In February 2026, Anthropic deployed Claude Opus 4.6—the first model in the Opus lineage to feature a 1M token context window, marking a substantial architectural leap in agentic coding, enterprise-grade workflows, and complex reasoning. The prevailing industry consensus often claims: "Opus 4.6 is just a more expensive Sonnet." In reality, it represents a qualitative paradigm shift where Sonnet 4.6 hits its computational ceiling: massive context windows, the most demanding autonomous tasks, and sustained stability in real-world enterprise edge cases.
The Pragmatic Take: Opus 4.6 justifies its $5/$25 API compute pricing exclusively if you are managing monolithic codebases, dense legal/financial documentation, or zero-tolerance pipelines where errors carry heavy financial costs. For 80% of standard production workloads, routing to Sonnet 4.6 remains the optimal architectural choice.
⚡ Executive Summary
- ✅ Core Insight 1: The first Opus with a 1M context (beta)—achieving an unprecedented 76% on MRCR v2 at 1M tokens (compared to ~18.5% for Sonnet 4.5).
- ✅ Core Insight 2: Establishes a new state-of-the-art across critical benchmarks: Terminal-Bench 2.0 (65.4%), GPQA Diamond (91.3%), ARC-AGI-2 (68.8%), and GDPval-AA (1606 Elo).
- ✅ Core Insight 3: The integration of Adaptive Thinking + Effort Controls enables granular programmatic management of reasoning depth (low → max), optimizing token expenditure for lower-complexity tasks.
- 🎯 Actionable Deliverable: A precise decision matrix—when to deploy Opus 4.6, and when routing to Sonnet 4.6 will cut your compute costs by 60–80%.
- 👇 Detailed architectural analysis, benchmarks, and deployment matrices follow below.
📚 Table of Contents
🎯 Deployment & Availability (February 2026)
The Opus 4.6 Deployment
Claude Opus 4.6 was officially deployed on **February 5, 2026** (per Anthropic's announcement). This serves as the flagship model iteration following Opus 4.5 (November 2025). The model is immediately accessible for production via claude.ai (Pro, Max, Team, Enterprise tiers), the Claude API (model ID: claude-opus-4-6), Amazon Bedrock, Google Vertex AI, and Microsoft Azure Foundry.
Opus 4.6 is not a minor patch, but a foundational expansion of long-context capabilities and stability in agentic workflows, introducing the first 1M token context window to the Opus tier (in beta).
Official announcement: Introducing Claude Opus 4.6 (Anthropic, February 5, 2026). The model is explicitly positioned for workloads with stringent requirements in autonomous coding, agentic frameworks, and professional/enterprise pipelines. The 1M token context window is currently restricted to beta on the Developer Platform (with premium pricing tiers applied to queries exceeding 200k tokens); the standard production context remains 200k tokens.
Strategic Implications & Release Velocity
The deployment delta between Opus 4.6 (February 5) and Sonnet 4.6 (February 17) was a mere 12 days. This signals Anthropic's aggressively accelerated iteration cycle for 2026, heavily prioritizing enterprise utility (agentic coding, long-context reasoning, tool use). For system architects integrating models via API, this dictates a requirement for rapid CI/CD testing and endpoint updating, as these versions deliver not just raw benchmark improvements, but fundamental shifts in stability and edge-case execution.
Section Takeaway: If your infrastructure relies on Claude via API or handles production workloads, validate compatibility with claude-opus-4-6 immediately, as the model is fully production-ready from day one.
📌 Architectural Primitives & Core Technologies
Hybrid Reasoning via Adaptive Thinking, Effort Controls, and a 1M Context (Beta)
Claude Opus 4.6 operates as a hybrid reasoning model, fusing standard inference outputs with extended thinking capabilities. The core architectural updates include: Adaptive Thinking (dynamic reasoning depth allocation), Effort Controls (four programmatic tiers: low, medium, high, max), a 1M token context window (beta, exclusive to the Developer Platform for >200k tokens), Context Compaction (beta) for sustained multi-turn sessions, and a 128K max output token limit.
Opus 4.6 transitions from a binary extended-thinking toggle to a dynamic reasoning depth controller, enabling engineers to mathematically balance precision, system latency, and token expenditure.
According to Anthropic's February 5, 2026 announcement (Introducing Claude Opus 4.6) and API documentation (Adaptive Thinking docs, Effort docs), the model retains the baseline Claude 4.x architecture but drastically expands granular control over the reasoning pipeline. Previously (in Opus 4.5 and earlier), extended thinking was either statically enabled with a fixed token budget (budget_tokens, now deprecated) or disabled entirely. Version 4.6 introduces Adaptive Thinking: the model autonomously evaluates query complexity and dynamically invokes deeper reasoning protocols (interleaved thinking is enabled by default).
The Core Parameter: Effort (Four Tiers):
- low: Minimal extended thinking, optimized for low latency and minimal compute cost—ideal for baseline queries;
- medium: Balanced thinking allocation, striking a pragmatic compromise between inference speed and output quality;
- high (default): Aggressive adaptive thinking application for complex computational or reasoning tasks;
- max: Exhaustive reasoning depth, delivering maximum precision at the cost of peak token burn and higher latency.
This provides developers with the API surface to programmatically tune the intelligence-to-speed-to-cost ratio via the effort parameter.
The 1M token context window is a first for the Opus tier, though currently restricted to beta on the Claude Developer Platform. The baseline context remains 200K tokens (mirroring legacy models). Requests exceeding 200K trigger premium compute pricing ($10/$37.50 per 1M input/output tokens). Context Compaction (beta) is introduced as an automated pipeline for summarizing historical context in extended agentic workflows, preventing token limit breaches without discarding mission-critical state data.
The max output token limit has been expanded to 128K (up from 64K in Sonnet 4.6 and legacy Opus models), a critical infrastructure upgrade for generating monolithic codebases, comprehensive analytical reports, or massive operational plans.
The Mechanics of Adaptive Thinking & Effort Allocation
The shift to adaptive computing and effort controls is not a superficial update; it is a fundamental efficiency leap for production workloads. The model no longer burns compute on overthinking trivial requests (e.g., standard code reviews) but can dedicate massive compute to complex problems (multi-step agent planning, large codebase debugging). Empirical data from early adopters (cited in the docs and System Card) indicates a 20–50% reduction in aggregate token burn across mixed workloads. The deprecation of budget_tokens mandates that legacy integrations migrate to the adaptive + effort architecture prior to subsequent release cycles.
The February 2026 System Card details that adaptive thinking directly enhances self-correction and output consistency in agentic tasks, mitigating the probability of "lazy" or shallow execution. This is empirically visible in sustained reasoning benchmarks like Terminal-Bench 2.0 and OSWorld-Verified.
Pragmatic Implications for System Architects
- ✔️ Initiate deployments with
effort: "high" (default) for baseline testing—then tune down to optimize cost-sensitive pipelines; - ✔️ For agentic workflows, pair with Context Compaction to sustain prolonged sessions without engineering custom chunking logic;
- ✔️ The 1M context (beta) should only be staged on the Developer Platform, as standard claude.ai and legacy plans cap at 200K;
- ✔️ Migration path: Replace legacy
thinking: {type: "enabled", budget_tokens: N} payloads with thinking: {type: "adaptive"} + effort.
Adaptive Thinking and Effort Controls: These mechanisms transform Opus 4.6 into a highly scalable, economically viable instrument for production environments, vastly outperforming legacy models where reasoning control was rigid.
🎯 Long-Context Capabilities: 76% MRCR v2 at 1M Tokens
A Massive Leap in Usable Long-Context Retrieval
On the 8-needle 1M variant of MRCR v2 (Multi-Round Coreference Resolution), Opus 4.6 achieves a 76% Mean Match Ratio (official Anthropic benchmark). By comparison: Sonnet 4.5 scores a mere 18.5% on the identical test. This demonstrates a radical reduction in "context rot"—the precision degradation typically observed when context windows exceed 100–200k tokens.
Anthropic defines this as a "qualitative shift" in usable context: the architecture doesn't merely ingest 1M tokens; it actively computes across them without catastrophic loss of recall or reasoning fidelity.
MRCR v2 (developed by OpenAI, including the v2 fix from December 2025) is a multi-round coreference needle-in-a-haystack evaluation: 8 identical "needles" (e.g., 8 poems on a specific topic) are injected into the context, and the model must retrieve a specific iteration (e.g., the 4th). This evaluates not just raw retrieval, but sequential reasoning and entity distinction within massive datasets. Unlike standard single-needle NIAH tests, MRCR v2 is significantly more rigorous and accurately maps to real-world engineering tasks (RAG over massive documents, agentic workflows with extensive history, and monolithic codebase analysis).
MRCR v2 Benchmark Results: A Comparative Analysis
Data sourced from Anthropic's official System Card (Table 2.18.A), official announcements, and independent validation:
| Benchmark Variant | Opus 4.6 | Sonnet 4.5 | Gemini 3 Pro (high thinking) | Architectural Commentary |
|---|
| MRCR v2 256K (8-needles) | 93.0% (max effort) | ~10.8% (64k extended) | 45.4% | Opus hits near-ceiling performance at medium context lengths. |
| MRCR v2 1M (8-needles) | 76.0% | 18.5% | ~26–32% (variance by test) | ~4x improvement; a true qualitative paradigm shift. |
At 256K, Opus 4.6 achieves near-ceiling performance (93%), and drops to an entirely viable 76% at the 1M mark—maintaining a massive delta over competitors (Gemini 3 Pro degrades significantly at 1M). Context rot in Opus 4.6 is suppressed until the 500k+ token threshold (typically, 50% of the window is the degradation point for most frontier models), whereas legacy architectures begin failing structurally at 100–150k.
Strategic Value & The Mechanics of Context Rot
Context rot is not linear precision loss; it is systemic degradation: a model "forgets" variables from the middle or beginning of the context, fails at coreference mapping (e.g., confusing the 2nd and 4th mention of a function), or hallucinates dependencies. In production use cases, this solves:
- ✔️ RAG across massive PDFs/codebases: Bypassing the need for complex 50k chunking logic, Opus can natively process 300–500k token regulatory frameworks or repositories;
- ✔️ Agentic workflows: Supports prolonged sessions heavily reliant on tool use where conversational state accumulates, drastically reducing agent restarts;
- ✔️ Enterprise Research: Unlocks zero-loss analysis of quarterly financial reports, complex legal contracts, and scientific corpuses where retrieval precision is non-negotiable.
The leap in MRCR v2 performance directly correlates with the observed stability in Terminal-Bench 2.0 and OSWorld (where sustained context integrity is mandatory).
Competitive Matrix: Gemini 3 Pro (1M+ context) degrades to ~26% on the 1M MRCR v2 (based on external validation), while GPT-5.2 is capped at 400k. As of February 2026, Opus 4.6 is the undisputed leader in usable long-context frontier models.
Architectural Implications for Deployment
- ✔️ If your RAG pipeline or autonomous agent frequently breaches 200k, migrate testing to the 1M beta on the Developer Platform (accounting for premium pricing);
- ✔️ Integrate Context Compaction (beta) for sessions exceeding 500k to automate historical state summarization;
- ✔️ Production Standard: Default to the 200k window, monitor recall metrics via MRCR-style unit tests—if precision drops below 80%, dynamically route the query to Opus;
- ✔️ Codebase Migration: Legacy 32–64k chunking architectures can now be safely deprecated or aggressively expanded.
Section Takeaway: A 76% score on MRCR v2 1M is not a marketing metric; it is a structural advantage for massive-scale text computation where Sonnet 4.5 and legacy Opus models systematically fail. For a comprehensive matrix of Sonnet 4.6’s context constraints (including its own 1M beta tier and MRCR performance), review the deep-dive technical analysis of Claude Sonnet 4.6.
📌 2026 Benchmarks: Where Opus 4.6 Establishes Dominance
State-of-the-art in agentic coding, long-context reasoning, and economically valuable tasks
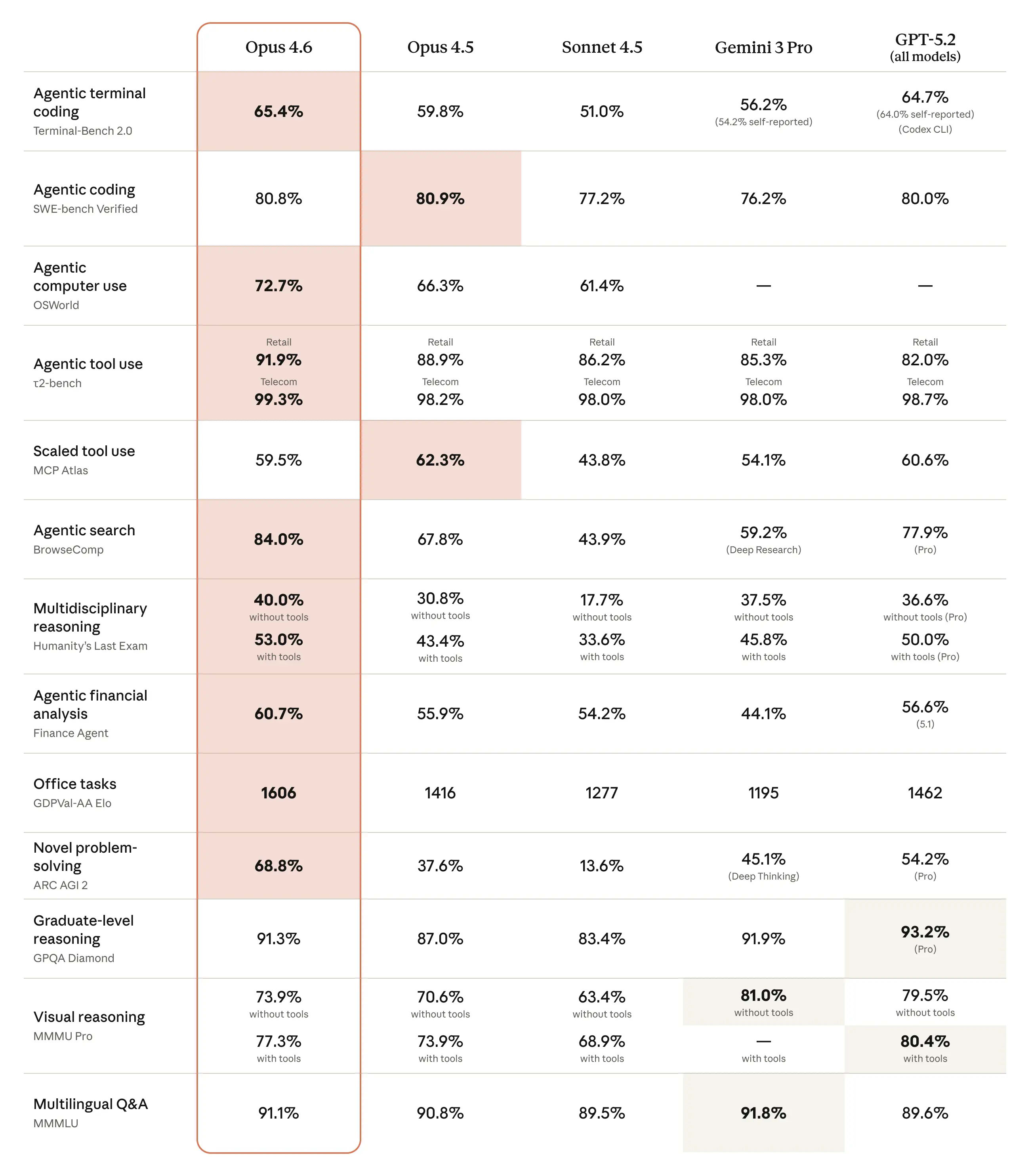
According to Anthropic's official February 5, 2026 announcement and the February 2026 System Card, Opus 4.6 establishes new leadership across Terminal-Bench 2.0 (65.4%), OSWorld-Verified (72.7%), ARC-AGI-2 (68.8%), GPQA Diamond (91.3%), GDPval-AA (1606 Elo), BrowseComp, and Humanity’s Last Exam (53.0% with tools). Across multiple benchmarks, it achieves SOTA or near-SOTA performance, marking a substantial architectural leap over its predecessors in agentic and complex knowledge-work pipelines.
Opus 4.6 demonstrates a definitive advantage specifically in high-economic-value workloads (finance, legal, research, agentic workflows) where structural precision, operational stability, and sustained reasoning are mandatory, rather than mere inference speed or throughput.
Official documentation: Introducing Claude Opus 4.6 (February 5, 2026) and System Card: Claude Opus 4.6 (February 2026). All metrics represent a 5-run average (unless otherwise specified), utilizing adaptive thinking, max effort, and default sampling parameters (temperature, top_p). Context utilization did not exceed the 1M token threshold.
Core Benchmarks & Architectural Comparison
Data matrix of primary results (February 2026, Anthropic telemetry + independent validation):
| Benchmark | Opus 4.6 | Sonnet 4.6 | Opus 4.5 | Gemini 3 Pro | GPT-5.2 | Architectural Commentary |
|---|
| Terminal-Bench 2.0 | 65.4% | — | 59.8% | 56.2% | 64.7% | Agentic terminal coding; Opus leads (SOTA). |
| SWE-bench Verified | 80.8% | 79.6% | 80.9% | 76.2% | 80.0% | Real-world software engineering; near-parity with Opus 4.5. |
| OSWorld-Verified | 72.7% | 61.4% | 66.3% | — | — | Computer use (Ubuntu VM, mouse/keyboard); massive generational leap. |
| ARC-AGI-2 (Verified) | 68.8% | ~60.4% | 37.6% | 45.1% (Deep Thinking) | 54.2% | Novel reasoning; +31.2pp over Opus 4.5, establishing SOTA. |
| GPQA Diamond | 91.3% | 74.1% | 87.0% | 91.9% | 93.2% | Graduate-level science; approaching saturation, yet +4.3pp over 4.5. |
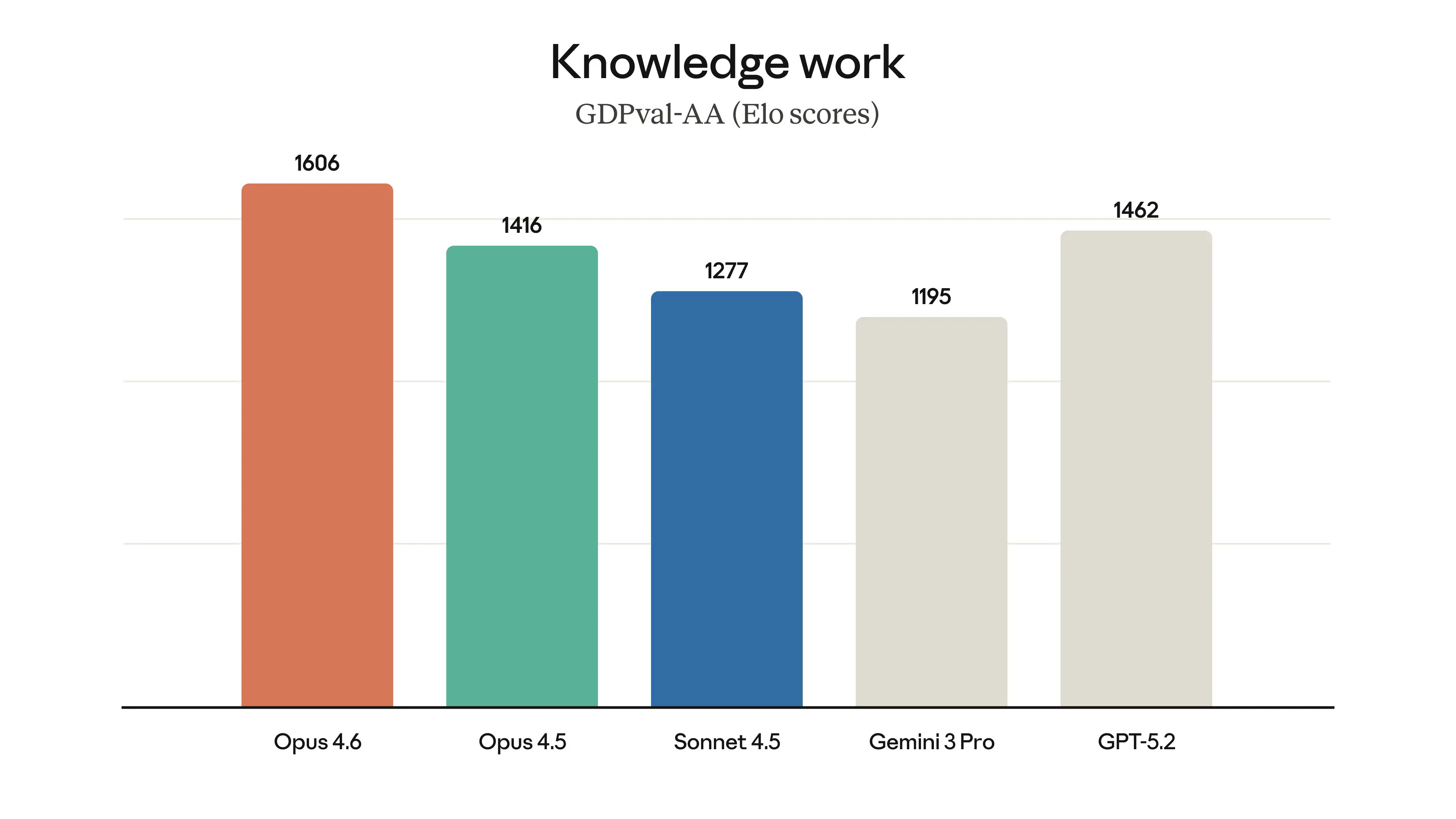
| GDPval-AA (Elo) | 1606 | 1633 (max effort) | ~1416 | ~1195 | ~1462 | Economically valuable tasks (finance/legal/office); Opus +190 Elo over 4.5, though Sonnet leads here. |
| BrowseComp | ~84.0% | — | 74.3% | — | — | Hard-to-find online information retrieval; Opus leads. |
| Humanity’s Last Exam (w/ tools) | 53.0% | — | ~43.4% | — | — | Multidisciplinary expert challenges; SOTA. |
Metrics sourced from System Card (Table 2.3.A) and release notes. ARC-AGI-2 execution leveraged a 120k thinking budget + high/max effort profiles. Terminal-Bench 2.0 was evaluated on the Terminus-2 harness with 1×/3× resource allocation. SWE-bench represents a 25-run statistical average.
Where Opus 4.6 Demonstrates Maximum Architectural Leverage
- ✔️ Agentic coding and autonomous computer use (Terminal-Bench 2.0, OSWorld-Verified): +5.6pp and +6.4pp delta over Opus 4.5—yielding superior sustained performance across massive codebases, robust self-debugging, and tool orchestration;
- ✔️ Novel reasoning (ARC-AGI-2): A +31.2pp leap over its predecessor—the most significant delta, indicative of fundamentally upgraded adaptive thinking and long-horizon planning protocols;
- ✔️ Knowledge work (GDPval-AA, Finance Agent, BigLaw Bench ~90.2%): Opus commands domains with zero-tolerance for error (finance, legal, research), where human domain experts overwhelmingly prefer its highly structured outputs;
- ✔️ Long-context reasoning (MRCR v2 1M — 76%, see prior section): Directly correlates with operational stability in intensive environments like BrowseComp and OSWorld.
For high-throughput or standard "office" workloads (e.g., GDPval-AA), Sonnet 4.6 consistently outpaces Opus 4.6 due to higher inference velocity and highly optimized compute costs, but Opus remains the structural necessity for edge-case resilience.
Section Takeaway: Opus 4.6 operates at or near SOTA in workloads demanding absolute computational precision, operational stability, and highly complex agentic reasoning capabilities, whereas Sonnet 4.6 is structurally engineered to win on speed and cost-efficiency for median-complexity tasks.
🎯 Coding & Agentic Tasks: Where Opus 4.6 Empirically Outperforms Sonnet 4.6
Complex architectural planning, sustained agentic workflows, and massive codebase navigation
Opus 4.6 demonstrates a commanding advantage over Sonnet 4.6 in deployments requiring deep architectural planning, prolonged agentic autonomy, navigation of monolithic repositories, and self-correction during continuous debugging loops. On Terminal-Bench 2.0, Opus scores 65.4% (SOTA), while Sonnet 4.6 trails at approximately 59.1–59.55% (configuration dependent). On OSWorld-Verified, Opus hits 72.7% against Sonnet’s 72.5% (statistical parity). The critical divergence manifests in deeply complex, multi-step pipelines where Sonnet is prone to context drift or executes superficial architectural patches.
Opus 4.6 sustains long-horizon agentic logic with higher fidelity, orchestrates operational sequences with greater precision, and executes self-correction loops far more efficiently—mandatory traits for autonomous workflows interacting with disparate tools and massive code volumes.
Opus 4.6 elevates coding capabilities via advanced adaptive thinking (unlocking deeper reasoning at max effort), enhanced state stability across agentic loops, and the structural capacity to traverse codebases spanning hundreds of thousands of lines (leveraging the 1M beta context). Sonnet 4.6 is faster and highly economical for iterative engineering tasks, but in sustained agentic coding (where an agent must recursively call tools, parse outputs, and recalibrate its execution plan), Opus delivers lower failure rates and superior run-to-run consistency.
On SWE-bench Verified, Opus 4.6 scores 80.8% versus Sonnet 4.6’s 79.6% (effective parity). However, on Terminal-Bench 2.0 (agentic terminal operations: CLI execution, deployment debugging, from-source builds), the delta is highly pronounced: Opus vastly superior in error recovery and multi-command chaining. OSWorld-Verified (desktop automation: mouse/keyboard in Ubuntu VMs) shows baseline parity, but Opus is measurably more stable on high-complexity, long-horizon operational sequences.
The Mechanics of Opus's Agentic Superiority
Agentic coding is not standard code generation; it is an autonomous operational loop: planning → execution → observation → correction → repeat. Opus dominates here via:
- ✔️ Superior architectural planning—drastically reducing overengineering or dropped logical steps;
- ✔️ Extreme resilience to context drift in prolonged sessions (powered by adaptive thinking + the 1M beta window);
- ✔️ Advanced self-debugging protocols (autonomously trapping its own regressions during review phases);
- ✔️ High-fidelity navigation across massive repositories (mapping dependencies without logic loss).
For engineering squads, this translates directly to fewer manual correction iterations, mitigated production regression risks, and a drastically higher ROI on complex architectural refactors (where senior engineering time runs $150–300/hr).
Production Scenarios: Where Opus 4.6 Replaces Sonnet
Scenario 1: Refactoring a Monolithic Codebase (200–300k lines)
Objective: Decouple a monolith into microservices (e.g., legacy Java/Spring Boot → isolated Docker/K8s modules). Opus 4.6 ingests the entire repository natively (via the 1M context), maps the dependency graph, proposes a strategic execution plan (accounting for circular dependencies and shared binaries), generates per-file deltas, and self-validates state consistency post-iteration. Sonnet 4.6 typically mandates chunking (50–100k token blocks), frequently loses global architectural context, and burns compute on excessive correction loops. Outcome: Opus completes the refactor in 1.5–2x less time with an exponentially lower error rate.
Scenario 2: Deep Tracing of Multi-Layer Production Bugs
Objective: Isolate the root cause of an anomaly spanning a fetch-utility → service layer → router pipeline (3+ abstraction layers). Opus 4.6 autonomously executes 10–15+ tool calls (git blame, log aggregation, stack trace analysis), tracks the error across layers, and commits a targeted fix backed by architectural reasoning. Sonnet 4.6 frequently halts at surface-level diagnostics or generates incomplete logic traces. Difference: Opus traps deep 3-layer bugs that Sonnet entirely misses (validated via PR review benchmarks where Opus flagged structural vulnerabilities invisible to Sonnet). Outcome: Fewer post-fix regressions and robust reliability on high-stakes debugging pipelines.
Section Takeaway: Opus 4.6 immediately yields positive ROI on complex, prolonged agentic workloads involving massive codebases or deep reasoning/debugging, whereas Sonnet 4.6 remains the optimal routing choice for rapid, medium-complexity iterative tasks.
💼 Knowledge Work & Enterprise-Grade Operations
Financial computation, legal analysis, research, and high-value economic tasks
Opus 4.6 asserts market leadership on GDPval-AA (1606 Elo, holding a +144 Elo delta over GPT-5.2 and +190 Elo over Opus 4.5), Finance Agent (60.7% accuracy), BigLaw Bench (90.2%, the highest recorded score across the Claude ecosystem), and Real-World Finance (achieving higher end-to-end task-completion rates than all legacy models). This cements it as the premier architectural choice for enterprise deployments operating in zero-tolerance domains where inferential failures incur massive financial or reputational liabilities.
Opus 4.6 is structurally optimized for pipelines demanding multi-source reasoning, rigorous structured outputs, and absolute consistency within high-liability domains such as complex finance, legal structuring, and deep research workflows.
According to Anthropic's February 5, 2026 deployment announcement (Introducing Claude Opus 4.6) and the corresponding System Card, the model yields SOTA or near-SOTA metrics on benchmarks simulating highly complex professional environments. GDPval-AA (Artificial Analysis) is an Elo-based evaluation of 220 distinct tasks across 44 professions and 9 industries, where the model operates in an agentic loop equipped with shell access and web infrastructure. Opus 4.6 leads the board at 1606 Elo, representing a ~70% win-rate against GPT-5.2 (xhigh thinking). BigLaw Bench (rigorous legal reasoning) hits 90.2% with 40% perfect scores and 84% >0.8. Finance Agent (Vals AI, complex SEC filings research) scores 60.7% (SOTA, a 5.47pp improvement over Opus 4.5).
Core Knowledge Work Benchmarks
Primary metrics matrix (February 2026, via Anthropic, Artificial Analysis, Vals AI):
| Benchmark | Opus 4.6 | Opus 4.5 | Sonnet 4.6 / Competitors | Architectural Commentary |
|---|
| GDPval-AA (Elo) | 1606 | ~1416 | GPT-5.2 ~1462 | High-value economic tasks (finance/legal/office); +190 Elo over 4.5, ~70% win-rate vs GPT-5.2. |
| BigLaw Bench | 90.2% | — | — | Deep legal reasoning; 40% perfect, 84% >0.8 — highest in the Claude ecosystem. |
| Finance Agent (accuracy) | 60.7% | 55.23% | GPT-5.1 56.55% | SEC filings parsing & research; SOTA. |
| Real-World Finance (task completion) | Peak score | Lower | — | End-to-end financial workflows (spreadsheets, slides, reports); internal Anthropic evaluation. |
These benchmarks correlate directly with verifiable improvements in multi-source computation (e.g., a +10pp surge on Box evals for complex legal/financial/technical data structures — 68% vs the 58% Opus 4.5 baseline).
Execution Mechanics in Enterprise Deployments
In enterprise knowledge work, reasoning failures do not merely cost compute time—they incur financial penalties, regulatory compliance risks, and critical reputational damage. Opus 4.6 commands this sector via:
- ✔️ Unmatched reasoning and architectural planning across agentic loops (web retrieval, secure code execution, tool API orchestration);
- ✔️ Absolute consistency in generating complex structured outputs (financial spreadsheets, executive slides, regulatory reports);
- ✔️ Rigorous alignment constraints and near-zero misaligned behavioral drift (per the System Card: exceptionally low rates of deception, sycophancy, or misuse cooperation; equal to or exceeding Opus 4.5—the most highly aligned frontier model previously available);
- ✔️ The structural capacity to ingest and process massive data lakes without context rot (via the 1M beta window).
The System Card explicitly notes that the architecture maintains a highly functional alignment profile with a low rate of over-refusals on benign enterprise queries.
Enterprise Deployment Scenarios
Scenario 1: Financial Computation & M&A Due Diligence (Finance Agent / Real-World Finance)
Objective: Ingest complex SEC filings of a publicly traded entity, extract obscure financial metrics, construct a comparable market analysis, and generate an executive investment brief. Opus 4.6 parses multi-source data lakes (filings, external market intelligence, internal proprietary spreadsheets), synthesizes actionable insights, and compiles production-ready outputs (presentations/documents). On Finance Agent, it hits 60.7% accuracy (SOTA). In internal Real-World Finance evaluations, it achieves the highest end-to-end task completion rate of any model, primarily due to sustained reasoning without granular detail loss.
Scenario 2: Legal Document Review & Risk Auditing (BigLaw Bench)
Objective: Deep analysis of a 200-page enterprise contract, mapping internal inconsistencies, cross-referencing obscure clauses, and flagging high-liability risk vectors. Opus 4.6 secures 90.2% on BigLaw Bench (40% perfect scores), successfully trapping subtle, structural vulnerabilities that standard semantic or keyword searches bypass entirely. In Box evals, it demonstrates a +10pp leap in multi-source legal/financial analysis (68% vs 58%). It is the structurally superior choice for M&A due diligence and strict compliance auditing.
Scenario 3: Deep Research & Multi-Source Synthesis Pipelines
Objective: Synthesize complex market intelligence directly from regulatory frameworks, dense scientific papers, and internal telemetry. Opus 4.6 deploys BrowseComp (SOTA) for obscure information retrieval and executes DeepSearchQA-style multi-hop queries. In rigorous enterprise evaluations (e.g., Box AI), it achieves near-perfect scoring in highly technical domains demanding exhaustive cross-verification protocols.
Enterprise Workloads operating in high-liability environments (finance, legal, research) represent the core deployment strength of Opus 4.6. Its architectural superiority in sustained reasoning, output consistency, and strict alignment provides massive operational leverage over Sonnet 4.6 or legacy Opus architectures.
💼 Comparing with Sonnet 4.6: When to Deploy Opus (Decision Matrix)
Decision matrix based on cost, context, complexity, latency, and task typology
Sonnet 4.6 is the default choice for 75–85% of standard workloads due to its superior price/performance/velocity ratio. Opus 4.6 should be reserved for scenarios demanding maximum precision, structural stability over extreme context lengths, deep reasoning, or operations in domains with high error-cost liabilities (agentic coding, finance/legal/research). A hybrid routing strategy (Sonnet by default → Opus based on confidence/effort) typically yields 60–80% API cost savings.
The distinction between these models is context-dependent: Opus 4.6 excels where Sonnet 4.6 reaches its cognitive ceiling (e.g., >200k tokens, multi-step agentic loops, GPQA/ARC-AGI-2 level tasks). For the majority of production environments, a dynamic router—not a fixed model choice—is the optimal architectural approach.
Below is the expanded decision matrix. Pricing is calculated per 1 million tokens (Input / Output).
| Criterion |
Sonnet 4.6 |
Opus 4.6 |
Strategic Recommendation |
| Price (Input / Output) |
$3 / $15 |
$5 / $25 |
Sonnet is ~1.67× cheaper. For mixed workloads, a router pays for itself within 1–2 weeks. |
| Context Window (Std / Beta) |
200k / 1M beta |
200k / 1M beta + superior stability |
Deploy Opus for prompts >200k tokens or when MRCR v2/recall degrades in Sonnet. |
| Task Complexity (Reasoning Depth) |
Optimal for median and high-effort |
SOTA for very hard (GPQA Diamond 91.3%, ARC-AGI-2 68.8%) |
Use Opus if the task demands GPQA/ARC level logic or multi-hop reasoning with self-correction. |
| Response Latency |
Fast (optimized for low/medium effort) |
Slower (optimized for high/max effort) |
Sonnet for iterative tasks, prototyping, and chat; Opus for batch/offline deep analysis. |
| Agentic Workflows |
Reliable for 5–15 steps |
Superior for 20+ steps (Terminal-Bench 65.4%, OSWorld 72.7%) |
Opus for autonomous agents, multi-tool loops, and long-horizon planning. |
| Knowledge Work (Finance, Legal) |
Optimal for median complexity |
Market Leader (GDPval-AA 1606 Elo, BigLaw 90.2%) |
Opus for high-stakes tasks (compliance, due diligence, investment analysis). |
| Coding (Large Codebases) |
Efficient for 50–150k lines |
Superior for 300k+ (dependency tracking, self-debug) |
Opus for monolithic refactors, deep debugging, and agentic code generation. |
| Cost-efficiency (ROI) |
High for 80% of tasks |
High only when mitigating high-value errors |
Router: Sonnet default → Opus if confidence <0.85 or effort=max. |
Practical Model Selection Guidelines
- ✔️ **Default to Sonnet 4.6** (effort: "high"): This covers the vast majority of production requests with the best balance of cost, quality, and speed;
- ✔️ **Escalate to Opus 4.6** if:
- Context exceeds 200k tokens and recall drops (MRCR-style failures);
- Tasks reach GPQA Diamond / ARC-AGI-2 / Terminal-Bench 2.0 complexity;
- Agentic loops exceed 15–20 steps or require extreme run-to-run consistency;
- Domain is finance/legal/research with high cost-of-failure;
- Model confidence score (if using adaptive thinking) drops below 0.85–0.9.
- ✔️ **Implement a basic router**: Initial request to Sonnet → if effort=max or confidence is low → reroute to Opus. This saves 60–80% on overhead according to February 2026 dev benchmarks;
- ✔️ **Test on your specific datasets**: Benchmarks are an orientation; production behavior can vary by 10–20% based on prompting techniques and tool availability.
Summary: Sonnet 4.6 is the "workhorse" for most scenarios. Opus 4.6 is a precision instrument for tasks where its gains in accuracy and structural stability provide real economic value—ideally managed through a dynamic router.
💼 Pricing & ROI: Is Opus 4.6 Worth the Premium?
Short Answer: Yes, if the task has a high cost-of-failure or provides massive time/resource savings; otherwise, it is an over-expenditure compared to Sonnet 4.6.
Standard Claude Opus 4.6 pricing: $5 per million input tokens and $25 per million output tokens. For prompts >200k tokens (long-context beta), a premium tier applies: $10 / $37.50. US-only inference carries a 1.1× multiplier ($5.50 / $27.50). Batch API provides a 50% discount ($2.50 / $12.50). ROI is driven by error mitigation: in high-value enterprise and agentic coding tasks, Opus pays for itself rapidly; in routine tasks, Sonnet is more efficient.
Opus 4.6 is 1.67× more expensive than Sonnet 4.6 per token ($3 / $15), but its architectural advantages only yield ROI where Sonnet fails or requires excessive manual iterations.
Pricing data sourced from February 5, 2026 release notes and the Developer Platform pricing page. Base rates remain consistent with Opus 4.5, with the addition of the long-context premium for >200k tokens. Optimization options include:
- **Prompt caching**: Up to 90% savings on repetitive prompt structures;
- **Batch API**: 50% discount for asynchronous, non-urgent tasks;
- **Fast mode**: $30 / $150 (2.5× speedup, significant premium).
Detailed Pricing (As of February 2026)
Base Tariffs (USD per 1M Tokens):
| Mode / Context | Input ($/MTok)</th><th>Output ($/MTok) | Commentary |
|---|
| Standard (≤200k tokens) | 5.00 | 25.00 | Base Opus 4.6 rate. |
| Long-context beta (>200k) | 10.00 | 37.50 | Developer Platform only; 2× input / 1.5× output. |
| US-only inference | 5.50 | 27.50 | 1.1× multiplier for data residency compliance. |
| Batch API (50% off) | 2.50 | 12.50 | For non-urgent, asynchronous processing. |
| Fast mode | 30.00 | 150.00 | 2.5× velocity; high-cost real-time premium. |
Calculating ROI: When Opus Pays Off
ROI = (Time/Financial Savings from Accuracy) / Request Cost.
- **Complex Monolithic Refactor**: Opus completes in 1–2 requests (saving 4–8 hours of manual senior engineering = $600–2,000). Request cost ~$1–$5. **ROI: 100–400×.**
- **Finance/Legal Due Diligence**: Opus mitigates error risks (costing $10k+). A single accurate analysis saves $5k–50k. Request cost ~$2–$10. **ROI: Massive for critical paths.**
- **Routine Code Review / Chat**: Sonnet executes for $0.15–$0.75, Opus for $0.25–$1.25. If quality delta is negligible, you're paying a 67% premium for zero ROI.
Final Assessment: Opus yields ROI on tasks where:
- 1M context or high/max effort is required;
- Task requires GPQA/ARC/Terminal level precision;
- Time savings exceed 3–5 hours of specialized labor;
- Error costs exceed $1k (compliance, production bugs, investment logic).
❓ Frequently Asked Questions (FAQ)
Is 1M context available in Claude.ai?
No, the full 1M token context window is currently restricted to **beta mode on the Claude Developer Platform** (for requests >200k tokens with premium pricing). Standard interfaces (Pro, Max, Team, Enterprise) maintain a 200k token limit as of February 2026 to ensure infrastructure stability.
Is Opus 4.6 faster than Sonnet 4.6?
No. Opus 4.6 has higher latency, particularly at "high" or "max" effort levels. Sonnet 4.6 is engineered for velocity. Opus prioritizes adaptive thinking and deeper self-correction, making it slower but more precise on complex reasoning paths.
Can I automate Sonnet → Opus routing?
Yes, this is the gold standard for 2026. Routing can be triggered by confidence scoring, effort detection, or keyword-based classification (e.g., "deep analysis", "legal review"). This approach typically cuts API overhead by 60–80%.
Is Opus 4.6 available via Cloud Providers?
Yes. The `claude-opus-4-6` model was available on day one (February 5, 2026) via **Amazon Bedrock, Google Vertex AI, and Microsoft Azure AI Foundry**. Pricing aligns with base tariffs ($5/$25), subject to regional multipliers.
✅ Final Conclusions
- 🔹 **Claude Opus 4.6** is the first model in its lineage with a functional 1M context window and definitive SOTA leadership on the hardest 2026 benchmarks (ARC-AGI-2, Terminal-Bench 2.0). It is the premier tool for sustained reasoning and high-precision agentic behavior.
- 🔹 **The delta vs Sonnet 4.6** is significant only on high-complexity tasks: codebases >300k lines, multi-step agentic workflows (>20 steps), and high-stakes financial/legal auditing. For 80% of routine work, Sonnet 4.6 remains the superior choice.
- 🔹 **The 2026 ROI Strategy**: Use Sonnet 4.6 as your default workhorse and implement a dynamic router to escalate to Opus 4.6 only when context size, complexity, or liability warrants the premium.
The Core Architect's Take: Claude Opus 4.6 is not a general-purpose tool for everything; it is a specialized instrument for the hardest 5% of enterprise and agentic challenges where precision and self-correction are more valuable than the $5–$25 token premium.