En 2025, tus servidores **gimen bajo el ataque de invitados invisibles** 🤖—los bots de IA—que se tragan el contenido más rápido de lo que tardas en decir robots.txt. Estos viajeros digitales no solo escanean páginas; **aprenden de ellas**, generando respuestas sin que nadie haga clic en tu web. ¿El problema? Los editores pierden tráfico, y las empresas de IA, los datos para sus modelos. *Spoiler*: la nueva explicación del *crawling* es el **análisis semántico** para entrenar LLMs, donde la **ética y el control** son la clave para la supervivencia del ecosistema web. 💥
⚡ En resumen
- ✅ Idea Clave 1: Los *crawlers* de IA no son solo bots, sino **alumnos** que recogen datos para ChatGPT y Claude, generando más del 50% del tráfico web en 2025.
- ✅ Idea Clave 2: La diferencia con el *crawling* tradicional es el foco: **entrenar modelos, no buscar**, con referidos mínimos de vuelta a tu web.
- ✅ Idea Clave 3: Desafíos: servidores sobrecargados y ética; la solución pasa por el **AI Crawl Control de Cloudflare** y el "pago por *crawl*".
- 🎯 **Lo que te llevas:** Un conocimiento profundo de los mecanismos, estadísticas de 2025 y consejos prácticos para tu sitio.
- 👇 **Lee los detalles abajo** — ¡con ejemplos y conclusiones!
Índice del artículo:
⸻
🎯 Sección 1: Introducción al *Crawling* en la Era de la IA
🕵️♂️ "Los *AI-crawlers* no son ladrones, sino **alumnos que copian los deberes de Internet** sin pedir permiso." 😮Cloudflare Radar, 2025.
🕸️ El *crawling* es el escaneo automatizado de webs por bots para recoger datos, como arañas invisibles tejiendo una red de conocimiento en todo Internet. 🌐 En el mundo clásico, servía a buscadores como Googlebot para indexar páginas y devolver tráfico a las webs, donde los editores ganaban con anuncios y clics. 💰 Pero en la era de la IA, la cosa ha cambiado radicalmente: bots como GPTBot (de OpenAI) y ClaudeBot (de Anthropic) no solo indexan, sino que **analizan a fondo** la semántica, el contexto, el tono emocional y **entrenan Modelos Grandes de Lenguaje (LLM)**, convirtiendo tu contenido único en combustible para ChatGPT o Claude. 🔥📈
Según datos fresquitos de Cloudflare Radar AI Insights, en junio de 2025 el *AI-crawling* subió un **24% interanual**, llegando a un impresionante 80% del tráfico total de bots de IA, antes de frenar hasta el 4% en julio por nuevas regulaciones. Esta es la "nueva explicación" del *crawling*: el proceso se ha vuelto **inteligente y semántico** de verdad, donde las máquinas no solo recogen datos, sino que aprenden de ellos, generando respuestas sin un solo clic a tu web — ¡así que **cero recompensa** en forma de tráfico o ingresos! 😲 Imagina: tus artículos y noticias "viven" en las respuestas de la IA, ¡pero tú no ves ni un visitante! 😱
¿Por qué es esto importante ahora? Cloudflare, desde el 1 de julio, ha empezado a **bloquear los *AI-crawlers* por defecto** para millones de webs, permitiendo a los dueños controlar el acceso e incluso monetizar su contenido a través del "pago por *crawl*". Veamos la evolución paso a paso para entender cómo de simples bots de búsqueda llegamos a los dilemas éticos de la inteligencia artificial. 🚀
📚 Sección 2: *Crawling* Tradicional — Lo Básico
"El *crawling* es como un bibliotecario que ordena libros para una búsqueda rápida." — Definición clásica de Google Search Central.
📖 El ***Crawling* Tradicional** (Traditional Crawling) es el proceso fundamental que arrancó con los primeros motores de búsqueda en los 90, y sigue siendo la base para indexar contenido web.
Los **Bots** 🤖, como **Googlebot** o **Bingbot**, empiezan con una "**seed-URL**" 🌱 — una lista inicial de direcciones conocidas (webs populares, sitemaps...) — y siguen los enlaces 🔗, formando un árbol de descubrimientos. Extraen palabras clave 🔑, metaetiquetas, la estructura HTML e incluso ejecutan **JavaScript** 🖥️ para renderizar contenido dinámico, como se describe en la documentación de Google. El objetivo es sencillo: crear un inmenso **índice** 🗄️ para resultados de búsqueda relevantes, donde **cada clic redirige a la web**, generando ingresos por publicidad o tráfico 💰. 🔄
Imagina: Googlebot 🟢, con el *user-agent* "Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)", escanea páginas, valorando su frescura y relevancia. Bingbot 🔵, de forma similar, con "Mozilla/5.0 (compatible; bingbot/2.0; +http://www.bing.com/bingbot.htm)", indexa para Bing, que tiene una cuota de búsqueda global de $\sim$$\text{4\%}$.
Según datos de 2025, Googlebot domina con el 89.6% del mercado de búsqueda 👑, escaneando cientos de miles de millones de páginas al día — *grosso modo*, un tercio de la web conocida. Por ejemplo: en una web media, Googlebot realiza 2741 peticiones en 62 días 📈, mientras que Bingbot hace 4188 📉, demostrando la intensidad del trabajo. No es un caos, sino un proceso controlado: los bots respetan el robots.txt 🛑, limitan la frecuencia de peticiones (Googlebot — no más de unos segundos entre ellas) ⏱️ y se centran en la **versión móvil del contenido** 📱 desde 2020. 📊
En 2025, el *crawling* tradicional sigue estable, pero solo supone el 20-30% de la actividad total de bots, ya que los **bots de IA** 🧠 capturan el 80% del tráfico de *AI-crawlers*. En total, los bots generan el 49.6% del tráfico de Internet 🕸️, siendo los *crawlers* tradicionales los bots "**buenos**" que promueven la visibilidad. Es una **simbiosis**: las webs ganan visibilidad en la búsqueda 👀 (Googlebot creció un 96% desde 2024), y los buscadores, datos para sus algoritmos. ¡Pero la llegada de la IA 🤖 rompe este modelo, convirtiendo el *crawling* de un "enlace de vuelta" en un "**aprendizaje sin recompensa**" 🎁❌! Pasamos a la evolución en la siguiente sección. 🔍
🔄 Sección 3: La Evolución a *AI-Crawlers*
"De las palabras clave a la semántica: la IA convierte el *crawling* en aprendizaje." — Inspirado por las tendencias de 2025 de Vercel y Cloudflare.
🔄 Echemos un vistazo atrás para entender mejor la diferencia: **¿cómo era antes** con el *crawling* tradicional? Imagina Internet de 2010 a 2020: bots como Googlebot o Bingbot escaneaban la web **principalmente para indexar** — recogían palabras clave, enlaces, metaetiquetas y estructura HTML sencilla. A menudo ignoraban el contenido dinámico de JavaScript (porque no lo renderizaban del todo hasta 2019 para Google), se centraban en el volumen y la velocidad, y lo más importante: **devolvían tráfico** a través de los resultados de búsqueda. Era una simbiosis: las webs recibían visitantes, los buscadores, datos. Un clic en un enlace de Google generaba ingresos por publicidad, y la proporción *crawl-to-refer* era rentable — por ejemplo, Google rastreaba $\sim$$14$ páginas por cada 1 referido. 📊
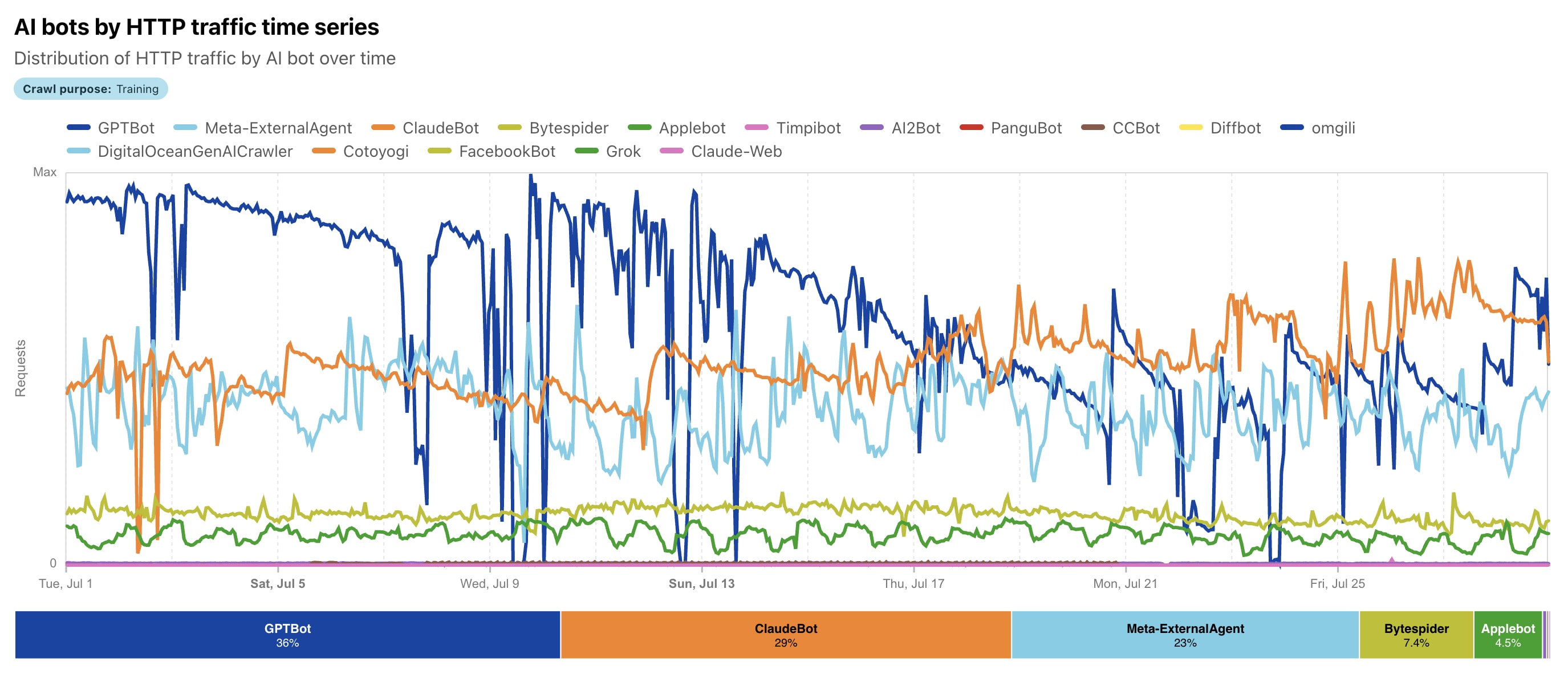
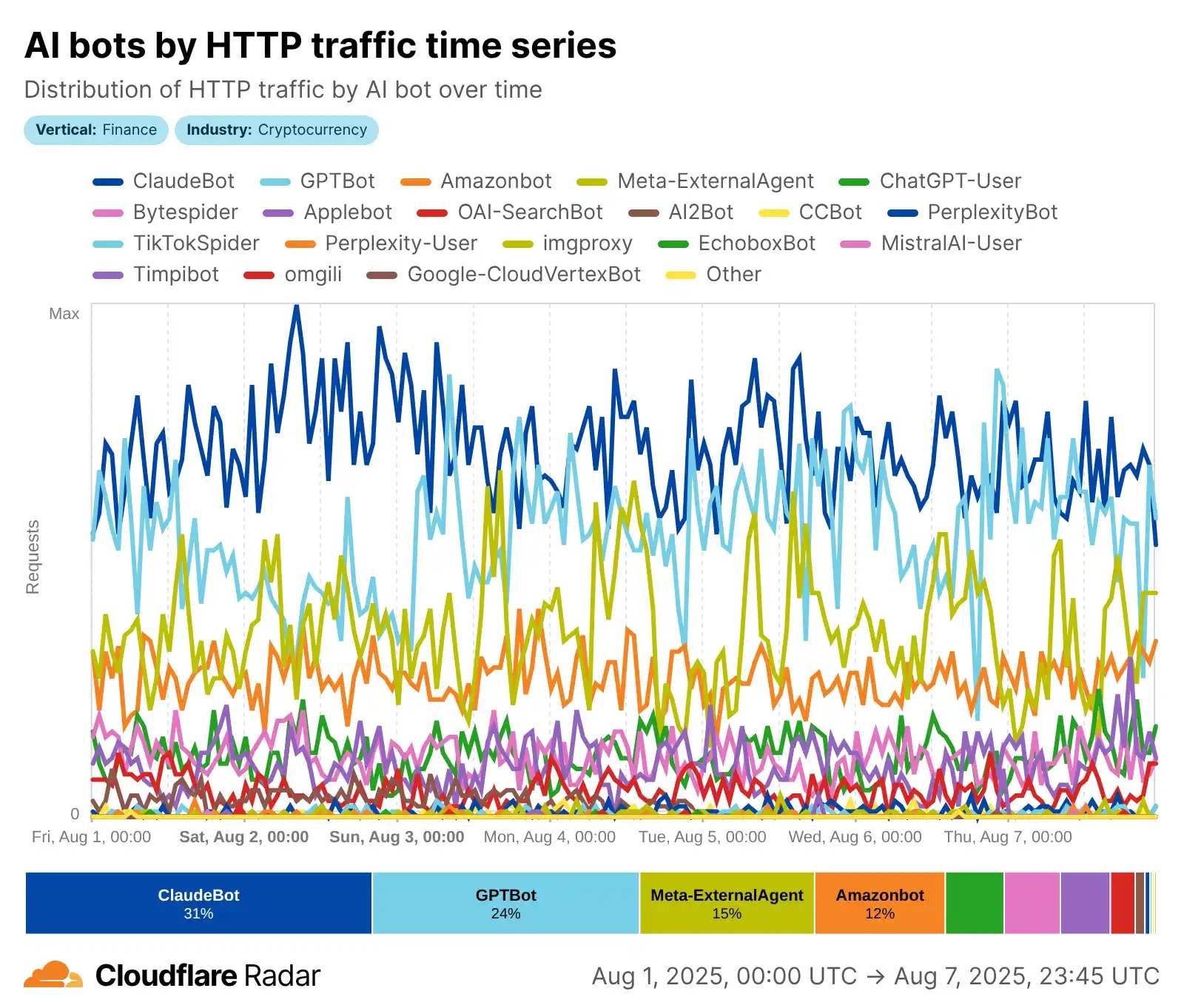
Pero todo se aceleró desde 2023 con el *boom* de la IA generativa: la evolución pasó de simples bots de búsqueda a verdaderos **agentes de IA** que usan NLP (procesamiento de lenguaje natural) para una comprensión profunda del contexto, la semántica, el tono del texto e incluso el contenido visual. Según Cloudflare, de mayo de 2024 a mayo de 2025, el *AI-crawling* cambió radicalmente: GPTBot (OpenAI) se disparó al liderazgo con una **cuota del 30%** (subiendo desde el 5%), Meta-ExternalAgent (Meta) debutó con un 19%, mientras que el antiguo líder Bytespider (ByteDance) cayó del 42% al 7%. ClaudeBot (Anthropic) se centra en la recogida ética de datos para el modelo Claude, y el *AI-crawling* total subió decenas de puntos. 🚀
La **diferencia clave**, para que lo veas claro: los bots tradicionales (como Googlebot) a menudo ignoraban o gestionaban mal el contenido JS, recogían datos para la búsqueda y devolvían tráfico. Los *AI-crawlers* renderizan contenido dinámico (aunque no siempre ejecutan el JS a la perfección, según Vercel), **priorizan la calidad y relevancia para entrenar LLMs**, pero... **¡casi no devuelven clics!** El resultado es la recopilación para el entrenamiento de grandes modelos de lenguaje (LLM), RAG (*Retrieval Augmented Generation*) y respuestas en tiempo real en ChatGPT o Claude. La evolución sigue: en 2025, Meta lidera en algunos segmentos (hasta un 52% según otros informes de Cloudflare), y el tráfico total de bots de IA roza el 80% de la actividad bot. No es solo un escaneo — es "**aprendizaje**" de tu contenido sin la antigua recompensa. 📈😲
📖 Lee también en nuestro blog
Si el tema del *AI-crawling* te ha enganchado, aquí tienes algunos artículos relacionados que te ayudarán a profundizar en el SEO moderno y la interacción con la inteligencia artificial:
Estos materiales complementarán a la perfección tu comprensión de cómo está cambiando la web en 2025. 🚀
⚙️ Sección 4: Cómo Funcionan los *AI-Crawlers*
🤖 El *AI-crawling* no es solo un escaneo mecánico, como el de los bots clásicos, sino un proceso complejo e "**inteligente**" enfocado en recopilar datos de alta calidad para entrenar Modelos Grandes de Lenguaje (LLM) y dar respuestas en tiempo real. A diferencia de Googlebot, que indexa para buscar, los *AI-crawlers* como GPTBot o ClaudeBot se centran en el **entendimiento semántico** del contenido: extraen texto, analizan el contexto, el sentimiento y la relevancia para mejorar modelos como ChatGPT o Claude. Según Cloudflare 2025, el *crawling* de entrenamiento ya es casi el 80% de todo el tráfico de bots de IA, con líderes como GPTBot (hasta un 30% de cuota) y Meta-ExternalAgent (hasta un 52% en algunos segmentos). Desglosemos el proceso paso a paso: esta es la "**nueva explicación**" del *crawling* en la era de la IA. 🔍
Paso 1: Descubrimiento (Discovery) 🚀
Todo empieza con una "*seed-URL*" — una lista inicial de direcciones conocidas (webs populares, sitemaps, enlaces de *crawls* anteriores). Pero en los *AI-crawlers* se añaden filtros inteligentes: modelos NLP evalúan de antemano la relevancia y la calidad del contenido, priorizando material textual, educativo o estructurado. Por ejemplo, GPTBot (User-agent: GPTBot/1.0) y ClaudeBot (User-agent: ClaudeBot/1.0) buscan contenido disponible públicamente sin *paywalls* ni *logins*. Respetan robots.txt (por ejemplo, Disallow: / bloquea el acceso), pero pueden ignorar CAPTCHAs u otras barreras si no se indica lo contrario. En 2025, el descubrimiento es más eficiente: **los bots evitan las páginas de baja calidad**, centrándose en datos para LLMs.
Paso 2: Recolección de Datos (Fetching) 📥
El bot envía peticiones HTTP, identificándose con su *user-agent* (por ejemplo, "Mozilla/5.0 (compatible; GPTBot/1.0; +https://openai.com/gptbot)"). Descarga HTML, **renderiza parcialmente el contenido dinámico** (aunque no siempre ejecuta el JavaScript por completo, a diferencia de Googlebot), extrae texto, imágenes, PDFs e incluso metadatos. GPTBot recopila para el entrenamiento de futuros modelos (GPT-5+), ClaudeBot — para actualizar Claude, enfocándose en **contenido ético y diverso**. Según Vercel y Cloudflare, los *AI-crawlers* generan miles de millones de peticiones: GPTBot — cientos de millones al mes, con picos de decenas de miles de peticiones por minuto en sitios populares. Son escalables en paralelo, pero intentan ser *well-behaved* — limitan la velocidad para no sobrecargar los servidores.
Paso 3: Análisis y Procesamiento Semántico (Parsing & Semantic Analysis) 🧠
Aquí ocurre la magia: el contenido extraído se analiza utilizando NLP para la **comprensión semántica** — desglosar el sentimiento, la intención, las entidades y el contexto. Los bots filtran el *boilerplate* (publicidad, navegación), extraen el texto limpio y evalúan su utilidad para el entrenamiento. Por ejemplo, ClaudeBot prioriza el contenido educativo, GPTBot — fuentes diversas para mejorar la precisión de las respuestas. Los datos se integran en RAG (*Retrieval Augmented Generation*) para consultas en tiempo real o en conjuntos de datos de entrenamiento. **Esta es la diferencia clave**: ¡no solo es indexación, sino "**aprendizaje**" de tu contenido para el modelo!
Paso 4: Escalabilidad y Almacenamiento (Scaling & Storage) ⚡
El proceso se repite masivamente: peticiones paralelas desde distintas IPs (a menudo desde nubes como AWS/Azure), respetando el *crawl-delay* en robots.txt. En 2025, el tráfico es explosivo — los bots de Meta generan hasta el 52% del *AI-crawling*, GPTBot ha crecido un 305%. Los datos se almacenan para el entrenamiento *offline* o RAG *online*. Ejemplos: ClaudeBot recopila para el entrenamiento ético de Claude, centrándose en contenido de calidad; GPTBot — para la mejora a gran escala de ChatGPT. Esta es la "**nueva explicación**": el *crawling* se ha convertido en un proceso de **enseñanza a las máquinas**, no solo de búsqueda. 🤖🌟
📊 Sección 5: Estadísticas e Impacto en el Tráfico 2025
📊 En 2025, el tráfico de bots se ha convertido en una verdadera "hormiga silenciosa" de Internet, donde los agentes automatizados **superan al tráfico humano** en volumen e impacto. Según Cloudflare Radar, los bots son cerca del **30% del tráfico web global**, siendo los *AI-crawlers* la nueva fuerza dominante, generando hasta el 80% de toda la actividad de bots de IA. Fastly, en su Informe Q2 Threat Insights, fija una cifra aún mayor: *AI-crawlers* — casi el 80% del tráfico de bots de IA, con bots "**malos**" (incluyendo *scraping* no autorizado) en el 37% del tráfico total. ¡Imagina! De 6.5 billones de peticiones al mes a través de Fastly, miles de millones van a entrenar LLMs, sobrecargando servidores y distorsionando la analítica. **No son solo números, es una crisis** para las webs donde los datos se van "en una dirección". 📉
Veamos los indicadores clave: el tráfico total de bots alcanza el 49.6–51% de Internet (según Thunderbit 2025), con los *AI-crawlers* como principal motor de crecimiento. ¿Quién lidera? Los bots de Meta generan el 52% del *AI-crawling*, Google — 23%, OpenAI — 20%, mientras que Anthropic (ClaudeBot) se mantiene en el 3.76% con acento en la ética. GPTBot **creció un 305%** de mayo de 2024 a 2025, ClaudeBot — al doble (hasta el 10%), y Bytespider de ByteDance cayó del 14.1% al 2.4% por regulaciones. Cloudflare registra 50 mil millones de peticiones al día de IA, con picos de hasta 39 mil peticiones/min de un *fetcher* (respuestas en tiempo real) y 1 mil de un *crawler* — ¡es un efecto tipo DDoS sin ser malicioso! 🚨
Impacto en el Tráfico: De la Sobrecarga a las Pérdidas 😩
Para las webs es un doble golpe: **sobrecarga de servidores** (hasta 30 TB/mes de un solo bot) y un **bajo *crawl-to-click ratio*** — la IA no devuelve tráfico. Según Cloudflare, el *crawling* de entrenamiento es el 79–80% de la actividad de IA (subiendo desde el 72% en 2024), con referidos de 70,900:1 para Anthropic (¡71 mil *crawls* por 1 clic!) o 887:1 para OpenAI. En noticias, los referidos de Google cayeron un 9% en marzo de 2025, y el CTR total cae un 61% para el orgánico y un 68% para el pagado debido a los AI Overviews (Seer Interactive, septiembre de 2025). Incluso sin AIO: CTR orgánico -41%, pagado -20%. Ejemplo: para consultas informativas con AIO, el CTR cayó del 1.76% al 0.61%, las impresiones suben (+27%), ¡pero los clics caen (-36%)! Los editores pierden un 10–25% de tráfico interanual, con caídas de hasta el 64% en palabras clave importantes. Para la IA es una "mina de oro" de datos, pero para los negocios, es la **erosión de ingresos por publicidad**. 🌐
Gráfico de Crecimiento: Explosión y Estabilización 📈
De mayo de 2024 a mayo de 2025, el tráfico de IA subió un 18% en total, con un +32% interanual en abril de 2025 (pico), +24% en junio y una ralentización al +4% en julio por los bloqueos (Cloudflare bloquea por defecto desde el 1 de julio). En noticias/medios: 37 de los 50 principales sitios de EE. UU. cayeron un 27–38% interanual. Regionalmente: 90% del *AI-crawling* en Norteamérica, menos en Europa (41%) y Asia (58%) — ¡**sesgo de datos**! Pronóstico: para finales de 2025, los bots alcanzarán el 51%, con la IA en el 80%+, lo que exigirá nuevas herramientas como el AI Crawl Control. Esta es la "**nueva explicación**" del impacto: **el *crawling* no alimenta las webs, sino que las agota**. A continuación, la ética. ⚖️
⚖️ Sección 6: Retos Éticos
"Sin consentimiento — sin datos: la ética del *crawling* en la era de la IA." — Inspirado por los principios de Anthropic y las discusiones de 2025.
⚖️ Los retos éticos del *AI-crawling* son uno de los temas más candentes de 2025: empresas como OpenAI, Anthropic y Meta **recopilan datos sin el consentimiento expreso** de los dueños, infringiendo derechos de autor y sin compensar a los creadores. Imagina: tu contenido se usa para entrenar LLMs, genera miles de millones en ganancias, pero tú no recibes ni un céntimo ni tráfico de vuelta — los referidos son ínfimos (por ejemplo, en Anthropic el ratio *crawl-to-refer* alcanza los 70,900:1 según Cloudflare). Esto **rompe el modelo tradicional de "contenido por tráfico"**, donde los editores pierden ingresos por publicidad y suscripciones. 😔
Problemas clave: *scraping* no autorizado (incluso la ignorancia de robots.txt por algunos bots), falta de transparencia y compensación. En 2025, estallaron las demandas — desde *The New York Times* contra Perplexity por copiar millones de artículos hasta Disney/Universal contra Midjourney por usar personajes. Muchos casos se centran en si el entrenamiento es "*fair use*", pero los tribunales a menudo se inclinan por la protección de los autores. Anthropic se posiciona éticamente (respeta robots.txt, se enfoca en el impacto mínimo), pero incluso ellos se enfrentan a acusaciones de *crawling* excesivo. Soluciones en el horizonte: regulaciones tipo GDPR (*EU AI Act*), el estándar propuesto llms.txt para permisos claros y el **"pago por *crawl*" de Cloudflare**, donde las webs pueden monetizar el acceso. El bloqueo de bots de IA se ha disparado — Cloudflare bloquea miles de millones de peticiones desde julio de 2025. ⚠️
Yo creo que el desafío principal es encontrar un equilibrio entre la innovación de la IA y los derechos de los creadores. Sin estándares éticos, la web se volverá más cerrada y la IA, **sesgada por la falta de datos**. Para los desarrolladores, considero que ¡es hora de implementar herramientas de control! A continuación, las soluciones técnicas. 🛡️
🛡️ Sección 7: Problemas Técnicos y Soluciones
🛡️ Los problemas técnicos del *AI-crawling* en 2025 no son teoría abstracta, sino una **amenaza real** para servidores e infraestructura: los bots generan tráfico masivo que sobrecarga recursos, distorsiona la analítica y aumenta los costes. Según Forum One, los *AI-crawlers* a menudo evitan cachés, ignoran robots.txt (13.26% de las peticiones en Q2 2025), suplantan *user-agents* y atacan sitemap.xml o páginas de búsqueda, provocando ralentizaciones, *timeouts* del servidor y **subida de facturas de *hosting*** — ¡hasta 30 TB de tráfico al mes de un solo bot! Imagina: en webs gubernamentales (.gov), esto causa fallos en el servicio, y en los *logs*, un caos con miles de peticiones/minuto que dificulta el monitoreo del tráfico real. Cloudflare registra miles de millones de peticiones bloqueadas cada día, con picos de hasta 39 mil/min de *fetchers* en tiempo real. 🚨
Los Problemas Principales en Detalle 😩
1) **Sobrecarga de recursos**: Los bots de IA, como GPTBot o Meta-ExternalAgent, hacen peticiones paralelas sin pausas, saltándose cachés y generando hasta 50 mil millones de peticiones/día globalmente. Resultado: mayor uso de CPU/memoria, cargas más lentas para los usuarios y **costes de tráfico** (por ejemplo, las facturas de AWS suben un 20–50%). 2) **Caos en *logs* y analítica**: Las peticiones se disfrazan de "humanas" (Mozilla/5.0), distorsionando Google Analytics — hasta el 80% del "tráfico" es de bots, falseando métricas. 3) **Seguridad y disponibilidad**: Los bots ignoran la autenticación, atacan contenido dinámico (JS), causando efectos tipo DDoS sin ser maliciosos. En 2025, 5.6 millones de webs bloquearon GPTBot en robots.txt — un aumento del 70% desde julio.
Mi recomendación — **Soluciones: De Básicas a Innovadoras** 🔧
Creo que para recuperar el control, debes seguir estrategias paso a paso basadas en las recomendaciones oficiales de 2025. Empieza por lo simple, ve a lo avanzado.
1. Robots.txt para Bloqueo Básico 📜
La herramienta estándar: añade un archivo robots.txt en la raíz de tu web con reglas. Ejemplo para GPTBot (OpenAI):
User-agent: GPTBot
Disallow: /
O para ClaudeBot (Anthropic):
User-agent: ClaudeBot
Disallow: /
GPTBot respeta esto oficialmente (user-agent:
"Mozilla/5.0 (compatible; GPTBot/1.3; +https://openai.com/gptbot)"), con los rangos de IP en
openai.com/gptbot.json. Para una lista completa de más de 20 *AI-crawlers* (Amazonbot, CCBot, etc.) — consulta la
guía de Playwire. Consejo: actualiza semanalmente, porque los bots evolucionan; la incompatibilidad puede ser un argumento en un juicio (como en el caso Reddit vs. Anthropic).
2. Cloudflare AI Crawl Control — Control Selectivo ☁️
Desde julio de 2025, Cloudflare bloquea a los *AI-crawlers* por defecto para más de 1 millón de clientes (con un solo clic en el panel). Características: distinción por propósito (entrenamiento vs. inferencia/RAG), *whitelist* para bots "buenos" (Googlebot) y monitoreo de tráfico. Pasos: 1) Activa en *Security > Bots*; 2) Elige "Block AI Training" para GPTBot; 3) Permite el tiempo real para ChatGPT. Esto reduce el tráfico en un 80% sin perder visibilidad en la búsqueda.
3. Pay per Crawl — Monetización del Acceso 💰
Una novedad de Cloudflare (beta desde julio de 2025): **establece un precio por zona** (por ejemplo, $0.01/petición). Un bot sin pagar recibe un HTTP 402 *Payment Required* con los detalles. Cloudflare, como *Merchant of Record*, gestiona los pagos, permitiéndote ganar dinero con tus datos. Ejemplo: los editores fijan tarifas, las empresas de IA (OpenAI, Meta) pagan o se van. Según Cloudflare Docs, es la tercera vía tras "permitir/bloquear" — ya lo usan grandes medios. Alternativa: *Really Simple Licensing* (RSL) en robots.txt para *pay-per-crawl* o *pay-per-inference*.
4. Herramientas Adicionales: Trampas y Optimización 🕸️
*AI Labyrinth* (o trampas similares de Cloudflare/WAF) — generan contenido falso para los infractores, gastando sus recursos. **Bloquea en el borde**: Cloudflare WAF, Akamai o Anubis para filtrar por IP/*user-agent*. Recomendación: **optimiza tus *structured data*** (Schema.org) para un contenido amigable con la IA — los bots entienden mejor y tú controlas qué indexar. Cachea lo dinámico, pon en *whitelist* las páginas de alto valor. Para .gov — combina con autenticación. 🔒
Mi opinión es que estas soluciones devuelven el poder a los dueños: desde el bloqueo gratuito hasta la ganancia de dinero. Creo que vale la pena empezar con robots.txt y Cloudflare y monitorear los *logs*. ¡A continuación, el futuro! 🔮
🔮 Sección 8: El Futuro del *Crawling*
🌟 En 2025 ya estamos viendo los primeros pasos hacia un *crawling* controlado: *Pay per Crawl* de Cloudflare, acuerdos directos de editores con OpenAI y Google, y nuevos estándares RSL y llms.txt. Para 2030, la situación cambiará radicalmente: los **agentes de IA autónomos** (según Gartner, para 2028, el 33% del software corporativo tendrá IA agéntica) negociarán el acceso a los datos, y el aprendizaje federado permitirá actualizar modelos sin copiar el contenido por completo.
Tendencias clave:
• La **búsqueda por IA** (*Overviews*, chatbots) acaparará hasta el 75% del tráfico de consultas para 2028 (Semrush).
• Las **regulaciones** se endurecerán: la *EU AI Act* exige transparencia; EE. UU. avanza hacia nuevas leyes de datos.
• Las **asociaciones** serán la norma: los grandes medios ya ganan millones con licencias de contenido.
• **Monetización**: el *pay-per-crawl* y las licencias se extenderán a las webs medianas.
Recomendaciones desde hoy:
Añade *structured data* (Schema.org), implementa llms.txt/RSL, y conecta Cloudflare *Pay per Crawl*. Para tu web: crea una /ai-policy, indica las condiciones de acceso y el precio. Protege y **monetiza tu contenido ahora** — en 2 o 3 años será lo normal. 💰
El futuro pasa por un *crawling* transparente y mutuamente beneficioso, donde las webs se conviertan en **socios de la IA**, no solo en una fuente de datos. Tu contenido vale dinero — ¡es hora de empezar a ganarlo! 🌟
❓ Preguntas Frecuentes (FAQ)
✅ Conclusiones
Yo creo, basándome en mi experiencia, que el *crawling* en la era de la IA es una **verdadera revolución**: de un escaneo pasivo para buscar, hemos pasado a un "**aprendizaje**" activo de las máquinas a partir de nuestro contenido. En 2025, la clave para sobrevivir es el **equilibrio**: permite a los bots éticos, bloquea a los infractores y, lo más importante, ¡empieza a monetizar tus datos! 💰
Para desarrolladores, blogueros y dueños de webs, considero que esto es especialmente importante: **adaptaos ahora**. Añade *structured data* (Schema.org), actualiza robots.txt, conecta Cloudflare AI Crawl Control y *Pay per Crawl*. Empieza a monitorear el tráfico a través de Cloudflare Radar — es gratis y te mostrará quién está "**comiéndose**" tu contenido. 🧐
Puedes leer más sobre la implementación de datos estructurados para *Rich Snippets* aquí.
El futuro, en mi opinión, pertenece a quienes **controlan sus datos**, no a quienes los regalan. Tu contenido es un activo, ¡y es hora de hacer que la IA pague por él! ¡Gracias por leer! 🚀
🔥 Artículos Recomendados para Seguir Leyendo
¿Te gustó el artículo? Aquí tienes una selección de materiales que te ayudarán a mantenerte al día con las nuevas realidades de la búsqueda y la IA:
¡Suscríbete al blog para no perderte nuevas publicaciones sobre IA, SEO y marketing digital! 🚀
Vadim Kharoviuk
☕ Desarrollador Java, Fundador de WebCraft Studio