TL;DR — Cambios clave en 30 segundos
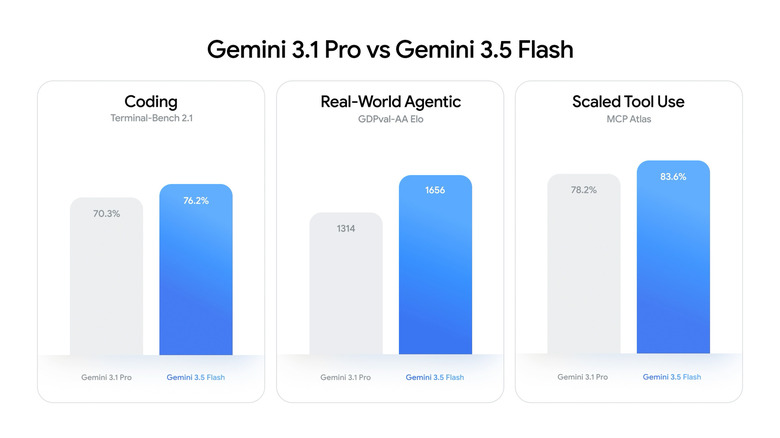
Google lanzó Gemini 3.5 Flash como el primer modelo de la línea 3.5, inmediatamente en versión estable GA. Supera a Gemini 3.1 Pro en la mayoría de los benchmarks agentic y de codificación (MCP Atlas 83.6%, Terminal-Bench 76.2%, GDPval-AA +342 Elo), es 4 veces más rápido en la salida y admite 1 millón de contexto.
Nuevos precios: $1.50 / $9 por millón de tokens (entrada/salida) + $0.15 por entrada en caché (descuento del 90%). Es más caro que el Flash anterior, pero beneficioso para los agentes gracias al almacenamiento en caché.
Cambios críticos que rompen la compatibilidad para desarrolladores:
thinking_budget → thinking_level (nuevo valor predeterminado: medium, en lugar de high)id obligatorio en FunctionResponse- La preservación de pensamientos está habilitada por defecto
El modelo está perfectamente adaptado para flujos de trabajo de agentes, uso de herramientas y codificación compleja.
Desventajas: regresiones en algunos benchmarks de razonamiento (Humanity’s Last Exam, ARC-AGI-2) y un costo real más alto en bucles pesados. Se espera Gemini 3.5 Pro en junio de 2026.
Contenido
- ¿Qué es Gemini 3.5 Flash y por qué este lanzamiento es inusual?
- Arquitectura: niveles de pensamiento, contexto de 1 millón, corte de conocimiento en enero de 2026
- Uso de herramientas y llamadas a funciones: @tool como primera persona en el agente
- Benchmarks: dónde gana Flash, y dos regresiones que Google no destacó
- Velocidad: 4 veces más rápido, y por qué para los agentes la cifra real es diferente
- Economía real: no $9, sino $0.15, cómo calcular el costo de un bucle de agente
- Dónde se lanzó: Gemini app, Antigravity 2.0, AI Studio, Vertex, Search
- Comparación con Claude Opus 4.7 y GPT-5.5: por tareas, no por el bombo
- Dónde Flash pierde y cuándo quedarse con Pro
- El modelo Lazy ya no es perezoso: qué ha cambiado en la práctica
- Gemini 3.5 Pro: qué se sabe sobre el próximo modelo (junio de 2026)
- Conclusión: Investigador vs. Creador: cómo elegir un modelo en 2026
1. ¿Qué es Gemini 3.5 Flash y por qué este lanzamiento es inusual?
El 19 de mayo de 2026, en la inauguración de Google I/O 2026, Google DeepMind lanzó Gemini 3.5 Flash al público general. Es el primer modelo de la nueva línea Gemini 3.5, y rompió inmediatamente la lógica habitual de los lanzamientos de modelos.
El esquema tradicional era el siguiente: primero se lanzaba Pro, el modelo más potente y caro, y Flash aparecía más tarde como una opción económica. Según felloai.com, Google ha invertido el esquema esta vez: Gemini 3.5 Flash, en benchmarks oficiales, supera a Gemini 3.1 Pro en tareas de codificación y flujos de trabajo de agentes, y además cuesta un 40% menos y es 4 veces más rápido.
Gemini 3.5 Pro no se lanzó en I/O. Según informes de Let's Data Science y Business Insider, el anuncio del retraso de Pro provocó exclamaciones de decepción en la sala. Pichai dijo personalmente a la audiencia: "Sé que no puedes esperar a tenerlo en tus manos. Dános hasta el próximo mes para entregártelo". Pro se está utilizando actualmente solo internamente en Google, se espera para junio de 2026.
Por lo tanto, Flash no es una versión simplificada, sino el único modelo actualizado de la línea 3.5 disponible hoy. Es el que impulsa Antigravity 2.0, Gemini Spark y el Modo IA en Google Search.
2. Arquitectura: niveles de pensamiento, contexto de 1 millón, corte de conocimiento en enero de 2026
Especificaciones básicas
Según la tarjeta de modelo oficial de Google DeepMind:
- ID del modelo API: gemini-3.5-flash (sin sufijo preview — versión estable GA)
- Snapshot: gemini-3.5-flash-05-2026
- Ventana de contexto de entrada: 1.048.576 tokens (1M)
- Salida máxima: 65.536 tokens
- Entrada multimodal: texto, imágenes, audio, video, PDF
- Corte de conocimiento: enero de 2026
Corte de conocimiento: +12 meses — por qué es importante
El Gemini 3 Flash anterior tenía un corte de conocimiento en enero de 2025. Según llm-stats.com, Gemini 3.5 Flash es de enero de 2026. Una diferencia de un año. Para un desarrollador, esto es una ventaja práctica concreta: frameworks, bibliotecas, API — el modelo conoce sus versiones actuales sin muletas RAG.
Niveles de pensamiento en lugar de thinking_budget
Este es un cambio importante con consecuencias directas en tu código. Según la documentación oficial de la API de Gemini: el parámetro thinking_budget (un número entero) ha sido reemplazado por thinking_level (una cadena enum):
- minimal — razonamiento mínimo, máxima velocidad
- low — razonamiento ligero
- medium — equilibrio (nuevo valor predeterminado, en lugar del anterior high)
- high — razonamiento profundo para tareas complejas
Detalle crítico para la migración de byteiota.com: si simplemente cambias la cadena del modelo de gemini-3-flash-preview a gemini-3.5-flash sin otros cambios, el nivel de pensamiento predeterminado cambiará de high a medium. Esto reducirá silenciosamente la calidad de las respuestas en tu aplicación. Siempre verifica el comportamiento después de la migración.
Además: la preservación de pensamientos está habilitada por defecto. El modelo conserva el contexto de razonamiento entre turnos — mejora la calidad de las tareas de múltiples turnos, pero aumenta el uso de tokens en conversaciones largas.
Lista de verificación completa de migración del Guía oficial para desarrolladores de Google en DEV Community:
- Actualiza la cadena del modelo: gemini-3-flash-preview → gemini-3.5-flash
- Reemplaza thinking_budget por thinking_level
- Elimina temperature, top_p, top_k de la configuración
- Agrega id y el name correspondiente a todas las partes de FunctionResponse
- Actualiza el SDK a google-genai v2.0.0 o posterior
- Verifica el uso de tokens — la preservación de pensamientos ahora está activa por defecto
El uso de herramientas no es solo otra característica. Según Coding Beauty: "El uso de herramientas se está convirtiendo en el verdadero sistema operativo para la IA". Gemini 3.5 Flash se construyó en torno a esto desde el primer día.
MCP Atlas 83.6% — el indicador más alto entre todos los modelos
Según aimadetools.com: Gemini 3.5 Flash obtuvo un 83.6% en MCP Atlas, el indicador más alto entre todos los modelos probados. MCP Atlas es un benchmark específicamente sobre la calidad de la orquestación de herramientas externas y flujos de trabajo complejos de llamada de herramientas. Para un desarrollador que crea un agente con docenas de llamadas a @tool, esta es la cifra más práctica de todo el lanzamiento.
Lo que se admite de fábrica
Según la documentación oficial de la API de Gemini, en una sola solicitud se pueden combinar simultáneamente:
- Búsqueda de Google — anclaje en datos actuales de la web
- Google Maps — consultas de geolocalización
- Contexto de URL — lectura de páginas externas
- Ejecución de código — ejecución de código en sandbox
- Funciones personalizadas — sus propios @tool
Todo esto en paralelo, en una sola llamada a la API. Anteriormente, tenía que construir una capa de orquestación manualmente; ahora el modelo decide por sí mismo qué herramientas ejecutar y en qué orden.
Cambio importante en FunctionResponse — qué se romperá en el código antiguo
La documentación oficial corrige un cambio crítico: ahora en cada FunctionResponse es necesario pasar tanto el id como el name que corresponden a la functionCall anterior. Si su código antiguo no pasa el id, se romperá sin un mensaje de error obvio.
// Correcto — con id y name
{
functionResponse: {
name: toolCall.name,
id: toolCall.id, // NUEVO — obligatorio
response: { result: result }
}
}
Otro matiz: si agrega instrucciones junto con FunctionResponse, no las haga como Partes separadas. Agréguelas al texto de la respuesta de la función a través de dos saltos de línea. De lo contrario, habrá "fuga de pensamiento" y una menor calidad de la salida.
Uso paralelo de herramientas: firmas de pensamiento
Según la documentación oficial de la Guía del desarrollador de Gemini 3, al llamar a funciones en paralelo: solo la primera functionCall en la lista contiene thoughtSignature. Debe devolver las Partes en el mismo orden exacto en que las recibió. Violar el orden es un error de la API.
Casos de uso reales
Según MarkTechPost:
- Salesforce Agentforce — los subagentes conservan el contexto entre llamadas a herramientas complejas de varios pasos
- Shopify — subagentes paralelos para analizar datos y predecir el crecimiento de los comerciantes
- Ramp — OCR de documentos financieros con cadenas de herramientas complejas
Lo que no se admite
La documentación oficial dice directamente: "El uso de la computadora no es compatible en este momento". Para cargas de trabajo con control directo del sistema operativo, quédese con Gemini 3 Flash Preview o considere GPT-5.5.
4. Benchmarks: dónde gana Flash — y dos regresiones que Google no destacó
Todos los benchmarks son de la publicación oficial de Google DeepMind del 19 de mayo de 2026, a menos que se indique lo contrario. Handy AI Substack compiló una tabla completa que incluye las regresiones.
| Benchmark |
Gemini 3.5 Flash |
Gemini 3.1 Pro |
Quién es mejor |
| Terminal-Bench 2.1 (agentes de codificación CLI) |
76.2% |
70.3% |
Flash |
| MCP Atlas (uso de herramientas de agente) |
83.6% |
78.2% |
Flash |
| Finance Agent v2 |
57.9% |
43.0% |
Flash (+14.9 pp) |
| CharXiv Reasoning |
84.2% |
inferior |
Flash |
| GDPval-AA (agente real) |
1656 Elo |
1314 Elo |
Flash (+342 Elo) |
| MRCR v2 a 1M (contexto largo) |
77.3% |
84.9% |
Pro (regresión) |
| Humanity's Last Exam |
40.2% |
44.4% |
Pro (regresión) |
| ARC-AGI-2 |
72.1% |
77.1% |
Pro (regresión) |
Dos regresiones de las que Google no habla en los titulares
llm-stats.com lo formula honestamente: Flash es inferior a 3.1 Pro en Humanity's Last Exam (40.2% vs 44.4%) y ARC-AGI-2 (72.1% vs 77.1%). Estos no son errores, es una elección arquitectónica: Flash está optimizado para el trabajo real, no para el razonamiento abstracto. Cita de llm-stats.com: "Si su carga de trabajo es un agente que necesita hacer algo en lugar de un investigador que hace una pregunta difícil, 3.5 Flash es la mejor opción hoy".
El independiente BenchLM.ai sitúa a Flash en el puesto #11 de 116 modelos. La categoría más fuerte es Agentic (#3 de todos). La más débil es Instruction Following (#37).
5. Velocidad: 4 veces más rápido — y por qué para los agentes la cifra real es diferente
Google afirma: Gemini 3.5 Flash genera tokens 4 veces más rápido que otros modelos de vanguardia. WaveSpeed y Artificial Analysis confirman: más de 289 tokens de salida por segundo. Claude Opus 4.7 — 67 tok/s, GPT-5.5 — 71 tok/s.
Pero hay un matiz importante de Build Fast with AI: "La generación de tokens más rápida reduce la parte del tiempo de un agente que se dedica a generar texto, y para la codificación de agentes, esa parte de texto suele ser grande. Por lo tanto, los agentes se vuelven más rápidos, pero no 4 veces más rápidos". Parte del tiempo de un agente se dedica a llamar a herramientas externas, esperar la API, operaciones de archivos, y esta parte el modelo no la acelera.
Dentro de Antigravity 2.0, Google afirma una aceleración de 12 veces gracias a un arnés de agente optimizado. A escala: VentureBeat informa que los desarrolladores de Google en Antigravity procesaron 0.5 billones de tokens por día en marzo de 2026, y para mayo, más de 3 billones. Un aumento de 6 veces en 10 semanas.
6. Economía real: no $9, sino $0.15 — cómo calcular el costo de un bucle de agente
La mayoría de las revisiones se detienen en $9.00 por millón de tokens de salida. Pero para los flujos de trabajo de agentes, esta no es la imagen completa.
Tabla de precios básica
Según llm-stats.com y WaveSpeed:
| Modelo |
Entrada ($/1M) |
Salida ($/1M) |
Entrada en caché ($/1M) |
| Gemini 3 Flash (anterior) |
$0.50 |
$3.00 |
— |
| Gemini 3.5 Flash (nuevo) |
$1.50 |
$9.00 |
$0.15 |
| Gemini 3.1 Pro |
$2.50 |
$15.00 |
— |
Por qué $0.15 de entrada en caché es la cifra clave para los agentes
aimadetools.com explica: en un bucle de agente típico, el prompt del sistema y las definiciones de herramientas se repiten en cada solicitud. Sin caché, estos tokens se cuentan a $1.50/M en cada llamada. Con caché — $0.15/M, un descuento del 90%.
Para un arnés de agente con 50 subagentes paralelos y un prompt del sistema de 5000 tokens, la diferencia entre la entrada en caché y la no en caché se convierte en la principal palanca de costos, no el precio base por token. llm-stats.com: "El descuento del 90% en caché hace que los contextos largos de agente sean la palanca de costos dominante, no la entrada por solicitud".
Donde hay insatisfacción real
3.5 Flash es 3 veces más caro que el Gemini 3 Flash anterior. Latent Space registra: la comunidad en r/LocalLLaMA reacciona negativamente al aumento del precio por token. Build Fast with AI: "Con 3 veces el precio anterior de Flash, Google te pide que valides que el salto de capacidad vale la pena".
7. Dónde se lanzó: Gemini app, Antigravity 2.0, AI Studio, Vertex, Search
WaveSpeed confirma: el 19 de mayo de 2026, Gemini 3.5 Flash estuvo disponible simultáneamente en todas las superficies principales:
- Aplicación Gemini (web, Android, iOS) — modelo predeterminado, incluido el nivel gratuito
- Modo IA en Google Search — lanzamiento global
- Google Antigravity 2.0 — con arnés de agente optimizado (12 veces más rápido en el entorno de la plataforma)
- Google AI Studio — modo de creación y API estándar
- API de Gemini — ID estable: gemini-3.5-flash; snapshot: gemini-3.5-flash-05-2026
- Vertex AI — API empresarial con SLAs escalonados
- Android Studio
- Plataforma de Agentes Empresariales Gemini
Acceso gratuito: según felloai.com, Flash es gratuito en la aplicación Gemini (límites diarios) y en AI Studio a través de una clave API.
Confusión de marca: Latent Space registra un problema de la comunidad: los desarrolladores después de I/O no entienden si usar Gemini CLI o Antigravity CLI. La posición oficial: Gemini CLI se cerrará el 18 de junio de 2026, Antigravity CLI es su reemplazo. Pero la documentación aún no se ha actualizado en todas partes.
8. Comparación con Claude Opus 4.7 y GPT-5.5 — por tareas, no por hype
La comparación se basa en benchmarks oficiales y análisis de felloai.com, aimadetools.com y Handy AI.
| Tarea |
Gemini 3.5 Flash |
Claude Opus 4.7 |
GPT-5.5 |
| Uso de herramientas de agente (MCP Atlas) |
83.6% |
inferior |
inferior |
| Terminal / Codificación CLI |
76.2% |
69.4% |
82.7% |
| Finance Agent v2 |
57.9% |
— |
inferior |
| SWE-Bench Verificado |
inferior |
líder |
superior a Flash |
| Tasa de alucinación |
promedio |
la más baja |
promedio |
| ARC-AGI-2 |
72.1% |
— |
84.6% |
| Uso de la computadora |
no admitido |
sí |
75%+ OSWorld |
| Velocidad de salida |
289 tok/s |
67 tok/s |
71 tok/s |
| Precio de salida ($/1M) |
$9.00 (el más barato) |
más caro |
más caro |
felloai.com: "La ventaja de Gemini es la velocidad y el precio con una calidad casi insignia". Flash no reclama la victoria general — cambia la ecuación de valor: esta calidad a este precio y a esta velocidad antes no existía en el nivel Flash.
9. Dónde Flash juega y cuándo quedarse con Pro
Dónde Gemini 3.5 Flash se queda atrás
- Codificación de terminal: GPT-5.5 está por delante: 82,7 % frente al 76,2 %.
- Contexto largo con extracción precisa: MRCR v2: Flash 77,3 % frente a Pro 84,9 %.
- Codificación compleja (SWE-Bench): Claude Opus 4.7 y GPT-5.5 están por delante.
- Razonamiento abstracto (ARC-AGI-2): GPT-5.5 lidera con un 84,6 % frente a un 72,1 %.
- Tasa de alucinaciones: Claude Opus 4.7 tiene la más baja. Para tareas críticas, es sustancial.
- Uso de computadora: no compatible con Flash. GPT-5.5 lidera.
- Seguimiento de instrucciones: BenchLM sitúa a Flash en el puesto 37. Para instrucciones complejas y estrictas, compruebe por separado.
Cuándo quedarse con Gemini 3.1 Pro
- La tarea es la extracción de documentos muy largos (cerca de 1 millón de tokens), donde la precisión es crítica.
- Se requiere el razonamiento abstracto más profundo sin concesiones.
- Ya tiene un pipeline configurado con un thinking_budget preciso y no está listo para verificar el comportamiento después de cambiar los valores predeterminados.
llm-stats.com: "Lea las filas, no el titular": en la mayoría de las tareas de agente, Flash es mejor, pero hay filas específicas de la tabla donde Pro sigue estando por delante.
10. El modelo Lazy ya no es perezoso: qué ha cambiado en la práctica
Esta es una sección que falta en la mayoría de las revisiones técnicas, pero es la más importante para un desarrollador que ya ha probado Gemini Flash en el trabajo.
Durante meses, una de las quejas más frecuentes sobre los modelos Gemini Flash fue que el modelo era perezoso. Manifestaciones específicas, registradas por Build Fast with AI:
- recorta salidas de código complejas y inserta // TODO: implement this en lugar de lógica real;
- genera un andamio en lugar de código completo;
- termina la tarea antes de haberla completado por completo;
- en modo Canvas, más marcadores de posición que soluciones reales.
Los primeros probadores de Gemini 3.5 Flash, según NPowerUser, dicen que este problema "en gran medida ha quedado atrás". Build Fast with AI aclara: en las pruebas previas a I/O, el modelo producía "implementaciones más completas con menos comentarios de marcador de posición y lógica más realista".
Una advertencia importante: "en gran medida", no "completamente". Para tareas complejas donde el modelo solía ser consistentemente perezoso, vale la pena probarlo específicamente en su caso de uso. Pero la dirección del cambio es correcta, y esto lo confirman probadores independientes.
11. Gemini 3.5 Pro: lo que se sabe sobre el próximo modelo (junio de 2026)
La posición oficial de Google al 21 de mayo de 2026: Gemini 3.5 Pro se está utilizando internamente en Google y está previsto que salga "el próximo mes", es decir, en junio de 2026. La fecha pública no ha sido anunciada.
Lo que se sabe de fuentes oficiales y apidog.com:
- El mismo enfoque en la codificación de agentes y tareas de largo alcance que en Flash.
- Posicionado para tareas donde el presupuesto de tareas incluye trabajo autónomo de varias horas o investigación profunda.
- Se espera compatibilidad con Computer Use, que no está disponible en Flash.
- Modelo de precios: se espera que esté cerca de GPT-5.5 y Opus 4.7.
Hasta el lanzamiento de Pro, Flash es el único modelo actualizado de la línea 3.5 y cubre la gran mayoría de las tareas de agentes de producción.
12. Conclusión: Investigador vs Constructor: cómo elegir un modelo en 2026
The Inference Report en Medium ofrece el marco más preciso: la elección ya no es "inteligente y lento" vs "rápido y superficial". Ahora la pregunta es diferente: ¿necesita el conocimiento paramétrico profundo de un Investigador (Gemini 3.1 Pro) o la capacidad ejecutiva iterativa de baja latencia de un Constructor (Gemini 3.5 Flash)?
Gemini 3.5 Flash es la elección correcta si:
- está creando flujos de trabajo de agentes con muchas llamadas a @tool;
- la velocidad de iteración es importante, no la profundidad de un solo paso de razonamiento;
- su pipeline reutiliza el prompt del sistema: el almacenamiento en caché lo hará más rentable que Pro;
- está migrando de Gemini 3 Flash y necesita un mejor uso de las herramientas.
Quédese con Pro o Claude / GPT-5.5 si:
- la tarea requiere el razonamiento abstracto más complejo;
- la tasa mínima de alucinaciones es crítica;
- necesita Computer Use;
- su carga de trabajo es la extracción precisa de documentos de hasta 1 millón de tokens.
Para los desarrolladores que ya utilizan la API de Gemini: preste atención a los cambios importantes: thinking_level en lugar de thinking_budget, id obligatorio en FunctionResponse, nuevo valor predeterminado medium en lugar de high, preservación de pensamientos por defecto. Un simple reemplazo de la cadena del modelo sin verificación es un riesgo de degradación silenciosa de la calidad.
Gemini 3.5 Pro en junio de 2026 volverá a cambiar el panorama. Pero ya ahora Flash no es un compromiso. Es la nueva norma para el desarrollo de agentes.
Fuentes