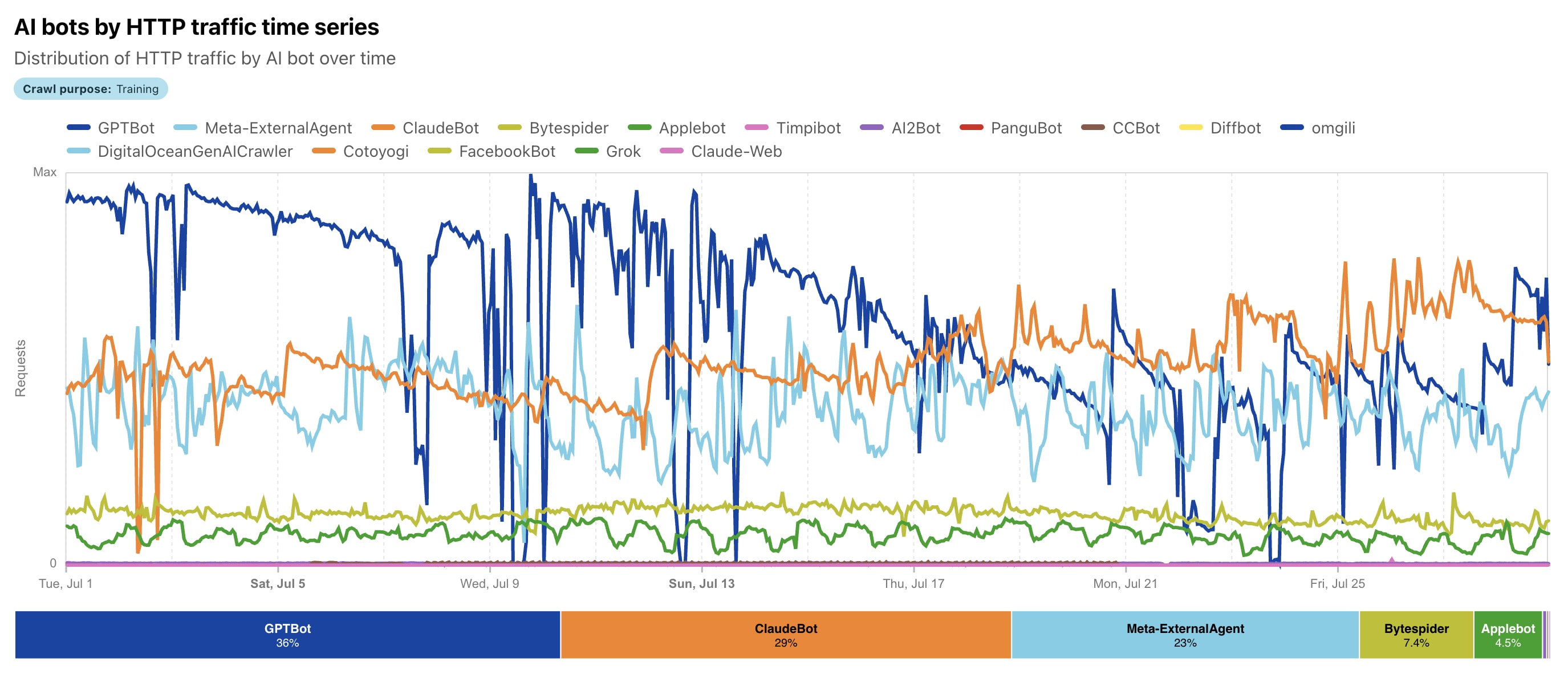
In 2025, your servers are groaning under the pressure of **invisible guests**—AI-bots that are swallowing content faster than you can say `robots.txt`. These digital travelers aren't just scanning pages; they are **learning** from them, generating answers without a single click back to your site. The problem? **Publishers lose traffic**, and AI companies lose data for models. Spoiler: The new definition of crawling is **semantic analysis for LLM training**, where **ethics and control** become the key to the web ecosystem's survival.
⚡ Quick Takeaway
- ✅ Key Point 1: AI crawlers aren't just bots; they are **students** gathering data for ChatGPT and Claude, generating **50%+ of web traffic** in 2025.
- ✅ Key Point 2: The difference from traditional crawling: the focus is on **model training**, not search indexing, with **minimal referrals** back to the site.
- ✅ Key Point 3: Challenges include **server overload and ethics**; solutions involve Cloudflare's **AI Crawl Control** and "pay per crawl" models.
- 🎯 What You Get: A deep understanding of the mechanisms, 2025 statistics, and practical recommendations for website owners.
- 👇 Read the details below for examples and conclusions.
Article Content:
⸻
🎯 Section 1: The Intro to Crawling in the Age of AI
🕵️♂️ "AI crawlers are not thieves, but students who copy homework from the internet without asking for permission." Cloudflare Radar, 2025.
🕸️ Crawling is the **automated scanning of websites by bots** to gather data—like invisible spiders spinning a web of knowledge across the entire internet. 🌐 In the traditional world, this served search engines like Googlebot to index pages and send traffic back to sites, where publishers made money from ads and clicks. 💰 But in the Age of AI, everything has changed: bots like **GPTBot** (from OpenAI) and **ClaudeBot** (from Anthropic) don't just index—they deeply analyze the **semantics**, context, emotional tone, and train Large Language Models (LLMs), turning your unique content into **fuel** for ChatGPT or Claude. 🔥📈
According to fresh data from Cloudflare Radar AI Insights, in 2025, AI crawling grew by **24% year-over-year** in June, hitting an impressive **80% of total AI-bot traffic** before slowing down to 4% in July due to new regulations. This is the "new definition" of crawling: the process has become truly intelligent and **semantic**, where machines not only collect data but learn from it, generating answers without a single click to your site—meaning **no traffic or revenue reward**. Imagine: your articles, blogs, or news "live" in AI answers, but you don't see a single visitor! 😲
Why is this a big deal right now? Since July 1st, Cloudflare has introduced a **default block** on AI crawlers for millions of sites, allowing owners to control access and even **monetize content** through a "pay per crawl" model. Let's look at the evolution step-by-step to understand how we went from simple search bots to AI's ethical dilemmas. 🚀
📚 Section 2: Traditional Crawling — The Basics
"Crawling is like a librarian sorting books for quick reference." — Classic definition from Google Search Central.
📖 **Traditional Crawling** is the fundamental process that started with early search engines in the 1990s and is still the backbone of web content indexing.
**Bots** 🤖, like **Googlebot** or **Bingbot**, start with a "**seed URL**" 🌱 — an initial list of known addresses (e.g., popular sites or sitemaps) — and follow links 🔗, forming a discovery tree. They extract **keywords** 🔑, meta-tags, HTML structure, and even execute **JavaScript** 🖥️ to render dynamic content, as described in Google's documentation. The goal is simple: to create a huge **index** 🗄️ for relevant search results, where every click leads back to the site, generating ad revenue or traffic 💰. 🔄
Imagine: Googlebot 🟢, with the user-agent "Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)", scans pages, evaluating their freshness and relevance. Bingbot 🔵, similarly, with "Mozilla/5.0 (compatible; bingbot/2.0; +http://www.bing.com/bingbot.htm)", indexes for Bing, which has $\sim$$\text{4\%}$ of the global search share.
According to 2025 data, Googlebot dominates with 89.6% of the search market 👑, scanning hundreds of billions of pages daily—roughly a third of the known web. Example: on an average site, Googlebot makes 2741 requests over 62 days 📈, while Bingbot makes 4188 📉, showing the intensity of the work. It's not chaos but a controlled process: bots respect `robots.txt` 🛑, limit the query rate (Googlebot - no more than a few seconds between requests) ⏱️, and focus on the **mobile version of the content** 📱 since 2020. 📊
In 2025, traditional crawling remains stable but accounts for only 20-30% of total bot activity, as **AI bots** 🧠 take over **80% of AI-crawler traffic**. Overall, bots generate 49.6% of internet traffic 🕸️, with traditional crawlers being the "**good**" bots that promote visibility. This is a **symbiosis**: sites gain search visibility 👀 (Googlebot grew by 96% since 2024), and search engines get data for algorithms. However, the arrival of AI 🤖 breaks this model, turning crawling from "link back" into "**learning without reward**" 🎁❌. Let's move to the evolution in the next section. 🔍
🔄 Section 3: The Evolution to AI Crawlers
"From keywords to semantics: AI turns crawling into learning." — Inspired by 2025 trends from Vercel and Cloudflare.
🔄 Let's go back to better understand the difference: **what was it like before** with traditional crawling? Imagine the internet of the 2010s–2020s: bots like Googlebot or Bingbot scanned the web mainly for **indexing**—collecting keywords, links, meta-tags, and simple HTML structure. They often ignored dynamic JavaScript content (because they didn't fully render it until 2019 for Google), focused on volume and speed, and most importantly—**sent traffic back** through search results. It was a symbiosis: sites got visitors, search engines got data. A click on a Google link generated ad revenue, and the crawl-to-refer ratio was favorable—for example, Google crawls ~14 pages for 1 referral. 📊
But everything accelerated from 2023 with the boom of generative AI: the evolution shifted from simple search bots to true **AI agents** that use NLP (natural language processing) for a deep understanding of context, semantics, text sentiment, and even visual content. According to Cloudflare, from May 2024 to May 2025, AI crawling radically changed: **GPTBot** (OpenAI) jumped into the lead with a **30% share** (up from 5%), **Meta-ExternalAgent** (Meta) debuted with 19%, while the former leader **Bytespider** (ByteDance) dropped from 42% to 7%. **ClaudeBot** (Anthropic) focuses on ethical data collection for the Claude model, and overall AI crawling grew by tens of percent. 🚀
The key **difference**, so you can clearly see it: traditional bots (like Googlebot) often ignored or poorly processed JS content, collected data for search, and returned traffic. AI crawlers render dynamic content (though they don't always execute JS perfectly, according to Vercel), prioritize **quality and relevance for LLM training**, but... **almost never return clicks!** The result is data collection for training Large Language Models (LLMs), RAG (Retrieval Augmented Generation), and real-time answers in ChatGPT or Claude. The evolution continues: in 2025, Meta leads in some segments (up to 52% according to other Cloudflare reports), and the total traffic from AI bots reaches **80% of bot activity**. It's not just scanning—it's "**learning**" from your content without the old reward. 📈😲
📖 Also Read on Our Blog
If the topic of AI crawling has caught your interest, here are a few related articles that will help you dive deeper into modern SEO and interaction with artificial intelligence:
These materials will perfectly complement your understanding of how the web is changing in 2025. 📈
⚙️ Section 4: How AI Crawlers Actually Work
🤖 AI crawling isn't just a mechanical scan like with traditional bots; it's a complex, **"smart" process** focused on gathering high-quality data for training Large Language Models (**LLMs**) and for real-time answers. Unlike Googlebot, which indexes for search, AI crawlers like **GPTBot** or **ClaudeBot** focus on the **semantic understanding of content**: they extract text, analyze context, sentiment, and relevance to improve models like ChatGPT or Claude. According to **Cloudflare 2025** data (source), training-focused crawling makes up almost **80% of all AI-bot traffic**, with leaders like GPTBot (up to 30% share) and Meta-ExternalAgent (up to 52% in some segments). Let's break down the process step-by-step—this is the **"new definition" of crawling** in the AI era. 🔍
**Step 1: Discovery** 🚀
It all starts with a "**seed URL**"—an initial list of known addresses (popular sites, sitemaps, links from previous crawls). But AI crawlers add **smart filters**: **NLP models** pre-assess content relevance and quality, prioritizing textual, educational, or structured material. For example, GPTBot (User-agent: GPTBot/1.0) and ClaudeBot (User-agent: ClaudeBot/1.0) look for publicly available content without paywalls or logins. They respect `robots.txt` (e.g., `Disallow: /` blocks access), but might ignore CAPTCHA or other barriers if not explicitly told otherwise. In 2025, discovery is more efficient: bots avoid low-quality pages, focusing on data for LLMs.
**Step 2: Fetching Data** 📥
The bot sends **HTTP requests**, identifying itself with a user-agent (e.g., "Mozilla/5.0 (compatible; GPTBot/1.0; +https://openai.com/gptbot)"). It downloads HTML, renders partially dynamic content (though not always fully executing JavaScript, unlike Googlebot), and extracts text, images, PDF, and even metadata. GPTBot collects data for training future models (GPT-5+), and ClaudeBot for updating Claude, focusing on ethical and diverse content. According to Vercel and Cloudflare, AI crawlers generate billions of requests: GPTBot—hundreds of millions monthly, with peaks up to tens of thousands of requests per minute on popular sites. They are scaled in parallel, but try to be "well-behaved"—limiting speed so as not to overload servers.
**Step 3: Parsing & Semantic Analysis** 🧠
Here's where the magic happens: the extracted content is parsed using **NLP** for **semantic understanding**—analysis of mood, intent, entities, and context. Bots filter out boilerplate (ads, navigation), extract clean text, and evaluate its usefulness for training. For instance, ClaudeBot prioritizes educational content, GPTBot—diverse sources to improve answer accuracy. The data is integrated into **RAG** (Retrieval Augmented Generation) for real-time queries or into training datasets. This is the **key difference**: not just indexing, but **model "learning" from your content**!
**Step 4: Scaling & Storage** ⚡
The process is repeated massively: **parallel requests** from different IPs (often from clouds like AWS/Azure), respecting the `crawl-delay` in `robots.txt`. In 2025, traffic is explosive—Meta-bots generate up to 52% of AI crawling, GPTBot grew by 305%. Data is stored for offline training or online RAG. Examples: ClaudeBot collects for Claude's ethical training, focusing on quality content; GPTBot—for massive ChatGPT improvements. This is the "new definition": crawling has become a machine learning process, not just searching. 🤖🌟
📊 Section 5: Statistics and Traffic Impact 2025
📊 In 2025, bot traffic has become the internet's true "**silent army**," where automated agents surpass human traffic in volume and influence. According to Cloudflare Radar, bots account for about **30% of global web traffic**, with **AI crawlers** as the new dominant force, generating up to **80% of all AI-bot activity**. Fastly in its Q2 Threat Insights Report records an even higher figure: AI crawlers—almost **80% of AI-bot traffic**, with "**bad**" bots (including unauthorized scraping) at 37% of total traffic. Imagine: out of 6.5 trillion requests per month through Fastly, billions go to train LLMs, overloading servers and distorting analytics. These aren't just numbers—it's a crisis for sites where data flows "**one way**." 📉
Let's look at key metrics: total bot traffic reaches **49.6–51%** of the internet (per Thunderbit 2025), with AI crawlers as the main growth driver. Leaders? Meta-bots generate **52% of AI crawling**, Google—23%, OpenAI—20%, while Anthropic (ClaudeBot) stays at 3.76% with an emphasis on ethics. GPTBot grew by **305%** from May 2024 to 2025, ClaudeBot—doubled (to 10%), and ByteDance's Bytespider dropped from 14.1% to 2.4% due to regulations. Cloudflare logs **50 billion requests per day** from AI, with peaks up to **39k requests/min** from a single fetcher (real-time answers) and 1k from a crawler—this is a **DDoS-like effect** without malice! 🚨
**Traffic Impact: From Overload to Loss** 😩
For sites, this is a double whammy: **server overload** (up to 30 TB/month from a single bot) and a **low crawl-to-click ratio**—AI doesn't send traffic back. According to Cloudflare, training crawling is **79–80%** of AI activity (up from 72% in 2024), with referrals as low as **70,900:1 for Anthropic** (71k crawls per 1 click!) or 887:1 for OpenAI. In the news sector, Google referrals fell by 9% in March 2025, and overall **CTR drops by 61%** for organic and 68% for paid due to AI Overviews (Seer Interactive, Sept 2025). Even without AIO: organic CTR is -41%, paid -20%. Example: for informational queries with AIO, CTR dropped from 1.76% to 0.61%, impressions grow (+27%), but clicks fall (-36%). Publishers lose **10–25% of traffic YoY**, with drops up to 64% on key keywords. For AI—this is a **"gold mine" of data**, but for business—**revenue erosion** from advertising. 🌐
**Growth Chart: Boom and Stabilization** 📈
From May 2024 to May 2025, AI traffic grew by 18% overall, with +32% YoY in April 2025 (peak), +24% in June, and a slowdown to +4% in July due to blocking (Cloudflare blocks by default from July 1st). In news/media: 37 of the top 50 US sites fell by 27–38% YoY. Regionally: **90% of AI crawling in North America**, less in Europe (41%) and Asia (58%)—data bias! Forecast: by the end of 2025, bots will reach 51%, with AI at 80%+, demanding new tools like AI Crawl Control. This is the "new definition" of impact: **crawling doesn't feed sites, it depletes them**. Next—ethics. ⚖️
⚖️ Section 6: Ethical Challenges
"No consent—no data: the ethics of crawling in the Age of AI." — Inspired by Anthropic principles and 2025 discussions.
⚖️ The **ethical challenges** of AI crawling are one of the most pressing issues of 2025: companies like OpenAI, Anthropic, and Meta are gathering data **without explicit owner consent**, infringing on **copyrights** and failing to compensate creators. Imagine: your content is used to train LLMs, generating billions in profit, but you don't receive a dime or traffic back—referrals are negligible (e.g., Anthropic's crawl-to-refer ratio reaches 70,900:1 according to Cloudflare). This breaks the traditional "**content for traffic**" model, where publishers lose revenue from advertising and subscriptions. 😔
Key problems: **unauthorized scraping** (even ignoring `robots.txt` by some bots), **lack of transparency**, and **compensation**. In 2025, lawsuits exploded—from The New York Times against Perplexity for copying millions of articles to Disney/Universal against Midjourney for using characters. Many cases focus on whether training is "**fair use**," but courts often lean towards protecting authors. Anthropic positions itself ethically (respects `robots.txt`, focuses on minimal impact), but even they face accusations of excessive crawling. Solutions on the horizon: **GDPR-like regulations** (EU AI Act), the proposed **llms.txt standard** for clear permissions, and **"pay per crawl"** from Cloudflare, where sites can monetize access. AI bot blocking has increased—Cloudflare blocks billions of requests since July 2025. ⚠️
I think the main challenge is finding a **balance between AI innovation and creators' rights**. Without ethical standards, the web will become more closed, and AI—biased due to a lack of data. For developers, I believe it's time to implement control tools! Next—technical solutions. 🛡️
🛡️ Section 7: Technical Problems and Solutions
🛡️ The **technical problems** of AI crawling in 2025 are not abstract theory, but a real threat to servers and infrastructure: bots generate massive traffic that **overloads resources**, **distorts analytics**, and **increases costs**. According to Forum One, AI crawlers often bypass caches, ignore `robots.txt` (13.26% of requests in Q2 2025), spoof user-agents, and attack `sitemap.xml` or search pages, leading to **slowed performance**, server timeouts, and rising hosting bills—up to **30 TB of traffic per month** from a single bot! Imagine: on government sites (.gov), this causes operational failures, and logs are a chaos of thousands of requests/min, complicating the monitoring of real traffic. Cloudflare logs billions of blocked requests daily, with peaks up to 39k/min from real-time fetchers. 🚨
**Main Problems in Detail** 😩
1) **Resource Overload**: AI bots, like GPTBot or Meta-ExternalAgent, make parallel requests without pauses, bypassing caches and generating up to 50 billion requests/day globally. The result—higher CPU/memory usage, slower loading for users, and traffic costs (e.g., AWS bills rising by 20–50%). 2) **Log and Analytics Chaos**: Requests are masked as "human" (Mozilla/5.0), distorting Google Analytics—up to **80% of "traffic" from bots**, falsifying metrics. 3) **Security and Availability**: Bots ignore authentication, attack dynamic content (JS), leading to **DDoS-like effects** without malice. In 2025, 5.6 million sites blocked GPTBot in `robots.txt`—a 70% increase since July.
My assumption—**Solutions: From Basic to Innovative** 🔧
I believe that to regain control, you should follow step-by-step strategies based on 2025 official recommendations. Start simple, move to advanced.
**1. Robots.txt for Basic Blocking** 📜
The standard tool: add a `robots.txt` file with rules to the root of the site. Example for GPTBot (OpenAI):
User-agent: GPTBot
Disallow: /
Or for ClaudeBot (Anthropic):
User-agent: ClaudeBot
Disallow: /
GPTBot officially respects this (user-agent: "Mozilla/5.0 (compatible; GPTBot/1.3; +https://openai.com/gptbot)"), with IP ranges at
openai.com/gptbot.json. For a complete list of 20+ AI crawlers (Amazonbot, CCBot, etc.)—check the
Playwire guide. Tip: update weekly, as bots evolve; incompatibility can become an argument in court (as in the Reddit vs. Anthropic case).
**2. Cloudflare AI Crawl Control — Selective Control** ☁️
Since July 2025, Cloudflare blocks AI crawlers by default for 1+ million clients (with one click in the dashboard). Features: distinction by purpose (training vs. inference/RAG), **whitelist for "good" bots** (Googlebot), and traffic monitoring. Step-by-step: 1) Enable in Security > Bots; 2) Select "Block AI Training" for GPTBot; 3) Allow real-time for ChatGPT. This **reduces traffic by 80%** without search loss.
**3. Pay per Crawl — Monetizing Access** 💰
A new Cloudflare feature (beta since July 2025): set a price per zone (e.g., $0.01/request). A bot without payment receives **HTTP 402 Payment Required** with details. Cloudflare acts as the "Merchant of Record" to process payments, allowing you to earn from data. Example: publishers set rates, AI companies (OpenAI, Meta) pay or leave. According to Cloudflare Docs, this is the third way after "allow/block"—already used by major media. Alternative: Really Simple Licensing (RSL) in `robots.txt` for pay-per-crawl or pay-per-inference.
**4. Additional Tools: Traps and Optimization** 🕸️
AI Labyrinth (or similar "traps" from Cloudflare/WAF)—generate fake content for violators, consuming their resources. **Block at the edge**: Cloudflare WAF, Akamai, or Anubis for filtering by IP/user-agent. Recommendation: **optimize structured data (Schema.org)** for AI-friendly content—bots understand better, and you control what to index. Cache dynamic content, whitelist high-value pages. For .gov—combine with authentication. 🔒
My opinion—these solutions give power back to the owners: from free blocking to earning. I think you should start with `robots.txt` and Cloudflare and monitor the logs. Next—the future! 🔮
🔮 Section 8: The Future of Crawling
🌟 In 2025, we are already seeing the first steps towards **controlled crawling**: Pay per Crawl from Cloudflare, direct publisher deals with OpenAI and Google, and new standards like RSL and `llms.txt`. By 2030, the situation will change dramatically: **autonomous AI agents** (Gartner predicts 33% of enterprise software will use agentic AI by 2028) will negotiate data access, and **federated learning** will allow models to update without full content copying.
**Key Trends:**
* AI search (Overviews, chatbots) will take up to **75% of query traffic** by 2028 (Semrush).
* **Regulations will tighten**: The EU AI Act demands transparency, and the US is moving towards new data laws.
* **Partnerships will become the norm**: Major media outlets are already earning millions from content licenses.
* **Monetization**: Pay-per-crawl and licensing will extend to medium-sized sites.
**Recommendations Starting Today:**
Add **structured data (Schema.org)**, implement **llms.txt/RSL**, and connect **Cloudflare Pay per Crawl**. For sites: create an `/ai-policy`, state access terms, and set a price. **Protect and monetize your content now**—in 2–3 years, this will be standard.
The future is in transparent and mutually beneficial crawling, where sites become **AI partners**, not just data sources. Your content is worth money—it's time to start earning it! 🌟
❓ Frequently Asked Questions (FAQ)
✅ Conclusions
I think, from my experience, crawling in the AI era is a true **revolution**: from passive scanning for search, we have moved to active "**learning**" by machines from our content. In 2025, the key to survival is **balance**: allow ethical bots, block violators, and most importantly, **start monetizing your data**.
For developers, bloggers, and site owners, I consider this especially important: **adapt now**. Add structured data (Schema.org), update `robots.txt`, connect Cloudflare AI Crawl Control and Pay per Crawl. Start monitoring traffic through **Cloudflare Radar**—it's free and will show you exactly who is "eating" your content.
You can read more about implementing structured data for Rich Snippets here.
The future, in my opinion, belongs to those who **control their data**, not those who give it away for free. Your content is valuable, and it's time to make AI pay for it. Thank you for reading! 🚀
🔥 Recommended Articles for Further Reading
Liked the article? Here's a selection of materials to help you stay up-to-date with the new realities of search and AI:
Subscribe to the blog to not miss new publications about AI, SEO, and digital marketing! 🚀
Vadim Kharovyiuk
☕ Java Developer, Founder of WebCraft Studio