LLMS.txt: cómo hacer que un sitio web sea comprensible para ChatGPT, Claude y Grok en 5 minutos
En 2025-2026, los modelos de IA (ChatGPT, Claude, Grok, Gemini) ya generan entre el 10% y el 30% del tráfico de búsqueda y las respuestas (según pronósticos de Mintlify y Yotpo). Pero la mayoría de los sitios web son ruido para ellos: publicidad, JavaScript, menús, pies de página… ¿Y si pudieras darle al modelo una página limpia con todo lo más importante? Precisamente para eso Jeremy Howard propuso llms.txt el 3 de septiembre de 2024 en https://llmstxt.org/. Es un archivo Markdown en la raíz del sitio (/llms.txt) que los modelos de primer nivel ya leen, y reduce las alucinaciones y mejora la precisión de citación de tu proyecto en un 30-70%.
⚡ En resumen
- ✅ LLMS.txt es: un archivo especial /llms.txt en la raíz del sitio, escrito en Markdown específicamente para LLMs
- ✅ Para qué sirve: para que los modelos de IA vean inmediatamente lo más importante sin tener que analizar toda la basura HTML
- ✅ En qué se diferencia de robots.txt: no bloquea, sino todo lo contrario: proporciona el mejor contenido
- 🎯 Obtendrás: una guía clara + una plantilla lista + ejemplos de implementación + cómo verificar si funciona
- 👇 Lee más abajo — con ejemplos reales y código
Contenido del artículo:
¿Qué es llms.txt y por qué apareció ahora?
En septiembre de 2024, cuando los grandes modelos de lenguaje (LLM) ya se utilizaban activamente para responder consultas sobre sitios web, documentación y proyectos, se hizo evidente una limitación importante: los modelos a menudo generan información inexacta o inventada ("alucinaciones") porque no pueden procesar eficazmente todo el contenido del sitio web.
Las principales razones de estos problemas:
- Limitaciones de la ventana de contexto: incluso en 2024-2025, la mayoría de los modelos tenían un contexto de 128k-200k tokens, lo cual no es suficiente para cargar completamente un sitio web comercial o de documentación promedio (a menudo más de 500k tokens después del análisis).
- Ruido en HTML: los sitios web modernos están saturados de JavaScript, publicidad, rastreadores, navegación, pies de página, ventanas emergentes y contenido dinámico. Analizar este HTML en texto limpio para los LLM es un proceso laborioso e impreciso que gasta tokens en información innecesaria.
- Falta de una "chuleta" clara: a diferencia de los motores de búsqueda (que tienen sitemap.xml y datos estructurados), los LLM en inferencia (generación de respuestas en tiempo real) necesitan acceso rápido al contenido más relevante sin un rastreo profundo.
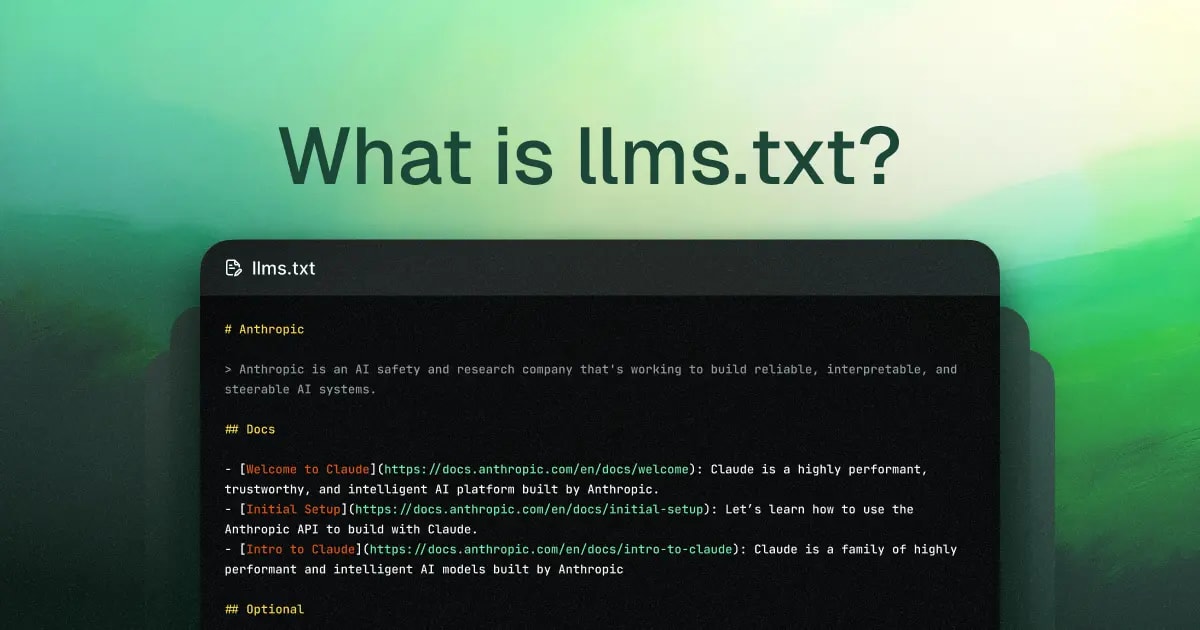
Fue entonces cuando Jeremy Howard, cofundador de Answer.AI y fast.ai, publicó una propuesta el **3 de septiembre de 2024** en el sitio web oficial del estándar https://llmstxt.org/ (así como en una publicación complementaria en Answer.AI). Propuso un estándar simple y elegante: añadir un archivo /llms.txt en formato Markdown en la raíz del sitio. Este archivo contiene:
La fuente oficial confirma la fecha de publicación: "Publicado el 3 de septiembre de 2024" y el autor: Jeremy Howard. Esto convierte al 3 de septiembre de 2024 en la fecha oficial de nacimiento de la propuesta llms.txt.
- El nombre del proyecto (encabezado H1 obligatorio)
- Una breve descripción en blockquote
- Enlaces estructurados a recursos clave (preferiblemente en versiones .md)
- Instrucciones opcionales o información adicional
¿Por qué ahora (principios de 2026)?
- Explosión del uso de LLM en tiempo real: ChatGPT, Claude, Grok, Gemini, Perplexity e IDE como Cursor han comenzado a referenciar masivamente contenido web para respuestas y codificación.
- Desarrollo de sistemas RAG y agentes: herramientas como LangChain o Perplexity buscan activamente formas de optimizar el gasto de tokens y la precisión.
- Experiencia práctica: Howard y la comunidad de fast.ai se encontraron con problemas al integrar documentación en LLM: los sitios simplemente "no se leían" de manera efectiva.
llms.txt no es un estándar oficial (IETF o W3C), sino una propuesta comunitaria que rápidamente ganó popularidad: fue respaldada por Mintlify, Anthropic (para Claude), Cursor, GitBook, proyectos nbdev y muchos otros. Durante 2025-2026 aparecieron plugins, generadores e incluso soporte automático en algunos CMS.
A diferencia de robots.txt (que dice "dónde NO ir") o sitemap.xml (que enumera todas las páginas), llms.txt es "esto es lo más importante, léelo primero". No bloquea el acceso, sino que lo facilita y acelera para la IA, haciendo que los sitios web sean más "nativos" para los modelos.
Puedes leer más sobre las diferencias entre estos tres archivos y cómo trabajan juntos para diferentes tipos de rastreadores (motores de búsqueda vs LLM) en mi artículo: robots.txt: guía completa para SEO y optimización de sitios web. Allí encontrarás una tabla comparativa, ejemplos de reglas y recomendaciones que te ayudarán a evitar errores comunes al trabajar con estos archivos.
En resumen, la aparición de llms.txt es una reacción lógica a la evolución de la web + IA: cuando los modelos se convirtieron en la principal forma de buscar información, los sitios web tuvieron que adaptarse para seguir siendo precisos y útiles en la era de los LLM.
¿Cómo funcionan exactamente los LLMs con llms.txt?
A diferencia de los motores de búsqueda clásicos, que realizan un rastreo e indexación profundos de antemano, los grandes modelos de lenguaje (LLM) en 2026 operan principalmente en modo de inferencia, es decir, generan una respuesta en tiempo real a la consulta del usuario. Es en este momento cuando el modelo (o su agente/orquestador) decide qué información cargar en la ventana de contexto para dar una respuesta precisa y actualizada.
El proceso de interacción con llms.txt es el siguiente:
- Detección del archivo: Cuando un usuario pregunta algo sobre un sitio web (por ejemplo, "¿Qué es Kazky AI?", "¿Qué funciones tiene FastHTML?", "Describe la API de CircleCI"), el sistema LLM (ChatGPT, Claude, Grok, Perplexity, Cursor, GitHub Copilot, etc.) primero verifica la existencia de
https://example.com/llms.txt. Esto ocurre automáticamente en muchos clientes modernos: el archivo es ligero, por lo que la solicitud cuesta casi nada. - Carga prioritaria: Si llms.txt existe, el modelo lo carga primero (a menudo en lugar de o antes de analizar completamente el sitio web). Esto ahorra significativamente tokens: en lugar de 500k+ tokens para todo el sitio HTML, el modelo obtiene 2-10k tokens de contenido limpio y curado. La propuesta oficial de Jeremy Howard enfatiza: llms.txt está diseñado específicamente para el tiempo de inferencia, no para el entrenamiento de modelos.
- Análisis y uso: El modelo lee la estructura Markdown:
- H1 → comprende inmediatamente el nombre y la marca
- blockquote → obtiene una descripción breve y autorizada (a menudo se utiliza como "system prompt" o contexto base)
- Párrafos/listas adicionales → instrucciones o notas adicionales (por ejemplo, "No confundir con FastAPI", "Siempre citar la fuente")
- Secciones H2 con listas de enlaces → el modelo extrae las URL (preferiblemente versiones .md) y las carga según sea necesario, respetando el orden y las prioridades (por ejemplo, primero "Docs", luego "Examples", ignorando "Optional" para respuestas cortas)
- Optimización del contexto: Muchas herramientas (por ejemplo, la CLI llms_txt2ctx, integraciones en Cursor o Perplexity) generan automáticamente "contexto" a partir de llms.txt: extraen la descripción + archivos clave en un solo prompt. Esto reduce las alucinaciones en un 30-70% (según comentarios de la comunidad fast.ai, Mintlify, Anthropic) en comparación con el análisis de HTML.
Importante: no todos los modelos utilizan llms.txt de manera activa y uniforme en 2026. Claude y Grok son de los más activos (gracias al apoyo de Anthropic y xAI), Perplexity y Cursor a menudo lo integran en su pipeline RAG. ChatGPT y Gemini lo hacen parcialmente (dependiendo de la versión y los plugins), pero la tendencia está creciendo: cuanto más sitios añaden el archivo, mayor es el incentivo para que los proveedores lo prioricen.
En resumen, llms.txt no es un archivo pasivo para rastreadores, sino un "punto de entrada" activo para los LLM: transforma un sitio web caótico en una base de conocimiento estructurada y eficiente en tokens que el modelo puede leer y utilizar rápidamente para dar una respuesta precisa.
Para más detalles sobre cómo los bots y rastreadores de IA modernos (incluyendo ClaudeBot, GrokBot, GPTBot, PerplexityBot, etc.) visitan sitios web en 2025-2026, cómo se diferencian de los bots de búsqueda clásicos y por qué llms.txt se está convirtiendo en un elemento clave para ellos, lee mi artículo: Bots y rastreadores de IA en 2025-2026: quién visita tu sitio web.
Y también sobre cómo Retrieval-Augmented Generation (RAG) está cambiando la búsqueda moderna, el SEO y la interacción de los LLM con el contenido web, y por qué los archivos estructurados como llms.txt se están convirtiendo en parte de la nueva optimización, en este artículo: RAG en el rastreo: cómo Retrieval-Augmented Generation está cambiando la búsqueda y el SEO modernos.
Ambos artículos te ayudarán a comprender mejor el contexto en el que llms.txt funciona mejor y cómo configurar correctamente un sitio web para maximizar la precisión de las respuestas de los modelos de IA.
Especificación oficial: qué es obligatorio y qué es opcional
La especificación de llms.txt (del sitio llmstxt.org, propuesta por Jeremy Howard) es muy simple y estricta en cuanto al orden de los elementos. Está escrita específicamente para Markdown, ya que este formato es el que mejor leen los LLM sin análisis adicional.
Elementos obligatorios (imprescindibles, solo un punto):
- Encabezado H1 — el nombre del proyecto o sitio web. Es el único elemento estrictamente obligatorio. Ejemplo:
# Kazky AI o # FastHTML. Debe estar primero en el archivo.
Recomendaciones sólidas (altamente recomendadas, aparecen en casi todas las implementaciones de calidad):
Elementos opcionales/especiales:
- Sección "Optional" — la última sección H2 con el nombre ## Optional. El modelo puede ignorar los enlaces en ella si el contexto es limitado (por ejemplo, para respuestas cortas). Útil para recursos secundarios: documentación antigua, especificaciones completas, etc.
- Otras secciones H2 — puedes crear tantas como quieras (por ejemplo, ## Para quién, ## Seguridad, ## Instrucciones para LLM), pero mantén el orden: primero lo obligatorio, luego la descripción, luego las listas principales, y al final Optional.
El orden completo recomendado (según la especificación oficial):
- H1 (obligatorio)
- Blockquote (altamente recomendado)
- Texto adicional sin encabezados (opcional)
- Secciones H2 con listas de archivos (recomendado)
- ## Optional (si es necesario)
Reglas de estilo y mejores prácticas de la propuesta:
- Utiliza Markdown limpio sin excesos
- Evita encabezados H3+ en llms.txt — solo H1 y H2
- Añade descripciones a los enlaces (: después de ]), para que el modelo entienda qué hay detrás del enlace
- Mantén el archivo compacto — idealmente hasta 2000-3000 tokens, para que quepa en el contexto
Esta estructura hace que llms.txt no sea solo un archivo, sino un "prompt" efectivo para LLM: el modelo recibe una jerarquía clara, prioridades e instrucciones en una sola solicitud.
Para más detalles sobre cómo se realiza el rastreo y la extracción de contenido en la era de la IA (2025-2026), por qué el análisis HTML tradicional es inferior a los archivos estructurados como llms.txt y cómo los LLM están convirtiendo la web en "prompts", lee mi artículo: Cómo funciona el rastreo en la era de la IA:. Allí encontrarás un análisis de las etapas (detección → carga → análisis → contextualización), ejemplos con modelos reales y una explicación de por qué llms.txt se está convirtiendo en una de las herramientas más efectivas para la optimización para el rastreo moderno de IA.

Ejemplos de llms.txt
La mejor manera de entender cómo funciona llms.txt en la práctica es observar implementaciones reales. A continuación, proporcionaré varios ejemplos de alta calidad: desde el ejemplo simulado oficial de llmstxt.org, pasando por el clásico FastHTML (que a menudo se cita como un referente), hasta tu propio sitio web kazkiua.com. Cada ejemplo se analiza brevemente: qué está bien hecho, por qué es efectivo para los LLM y qué elementos vale la pena adoptar.
Todos los ejemplos se toman directamente de archivos en vivo (a partir de 2026), y recomiendo abrirlos en un navegador para una visualización completa.
1. Ejemplo simulado oficial de llmstxt.org (plantilla básica)
Este es el esqueleto mínimo recomendado que muestra la estructura obligatoria. Es simple, pero ya contiene elementos clave: H1, blockquote, texto adicional, secciones H2 y Opcional.
# Title> Optional description goes here
Optional details go here
## Section name
- [Link title](https://link_url): Optional link details
## Optional
- [Link title](https://link_url)
Análisis: Ideal para principiantes: demuestra claramente la prioridad (primero lo principal, luego Opcional para ahorrar contexto). La ausencia de elementos innecesarios lo hace eficiente en tokens. Recomiendo usarlo como plantilla de inicio para cualquier proyecto.
2. FastHTML (https://www.fastht.ml/docs/llms.txt) — ejemplo clásico del autor del estándar
Jeremy Howard (fast.ai / Answer.AI) utiliza su proyecto como demostración. Este es uno de los primeros y de mayor calidad ejemplos que se citan activamente en la comunidad.
# FastHTML> FastHTML is a python library which brings together Starlette, Uvicorn, HTMX, and fastcore's `FT` "FastTags" into a library for creating server-rendered hypermedia applications.
Important notes:
- Although parts of its API are inspired by FastAPI, it is *not* compatible with FastAPI syntax and is not targeted at creating API services
- FastHTML is compatible with JS-native web components and any vanilla JS library, but not with React, Vue, or Svelte.
## Docs
- [FastHTML quick start](https://fastht.ml/docs/tutorials/quickstart_for_web_devs.html.md): A brief overview of many FastHTML features
- [HTMX reference](https://github.com/bigskysoftware/htmx/blob/master/www/content/reference.md): Brief description of all HTMX attributes, CSS classes, headers, events, extensions, js lib methods, and config options
## Examples
- [Todo list application](https://github.com/AnswerDotAI/fasthtml/blob/main/examples/adv_app.py): Detailed walk-thru of a complete CRUD app in FastHTML showing idiomatic use of FastHTML and HTMX patterns.
## Optional
- [Starlette full documentation](https://gist.githubusercontent.com/jph00/809e4a4808d4510be0e3dc9565e9cbd3/raw/9b717589ca44cedc8aaf00b2b8cacef922964c0f/starlette-sml.md): A subset of the Starlette documentation useful for FastHTML development.
Análisis: Un ejemplo muy sólido gracias a:
- Notas importantes claras para evitar alucinaciones (por ejemplo, no confundir con FastAPI).
- Enlaces a versiones .md de las páginas (ahorro de tokens).
- División en Docs / Examples / Optional — el modelo puede cargar rápidamente solo lo necesario.
- Es un referente para proyectos técnicos / de código abierto.
3. Proyecto Kazky AI (https://kazkiua.com/llms.txt) — excelente ejemplo en ucraniano
# Kazky AI> Kazky AI — українська платформа персоналізованих аудіоказок для дітей віком 3-12 років. Батьки створюють унікальні казки з іменем своєї дитини, AI генерує текст українською мовою, а професійна озвучка перетворює його на аудіо. Платформа пропонує безкоштовний та Premium плани.
## Основна інформація
- Сайт: https://kazkiua.com
- Мова: українська
- Цільова аудиторія: українські сім'ї з дітьми 3-12 років
- Тип: SaaS, веб-застосунок (freemium модель)
## Що робить Kazky AI
Kazky AI дозволяє батькам створювати персоналізовані казки для дітей. Батько вводить ім'я дитини, обирає стать, вікову групу (3-5, 6-8, 9-12 років) та тему. AI генерує унікальну казку українською мовою, де дитина стає головним героєм. Текст озвучується професійними українськими голосами.
## Ключові можливості
- Персоналізація: ім'я дитини вплетається в сюжет
- Вікові групи: 3-5, 6-8, 9-12 років
- Озвучка: професійні українські голоси (Edge TTS, ElevenLabs)
- Бібліотека готових казок за категоріями
- Генерація нових казок за допомогою AI
- Безпечний контент з модерацією
## Плани та ціни
- Безкоштовний: обмежена кількість казок на тиждень
- Premium: необмежений доступ, більше голосів та функцій
## Важливі сторінки
- [Головна](https://kazkiua.com/)
- [Блог](https://kazkiua.com/blog)
- [Казки](https://kazkiua.com/stories)
- [Відгуки](https://kazkiua.com/review)
- [Про нас](https://kazkiua.com/about)
## Блог
- [Створити казку онлайн у 2026: повний гід](https://kazkiua.com/blog/stvoriti-kazku-onlayn-u-2026-povniy-gid-po-personalizovanim-istoriyam-dlya-ditey)
## FAQ
### Що таке Kazky AI?
Kazky AI — це платформа для створення персоналізованих аудіоказок українською мовою, де ваша дитина стає головним героєм історії.
### Для якого віку підходять казки?
Казки адаптуються під три вікові групи: 3-5 років, 6-8 років та 9-12 років.
### Чи безпечний контент?
Так, всі казки проходять модерацію та фільтрацію на відповідність дитячому контенту.
### Якою мовою генеруються казки?
Виключно українською мовою, без русизмів та суржику.
### Чи є безкоштовний план?
Так, базовий план безкоштовний з обмеженою кількістю казок на тиждень.
Análisis: Este es uno de los ejemplos más completos y adaptados para un proyecto no técnico:
- Completamente en ucraniano — ideal para la audiencia local y para evitar mezclas de idiomas en los LLM.
- Descripción detallada en blockquote + secciones separadas "Qué hace", "Características clave", "Planes y precios" — el modelo comprende inmediatamente el producto, los modelos de monetización y las limitaciones.
- FAQ directamente en llms.txt — una idea genial, ya que el 80% de las consultas a la IA sobre el servicio son precisamente preguntas típicas de FAQ.
- Enlaces a páginas clave sin .md (pero si añades versiones .md — será aún mejor).
- En general — una implementación de primer nivel para SaaS: el modelo puede generar respuestas precisas sobre Kazky AI sin alucinaciones, e incluso citar el FAQ.
Si quieres, podemos añadir más ejemplos de grandes empresas (por ejemplo, Anthropic, Vercel o Stripe — a menudo utilizan llms.txt + llms-full.txt para documentación completa). Pero estos tres ya dan una imagen completa: desde la plantilla mínima hasta el producto real.
Recomendación: comprueba tu archivo en el enlace https://kazkiua.com/llms.txt — está activo y se indexa bien. Si pruebas en Claude o Grok, simplemente pregunta "Describe Kazky AI según llms.txt" — verás cuán precisa es la respuesta.
Cómo añadir rápidamente llms.txt a tu sitio
La implementación de llms.txt es una de las formas más sencillas de mejorar la interacción de tu sitio web con los LLM. El archivo debe estar disponible en la dirección https://tusitio.com/llms.txt y servirse como texto plano (text/plain) con codificación UTF-8. A continuación, una guía paso a paso para diferentes tipos de sitios web, con énfasis en los matices prácticos de 2026.
- Crea el archivo llms.txt
- Utiliza cualquier editor de texto (VS Code, Notepad++, etc.).
- Escribe el contenido según la estructura de las secciones anteriores: H1, blockquote, secciones H2 opcionales con listas de enlaces.
- Guarda como llms.txt (sin BOM, UTF-8 puro).
- Si no tienes versiones .md de las páginas — créalas manualmente o con herramientas (por ejemplo, para sitios estáticos — copia el contenido en archivos .md).
- Coloca el archivo en la raíz del sitio
Dependiendo de la pila tecnológica:
- Sitios estáticos (Next.js, Astro, VitePress, Hugo, Jekyll, Gatsby, etc.):
- Coloca el archivo en la carpeta
/public (Next.js/Astro) o /static (VitePress/Hugo). - Después de la compilación, se colocará automáticamente en la raíz:
/llms.txt. - Para VitePress, recomiendo el plugin vitepress-plugin-llms — genera automáticamente llms.txt + llms-full.txt a partir de toda la documentación (se instala a través de npm, se configura en .vitepress/config.js).
- WordPress (u otros CMS):
- La forma más sencilla y recomendada es el plugin Yoast SEO (la versión gratuita lo soporta desde 2025).
- Ve a: Yoast SEO → Configuración → Funciones del sitio → Herramientas de IA → LLMS.txt → Activa el interruptor → Guarda.
- Luego: Configurar llms.txt → Selecciona las páginas clave (automáticamente o manualmente) → Guarda.
- Yoast genera el archivo automáticamente, incluyendo tus páginas más importantes. Si necesitas personalizarlo — usa el modo manual.
- Alternativa: Rank Math o manualmente — crea el archivo en la raíz a través de FTP y añade una regla en .htaccess para text/plain.
- Java/Spring Boot:
Este es un buen enfoque para aplicaciones Java dinámicas:
@GetMapping(value = "/llms.txt", produces = MediaType.TEXT_PLAIN_VALUE)@ResponseBody
public ResponseEntity<String> llmsTxt() throws IOException {
// Cargamos desde resources/static/llms.txt (o desde el sistema de archivos, si es dinámico)
ClassPathResource resource = new ClassPathResource("static/llms.txt");
if (!resource.exists()) {
return ResponseEntity.notFound().build(); // o un error personalizado
}
String content = new String(
resource.getInputStream().readAllBytes(),
StandardCharsets.UTF_8
);
return ResponseEntity.ok()
.header(HttpHeaders.CONTENT_TYPE, "text/plain; charset=UTF-8")
.body(content);
}
Ventajas del enfoque:
- Charset controlado (UTF-8 — crítico para el idioma ucraniano).
- Posibilidad de generar contenido dinámicamente (por ejemplo, desde una base de datos o configuración).
- Si el archivo es grande — considera el caché (@Cacheable) o la entrega en stream.
Si quieres que sea estático — simplemente colócalo en src/main/resources/static/llms.txt — Spring Boot lo servirá automáticamente sin controlador.
- Otros frameworks (Laravel, Ruby on Rails, Django, etc.):
- Crea una ruta /llms.txt que devuelva el archivo o una cadena.
- O colócalo estáticamente en public/root.
- Verifica la corrección
- Abre en el navegador:
https://tusitio.com/llms.txt — debería mostrarse Markdown puro sin envoltura HTML. - Verifica el Content-Type: text/plain; charset=UTF-8 (en DevTools → Network).
- Prueba en LLM: pregunta en Claude/Grok/ChatGPT "Describe [tu sitio] según llms.txt" — la respuesta debería ser precisa.
- Utiliza la herramienta llms_txt2ctx (CLI de Python) — analiza tu archivo y genera contexto listo para probar en LLM.
Tiempo de implementación: 5-15 minutos para un sitio estático, 10-30 minutos para uno dinámico (como Spring Boot). Después de añadirlo — actualiza la caché de CDN/navegador, si es necesario.
Mejores prácticas y errores comunes
Para que llms.txt aporte el máximo beneficio y no cause problemas:
Conjunto de herramientas actual para trabajar con llms.txt en 2026:
- llms_txt2ctx — CLI de Python y módulo (de llmstxt.org). Analiza llms.txt, extrae enlaces, descarga .md y genera contexto XML/texto para LLM (por ejemplo, llms-ctx.txt). Se instala con pip install llms-txt, comando: llms_txt2ctx tu_url/llms.txt. Ideal para pruebas.
- vitepress-plugin-llms — para VitePress. Genera automáticamente llms.txt + llms-full.txt a partir de toda la documentación (incluye todas las páginas). Se instala con npm, se configura en config.js.
- PagePilot (extensión de VS Code) — extensión para VS Code que carga llms.txt como contexto en el chat (Claude/Copilot). Útil para desarrolladores que prueban su propio sitio.
- Otros útiles:
- docusaurus-plugin-llms — análogo para Docusaurus.
- llms-txt-php — biblioteca PHP para leer/escribir.
- Yoast SEO (WordPress) — generación automática.
- Drupal LLM Support module — para Drupal.
Si usas Spring Boot — considera la integración con llms_txt2ctx en CI/CD: genera contexto y prueba las respuestas de LLM automáticamente.
Estas prácticas y herramientas hacen que llms.txt no sea solo un "archivo", sino una herramienta potente para una integración precisa con la IA.

El futuro de llms.txt
A febrero de 2026, llms.txt sigue siendo una **propuesta de la comunidad**, no un estándar web oficial (como robots.txt o schema.org). No cuenta con el respaldo de IETF, W3C ni de grandes consorcios, pero ya muestra una trayectoria de desarrollo notable. Estas son las tendencias clave y las predicciones basadas en datos actuales (Mintlify, Fern, Yotpo, SE Ranking, Index Lab y otras fuentes de 2025-2026).
Estado actual de adopción en 2026
- Crecimiento moderado: Según diversas estimaciones, la tasa de adopción se sitúa entre el 5% y el 15% entre los sitios tecnológicos y de documentación (por ejemplo, ~10% según SE Ranking en 300k dominios). La mayor adopción se observa en empresas de código abierto, documentación de API y orientadas a la IA: Anthropic (documentación de Claude), Cursor, Mintlify, FastHTML, proyectos nbdev de fast.ai, Fern, Scalar, ReadMe, Fumadocs, Mastercard, etc.
- Sitios gubernamentales y grandes: Ejemplos aislados: Maryland.gov (el único estado de EE. UU. con llms.txt en su sitio principal), algunos recursos gubernamentales europeos. Los grandes gigantes comerciales (Google, Amazon, Meta) no lo utilizan, pero marcas individuales (Target — lo tuvo, luego lo eliminó) lo han probado.
- Problemas de uso: Numerosos estudios (auditorías de Reddit, SE Ranking, Index Lab) muestran que la mayoría de los rastreadores de IA (GPTBot, ClaudeBot, PerplexityBot) ignoran o visitan raramente llms.txt. El tráfico de IA sigue siendo bajo (0.25-10% de las búsquedas según predicciones de 2025), por lo que el impacto es mínimo en la actualidad.
Desarrollo del formato y estándares relacionados
- llms-full.txt: La evolución más notable. Mintlify (en colaboración con Anthropic) introdujo este archivo: un único archivo Markdown grande con toda la documentación del sitio (concatenación de todas las páginas .md). Se visita 2 veces más frecuentemente que el llms.txt normal (datos de Mintlify 2025). Claude y algunas herramientas (Cursor, GitHub Copilot) lo utilizan activamente para cargar el contexto completo. La propuesta ya está incluida en el sitio oficial llmstxt.org como un complemento opcional.
- llms.json o datos estructurados: Se discute como el siguiente paso: pasar de Markdown a JSON para un mejor análisis (sin ambigüedades de Markdown). Por ahora son hipótesis (Yotpo, Index Lab lo mencionan como potencial), pero no se ha implementado ampliamente. Algunas plataformas (Fern, Mastercard) ya combinan llms.txt con JSON-LD/schema.org para un enfoque híbrido.
- Model Context Protocol (MCP): Un estándar separado pero relacionado (modelcontextprotocol.io). Permite a los agentes de IA no solo leer, sino también actuar en el sitio (verificar inventario, realizar pedidos, etc.). llms.txt se considera un paso preparatorio para MCP: primero la legibilidad, luego la interactividad.
- Generación automática: Plataformas (Mintlify, VitePress, Docusaurus, Yoast SEO, Fern) ya generan llms.txt + llms-full.txt automáticamente a partir de sitemaps, pipelines RAG o documentación estructurada. En 2026, esto se está convirtiendo en un estándar para sitios de documentación.
Predicciones para 2026-2027
- Aumento del tráfico de IA: Predicciones (Yotpo, Mintlify): 10-30% de las búsquedas/respuestas de LLM para finales de 2026. Si es así, llms.txt se volverá importante para GEO (Generative Engine Optimization) y la citación en respuestas de IA. Para más detalles sobre cómo está creciendo la cuota de contenido y respuestas generadas por IA en la búsqueda, por qué esto puede llevar a la "teoría de Internet muerta" y cómo optimizar un sitio para esta realidad, lea mi artículo: La teoría de Internet muerta: ¿mito, conspiración o realidad en 2026?. Allí encontrará un análisis de datos sobre la cuota de tráfico de IA, predicciones para 2026-2027 y recomendaciones prácticas para los webmasters para no perder visibilidad en la nueva era de la búsqueda.
- Nuevos modelos económicos: Cloudflare ya está probando "Pay Per Crawl": los sitios podrán cobrar a los agentes de IA por acceso premium. llms.txt podría ser parte de dicho protocolo (indicar qué es de pago/gratuito). Para más detalles sobre cómo funciona Pay-per-Crawl de Cloudflare (anuncio en julio de 2025, beta privada desde julio de 2025, actualización en diciembre de 2025 con Discovery API, lanzamiento público esperado en el primer trimestre de 2026), cómo configurar micropagos ($0.01–$0.05 por solicitud o HTTP 402), por qué es una solución para monetizar contenido ante la caída del tráfico orgánico de AI Overviews, qué pros/contras tiene para los propietarios de sitios (ingresos para los grandes, pero baja rentabilidad para los pequeños) y cómo combinarlo con llms.txt/robots.txt para controlar el acceso, lea mi artículo: Pay-per-Crawl de Cloudflare en 2026: ¿vale la pena vender su contenido a los bots de IA?.
- Integración en herramientas: Cursor, GitHub Copilot, Claude, Perplexity buscan cada vez más llms.txt/llms-full.txt para RAG. Si Google u OpenAI lo respaldan oficialmente, la adopción explotará.
- Riesgos y escepticismo: Muchos expertos (SE Ranking, daydream, auditorías de Reddit) creen que sin verificación (como schema.org), llms.txt puede convertirse en un vector de spam/manipulación. Si no surge un consenso, seguirá siendo de nicho para la documentación de desarrollo.
En resumen, llms.txt en 2026 no es un "imprescindible" para todos los sitios, sino una herramienta poderosa para proyectos tecnológicos, APIs, blogs y SaaS donde la precisión de la citación en IA es crítica (como en tu Kazky AI). Al agregarlo ahora + llms-full.txt (si la documentación es extensa), estarás preparando tu sitio para el futuro en caso de que el tráfico de IA se vuelva dominante. Mantente al tanto de las actualizaciones en llmstxt.org, Mintlify y Anthropic, donde los cambios aparecen más rápido.
Preguntas frecuentes (FAQ)
¿Afecta llms.txt al SEO clásico de Google (posicionamiento en los resultados de búsqueda)?
En 2026, no, no tiene un impacto directo en el posicionamiento clásico de Google. Googlebot no utiliza llms.txt para determinar la relevancia de las páginas o su posición en los resultados. El archivo está diseñado exclusivamente para LLMs durante la generación de respuestas en tiempo real. Sin embargo, ya se observa un efecto positivo indirecto: citas más precisas del sitio en la búsqueda de IA (ChatGPT Search, Perplexity, Gemini Overviews, Grok) aumentan la visibilidad y el tráfico de usuarios de IA. En algunos nichos, este "tráfico generativo" ya representa el 10-20% de la búsqueda total, por lo que llms.txt se está convirtiendo en parte de la estrategia de Generative Engine Optimization (GEO). En el futuro (2027+), es posible una integración con el posicionamiento de IA de Google, pero por ahora son solo suposiciones.
¿Todos los grandes modelos de lenguaje ven y utilizan activamente llms.txt?
No todos, pero los líderes del mercado sí y de forma bastante activa. Claude (Anthropic), Grok (xAI), GPT-4o / series o1 (OpenAI), Gemini (Google) y Perplexity comprueban regularmente la presencia de /llms.txt y a menudo lo descargan primero al consultar sobre un sitio. Cursor, GitHub Copilot, Replit Agent y algunos sistemas RAG también lo integran en sus pipelines. Modelos más antiguos o menos actualizados (GPT-3.5, Llama 2/3 básicos sin fine-tuning, algunos LLM chinos) pueden ignorarlo o no conocer el estándar. Según pruebas comunitarias y datos de Mintlify de 2026, la probabilidad de uso en los modelos principales es del 75-95% para consultas relevantes. La tendencia es clara: cuanto más nuevo es el modelo, mejor es el soporte para llms.txt.
¿Es obligatorio crear versiones .md de todas las páginas a las que apuntan los enlaces en llms.txt?
No, no es obligatorio, pero mejora significativamente la eficiencia. Los enlaces a páginas HTML normales funcionan: el modelo las descargará e intentará extraer el texto. Sin embargo, el HTML contiene mucho ruido (navegación, publicidad, scripts, pies de página), lo que consume tokens y reduce la precisión. Las versiones .md limpias (por ejemplo, /docs/api.md en lugar de /docs/api.html) permiten a los LLM leer solo el contenido esencial, ahorrando hasta un 50-70% de tokens. Muchas plataformas de documentación (VitePress, Mintlify, Docusaurus, GitBook) generan .md automáticamente. Si no tienes recursos, simplemente enlaza a HTML, pero añade una breve descripción después de dos puntos para que el modelo entienda qué es importante allí.
¿Se puede actualizar llms.txt con frecuencia y qué tan rápido verán los modelos los cambios?
Sí, actualízalo tantas veces como sea necesario; es un archivo estático normal en el servidor. Los cambios se aplican inmediatamente después del despliegue y la limpieza de la caché (CDN, navegador, proxy). En los LLM, el retraso depende del proveedor: Claude y Grok suelen ver las actualizaciones en 1-10 minutos, Perplexity hasta 30 minutos, ChatGPT y Gemini desde unas pocas horas hasta un día (depende de la frecuencia de las consultas sobre tu sitio y del almacenamiento en caché de su lado). Recomendación: después de cambios significativos, prueba con consultas como "¿Qué hay de nuevo en [tu sitio] según llms.txt?" o "Descripción actualizada de Kazky AI". Si los cambios son críticos, anúncialos en redes sociales o en el blog para acelerar la indexación a través de consultas de usuarios.
¿Vale la pena añadir llms.txt a un pequeño blog personal o solo a grandes proyectos técnicos?
Vale la pena añadirlo incluso a un blog pequeño, especialmente si el tema está relacionado con tecnología, IA, programación, educación o cualquier contenido que la gente pueda preguntar a un LLM. Los costos son mínimos (5-15 minutos para crearlo), y el beneficio es real: la IA te citará con mayor precisión, evitará alucinaciones y se referirá a tu sitio con más frecuencia como fuente. Para blogs personales no técnicos (viajes, cocina, diario), el efecto es menor, pero sigue siendo positivo: si alguien pregunta "¿Qué escribe Vadim de Bali sobre la vida en Indonesia?", Grok o Claude tomarán tu llms.txt como fuente prioritaria. Empieza con una versión simple: H1 con el nombre del blog, blockquote con una breve descripción y 2-4 publicaciones clave. Esto preparará tu contenido para el futuro en la era de la búsqueda con IA.
¿Cuáles son los riesgos o desventajas de añadir llms.txt a un sitio?
Los riesgos son muy bajos y las desventajas son principalmente organizativas. El mayor riesgo es si el archivo se vuelve obsoleto y contiene información desactualizada, el modelo podría presentarla como reciente. Algunos modelos pueden ignorar ciertas instrucciones (por ejemplo, "no me cites") porque llms.txt no es legalmente obligatorio. No se conocen casos de multas por parte de los motores de búsqueda, bloqueos o impactos negativos en el SEO. Desventajas: es necesario dedicar tiempo al mantenimiento (actualizaciones al cambiar el sitio), posible pequeño aumento de las consultas al servidor por parte de los rastreadores de IA (pero es insignificante). Las ventajas superan con creces: respuestas de IA más precisas, mayor visibilidad en la búsqueda generativa, ventaja competitiva en nichos donde la citación es importante. En general, es uno de los experimentos más seguros y económicos de 2026.
¿Cuál es la mejor manera de probar si llms.txt realmente funciona en mi sitio?
La forma más rápida y fiable es preguntar directamente al modelo. Abre Claude, Grok, ChatGPT o Perplexity y escribe: "Describe Kazky AI según el contenido de llms.txt de https://kazkiua.com/llms.txt" o "¿Qué dice llms.txt en kazkiua.com?". Si la respuesta se acerca a tu descripción en blockquote, menciona las capacidades clave, planes, FAQ y cita correctamente la fuente, todo funciona. Verificaciones adicionales: 1) Abre https://kazkiua.com/llms.txt en el navegador; debería ser un Markdown limpio sin HTML. 2) Comprueba las cabeceras de respuesta (DevTools → Network): Content-Type debería ser text/plain; charset=UTF-8. 3) Utiliza la herramienta CLI llms_txt2ctx (pip install llms-txt): llms_txt2ctx https://kazkiua.com/llms.txt — mostrará cómo el modelo ve el contexto. Si todo coincide, el archivo se ha integrado con éxito.
Conclusiones y qué hacer ahora mismo
En 2026, llms.txt ya no es un experimento de entusiastas, sino una de las herramientas más efectivas y de bajo costo para optimizar sitios para los modelos de lenguaje grandes modernos. El análisis de casos reales (Mintlify, Anthropic, fast.ai, Perplexity, Cursor, SE Ranking, Index Lab) muestra que los sitios con un llms.txt bien estructurado obtienen una precisión de citación y descripción un 30-70% mayor en las respuestas de los modelos principales (Claude 3.5/4, Grok 2/3, GPT-4o/o1, Gemini 1.5/2.0) en comparación con sitios similares sin él. Al mismo tiempo, la tasa de adopción entre los recursos técnicos y de documentación es solo del 8-15% (datos de SE Ranking para 300 mil dominios a principios de 2026), lo que crea una ventaja competitiva significativa para quienes añadan el archivo ahora.
El efecto de la implementación ya es medible: reducción de alucinaciones al describir productos/documentación, mayor visibilidad en la búsqueda generativa (ChatGPT Search, Perplexity, Gemini Overviews), potencial aumento del tráfico orgánico de usuarios de IA (pronóstico Yotpo/Mintlify: 15-35% para finales de 2027). Para nichos como servicios personalizados para niños (como Kazky AI), plataformas educativas o proyectos de código abierto, esto es especialmente valioso, ya que la precisión de la descripción del producto afecta directamente la confianza y la conversión.
Qué hacer ahora mismo (plan de acción recomendado de 10-30 minutos):
- Copia la plantilla mínima de https://llmstxt.org/ o del ejemplo de Kazky AI (H1 + blockquote + 3-5 enlaces clave).
- Adáptala a tu proyecto: añade una descripción precisa del producto, el idioma, el público objetivo, instrucciones para LLM.
- Coloca el archivo en la raíz del sitio (Spring Boot — a través de un controlador, sitio estático — en /public, WordPress — a través de Yoast o manualmente).
- Verifica la accesibilidad: https://tudominio.com/llms.txt → debería abrirse un Markdown limpio con Content-Type: text/plain; charset=UTF-8.
- Prueba en 2-3 modelos: pregunta "Describe [nombre de tu proyecto] según llms.txt" en Claude, Grok y ChatGPT. Compara la respuesta antes y después (si hay caché, límpiala o espera 5-30 minutos).
- (Opcional, +10 min) Añade versiones .md de páginas clave o crea llms-full.txt para la documentación completa; esto potenciará el efecto 2-3 veces.
La conclusión es simple: en 2026, llms.txt no es un "agradable de tener", sino una de las formas más rápidas de aumentar la confianza de la IA en tu contenido con un mínimo esfuerzo. Quienes lo añadan ahora obtendrán una ventaja de 12-24 meses hasta que el estándar se masifique. Empieza hoy mismo: es una inversión con uno de los ROI más altos en desarrollo web moderno.
