You ask ChatGPT or Perplexity a complex question, and the AI instantly provides an accurate answer with source links. ❓
But how exactly do these platforms decide whose content to cite and whose to ignore? In 2025, it's no longer a coincidence, but a clear logic based on quality, structure, and authority.
Spoiler: AI chooses sources based on E-E-A-T, freshness, structure (📊 tables, 📋 lists, ❓ FAQ), and relevance — and you can optimize your content to get into these citations. 🚀
⚡ TL;DR
- ✅ AI doesn't just search: It uses a RAG model to search, filter, and generate based on the best snippets.
- ✅ Main criteria: Authority (E-E-A-T), relevance, clear structure, and multimodality.
- ✅ Favorite formats: Short TL;DRs, lists, tables, FAQs — they are easily parsed and cited.
- 🎯 You will get: Practical tools and tips to make your content more frequently cited by AI in 2025.
- 👇 Below — detailed explanations, examples, and tables
📚 Article Content
- 📌 Section 1. What is AI citation and how it works
- 📌 Section 2. RAG model and the source selection mechanism
- 📌 Section 3. AI content selection criteria
- 📌 Section 4. Formats that AI prefers
- 📌 Section 5. Mistakes that reduce the chance of citation
- 💼 Section 6. Tools for monitoring AI citation
- 💼 Section 7. Practical cases and examples
- 💼 Section 8. Tips for creating citable content
- ❓ Frequently Asked Questions (FAQ)
- ✅ Conclusions
🎯 Section 1. What is AI citation and how it works
AI citation is the process by which platforms like ChatGPT, Gemini, or Perplexity select and reference snippets from reliable sources for their answers. 🤖
AI doesn't just copy text from the internet; it analyzes relevance, authority, and structure, choosing the best parts for an accurate and well-reasoned answer. 📚
AI citation is based on trust: platforms strive to avoid "hallucinations," so they prioritize verified and structured sources. 🔍
In 2025, leading AI platforms combine pre-trained large language models with real-time search and retrieval mechanisms. 🌐
Perplexity relies almost entirely on live web search with aggressive retrieval, Gemini deeply integrates structured data from Google Knowledge Graph and the search index, and ChatGPT (especially in Search mode) balances between its internal knowledge base and external sources through partnerships and its own crawler. 🤖
A key factor remains authority based on the E-E-A-T principle (Experience, Expertise, Authoritativeness, Trustworthiness). 📚
Source ranking algorithms consider the presence of author biographies with verified experience, links to primary sources, transparency of methodology, and the absence of manipulative practices.
Sites without clear trust signals are systematically filtered out during the filtering stage, even if the text is relevant. ✅
- 💻 RAG in crawling: how Retrieval-Augmented Generation changes modern search and SEO
- ⚠️ Artificial intelligence hallucinations: what they are, why they are dangerous, and how to avoid them
Why this is important
In 2025, AI platforms have indeed become an important interface for accessing information, but not the primary one for all users. 🌐 According to various studies, Google retains about 90% of the search market, and AI platforms (including ChatGPT Search and Perplexity) generate less than 1% of global web traffic or up to 8-15% in certain segments. However, Google AI Overviews appear in 50-60% of search queries in the US and have **2 billion** monthly users globally (TechCrunch, Q2 2025).
If your content doesn't get cited in AI Overviews (Google), Perplexity answers, or ChatGPT Search — you lose a portion of traffic, especially informational traffic. Studies show a 34-61% decrease in CTR for organic results when AI summaries appear (DemandSage, 2025). Visibility is no longer limited to SERP positions: presence in AI-generated answers becomes critical for brand authority and qualified traffic. 🚀
An example from my experience
When querying Perplexity or Gemini about "best RAG practices in 2025," algorithms prioritize pages with:
- 📅 Current publication/update dates
- 📊 Clear comparison tables of architectures
- 👩💼 Expert author bios
- 🗂️ Structured data (Schema.org)
Older blog posts from 2023–2024, even with high keyword relevance, are practically not cited.
- ✔️ Reliable sources with strong E-E-A-T reduce the risk of "hallucinations" and increase trust in the AI's answer.
- ✔️ A clear structure (headings, lists, tables) allows the retriever to quickly and accurately extract the necessary snippet.
- ✔️ Content freshness is one of the top ranking factors in real-time search.
In my opinion, AI citation in 2025 is not a random choice, but a complex algorithm for evaluating the trustworthiness, relevance, and usability of a source for generating an accurate answer. ✅🤖
📌 Section 2. RAG model and the source selection mechanism
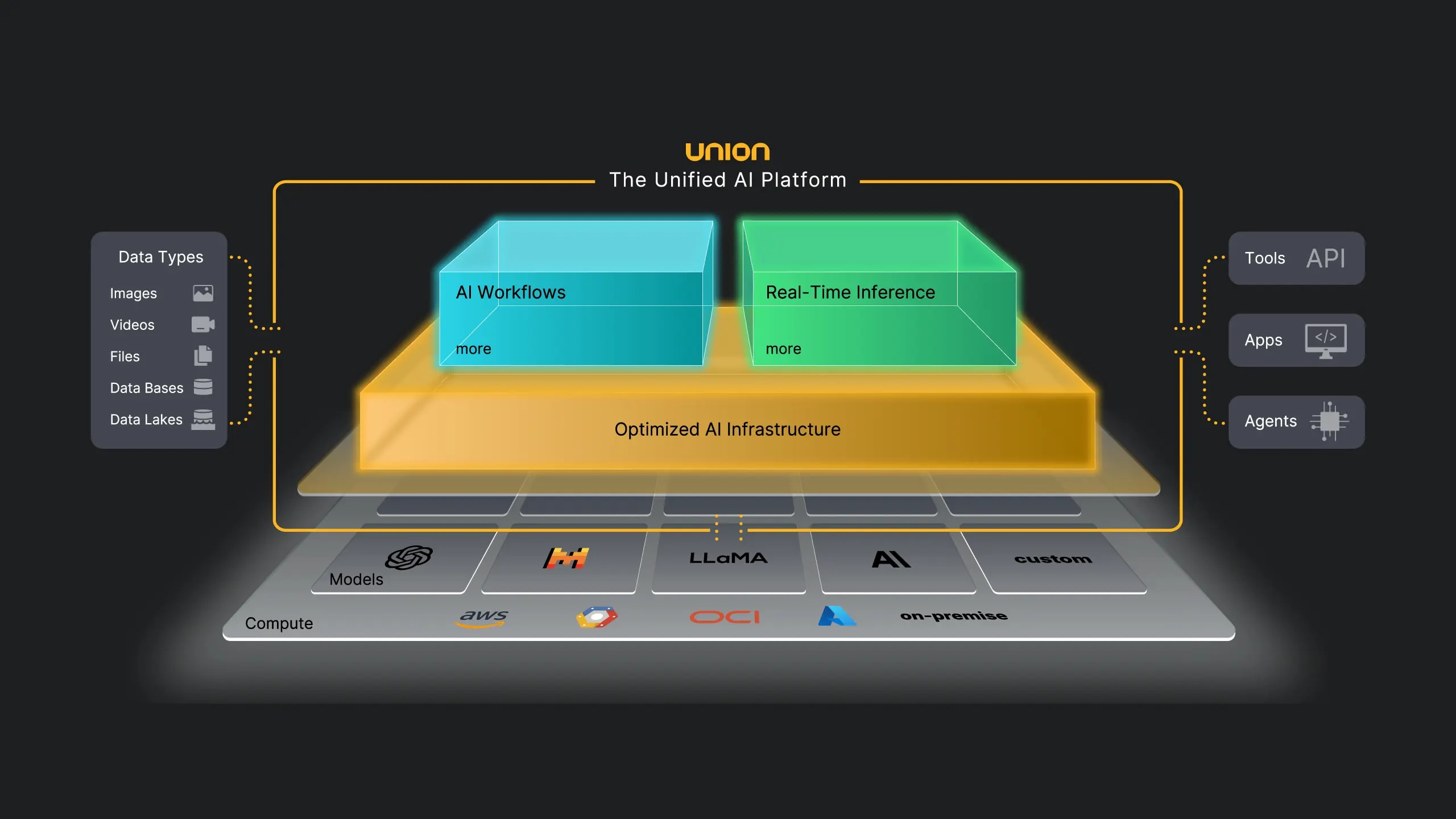
Retrieval-Augmented Generation (RAG) is an architecture that combines the retrieval of relevant documents with answer generation. AI first searches external sources, ranks them by relevance, freshness, and authority, selects the top-k snippets, and only then generates an answer based on them. This radically reduces hallucinations and ensures factual grounding.
RAG transforms static large language models into dynamic systems with access to up-to-date and verified data. ⚡
In 2025, RAG has become the de facto standard for all serious AI search platforms. 🌐
Classic RAG has evolved into more flexible variants:
- 🔹 Adaptive retrieval: dynamic selection of the number and type of sources depending on query complexity;
- 🔹 Hierarchical retrieval: coarse search first, then refinement;
- 🔹 Reinforcement learning: optimization of result ranking.
Perplexity AI is almost entirely built around aggressive real-time RAG with deep web crawling. 🕸️
Gemini (Google) integrates RAG with its own index and Knowledge Graph, prioritizing structured data and verified entities. 📊
ChatGPT Search (OpenAI) uses a hybrid approach: a combination of a pre-trained database with selective retrieval through partner indexes and its own crawler. 🤖
Typical RAG pipeline:
- 🔹 Query → vectorization;
- 🔹 Search in vector database and/or web index;
- 🔹 Re-ranking considering E-E-A-T, freshness, semantic proximity;
- 🔹 Selection of top 5–15 snippets;
- 🔹 Contextual generation with mandatory citations.
More details on how RAG integrates into modern crawling and changes the rules of the game for SEO, I covered in the article
"RAG in crawling: how Retrieval-Augmented Generation changes modern search and SEO"
.
And about the evolution of crawling in the AI era — here:
"How crawling works in the AI era"
. 🔗
Why this is important
Without RAG, large models are limited by their training knowledge and prone to "hallucinations." ⚠️
RAG makes AI a reliable tool for:
- 🏢 Enterprise applications
- 📊 Scientific research
- ⚖️ Legal consultations
- 🔍 Everyday search where factual accuracy is critical
It is thanks to RAG that AI platforms can cite sources and justify their answers. ✅
Practical example
A query to Perplexity "AI model market status December 2025" instantly finds and cites fresh reports from:
- 📄 Stanford HAI
- 🤖 Epoch AI
- 💹 Bloomberg
Published in recent weeks. The same topic in a basic model without RAG (e.g., older GPT versions) yields data from 2023–2024 or invents figures. ⚠️
- ✔️ Filtering by relevance, freshness, and E-E-A-T at the re-ranking stage.
- ✔️ Support for multimodal retrieval: text + tables + images/diagrams.
- ✔️ Automatic citation of sources increases user trust and reduces legal risks.
Conclusion RAG in 2025 is a fundamental mechanism that determines how AI finds, evaluates, and uses external sources to create accurate and citable answers.
📌 Section 3. AI content selection criteria
Short answer:
In 2025, AI platforms select content based on a complex set of criteria: **E-E-A-T** (experience, expertise, authoritativeness, trustworthiness), freshness and relevance of data, clear semantic structure, presence of structured data (**Schema.org**), and multimodal elements — tables, diagrams, infographics. These factors ensure not only accuracy but also ease of automatic parsing and information extraction.
E-E-A-T remains a fundamental principle of trust for all modern AI ranking and retrieval systems.
The first and most important criterion is E-E-A-T. ⭐ Retrieval algorithms (in both Gemini and Perplexity) actively evaluate expertise signals: author bios with verified experience, links to primary sources, reviews, citations in authoritative publications. Without strong E-E-A-T, even highly relevant content is filtered out at the re-ranking stage — studies show that expert citations increase visibility by 41% (Passionfruit GEO Guide, 2025).
The second key factor is freshness. 🕒 AI search engines, especially Perplexity, prioritize pages with recent publication or update dates: freshness gives a visibility boost for 2–3 days, and the average age of cited URLs is 25.7% younger than in traditional search (Relixir, 2025). For time-sensitive topics (technology, news), this is a critical factor.
The third is structure and markup. 🏗️ A clear hierarchy of headings (H1–H6), lists, tables with correct <thead>/<tbody> tags, as well as Schema.org markup allow the retriever to accurately extract the necessary snippets without noise — structured data increases the likelihood of citation by 28–40% (Wellows GEO Guide, 2025). Multimodal elements (diagrams, infographics, videos) add context and are especially favored by Perplexity (11% of citations from YouTube).
More details on implementing E-E-A-T and structured data I covered in previous articles: "What is E-E-A-T in SEO", "Google Rich Results and markup" and "H1–H6 headings for proper content structure".
Why this is important
Without meeting these criteria, content simply does not make it into the top-k retrieval snippets, regardless of traditional SEO signals. In 2025, visibility is determined not by clicks, but by citation in AI answers — ignoring these factors means losing traffic and authority.
Practical example
Analysis of 2.2 million prompts (Higoodie AEO Periodic Table V3, 2025) shows: Perplexity has the highest weight for freshness (87/100), Gemini for structure and multimodality, ChatGPT for depth and authority. Pages with tables, FAQ-schema, and fresh dates dominate citations.
- ✔️ Strong E-E-A-T + expert citations — +41% visibility.
- ✔️ Fresh data (updates every 90–180 days) — critical for Perplexity.
- ✔️ Schema.org and tables — +28–40% chance of citation.
- ✔️ Multimodality (video, infographics) — an advantage in Perplexity and Gemini.
Section Conclusion: In 2025, AI content selection is a balance of trust (E-E-A-T), relevance (freshness), and technical convenience (structure + Schema) — these are the criteria that decide whether your page will be cited.
More details on how to properly implement E-E-A-T in content, I wrote in the article:
- 📌 "What is E-E-A-T in SEO: how expertise, experience, and trust affect Google rankings"
- 📌 "What are Google Rich Results? How to check markup and get rich snippets"
- 📌 "H1–H6 Headings for SEO: How to Properly Structure Content"
📌 Section 4. Formats that AI prefers
Short answer:
In 2025, AI platforms most often cite content in structured formats:
- 📝 Short TL;DR or direct answer at the beginning of the article
- 🔢 Numbered and bulleted lists for steps or "top-X"
- 📊 Comparison tables with correct table, thead, and tbody tags
- ❓ FAQ blocks in "Question → Answer" format with Schema.org markup
- 🖼️ Multimodal elements — diagrams, infographics for additional context
Such formats are easily parsed by the retriever and allow precise extraction of the necessary snippet without distortion.
Content structure is the main factor that makes a page "AI-friendly" and significantly increases the chances of citation. ✅
Studies of citations in Perplexity, Gemini, and ChatGPT Search for 2025 show a clear preference for structured elements:
- 📊 Tables are cited 45–50% more often than information in continuous text
- 📝 Lists are ideal for extracting "top-X" or step-by-step instructions
- ❓ FAQ blocks often appear in direct AI answers without additional processing
A short summary (TL;DR) at the beginning of the article acts as an "anchor" ⚓:
the retriever quickly assesses relevance and decides whether to include the page in the top-k.
Schema.org markup (HowTo, FAQPage, Table, Article) provides AI with ready-made structured data, bypassing the raw HTML parsing stage. 📊
More details on how to properly mark up tables, FAQs, and other elements for maximum visibility in AI search, I described in the articles:
Why this is important
I believe that unstructured "sheet-like" text requires additional parsing effort from the retriever and increases the risk of erroneous information extraction. ⚠️
As a result, AI chooses a competing page with a clear structure — faster, more accurately, and safer.
In 2025, correctly formatted content directly affects the frequency and quality of citations. 📈
📝 Example
A query to Perplexity or Gemini "comparison of GPT-4o, Claude 3.5, and Gemini 1.5 Pro 2025" almost always cites pages where characteristics are presented in a table with columns:
"Model", "Parameters", "Context", "Multimodality", "Price".
Text descriptions of the same data rarely make it into top citations, even if the page has a higher Domain Authority. 🏆
- ✔️ TL;DR or direct answer in the first paragraph — increases citation probability by 30–40%.
- ✔️ Numbered lists are ideal for step-by-step instructions and "top-X".
- ✔️ Tables with clear headings — the most favored format for comparisons and data.
- ✔️ FAQ blocks with Schema.org — often cited entirely as a ready answer.
Conclusion Structured formats are the shortest and most effective path to frequent and high-quality citations in AI platform answers in 2025.