Im Jahr 2025 stöhnen Ihre Server unter dem Ansturm unsichtbarer Gäste – KI-Bots, die Inhalte schneller verschlingen, als Sie robots.txt sagen können. Diese digitalen Reisenden scannen nicht nur Seiten, sie lernen von ihnen und generieren Antworten, ohne dass auf Ihre Website geklickt wird. Das Problem? Publisher verlieren Traffic, und KI-Unternehmen – Daten für Modelle. Spoiler: Die neue Erklärung des Crawlings ist die semantische Analyse zum Trainieren von LLMs, wobei Ethik und Kontrolle zum Schlüssel für das Überleben des Web-Ökosystems werden.
⚡ Zusammenfassung
- ✅ Kerngedanke 1: KI-Crawler sind nicht nur Bots, sondern Lernende, die Daten für ChatGPT und Claude sammeln und 2025 über 50 % des Web-Traffics generieren.
- ✅ Kerngedanke 2: Unterschied zum Traditionellen: Fokus auf Modelltraining statt Suche, mit minimalen Rückverweisen.
- ✅ Kerngedanke 3: Herausforderungen: Serverüberlastung und Ethik; Lösungen – AI Crawl Control von Cloudflare und Pay-per-Crawl.
- 🎯 Sie erhalten: ein tiefes Verständnis der Mechanismen, Statistiken für 2025 und praktische Empfehlungen für Websites.
- 👇 Lesen Sie unten mehr – mit Beispielen und Schlussfolgerungen
Inhalt des Artikels:
⸻
🎯 Abschnitt 1: Einführung in das Crawling im Zeitalter der KI
🕵️♂️ „KI-Crawler sind keine Diebe, sondern Schüler, die ihre Hausaufgaben aus dem Internet kopieren, ohne um Erlaubnis zu fragen.“ Cloudflare Radar, 2025.
🕸️ Crawling ist das automatisierte Scannen von Websites durch Bots zum Sammeln von Daten, als ob unsichtbare Spinnen ein Wissensnetzwerk im gesamten Internet spinnen würden. 🌐 In der traditionellen Welt diente dies Suchmaschinen wie Googlebot dazu, Seiten zu indexieren und Traffic auf Websites zurückzuleiten, wo Publisher mit Werbung und Klicks Geld verdienten. 💰 Doch im Zeitalter der KI hat sich alles grundlegend geändert: Bots wie GPTBot (von OpenAI) und ClaudeBot (von Anthropic) indexieren nicht nur – sie analysieren tiefgreifend Semantik, Kontext, emotionalen Ton und trainieren große Sprachmodelle (LLMs), wodurch Ihr einzigartiger Inhalt zu Treibstoff für ChatGPT oder Claude wird. 🔥📈
Laut aktuellen Daten von Cloudflare Radar AI Insights stieg das KI-Crawling im Juni 2025 um 24 % im Jahresvergleich und erreichte beeindruckende 80 % des gesamten KI-Bot-Traffics, bevor es im Juli aufgrund neuer Regulierungen auf 4 % zurückging. Dies ist die „neue Erklärung“ des Crawlings: Der Prozess ist wirklich intelligent und semantisch geworden, wobei Maschinen nicht nur Daten sammeln, sondern auch von ihnen lernen und Antworten generieren, ohne dass auf Ihre Website geklickt wird – also ohne Belohnung in Form von Traffic oder Einnahmen. Stellen Sie sich vor: Ihre Artikel, Blogs oder Nachrichten „leben“ in den KI-Antworten, aber Sie sehen keinen einzigen Besucher! 😲
Warum ist das gerade jetzt relevant? Cloudflare hat ab dem 1. Juli standardmäßig die Blockierung von KI-Crawlern für Millionen von Websites eingeführt, wodurch Website-Betreiber den Zugriff kontrollieren und Inhalte sogar über „Pay-per-Crawl“ monetarisieren können. Betrachten wir die Evolution Schritt für Schritt, um zu verstehen, wie wir von einfachen Suchmaschinen-Bots zu den ethischen Dilemmata der künstlichen Intelligenz gelangt sind. 🚀
📚 Abschnitt 2: Traditionelles Crawling – Grundlagen
„Crawling ist wie ein Bibliothekar, der Bücher für eine schnelle Suche sortiert.“ — Klassische Definition von Google Search Central.
📖 **Traditionelles Crawling** ist ein grundlegender Prozess, der mit den frühen Suchmaschinen in den 1990er Jahren begann und bis heute die Grundlage für die Indexierung von Webinhalten bildet.
**Bots** 🤖, wie der Googlebot oder Bingbot, starten mit einer „**Seed-URL**“ 🌱 – einer anfänglichen Liste bekannter Adressen (z. B. beliebte Websites oder Sitemaps) – und folgen Links 🔗, wodurch ein Baum von Entdeckungen entsteht. Sie extrahieren Schlüsselwörter 🔑, Meta-Tags, die HTML-Struktur und führen sogar **JavaScript** 🖥️ zur Darstellung dynamischer Inhalte aus, wie in der Google-Dokumentation beschrieben. Das Ziel ist einfach: einen riesigen **Index** 🗄️ für relevante Suchergebnisse zu erstellen, wobei jeder Klick zurück zur Website führt und Einnahmen aus Werbung oder Traffic generiert 💰. 🔄
Stellen Sie sich vor: Der Googlebot 🟢, mit dem User-Agent "Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)", scannt Seiten und bewertet deren Aktualität und Relevanz. Der Bingbot 🔵, analog dazu, mit "Mozilla/5.0 (compatible; bingbot/2.0; +http://www.bing.com/bingbot.htm)", indexiert für Bing, das einen globalen Suchanteil von $\sim$$\text{4\%}$ hat.
Laut Daten von 2025 dominiert der Googlebot mit 89,6 % des Suchmarktes 👑 und scannt täglich Hunderte Milliarden Seiten – etwa ein Drittel des bekannten Webs. Beispiel: Auf einer durchschnittlichen Website führt der Googlebot in 62 Tagen 2741 Anfragen durch 📈, während der Bingbot 4188 📉 durchführt, was die Intensität der Arbeit demonstriert. Dies ist kein Chaos, sondern ein kontrollierter Prozess: Bots respektieren robots.txt 🛑, begrenzen die Anfragehäufigkeit (Googlebot – nicht mehr als ein paar Sekunden zwischen Anfragen) ⏱️ und konzentrieren sich seit 2020 auf die **mobile Version des Inhalts** 📱. 📊
Im Jahr 2025 bleibt das traditionelle Crawling stabil, macht aber nur 20-30 % der gesamten Bot-Aktivität aus, da **KI-Bots** 🧠 80 % des KI-Crawler-Traffics übernehmen. Insgesamt generieren Bots 49,6 % des Internet-Traffics 🕸️, wobei traditionelle Crawler als „**gute**“ Bots die Sichtbarkeit fördern. Dies ist eine **Symbiose**: Websites erhalten Sichtbarkeit in der Suche 👀 (Googlebot ist seit 2024 um 96 % gewachsen), Suchmaschinen – Daten für Algorithmen. Doch das Aufkommen der KI 🤖 bricht dieses Modell auf, indem es das Crawling von „Zurückverlinkung“ in „**Lernen ohne Belohnung**“ 🎁❌ verwandelt. Wir gehen im nächsten Abschnitt zur Evolution über. 🔍
🔄 Abschnitt 3: Evolution zu KI-Crawlern
„Von Schlüsselwörtern zur Semantik: KI verwandelt Crawling in Lernen.“ — Inspiriert von den Trends 2025 von Vercel und Cloudflare.
🔄 Gehen wir zurück, um den Unterschied besser zu verstehen: **Wie war es früher** mit dem traditionellen Crawling? Stellen Sie sich das Internet der 2010er- bis 2020er-Jahre vor: Bots wie Googlebot oder Bingbot scannten das Web hauptsächlich zur Indexierung – sie sammelten Schlüsselwörter, Links, Meta-Tags und eine einfache HTML-Struktur. Sie ignorierten oft dynamische JavaScript-Inhalte (da sie diese für Google bis 2019 nicht vollständig renderten), konzentrierten sich auf Volumen und Geschwindigkeit und vor allem – sie leiteten Traffic über die Suchergebnisse zurück. Es war eine Symbiose: Websites erhielten Besucher, Suchmaschinen – Daten. Ein Klick auf einen Link in Google brachte Werbeeinnahmen, und das Crawl-to-Refer-Verhältnis (Verhältnis von Crawling zu Referrals) war vorteilhaft – zum Beispiel crawlt Google ~14 Seiten pro 1 Referral. 📊
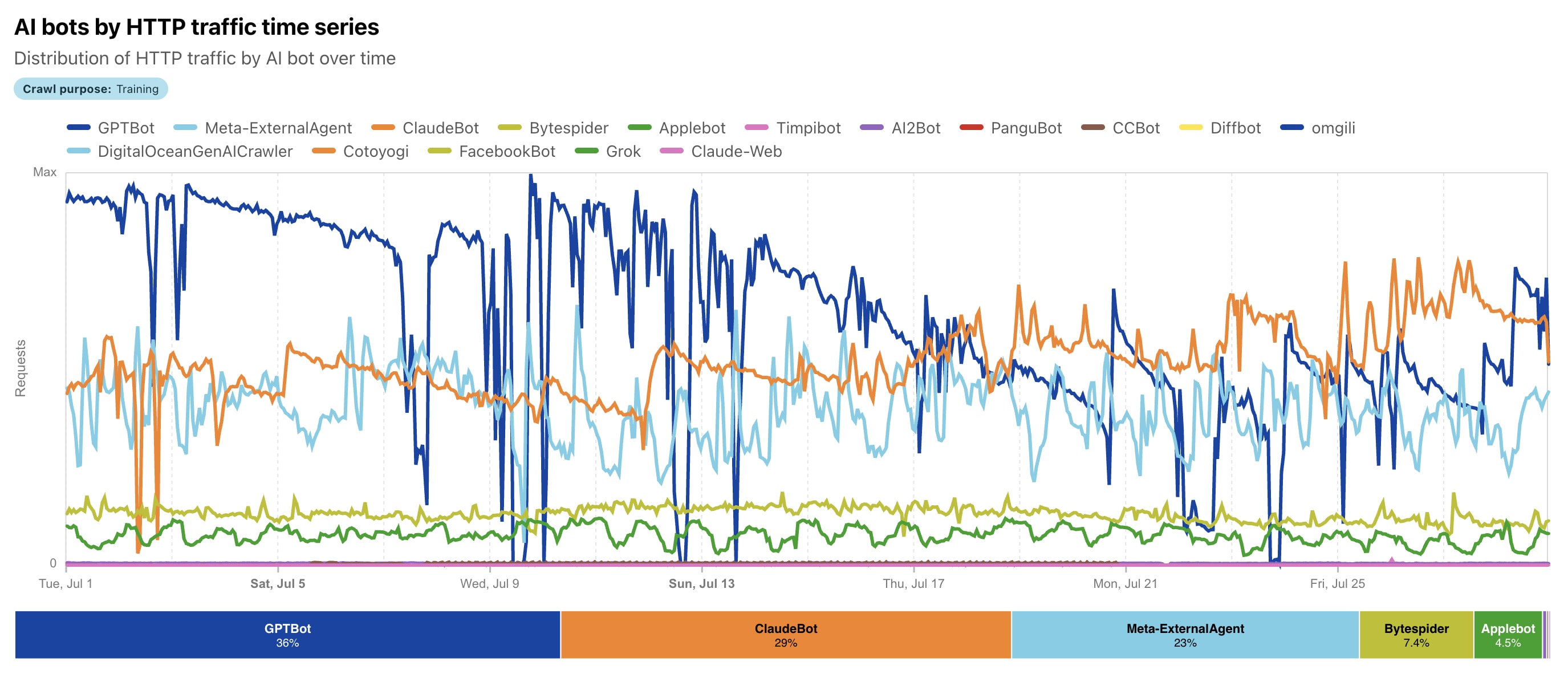
Doch seit 2023 hat sich alles mit dem Boom der generativen KI beschleunigt: Die Evolution ging von einfachen Suchmaschinen-Bots zu echten **KI-Agenten** über, die NLP (Natural Language Processing) nutzen, um Kontext, Semantik, Textstimmung und sogar visuelle Inhalte tiefgreifend zu verstehen. Laut Daten von Cloudflare hat sich das KI-Crawling von Mai 2024 bis Mai 2025 radikal verändert: GPTBot (OpenAI) stieg mit **30 % Anteil** (ein Anstieg von 5 %) an die Spitze, Meta-ExternalAgent (Meta) debütierte mit 19 %, während der frühere Marktführer Bytespider (ByteDance) von 42 % auf 7 % fiel. ClaudeBot (Anthropic) konzentriert sich auf die ethische Datenerfassung für das Claude-Modell, und das gesamte KI-Crawling ist um Dutzende von Prozent gestiegen. 🚀
Der entscheidende **Unterschied**, damit Sie den Unterschied klar erkennen: Traditionelle Bots (wie Googlebot) ignorierten oder verarbeiteten JS-Inhalte oft schlecht, sammelten Daten für die Suche und leiteten Traffic zurück. KI-Crawler rendern dynamische Inhalte (obwohl sie JS laut Vercel nicht immer perfekt ausführen), priorisieren Qualität und Relevanz für das LLM-Training, aber... sie leiten fast keine Klicks zurück! Das Ergebnis ist die Sammlung für das Training großer Sprachmodelle (LLMs), RAG (Retrieval Augmented Generation) und Echtzeit-Antworten in ChatGPT oder Claude. Die Evolution geht weiter: Im Jahr 2025 führt Meta in einigen Segmenten (bis zu 52 % laut anderen Cloudflare-Berichten), und der gesamte KI-Bot-Traffic erreicht 80 % der Bot-Aktivität. Dies ist nicht nur Scannen – es ist „Lernen“ aus Ihren Inhalten ohne die alte Belohnung. 📈😲
📖 Lesen Sie auch in unserem Blog
Wenn Sie das Thema KI-Crawling interessiert, finden Sie hier einige verwandte Artikel, die Ihnen helfen, sich tiefer mit modernem SEO und der Interaktion mit künstlicher Intelligenz auseinanderzusetzen:
Diese Materialien ergänzen ideal das Verständnis, wie sich das Web im Jahr 2025 verändert. 📈
⚙️ Kapitel 4: Funktionsweise von KI-Crawlern
🤖 KI-Crawling ist nicht nur ein mechanisches Scannen wie bei traditionellen Bots, sondern ein komplexer, "intelligenter" Prozess, der auf die Sammlung hochwertiger Daten für das Training großer Sprachmodelle (LLM) und Echtzeit-Antworten ausgerichtet ist. Im Gegensatz zum Googlebot, der für die Suche indiziert, konzentrieren sich KI-Crawler wie GPTBot oder ClaudeBot auf das semantische Verständnis von Inhalten: Sie extrahieren Text, analysieren Kontext, Stimmungen und Relevanz, um Modelle wie ChatGPT oder Claude zu verbessern. Laut Cloudflare 2025 macht das Trainings-Crawling fast 80 % des gesamten KI-Bot-Traffics aus, mit führenden Crawlern wie GPTBot (bis zu 30 % Anteil) und Meta-ExternalAgent (bis zu 52 % in einigen Segmenten). Wir werden den Prozess Schritt für Schritt aufschlüsseln – das ist die "neue Erklärung" des Crawlings im Zeitalter der KI. 🔍
Schritt 1: Entdeckung (Discovery) 🚀
Alles beginnt mit einer "Seed-URL" – einer anfänglichen Liste bekannter Adressen (beliebte Websites, Sitemaps, Links aus früheren Crawls). Bei KI-Crawlern kommen jedoch intelligente Filter hinzu: NLP-Modelle bewerten Relevanz und Qualität des Inhalts im Voraus und priorisieren textbasiertes, lehrreiches oder strukturiertes Material. Zum Beispiel suchen GPTBot (User-agent: GPTBot/1.0) und ClaudeBot (User-agent: ClaudeBot/1.0) nach öffentlich zugänglichen Inhalten ohne Paywall oder Logins. Sie respektieren robots.txt (z.B. blockiert Disallow: / den Zugriff), können aber CAPTCHA oder andere Barrieren ignorieren, wenn nichts Gegenteiliges angegeben ist. Im Jahr 2025 wurde die Entdeckung effizienter: Bots vermeiden minderwertige Seiten und konzentrieren sich auf Daten für LLMs.
Schritt 2: Datenerfassung (Fetching) 📥
Der Bot sendet HTTP-Anfragen und identifiziert sich über den User-Agent (z.B. "Mozilla/5.0 (compatible; GPTBot/1.0; +https://openai.com/gptbot)"). Er lädt HTML herunter, rendert teilweise dynamische Inhalte (führt jedoch im Gegensatz zum Googlebot nicht immer JavaScript vollständig aus), extrahiert Text, Bilder, PDFs und sogar Metadaten. GPTBot sammelt für das Training zukünftiger Modelle (GPT-5+), ClaudeBot für die Aktualisierung von Claude, wobei der Fokus auf ethischen und vielfältigen Inhalten liegt. Laut Vercel und Cloudflare generieren KI-Crawler Milliarden von Anfragen: GPTBot – Hunderte Millionen pro Monat, mit Spitzen von Zehntausenden Anfragen pro Minute auf beliebten Websites. Sie sind parallel skalierbar, versuchen aber, "wohlverhaltend" zu sein – sie begrenzen die Geschwindigkeit, um Server nicht zu überlasten.
Schritt 3: Parsing und semantische Analyse (Parsing & Semantic Analysis) 🧠
Hier geschieht die Magie: Der extrahierte Inhalt wird mittels NLP für das semantische Verständnis geparst – Analyse von Stimmung, Absicht, Entitäten und Kontext. Bots filtern Boilerplate (Werbung, Navigation), extrahieren reinen Text und bewerten die Nützlichkeit für das Training. Zum Beispiel priorisiert ClaudeBot Bildungsinhalte, GPTBot – vielfältige Quellen zur Verbesserung der Antwortgenauigkeit. Die Daten werden in RAG (Retrieval Augmented Generation) für Echtzeit-Anfragen oder in Trainings-Datensätze integriert. Das ist der entscheidende Unterschied: nicht nur Indizierung, sondern das "Lernen" des Modells anhand Ihrer Inhalte!
Schritt 4: Skalierung und Speicherung (Scaling & Storage) ⚡
Der Prozess wiederholt sich massiv: parallele Anfragen von verschiedenen IPs (oft aus Clouds wie AWS/Azure), unter Beachtung des Crawl-Delays in robots.txt. Im Jahr 2025 ist der Traffic explosiv – Meta-Bots generieren bis zu 52 % des KI-Crawl-Traffics, GPTBot ist um 305 % gestiegen. Daten werden für Offline-Training oder Online-RAG gespeichert. Beispiele: ClaudeBot sammelt für das ethische Training von Claude, wobei der Fokus auf qualitativ hochwertigen Inhalten liegt; GPTBot – für die massive Verbesserung von ChatGPT. Das ist die "neue Erklärung": Crawling ist zu einem Prozess des maschinellen Lernens geworden, nicht nur der Suche. 🤖🌟
📊 Kapitel 5: Statistiken und Traffic-Auswirkungen 2025
📊 Im Jahr 2025 hat sich der Bot-Traffic zu einem wahren "stillen Ameisenhaufen" des Internets entwickelt, in dem automatisierte Agenten den menschlichen Traffic in Volumen und Einfluss übertreffen. Laut Cloudflare Radar machen Bots etwa 30 % des globalen Web-Traffics aus, wobei KI-Crawler als neue dominierende Kraft bis zu 80 % der gesamten KI-Bot-Aktivität generieren. Fastly verzeichnet in seinem Q2 Threat Insights Report eine noch höhere Zahl: KI-Crawler – fast 80 % des KI-Bot-Traffics, wobei "schlechte" Bots (einschließlich nicht autorisiertem Scraping) 37 % des gesamten Traffics ausmachen. Stellen Sie sich vor: Von 6,5 Billionen Anfragen pro Monat über Fastly gehen Milliarden an das Training von LLMs, überlasten Server und verzerren die Analysen. Das sind nicht nur Zahlen – das ist eine Krise für Websites, bei denen Daten "einseitig" fließen. 📉
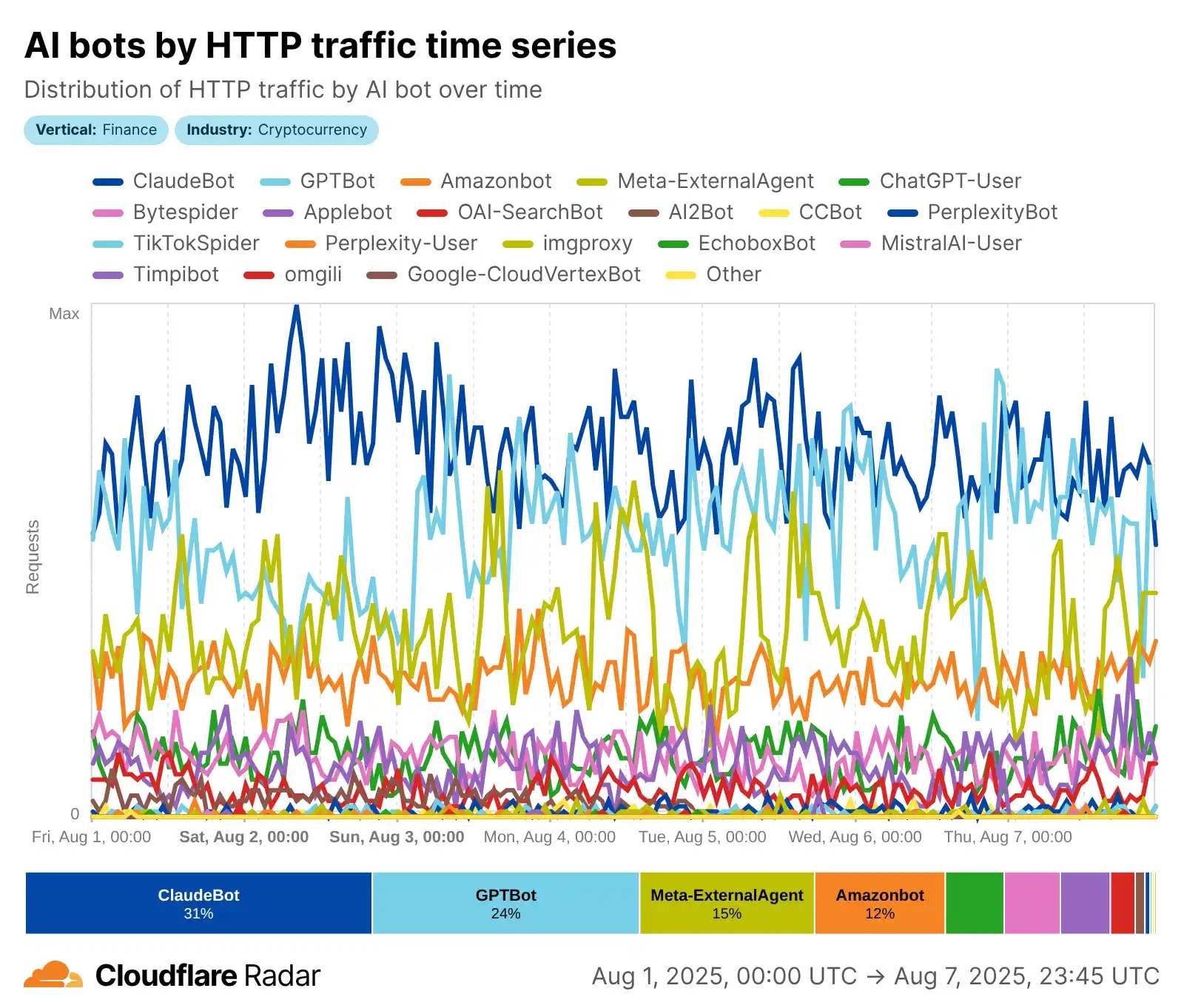
Betrachten wir die Schlüsselindikatoren: Der gesamte Bot-Traffic erreicht 49,6–51 % des Internets (laut Thunderbit 2025), wobei KI-Crawler der Haupttreiber des Wachstums sind. Die Spitzenreiter? Meta-Bots generieren 52 % des KI-Crawl-Traffics, Google – 23 %, OpenAI – 20 %, während Anthropic (ClaudeBot) bei 3,76 % liegt, mit einem Fokus auf Ethik. GPTBot ist von Mai 2024 bis 2025 um 305 % gestiegen, ClaudeBot – um das Doppelte (auf 10 %), und ByteDance's Bytespider ist aufgrund von Regulierungen von 14,1 % auf 2,4 % gefallen. Cloudflare verzeichnet 50 Milliarden Anfragen pro Tag von KI, mit Spitzen von bis zu 39 Tausend Anfragen/Min von einem Fetcher (Echtzeit-Antworten) und 1 Tausend von einem Crawler – das ist ein DDoS-ähnlicher Effekt ohne böswillige Absicht! 🚨
Auswirkungen auf den Traffic: Von Überlastung bis zu Verlusten 😩
Für Websites ist dies ein doppelter Schlag: Serverüberlastung (bis zu 30 TB/Monat von einem Bot) und ein niedriges Crawl-to-Click-Verhältnis – die KI gibt den Traffic nicht zurück. Laut Cloudflare macht das Trainings-Crawling 79–80 % der KI-Aktivität aus (ein Anstieg von 72 % im Jahr 2024), mit Referrals von 70.900:1 für Anthropic (71 Tausend Crawls pro 1 Klick!) oder 887:1 für OpenAI. In den Nachrichten fielen die Referrals von Google im März 2025 um 9 %, und der Gesamt-CTR sinkt um 61 % für organische und 68 % für bezahlte Ergebnisse aufgrund von AI Overviews (Seer Interactive, September 2025). Auch ohne AIO: organischer CTR -41 %, bezahlter -20 %. Beispiel: Für Informationsanfragen mit AIO fiel der CTR von 1,76 % auf 0,61 %, Impressions steigen (+27 %), aber Klicks fallen (-36 %). Publisher verlieren 10–25 % des Traffics im Jahresvergleich, mit einem Rückgang von bis zu 64 % bei Schlüsselwörtern. Für KI ist dies eine "Goldgrube" an Daten, aber für Unternehmen – eine Erosion der Werbeeinnahmen. 🌐
Wachstumskurve: Explosion und Stabilisierung 📈
Von Mai 2024 bis Mai 2025 stieg der KI-Traffic insgesamt um 18 %, mit +32 % im Jahresvergleich im April 2025 (Spitze), +24 % im Juni und einer Verlangsamung auf +4 % im Juli aufgrund von Blockierungen (Cloudflare blockiert ab dem 1. Juli standardmäßig). In Nachrichten/Medien: 37 von 50 Top-Websites in den USA fielen im Jahresvergleich um 27–38 %. Regional: 90 % des KI-Crawl-Traffics in Nordamerika, weniger in Europa (41 %) und Asien (58 %) – Datenverzerrung! Prognose: Bis Ende 2025 werden Bots 51 % erreichen, mit KI bei 80 %+, was neue Tools wie AI Crawl Control erfordert. Das ist die "neue Erklärung" der Auswirkungen: Crawling nährt Websites nicht, sondern erschöpft sie. Als Nächstes – Ethik. ⚖️
⚖️ Kapitel 6: Ethische Herausforderungen
"Ohne Zustimmung – keine Daten: Die Ethik des Crawlings im Zeitalter der KI." – Inspiriert von den Prinzipien von Anthropic und den Diskussionen des Jahres 2025.
⚖️ Die ethischen Herausforderungen des KI-Crawl-Traffics sind eines der drängendsten Probleme des Jahres 2025: Unternehmen wie OpenAI, Anthropic und Meta sammeln Daten ohne ausdrückliche Zustimmung der Eigentümer, verletzen Urheberrechte und entschädigen die Urheber nicht. Stellen Sie sich vor: Ihr Inhalt wird zum Training von LLMs verwendet, generiert Milliarden an Gewinn, aber Sie erhalten keinen Cent und keinen Traffic zurück – die Referrals sind mager (z.B. erreicht bei Anthropic das Crawl-to-Refer-Verhältnis 70.900:1 laut Cloudflare). Dies bricht das traditionelle Modell "Inhalt gegen Traffic", bei dem Publisher Einnahmen aus Werbung und Abonnements verlieren. 😔
Schlüsselprobleme: nicht autorisiertes Scraping (sogar die Ignorierung von robots.txt durch einige Bots), mangelnde Transparenz und fehlende Kompensation. Im Jahr 2025 explodierten Klagen – von der New York Times gegen Perplexity wegen des Kopierens von Millionen von Artikeln bis zu Disney/Universal gegen Midjourney wegen der Verwendung von Charakteren. Viele Fälle konzentrieren sich darauf, ob es sich um "Fair Use" für das Training handelt, aber Gerichte neigen oft dazu, die Urheber zu schützen. Anthropic positioniert sich ethisch (respektiert robots.txt, Fokus auf minimalen Einfluss), aber selbst sie sehen sich Vorwürfen über exzessives Crawling gegenüber. Lösungen am Horizont: DSGVO-ähnliche Regulierungen (EU AI Act), der vorgeschlagene llms.txt-Standard für klare Berechtigungen und "Pay per Crawl" von Cloudflare, wo Websites den Zugriff monetarisieren können. Die Blockierung von KI-Bots ist gestiegen – Cloudflare blockiert seit Juli 2025 Milliarden von Anfragen. ⚠️
Ich denke, die größte Herausforderung besteht darin, ein Gleichgewicht zwischen KI-Innovationen und den Rechten der Urheber zu finden. Ohne ethische Standards wird das Web geschlossener und die KI – voreingenommen durch Datenmangel. Für Entwickler halte ich es für an der Zeit, Kontrollwerkzeuge einzuführen! Als Nächstes – technische Lösungen. 🛡️
🛡️ Kapitel 7: Technische Probleme und Lösungen
🛡️ Die technischen Probleme des KI-Crawl-Traffics im Jahr 2025 sind keine abstrakte Theorie, sondern eine reale Bedrohung für Server und Infrastruktur: Bots generieren massiven Traffic, der Ressourcen überlastet, Analysen verzerrt und Kosten erhöht. Laut Forum One umgehen KI-Crawler oft Caches, ignorieren robots.txt (13,26 % der Anfragen im Q2 2025), spoofen User-Agents und greifen sitemap.xml oder Suchseiten an, was zu Leistungseinbußen, Server-Timeouts und steigenden Hosting-Rechnungen führt – bis zu 30 TB Traffic pro Monat von einem Bot! Stellen Sie sich vor: Auf Regierungswebsites (.gov) führt dies zu Betriebsstörungen, und in den Logs herrscht Chaos mit Tausenden von Anfragen/Min, was die Überwachung des realen Traffics erschwert. Cloudflare verzeichnet täglich Milliarden blockierter Anfragen, mit Spitzen von bis zu 39 Tausend/Min von Echtzeit-Fetchern. 🚨
Hauptprobleme im Detail 😩
1) **Ressourcenüberlastung**: KI-Bots wie GPTBot oder Meta-ExternalAgent stellen parallele Anfragen ohne Pausen, umgehen Caches und generieren global bis zu 50 Milliarden Anfragen/Tag. Das Ergebnis – höhere CPU/Speicher, langsamere Ladezeiten für Benutzer und Traffic-Kosten (z.B. steigen AWS-Rechnungen um 20–50 %). 2) **Chaos in Logs und Analysen**: Anfragen werden als "menschlich" getarnt (Mozilla/5.0), was Google Analytics verzerrt – bis zu 80 % des "Traffics" von Bots, was Metriken fälscht. 3) **Sicherheit und Verfügbarkeit**: Bots ignorieren Authentifizierung, greifen dynamische Inhalte (JS) an, was zu DDoS-ähnlichen Effekten ohne böswillige Absicht führt. Im Jahr 2025 blockierten 5,6 Millionen Websites GPTBot in robots.txt – ein Anstieg von 70 % seit Juli.
Meine Annahme – Lösungen: von grundlegend bis innovativ 🔧
Ich bin der Meinung, dass man, um die Kontrolle zurückzugewinnen, schrittweise Strategien auf der Grundlage der offiziellen Empfehlungen von 2025 befolgen sollte. Beginnen Sie mit dem Einfachen, gehen Sie zum Fortgeschrittenen über.
1. Robots.txt für grundlegende Blockierung 📜
Standardwerkzeug: Fügen Sie eine robots.txt-Datei mit Regeln im Stammverzeichnis der Website hinzu. Beispiel für GPTBot (OpenAI):
User-agent: GPTBot
Disallow: /
Oder für ClaudeBot (Anthropic):
User-agent: ClaudeBot
Disallow: /
GPTBot respektiert dies offiziell (User-Agent: "Mozilla/5.0 (compatible; GPTBot/1.3; +https://openai.com/gptbot)"), mit IP-Bereichen auf
openai.com/gptbot.json. Für eine vollständige Liste von über 20 KI-Crawlern (Amazonbot, CCBot usw.) – konsultieren Sie den
Playwire-Leitfaden. Tipp: Wöchentlich aktualisieren, da Bots sich weiterentwickeln; Inkompatibilität kann ein Argument vor Gericht werden (wie im Fall Reddit vs. Anthropic).
2. Cloudflare AI Crawl Control – selektive Kontrolle ☁️
Ab Juli 2025 blockiert Cloudflare KI-Crawler standardmäßig für über 1 Million Kunden (mit einem Klick im Dashboard). Features: Unterscheidung nach Zweck (Training vs. Inferenz/RAG), Whitelist für "gute" Bots (Googlebot) und Traffic-Monitoring. Schritt für Schritt: 1) Aktivieren Sie unter Security > Bots; 2) Wählen Sie "Block AI Training" für GPTBot; 3) Erlauben Sie Echtzeit für ChatGPT. Dies reduziert den Traffic um 80 % ohne Verluste bei der Suche.
3. Pay per Crawl – Monetarisierung des Zugriffs 💰
Neues Feature von Cloudflare (Beta ab Juli 2025): Legen Sie einen Preis pro Zone fest (z.B. $0,01/Anfrage). Ein Bot ohne Bezahlung erhält HTTP 402 Payment Required mit Details. Cloudflare als "Merchant of Record" verarbeitet Zahlungen und ermöglicht es, mit Daten Geld zu verdienen. Beispiel: Publisher legen Tarife fest, KI-Unternehmen (OpenAI, Meta) zahlen oder gehen. Laut Cloudflare Docs ist dies der dritte Weg nach "allow/block" – bereits von großen Medien genutzt. Alternative: Really Simple Licensing (RSL) in robots.txt für Pay-per-Crawl oder Pay-per-Inference.
4. Zusätzliche Tools: Fallen und Optimierung 🕸️
AI Labyrinth (oder ähnliche "Fallen" von Cloudflare/WAF) – generieren gefälschte Inhalte für Übeltäter, um deren Ressourcen zu verbrauchen. Am Edge blockieren: Cloudflare WAF, Akamai oder Anubis zur Filterung nach IP/User-Agent. Empfehlung: Strukturierte Daten (Schema.org) für KI-freundliche Inhalte optimieren – Bots verstehen besser, und Sie kontrollieren, was indiziert wird. Dynamische Inhalte cachen, hochwertige Seiten whitelisten. Für .gov – mit Authentifizierung kombinieren. 🔒
Meine Meinung – diese Lösungen geben den Eigentümern die Macht zurück: von kostenloser Blockierung bis zum Verdienen. Ich denke, es lohnt sich, mit robots.txt und Cloudflare zu beginnen und die Logs zu überwachen. Als Nächstes – die Zukunft! 🔮
🔮 Kapitel 8: Die Zukunft des Crawlings
🌟 Im Jahr 2025 sehen wir bereits die ersten Schritte zu einem kontrollierten Crawling: Pay per Crawl von Cloudflare, direkte Vereinbarungen von Publishern mit OpenAI und Google, neue Standards wie RSL und llms.txt. Bis 2030 wird sich die Situation grundlegend ändern: Autonome KI-Agenten (laut Gartner bis 2028 – 33 % der Unternehmenssoftware mit agentic AI) werden über den Datenzugriff verhandeln, und föderiertes Lernen wird die Aktualisierung von Modellen ohne vollständiges Kopieren von Inhalten ermöglichen.
Schlüsseltrends:
• KI-Suche (Overviews, Chatbots) wird bis 2028 bis zu 75 % des Suchanfragen-Traffics ausmachen (Semrush).
• Regulierungen werden strenger: Der EU AI Act fordert Transparenz, die USA bewegen sich auf neue Datengesetze zu.
• Partnerschaften werden zur Norm: Große Medien verdienen bereits Millionen mit Content-Lizenzen.
• Monetarisierung: Pay-per-Crawl und Lizenzen werden sich auf mittlere Websites ausweiten.
Empfehlungen schon heute:
Fügen Sie strukturierte Daten (Schema.org) hinzu, implementieren Sie llms.txt/RSL, und aktivieren Sie Cloudflare Pay per Crawl. Für Websites: Erstellen Sie eine /ai-policy, geben Sie Zugriffsbedingungen und Preise an. Schützen und monetarisieren Sie Inhalte jetzt – in 2–3 Jahren wird dies Standard sein.
Die Zukunft gehört einem transparenten und für beide Seiten vorteilhaften Crawling, bei dem Websites Partner der KI werden und nicht nur Datenquellen sind. Ihr Inhalt ist Geld wert – es ist Zeit, damit anzufangen, ihn zu verdienen! 🌟
❓ Häufig gestellte Fragen (FAQ)
✅ Fazit
Ich denke, aus meiner Erfahrung ist Crawling im Zeitalter der KI eine echte Revolution: Vom passiven Scannen für die Suche sind wir zum aktiven „Training“ von Maschinen mit unseren Inhalten übergegangen. Im Jahr 2025 ist der Schlüssel zum Überleben das Gleichgewicht: Erlauben Sie ethischen Bots, blockieren Sie Übeltäter und, am wichtigsten, beginnen Sie, Ihre Daten zu monetarisieren.
Für Entwickler, Blogger und Website-Betreiber halte ich dies für besonders wichtig: Passen Sie sich jetzt an. Fügen Sie strukturierte Daten (Schema.org) hinzu, aktualisieren Sie robots.txt, aktivieren Sie Cloudflare AI Crawl Control und Pay per Crawl. Beginnen Sie, den Traffic über Cloudflare Radar zu überwachen – das ist kostenlos und zeigt Ihnen, wer genau Ihre Inhalte „frisst“.
Mehr über die Implementierung strukturierter Daten für Rich Snippets können Sie hier nachlesen.
Die Zukunft gehört meiner Meinung nach denen, die ihre Daten kontrollieren und sie nicht kostenlos abgeben. Ihr Inhalt ist ein Wert, und es ist Zeit, dafür zu sorgen, dass die KI dafür bezahlt. Vielen Dank fürs Lesen! 🚀
🔥 Empfohlene Artikel zum Weiterlesen
Hat Ihnen der Artikel gefallen? Hier ist eine Auswahl an Materialien, die Ihnen helfen, über die neuen Realitäten der Suche und KI auf dem Laufenden zu bleiben:
Abonnieren Sie den Blog, um keine neuen Beiträge über KI, SEO und digitales Marketing zu verpassen! 🚀
Vadim Kharovyuk
☕ Java-Entwickler, Gründer von WebCraft Studio