У 2025 році ваші сервери стогнуть під натиском невидимих гостей — AI-ботів, які ковтають контент швидше, ніж ви встигаєте сказати robots.txt. Ці цифрові мандрівники не просто сканують сторінки, вони вчаться на них, генеруючи відповіді без кліків на ваш сайт. Проблема? Видавці втрачають трафік, а AI-компанії — дані для моделей. Спойлер: нове пояснення краулингу — це семантичний аналіз для тренування LLM, де етика та контроль стають ключем до виживання веб-екосистеми.
⚡ Коротко
- ✅ Ключова думка 1: AI-краулери — це не просто боти, а учні, що збирають дані для ChatGPT та Claude, генеруючи 50%+ веб-трафіку у 2025.
- ✅ Ключова думка 2: Відмінність від традиційного: фокус на тренуванні моделей, а не на пошуку, з мінімальними рефералами назад.
- ✅ Ключова думка 3: Виклики: перевантаження серверів та етика; рішення — AI Crawl Control від Cloudflare та pay per crawl.
- 🎯 Ви отримаєте: глибоке розуміння механізмів, статистику 2025 та практичні рекомендації для сайтів.
- 👇 Детальніше читайте нижче — з прикладами та висновками
Зміст статті:
⸻
🎯 Розділ 1: Вступ до краулингу в епосі AI
🕵️♂️ "AI-краулери — це не злодії, а учні, які копіюють домашнє завдання з інтернету, не питаючи дозволу." Cloudflare Radar, 2025.
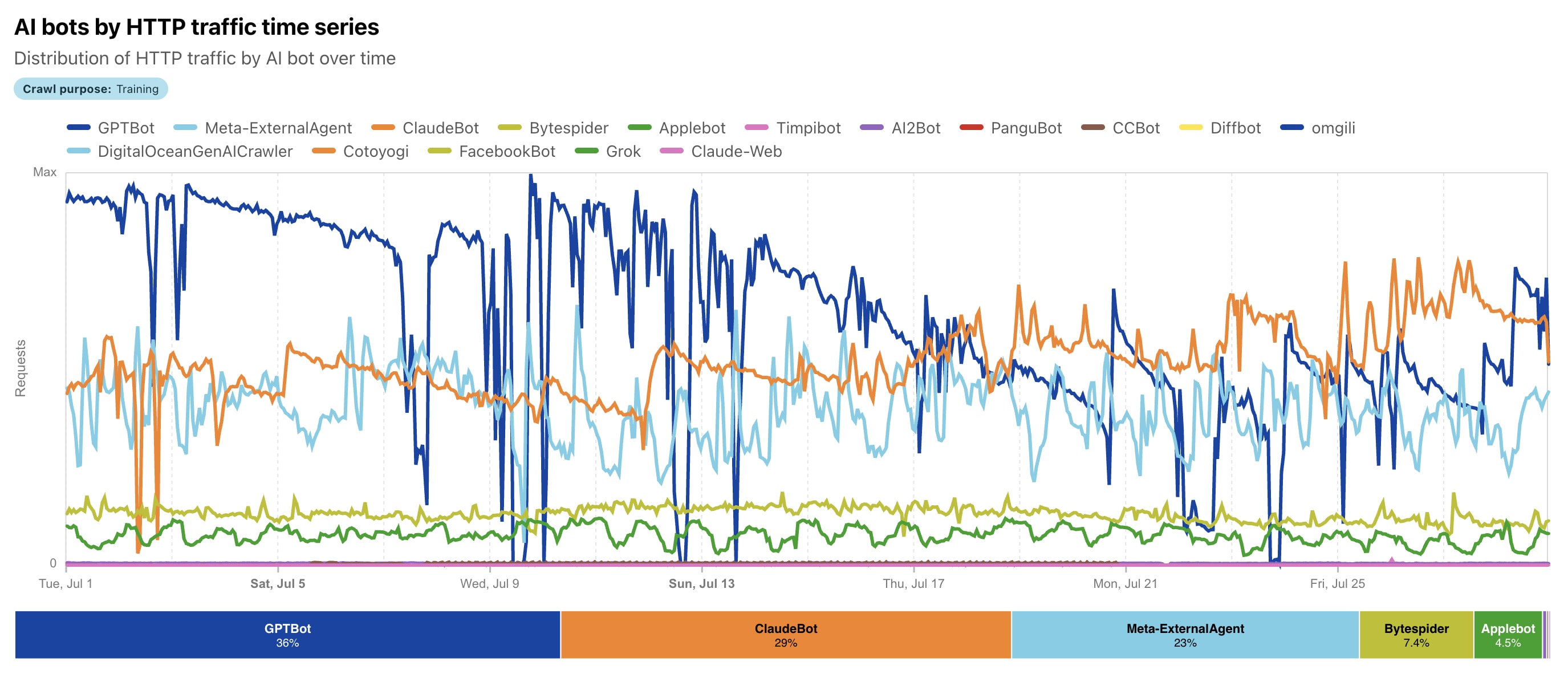
🕸️ Краулинг — це автоматизоване сканування веб-сайтів ботами для збору даних, ніби невидимі павуки плетуть мережу знань по всьому інтернету. 🌐 У традиційному світі це слугувало пошуковикам, як Googlebot, для індексації сторінок і направлення трафіку назад на сайти, де видавці заробляли на рекламі та кліках. 💰 Але в епосі AI все кардинально змінилося: боти на кшталт GPTBot (від OpenAI) та ClaudeBot (від Anthropic) не просто індексують — вони глибоко аналізують семантику, контекст, емоційний тон і тренують великі мовні моделі (LLM), перетворюючи ваш унікальний контент на паливо для ChatGPT чи Claude. 🔥📈
За свіжими даними з Cloudflare Radar AI Insights, у 2025 році AI-краулинг зріс на 24% рік до року у червні, досягаючи вражаючих 80% від загального AI-бот трафіку, перш ніж сповільнитися до 4% у липні через нові регуляції. Це "нове пояснення" краулингу: процес став по-справжньому розумним і семантичним, де машини не тільки збирають дані, а й вчаться на них, генеруючи відповіді без жодного кліку на ваш сайт — отже, без винагороди у вигляді трафіку чи доходу. Уявіть: ваші статті, блоги чи новини "живуть" у відповідях AI, але ви не бачите жодного відвідувача! 😲
Чому це актуально саме зараз? Cloudflare з 1 липня ввів блокування AI-краулерів за замовчуванням для мільйонів сайтів, дозволяючи власникам контролювати доступ і навіть монетизувати контент через "pay per crawl". Розглянемо еволюцію крок за кроком, щоб зрозуміти, як з простих пошукових ботів ми дійшли до етичних дилем штучного інтелекту. 🚀
📚 Розділ 2: Традиційний краулинг — основи
"Краулинг — це як бібліотекар, що сортує книги для швидкого пошуку." — Класичне визначення з пошукових систем Google Search Central.
📖 **Традиційний краулинг** (Traditional Crawling) — це фундаментальний процес, який почався з ранніх пошукових двигунів у 1990-х, і досі є основою для індексації веб-контенту.
**Боти** 🤖, як Googlebot чи Bingbot, стартують з "**seed-URL**" 🌱 — початкового списку відомих адрес (наприклад, популярні сайти чи sitemaps), — і слідують посиланнями 🔗, утворюючи дерево відкриттів. Вони витягують ключові слова 🔑, мета-теги, HTML-структуру та навіть виконують **JavaScript** 🖥️ для рендерингу динамічного контенту, як описано в документації Google. Мета проста: створити величезний **індекс** 🗄️ для релевантних пошукових результатів, де кожен клік веде назад на сайт, генеруючи дохід від реклами чи трафіку 💰. 🔄
Уявіть: Googlebot 🟢, з user-agent "Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)", сканує сторінки, оцінюючи їхню свіжість і релевантність. Bingbot 🔵, аналогічно, з "Mozilla/5.0 (compatible; bingbot/2.0; +http://www.bing.com/bingbot.htm)", індексує для Bing, який має $\sim$$\text{4\%}$ глобальної частки пошуку.
За даними 2025 року, Googlebot домінує з 89.6 % ринку пошуку 👑, скануючи сотні мільярдів сторінок щодня — приблизно третину відомого вебу. Приклад: на середньому сайті Googlebot робить 2741 запитів за 62 дні 📈, тоді як Bingbot — 4188 📉, демонструючи інтенсивність роботи. Це не хаос, а контрольований процес: боти поважають robots.txt 🛑, обмежують частоту запитів (Googlebot — не більше кількох секунд між запитами) ⏱️ і фокусуються на **мобільній версії контенту** 📱 з 2020 року. 📊
У 2025 році традиційний краулинг залишається стабільним, але складає лише 20-30 % загального бот-активу, оскільки **AI-боти** 🧠 захоплюють 80 % трафіку AI-краулерів. Загалом боти генерують 49.6% інтернет-трафіку 🕸️, з традиційними краулерами як "**добрими**" ботами, що сприяють видимості. Це **симбіоз**: сайти отримують видимість у пошуку 👀 (Googlebot зріс на 96 % з 2024), пошуковики — дані для алгоритмів. Однак прихід AI 🤖 ламає цю модель, перетворюючи краулинг з "посилання назад" на "**навчання без винагороди**" 🎁❌. Переходимо до еволюції в наступному розділі. 🔍
🔄 Розділ 3: Еволюція до AI-краулерів
"Від ключових слів до семантики: AI перетворює краулинг на навчання." — Натхненне трендами 2025 від Vercel та Cloudflare.
🔄 Давайте повернемося назад, щоб краще зрозуміти різницю: **як було раніше** з традиційним краулингом? Уявіть інтернет 2010–2020-х: боти на кшталт Googlebot чи Bingbot сканували веб переважно для індексації — збирали ключові слова, посилання, мета-теги та просту HTML-структуру. Вони часто ігнорували динамічний JavaScript-контент (бо не рендерили його повноцінно до 2019 року для Google), фокусувалися на обсязі та швидкості, а головне — повертали трафік назад через пошукові результати. Це був симбіоз: сайти отримували відвідувачів, пошуковики — дані. Клік на посилання в Google приносив дохід від реклами, а crawl-to-refer ratio (співвідношення краулингу до рефералів) був вигідним — наприклад, Google краулить ~14 сторінок на 1 реферал. 📊
Але все прискорилося з 2023 року з буму генеративного AI: еволюція перейшла від простих пошукових ботів до справжніх **AI-агентів**, що використовують NLP (natural language processing) для глибокого розуміння контексту, семантики, настрою тексту та навіть візуального контенту. За даними Cloudflare, з травня 2024 по травень 2025 AI-краулинг радикально змінився: GPTBot (OpenAI) вирвався в лідери з **30% частки** (зростання з 5%), Meta-ExternalAgent (Meta) дебютував з 19%, тоді як колишній лідер Bytespider (ByteDance) впав з 42% до 7%. ClaudeBot (Anthropic) фокусується на етичному зборі даних для моделі Claude, а загальний AI-краулинг зріс на десятки відсотків. 🚀
Ключова **відмінність**, щоб ви чітко побачили різницю: традиційні боти (як Googlebot) часто ігнорували або погано обробляли JS-контент, збирали дані для пошуку та повертали трафік. AI-краулери рендерять динамічний контент (хоча не завжди виконують JS ідеально, за даними Vercel), пріоритизують якість та релевантність для тренування LLM, але... майже не повертають кліки! Результат — збір для тренування великих мовних моделей (LLM), RAG (Retrieval Augmented Generation) та реал-тайм відповідей у ChatGPT чи Claude. Еволюція триває: у 2025 Meta лідирує в деяких сегментах (до 52% за іншими звітами Cloudflare), а загальний трафік AI-ботів сягає 80% від бот-активності. Це не просто сканування — це "навчання" на вашому контенті без старої винагороди. 📈😲
📖 Читайте також на нашому блозі
Якщо тема AI-краулингу вас зацікавила, ось кілька пов’язаних статей, які допоможуть глибше розібратися в сучасному SEO та взаємодії з штучним інтелектом:
Ці матеріали ідеально доповнять розуміння того, як змінюється веб у 2025 році. 📈
⚙️ Розділ 4: Механізми роботи AI-краулерів
🤖 AI-краулинг — це не просто механічне сканування, як у традиційних ботів, а складний, "розумний" процес, орієнтований на збір високоякісних даних для тренування великих мовних моделей (LLM) та реал-тайм відповідей. На відміну від Googlebot, який індексує для пошуку, AI-краулери, як GPTBot чи ClaudeBot, фокусуються на семантичному розумінні контенту: вони витягають текст, аналізують контекст, настрої та релевантність для покращення моделей на кшталт ChatGPT чи Claude. За даними Cloudflare 2025, тренувальний краулинг становить майже 80% всього AI-бот трафіку, з лідерами на кшталт GPTBot (до 30% частки) та Meta-ExternalAgent (до 52% у деяких сегментах). Розберемо процес крок за кроком — це і є "нове пояснення" краулингу в епосі AI. 🔍
Крок 1: Відкриття (Discovery) 🚀
Все починається з "seed-URL" — початкового списку відомих адрес (популярні сайти, sitemaps, посилання з попередніх краулів). Але в AI-краулерах додаються розумні фільтри: NLP-моделі оцінюють релевантність та якість контенту заздалегідь, пріоритизуючи текстовий, освітній чи структурований матеріал. Наприклад, GPTBot (User-agent: GPTBot/1.0) та ClaudeBot (User-agent: ClaudeBot/1.0) шукають публічно доступний контент без paywall чи логінів. Вони поважають robots.txt (наприклад, Disallow: / блокує доступ), але можуть ігнорувати CAPTCHA чи інші бар'єри, якщо не вказано протилежне. У 2025 році відкриття стало ефективнішим: боти уникають низькоякісних сторінок, фокусуючись на даних для LLM.
Крок 2: Збір даних (Fetching) 📥
Бот надсилає HTTP-запити, ідентифікуючись user-agent (наприклад, "Mozilla/5.0 (compatible; GPTBot/1.0; +https://openai.com/gptbot)"). Він завантажує HTML, рендерить частково динамічний контент (хоча не завжди повноцінно виконує JavaScript, на відміну від Googlebot), витягає текст, зображення, PDF та навіть метадані. GPTBot збирає для тренування майбутніх моделей (GPT-5+), ClaudeBot — для оновлення Claude, фокусуючись на етичному та різноманітному контенті. За даними Vercel та Cloudflare, AI-краулери генерують мільярди запитів: GPTBot — сотні мільйонів на місяць, з піками до десятків тисяч запитів на хвилину на популярних сайтах. Вони масштабовані паралельно, але намагаються бути "well-behaved" — обмежують швидкість, щоб не перевантажувати сервери.
Крок 3: Парсинг та аналіз (Parsing & Semantic Analysis) 🧠
Тут відбувається магія: витягнутий контент парситься з використанням NLP для семантичного розуміння — розбір настрою, наміру, сутностей та контексту. Боти фільтрують boilerplate (рекламу, навігацію), витягають чистий текст і оцінюють корисність для тренування. Наприклад, ClaudeBot пріоритизує освітній контент, GPTBot — різноманітні джерела для покращення точності відповідей. Дані інтегруються в RAG (Retrieval Augmented Generation) для реал-тайм запитів або в тренувальні датасети. Це ключова відмінність: не просто індексація, а "навчання" моделі на вашому контенті!
Крок 4: Масштабування та зберігання (Scaling & Storage) ⚡
Процес повторюється масово: паралельні запити з різних IP (часто з хмар як AWS/Azure), з повагою до crawl-delay у robots.txt. У 2025 році трафік вибуховий — Meta-боти генерують до 52% AI-краулингу, GPTBot зріс на 305%. Дані зберігаються для офлайн-тренування або онлайн-RAG. Приклади: ClaudeBot збирає для етичного тренування Claude, фокусуючись на якісному контенті; GPTBot — для масштабного покращення ChatGPT. Це "нове пояснення": краулинг став процесом навчання машин, а не просто пошуку. 🤖🌟
📊 Розділ 5: Статистика та вплив на трафік 2025
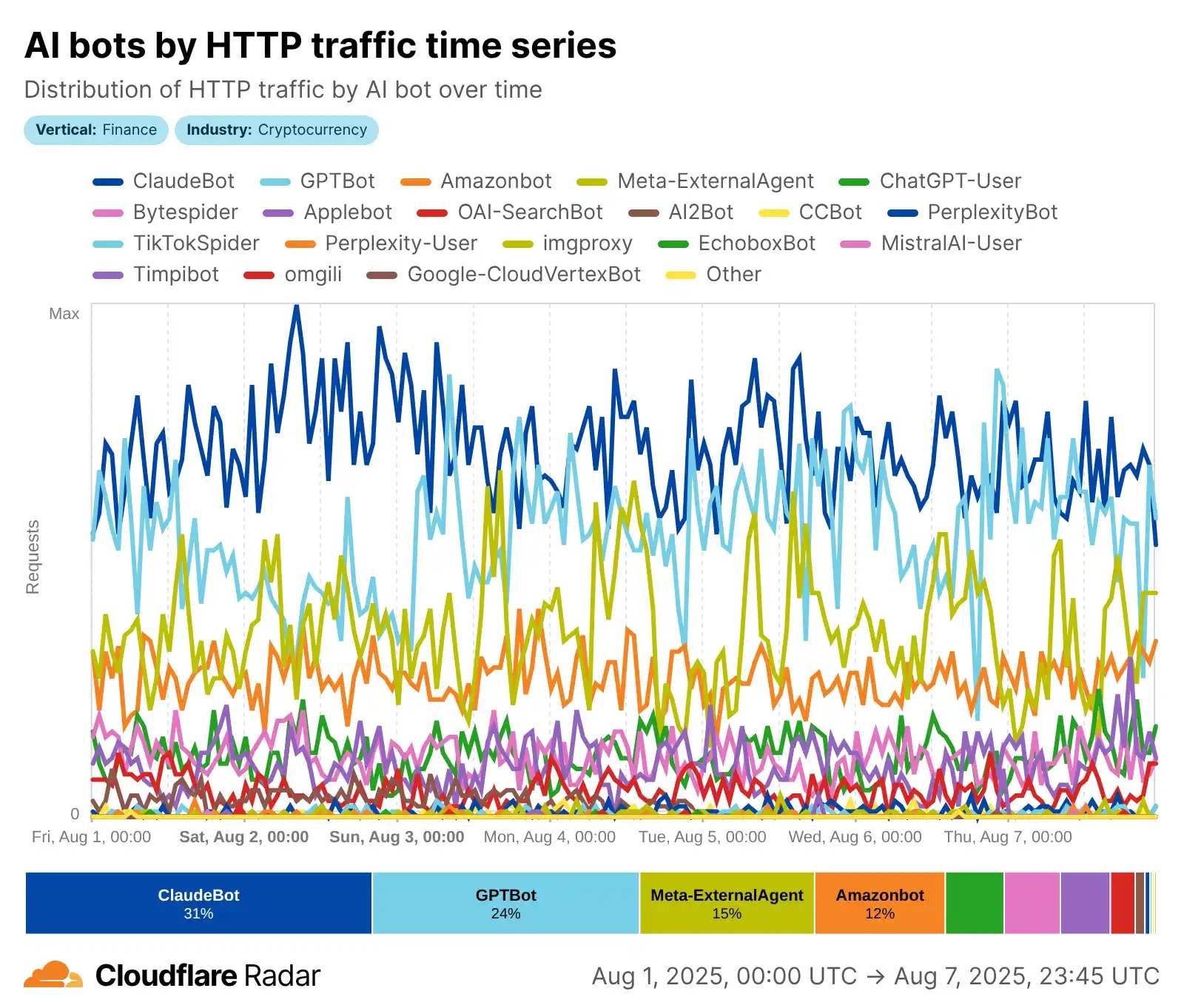
📊 У 2025 році бот-трафік перетворився на справжню "тихомурашину" інтернету, де автоматизовані агенти перевершують людський трафік за обсягом і впливом. За даними Cloudflare Radar, боти становлять близько 30% глобального веб-трафіку, з AI-краулерами як новою домінуючою силою, що генерують до 80% усього AI-бот активу. Fastly у своєму Q2 Threat Insights Report фіксує ще вищу цифру: AI-краулери — майже 80% AI-бот трафіку, з "поганими" ботами (включаючи несанкціонований скрапінг) на рівні 37% загального трафіку. Уявіть: з 6.5 трлн запитів на місяць через Fastly, мільярди йдуть на тренування LLM, перевантажуючи сервери та спотворюючи аналітику. Це не просто цифри — це криза для сайтів, де дані йдуть "в один бік". 📉
Розглянемо ключові показники: загальний бот-трафік сягає 49.6–51% інтернету (за Thunderbit 2025), з AI-краулерами як основним драйвером зростання. Лідери? Meta-боти генерують 52% AI-краулингу, Google — 23%, OpenAI — 20%, тоді як Anthropic (ClaudeBot) тримається на 3.76% з акцентом на етику. GPTBot зріс на 305% з травня 2024 по 2025, ClaudeBot — удвічі (до 10%), а ByteDance's Bytespider впав з 14.1% до 2.4% через регуляції. Cloudflare фіксує 50 млрд запитів на день від AI, з піками до 39 тис. запитів/хв від одного фетчера (реал-тайм відповіді) та 1 тис. від краулера — це DDoS-подібний ефект без зловмисності! 🚨
Вплив на трафік: від перевантаження до втрат 😩
Для сайтів це подвійний удар: перевантаження серверів (до 30 TB/місяць від одного бота) та низький crawl-to-click ratio — AI не повертає трафік назад. За Cloudflare, тренувальний краулинг — 79–80% AI-активу (зростання з 72% у 2024), з рефералами як 70,900:1 для Anthropic (71 тис. краулів на 1 клік!) чи 887:1 для OpenAI. У новинах реферали від Google впали на 9% у березні 2025, а загальний CTR падає на 61% для органічного та 68% для платного через AI Overviews (Seer Interactive, вересень 2025). Навіть без AIO: органічний CTR -41%, платний -20%. Приклад: для інформ-запитів з AIO CTR впав з 1.76% до 0.61%, impressions ростуть (+27%), але кліки падають (-36%). Видавці втрачають 10–25% трафіку YoY, з падінням до 64% на ключових ключових словах. Для AI — це "золота жила" даних, але для бізнесу — ерозія доходу від реклами. 🌐
Графік зростання: вибух і стабілізація 📈
З травня 2024 по травень 2025 AI-трафік зріс на 18% загалом, з +32% YoY у квітні 2025 (пік), +24% у червні та сповільненням до +4% у липні через блокування (Cloudflare з 1 липня блокує за замовчуванням). У новинах/медіа: 37 з 50 топ-сайтів США впали на 27–38% YoY. Регіонально: 90% AI-краулингу в Північній Америці, менше в Європі (41%) та Азії (58%) — упередження даних! Прогноз: до кінця 2025 боти досягнуть 51%, з AI на 80%+, вимагаючи нових інструментів як AI Crawl Control. Це "нове пояснення" впливу: краулинг не годує сайти, а виснажує їх. Далі — етика. ⚖️
⚖️ Розділ 6: Етичні виклики
"Без згоди — без даних: етика краулингу в епосі AI." — Натхненне принципами Anthropic та дискусіями 2025 року.
⚖️ Етичні виклики AI-краулингу — це одна з найгостріших проблем 2025 року: компанії на кшталт OpenAI, Anthropic та Meta збирають дані без явної згоди власників, порушуючи авторські права та не компенсуючи творців. Уявіть: ваш контент використовується для тренування LLM, генерує мільярди прибутку, але ви не отримуєте ні копійки, ні трафіку назад — реферали мізерні (наприклад, у Anthropic співвідношення crawl-to-refer сягає 70 900:1 за даними Cloudflare). Це ламає традиційну модель "контент за трафік", де видавці втрачають дохід від реклами та підписок. 😔
Ключові проблеми: несанкціонований скрапінг (навіть ігнорування robots.txt деякими ботами), відсутність прозорості та компенсації. У 2025 році вибухнули позови — від The New York Times проти Perplexity за копіювання мільйонів статей до Disney/Universal проти Midjourney за використання персонажів. Багато справ фокусуються на тому, чи є "fair use" для тренування, але суди часто схиляються до захисту авторів. Anthropic позиціонує себе етично (поважає robots.txt, фокус на мінімальному впливі), але навіть вони стикаються з обвинуваченнями в надмірному краулингу. Рішення на горизонті: GDPR-подібні регуляції (EU AI Act), пропонований стандарт llms.txt для чітких дозволів та "pay per crawl" від Cloudflare, де сайти можуть монетизувати доступ. Блокування AI-ботів зросло — Cloudflare блокує мільярди запитів з липня 2025. ⚠️
Я думаю, головний виклик — знайти баланс між інноваціями AI та правами творців. Без етичних стандартів веб стане закритішим, а AI — упередженим через брак даних. Для розробників я вважаю: час впроваджувати інструменти контролю! Далі — технічні рішення. 🛡️
🛡️ Розділ 7: Технічні проблеми та рішення
🛡️ Технічні проблеми AI-краулингу в 2025 році — це не абстрактна теорія, а реальна загроза для серверів і інфраструктури: боти генерують масовий трафік, що перевантажує ресурси, спотворює аналітику та підвищує витрати. За даними Forum One, AI-краулери часто обходять кеші, ігнорують robots.txt (13.26% запитів у Q2 2025), спуфують user-agent'и та атакують sitemap.xml чи пошукові сторінки, призводячи до уповільнення продуктивності, таймаутів серверів і зростання рахунків на хостинг — до 30 TB трафіку на місяць від одного бота! Уявіть: на урядових сайтах (.gov) це спричиняє збої в роботі, а в логах — хаос з тисячами запитів/хв, що ускладнює моніторинг реального трафіку. Cloudflare фіксує мільярди заблокованих запитів щодня, з піками до 39 тис./хв від реал-тайм фетчерів. 🚨
Основні проблеми в деталях 😩
1) **Перевантаження ресурсів**: AI-боти, як GPTBot чи Meta-ExternalAgent, роблять паралельні запити без пауз, обходячи кеші та генеруючи до 50 млрд запитів/день глобально. Результат — вищий CPU/пам'ять, повільніші завантаження для користувачів і витрати на трафік (наприклад, AWS рахунки ростуть на 20–50%). 2) **Хаос у логах і аналітиці**: Запити маскуються під "людські" (Mozilla/5.0), спотворюючи Google Analytics — до 80% "трафіку" від ботів, що фальсифікує метрики. 3) **Безпека та доступність**: Боти ігнорують аутентифікацію, атакують динамічний контент (JS), призводячи до DDoS-подібних ефектів без зловмисності. У 2025 році 5.6 млн сайтів заблокували GPTBot у robots.txt — зростання на 70% з липня.
Моє допущення — Рішення: від базових до інноваційних 🔧
Я вважаю, що щоб повернути контроль, варто дотримуватися покрокових стратегій на основі офіційних рекомендацій 2025. Почніть з простого, переходьте до просунутого.
1. Robots.txt для базового блокування 📜
Стандартний інструмент: додайте в корінь сайту файл robots.txt з правилами. Приклад для GPTBot (OpenAI):
User-agent: GPTBot
Disallow: /
Або для ClaudeBot (Anthropic):
User-agent: ClaudeBot
Disallow: /
GPTBot офіційно поважає це (user-agent: "Mozilla/5.0 (compatible; GPTBot/1.3; +https://openai.com/gptbot)"), з IP-діапазонами на
openai.com/gptbot.json. Для повного списку 20+ AI-краулерів (Amazonbot, CCBot тощо) — перевірте
Playwire гайд. Порада: оновлюйте щотижня, бо боти еволюціонують; несумісність може стати аргументом у суді (як у справі Reddit vs. Anthropic).
2. Cloudflare AI Crawl Control — вибірковий контроль ☁️
З липня 2025 Cloudflare блокує AI-краулерів за замовчуванням для 1+ млн клієнтів (одним кліком у дашборді). Фічі: розрізнення за метою (тренування vs. інференс/RAG), whitelist для "добрих" ботів (Googlebot) і моніторинг трафіку. Крок за кроком: 1) Увімкніть у Security > Bots; 2) Виберіть "Block AI Training" для GPTBot; 3) Дозвольте реал-тайм для ChatGPT. Це зменшує трафік на 80% без втрат у пошуку.
3. Pay per Crawl — монетизація доступу 💰
Нова фішка Cloudflare (бета з липня 2025): встановіть ціну за зону (наприклад, $0.01/запит). Бот без оплати отримує HTTP 402 Payment Required з деталями. Cloudflare як "Merchant of Record" обробляє платежі, дозволяючи заробляти на даних. Приклад: видавці встановлюють ставки, AI-компанії (OpenAI, Meta) платять або йдуть. За даними Cloudflare Docs, це третій шлях після "allow/block" — вже використовують великі медіа. Альтернатива: Really Simple Licensing (RSL) у robots.txt для pay-per-crawl чи pay-per-inference.
4. Додаткові інструменти: пастки та оптимізація 🕸️
AI Labyrinth (або подібні "пастки" від Cloudflare/WAF) — генерують фейковий контент для порушників, витрачаючи їх ресурси. Блокуйте на краю: Cloudflare WAF, Akamai чи Anubis для фільтрації за IP/user-agent. Рекомендація: оптимізуйте structured data (Schema.org) для AI-дружнього контенту — боти краще розуміють, а ви контролюєте, що індексувати. Кешуйте динаміку, whitelist високоцінні сторінки. Для .gov — комбінуйте з аутентифікацією. 🔒
Моя думка — ці рішення дають владу назад власникам: від безкоштовного блокування до заробітку. Я думаю, варто почати з robots.txt та Cloudflare і моніторити логи. Далі — майбутнє! 🔮
🔮 Розділ 8: Майбутнє краулингу
🌟 У 2025-му ми вже бачимо перші кроки до контрольованого краулингу: Pay per Crawl від Cloudflare, прямі угоди видавців з OpenAI та Google, нові стандарти RSL і llms.txt. До 2030 року ситуація зміниться кардинально: автономні AI-агенти (за Gartner, до 2028 — 33% корпоративного софту з agentic AI) вестимуть переговори за доступ до даних, а федеративне навчання дозволить оновлювати моделі без повного копіювання контенту.
Ключові тренди:
• AI-пошук (Overviews, чат-боти) займе до 75% трафіку запитів до 2028 (Semrush).
• Регуляції посиляться: EU AI Act вимагає прозорості, США рухаються до нових законів про дані.
• Партнерства стануть нормою: великі медіа вже заробляють мільйони на ліцензіях контенту.
• Монетизація: pay-per-crawl та ліцензії поширяться на середні сайти.
Рекомендації вже сьогодні:
Додавайте structured data (Schema.org), впроваджуйте llms.txt/RSL, підключайте Cloudflare Pay per Crawl. Для сайтів: створіть /ai-policy, вкажіть умови доступу та ціну. Захистіть і монетизуйте контент зараз — через 2–3 роки це буде стандарт.
Майбутнє — за прозорим і взаємовигідним краулингом, де сайти стануть партнерами AI, а не просто джерелом даних. Ваш контент вартий грошей — час почати його заробляти! 🌟
❓ Часті питання (FAQ)
✅ Висновки
Я думаю, з мого досвіду, краулінг в епосі AI — це справжня революція: від пасивного сканування для пошуку ми перейшли до активного «навчання» машин на нашому контенті. У 2025 році ключ до виживання — баланс: дозволяйте етичним ботам, блокуйте порушників і, головне, починайте монетизувати свої дані.
Для розробників, блогерів і власників сайтів я вважаю це особливо важливим: адаптуйтеся вже зараз. Додайте structured data (Schema.org), оновіть robots.txt, підключіть Cloudflare AI Crawl Control і Pay per Crawl. Почніть моніторити трафік через Cloudflare Radar — це безкоштовно і покаже, хто саме «їсть» ваш контент.
Детальніше про впровадження структурованих даних для Rich Snippets можна почитати тут.
Майбутнє, на мою думку, за тими, хто контролює свої дані, а не віддає їх безкоштовно. Ваш контент — це цінність, і час зробити так, щоб AI платив за нього. Дякуємо за читання! 🚀
🔥 Рекомендовані статті для подальшого читання
Сподобалась стаття? Ось добірка матеріалів, які допоможуть вам залишатися в курсі нових реалій пошуку та AI:
Підписуйтесь на блог, щоб не пропустити нові публікації про AI, SEO та цифровий маркетинг! 🚀
Вадим Харовюк
☕ Java розробник, засновник WebCraft Studio