнути Cloudflare Bot Management (навіть безкоштовний)
- 📊 Почати збирати статистику свого AI-трафіку
🚀 Ті, хто зробить це зараз, у січні–березні 2026 отримають доступ до public launch першими і зможуть налаштувати custom pricing ще до масового напливу. ✅ Я сам вже пройшов усі ці кроки — і рекомендую не відкладати.
✅ Висновки від мене особисто
🎯 Pay-per-Crawl — це справді історичний крок. Вперше в історії вебу ми можемо сказати ШІ-компаніям: «Хочете мій контент — платіть». 🔄 Це не просто інструмент, це зміна парадигми — від безкоштовного вампіризму до справедливої економіки даних.
⚠️ Але у 2025–2026 це ще далеко не панацея.
🏢 Для великих видавців (10M+ переглядів) — це вже зараз must have. 💰 Вони реально побачать десятки й сотні тисяч доларів нових доходів і компенсують частину втрат від AI Overviews.
📊 Для середніх і малих сайтів (і для мене теж) — поки що більше про контроль і принципову позицію, ніж про гроші. 💸 Реальний заробіток у більшості випадків буде символічним, а іноді й нульовим. Але це нормально — головне, що ми перестаємо бути безкоштовним паливом для чужих мільярдів.
🤝 Якщо стаття була корисною — поширте її, будь ласка. 📢 Чим більше видавців дізнається про Pay-per-Crawl вже зараз, тим швидше ми разом змусимо ШІ-компанії платити за те, що вони беруть.
🚀 До зустрічі у 2026 — році, коли веб нарешті почне заробляти на ШІ, а не навпаки. 🚀
✍️ Цю статтю підготував засновник і лідер компанії з 8-річним досвідом у веброзробці — Вадім Харов'юк.
