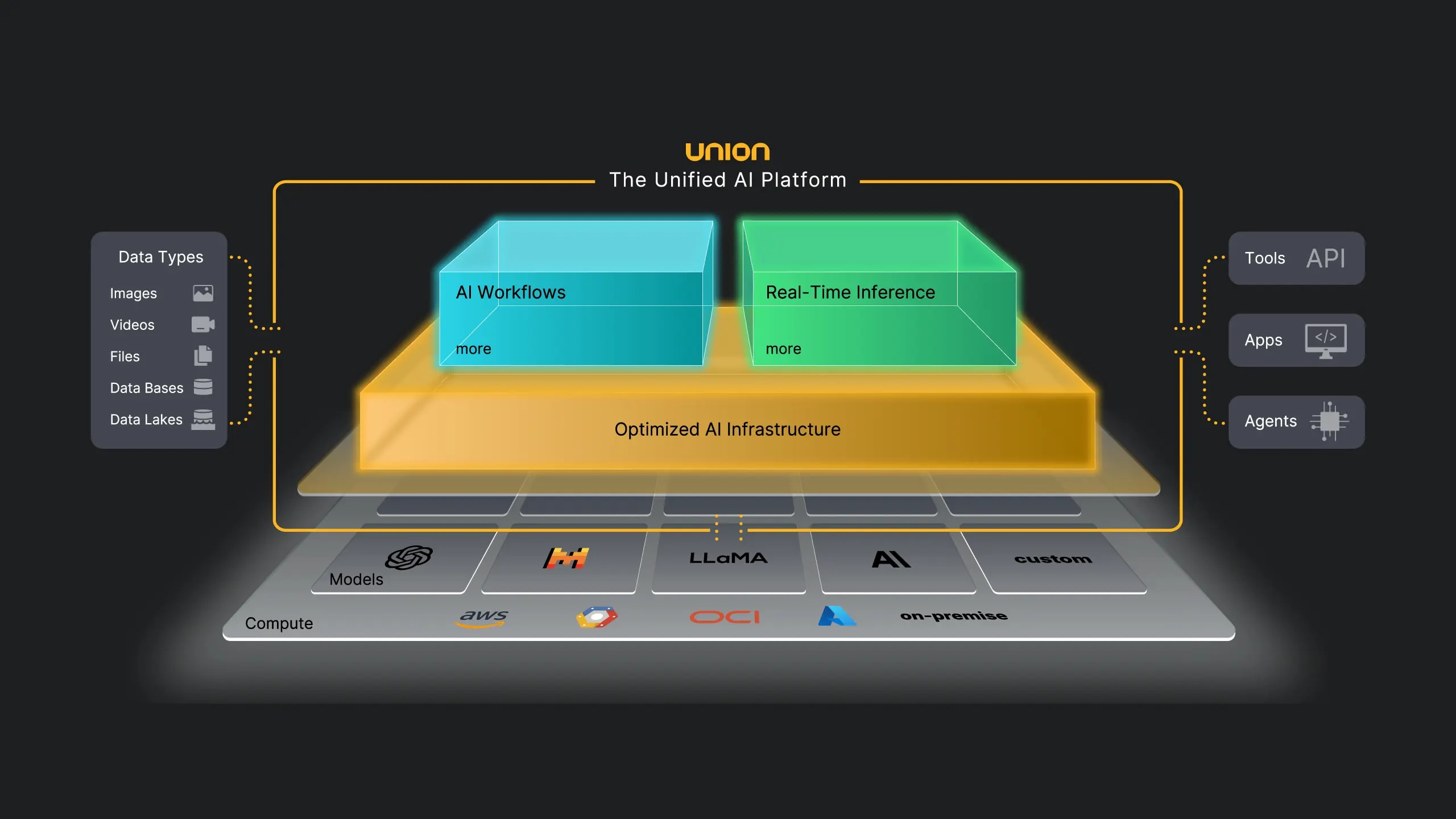
Sie stellen ChatGPT oder Perplexity eine komplexe Frage, und die KI liefert sofort eine präzise Antwort mit Quellenangaben. ❓
Doch wie genau entscheiden diese Plattformen, welcher Inhalt zitiert und welcher ignoriert wird? Im Jahr 2025 ist dies kein Zufall mehr, sondern eine klare Logik, basierend auf Qualität, Struktur und Autorität.
Spoiler: KI wählt Quellen nach den Kriterien E-E-A-T, Aktualität, Struktur (📊 Tabellen, 📋 Listen, ❓ FAQ) und Relevanz aus — und Sie können Ihren Inhalt optimieren, um in diesen Zitaten zu erscheinen. 🚀
⚡ Kurz gesagt
- ✅ KI sucht nicht nur: Sie verwendet ein RAG-Modell zur Suche, Filterung und Generierung basierend auf den besten Fragmenten.
- ✅ Hauptkriterien: Autorität (E-E-A-T), Aktualität, klare Struktur und Multimodalität.
- ✅ Bevorzugte Formate: Kurze TL;DRs, Listen, Tabellen, FAQs – sie lassen sich leicht parsen und zitieren.
- 🎯 Sie erhalten: Praktische Tools und Tipps, damit Ihr Inhalt im Jahr 2025 häufiger von KI zitiert wird.
- 👇 Unten – detaillierte Erklärungen, Beispiele und Tabellen
📚 Inhaltsverzeichnis
- 📌 Abschnitt 1. Was ist KI-Zitierung und wie funktioniert sie
- 📌 Abschnitt 2. Das RAG-Modell und der Mechanismus zur Quellenauswahl
- 📌 Abschnitt 3. Kriterien für die KI-Inhaltsauswahl
- 📌 Abschnitt 4. Formate, die KI bevorzugt
- 📌 Abschnitt 5. Fehler, die die Zitierwahrscheinlichkeit verringern
- 💼 Abschnitt 6. Tools zur Überwachung von KI-Zitierungen
- 💼 Abschnitt 7. Praktische Anwendungsfälle und Beispiele
- 💼 Abschnitt 8. Tipps zur Erstellung zitierfähiger Inhalte
- ❓ Häufig gestellte Fragen (FAQ)
- ✅ Fazit
🎯 Abschnitt 1. Was ist KI-Zitierung und wie funktioniert sie
KI-Zitierung ist der Prozess, bei dem Plattformen wie ChatGPT, Gemini oder Perplexity Fragmente aus zuverlässigen Quellen für Antworten auswählen und darauf verweisen. 🤖
KI kopiert nicht einfach Text aus dem Internet, sondern analysiert Relevanz, Autorität und Struktur, um die besten Teile für eine präzise und fundierte Antwort auszuwählen. 📚
KI-Zitierung basiert auf Vertrauen: Plattformen versuchen, „Halluzinationen“ zu vermeiden, und bevorzugen daher verifizierte und strukturierte Quellen. 🔍
Im Jahr 2025 kombinieren führende KI-Plattformen vortrainierte große Sprachmodelle mit Echtzeit-Such- und Retrieval-Mechanismen. 🌐
Perplexity verlässt sich fast vollständig auf die Live-Websuche mit aggressivem Retrieval, Gemini integriert strukturierte Daten aus dem Google Knowledge Graph und dem Suchindex tiefgreifend, und ChatGPT (insbesondere im Suchmodus) balanciert zwischen einer internen Wissensbasis und externen Quellen durch Partnerschaften und einen eigenen Crawler. 🤖
Ein Schlüsselfaktor bleibt die Autorität nach dem E-E-A-T-Prinzip (Experience, Expertise, Authoritativeness, Trustworthiness). 📚
Die Ranking-Algorithmen für Quellen berücksichtigen das Vorhandensein von Autorenbiografien mit verifizierter Erfahrung, Verweise auf Primärquellen, Transparenz der Methodik und das Fehlen manipulativer Praktiken.
Websites ohne klare Vertrauenssignale werden in der Filterphase systematisch aussortiert, selbst wenn der Text relevant ist. ✅
- 💻 RAG im Crawling: Wie Retrieval-Augmented Generation die moderne Suche und SEO verändert
- ⚠️ Halluzinationen der künstlichen Intelligenz: Was sie sind, warum sie gefährlich sind und wie man sie vermeidet
Warum das wichtig ist
Im Jahr 2025 sind KI-Plattformen tatsächlich zu einer wichtigen Schnittstelle für den Informationszugang geworden, jedoch nicht die primäre für alle Nutzer. 🌐 Laut verschiedenen Studien hält Google etwa 90 % des Suchmarktes, während KI-Plattformen (einschließlich ChatGPT Search und Perplexity) weniger als 1 % des globalen Webtraffics oder bis zu 8-15 % in bestimmten Segmenten generieren. Google AI Overviews erscheinen jedoch bei 50-60 % der Suchanfragen in den USA und haben weltweit **2 Milliarden** monatliche Nutzer (TechCrunch, Q2 2025).
Wenn Ihr Inhalt nicht in den Zitaten der AI Overviews (Google), den Antworten von Perplexity oder ChatGPT Search erscheint, verlieren Sie einen Teil des Traffics, insbesondere des informativen. Studien zeigen einen Rückgang der Klickrate (CTR) um 34-61 % für organische Ergebnisse, wenn KI-Zusammenfassungen erscheinen (DemandSage, 2025). Die Sichtbarkeit ist nicht mehr auf SERP-Positionen beschränkt: Die Präsenz in generierten KI-Antworten wird entscheidend für die Markenautorität und qualifizierten Traffic. 🚀
Beispiel aus meiner Erfahrung
Bei einer Anfrage an Perplexity oder Gemini nach „Best Practices für RAG im Jahr 2025“ bevorzugen die Algorithmen Seiten mit:
- 📅 Aktuellen Veröffentlichungs-/Aktualisierungsdaten
- 📊 Klaren Vergleichstabellen von Architekturen
- 👩💼 Autorenbiografien von Experten
- 🗂️ Strukturierten Daten (Schema.org)
Alte Blogbeiträge aus den Jahren 2023–2024 werden, selbst bei hoher Keyword-Relevanz, praktisch nicht zitiert.
- ✔️ Zuverlässige Quellen mit starkem E-E-A-T verringern das Risiko von „Halluzinationen“ und erhöhen das Vertrauen in die KI-Antwort.
- ✔️ Eine klare Struktur (Überschriften, Listen, Tabellen) ermöglicht es dem Retriever, das benötigte Fragment schnell und präzise zu extrahieren.
- ✔️ Aktualität des Inhalts – einer der Top-Ranking-Faktoren in der Echtzeit-Suche.
Meiner Meinung nach ist die KI-Zitierung im Jahr 2025 keine zufällige Auswahl, sondern ein komplexer Algorithmus zur Bewertung von Vertrauen, Aktualität und Benutzerfreundlichkeit der Quelle für die Generierung einer präzisen Antwort. ✅🤖
📌 Abschnitt 2. Das RAG-Modell und der Mechanismus zur Quellenauswahl
Retrieval-Augmented Generation (RAG) ist eine Architektur, die das Retrieval relevanter Dokumente mit der Generierung einer Antwort kombiniert. Die KI sucht zunächst in externen Quellen, rankt diese nach Relevanz, Aktualität und Autorität, wählt die Top-k-Fragmente aus und generiert erst dann eine Antwort auf deren Grundlage. Dies reduziert Halluzinationen radikal und gewährleistet eine faktische Fundierung.
RAG verwandelt statische große Sprachmodelle in dynamische Systeme mit Zugriff auf aktuelle und verifizierte Daten. ⚡
Im Jahr 2025 ist RAG zum De-facto-Standard für alle ernsthaften KI-Suchplattformen geworden. 🌐
Klassisches RAG hat sich zu flexibleren Varianten entwickelt:
- 🔹 Adaptive retrieval: dynamische Auswahl der Anzahl und Art der Quellen je nach Komplexität der Anfrage;
- 🔹 Hierarchical retrieval: zuerst grobe Suche, dann Verfeinerung;
- 🔹 Reinforcement learning: Optimierung des Ergebnis-Rankings.
Perplexity AI ist praktisch vollständig um aggressives Echtzeit-RAG mit tiefem Web-Crawling herum aufgebaut. 🕸️
Gemini (Google) integriert RAG mit seinem eigenen Index und Knowledge Graph, wobei strukturierten Daten und verifizierten Entitäten der Vorzug gegeben wird. 📊
ChatGPT Search (OpenAI) verwendet einen hybriden Ansatz: eine Kombination aus einer vortrainierten Basis mit selektivem Retrieval über Partnerindizes und einen eigenen Crawler. 🤖
Typische RAG-Pipeline:
- 🔹 Anfrage → Vektorisierung;
- 🔹 Suche in der Vektordatenbank und/oder im Web-Index;
- 🔹 Re-Ranking unter Berücksichtigung von E-E-A-T, Aktualität, semantischer Nähe;
- 🔹 Auswahl der Top-5–15 Fragmente;
- 🔹 Kontextuelle Generierung mit obligatorischen Zitaten.
Näheres dazu, wie RAG in das moderne Crawling integriert wird und die Spielregeln für SEO verändert, habe ich im Artikel behandelt:
„RAG im Crawling: Wie Retrieval-Augmented Generation die moderne Suche und SEO verändert“
.
Und zur Evolution des Crawlings im Zeitalter der KI – hier:
„Wie Crawling im Zeitalter der KI funktioniert“
. 🔗
Warum das wichtig ist
Ohne RAG sind große Modelle auf das Wissen zum Zeitpunkt des Trainings beschränkt und neigen zu „Halluzinationen“. ⚠️
RAG macht KI zu einem zuverlässigen Werkzeug für:
- 🏢 Enterprise-Anwendungen
- 📊 Wissenschaftliche Forschung
- ⚖️ Rechtsberatung
- 🔍 Tägliche Suche, bei der faktische Genauigkeit entscheidend ist
Gerade dank RAG können KI-Plattformen Quellen zitieren und ihre Antworten begründen. ✅
Praxisbeispiel
Eine Anfrage an Perplexity nach „Stand des KI-Modellmarktes Dezember 2025“ findet und zitiert sofort aktuelle Berichte von:
- 📄 Stanford HAI
- 🤖 Epoch AI
- 💹 Bloomberg
Veröffentlicht in den letzten Wochen. Dasselbe Thema in einem Basismodell ohne RAG (z. B. ältere GPT-Versionen) liefert Daten aus den Jahren 2023–2024 oder erfindet Zahlen. ⚠️
- ✔️ Filterung nach Relevanz, Aktualität und E-E-A-T in der Re-Ranking-Phase.
- ✔️ Unterstützung des multimodalen Retrievals: Text + Tabellen + Bilder/Diagramme.
- ✔️ Automatische Quellenangabe erhöht das Nutzervertrauen und reduziert rechtliche Risiken.
Fazit RAG im Jahr 2025 ist ein fundamentaler Mechanismus, der bestimmt, wie KI externe Quellen findet, bewertet und nutzt, um präzise und zitierfähige Antworten zu erstellen.
📌 Abschnitt 3. Kriterien für die KI-Inhaltsauswahl
Kurze Antwort:
Im Jahr 2025 wählen KI-Plattformen Inhalte nach einer Reihe von Kriterien aus: **E-E-A-T** (Erfahrung, Expertise, Autorität, Vertrauenswürdigkeit), Aktualität und Relevanz der Daten, einer klaren semantischen Struktur, dem Vorhandensein strukturierter Daten (**Schema.org**) und multimodalen Elementen – Tabellen, Diagrammen, Infografiken. Diese Faktoren gewährleisten nicht nur Genauigkeit, sondern auch die einfache automatische Analyse und Extraktion von Informationen.
E-E-A-T bleibt ein fundamentales Vertrauensprinzip für alle modernen KI-Ranking- und Retrieval-Systeme.
Das erste und wichtigste Kriterium ist E-E-A-T. ⭐ Retrieval-Algorithmen (sowohl bei Gemini als auch bei Perplexity) bewerten aktiv Expertise-Signale: Autorenbiografien mit verifizierter Erfahrung, Verweise auf Primärquellen, Rezensionen, Zitate in maßgeblichen Publikationen. Ohne starkes E-E-A-T wird selbst hochrelevanter Inhalt in der Re-Ranking-Phase aussortiert – Studien zeigen, dass Expertenzitate die Sichtbarkeit um 41 % erhöhen (Passionfruit GEO Guide, 2025).
Ein zweiter Schlüsselfaktor ist die Aktualität. 🕒 KI-Suchmaschinen, insbesondere Perplexity, bevorzugen Seiten mit aktuellen Veröffentlichungs- oder Aktualisierungsdaten: Aktualität führt zu einem Sichtbarkeitsschub von 2–3 Tagen, und das Durchschnittsalter zitierter URLs ist um 25,7 % jünger als bei der traditionellen Suche (Relixir, 2025). Für zeitkritische Themen (Technologie, Nachrichten) ist dies ein entscheidender Faktor.
Der dritte ist Struktur und Markup. 🏗️ Eine klare Hierarchie von Überschriften (H1–H6), Listen, Tabellen mit korrekten <thead>/<tbody>-Tags sowie Schema.org-Markup ermöglichen es dem Retriever, die benötigten Fragmente präzise und ohne Rauschen zu extrahieren — strukturierte Daten erhöhen die Zitierwahrscheinlichkeit um 28–40 % (Wellows GEO Guide, 2025). Multimodale Elemente (Diagramme, Infografiken, Videos) fügen Kontext hinzu und werden von Perplexity besonders bevorzugt (11 % der Zitate von YouTube).
Näheres zur Implementierung von E-E-A-T und strukturierten Daten habe ich in früheren Artikeln behandelt: „Was ist E-E-A-T in SEO“, „Google Rich Results und Markup“ und „H1–H6 Überschriften für die richtige Struktur“.
Warum das wichtig ist
Ohne die Einhaltung dieser Kriterien gelangt der Inhalt einfach nicht in die Top-k-Fragmente des Retrievals, unabhängig von traditionellen SEO-Signalen. Im Jahr 2025 wird die Sichtbarkeit nicht durch Klicks, sondern durch Zitate in KI-Antworten bestimmt – die Missachtung dieser Faktoren bedeutet den Verlust von Traffic und Autorität.
Praxisbeispiel
Eine Analyse von 2,2 Millionen Prompts (Higoodie AEO Periodic Table V3, 2025) zeigt: Perplexity hat das höchste Gewicht für Aktualität (87/100), Gemini für Struktur und Multimodalität, ChatGPT für Tiefe und Autorität. Seiten mit Tabellen, FAQ-Schema und aktuellen Daten dominieren die Zitate.
- ✔️ Starkes E-E-A-T + Expertenzitate — +41 % Sichtbarkeit.
- ✔️ Aktuelle Daten (Updates alle 90–180 Tage) — kritisch für Perplexity.
- ✔️ Schema.org und Tabellen — +28–40 % Zitierwahrscheinlichkeit.
- ✔️ Multimodalität (Videos, Infografiken) — Vorteil bei Perplexity und Gemini.
Fazit des Abschnitts: Im Jahr 2025 ist die KI-Inhaltsauswahl ein Gleichgewicht aus Vertrauen (E-E-A-T), Aktualität (Frische) und technischer Bequemlichkeit (Struktur + Schema) – genau diese Kriterien entscheiden, ob Ihre Seite zitiert wird.
Näheres dazu, wie E-E-A-T korrekt in Inhalte implementiert wird, habe ich im Artikel beschrieben:
- 📌 „Was ist E-E-A-T in SEO: Wie Expertise, Erfahrung und Vertrauen die Positionen bei Google beeinflussen“
- 📌 „Was sind Google Rich Results? Wie man Markup prüft und Rich Snippets erhält“
- 📌 „H1–H6 Überschriften für SEO: Wie man Inhalte richtig strukturiert“
📌 Abschnitt 4. Formate, die KI bevorzugt
Kurze Antwort:
Im Jahr 2025 zitieren KI-Plattformen am häufigsten Inhalte in strukturierten Formaten:
- 📝 Kurzes TL;DR oder direkte Antwort am Anfang des Artikels
- 🔢 Nummerierte und Aufzählungslisten für Schritte oder „Top-X“
- 📊 Vergleichstabellen mit den korrekten Tags table &; thead; t;tbody;
- ❓ FAQ-Blöcke im Format „Frage → Antwort“ mit Schema.org-Markup
- 🖼️ Multimodale Elemente – Diagramme, Infografiken für zusätzlichen Kontext
Solche Formate lassen sich vom Retriever leicht parsen und ermöglichen die präzise Extraktion des benötigten Fragments ohne Verzerrungen.
Die Inhaltsstruktur ist der Hauptfaktor, der eine Seite „KI-freundlich“ macht und die Chancen auf Zitierung erheblich erhöht. ✅
Studien zu Zitierungen in Perplexity, Gemini und ChatGPT Search für das Jahr 2025 zeigen eine klare Präferenz für strukturierte Elemente:
- 📊 Tabellen werden 45–50 % häufiger zitiert als Informationen im Fließtext
- 📝 Listen – ideal für die Extraktion von „Top-X“ oder Schritt-für-Schritt-Anleitungen
- ❓ FAQ-Blöcke gelangen oft ohne zusätzliche Verarbeitung direkt in die KI-Antworten
Eine kurze Zusammenfassung (TL;DR) am Anfang des Artikels wirkt als „Anker“ ⚓:
der Retriever bewertet schnell die Relevanz und entscheidet, ob die Seite in die Top-k aufgenommen werden soll.
Das Schema.org-Markup (HowTo, FAQPage, Table, Article) liefert der KI fertige strukturierte Daten, wodurch die Parsing-Phase des rohen HTML umgangen wird. 📊
Näheres dazu, wie Tabellen, FAQs und andere Elemente für maximale Sichtbarkeit in der KI-Suche korrekt ausgezeichnet werden, habe ich in den Artikeln beschrieben:
- 📌 Google Rich Results und Markup-Prüfung
- 📌 Korrekte Inhaltsstrukturierung mittels H1–H6 Überschriften
- 📌 Google Rich Results und Markup-Prüfung
- 📌 Korrekte Inhaltsstrukturierung mittels H1–H6 Überschriften
Warum das wichtig ist
Ich denke, dass unstrukturierter „Fließtext“ vom Retriever zusätzlichen Parsing-Aufwand erfordert und das Risiko einer fehlerhaften Informationsentnahme erhöht. ⚠️
Im Ergebnis wählt die KI eine konkurrierende Seite mit klarer Struktur – schneller, präziser und sicherer.
Im Jahr 2025 wirken sich korrekt formatierte Inhalte direkt auf die Häufigkeit und Qualität der Zitate aus. 📈
📝 Beispiel
Eine Anfrage an Perplexity oder Gemini nach „Vergleich von GPT-4o, Claude 3.5 und Gemini 1.5 Pro 2025“ zitiert fast immer Seiten, auf denen die Merkmale in einer Tabelle mit Spalten dargestellt sind:
- „Modell“, „Parameter“, „Kontext“, „Multimodalität“, „Preis“.
Textuelle Beschreibungen derselben Daten gelangen selten in die Top-Zitate, selbst wenn die Seite eine höhere Domain Authority aufweist. 🏆
- ✔️ TL;DR oder direkte Antwort im ersten Absatz – erhöht die Zitierwahrscheinlichkeit um 30–40 %.
- ✔️ Nummerierte Listen sind ideal für Schritt-für-Schritt-Anleitungen und „Top-X“.
- ✔️ Tabellen mit klaren Überschriften – das beliebteste Format für Vergleiche und Daten.
- ✔️ FAQ-Blöcke mit Schema.org – werden oft vollständig als fertige Antwort zitiert.
Fazit Strukturierte Formate sind der kürzeste und effektivste Weg zu häufigen und qualitativ hochwertigen Zitaten in den Antworten von KI-Plattformen im Jahr 2025.