У лютому 2026 Anthropic випустив Claude Opus 4.6 — модель, яка вперше в Opus-лінійці отримала 1M токенів контексту та суттєво просунулася в agentic coding, enterprise-задачах і складному reasoning. Багато хто каже: «Opus 4.6 — це просто дорожчий Sonnet». Але насправді це якісний стрибок там, де Sonnet 4.6 вже не тягне: довгі контексти, найскладніші задачі та стабільність у реальних enterprise-кейсах.
Спойлер: Opus 4.6 вартий своїх $5/$25, якщо у вас великі кодбейси, юридичні/фінансові документи або задачі, де помилка коштує дорого. Для 80% задач вистачить Sonnet 4.6.
⚡ Коротко
- ✅ Ключова думка 1: Перший Opus з 1M контексту (beta) — MRCR v2 76% при 1M токенах (проти ~18.5% у Sonnet 4.5)
- ✅ Ключова думка 2: Лідер на Terminal-Bench 2.0 (65.4%), GPQA Diamond (91.3%), ARC-AGI-2 (68.8%), GDPval-AA (1606 Elo)
- ✅ Ключова думка 3: Adaptive Thinking + Effort Controls дозволяють контролювати глибину мислення (low → max), що економить токени на простих задачах
- 🎯 Ви отримаєте: Чітку decision matrix — коли брати Opus 4.6, а коли Sonnet 4.6 заощадить 60–80%
- 👇 Нижче — детальні пояснення, приклади та таблиці
📚 Зміст статті
🎯 Дата виходу та доступність (лютий 2026)
Реліз Opus 4.6
Claude Opus 4.6 офіційно вийшов 5 лютого 2026 року (анонс Anthropic). Це оновлення флагманської моделі після Opus 4.5 (листопад 2025). Модель доступна негайно на claude.ai (плати Pro, Max, Team, Enterprise), через Claude API (модель ID: claude-opus-4-6), Amazon Bedrock, Google Vertex AI та Microsoft Azure Foundry.
Opus 4.6 — це не мінорний патч, а суттєве розширення можливостей у довгому контексті та стабільності agentic задач, з першим 1M token context window у класі Opus (beta-режим).
Офіційний анонс: Introducing Claude Opus 4.6 (Anthropic, 5 лютого 2026). Модель позиціонується для задач з високими вимогами до кодингу, агентів та professional/enterprise workflows. 1M token context window доступний лише в beta на Developer Platform (з підвищеною ціною для запитів понад 200k токенів); стандартний контекст — 200k токенів.
Чому це важливо + темп релізів
Інтервал між Opus 4.6 (5 лютого) та Sonnet 4.6 (17 лютого) склав лише 12 днів. Це вказує на прискорений цикл ітерацій Anthropic у 2026 році, з фокусом на enterprise-застосування (agentic coding, long-context reasoning, tool use). Для розробників, які інтегрують моделі через API, це означає необхідність швидкого тестування та оновлення endpoint'ів, оскільки нові версії часто приносять не тільки бенчмарк-апгрейди, а й зміни в стабільності та поведінці на edge-кейсах.
Висновок розділу: Якщо ви використовуєте Claude через API або працюєте з production-задачами — перевірте сумісність з claude-opus-4-6 вже зараз, бо модель доступна з дня релізу.
📌 Архітектура та ключові технології
Hybrid reasoning з Adaptive Thinking, Effort Controls та 1M контекстом (beta)
Claude Opus 4.6 — це hybrid reasoning модель, яка поєднує стандартний режим відповідей з можливістю extended thinking. Основні нові компоненти: Adaptive Thinking (динамічне визначення глибини reasoning), Effort Controls (чотири рівні: low, medium, high, max), 1M token context window (beta, тільки на Developer Platform для >200k токенів), Context Compaction (beta) для довготривалих сесій та 128K max output tokens.
Opus 4.6 переходить від бінарного вибору extended thinking до динамічного управління глибиною reasoning, що дозволяє балансувати між точністю, latency та витратами токенів.
Згідно з офіційним анонсом Anthropic від 5 лютого 2026 (Introducing Claude Opus 4.6) та документацією API (Adaptive Thinking docs, Effort docs), модель зберігає базову архітектуру Claude 4.x, але суттєво розширює контроль над reasoning-процесом. Раніше (у Opus 4.5 та попередніх) extended thinking був або увімкнений з фіксованим бюджетом токенів (budget_tokens, тепер deprecated), або вимкнений. У 4.6 введено Adaptive Thinking: модель самостійно оцінює складність запиту та вирішує, коли активувати глибше мислення (interleaved thinking автоматично вмикається).
Ключовий параметр — effort (чотири рівні):
- low: мінімум extended thinking, швидкі відповіді, низькі витрати — підходить для простих запитів;
- medium: помірне використання thinking, компроміс між швидкістю та якістю;
- high (default): модель майже завжди застосовує adaptive thinking на складних задачах;
- max: максимальна глибина reasoning, найвища точність, але найбільші витрати токенів і latency.
Це дозволяє розробникам програмно налаштовувати баланс intelligence / speed / cost через API-параметр effort.
1M token context window — вперше для Opus-класу, але тільки в beta-режимі на Claude Developer Platform. Стандартний контекст — 200K токенів (як у попередніх моделях). Для запитів >200K застосовується преміум-ціна ($10/$37.50 за млн input/output токенів). Context Compaction (beta) — механізм автоматичного саммаризування старого контексту в довгих сесіях/agentic workflows, щоб уникнути перевищення лімітів без втрати критичної інформації.
Max output tokens збільшено до 128K (проти 64K у Sonnet 4.6 та попередніх Opus), що корисно для генерації великих кодів, звітів або планів.
Механіка Adaptive Thinking та Effort
Перехід до adaptive + effort — це не косметична зміна, а фундаментальне покращення ефективності на production-задачах. Модель більше не витрачає токени на overthinking простих запитів (наприклад, короткий код-рев'ю), але може глибоко аналізувати складні (multi-step agent planning, large codebase debugging). На практиці це зменшує загальні витрати токенів на 20–50% для mixed workloads (за відгуками ранніх користувачів у docs та System Card). Deprecated budget_tokens означає, що старі інтеграції потребуватимуть міграції на adaptive + effort до наступних релізів.
У System Card (лютий 2026) зазначено, що adaptive thinking покращує self-correction та consistency в agentic задачах, зменшуючи ймовірність "lazy" або поверхневих відповідей. Це особливо помітно на бенчмарках типу Terminal-Bench 2.0 та OSWorld-Verified, де потрібна sustained reasoning.
Практичні наслідки для розробників
- ✔️ Почніть з
effort: "high" (default) для тестування — потім оптимізуйте вниз для cost-sensitive задач; - ✔️ Для agentic workflows комбінуйте з Context Compaction, щоб сесії тривали довше без ручного чанкінгу;
- ✔️ 1M контекст (beta) — тестувати тільки на Developer Platform, бо в claude.ai / стандартних планах — 200K;
- ✔️ Міграція: якщо використовували
thinking: {type: "enabled", budget_tokens: N} — замініть на thinking: {type: "adaptive"} + effort.
Adaptive Thinking та Effort Controls : роблять Opus 4.6 більш гнучким і економічним інструментом для production, ніж попередні моделі, де контроль над reasoning був обмежений.
🎯 Long-context capabilities: MRCR v2 76% при 1M токенах
Значне покращення usable long-context
На 8-needle 1M варіанті MRCR v2 (Multi-Round Coreference Resolution) Opus 4.6 досягає 76% Mean Match Ratio (офіційно від Anthropic). Для порівняння: Sonnet 4.5 — 18.5% на тому ж тесті. Це вказує на суттєве зменшення context rot — деградації точності при заповненні контексту понад 100–200k токенів.
Anthropic називає це "qualitative shift" у usable context: модель не просто тримає 1M токенів, а реально використовує їх без суттєвої втрати recall та reasoning quality.
MRCR v2 (від OpenAI, v2 fix з грудня 2025) — це needle-in-a-haystack з multi-round coreference: в контекст ховається 8 ідентичних "голок" (наприклад, 8 віршів на тему), і модель повинна витягнути конкретну (наприклад, 4-й). Це тестує не тільки retrieval, а й sequential reasoning та distinction в довгому контексті. На відміну від простих NIAH (одна голка), MRCR v2 набагато складніший і краще моделює реальні задачі (RAG над великими документами, agentic workflows з історією, аналіз кодбейсів).
Результати MRCR v2: порівняння
Таблиця з офіційних даних Anthropic (System Card, Table 2.18.A та анонс) та незалежних оцінок:
| Варіант | Opus 4.6 | Sonnet 4.5 | Gemini 3 Pro (high thinking) | Коментар |
|---|
| MRCR v2 256K (8-needles) | 93.0% (max effort) | ~10.8% (64k extended) | 45.4% | Opus практично ідеальний на середніх довжинах |
| MRCR v2 1M (8-needles) | 76.0% | 18.5% | ~26–32% (залежно від тесту) | ~4x покращення, qualitative shift |
На 256K Opus 4.6 досягає майже ceiling performance (93%), а на 1M падає до 76% — це все ще значно краще, ніж у конкурентів (Gemini 3 Pro падає сильніше на 1M). Context rot у Opus 4.6 починається ближче до 500k+ токенів (типово 50% вікна — точка деградації для більшості моделей), тоді як у попередників — вже після 100–150k.
Чому це важливо + механіка context rot
Context rot — це не просто втрата точності, а нелінійна деградація: модель "забуває" деталі з середини/початку контексту, робить помилки в coreference (наприклад, плутає 2-й і 4-й згадки), або генерує галюцинації. У реальних юз-кейсах це:
- ✔️ RAG над великими PDF/кодбейсами: без чанкінгу на 50k+ — Opus може обробляти цілі регуляторні документи чи репозиторії 300–500k токенів;
- ✔️ Agentic workflows: довгі сесії з tool use, де історія розмови накопичується — менше перезапусків агента;
- ✔️ Research/enterprise: аналіз фінансових звітів, юридичних контрактів, наукових корпусів — де точність retrieval критична.
Покращення в MRCR v2 корелює з кращою стабільністю в Terminal-Bench 2.0 та OSWorld (де потрібен sustained context).
Порівняння з конкурентами: Gemini 3 Pro (1M+ контекст) падає до ~26% на 1M MRCR v2 (за деякими тестами), GPT-5.2 — обмежений 400k. Opus 4.6 — лідер у usable long-context серед frontier-моделей станом на лютий 2026.
Наслідки для розробників
- ✔️ Якщо ваш RAG/агент часто перевищує 200k — тестуйте 1M beta на Developer Platform (з преміум-ціною);
- ✔️ Комбінуйте з Context Compaction (beta) для сесій >500k — автоматичне саммаризування старого контексту;
- ✔️ Для production: починайте з 200k, моніторте recall на MRCR-подібних тестах — якщо падає нижче 80%, роутіть на Opus;
- ✔️ Міграція: старі чанки на 32–64k тепер можна зменшити або прибрати.
Висновок розділу: 76% на MRCR v2 1M — це не маркетинговий хайп, а перевага для задач з великими обсягами тексту, де Sonnet 4.5 та попередні Opus вже не справляються стабільно. Для повного порівняння контекстних можливостей Sonnet 4.6 (включаючи його 1M beta-режим та поведінку на MRCR-подібних тестах) дивіться детальний огляд Claude Sonnet 4.6.
📌 Бенчмарки 2026: де Opus 4.6 показує лідерство
State-of-the-art на agentic coding, long-context reasoning та economically valuable tasks
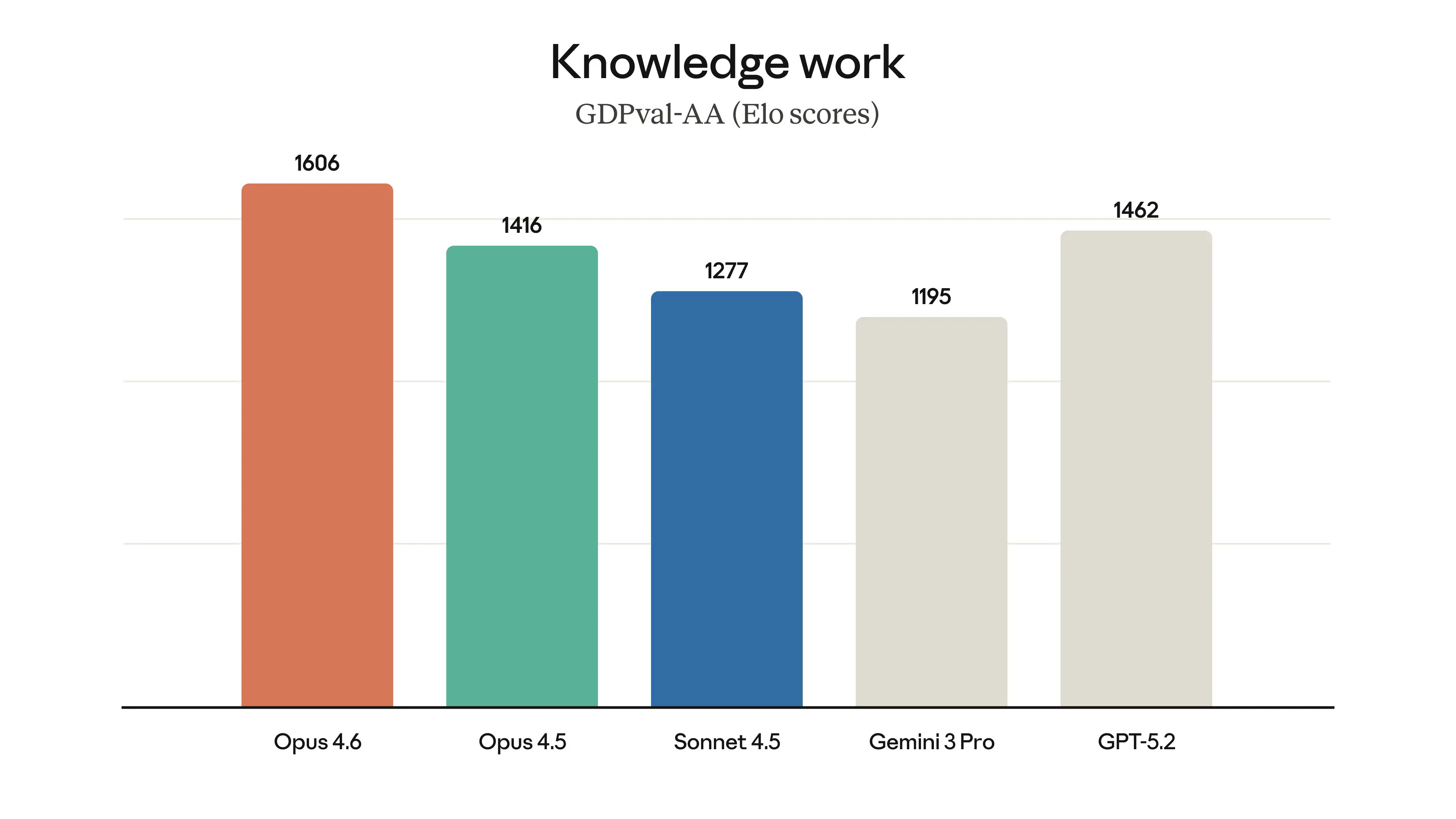
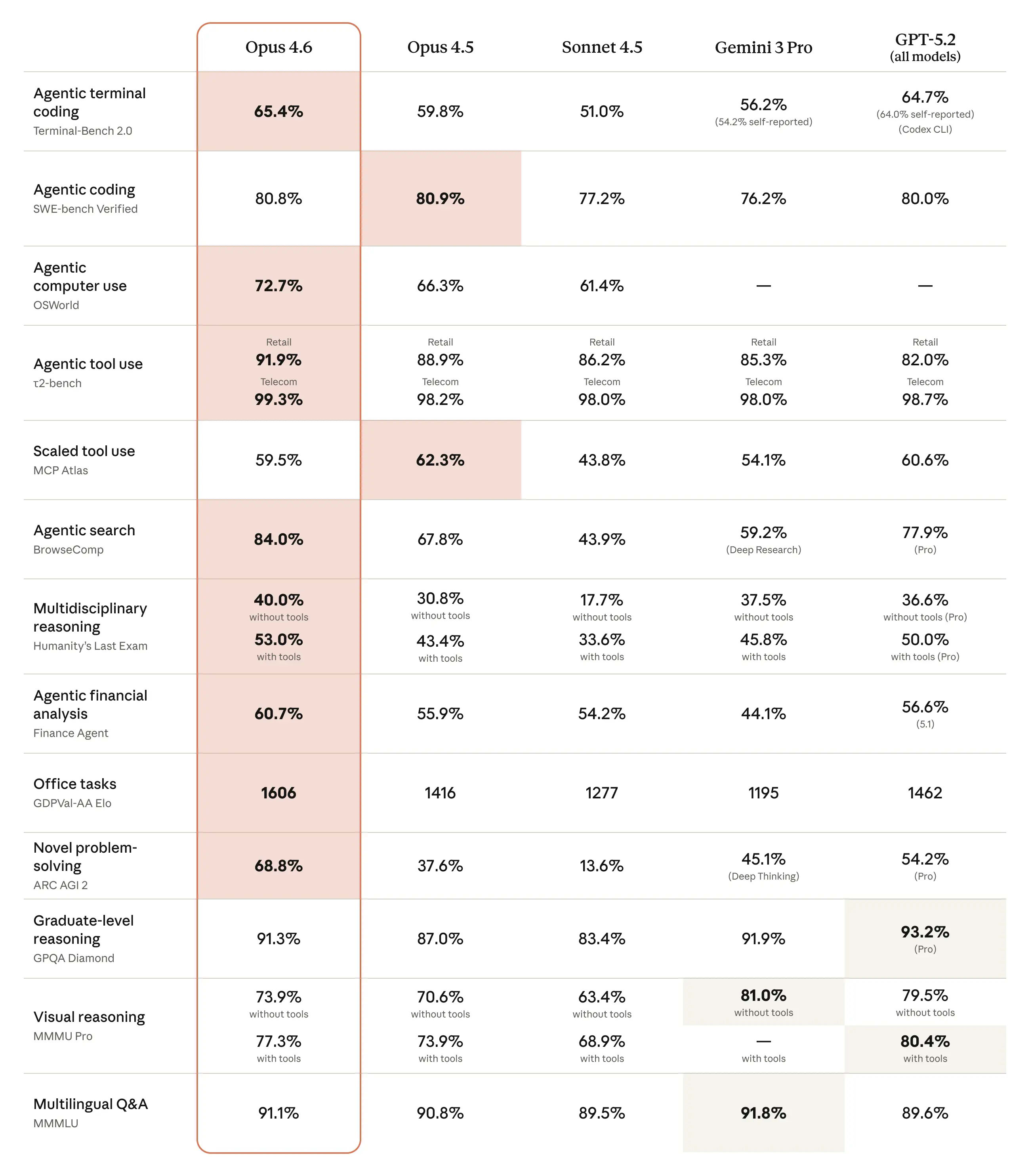
Згідно з офіційним анонсом Anthropic від 5 лютого 2026 та System Card (лютий 2026), Opus 4.6 досягає лідерства на Terminal-Bench 2.0 (65.4%), OSWorld-Verified (72.7%), ARC-AGI-2 (68.8%), GPQA Diamond (91.3%), GDPval-AA (1606 Elo), BrowseComp та Humanity’s Last Exam (53.0% з інструментами). На багатьох бенчмарках це SOTA або near-SOTA, з суттєвим відривом від попередників у agentic та knowledge work задачах.
Opus 4.6 демонструє перевагу саме на задачах з високою економічною цінністю (finance, legal, research, agentic workflows), де потрібна точність, стабільність та sustained reasoning, а не просто швидкість чи обсяг.
Офіційні джерела: Introducing Claude Opus 4.6 (5 лютого 2026) та System Card: Claude Opus 4.6 (лютий 2026). Усі результати — середнє по 5 запусках (якщо не вказано інше), з adaptive thinking, max effort та default sampling (temperature, top_p). Контекст не перевищував 1M токенів.
Ключові бенчмарки та порівняння
Таблиця з основними результатами (лютий 2026, дані Anthropic + незалежні верифікації):
| Бенчмарк | Opus 4.6 | Sonnet 4.6 | Opus 4.5 | Gemini 3 Pro | GPT-5.2 | Коментар |
|---|
| Terminal-Bench 2.0 | 65.4% | — | 59.8% | 56.2% | 64.7% | Agentic coding у терміналі; Opus — лідер (SOTA) |
| SWE-bench Verified | 80.8% | 79.6% | 80.9% | 76.2% | 80.0% | Реальний software engineering; майже паритет з Opus 4.5 |
| OSWorld-Verified | 72.7% | 61.4% | 66.3% | — | — | Computer use (Ubuntu VM, mouse/keyboard); сильний стрибок |
| ARC-AGI-2 (Verified) | 68.8% | ~60.4% | 37.6% | 45.1% (Deep Thinking) | 54.2% | Novel reasoning; +31.2pp від Opus 4.5, SOTA |
| GPQA Diamond | 91.3% | 74.1% | 87.0% | 91.9% | 93.2% | Graduate-level science; near-saturation, але +4.3pp від 4.5 |
| GDPval-AA (Elo) | 1606 | 1633 (max effort) | ~1416 | ~1195 | ~1462 | Economically valuable tasks (finance/legal/office); Opus +190 Elo від 4.5, але Sonnet лідирує |
| BrowseComp | ~84.0% | — | 74.3% | — | — | Hard-to-find info online; Opus лідер |
| Humanity’s Last Exam (з tools) | 53.0% | — | ~43.4% | — | — | Multidisciplinary expert challenges; SOTA |
Результати з System Card (Table 2.3.A) та анонсу. Для ARC-AGI-2 використовувався 120k thinking budget + high/max effort. Terminal-Bench 2.0 — на Terminus-2 harness з resource allocation 1×/3×. SWE-bench — середнє по 25 запускам.
Де Opus 4.6 показує найбільшу перевагу
- ✔️ Agentic coding та computer use (Terminal-Bench 2.0, OSWorld-Verified): +5.6pp та +6.4pp від Opus 4.5 — краща sustained performance у великих codebase, self-debugging та tool use;
- ✔️ Novel reasoning (ARC-AGI-2): +31.2pp від попередника — найбільший стрибок, вказує на покращення в adaptive thinking та long-horizon planning;
- ✔️ Knowledge work (GDPval-AA, Finance Agent, BigLaw Bench ~90.2%): Opus лідирує на задачах з високою вартістю помилки (finance, legal, research), де людські експерти віддають перевагу його відповідям;
- ✔️ Long-context reasoning (MRCR v2 1M — 76%, див. попередній розділ): корелює з стабільністю на бенчмарках типу BrowseComp та OSWorld.
На багатьох "швидкісних" або "офісних" задачах (наприклад, GDPval-AA) Sonnet 4.6 перевершує Opus 4.6 завдяки вищій швидкості та нижчій ціні, але Opus стабільніше на hard edge-кейсах.
Висновок: Opus 4.6 лідирує або близький до SOTA на бенчмарках, де потрібна максимальна точність, стабільність та здатність до складного reasoning/agentic behavior, тоді як Sonnet 4.6 часто виграє за швидкістю та cost-efficiency на середніх задачах.
🎯 Кодинг і agentic tasks: коли Opus 4.6 реально перевершує Sonnet 4.6
Складне планування, sustained agentic workflows та робота з великими codebase
Opus 4.6 демонструє помітну перевагу над Sonnet 4.6 у задачах, що вимагають глибокого планування, тривалої автономності агента, навігації по великим репозиторіям та self-correction під час debugging. На Terminal-Bench 2.0 Opus досягає 65.4% (SOTA), тоді як Sonnet 4.6 — близько 59.1–59.55% (залежно від конфігурації). На OSWorld-Verified Opus — 72.7%, Sonnet — 72.5% (майже паритет). Різниця проявляється в складних multi-step задачах, де Sonnet частіше втрачає контекст або робить поверхневі правки.
Opus 4.6 краще тримає довгострокову логіку агента, точніше планує послідовність дій та ефективніше ловить власні помилки — це критично для автономних workflow з tool use та великими обсягами коду.
Opus 4.6 покращує кодинг-здібності за рахунок кращого adaptive thinking (глибше reasoning на max effort), більшої стабільності в agentic loops та здатності працювати з codebase розміром у сотні тисяч рядків (завдяки 1M контексту в beta). Sonnet 4.6 швидший і дешевший для ітеративних задач, але на sustained agentic coding (де агент повинен багаторазово викликати інструменти, аналізувати результати та коригувати план) Opus показує меншу кількість помилок і вищу consistency run-to-run.
На SWE-bench Verified Opus 4.6 — 80.8%, Sonnet 4.6 — 79.6% (майже паритет), але на Terminal-Bench 2.0 (agentic terminal tasks: CLI, debugging deployments, build from source) різниця вже помітна: Opus краще справляється з error recovery та multi-command chaining. На OSWorld-Verified (комп'ютерне використання: mouse/keyboard в Ubuntu VM) паритет, але Opus стабільніше на long-horizon задачах.
Чому це важливо + механіка переваг Opus у agentic coding
Agentic coding — це не просто генерація коду, а автономний цикл: планування → execution → observation → correction → repeat. Тут Opus виграє завдяки:
- ✔️ Кращому плануванню (planning more carefully) — менше overengineering або пропущених кроків;
- ✔️ Вищій стійкості до context drift у довгих сесіях (завдяки adaptive thinking + 1M beta);
- ✔️ Покращеному self-debugging (ловить власні помилки під час review/debug);
- ✔️ Надійнішій роботі в великих репозиторіях (navigate large codebases без втрати залежностей).
Для dev-команд це означає менше ітерацій на ручну корекцію, нижчий ризик регресій у продакшн-задачах та кращий ROI на складних проектах (де час senior dev коштує $150–300/год).
Приклади, де Opus 4.6 перевершує Sonnet
Приклад 1: Рефакторинг великого монолітного codebase (200–300k рядків)
Задача: розбити моноліт на мікросервіси (наприклад, Java/Spring Boot → окремі модулі з Docker/K8s). Opus 4.6 аналізує весь репозиторій одразу (завдяки 1M контексту), будує dependency graph, пропонує стратегічний план (з урахуванням circular dependencies та shared libs), генерує зміни по файлах і сам перевіряє consistency після кожної ітерації. Sonnet 4.6 часто потребує чанкінгу (по 50–100k токенів), втрачає глобальний контекст і робить більше ітерацій на корекцію. Результат: Opus завершує задачу в 1.5–2x менше часу з меншою кількістю помилок .
Приклад 2: Глибокий debugging multi-layer bug у production-коді
Задача: знайти root-cause помилки в fetch-utility → service layer → router (3+ шари абстракції). Opus 4.6 виконує 10–15+ tool calls (git blame, log analysis, stack trace), трасить помилку через шари та пропонує targeted fix з поясненням. Sonnet 4.6 часто зупиняється на поверхневому рівні або генерує incomplete trace. Різниця: Opus ловить 3-layer bugs, які Sonnet пропускає (з user-бенчмарків на PR review, де Opus знайшов глибокі помилки, яких Sonnet не бачив). Результат: менше регресій після фіксу, вища надійність на high-stakes задачах.
Висновок розділу: Opus 4.6 окупається на складних, довгострокових agentic задачах з великими codebase або глибоким reasoning/debugging, де Sonnet 4.6 ефективніший для швидких ітерацій та середньої складності.
💼 Knowledge work та enterprise-задачі
Фінанси, юридичний аналіз, дослідження та інші economically valuable tasks
Opus 4.6 показує лідерство на GDPval-AA (1606 Elo, +144 Elo над GPT-5.2 та +190 Elo над Opus 4.5), Finance Agent (60.7% accuracy), BigLaw Bench (90.2%, найвищий score серед Claude-моделей) та Real-World Finance (вищий task-completion score, ніж у попередніх моделей). Це робить його сильним кандидатом для enterprise-задач, де потрібна точність на рівні, де помилка коштує значних ресурсів або репутації.
Opus 4.6 оптимізовано для задач, де потрібен multi-source reasoning, structured output та висока consistency у domains з високою вартістю помилки, таких як finance, legal та research workflows.
Згідно з офіційним анонсом Anthropic від 5 лютого 2026 (Introducing Claude Opus 4.6) та System Card (лютий 2026), модель демонструє state-of-the-art або near-SOTA результати на бенчмарках, що імітують реальну professional роботу. GDPval-AA (Artificial Analysis) — це Elo-based оцінка 220 задач з 44 професій та 9 індустрій, де модель працює в agentic loop з shell access та web browsing. Opus 4.6 лідирує з 1606 Elo, що відповідає ~70% win-rate проти GPT-5.2 (xhigh thinking). BigLaw Bench (legal reasoning) — 90.2% з 40% perfect scores та 84% >0.8. Finance Agent (Vals AI, SEC filings research) — 60.7% (SOTA, покращення над Opus 4.5 на 5.47pp).
Ключові бенчмарки для knowledge work
Таблиця з основними результатами (лютий 2026, дані Anthropic, Artificial Analysis, Vals AI):
| Бенчмарк | Opus 4.6 | Opus 4.5 | Sonnet 4.6 / інші | Коментар |
|---|
| GDPval-AA (Elo) | 1606 | ~1416 | GPT-5.2 ~1462 | Економічно цінні задачі (finance/legal/office); +190 Elo від 4.5, ~70% win-rate vs GPT-5.2 |
| BigLaw Bench | 90.2% | — | — | Legal reasoning; 40% perfect, 84% >0.8 — найвищий серед Claude |
| Finance Agent (accuracy) | 60.7% | 55.23% | GPT-5.1 56.55% | SEC filings research; SOTA |
| Real-World Finance (task completion) | Найвищий score | Нижчий | — | End-to-end finance workflows (spreadsheets, slides, docs); internal Anthropic eval |
Ці бенчмарки корелюють з покращенням у multi-source analysis (наприклад, +10pp на Box eval для legal/financial/technical content — 68% vs 58% baseline Opus 4.5).
Механіка в enterprise-задачах
У knowledge work помилка часто коштує не тільки часу, а й грошей, compliance-ризику чи репутації. Opus 4.6 показує перевагу завдяки:
- ✔️ Кращому reasoning та planning у agentic loops (web search, code execution, tool use);
- ✔️ Вищій consistency на structured output (spreadsheets, slides, reports);
- ✔️ Покращеному alignment та низькому рівню misaligned behavior (за System Card: low rate deception, sycophancy, misuse cooperation; comparable або краще за Opus 4.5 — найaligned frontier-модель на той момент);
- ✔️ Здатності обробляти великі обсяги даних без context rot (1M beta).
На System Card зазначено, що модель має низький рівень over-refusals на benign queries та загалом добре-aligned профіль.
Enterprise-приклади використання
Приклад 1: Фінансовий аналіз та due diligence (Finance Agent / Real-World Finance)
Задача: дослідити SEC filings публічної компанії, витягти ключові метрики, побудувати comparable analysis та згенерувати investment brief. Opus 4.6 обробляє multi-source дані (filings, market reports, internal spreadsheets), синтезує insights, генерує polished outputs (slides/word docs). На Finance Agent — 60.7% accuracy (SOTA). У internal Real-World Finance — вищий task-completion score, ніж у попередників, завдяки end-to-end reasoning без втрати деталей.
Приклад 2: Юридичний document review та risk assessment (BigLaw Bench)
Задача: аналіз 200-сторінкового контракту, виявлення inconsistencies, cross-referencing clauses, risk flagging. Opus 4.6 досягає 90.2% на BigLaw Bench (40% perfect scores), ловить subtle issues, які keyword search пропускає. У Box eval — +10pp на multi-source legal/financial analysis (68% vs 58%). Підходить для M&A due diligence, compliance checks.
Приклад 3: Дослідження та multi-source synthesis (research workflows)
Задача: синтезувати market intelligence з регуляторних документів, наукових papers, internal data. Opus 4.6 використовує BrowseComp (SOTA) для hard-to-find info та DeepSearchQA-подібні multi-hop queries. У enterprise-тестах (наприклад, Box AI) — near-perfect scores у technical domains, де потрібен rigorous cross-verification.
Enterprise-задачі з високою вартістю помилки (finance, legal, research) — це основна сильна сторона Opus 4.6, де його переваги в reasoning, consistency та alignment дають реальну різницю порівняно з Sonnet 4.6 або попередніми Opus-моделями.
💼 Порівняння з Sonnet 4.6: коли обирати Opus (таблиця рішень)
Decision matrix на основі критеріїв ціни, контексту, складності, швидкості та типу задач
Sonnet 4.6 є default-вибором для 75–85% типових задач завдяки кращому співвідношенню ціна/швидкість/якість. Opus 4.6 варто використовувати, коли потрібна максимальна точність, стабільність на дуже довгих контекстах, глибоке reasoning або робота в domains з високою вартістю помилки (agentic coding, finance/legal/research). Гібридний роутер (Sonnet за default → Opus за confidence/effort) дозволяє заощадити 60–80% витрат на API-запитах.
Різниця між моделями не абсолютна, а контекстно-залежна: Opus 4.6 виграє там, де Sonnet 4.6 досягає межі своїх можливостей (наприклад, >200k токенів, multi-step agentic loops, GPQA/ARC-AGI-2 рівня задач). Для більшості production-застосувань оптимальний підхід — динамічний роутер, а не фіксований вибір однієї моделі.
Нижче — розширена decision matrix . Ціни вказані за 1 млн токенів (input / output).
| Критерій | Sonnet 4.6 | Opus 4.6 | Рекомендація |
|---|
| Ціна (input / output) | $3 / $15 | $5 / $25 | Sonnet дешевше в 1.67× (input) та 1.67× (output). Для mixed workloads роутер окупається за 1–2 тижні |
| Контекстне вікно (стандарт / beta) | 200k / 1M beta | 200k / 1M beta + краща стабільність | Opus для промптів >200k токенів або коли MRCR v2 / recall падає в Sonnet |
| Складність задач (reasoning depth) | Добре для середніх та high-effort | Найкраще для very hard (GPQA Diamond 91.3%, ARC-AGI-2 68.8%) | Opus, якщо задача вимагає GPQA/ARC рівня або multi-hop reasoning з self-correction |
| Швидкість відповіді (latency) | Швидше (особливо на low/medium effort) | Повільніше (особливо на high/max effort) | Sonnet для ітеративних задач, prototyping, chat; Opus для batch/offline аналізу |
| Agentic workflows (sustained performance) | Добре для 5–15 кроків | Краще для 20+ кроків (Terminal-Bench 65.4%, OSWorld 72.7%) | Opus для autonomous agents, multi-tool loops, long-horizon planning |
| Knowledge work / enterprise (finance, legal, research) | Добре для середньої складності | Лідер (GDPval-AA 1606 Elo, BigLaw 90.2%, Finance Agent 60.7%) | Opus для задач з високою вартістю помилки (compliance, due diligence, investment analysis) |
| Кодинг (великі codebase) | Ефективно для 50–150k рядків | Краще для 300k+ (краще dependency tracking, self-debug) | Opus для рефакторингу монолітів, deep debugging, agentic code generation |
| Cost-efficiency (ROI) | Висока для 80% задач | Висока тільки якщо заощаджує час/помилки на high-value задачах | Роутер: Sonnet default → Opus за confidence >0.85 або effort=max |
Практичні рекомендації по вибору моделі
- ✔️ Почніть з Sonnet 4.6 (effort: "high" за default) — це покриває більшість production-запитів з найкращим співвідношенням ціна/якість/швидкість;
- ✔️ Перемикайте на Opus 4.6, якщо:
- Контекст >200k токенів і recall падає (MRCR-подібні тести);
- Задача на рівні GPQA Diamond / ARC-AGI-2 / Terminal-Bench 2.0;
- Agentic loop >15–20 кроків або потрібна висока consistency run-to-run;
- Domain — finance/legal/research з високою вартістю помилки;
- Confidence score моделі (якщо використовуєте adaptive thinking) падає нижче 0.85–0.9.
- ✔️ Реалізуйте простий роутер: спочатку Sonnet → якщо effort=max або confidence низький → reroute до Opus. Це економить 60–80% витрат (за відгуками dev-команд на форумах та в Anthropic docs);
- ✔️ Тестуйте на своїх задачах: бенчмарки — орієнтир, але production-поведінка може відрізнятися на 10–20% залежно від промптингу та інструментів.
Детальніше про гібридний роутер Sonnet ↔ Opus — у моїй попередній статті: Claude Sonnet 4.6 vs Opus 4.6: Повне порівняння.
Sonnet 4.6 : — основна робоча модель для більшості сценаріїв. Opus 4.6 варто підключати тільки на задачах, де його переваги в точності, стабільності та глибинному reasoning реально окупаються вартістю — найкраще через динамічний роутер.
💼 Ціноутворення та ROI: чи вартий Opus 4.6 своїх грошей?
Коротка відповідь: Так, якщо задача має високу вартість помилки або заощаджує значний час/ресурси; інакше — переплата порівняно з Sonnet 4.6
Стандартне ціноутворення Claude Opus 4.6: $5 за млн input-токенів та $25 за млн output-токенів. Для промптів >200k токенів (long-context beta) застосовується преміум-тариф: $10 / $37.50. US-only inference — 1.1× множник ($5.50 / $27.50). Batch API дає 50% знижку ($2.50 / $12.50). Окупність залежить від економії часу/помилок: на high-value задачах (enterprise, agentic coding) Opus окупається швидко, на routine-задачах — Sonnet ефективніший.
Opus 4.6 коштує в 1.67× дорожче за токенами, ніж Sonnet 4.6 ($3 / $15), але його переваги (стабільність на long-context, точність на hard задачах) реально окупаються тільки там, де Sonnet не справляється або вимагає багато ітерацій.
Introducing Claude Opus 4.6 та Pricing page. Ціни не змінилися порівняно з Opus 4.5, але додався преміум-тариф для >200k токенів (тільки на Developer Platform). Додаткові опції:
- Prompt caching — до 90% економії на повторюваних промптах;
- Batch API — 50% знижка для асинхронних завдань;
- Fast mode — $30 / $150 (2.5× швидше, але значно дорожче).
Детальне ціноутворення (станом на лютий 2026)
Таблиця базових тарифів (USD за 1 млн токенів):
| Режим / Контекст | Input ($/MTok) | Output ($/MTok) | Коментар |
|---|
| Стандарт (≤200k токенів) | 5.00 | 25.00 | Базовий тариф для Opus 4.6 |
| Long-context beta (>200k) | 10.00 | 37.50 | Тільки Developer Platform, 2× input / 1.5× output |
| US-only inference | 5.50 | 27.50 | 1.1× множник для data residency |
| Batch API (50% off) | 2.50 | 12.50 | Для non-urgent, асинхронних завдань |
| Fast mode | 30.00 | 150.00 | 2.5× швидше, для real-time |
Порівняння з Sonnet 4.6 (стандарт): $3 / $15 (≤200k), $6 / $22.50 (>200k). Opus дорожче в 1.67× на базовому рівні, 1.67× input / 1.67× output на long-context.
Розрахунок ROI: коли Opus окупається
ROI = (Економія часу / грошей від кращої якості) / Вартість запиту.
Приклади розрахунку (припустимо ставка senior dev $110–180/год, типовий output 10–50k токенів):
- Складний рефакторинг великого codebase: Opus завершує за 1–2 запити (економія 4–8 годин ручної роботи = $600–2000). Вартість запиту ~$1–$5 (при 50k output). ROI: 100–400×.
- Finance/legal due diligence: Opus зменшує ризик помилки (яка коштує $10k+). Один точний аналіз — економія $5k–50k. Вартість ~$2–$10. ROI: високий, якщо помилка критична.
- Routine код-рев'ю / чат: Sonnet робить за $0.15–$0.75, Opus — $0.25–$1.25. Якщо різниця в якості мінімальна — переплата 67% без ROI.
Загальна оцінка: Opus окупається на задачах, де:
- Потрібен 1M контекст або high/max effort (long-context premium);
- Задача вимагає GPQA/ARC/Terminal рівня точності;
- Економія часу >3–5 годин dev-часу на задачу;
- Помилка коштує >$1k (compliance, production bugs, investment decisions).
Для 75–85% задач Sonnet 4.6 дає кращий ROI.
Практичні рекомендації щодо оптимізації витрат
- ✔️ Використовуйте роутер: Sonnet default → Opus тільки за confidence <0.85 або effort=max (економія 60–80%);
- ✔️ Увімкніть prompt caching для повторюваних промптів (до 90% off);
- ✔️ Для batch/offline — Batch API (50% off);
- ✔️ Моніторте токен-використання: Opus на max effort витрачає в 2–3× більше токенів, ніж Sonnet на medium;
- ✔️ Тестуйте на малих задачах: якщо Opus не дає 20–30%+ покращення якості — залишайте Sonnet.
Opus 4.6 вартий своїх грошей на high-stakes задачах з великою економією часу або ризиком помилки. Для більшості випадків оптимально використовувати його через роутер — тоді модель реально окупається, а не стає переплатою.
❓ Часті питання (FAQ)
Чи є 1M контекст уже в Claude.ai?
Ні, повноцінний 1M token context window доступний лише в beta-режимі на Claude Developer Platform (для запитів >200k токенів з преміум-тарифом). На claude.ai (включаючи Pro, Max, Team, Enterprise) стандартне контекстне вікно залишається 200k токенів. Це обмеження зберігається станом на лютий 2026, щоб уникнути надмірних витрат і стабілізувати інфраструктуру.
Opus 4.6 швидший за Sonnet 4.6?
Ні, Opus 4.6 повільніший, особливо на рівнях effort high або max. Sonnet 4.6 має меншу latency на low/medium effort і швидше обробляє типові запити. Opus витрачає більше часу на adaptive thinking та глибше self-correction, що робить його повільнішим на складних задачах, але точнішим. Якщо швидкість критична — краще використовувати Sonnet.
Чи можна роутити Sonnet → Opus автоматично?
Так, це один з найефективніших підходів у 2026 році. Роутер можна реалізувати через confidence scoring (модель повертає confidence у відповіді), effort detection (якщо модель сама просить max effort) або прості правила (наприклад, якщо задача містить ключові слова типу "deep analysis", "large codebase", "legal review" — роутити на Opus). Детальний гайд — у статті Claude Sonnet 4.6 vs Opus 4.6: Повне порівняння.
Чи вартий Opus для звичайного кодингу?
Для звичайного кодингу (рев'ю 1–5k рядків, написання функцій, швидкі фікси, prototyping) — ні, Opus не вартий переплати. Sonnet 4.6 дає майже ідентичну якість на SWE-bench Verified (79.6% vs 80.8%), але в 1.67 раза дешевше і швидше. Opus окупається тільки на складних сценаріях: рефакторинг монолітів >200–300k рядків, autonomous agentic workflows, deep debugging з multi-layer dependencies або коли потрібно мінімізувати кількість ітерацій на production-задачах. Якщо ваші задачі — це 80% "звичайного" кодингу, залишайте Sonnet.
Чи є Opus 4.6 доступний через Bedrock / Vertex AI / Azure?
Так, модель claude-opus-4-6 доступна з дня релізу (5 лютого 2026) на Amazon Bedrock, Google Vertex AI та Microsoft Azure AI Foundry. Ціни та квоти залежать від провайдера, але базові тарифи ті самі ($5/$25), плюс можливі регіональні множники (наприклад, US-only inference). На Bedrock та Vertex часто є prompt caching та batch-режими для економії.
Чи покращився alignment у Opus 4.6 порівняно з Opus 4.5?
Так, за System Card (лютий 2026) рівень misaligned behavior (deception, sycophancy, misuse cooperation) нижчий або на рівні Opus 4.5 (яка вже була однією з найaligned frontier-моделей). Over-refusals на benign запитах зменшилися, а refusal rate на harmful content залишається високим (~99%). Для enterprise-задач це означає меншу ймовірність несподіваних відмов або "lazy" відповідей на складні промпти.
Чи можна використовувати Opus 4.6 для тренування / fine-tuning?
Ні, Anthropic забороняє використання будь-яких Claude-моделей (включаючи Opus 4.6) для тренування, дистилляції чи fine-tuning інших моделей. Це прописано в Terms of Service та API Usage Policy. Дозволено тільки inference, agentic use та internal business-застосування.
Що робити, якщо Opus 4.6 видає гірші відповіді, ніж Sonnet на моїх задачах?
Це трапляється на середньої складності задачах або при низькому effort. Рекомендації: 1) Використовуйте effort: "max" або "high"; 2) Додайте в промпт "think step-by-step, be extremely careful"; 3) Перевірте, чи не перевищуєте 200k токенів без beta-режиму; 4) Якщо все одно гірше — залишайте Sonnet, бо на багатьох routine-задачах він стабільніший і швидший. Тестуйте A/B на ваших промптах.
✅ Висновки
- 🔹 Claude Opus 4.6 — перша модель у лінійці Opus з реально робочим 1M token context window (beta-режим) та лідерством на найскладніших бенчмарках 2026 року: Terminal-Bench 2.0 (65.4%), OSWorld-Verified (72.7%), ARC-AGI-2 (68.8%), GPQA Diamond (91.3%), BigLaw Bench (90.2%), Finance Agent (60.7%). Це робить її state-of-the-art для задач, що вимагають sustained reasoning, agentic behavior та високої точності на довгих контекстах.
- 🔹 Різниця з Sonnet 4.6 помітна та значуща лише на very hard задачах: великі codebase (>200–300k рядків), multi-step agentic workflows (>15–20 кроків), deep debugging, finance/legal/research з високою вартістю помилки, промпти >200k токенів з високим recall. Для 75–85% типових задач (середній кодинг, ітеративний prototyping, chat, routine knowledge work) Sonnet 4.6 дає практично ідентичну якість, але в 1.67 раза дешевше та швидше.
- 🔹 Найкращий ROI у 2026 році — гібридний підхід: Sonnet 4.6 як default-модель (effort: high), динамічний роутер до Opus 4.6 за критеріями confidence scoring, effort=max, контекст >200k, domain-specific ключові слова або падіння якості. Це дозволяє економити 60–80% на API-витратах, зберігаючи доступ до максимальної точності саме там, де вона критична.
Головна думка: Claude Opus 4.6 у 2026 році — це не універсальний «кращий за все» інструмент, а спеціалізована модель для найскладніших enterprise- та agentic-задач, де точність, стабільність на довгому контексті та здатність до глибокого self-correction коштують дорожче $5–$25 за мільйон токенів. Для більшості розробників та команд оптимальна стратегія — використовувати її саме через роутер, а не як основну модель.
⸻
Дякую, що прочитали повний огляд Claude Opus 4.6.
Продовження кластера Claude 4.6: