Ви запитуєте в ChatGPT чи Perplexity складне питання, а AI миттєво дає точну відповідь з посиланнями на джерела. ❓
Але як саме ці платформи вирішують, чий контент цитувати, а чий ігнорувати? У 2025 році це вже не випадковість, а чітка логіка, заснована на якості, структурі та авторитетності.
Спойлер: AI обирає джерела за критеріями E-E-A-T, свіжості, структури (📊 таблиці, 📋 списки, ❓ FAQ) та релевантності — і ви можете оптимізувати свій контент, щоб потрапити в ці цитати. 🚀
⚡ Коротко
- ✅ AI не просто шукає: Використовує RAG-модель для пошуку, фільтрації та генерації на основі найкращих фрагментів.
- ✅ Головні критерії: Авторитетність (E-E-A-T), актуальність, чітка структура та мультимодальність.
- ✅ Улюблені формати: Короткі TL;DR, списки, таблиці, FAQ — вони легко парсяться та цитуються.
- 🎯 Ви отримаєте: Практичні інструменти та поради, щоб ваш контент частіше цитували AI у 2025 році.
- 👇 Нижче — детальні пояснення, приклади та таблиці
📚 Зміст статті
- 📌 Розділ 1. Що таке AI-цитуування і як воно працює
- 📌 Розділ 2. RAG-модель і механізм вибору джерел
- 📌 Розділ 3. Критерії відбору контенту AI
- 📌 Розділ 4. Формати, які AI предпочитає
- 📌 Розділ 5. Помилки, що знижують шанс цитувания
- 💼 Розділ 6. Інструменти для моніторингу цитувания AI
- 💼 Розділ 7. Практичні кейси та приклади
- 💼 Розділ 8. Поради для створення цитованого контенту
- ❓ Часті питання (FAQ)
- ✅ Висновки
🎯 Розділ 1. Що таке AI-цитування і як воно працює
AI-цитування — це процес, коли платформи на кшталт ChatGPT, Gemini або Perplexity обирають і посилаються на фрагменти з надійних джерел для відповідей. 🤖
AI не просто копіює текст з інтернету, а аналізує релевантність, авторитетність та структуру, обираючи найкращі частини для точної та обґрунтованої відповіді. 📚
AI-цитування базується на довірі: платформи прагнуть уникнути «галюцинацій», тому віддають перевагу перевіреним та структурованим джерелам. 🔍
У 2025 році провідні AI-платформи комбінують попередньо навчені великі мовні моделі з механізмами пошуку в реальному часі та ретривалу. 🌐
Perplexity майже повністю покладається на живий веб-пошук із агресивним ретривалом, Gemini глибоко інтегрує структуровані дані з Google Knowledge Graph та індексу пошуку, а ChatGPT (особливо в режимі Search) балансує між внутрішньою базою знань та зовнішніми джерелами через партнерства та власний краулер. 🤖
Ключовим фактором залишається авторитетність за принципом E-E-A-T (Experience, Expertise, Authoritativeness, Trustworthiness). 📚
Алгоритми ранжування джерел враховують наявність авторських біографій із верифікованим досвідом, посилання на першоджерела, прозорість методології та відсутність маніпулятивних практик.
Сайти без чітких сигналів довіри систематично відсіюються на етапі фільтрації, навіть якщо текст релевантний. ✅
- 💻 RAG у краулингу: як Retrieval-Augmented Generation змінює сучасний пошук і SEO
- ⚠️ Галюцинації штучного інтелекту: що це, чому вони небезпечні та як їх уникнути
Чому це важливо
У 2025 році AI-платформи дійсно стали важливим інтерфейсом для доступу до інформації, але не основним для всіх користувачів. 🌐 За даними різних досліджень, Google зберігає близько 90% ринку пошуку, а AI-платформи (включаючи ChatGPT Search та Perplexity) генерують менше 1% глобального веб-трафіку або до 8-15% у певних сегментах. Однак, Google AI Overviews з'являються в 50-60% пошукових запитів у США і мають **2 мільярди** щомісячних користувачів глобально (TechCrunch, Q2 2025).
Якщо ваш контент не потрапляє в цитати AI Overviews (Google), відповіді Perplexity чи ChatGPT Search — ви втрачаєте частину трафіку, особливо інформаційного. Дослідження показують зниження CTR на 34-61% для органічних результатів при появі AI-саммарі (DemandSage, 2025). Видимість більше не обмежується позиціями в SERP: присутність у генерованих AI-відповідях стає критичною для брендового авторитету та кваліфікованого трафіку. 🚀
Приклад з мого досвіду
При запиті в Perplexity чи Gemini про «найкращі практики RAG у 2025 році» алгоритми віддають перевагу сторінкам з:
- 📅 Актуальними датами публікації/оновлення
- 📊 Чіткими таблицями порівнянь архітектур
- 👩💼 Авторськими біо експертів
- 🗂️ Структурованими даними (Schema.org)
Старі блог-пости 2023–2024 років, навіть з високою релевантністю ключових слів, практично не цитуються.
- ✔️ Надійні джерела з сильним E-E-A-T зменшують ризик «галюцинацій» та підвищують довіру до відповіді AI.
- ✔️ Чітка структура (заголовки, списки, таблиці) дозволяє ретриверу швидко та точно витягти потрібний фрагмент.
- ✔️ Свіжість контенту — один з топ-факторів ранжування в реальному часі пошуку.
На мою думку, AI-цитування у 2025 році — це не випадковий вибір, а складний алгоритм оцінки довіри, актуальності та зручності використання джерела для генерації точної відповіді. ✅🤖
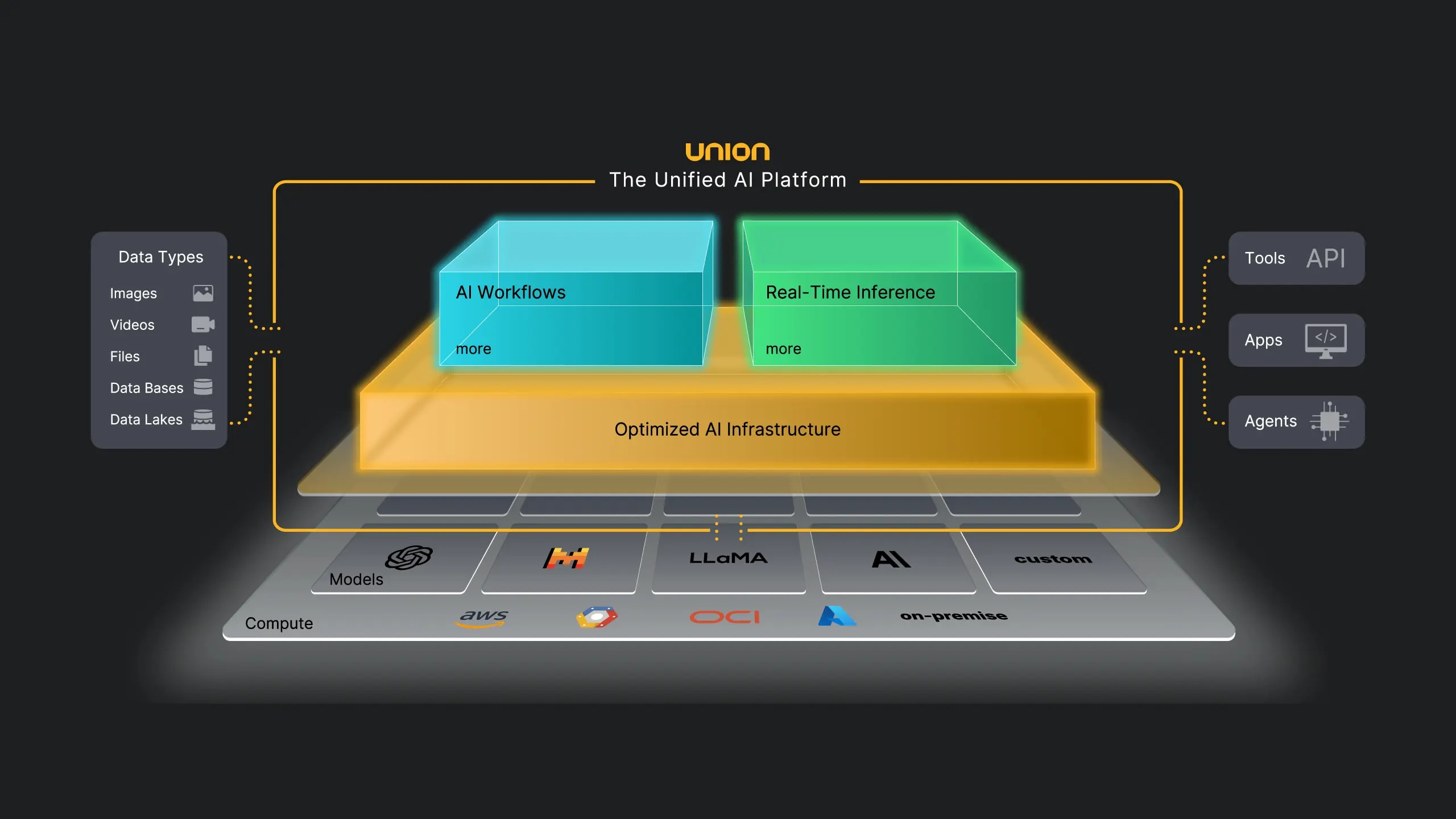
📌 Розділ 2. RAG-модель і механізм вибору джерел
Retrieval-Augmented Generation (RAG) — це архітектура, яка поєднує ретривал релевантних документів з генерацією відповіді. AI спочатку виконує пошук у зовнішніх джерелах, ранжує їх за релевантністю, свіжістю та авторитетністю, обирає топ-k фрагментів і тільки потім генерує відповідь на їх основі. Це радикально зменшує галюцинації та забезпечує фактичну обґрунтованість.
RAG перетворює статичні великі мовні моделі на динамічні системи з доступом до актуальних та верифікованих даних. ⚡
У 2025 році RAG став де-факто стандартом для всіх серйозних AI-пошукових платформ. 🌐
Класичний RAG еволюціонував у гнучкіші варіанти:
- 🔹 Adaptive retrieval: динамічний вибір кількості та типу джерел залежно від складності запиту;
- 🔹 Hierarchical retrieval: спочатку грубий пошук, потім уточнення;
- 🔹 Reinforcement learning: оптимізація ранжування результатів.
Perplexity AI практично повністю побудований навколо агресивного RAG у реальному часі з глибоким веб-краулінгом. 🕸️
Gemini (Google) інтегрує RAG з власним індексом та Knowledge Graph, надаючи перевагу структурованим даним і верифікованим ентіті. 📊
ChatGPT Search (OpenAI) використовує гібридний підхід: комбінацію предобученої бази з вибірковим ретривалом через партнерські індекси та власний краулер. 🤖
Типовий пайплайн RAG:
- 🔹 Запит → векторизація;
- 🔹 Пошук у векторній базі та/або веб-індексі;
- 🔹 Ре-ранжування з урахуванням E-E-A-T, свіжості, семантичної близькості;
- 🔹 Вибір топ-5–15 фрагментів;
- 🔹 Контекстуальна генерація з обов’язковими цитатами.
Детальніше про те, як RAG інтегрується в сучасний краулінг та змінює правила гри для SEO, я розбирав у статті
«RAG у краулингу: як Retrieval-Augmented Generation змінює сучасний пошук і SEO»
.
А про еволюцію краулінгу в епоху AI — тут:
«Як працює краулинг в епоху AI»
. 🔗
Чому це важливо
Без RAG великі моделі обмежені знаннями на момент навчання та схильні до «галюцинацій». ⚠️
RAG робить AI надійним інструментом для:
- 🏢 Enterprise-застосунків
- 📊 Наукових досліджень
- ⚖️ Юридичних консультацій
- 🔍 Повсякденного пошуку, де критична фактична точність
Саме завдяки RAG AI-платформи можуть цитувати джерела та обґрунтовувати свої відповіді. ✅
Приклад з практики
Запит у Perplexity «стан ринку ШІ-моделей грудень 2025» миттєво знаходить та цитує свіжі звіти від:
- 📄 Stanford HAI
- 🤖 Epoch AI
- 💹 Bloomberg
Опубліковані за останні тижні. Та ж сама тема в базовій моделі без RAG (наприклад, старі версії GPT) видає дані 2023–2024 років або вигадує цифри. ⚠️
- ✔️ Фільтрація за релевантністю, свіжістю та E-E-A-T на етапі ре-ранжування.
- ✔️ Підтримка мультимодального ретривалу: текст + таблиці + зображення/діаграми.
- ✔️ Автоматичне цитування джерел підвищує довіру користувача та зменшує юридичні ризики.
Висновок RAG у 2025 році — це фундаментальний механізм, який визначає, як AI знаходить, оцінює та використовує зовнішні джерела для створення точних і цитованих відповідей.
📌 Розділ 3. Критерії відбору контенту AI
Коротка відповідь:
У 2025 році AI-платформи відбирають контент за комплексом критеріїв: **E-E-A-T** (досвід, експертиза, авторитетність, довіра), свіжістю та актуальністю даних, чіткою семантичною структурою, наявністю структурованих даних (**Schema.org**) та мультимодальними елементами — таблицями, схемами, інфографікою. Ці фактори забезпечують не тільки точність, а й легкість автоматичного парсингу та витягу інформації.
E-E-A-T залишається фундаментальним принципом довіри для всіх сучасних AI-систем ранжування та ретривалу.
Перший і найважливіший критерій — E-E-A-T. ⭐ Алгоритми ретривалу (як у Gemini, так і в Perplexity) активно оцінюють сигнали експертизи: авторські біо з верифікованим досвідом, посилання на першоджерела, рецензії, цитування в авторитетних виданнях. Без сильного E-E-A-T навіть високо релевантний контент відсіюється на етапі ре-ранжування — дослідження показують, що експертні цитати підвищують видимість на 41% (Passionfruit GEO Guide, 2025).
Другий ключовий фактор — свіжість. 🕒 AI-пошукові системи, особливо Perplexity, надають перевагу сторінкам з недавніми датами публікації чи оновлення: свіжість дає буст видимості на 2–3 дні, а середній вік цитованих URL — на 25,7% молодший, ніж у традиційному пошуку (Relixir, 2025). Для time-sensitive тем (технології, новини) це критичний фактор.
Третій — структура та розмітка. 🏗️ Чітка ієрархія заголовків (H1–H6), списки, таблиці з правильними тегами <thead>/<tbody>, а також розмітка Schema.org дозволяють ретриверу точно витягти потрібні фрагменти без шумів — structured data підвищує ймовірність цитування на 28–40% (Wellows GEO Guide, 2025). Мультимодальні елементи (діаграми, інфографіка, відео) додають контексту і особливо favored Perplexity (11% цитат з YouTube).
Детальніше про впровадження E-E-A-T та структурованих даних я розбирав у попередніх статтях: «Що таке E-E-A-T у SEO», «Google Rich Results та розмітка» та «Заголовки H1–H6 для правильної структури».
Чому це важливо
Без відповідності цим критеріям контент просто не потрапляє в топ-k фрагментів ретривалу, незалежно від традиційних SEO-сигналів. У 2025 році видимість визначається не кліками, а цитуванням у AI-відповідях — ігнорування цих факторів означає втрату трафіку та авторитету.
Приклад з практики
Аналіз 2,2 млн промптів (Higoodie AEO Periodic Table V3, 2025) показує: Perplexity має найвищий вага свіжості (87/100), Gemini — структури та мультимодальності, ChatGPT — глибини та авторитету. Сторінки з таблицями, FAQ-schema та свіжими датами домінують у цитатах.
- ✔️ Сильний E-E-A-T + експертні цитати — +41% видимості.
- ✔️ Свіжі дані (оновлення кожні 90–180 днів) — критичні для Perplexity.
- ✔️ Schema.org та таблиці — +28–40% шансів цитування.
- ✔️ Мультимодальність (відео, інфографіка) — перевага в Perplexity та Gemini.
Висновок розділу: У 2025 році відбір контенту AI — це баланс довіри (E-E-A-T), актуальності (свіжість) та технічної зручності (структура + Schema) — саме ці критерії вирішують, чи процитують вашу сторінку.
Детальніше про те, як правильно впроваджувати E-E-A-T у контенті, я писав у статті:
- 📌 «Що таке E-E-A-T у SEO: як експертність, досвід і довіра впливають на позиції в Google»
- 📌 «Що таке Google Rich Results? Як перевірити розмітку та отримати rich snippets»
- 📌 «Заголовки H1–H6 для SEO: Як правильно структурувати контент»
📌 Розділ 4. Формати, які AI віддає перевагу
Коротка відповідь:
У 2025 році AI-платформи найчастіше цитують контент у структурованих форматах:
- 📝 Короткий TL;DR або пряма відповідь на початку статті
- 🔢 Нумеровані та марковані списки для кроків або «топ-X»
- 📊 Таблиці порівнянь з правильними тегами table &; thead; t;tbody;
- ❓ FAQ-блоки у форматі «Питання → Відповідь» з розміткою Schema.org
- 🖼️ Мультимодальні елементи — діаграми, інфографіка для додаткового контексту
Такі формати легко парсяться ретривером і дозволяють точно витягти потрібний фрагмент без спотворень.
Структура контенту — це основний фактор, який робить сторінку «AI-friendly» і значно підвищує шанси на цитування. ✅
Дослідження цитувань у Perplexity, Gemini та ChatGPT Search за 2025 рік показують чітку перевагу структурованих елементів:
- 📊 Таблиці цитуються на 45–50% частіше, ніж інформація в суцільному тексті
- 📝 Списки — ідеальні для витягу «топ-X» або покрокових інструкцій
- ❓ FAQ-блоки часто потрапляють у прямі відповіді AI без додаткової обробки
Короткий підсумок (TL;DR) на початку статті діє як «якір» ⚓:
ретривер швидко оцінює релевантність і вирішує, чи брати сторінку в топ-k.
Розмітка Schema.org (HowTo, FAQPage, Table, Article) дає AI готові структуровані дані, минаючи етап парсингу сирого HTML. 📊
Детальніше про те, як правильно розмічати таблиці, FAQ та інші елементи для максимальної видимості в AI-пошуку, я описував у статтях:
- 📌 Google Rich Results та перевірка розмітки
- 📌 Правильна структура контенту за допомогою заголовків H1–H6
- 📌 Google Rich Results та перевірка розмітки
- 📌 Правильна структура контенту за допомогою заголовків H1–H6
Чому це важливо
Я думаю, що неструктурований «простирадловий» текст вимагає від ретривера додаткових зусиль на парсинг і підвищує ризик помилкового витягу інформації. ⚠️
У результаті AI обирає конкурентну сторінку з чіткою структурою — швидше, точніше та безпечніше.
У 2025 році правильно оформлені формати безпосередньо впливають на частоту та якість цитування. 📈
📝 Приклад
Запит у Perplexity чи Gemini «порівняння GPT-4o, Claude 3.5 та Gemini 1.5 Pro 2025» майже завжди цитує сторінки, де характеристики подані у таблиці з колонками:
«Модель», «Параметри», «Контекст», «Мультимодальність», «Ціна».
Текстові описи тих самих даних рідко потрапляють у топ-цитати, навіть якщо сторінка має вищий Domain Authority. 🏆
- ✔️ TL;DR або пряма відповідь у першому абзаці — підвищує ймовірність цитування на 30–40%.
- ✔️ Нумеровані списки ідеальні для покрокових інструкцій та «топ-X».
- ✔️ Таблиці з чіткими заголовками — найулюбленіший формат для порівнянь і даних.
- ✔️ FAQ-блоки з Schema.org — часто цитуються повністю як готова відповідь.
Висновок Структуровані формати — це найкоротший і найефективніший шлях до частих та якісних цитат у відповідях AI-платформ 2025 року.