
Der Agent hat eine Anfrage erhalten – verarbeitet – geantwortet. Die nächste Anfrage – und er erinnert sich an nichts von der vorherigen.
Nicht weil etwas kaputt ist. Sondern weil LLMs standardmäßig so funktionieren: jeder Aufruf ist ein leeres Blatt.
Wenn Sie einen Agenten bauen und nicht über Speicher nachdenken – bauen Sie einen Amnesiker mit Internetzugang.
Dieser Artikel ist Teil einer Serie über KI-Agenten auf Spring Boot.
Wenn Sie noch nichts über die Skalierung von Tools gelesen haben –
Tool RAG: Was tun, wenn der Agent zu viele Tools hat.
Darüber, wie ein Agent entscheidet, was er aufrufen soll –
Wie LLM entscheidet, wann ein Tool aufgerufen werden soll.
Inhalt
Der Agent ohne Speicher: ein lebender Bug und warum es kein Bug ist
In Agent Chat gibt es fünf Tools: Wikipedia, Tavily, NewsAPI, Alpha Vantage, ArXiv.
Der Agent führt eine Diskussion, sucht Fakten, formuliert Argumente – alles sieht gut aus.
Aber zu einem bestimmten Zeitpunkt beginnt etwas Seltsames.
Wie das Problem in den Logs aussieht
// Runde 1 – alles normal:
INFO: Round 1 AGENT_A — Tavily search: 'vibe coding productivity statistics'
INFO: Tavily found 3 results, top: "GitHub Copilot boosts productivity by 51%"
INFO: Round 1 AGENT_A reply: "Die Daten zeigen, dass Vibe Coding die Produktivität steigert..."
// Runde 5 – derselbe Agent, dasselbe Thema:
INFO: Round 5 AGENT_A — Tavily search: 'vibe coding productivity statistics'
// ↑ Derselbe Suchbegriff wie in Runde 1. Der Agent erinnert sich nicht, dass er dies bereits gesucht hat.
INFO: Tavily found 3 results — dieselben Ergebnisse
INFO: Round 5 AGENT_A reply: "Wie ich bereits erwähnt habe..."
// ↑ Der Agent DENKT, er habe es erwähnt – aber in Runde 5 sieht er nur die letzten 8 Nachrichten.
// Runde 1 ist bereits aus dem Fenster gefallen. Er hat nichts "erwähnt" – er halluziniert über seinen eigenen Speicher.
Das ist kein Bug im Code. Tavily hat richtig geantwortet. Spring AI hat korrekt funktioniert.
Das Problem liegt in der Architektur: Ein Agent ohne Speicher weiß nicht, was er vor drei Schritten getan hat.
Das Ergebnis sind wiederholte Tool-Aufrufe, widersprüchliche Aussagen und am gefährlichsten –
selbstbewusste Verweise auf "zuvor Gesagtes", das tatsächlich nicht im Kontext vorhanden ist.
65% der gescheiterten Enterprise-KI-Systeme im Jahr 2025 wurden verursacht
nicht durch die Überschreitung des Kontextfensters, sondern durch "Context Drift" – den allmählichen Verlust
der Kohärenz aufgrund fehlenden strukturierten Speichers. Darüber –
Zylos Research (Februar 2026).
Drei Symptome eines Amnesie-Agenten
Bevor wir Lösungen diskutieren – ist es wichtig, das Problem zu erkennen.
Als ich zum ersten Mal auf dieses Problem in Agent Chat stieß, verstand ich nicht sofort, was geschah:
Der Code war richtig, die Tools antworteten, aber der Agent verhielt sich seltsam.
Es stellte sich heraus, dass die Diagnose nicht mit dem Code beginnt, sondern mit den Logs.
Hier sind drei Anzeichen dafür, dass Ihr Agent unter Gedächtnisverlust leidet:
Symptom 1 – Wiederholte Tool-Aufrufe. Der Agent ruft dasselbe Tool
mit derselben Anfrage mehrmals pro Sitzung auf. In den Logs – dieselben Zeilen mit wenigen Minuten Abstand.
Sie zahlen zweimal für die API für dieselbe Antwort.
Symptom 2 – Widersprüchliche Aussagen. In Runde 2 behauptet der Agent X.
In Runde 7 – behauptet er nicht-X und bemerkt den Widerspruch nicht. Runde 2 liegt bereits außerhalb des Fensters.
Für den Agenten existiert sie nicht mehr.
Symptom 3 – Halluzinationen über den eigenen Speicher. Am gefährlichsten.
Der Agent sagt "wie ich bereits erwähnt habe" oder "wir haben bereits besprochen" – aber diese Nachricht
ist bereits außerhalb des Fensters. Der Agent verweist vertrauensvoll auf etwas, an das er sich nicht erinnern kann.
Warum LLMs zustandslos sind – und was das für den Zyklus bedeutet
Ein LLM ist eine Funktion. Sie geben Text ein, Sie erhalten Text als Ausgabe.
Zwischen zwei Aufrufen – nichts. Kein Zustand, kein Gedächtnis, kein "Ich".
Jeder Aufruf ist eine unabhängige Operation.
Ich erinnere mich gut an die ersten Experimente mit frühen Modellen – GPT-3 und den ersten Versionen von ChatGPT.
Das Kontextfenster war klein (4K Token), und nach 10-15 Nachrichten
begann das Modell, den Anfang des Gesprächs zu "vergessen". Man musste den Kontext der Aufgabe wiederholen,
sich daran erinnern, was bereits besprochen wurde, und manchmal die Sitzung neu starten.
Damals schien es eine technische Einschränkung zu sein, die bald behoben würde.
Es stellte sich heraus, dass es keine Einschränkung ist – es ist eine architektonische Eigenschaft.
Die Fenster wurden größer (128K, 1M Token), aber die zustandslose Natur ist nirgendwo verschwunden.
Die Illusion von Gedächtnis durch Kontext
Wenn Sie mit ChatGPT sprechen und es sich "erinnert", was Sie vor fünf Nachrichten gesagt haben –
das ist kein Gedächtnis. Das ist eine Illusion. Jede Anfrage enthält die gesamte vorherige Korrespondenz als Text.
Das Modell "sieht" die Vergangenheit, weil sie ihm in der aktuellen Anfrage übergeben wird, nicht weil es sie "erinnert".
// Was tatsächlich bei jedem LLM-Aufruf passiert:
// Aufruf 1:
chatModel.call("Hallo, wie heißt du?")
// Das Modell sieht: ["user: Hallo, wie heißt du?"]
// Antwortet: "Ich bin ein KI-Agent..."
// Nach dem Aufruf – nichts bleibt im Modell
// Aufruf 2 (nach 5 Minuten):
chatModel.call(List.of(
new UserMessage("Hallo, wie heißt du?"),
new AssistantMessage("Ich bin ein KI-Agent..."),
new UserMessage("Und was kannst du?") // ← neue Anfrage
))
// Das Modell sieht die gesamte Korrespondenz – aber nur, weil wir sie erneut übergeben haben
// Zwischen Aufruf 1 und 2 hat das Modell absolut alles "vergessen"
Dies ist eine grundlegende architektonische Eigenschaft von Transformer-Modellen –
kein Bug und keine Einschränkung eines bestimmten Anbieters.
CoALA (Cognitive Architectures for Language Agents)
formalisiert dies als Unterscheidung zwischen "Arbeitsgedächtnis" (aktueller Kontext) und
"Langzeitgedächtnis" (externer Speicher, der separat implementiert werden muss).
Details darüber, wie das Kontextfenster Verhalten und Kosten beeinflusst –
im Artikel
Kontextfenster von LLM: Warum KI vergisst und was es kostet.
Zustandsloser Zyklus = Agent ohne Speicher bei jedem Schritt
Im Agentenzyklus bedeutet dies: Jede Runde ist ein separater LLM-Aufruf.
Wenn Sie den Verlauf nicht explizit übergeben – erinnert sich der Agent überhaupt nicht an frühere Runden.
Wenn Sie den Verlauf über ein gleitendes Fenster übergeben – "vergisst" der Agent alles, was außerhalb des Fensters liegt.
Und selbst innerhalb des Fensters – er weiß nicht, was er bereits getan hat: welche Tools er aufgerufen hat,
welche Ergebnisse er erhalten hat, welche Entscheidungen er getroffen hat.
// Typischer Agentenzyklus ohne Speicher:
while (!shouldStop) {
// Jede Iteration – ein separater Aufruf mit demselben Verlauf
// Der Agent weiß nicht:
// - welche Tools er in dieser Sitzung bereits aufgerufen hat
// - welche Ergebnisse er bereits erhalten hat
// - was er vor drei Runden entschieden hat
ChatResponse response = chatModel.call(
new Prompt(buildHistory(session)) // ← Verlauf mit begrenztem Fenster
);
// ...
}
Genau zur Lösung dieses Problems gibt es vier Arten von Agentenspeicher.
Jeder löst einen anderen Aspekt des Kontextverlusts – und jeder hat seine eigenen Kosten und Komplexität.
Vier Arten von Speicher: Tabelle und detaillierte Analyse
Die Klassifizierung der Agentenspeichertypen wird von
CoALA (Cognitive Architectures for Language Agents, Sumers et al. 2023) formalisiert –
ein Framework, das auf einer Analogie zur kognitiven Psychologie basiert.
Es unterscheidet zwischen Arbeitsgedächtnis (aktueller Kontext) und drei Arten von Langzeitgedächtnis:
episodisch, semantisch und prozedural. In den Jahren 2025–2026 wurde diese Klassifizierung zum Standard –
sie wird von
Mem0,
IBM,
LangMem und den meisten Produktions-Frameworks verwendet.
Für den praktischen Spring Boot-Entwickler passe ich diese Klassifizierung in vier Typen an
mit Bezug auf spezifische Implementierungen:
| Typ |
Was wird gespeichert |
Persistenz |
Latenz |
Komplexität |
Wann benötigt |
| In-context |
Die letzten N Nachrichten |
Nur in der Sitzung |
0ms |
Minimal |
Immer – der Ausgangspunkt |
| Episodisch (extern) |
Zusammenfassung + Tool-Aufrufe + Entscheidungen |
Zwischen Sitzungen, in der DB |
5–20ms |
Mittel |
Wenn das Fenster nicht mehr rettet |
| RAG-Speicher |
Fakten, Dokumente, Wissen |
Permanent, pgvector |
10–50ms |
Mittel |
Große Wissensbasis oder Sitzungsübergreifender Kontext |
| Semantisch (Graph) |
Entitäten und ihre Beziehungen |
Permanent, Graph-DB |
20–100ms |
Hoch |
Enterprise, komplexe Abhängigkeiten zwischen Fakten |
Typ 1: In-context-Speicher – gleitendes Fenster und Fixierung
Der einfachste Typ: Übergabe der letzten N Nachrichten bei jedem LLM-Aufruf.
Das ist es, was die meisten Entwickler standardmäßig tun – und das ist ein richtiger Start.
In Agent Chat implementiert über HISTORY_SIZE=8.
Im ContextService meines E-Commerce-Projekts – über HISTORY_SIZE=20 mit Fixierung.
Ein wichtiges Detail, das oft übersehen wird: Nicht alle Nachrichten sind gleich wichtig.
Die ersten Nachrichten einer Sitzung enthalten normalerweise den Kontext der Aufgabe – was wir tun, welche Einschränkungen gelten.
Wenn sie aus dem Fenster fallen – "vergisst" der Agent die Aufgabe selbst, erinnert sich aber an die letzten Kleinigkeiten.
// In-context mit Fixierung – Agent Chat-Ansatz:
private static final int HISTORY_SIZE = 20; // gleitendes Fenster
private static final int PINNED_COUNT = 3; // die ersten 3 Nachrichten sind immer im Kontext
public List<Message> buildHistory(ChatSession session) {
List<ChatMessage> all = chatMessageRepository
.findByChatSessionIdOrderByCreatedAtAsc(session.getId());
List<Message> result = new ArrayList<>();
// Schritt 1: fixiert – die ersten 3 Nachrichten (Aufgabenkontext)
int pinned = Math.min(PINNED_COUNT, all.size());
all.subList(0, pinned).forEach(m -> result.add(toSpringAiMessage(m)));
// Schritt 2: aktuell – die letzten HISTORY_SIZE Nachrichten (nicht doppelt fixiert)
int skipTo = Math.max(pinned, all.size() - HISTORY_SIZE);
if (skipTo < all.size()) {
all.subList(skipTo, all.size()).forEach(m -> result.add(toSpringAiMessage(m)));
}
return result;
}
// Ergebnis: Der Kontext enthält immer sowohl "was wir tun" (fixiert) als auch "was gerade passiert ist" (aktuell)
Token-Mathematik für In-Context: Eine Nachricht in Agent Chat
benötigt durchschnittlich 150–300 Token (mit Tool-Ergebnissen – bis zu 1000).
Bei HISTORY_SIZE=8 und deepseek-chat – das sind 1200–8000 Token nur für den Verlauf.
Bei HISTORY_SIZE=20 – 3000–20000 Token. Das Kontextfenster beginnt zu drücken.
Details zu Token-Kosten und Kompressionsstrategien –
im nächsten Artikel der Serie über
Kontextfenster von LLM.
Fallstrick: In-context-Speicher ist per Design verlustbehaftet.
Wenn eine Nachricht aus dem Fenster fällt – verschwindet sie für immer (wenn kein episodischer Speicher vorhanden ist).
Der Agent weiß nicht, was er "vergessen" hat. Er handelt einfach so, als wäre es nie passiert.
Typ 2: Episodischer Speicher – Aktionsprotokoll und Zusammenfassung
Episodischer Speicher speichert, was passiert ist: welche Tool-Aufrufe gemacht wurden,
welche Entscheidungen getroffen wurden, was gefunden wurde. Im Gegensatz zu In-Context – wird er in der DB gespeichert
und ist zwischen Sitzungen und nach dem Verschieben des Fensters verfügbar.
In meinem E-Commerce-Projekt auf Spring Boot habe ich episodischen Speicher
durch LLM-Zusammenfassung implementiert: Wenn die Anzahl der Nachrichten einen Schwellenwert überschreitet
(SUMMARY_THRESHOLD=30) – werden ältere Nachrichten zu einer Zusammenfassung komprimiert
und in der DB gespeichert. Beim nächsten buildHistory() wird die Zusammenfassung
als SystemMessage am Anfang des Kontexts eingefügt.
// Episodischer Speicher durch Zusammenfassung – aus ContextService:
private static final int SUMMARY_THRESHOLD = 30; // Auslöser für Zusammenfassung
private static final int KEEP_RECENT = 15; // wie viele Nachrichten "lebendig" bleiben
public void summarizeIfNeeded(ChatSession session) {
if (!needsSummarization(session)) return;
// WICHTIG: drei separate Transaktionen – keine lange!
// Schritt 1: Daten lesen → Transaktion geöffnet und sofort geschlossen
List<ChatMessage> toSummarize = getMessagesForSummarization(session);
// Schritt 2: Zusammenfassung generieren OHNE offene Transaktion
// Ollama/LLM kann 30–60s dauern – währenddessen ist die DB-Verbindung frei
String newSummary = generateSummary(toSummarize, session.getSummary());
// Schritt 3: Ergebnis speichern → neue kurze Transaktion
saveSummary(session, newSummary, summarizeUpTo);
}
// Bei der nächsten Anfrage – wird die Zusammenfassung in den Kontext eingefügt:
if (session.getSummary() != null && !session.getSummary().isBlank()) {
result.add(new SystemMessage(
"[Zusammenfassung des vorherigen Gesprächs]: " + session.getSummary()));
}
Drei Transaktionen – ein kritisches architektonisches Detail.
Neulinge in Spring machen eine lange Transaktion: Sie lesen Nachrichten,
halten die Verbindung offen, während LLM antwortet (30–60 Sekunden),
dann speichern sie. Ergebnis – der Connection Pool ist bei mehreren
parallelen Sitzungen erschöpft. Richtig: Lesen → Transaktion schließen → auf LLM warten → neue Transaktion zum Schreiben.
Fallstrick episodischer Speicher durch LLM-Zusammenfassung:
Ein 7B-Modell (Ollama qwen3:8b, llama3.1:8b) komprimiert technischen Kontext schlecht.
Tool-Ergebnisse mit Zahlen, Code, API-Antworten – gehen verloren oder werden verzerrt.
Die Studie
Augment Code (April 2026)
zeigte: Aggressive Zusammenfassung kann die Genauigkeit der Antworten verringern und
die Anzahl der Schritte zur Lösung einer Aufgabe erhöhen – auch wenn weniger Token verbraucht werden.
Zusammenfassung funktioniert an klaren Phasengrenzen, nicht als ständige Kompression.
Typ 3: RAG-Speicher – pgvector für Langzeitwissen
RAG-Speicher ist eine externe Vektor-Wissensdatenbank, auf die der Agent über semantische Suche zugreift.
Im Gegensatz zur episodischen Zusammenfassung (verlustbehaftete Kompression) – speichert RAG genaue Fakten
und ermöglicht die genaue Suche nach relevantem Kontext auch nach Wochen.
Der prinzipielle Unterschied zum klassischen RAG für Dokumente: Im Agenten-RAG-Speicher
werden nicht die Dokumente des Kunden gespeichert, sondern das *Wissen des Agenten selbst* –
Ergebnisse früherer Tool-Aufrufe, getroffene Entscheidungen, Fakten über den Benutzer.
-- Tabellenschema für Agenten-RAG-Speicher (pgvector):
CREATE TABLE agent_memory (
id UUID PRIMARY KEY DEFAULT gen_random_uuid(),
session_id VARCHAR(100),
user_id BIGINT, -- für Personalisierung zwischen Sitzungen
memory_type VARCHAR(50), -- 'tool_result', 'decision', 'user_fact'
content TEXT NOT NULL, -- Text für die Suche
metadata JSONB, -- zusätzliche Felder: tool_name, score, etc.
embedding vector(1536), -- pgvector, text-embedding-3-small
created_at TIMESTAMP DEFAULT NOW(),
expires_at TIMESTAMP -- TTL für veraltete Fakten
);
CREATE INDEX agent_memory_embedding_idx
ON agent_memory USING ivfflat (embedding vector_cosine_ops)
WITH (lists = 10);
-- Suche nach relevantem Speicher bei neuer Anfrage:
SELECT content, metadata, 1 - (embedding <=> :queryEmbedding) as score
FROM agent_memory
WHERE user_id = :userId
AND (expires_at IS NULL OR expires_at > NOW())
ORDER BY embedding <=> :queryEmbedding
LIMIT 5;
Wann RAG-Speicher gerechtfertigt ist: Wenn der Agent einen Benutzer
über einen längeren Zeitraum (Wochen, Monate) bedient und sich Fakten über Sitzungen hinweg merken muss.
Bei AskYourDocs stieß ich in der Praxis auf dieses Problem:
Der Kunde lädt Unternehmensdokumente hoch, stellt Fragen, erhält Antworten –
und kehrt am nächsten Tag mit einer Klärung zur gestrigen Anfrage zurück.
Ohne RAG-Speicher weiß der Agent nichts über das gestrige Gespräch.
Er erinnert sich nicht, welche Dokumente bereits analysiert wurden, welche Schlussfolgerungen gezogen wurden,
welche Fragen offen geblieben sind.
Jede neue Sitzung ist ein leeres Blatt, und der Benutzer muss den Kontext erneut erklären.
Deshalb speichert AskYourDocs nicht nur die Dokumente selbst,
sondern auch frühere Kundenanfragen, den Unternehmenskontext und getroffene Entscheidungen –
damit der Agent dort weitermachen kann, wo er aufgehört hat, und nicht von vorne beginnen muss.
Die Studie
Memori (März 2026, arXiv)
zeigte: Strukturierter RAG-Speicher ermöglicht eine Genauigkeit von 81,95 % auf dem LoCoMo-Benchmark
mit nur 1294 Token pro Anfrage – im Vergleich zu 26.000 Token bei einem Ansatz
"der gesamte Kontext im Fenster". Einsparung: 95 % der Token bei höherer Genauigkeit.
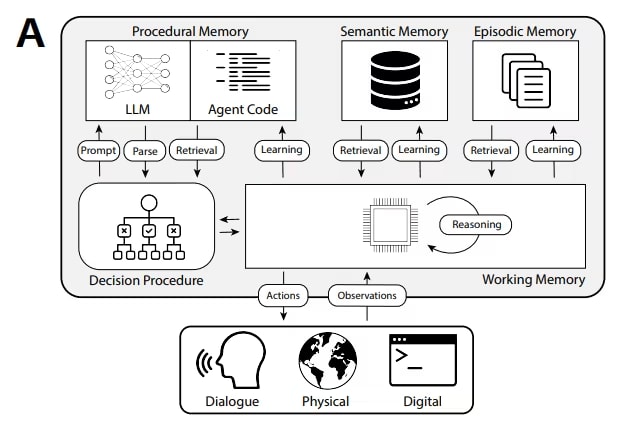
Typ 4: Semantischer Speicher — Wissensgraph des Agenten
Semantischer Speicher speichert nicht Ereignisse (episodisch) und nicht Dokumente (RAG),
sondern Entitäten und die Beziehungen zwischen ihnen in Form eines Graphen.
Beispiel: Der Agent weiß, dass "Kunde X → nutzt → Produkt Y",
"Produkt Y → hat Abhängigkeit → Modul Z", "Modul Z → hat Bug → Issue #123".
Solche Ketten können weder in einem Sliding Window noch in einer Vektordatenbank effizient gespeichert werden.
Im Jahr 2026 wird semantischer Speicher über Graphdatenbanken oder hybride Ansätze realisiert.
Mem0 (Mai 2026)
fügte im Januar 2026 Graph-Speicher hinzu — speichert Entitäten als Knoten
und die Beziehungen zwischen ihnen als gerichtete Kanten.
Atlan (April 2026)
stellt fest: Graph-DBs sind ideal für episodischen + semantischen Speicher zusammen —
schnelles Durchlaufen von Beziehungen, wo eine Vektorsuche unterliegt.
Ehrliche Warnung: Semantischer Speicher ist der schwierigste Typ.
Graph-DBs (Neo4j, Kuzu, Amazon Neptune) fügen separate Infrastruktur hinzu,
eine komplexe Abfragesprache und eine nicht-triviale Aktualisierungslogik bei Faktenänderungen.
Für den ersten Agenten — starten Sie nicht mit semantischem Speicher.
Er ist nur gerechtfertigt, wenn Sie ein komplexes Netzwerk verbundener Entitäten haben,
das über mehrere Schritte durchlaufen werden muss.
Beginnen Sie mit In-Context → Episodisch → RAG, und erst dann — Semantisch.
Hybride Architektur: Wie Speichertypen zusammenarbeiten
Die vier Speichertypen sind keine Alternativen zueinander. In echten Produktionssystemen
werden sie kombiniert. Die Frage ist nicht "welchen Typ wählen", sondern "welche Typen und in welcher Reihenfolge verbinden".
Wie hybrider Speicher im Agentenzyklus aussieht
Hier ist das vollständige Bild für Agent Chat, wenn alle Speicherebenen verbunden sind:
// Benutzeranfrage: "Was ist der Aktienkurs von Tesla und wurde darüber berichtet?"
//
// ─── Schritt 1: Kontext aus allen Speicherebenen sammeln ───────────────────────
//
// Ebene 1 — In-Context (Sliding Window + Pinned):
List<Message> history = contextService.buildHistory(session);
// → 3 Pinned + 17 Aktuelle = 20 Nachrichten
// → Der Agent erinnert sich, was in den letzten ~30 Minuten der Sitzung passiert ist
// Ebene 2 — Episodische Zusammenfassung (wenn die Sitzung lang ist):
if (session.getSummary() != null) {
history.add(0, new SystemMessage(
"[Zusammenfassung des vorherigen Gesprächs]: " + session.getSummary()));
}
// → Komprimierter Speicher dessen, was vor dem Sliding Window war
// → Der Agent "kennt" Entscheidungen, die vor einer Stunde getroffen wurden, auch wenn sie außerhalb des Fensters liegen
// Ebene 3 — RAG-Speicher (relevante Fakten aus der DB):
List<String> relevantFacts = agentMemoryService.findRelevant(
"Tesla stock price news", session.getUserId(), 3);
if (!relevantFacts.isEmpty()) {
history.add(new SystemMessage(
"[Relevanter Kontext aus früheren Sitzungen]:\n" +
String.join("\n", relevantFacts)));
}
// → "Vor drei Tagen fragte der Benutzer nach Tesla, damals lag der Preis bei 213 $"
// → Der Agent kann die Dynamik vergleichen, ohne einen erneuten Tool-Aufruf
// Ebene 4 — Semantisch (nur wenn ein Graph vorhanden ist):
// → "Tesla → CEO → Elon Musk → leitet auch → SpaceX, X"
// → Komplexe Beziehungen zwischen Entitäten
// (nicht implementiert im aktuellen Agent Chat — Enterprise-Level)
// ─── Schritt 2: Tool RAG — nur relevante Tools injizieren ────────────────────
List<ToolCallback> tools = toolRagService.findRelevantTools(userQuery, 3);
// → [AlphaVantageTool: 0.91, NewsApiTool: 0.84]
// ─── Schritt 3: LLM mit vollständigem Kontext aufrufen ───────────────────────────────
ChatResponse response = chatModel.call(new Prompt(history, options));
// ─── Schritt 4: Wichtiges im episodischen/RAG-Speicher speichern ────────────────────
agentMemoryService.save(AgentMemory.builder()
.userId(session.getUserId())
.memoryType("tool_result")
.content("Tesla TSLA Preis: $218.40 (+2.1%), Nachrichten: Gigafactory-Erweiterung")
.metadata(Map.of("tool", "AlphaVantageTool", "timestamp", Instant.now()))
.build());
// → Beim nächsten Mal kennt der Agent den aktuellen Kontext ohne erneute Suche
Die Reihenfolge der Injektion in den System-Prompt ist wichtig
Transformer-Modelle haben eine Positionsabhängigkeit — Token am Anfang und Ende
des Kontexts erhalten mehr Aufmerksamkeit als die in der Mitte.
Daher beeinflusst die Reihenfolge der Speicherebenen die Antwortqualität direkt:
// ✅ Korrekte Reihenfolge (vom wichtigsten zum unwichtigsten):
[1] SystemMessage: Rolle des Agenten und Verhaltensregeln ← immer zuerst
[2] SystemMessage: Episodische Zusammenfassung (falls vorhanden) ← Kontext "was war"
[3] SystemMessage: RAG-Speicher — relevante Fakten ← präzises Wissen
[4] UserMessage/AssistantMessage: Pinned (erste 3) ← Aufgabenkontext
[5] UserMessage/AssistantMessage: Aktuell (Sliding Window) ← aktuelles Gespräch
[6] UserMessage: Aktuelle Anfrage ← immer zuletzt
// ❌ Typischer Fehler — RAG und Zusammenfassung nach dem Verlauf:
[1] SystemMessage: Rolle des Agenten
[2...N] UserMessage/AssistantMessage: der gesamte Verlauf ← RAG geht in der Mitte verloren
[N+1] SystemMessage: RAG-Speicher ← Modell erhält weniger Aufmerksamkeit
Was im episodischen und RAG-Speicher gespeichert werden soll — und was nicht
Der häufigste Fehler: alles speichern. Das verwandelt den Speicher schnell
in eine Mülldeponie, auf der Nützliches im Rauschen untergeht.
Warum ist das kritisch? Wenn der Agent auf den Speicher zugreift — führt er eine semantische Suche durch:
Das Embedding der Anfrage wird mit dem Embedding der gespeicherten Fakten verglichen.
Je mehr Müll im Speicher ist — desto geringer ist die Suchqualität.
Irrelevante Fakten erscheinen in den Top-Ergebnissen und nehmen Platz im Kontext ein.
Der Agent beginnt zu "halluzinieren", indem er sich auf eine Begrüßung von vor fünf Wochen stützt
oder auf Zwischenüberlegungen, die zu keiner Entscheidung geführt haben.
Ich habe dies bei AskYourDocs überprüft: Nach zwei Wochen Betrieb ohne Filterung
ließ die Qualität der Antworten merklich nach — die Suche gab einen relevanten Score von 0.71
für "Hallo! Wie kann ich helfen?" zurück, anstatt des tatsächlichen Aufgabenkontexts.
Hier ist eine praktische Regel, die dieses Problem gelöst hat:
Unbedingt speichern: Ergebnisse von Tool-Aufrufen mit konkreten Zahlen
(Preise, Metriken, Daten), vom Agenten getroffene Entscheidungen ("Anbieter X ausgewählt"),
Fakten über den Benutzer ("bevorzugt kurze Antworten"),
Fehler und Gründe für Misserfolge ("Tool Y gab einen Fehler wegen Rate Limit zurück").
Nicht speichern: Begrüßungen und Smalltalk, Zwischenüberlegungen des Agenten,
die nicht zu einer Entscheidung geführt haben, Duplikate bereits gespeicherter Fakten,
rohe Tool-Ergebnisse von mehr als 500 Zeichen (auf das Wesentliche reduzieren).
Entscheidungsbaum: Mit welchem Typ beginnen
Der Hauptfehler: sofort eine komplexe hybride Architektur aufbauen.
Beginnen Sie mit dem Minimum und fügen Sie nur hinzu, wenn Sie auf eine reale Einschränkung stoßen.
Hier ist ein Entscheidungsbaum mit konkreten Auslösern für den Übergang:
Welchen Agenten bauen Sie?
↓
Einmalige Aufgabe (ohne Sitzung, ohne Verlauf)
→ Speicher ist überhaupt nicht erforderlich. LLM ist zustandslos — und das ist gut so.
Beispiel: classify_document(), generate_summary()
↓
Dialog innerhalb einer Sitzung (Agent Chat, Chatbot)
→ Start: In-Context Sliding Window (HISTORY_SIZE=8–20)
Fügen Sie Pinning für die ersten 3 Nachrichten hinzu (Aufgabenkontext).
Überwachen Sie: Wiederholt der Agent Tool-Aufrufe? Widerspricht er sich selbst?
↓
Die Sitzung wird lang (30+ Nachrichten) oder teuer in Bezug auf Token
→ Hinzufügen: Episodische Zusammenfassung (SUMMARY_THRESHOLD=30, KEEP_RECENT=15)
Ollama für die Zusammenfassung — kostenlos für lokale Entwicklung.
ACHTUNG: Überprüfen Sie die Qualität der Zusammenfassung für den technischen Inhalt Ihrer Domäne.
↓
Speicher zwischen Sitzungen oder für mehrere Benutzer erforderlich
→ Hinzufügen: RAG-Speicher (pgvector + agent_memory Tabelle)
Speichern Sie: Ergebnisse von Tool-Aufrufen, Entscheidungen, Fakten über den Benutzer.
Wenn bereits pgvector für Dokumente vorhanden ist — das Hinzufügen von RAG-Speicher ist einfach.
↓
Komplexes Netzwerk von Entitäten und Beziehungen (10+ Entitätstypen,
mehrstufige Abhängigkeiten, Wissensgraph einer Organisation)
→ Hinzufügen: Semantischer Speicher (Neo4j, Kuzu oder Mem0 Graph)
Nur wenn die Vektorsuche für Multi-Hop-Abfragen ("Wer ist für Komponente X verantwortlich, die von Y abhängt?")
nicht mehr die erforderliche Genauigkeit liefert.
↓
Fügen Sie niemals den nächsten Typ hinzu, bis Sie auf eine reale Einschränkung des vorherigen stoßen.
Tabelle: Symptom → Speichertyp
| Symptom |
Speichertyp, der es löst |
Priorität |
| Agent wiederholt denselben Tool-Aufruf |
In-Context oder Episodisch (je nachdem, ob bereits außerhalb des Fensters) |
Kritisch |
| Agent widerspricht sich nach 10+ Runden |
Episodische Zusammenfassung |
Kritisch |
| Tokenkosten steigen mit jeder Runde |
Episodische Zusammenfassung + Kürzen von Tool-Ergebnissen |
Wichtig |
| Neue Sitzung — Agent erinnert sich nicht an die vorherige |
RAG-Speicher (zwischen Sitzungen) |
Wichtig |
| Agent kennt den Kontext eines bestimmten Benutzers nicht |
RAG-Speicher mit Benutzer-ID-Scope |
Wichtig |
| Multi-Hop-Abfragen: "Wer ist für X verantwortlich, das von Y abhängt?" |
Semantischer Speicher (Graph) |
Enterprise |
Praktische Regel: Für die meisten B2B RAG-Szenarien
reichen In-Context + Episodische Zusammenfassung + RAG-Speicher für Kundendokumente aus.
Semantischer Speicher — nur wenn der Kunde eine komplexe Organisationshierarchie hat,
die über mehrere Schritte durchlaufen werden muss.
Drei Ebenen decken 90% der realen Anwendungsfälle ab.
Implementierung: ContextService aus dem Projekt
Unten finden Sie eine vollständige Aufschlüsselung von ContextService aus meinem E-Commerce-Projekt auf Spring Boot.
Dies ist kein synthetisches Beispiel: Der Dienst läuft in der Produktion und implementiert gleichzeitig
zwei Arten von Speicher – In-Context (Sliding Window + Pinning) und Episodisch (LLM-Zusammenfassung).
Service-Architektur: Was und warum
@Service
@RequiredArgsConstructor
@Slf4j
public class ContextService {
private final ChatMessageRepository chatMessageRepository;
private final ChatSessionRepository chatSessionRepository;
private final OllamaChatModel ollamaChatModel; // lokales Modell für Zusammenfassung
// ── Konstanten ─────────────────────────────────────────────────────────
private static final int HISTORY_SIZE = 20; // Sliding Window
private static final int PINNED_COUNT = 3; // Die ersten N Nachrichten immer im Kontext
private static final int SUMMARY_THRESHOLD = 30; // Trigger für Zusammenfassung
private static final int KEEP_RECENT = 15; // Aktive Nachrichten nach Zusammenfassung
}
Vier Konstanten bestimmen das gesamte Speicherverhalten. Lassen Sie uns jede einzeln betrachten:
HISTORY_SIZE=20 – wie viele der letzten Nachrichten in den Kontext gelangen.
Bei einer durchschnittlichen Nachricht von 200 Tokens sind das 4000 Tokens nur für den Verlauf.
Für deepseek-chat (0,27 $/M Eingabe) – ca. 0,001 $ pro Anfrage, akzeptabel.
Für claude-sonnet (ca. 3 $/M Eingabe) – bereits 0,012 $ pro Anfrage, und das steigt mit jeder Runde.
PINNED_COUNT=3 – die ersten drei Nachrichten sind *immer* im Kontext,
unabhängig von der Größe des Verlaufs. Sie enthalten den Kontext der Aufgabe: Was wir tun, welche Rolle der Agent hat,
welche Einschränkungen. Ohne Pinning – nach 20+ Runden "vergisst" der Agent die Aufgabe selbst.
SUMMARY_THRESHOLD=30 – bei 30+ Nachrichten wird die Zusammenfassung gestartet.
Warum 30 und nicht 20? Damit die Zusammenfassung nicht zu oft gestartet wird.
Jede Zusammenfassung ist ein separater LLM-Aufruf (15–60 Sekunden auf Ollama).
Ein zu aggressiver Schwellenwert = ständige Hintergrundlast.
KEEP_RECENT=15 – wie viele Nachrichten nach der Zusammenfassung "aktiv" bleiben.
Der Rest (Nachrichten 1 bis total - 15) wird zu einer Zusammenfassung komprimiert und in der Datenbank gespeichert.
Wichtig: Die Nachrichten selbst werden nicht aus der Datenbank gelöscht – sie werden nur als "bereits in der Zusammenfassung" markiert.
buildHistory: Hybrid aus Pinning + Sliding Window + Summary Inject
@Transactional(readOnly = true)
public List<Message> buildHistory(ChatSession session) {
List<ChatMessage> allMessages = chatMessageRepository
.findByChatSessionIdOrderByCreatedAtAsc(session.getId());
if (allMessages.isEmpty()) return Collections.emptyList();
List<Message> result = new ArrayList<>();
// ── Ebene 1: Episodische Zusammenfassung (falls vorhanden) ──────────────────────────────────
if (session.getSummary() != null && !session.getSummary().isBlank()) {
result.add(new SystemMessage(
"[Zusammenfassung des vorherigen Gesprächs]: " + session.getSummary()));
}
// ── Ebene 2: Angepinnte Nachrichten (die ersten PINNED_COUNT) ───────────────────
int pinnedCount = Math.min(PINNED_COUNT, allMessages.size());
allMessages.subList(0, pinnedCount)
.forEach(m -> result.add(toSpringAiMessage(m)));
// ── Ebene 3: Aktuelles Sliding Window (die letzten HISTORY_SIZE) ───────────────
int skipTo = Math.max(pinnedCount, allMessages.size() - HISTORY_SIZE);
if (skipTo < allMessages.size()) {
allMessages.subList(skipTo, allMessages.size())
.forEach(m -> result.add(toSpringAiMessage(m)));
}
log.debug("buildHistory: total={} pinned={} window={} result={}",
allMessages.size(), pinnedCount,
allMessages.size() - skipTo, result.size());
return result;
}
Beachten Sie skipTo = Math.max(pinnedCount, allMessages.size() - HISTORY_SIZE) –
dies ist ein Schutz vor Duplizierung. Wenn sich angepinnte und aktuelle Nachrichten überschneiden (bei wenigen Nachrichten)
– wird die Nachricht nicht doppelt hinzugefügt.
summarizeIfNeeded: Drei Transaktionen statt einer
// KEIN @Transactional auf Methodenebene – absichtlich!
public void summarizeIfNeeded(ChatSession session) {
if (!needsSummarization(session)) return;
// Transaktion 1: Lesen
List<ChatMessage> toSummarize = getMessagesForSummarization(session);
if (toSummarize.isEmpty()) return;
long total = chatMessageRepository.countByChatSessionId(session.getId());
int summarizeUpTo = (int) (total - KEEP_RECENT);
// KEINE Transaktion: LLM-Aufruf (30–60s auf Ollama)
String newSummary = generateSummary(toSummarize, session.getSummary());
if (newSummary.isBlank()) return;
// Transaktion 2: Schreiben
saveSummary(session, newSummary, summarizeUpTo);
}
private String generateSummary(List<ChatMessage> messages, String existingSummary) {
String historyText = messages.stream()
.map(m -> m.getRole() + ": " + m.getContent())
.collect(Collectors.joining("\n"));
String previousContext = (existingSummary != null && !existingSummary.isBlank())
? "Vorherige Zusammenfassung: " + existingSummary + "\n\nNeue Nachrichten:\n"
: "";
String prompt = """
Fasse diesen Teil des Gesprächs in 3–5 Sätzen zusammen.
Behalte bei: wichtige Fakten, Entscheidungen, wichtige Details über den Benutzer.
Verwerfe: Begrüßungen, Wiederholungen, unwichtige Details.
%s%s
""".formatted(previousContext, historyText);
try {
return ollamaChatModel.call(prompt).trim();
} catch (Exception e) {
log.error("Fehler bei der Generierung der Zusammenfassung", e);
return existingSummary != null ? existingSummary : "";
}
}
Was hier verbessert werden kann – eine ehrliche Analyse
Die aktuelle Implementierung löst die Aufgabe für einen E-Commerce-Chatbot gut.
Es gibt keinen universellen "besten" Ansatz für das Gedächtnis eines Agenten –
jede Lösung ist für ihren Projekttyp optimal.
Ein E-Commerce-Chatbot, ein juristisches RAG-System und eine Multi-Agenten-Debattenplattform
haben unterschiedliche Anforderungen an Persistenz, Genauigkeit und Kosten.
Was für das eine perfekt ist, ist für das andere übertrieben.
1. Tool-Ergebnisse werden nicht separat protokolliert.
ChatMessage speichert nur Benutzer-/Assistentennachrichten,
aber keine Tool-Aufrufe oder Tool-Ergebnisse. Wenn der Agent AlphaVantage aufgerufen und einen Preis von 213 $ erhalten hat –
diese Information ist nur in der Assistentennachricht als Text vorhanden, nicht strukturiert.
Bei der Zusammenfassung kann sie verzerrt oder verloren gehen.
Lösung: eine separate Tabelle tool_call_log mit Anfrage/Antwort-Paaren,
die unabhängig von der Zusammenfassung gespeichert wird.
2. Zusammenfassung über Ollama 7B – Risiko für technische Inhalte.
Das Modell kann numerische Daten, API-Antworten, technische Begriffe ungenau zusammenfassen.
Die Studie von Augment Code (2026)
zeigte: Bei aggressiver Zusammenfassung kann die Anzahl der Schritte zur Lösung einer Aufgabe
von 4 auf 14 steigen – auch wenn weniger Tokens verbraucht werden.
Lösung: Für kritische Fakten – speichern Sie sie im RAG-Gedächtnis separat von der Zusammenfassung.
3. Fehlender Cross-Session-Kontext.
Nach dem Schließen der Sitzung – die Zusammenfassung bleibt in der Datenbank, aber eine neue Sitzung beginnt mit einem leeren Blatt.
Für einen E-Commerce-Chatbot ist das akzeptabel.
Für AskYourDocs, wo der Kunde nach einer Woche zurückkehrt und die Arbeit am Dokument fortsetzt –
benötigt man ein RAG-Gedächtnis mit user_id-Scope, das Sitzungen überdauert.
Was der Agent beim Verschieben des Fensters verliert
Sliding Window erscheint als einfache und elegante Lösung.
Aber es ist wichtig zu verstehen, was genau passiert, wenn eine Nachricht
die Fenstergrenze überschreitet – denn der Agent weiß es nicht.
Anatomie des Kontextverlusts
// Sitzung mit 25 Nachrichten, HISTORY_SIZE=20, PINNED_COUNT=3:
//
// Nachrichten 1–3: [ANGEPINNT] immer im Kontext ✅
// Nachrichten 4–5: [LÜCKE] NICHT im Kontext ❌
// Nachrichten 6–25: [AKTUELL] im Kontext ✅
//
// Der Agent weiß nicht, dass die LÜCKE existiert.
// Er sieht angepinnte (1–3) und aktuelle (6–25) und glaubt, alles zu sehen.
Die LÜCKE zwischen angepinnten und aktuellen Nachrichten – die gefährlichste Stelle des Sliding Window mit Pinning.
Bei PINNED_COUNT=3 und HISTORY_SIZE=20 für eine Sitzung mit 25 Nachrichten
verschwinden die Nachrichten 4 und 5 vollständig aus dem Kontext.
Wenn dort etwas Entscheidendes war – wird der Agent falsch handeln und nicht wissen warum.
Drei Dinge, die der Agent zuerst verliert
1. Gründe für Entscheidungen. "Warum haben wir Lieferant X statt Y gewählt?" –
die Antwort war in Runde 4. Jetzt sieht der Agent die Entscheidung, erinnert sich aber nicht an die Argumente.
Bei wiederholter Frage – kann er eine andere Antwort geben oder Gründe halluzinieren.
2. Abgelehnte Optionen. "Wir haben Ansatz Z bereits ausprobiert – er hat nicht funktioniert, weil..."
Wenn diese Nachricht außerhalb des Fensters liegt – kann der Agent denselben Ansatz erneut vorschlagen.
Ohne episodisches Gedächtnis weiß er nichts von seinen früheren Fehlern.
3. Benutzerkontext. "Ich arbeite mit PostgreSQL 14 auf AWS RDS" –
wenn dies in Runde 3 (hinter angepinnt) und außerhalb des Fensters war – gibt der Agent eine allgemeine Antwort
statt einer spezifischen. Oder er fragt erneut – was den Benutzer frustriert.
Wann eine Zusammenfassung nicht mehr hilft
Episodische Zusammenfassung über LLM – eine gute Lösung, aber mit Grenzen.
Zylos Research (2026)
identifiziert drei Szenarien, in denen die Zusammenfassung abbaut:
Context Drift – jede nachfolgende Zusammenfassung verzerrt die vorherige leicht.
Wie im Spiel "Stille Post": Nach 5–6 Zusammenfassungsrunden
können sich die ursprünglichen Fakten erheblich ändern.
Lösung: Speichern Sie kritische Fakten im RAG-Gedächtnis separat von der Zusammenfassung.
Technische Inhalte – Zahlen, Fehlercodes, API-Antworten.
Ein 7B-Modell rundet Zahlen oft, ändert Codes oder vereinfacht sie bis zur Unkenntlichkeit.
Lösung: eine Tabelle important_facts, in der genaue Werte ohne Komprimierung gespeichert werden.
Lange Sitzungen (100+ Nachrichten) – die rollierende Zusammenfassung wird zu groß
oder zu komprimiert. Beide Varianten sind schlecht.
Lösung: hierarchische Zusammenfassung (Zusammenfassung von Zusammenfassungen) oder
eine harte Begrenzung der Zusammenfassungsgröße mit erzwungenem Zurückfallen auf RAG.
Der nächste Artikel der Serie – MEM-2 befasst sich genau mit diesen Grenzfall-Szenarien:
Sliding Window-Mathematik mit realen Kostenberechnungen,
rollierende Zusammenfassung vs. selektive Komprimierung,
und wann man das Fenster vollständig aufgeben und auf reines RAG-Gedächtnis umsteigen muss.
→ MEM-2: Kontext ist nicht dehnbar – Sliding Window, Zusammenfassung und Komprimierung für Agenten
Schlussfolgerungen
Das Gedächtnis eines Agenten – keine optionale Funktion. Ohne sie bauen Sie ein System,
das mit jeder Runde abbaut, Tool-Aufrufe wiederholt, sich selbst widerspricht und
über seine eigene Vergangenheit halluziniert.
Ich habe all diese Fehler in der Praxis durchgemacht – in einem E-Commerce-Chatbot.
Hier sind meine Empfehlungen basierend auf dieser Erfahrung:
Ich empfehle, mit In-Context und Pinning zu beginnen.
HISTORY_SIZE=20 + PINNED_COUNT=3
lösen 70 % der Probleme ohne jegliche externe Infrastruktur.
Pinning – ein unterschätztes Detail, das die meisten Tutorials auslassen.
Implementieren Sie dies zuerst – und sehen Sie dann, ob etwas anderes benötigt wird.
Ich empfehle, episodische Zusammenfassungen nur hinzuzufügen, wenn Sitzungen wirklich lang werden.
Nicht zu früh. Ein Schwellenwert von 30 Nachrichten – ein guter Start.
Teilen Sie es unbedingt in drei Transaktionen auf – sonst wird der Connection Pool
bei mehreren parallelen Sitzungen erschöpft sein.
RAG-Gedächtnis sollte angeschlossen werden, wenn das Gedächtnis zwischen Sitzungen zu einer echten Notwendigkeit wird –
nicht hypothetisch. Wenn Sie bereits pgvector haben – ist es eine weitere Tabelle und einige Abfragen.
Speichern Sie Fakten genau, nicht über Zusammenfassungen. Und filtern Sie sofort, was gespeichert werden soll –
sonst wird das Gedächtnis zu einer Müllhalde.
Semantisches Gedächtnis – fassen Sie es nicht an, bis Sie nicht mehr weiterkommen.
In drei Jahren Arbeit mit KI-Produkten habe ich noch kein Projekt getroffen,
bei dem es vom ersten Tag an benötigt wurde.
Ein Wissensgraph ist nur für komplexe Unternehmensszenarien gerechtfertigt
mit einem Netzwerk von miteinander verbundenen Entitäten. Für 90 % der Projekte – übermäßige Komplexität.
Und zuletzt: Die Reihenfolge des Injectens in den Kontext ist wichtig.
Zusammenfassung → RAG-Fakten → Angepinnt → Aktuell → Aktuelle Anfrage.
Ein Transformer-Modell schenkt dem Anfang und Ende des Kontexts mehr Aufmerksamkeit –
werfen Sie Wichtiges nicht in die Mitte.
Lesen Sie auch in der Serie:
→ TU-1: Tool Use vs Function Calling – grundlegende Mechanik des Agenten.
→ Wie LLM entscheidet, wann ein Tool aufgerufen werden soll – Entscheidungsmechanik.
→ Grounding und Vertrauen in Quellen – was nach einem Tool-Aufruf zu tun ist.
→ Tool RAG – Skalierung des Werkzeugregisters.
→ Wie man den Kontext eines KI-Agenten steuert: Sliding Window, Zusammenfassung und Komprimierung – nächster Artikel der Serie.
📖 Quellen
