
LLMS.txt: Making Your Site AI-Ready for ChatGPT, Claude, and Grok in 5 Minutes
In 2025–2026, AI models (ChatGPT, Claude, Grok, Gemini) are already driving 10–30% of search traffic and queries (per Mintlify and Yotpo forecasts). But for them, most websites are just noise: ads, heavy JavaScript, menus, and footers. What if you could hand these models a single, clean page containing only the essentials? This is exactly why Jeremy Howard proposed llms.txt on September 3, 2024, at https://llmstxt.org/. It’s a Markdown file living at your site’s root (
/llms.txt) that top-tier models already prioritize—slashing hallucinations and boosting citation accuracy for your project by 30–70%.
⚡ TL;DR
- ✅ What is it: A specialized
/llms.txtfile in your root directory, written in Markdown specifically for LLMs. - ✅ The Purpose: To let AI models instantly see your most critical content without parsing through HTML garbage.
- ✅ Difference from robots.txt: It doesn't block; instead, it serves up your best "signal."
- 🎯 Your Takeaway: A clear guide + ready-to-use template + implementation examples + verification steps.
- 👇 Deep Dive Below — featuring real-world code and architecture patterns.
Table of Contents:
- 📌 What is llms.txt and why did it emerge now?
- 📌 How LLMs actually interact with llms.txt
- 📌 Official Spec: Must-haves vs. Nice-to-haves
- 📌 Real-world llms.txt examples (including kazkiua.com)
- 📌 Quick Implementation (WordPress, Next.js, Hugo, etc.)
- 💼 Best Practices & Common Pitfalls
- 💼 Tools & Plugins for Generation and Testing
- 💼 The Future of llms.txt: What’s Next?
- ❓ FAQ
- ✅ Conclusions & Immediate Action Items
What is llms.txt and Why Did It Emerge Now?
By September 2024, as Large Language Models (LLMs) became the go-to for querying documentation and site data, a massive bottleneck became obvious: models were frequently hallucinating or providing outdated info because they couldn't efficiently ingest an entire website's content.
The core architectural pain points were:
- Context Window Constraints: Even in 2024–2025, most models operated within 128k–200k token windows. That’s not enough to fully load a mid-sized commercial or documentation site, which often hits 500k+ tokens after parsing.
- HTML Noise: Modern sites are cluttered with JS, ads, trackers, nav-bars, and pop-ups. Stripping this into clean text for an LLM is a resource-heavy, imprecise process that wastes tokens on "junk."
- Lack of a "Cheat Sheet": Unlike traditional search engines (which have
sitemap.xmland structured data), LLMs during inference (real-time generation) need lightning-fast access to the most relevant content without a deep crawl.
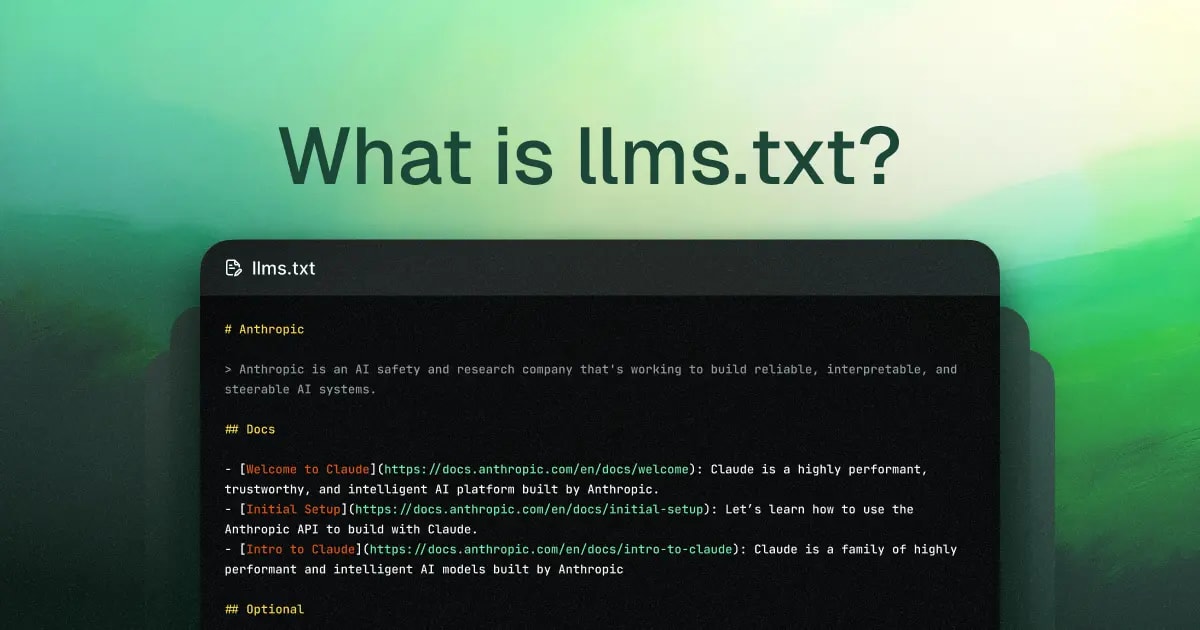
That’s when Jeremy Howard, co-founder of Answer.AI and fast.ai, dropped the proposal on September 3, 2024. He suggested a simple, elegant standard: place an /llms.txt Markdown file in your root. This file acts as a structured entry point containing:
- Project name (Required H1 header)
- Brief description (in a blockquote)
- Structured links to key resources (preferably
.mdversions) - Optional instructions or metadata
Why is this peaking in early 2026?
- Explosion of Real-Time LLM Usage: ChatGPT, Claude, and IDEs like Cursor now rely heavily on live web-browsing for coding and research.
- RAG & Agent Maturity: Tools like LangChain and Perplexity are aggressively optimizing for token efficiency and grounding.
- The "Fast.ai" Influence: The community realized that if an AI can’t "read" your site efficiently, your project effectively doesn't exist in the AI-mediated search era.
While not an IETF or W3C official standard yet, llms.txt has seen massive community adoption from Mintlify, Anthropic, Cursor, and GitBook. Think of it this way: robots.txt tells bots where not to go; llms.txt tells them where the gold is. For a deeper dive into how these files coexist, check out my guide on robots.txt for SEO and Optimization.
How LLMs Actually Interact with llms.txt
Unlike legacy search engines that crawl and index in advance, 2026-era LLMs largely operate in inference mode. When a user asks a question, the model (or its agentic orchestrator) must decide exactly what info to pull into the context window right then and there.
The interaction flow typically looks like this:
- Discovery: When a user asks about your project, the AI system (ChatGPT, Perplexity, Cursor, etc.) checks for
https://example.com/llms.txt. Because it's lightweight, this request is practically free. - Priority Loading: If found, the model loads this file first. Instead of burning 500k tokens on a messy HTML crawl, it gets 2k–10k tokens of pure, curated context. As Jeremy Howard noted, this is designed for inference time, not training.
- Parsing the Signal: The model decodes the Markdown structure:
- H1: Immediate brand/project identification.
- Blockquote: High-authority summary (often treated as a "system prompt" or core grounding).
- H2 Sections: The model extracts URLs (preferably Markdown) and fetches them as needed, following the priority order you've set.
- Context Optimization: Tools like
llms_txt2ctxCLI or Cursor integrations automatically bundle these links into a single prompt. This reduces hallucinations by 30–70% because the model isn't guessing based on fragmented HTML snippets.
In short, llms.txt isn't just a static file for crawlers; it’s an active entry point that turns a chaotic website into a token-efficient knowledge base. To understand the broader landscape of how bots like ClaudeBot or PerplexityBot visit your site, read my breakdown of AI Bots and Crawlers in 2025–2026.
Official Spec: Must-haves vs. Recommendations
The llms.txt spec is intentionally lean. It’s built on Markdown because that’s the "native language" of LLMs—no complex parsing required.
Required (Must-have):
- H1 Header: The project or site name. This must be the very first element. Example:
# Kazky AI.
Strongly Recommended (Found in all high-quality implementations):
- Blockquote: A 1–3 sentence summary. This block often becomes the model's "mental model" of your site.
A personalized fairy tale generator in Ukrainian for children aged 3–12. Safe, moderated, and culturally relevant.
- Unstructured Markdown: Paragraphs or lists providing specific instructions (e.g., "Always cite sources," "Incompatible with React").
- H2 Sections with File Lists: Grouped links to detailed resources (e.g.,
## Docs,## API). Format:- [Title](URL): Optional description. Pro Tip: Link to .md versions whenever possible to keep the signal high.
The "Optional" Section:
- The final H2 should be titled
## Optional. Models may ignore these links if they are running low on context window space. Use this for legacy docs or deep specs.
Architectural Style Rules:
- Keep it clean: Markdown only.
- Limit depth: Use H1 and H2 only; avoid H3+.
- Conciseness is king: Aim for under 3,000 tokens so the entire index fits in any model's context easily.
This structure transforms your site into a curated prompt. For more on how RAG (Retrieval-Augmented Generation) uses files like this to redefine search, see RAG in Crawling: How AI is Changing SEO.

