
Агент отримав запит — обробив — відповів. Наступний запит — і він не пам'ятає нічого з попереднього.
Не тому що щось зламалось. А тому що так влаштована LLM за замовчуванням: кожен виклик — чистий аркуш.
Якщо ви будуєте агента і не думали про пам'ять — ви будуєте амнезика з доступом до інтернету.
Ця стаття — частина серії про AI агентів на Spring Boot.
Якщо ви ще не читали про масштабування інструментів —
Tool RAG: що робити коли у агента забагато інструментів.
Про те як агент вирішує що викликати —
Як LLM вирішує коли викликати tool.
Зміст
Агент без пам'яті: живий баг і чому це не баг
В Agent Chat є п'ять інструментів: Wikipedia, Tavily, NewsAPI, Alpha Vantage, ArXiv.
Агент веде дискусію, шукає факти, формулює аргументи — все виглядає добре.
Але в певний момент починається щось дивне.
Як виглядає проблема в логах
// Раунд 1 — все нормально:
INFO: Round 1 AGENT_A — Tavily search: 'vibe coding productivity statistics'
INFO: Tavily found 3 results, top: "GitHub Copilot boosts productivity by 51%"
INFO: Round 1 AGENT_A reply: "Дані показують що vibe coding підвищує продуктивність..."
// Раунд 5 — той самий агент, та сама тема:
INFO: Round 5 AGENT_A — Tavily search: 'vibe coding productivity statistics'
// ↑ Той самий запит що і в раунді 1. Агент не пам'ятає що вже шукав це.
INFO: Tavily found 3 results — ті самі результати
INFO: Round 5 AGENT_A reply: "Як я вже зазначав раніше..."
// ↑ Агент ДУМАЄ що зазначав — але в раунді 5 він бачить тільки останні 8 повідомлень.
// Раунд 1 вже випав з вікна. Він не "зазначав" — він галюцинує про власну пам'ять.
Це не баг у коді. Tavily відповів правильно. Spring AI відпрацював коректно.
Проблема в архітектурі: агент без пам'яті не знає що він вже робив три кроки тому.
Результат — повторні tool calls, суперечливі твердження, і найнебезпечніше —
впевнені посилання на "раніше сказане" якого насправді немає в контексті.
65% відмов enterprise AI-систем у 2025 році були спричинені
не перевищенням контекстного вікна, а "context drift" — поступовою втратою
когерентності через відсутність структурованої пам'яті. Про це —
Zylos Research (лютий 2026).
Три симптоми агента-амнезика
Перш ніж розбирати рішення — важливо розпізнати проблему.
Коли я вперше зіткнувся з цим в Agent Chat, то не одразу зрозумів що відбувається:
код правильний, tools відповідають, але агент поводиться дивно.
Виявилось що діагностика починається не з коду, а з логів.
Ось три сигнали що ваш агент страждає від відсутності пам'яті:
Симптом 1 — Повторні tool calls. Агент викликає той самий інструмент
з тим самим запитом кілька разів за сесію. В логах — однакові рядки з різницею в кілька хвилин.
Ви платите за API двічі за ту саму відповідь.
Симптом 2 — Суперечливі твердження. В раунді 2 агент стверджує X.
В раунді 7 — стверджує не-X, не помічаючи протиріччя. Раунд 2 вже за межею вікна.
Для агента його більше не існує.
Симптом 3 — Галюцинації про власну пам'ять. Найнебезпечніший.
Агент каже "як я вже зазначав" або "ми вже обговорювали" — але це повідомлення
вже поза вікном. Агент конфідентно посилається на те чого він не пам'ятає.
Чому LLM stateless — і що це означає для циклу
LLM — це функція. На вхід подаєш текст, на виході отримуєш текст.
Між двома викликами — нічого. Жодного стану, жодної пам'яті, жодного "я".
Кожен виклик — незалежна операція.
Я добре пам'ятаю перші експерименти з ранніми моделями — GPT-3 і перші версії ChatGPT.
Контекстне вікно було маленьким (4K токенів), і вже через 10–15 повідомлень
модель починала "забувати" початок розмови. Доводилось повторювати контекст задачі,
нагадувати що ми вже обговорили, іноді починати сесію заново.
Тоді це здавалось технічним обмеженням яке скоро виправлять.
Виявилось що це не обмеження — це архітектурна властивість.
Вікна стали більшими (128K, 1M токенів), але stateless природа нікуди не зникла.
Ілюзія пам'яті через контекст
Коли ви спілкуєтесь з ChatGPT і він "пам'ятає" що ви сказали п'ять повідомлень тому —
це не пам'ять. Це ілюзія. Кожен запит містить всю попередню переписку як текст.
Модель "бачить" минуле тому що воно передано їй в поточному запиті, а не тому що вона його "пам'ятає".
// Що насправді відбувається при кожному виклику LLM:
// Виклик 1:
chatModel.call("Привіт, як тебе звати?")
// Модель бачить: ["user: Привіт, як тебе звати?"]
// Відповідає: "Я AI агент..."
// Після виклику — нічого не залишається всередині моделі
// Виклик 2 (через 5 хвилин):
chatModel.call(List.of(
new UserMessage("Привіт, як тебе звати?"),
new AssistantMessage("Я AI агент..."),
new UserMessage("А що ти вмієш?") // ← новий запит
))
// Модель бачить всю переписку — але тільки тому що ми її передали повторно
// Між викликами 1 і 2 модель "забула" абсолютно все
Це фундаментальна архітектурна властивість трансформерних моделей —
не баг і не обмеження конкретного провайдера.
CoALA (Cognitive Architectures for Language Agents)
формалізує це як розподіл між "working memory" (поточний контекст) і
"long-term memory" (зовнішнє сховище яке треба реалізовувати окремо).
Детально про те як контекстне вікно впливає на поведінку і вартість —
Контекстне вікно LLM: чому AI забуває і скільки це коштує.
Stateless цикл = агент без пам'яті на кожному кроці
В агентному циклі це означає: кожен раунд — окремий виклик LLM.
Якщо ви не передаєте history явно — агент не пам'ятає попередніх раундів взагалі.
Якщо передаєте history через sliding window — агент "забуває" все що за межею вікна.
І навіть у межах вікна — він не знає що вже робив: які tools викликав,
які результати отримав, які рішення приймав.
// Типовий агентний цикл без пам'яті:
while (!shouldStop) {
// Кожна ітерація — окремий виклик з тим самим history
// Агент не знає:
// - які tools він вже викликав в цій сесії
// - які результати він вже отримав
// - що він вирішив три раунди тому
ChatResponse response = chatModel.call(
new Prompt(buildHistory(session)) // ← history з обмеженим вікном
);
// ...
}
Саме для вирішення цієї проблеми існують чотири типи пам'яті агента.
Кожен вирішує різний аспект втрати контексту — і кожен має свою ціну і складність.
Чотири типи пам'яті: таблиця і детальний розбір
Класифікацію типів пам'яті агента формалізує
CoALA (Cognitive Architectures for Language Agents, Sumers et al. 2023) —
фреймворк побудований на аналогії з когнітивною психологією.
Він виділяє working memory (поточний контекст) і три типи довготривалої пам'яті:
episodic, semantic і procedural. У 2025–2026 ця класифікація стала стандартом —
її використовують
Mem0,
IBM,
LangMem, і більшість production фреймворків.
Для практичного Spring Boot розробника я адаптую цю класифікацію в чотири типи
з прив'язкою до конкретних реалізацій:
| Тип |
Що зберігає |
Персистентність |
Latency |
Складність |
Коли потрібен |
| In-context |
Останні N повідомлень |
Тільки в сесії |
0ms |
Мінімальна |
Завжди — стартова точка |
| Episodic (external) |
Summary + tool calls + рішення |
Між сесіями, в БД |
5–20ms |
Середня |
Коли вікно вже не рятує |
| RAG memory |
Факти, документи, знання |
Постійно, pgvector |
10–50ms |
Середня |
Велика база знань або крос-сесійний контекст |
| Semantic (граф) |
Сутності та зв'язки між ними |
Постійно, граф БД |
20–100ms |
Висока |
Enterprise, складні залежності між фактами |
Тип 1: In-context memory — sliding window і pinning
Найпростіший тип: передаємо останні N повідомлень при кожному виклику LLM.
Це те що більшість розробників роблять за замовчуванням — і це правильний старт.
В Agent Chat реалізовано через HISTORY_SIZE=8.
В ContextService з мого e-commerce проекту — через HISTORY_SIZE=20 з pinning.
Ключова деталь яку часто пропускають: не всі повідомлення однаково важливі.
Перші повідомлення сесії зазвичай містять контекст задачі — що робимо, які обмеження.
Якщо вони випадуть з вікна — агент "забуде" саму задачу, хоча пам'ятатиме останні дрібниці.
// In-context з pinning — Agent Chat підхід:
private static final int HISTORY_SIZE = 20; // sliding window
private static final int PINNED_COUNT = 3; // перші 3 повідомлення завжди в контексті
public List<Message> buildHistory(ChatSession session) {
List<ChatMessage> all = chatMessageRepository
.findByChatSessionIdOrderByCreatedAtAsc(session.getId());
List<Message> result = new ArrayList<>();
// Крок 1: pinned — перші 3 повідомлення (контекст задачі)
int pinned = Math.min(PINNED_COUNT, all.size());
all.subList(0, pinned).forEach(m -> result.add(toSpringAiMessage(m)));
// Крок 2: recent — останні HISTORY_SIZE повідомлень (не дублюючи pinned)
int skipTo = Math.max(pinned, all.size() - HISTORY_SIZE);
if (skipTo < all.size()) {
all.subList(skipTo, all.size()).forEach(m -> result.add(toSpringAiMessage(m)));
}
return result;
}
// Результат: контекст завжди містить і "що робимо" (pinned) і "що щойно сталось" (recent)
Математика токенів для in-context: одне повідомлення в Agent Chat
займає в середньому 150–300 токенів (з tool results — до 1000).
При HISTORY_SIZE=8 і deepseek-chat — це 1200–8000 токенів тільки на history.
При HISTORY_SIZE=20 — 3000–20000 токенів. Контекстне вікно починає тиснути.
Детально про вартість токенів і стратегії стиснення —
у наступній статті серії про
контекстне вікно LLM.
Підводний камінь: in-context memory — lossy by design.
Коли повідомлення випадає з вікна — воно зникає назавжди (якщо немає episodic memory).
Агент не знає що він "забув". Він просто діє як ніби цього ніколи не було.
Тип 2: Episodic memory — журнал дій і summary
Episodic memory зберігає те що відбувалось: які tool calls були зроблені,
які рішення прийняті, що знайдено. На відміну від in-context — зберігається в БД
і доступна між сесіями і після зміщення вікна.
У своєму e-commerce проекті на Spring Boot я реалізував episodic memory
через LLM summarization: коли кількість повідомлень перевищує поріг
(SUMMARY_THRESHOLD=30) — старіші повідомлення стискаються в summary
і зберігаються в БД. При наступному buildHistory() summary ін'єктується
як SystemMessage на початок контексту.
// Episodic memory через summarization — з ContextService:
private static final int SUMMARY_THRESHOLD = 30; // тригер summarization
private static final int KEEP_RECENT = 15; // скільки повідомлень залишається "живими"
public void summarizeIfNeeded(ChatSession session) {
if (!needsSummarization(session)) return;
// ВАЖЛИВО: три окремі транзакції — не одна довга!
// Крок 1: читаємо дані → транзакція відкрилась і одразу закрилась
List<ChatMessage> toSummarize = getMessagesForSummarization(session);
// Крок 2: генеруємо summary БЕЗ відкритої транзакції
// Ollama/LLM може думати 30–60с — за цей час БД-з'єднання вільне
String newSummary = generateSummary(toSummarize, session.getSummary());
// Крок 3: зберігаємо результат → нова коротка транзакція
saveSummary(session, newSummary, summarizeUpTo);
}
// При наступному запиті — summary ін'єктується в контекст:
if (session.getSummary() != null && !session.getSummary().isBlank()) {
result.add(new SystemMessage(
"[Резюме попередньої розмови]: " + session.getSummary()));
}
Три транзакції — критична архітектурна деталь.
Новачки зі Spring роблять одну довгу транзакцію: читають повідомлення,
тримають з'єднання відкритим поки LLM відповідає (30–60 секунд),
потім зберігають. Результат — connection pool вичерпується при кількох
паралельних сесіях. Правильно: читати → закрити транзакцію → чекати LLM → нова транзакція для запису.
Підводний камінь episodic через LLM summarization:
7B модель (Ollama qwen3:8b, llama3.1:8b) погано стискає технічний контекст.
Tool results з числами, кодом, API відповідями — втрачаються або спотворюються.
Дослідження
Augment Code (квітень 2026)
показало: агресивна summarization може знизити точність відповідей і
збільшити кількість кроків для вирішення задачі — навіть якщо токенів витрачається менше.
Summarization працює на чітких фазових межах, а не як постійна компресія.
Тип 3: RAG memory — pgvector для довготривалих знань
RAG memory — це зовнішня векторна база знань до якої агент звертається через семантичний пошук.
На відміну від episodic summary (lossy compression) — RAG зберігає точні факти
і дозволяє точно знайти релевантний контекст навіть через тижні.
Принципова відмінність від класичного RAG для документів: в agent RAG memory
зберігаються не документи клієнта, а знання самого агента —
результати попередніх tool calls, прийняті рішення, факти про користувача.
-- Схема таблиці для RAG memory агента (pgvector):
CREATE TABLE agent_memory (
id UUID PRIMARY KEY DEFAULT gen_random_uuid(),
session_id VARCHAR(100),
user_id BIGINT, -- для персоналізації між сесіями
memory_type VARCHAR(50), -- 'tool_result', 'decision', 'user_fact'
content TEXT NOT NULL, -- текст для пошуку
metadata JSONB, -- додаткові поля: tool_name, score, тощо
embedding vector(1536), -- pgvector, text-embedding-3-small
created_at TIMESTAMP DEFAULT NOW(),
expires_at TIMESTAMP -- TTL для застарілих фактів
);
CREATE INDEX agent_memory_embedding_idx
ON agent_memory USING ivfflat (embedding vector_cosine_ops)
WITH (lists = 10);
-- Пошук релевантної пам'яті при новому запиті:
SELECT content, metadata, 1 - (embedding <=> :queryEmbedding) as score
FROM agent_memory
WHERE user_id = :userId
AND (expires_at IS NULL OR expires_at > NOW())
ORDER BY embedding <=> :queryEmbedding
LIMIT 5;
Коли RAG memory виправдана: коли агент обслуговує одного користувача
протягом тривалого часу (тижні, місяці) і повинен пам'ятати факти між сесіями.
В AskYourDocs я зіткнувся з цим на практиці:
клієнт завантажує корпоративні документи, задає питання, отримує відповіді —
і повертається наступного дня з уточненням до вчорашнього запиту.
Без RAG memory агент не знає про що була вчорашня розмова.
Він не пам'ятає які документи вже були проаналізовані, які висновки зроблені,
які питання залишились відкритими.
Кожна нова сесія — чистий аркуш, і користувач змушений пояснювати контекст заново.
Саме тому в AskYourDocs RAG memory зберігає не тільки самі документи,
але й попередні запити клієнта, корпоративний контекст і прийняті рішення —
щоб агент міг продовжити роботу там де зупинився, а не починати з нуля.
Дослідження
Memori (березень 2026, arXiv)
показало: структурована RAG memory дозволяє досягти 81.95% точності на LoCoMo benchmark
використовуючи лише 1294 токени на запит — проти 26 000 токенів при підході
"весь контекст в вікно". Економія: 95% токенів при вищій точності.
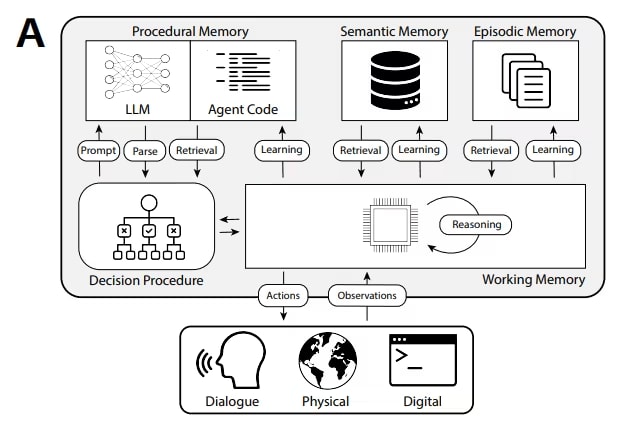
Тип 4: Semantic memory — граф знань агента
Semantic memory зберігає не події (episodic) і не документи (RAG),
а сутності і зв'язки між ними у вигляді графу.
Приклад: агент знає що "Клієнт X → використовує → Продукт Y",
"Продукт Y → має залежність → Модуль Z", "Модуль Z → має баг → Issue #123".
Такі ланцюжки неможливо ефективно зберігати ні в sliding window, ні у векторній БД.
У 2026 semantic memory реалізується через граф-бази даних або гібридні підходи.
Mem0 (травень 2026)
додав graph memory в січні 2026 — зберігає сутності як вузли
і зв'язки між ними як направлені ребра.
Atlan (квітень 2026)
зазначає: граф-БД ідеальні для episodic + semantic memory разом —
швидкий обхід зв'язків там де векторний пошук програє.
Чесне попередження: semantic memory — найскладніший тип.
Граф-БД (Neo4j, Kuzu, Amazon Neptune) додають окрему інфраструктуру,
складний query language, і нетривіальну логіку оновлення при зміні фактів.
Для першого агента — не починайте з semantic memory.
Вона виправдана тільки коли у вас складна мережа пов'язаних сутностей
яку потрібно обходити через кілька кроків.
Починайте з in-context → episodic → RAG, і тільки потім — semantic.
Гібридна архітектура: як типи пам'яті працюють разом
Чотири типи пам'яті — не альтернативи одне одному. В реальних production системах
вони комбінуються. Питання не "який тип обрати" а "які типи і в якому порядку підключати".
Як виглядає гібридна пам'ять в агентному циклі
Ось як виглядає повна картина для Agent Chat якщо підключити всі рівні пам'яті:
// Запит користувача: "яка ціна акцій Tesla і чи писали про неї новини?"
//
// ─── Крок 1: Збираємо контекст з усіх шарів пам'яті ───────────────────────
//
// Шар 1 — In-context (sliding window + pinned):
List<Message> history = contextService.buildHistory(session);
// → 3 pinned + 17 recent = 20 повідомлень
// → агент пам'ятає що відбувалось за останні ~30 хвилин сесії
// Шар 2 — Episodic summary (якщо сесія довга):
if (session.getSummary() != null) {
history.add(0, new SystemMessage(
"[Резюме попередньої розмови]: " + session.getSummary()));
}
// → стиснута пам'ять про те що було до sliding window
// → агент "знає" рішення прийняті годину тому навіть якщо вони за вікном
// Шар 3 — RAG memory (релевантні факти з БД):
List<String> relevantFacts = agentMemoryService.findRelevant(
"Tesla stock price news", session.getUserId(), 3);
if (!relevantFacts.isEmpty()) {
history.add(new SystemMessage(
"[Релевантний контекст з попередніх сесій]:\n" +
String.join("\n", relevantFacts)));
}
// → "Три дні тому користувач питав про Tesla, тоді ціна була $213"
// → агент може порівняти динаміку без повторного tool call
// Шар 4 — Semantic (тільки якщо є граф):
// → "Tesla → CEO → Elon Musk → також керує → SpaceX, X"
// → складні зв'язки між сутностями
// (не реалізовано в поточному Agent Chat — enterprise-рівень)
// ─── Крок 2: Tool RAG — inject тільки релевантні tools ────────────────────
List<ToolCallback> tools = toolRagService.findRelevantTools(userQuery, 3);
// → [AlphaVantageTool: 0.91, NewsApiTool: 0.84]
// ─── Крок 3: Виклик LLM з повним контекстом ───────────────────────────────
ChatResponse response = chatModel.call(new Prompt(history, options));
// ─── Крок 4: Зберігаємо важливе в episodic/RAG memory ────────────────────
agentMemoryService.save(AgentMemory.builder()
.userId(session.getUserId())
.memoryType("tool_result")
.content("Tesla TSLA ціна: $218.40 (+2.1%), новини: розширення Gigafactory")
.metadata(Map.of("tool", "AlphaVantageTool", "timestamp", Instant.now()))
.build());
// → наступного разу агент знатиме поточний контекст без повторного пошуку
Порядок inject в системний промпт має значення
Трансформерні моделі мають positional bias — токени на початку і в кінці
контексту отримують більше уваги ніж ті що в середині.
Тому порядок inject шарів пам'яті напряму впливає на якість відповіді:
// ✅ Правильний порядок (від найважливішого до найменш важливого):
[1] SystemMessage: роль агента і правила поведінки ← завжди перший
[2] SystemMessage: episodic summary (якщо є) ← контекст "що було"
[3] SystemMessage: RAG memory — релевантні факти ← точні знання
[4] UserMessage/AssistantMessage: pinned (перші 3) ← контекст задачі
[5] UserMessage/AssistantMessage: recent (sliding window) ← поточна розмова
[6] UserMessage: поточний запит ← завжди останній
// ❌ Типова помилка — RAG і summary після history:
[1] SystemMessage: роль агента
[2...N] UserMessage/AssistantMessage: вся history ← RAG загубиться в середині
[N+1] SystemMessage: RAG memory ← модель приділить менше уваги
Що зберігати в episodic і RAG memory — і що ні
Найпоширеніша помилка: зберігати все. Це швидко перетворює пам'ять
на сміттєзвалище де корисне тоне в шумі.
Чому це критично? Коли агент звертається до пам'яті — він робить семантичний пошук:
embedding запиту порівнюється з embedding збережених фактів.
Чим більше сміття в пам'яті — тим нижча якість пошуку.
Нерелевантні факти з'являються у топ результатах і займають місце в контексті.
Агент починає "галюцинувати" спираючись на вітання п'ятитижневої давності
або проміжні міркування які не призвели до жодного рішення.
Я перевірив це на AskYourDocs: після двох тижнів роботи без фільтрації
якість відповідей помітно просіла — пошук повертав релевантний score 0.71
для "Привіт! Як я можу допомогти?" замість реального контексту задачі.
Ось практичне правило яке вирішило цю проблему:
Зберігати обов'язково: результати tool calls з конкретними числами
(ціни, метрики, дати), рішення прийняті агентом ("обрано постачальника X"),
факти про користувача ("віддає перевагу коротким відповідям"),
помилки і причини невдач ("tool Y повернув помилку через rate limit").
Не зберігати: вітання і small talk, проміжні міркування агента
які не призвели до рішення, дублікати вже збережених фактів,
сирі tool results більше ніж 500 символів (стискати до суті).
Decision tree: з якого типу починати
Головна помилка — відразу будувати складну гібридну архітектуру.
Починайте з мінімального і додавайте тільки коли впираєтесь у реальне обмеження.
Ось decision tree з конкретними тригерами для переходу:
Який агент ви будуєте?
↓
Одноразова задача (без сесії, без history)
→ Пам'ять не потрібна взагалі. LLM stateless — і це добре.
Приклад: classify_document(), generate_summary()
↓
Діалог в межах однієї сесії (Agent Chat, чат-бот)
→ Старт: In-context sliding window (HISTORY_SIZE=8–20)
Додайте pinning для перших 3 повідомлень (контекст задачі).
Моніторте: чи агент повторює tool calls? Чи суперечить собі?
↓
Сесія стає довгою (30+ повідомлень) або дорогою за токенами
→ Додайте: Episodic summary (SUMMARY_THRESHOLD=30, KEEP_RECENT=15)
Ollama для summarization — безкоштовно для локального dev.
УВАГА: перевірте якість summary на технічному контенті вашого домену.
↓
Потрібна пам'ять між сесіями або для кількох користувачів
→ Додайте: RAG memory (pgvector + agent_memory таблиця)
Зберігайте: результати tool calls, рішення, факти про користувача.
Якщо вже є pgvector для документів — додати RAG memory легко.
↓
Складна мережа сутностей і зв'язків (10+ типів сутностей,
багатокрокові залежності, граф знань організації)
→ Додайте: Semantic memory (Neo4j, Kuzu, або Mem0 graph)
Тільки якщо векторний пошук вже не дає потрібної точності
для multi-hop запитів ("хто відповідає за компонент X який залежить від Y?")
↓
Ніколи не додавайте наступний тип поки не впрелись в реальне обмеження попереднього.
Таблиця: симптом → тип пам'яті
| Симптом |
Тип пам'яті який вирішує |
Пріоритет |
| Агент повторює той самий tool call |
In-context або Episodic (залежно від того чи вже за вікном) |
Критичний |
| Агент суперечить собі після 10+ раундів |
Episodic summary |
Критичний |
| Вартість токенів зростає з кожним раундом |
Episodic summary + tool result trimming |
Важливий |
| Нова сесія — агент не пам'ятає попередньої |
RAG memory (між сесіями) |
Важливий |
| Агент не знає контекст конкретного користувача |
RAG memory з user_id scope |
Важливий |
| Multi-hop запити: "хто відповідає за X що залежить від Y" |
Semantic memory (граф) |
Enterprise |
Практичне правило: для більшості B2B RAG сценаріїв
достатньо in-context + episodic summary + RAG memory для документів клієнта.
Semantic memory — тільки якщо у клієнта є складна організаційна ієрархія
яку потрібно обходити через кілька кроків.
Три рівні покривають 90% реальних кейсів.
Реалізація: ContextService з проекту
Нижче — повний розбір ContextService з мого e-commerce проекту на Spring Boot.
Це не синтетичний приклад: сервіс працює в production і реалізує одночасно
два типи пам'яті — in-context (sliding window + pinning) і episodic (LLM summarization).
Архітектура сервісу: що і чому
@Service
@RequiredArgsConstructor
@Slf4j
public class ContextService {
private final ChatMessageRepository chatMessageRepository;
private final ChatSessionRepository chatSessionRepository;
private final OllamaChatModel ollamaChatModel; // локальна модель для summary
// ── Константи ─────────────────────────────────────────────────────────
private static final int HISTORY_SIZE = 20; // sliding window
private static final int PINNED_COUNT = 3; // перші N повідомлень завжди в контексті
private static final int SUMMARY_THRESHOLD = 30; // тригер summarization
private static final int KEEP_RECENT = 15; // живі повідомлення після summary
}
Чотири константи визначають всю поведінку пам'яті. Розберемо кожну:
HISTORY_SIZE=20 — скільки останніх повідомлень потрапляє в контекст.
При середньому повідомленні в 200 токенів — це 4000 токенів тільки на history.
Для deepseek-chat ($0.27/M input) — ~$0.001 на запит, прийнятно.
Для claude-sonnet (~$3/M input) — вже $0.012 на запит, і це росте з кожним раундом.
PINNED_COUNT=3 — перші три повідомлення завжди в контексті,
незалежно від розміру history. Вони містять контекст задачі: що робимо, яка роль агента,
які обмеження. Без pinning — після 20+ раундів агент "забуває" саму задачу.
SUMMARY_THRESHOLD=30 — при 30+ повідомленнях запускається summarization.
Чому 30, а не 20? Щоб summary не запускався занадто часто.
Кожен summary — це окремий LLM виклик (15–60 секунд на Ollama).
Занадто агресивний поріг = постійне фонове навантаження.
KEEP_RECENT=15 — скільки повідомлень залишається "живими" після summary.
Решта (повідомлення 1 до total - 15) стискаються в summary і зберігаються в БД.
Важливо: самі повідомлення з БД не видаляються — тільки позначаються як "вже в summary".
buildHistory: гібрид pinning + sliding window + summary inject
@Transactional(readOnly = true)
public List<Message> buildHistory(ChatSession session) {
List<ChatMessage> allMessages = chatMessageRepository
.findByChatSessionIdOrderByCreatedAtAsc(session.getId());
if (allMessages.isEmpty()) return Collections.emptyList();
List<Message> result = new ArrayList<>();
// ── Шар 1: Episodic summary (якщо є) ──────────────────────────────────
if (session.getSummary() != null && !session.getSummary().isBlank()) {
result.add(new SystemMessage(
"[Резюме попередньої розмови]: " + session.getSummary()));
}
// ── Шар 2: Pinned повідомлення (перші PINNED_COUNT) ───────────────────
int pinnedCount = Math.min(PINNED_COUNT, allMessages.size());
allMessages.subList(0, pinnedCount)
.forEach(m -> result.add(toSpringAiMessage(m)));
// ── Шар 3: Recent sliding window (останні HISTORY_SIZE) ───────────────
int skipTo = Math.max(pinnedCount, allMessages.size() - HISTORY_SIZE);
if (skipTo < allMessages.size()) {
allMessages.subList(skipTo, allMessages.size())
.forEach(m -> result.add(toSpringAiMessage(m)));
}
log.debug("buildHistory: total={} pinned={} window={} result={}",
allMessages.size(), pinnedCount,
allMessages.size() - skipTo, result.size());
return result;
}
Зверніть на skipTo = Math.max(pinnedCount, allMessages.size() - HISTORY_SIZE) —
це захист від дублювання. Якщо pinned і recent перекриваються (при малій кількості повідомлень)
— повідомлення не додається двічі.
summarizeIfNeeded: три транзакції замість однієї
// БЕЗ @Transactional на рівні методу — навмисно!
public void summarizeIfNeeded(ChatSession session) {
if (!needsSummarization(session)) return;
// Транзакція 1: читання
List<ChatMessage> toSummarize = getMessagesForSummarization(session);
if (toSummarize.isEmpty()) return;
long total = chatMessageRepository.countByChatSessionId(session.getId());
int summarizeUpTo = (int) (total - KEEP_RECENT);
// БЕЗ транзакції: LLM виклик (30–60с на Ollama)
String newSummary = generateSummary(toSummarize, session.getSummary());
if (newSummary.isBlank()) return;
// Транзакція 2: запис
saveSummary(session, newSummary, summarizeUpTo);
}
private String generateSummary(List<ChatMessage> messages, String existingSummary) {
String historyText = messages.stream()
.map(m -> m.getRole() + ": " + m.getContent())
.collect(Collectors.joining("\n"));
String previousContext = (existingSummary != null && !existingSummary.isBlank())
? "Попереднє резюме: " + existingSummary + "\n\nНові повідомлення:\n"
: "";
String prompt = """
Стисни цю частину розмови в 3–5 речень.
Збережи: ключові факти, рішення, важливі деталі про користувача.
Відкинь: привітання, повтори, несуттєві деталі.
%s%s
""".formatted(previousContext, historyText);
try {
return ollamaChatModel.call(prompt).trim();
} catch (Exception e) {
log.error("Помилка при генерації summary", e);
return existingSummary != null ? existingSummary : "";
}
}
Що тут можна покращити — чесний розбір
Поточна реалізація добре вирішує задачу для e-commerce чат-бота.
Не існує універсального "кращого" підходу до пам'яті агента —
кожне рішення оптимальне для свого типу проекту.
E-commerce чат-бот, юридична RAG система і мульти-агентний дебатний майданчик
мають різні вимоги до персистентності, точності і вартості.
Те що ідеально для одного — надмірне для іншого.
1. Tool results не логуються окремо.
ChatMessage зберігає тільки user/assistant повідомлення,
але не tool calls і не tool results. Якщо агент викликав AlphaVantage і отримав ціну $213 —
ця інформація є тільки в assistant повідомленні у вигляді тексту, не структурована.
При summarization вона може спотворитись або загубитись.
Рішення: окрема таблиця tool_call_log з парами запит/відповідь,
яка зберігається незалежно від summary.
2. Summary через Ollama 7B — ризик для технічного контенту.
Модель може неточно стиснути числові дані, API відповіді, технічні терміни.
Дослідження Augment Code (2026)
показало: при агресивній summarization кількість кроків для вирішення задачі
може зрости з 4 до 14 — навіть якщо токенів витрачається менше.
Рішення: для критичних фактів — зберігати їх у RAG memory окремо від summary.
3. Відсутній cross-session контекст.
Після закриття сесії — summary залишається в БД, але нова сесія починає з чистого аркуша.
Для e-commerce чат-бота це прийнятно.
Для AskYourDocs де клієнт повертається через тиждень і продовжує роботу з документом —
потрібна RAG memory з user_id scope яка переживає між сесіями.
Що втрачає агент при зміщенні вікна
Sliding window виглядає як просте і елегантне рішення.
Але важливо розуміти точно що відбувається в момент коли повідомлення
виходить за межу вікна — бо агент про це не знає.
Анатомія втрати контексту
// Сесія з 25 повідомленнями, HISTORY_SIZE=20, PINNED_COUNT=3:
//
// Повідомлення 1–3: [PINNED] завжди в контексті ✅
// Повідомлення 4–5: [GAP] НЕ в контексті ❌
// Повідомлення 6–25: [RECENT] в контексті ✅
//
// Агент не знає що GAP існує.
// Він бачить pinned (1–3) і recent (6–25) і вважає що бачить все.
GAP між pinned і recent — найнебезпечніше місце sliding window з pinning.
При PINNED_COUNT=3 і HISTORY_SIZE=20 для сесії з 25 повідомленнями
повідомлення 4 і 5 повністю зникають з контексту.
Якщо саме там було щось критичне — агент діятиме неправильно і не знатиме чому.
Три речі які агент втрачає першими
1. Причини рішень. "Чому ми обрали постачальника X а не Y?" —
відповідь була в раунді 4. Зараз агент бачить рішення але не пам'ятає аргументів.
При повторному питанні — може дати іншу відповідь або галюцинувати причини.
2. Відхилені варіанти. "Ми вже пробували підхід Z — він не спрацював через..."
Якщо це повідомлення за вікном — агент може запропонувати той самий підхід знову.
Без episodic memory він не знає про свої попередні помилки.
3. Контекст користувача. "Я працюю з PostgreSQL 14 на AWS RDS" —
якщо це було в раунді 3 (за pinned) і за вікном — агент дасть загальну відповідь
замість специфічної. Або запитає знову — що дратує користувача.
Коли summary вже не рятує
Episodic summary через LLM — хороше рішення але з межами.
Zylos Research (2026)
виділяє три сценарії де summary деградує:
Context drift — кожен наступний summary трохи спотворює попередній.
Як у грі "зіпсований телефон": після 5–6 раундів summarization
оригінальні факти можуть суттєво змінитись.
Рішення: зберігати критичні факти в RAG memory окремо від summary.
Технічний контент — числа, коди помилок, API відповіді.
7B модель часто округлює числа, змінює коди або спрощує до нерозпізнання.
Рішення: important_facts таблиця де зберігаються точні значення без стиснення.
Довгі сесії (100+ повідомлень) — rolling summary стає занадто великим
або занадто стислим. Обидва варіанти погані.
Рішення: hierarchical summarization (summary of summaries) або
hard limit на розмір summary з примусовим скиданням до RAG.
Наступна стаття серії — MEM-2 розбирає саме ці граничні кейси:
sliding window математика з реальними цифрами вартості,
rolling summarization vs selective compression,
і коли треба повністю відмовитись від window і перейти на pure RAG memory.
→ MEM-2: Контекст не гумовий — sliding window, summarization і compression для агентів
Висновки
Пам'ять агента — не опціональна фіча. Без неї ви будуєте систему
яка деградує з кожним раундом, повторює tool calls, суперечить сама собі,
і галюцинує про власне минуле.
Я пройшов через всі ці помилки на практиці — в e-commerce чат-боті.
Ось що я раджу на основі цього досвіду:
Раджу починати з in-context і pinning.
HISTORY_SIZE=20 + PINNED_COUNT=3
вирішують 70% проблем без жодної зовнішньої інфраструктури.
Pinning — недооцінена деталь яку більшість туторіалів пропускають.
Реалізуйте це першим — і лише потім дивіться чи потрібно щось ще.
Раджу додавати episodic summary тільки коли сесії реально стають довгими.
Не передчасно. Поріг в 30 повідомлень — хороший старт.
Обов'язково розбийте на три транзакції — інакше connection pool
вичерпається при кількох паралельних сесіях.
RAG memory варто підключати коли пам'ять між сесіями стає реальною потребою —
не гіпотетичною. Якщо у вас вже є pgvector — це ще одна таблиця і кілька запитів.
Зберігайте факти точно, не через summary. І одразу фільтруйте що зберігати —
інакше пам'ять перетвориться на сміттєзвалище.
Semantic memory — не чіпайте поки не впретесь.
За три роки роботи з AI-продуктами я ще не зустрів проекту
де вона була б потрібна з першого дня.
Граф знань виправданий тільки для складних enterprise сценаріїв
з мережею взаємопов'язаних сутностей. Для 90% проектів — надмірна складність.
І останнє: порядок inject в контекст важливий.
Summary → RAG facts → pinned → recent → поточний запит.
Трансформерна модель приділяє більше уваги початку і кінцю контексту —
не кидайте важливе в середину.
Читайте також у серії:
→ TU-1: Tool Use vs Function Calling — базова механіка агента.
→ Як LLM вирішує коли викликати tool — механіка прийняття рішень.
→ Grounding і довіра до джерел — що робити після tool call.
→ Tool RAG — масштабування реєстру інструментів.
→ Як керувати контекстом AI агента: sliding window, summarization і compression — наступна стаття серії.
📖 Джерела
