TL;DR — Die wichtigsten Änderungen in 30 Sekunden
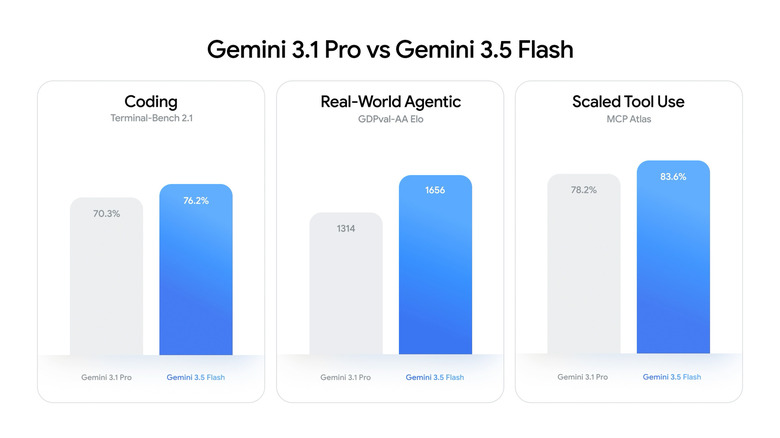
Google hat Gemini 3.5 Flash als erstes Modell der 3.5er-Reihe veröffentlicht – sofort in einer stabilen GA-Version. Es übertrifft Gemini 3.1 Pro in den meisten agentischen und Coding-Benchmarks (MCP Atlas 83,6%, Terminal-Bench 76,2%, GDPval-AA +342 Elo), ist 4x schneller bei der Ausgabe und unterstützt 1 Mio. Kontext.
Neue Preise: $1,50 / $9 pro Million Tokens (Input/Output) + $0,15 pro gecachtem Input (90% Rabatt). Das ist teurer als das frühere Flash, aber dank Caching vorteilhaft für Agenten.
Kritische Breaking Changes für Entwickler:
thinking_budget → thinking_level (neuer Standard – medium, statt high)- Obligatorisches
id in FunctionResponse
- Thought Preservation ist standardmäßig aktiviert
Das Modell ist ideal für agentische Workflows, Tool-Nutzung und komplexes Coding.
Nachteile: Regressionen bei einigen Reasoning-Benchmarks (Humanity’s Last Exam, ARC-AGI-2) und höhere reale Kosten in schwierigen Schleifen. Gemini 3.5 Pro wird für Juni 2026 erwartet.
Inhalt
- Was ist Gemini 3.5 Flash und warum ist dieser Release unkonventionell
- Architektur: Thinking Levels, 1 Mio. Kontext, Knowledge Cutoff Januar 2026
- Tool-Nutzung und Function Calling: @tool als erste Person im Agenten
- Benchmarks: Wo Flash gewinnt – und zwei Regressionen, die Google nicht in die Schlagzeilen brachte
- Geschwindigkeit: 4x schneller – und warum die reale Zahl für Agenten anders ist
- Reale Ökonomie: Nicht $9, sondern $0,15 – wie die Kosten einer Agenten-Schleife berechnet werden
- Wo gestartet: Gemini App, Antigravity 2.0, AI Studio, Vertex, Search
- Vergleich mit Claude Opus 4.7 und GPT-5.5 – nach Aufgaben, nicht nach Hype
- Wo Flash verliert und wann man bei Pro bleiben sollte
- Das Lazy-Modell ist nicht mehr faul – was sich in der Praxis geändert hat
- Gemini 3.5 Pro – was über das nächste Modell bekannt ist (Juni 2026)
- Fazit: Researcher vs. Builder – wie man 2026 ein Modell auswählt
1. Was ist Gemini 3.5 Flash und warum ist dieser Release unkonventionell
Am 19. Mai 2026, zur Eröffnung der Google I/O 2026, hat Google DeepMind Gemini 3.5 Flash für die breite Öffentlichkeit freigegeben. Es ist das erste Modell der neuen Gemini 3.5-Reihe – und es hat die übliche Logik von Modell-Releases sofort durchbrochen.
Das traditionelle Schema sah so aus: Zuerst kommt Pro – das leistungsstärkste und teuerste Modell, und Flash erscheint später als Budget-Option. Laut felloai.com hat Google dieses Mal das Schema umgedreht: Gemini 3.5 Flash übertrifft in den offiziellen Benchmarks Gemini 3.1 Pro bei Coding- und agentischen Workflow-Aufgaben – und ist dabei 40% günstiger und 4x schneller.
Gemini 3.5 Pro wurde auf der I/O nicht veröffentlicht. Laut Berichten von Let's Data Science und Business Insider löste die Ankündigung der Verzögerung von Pro deutliche Ausrufe der Enttäuschung im Saal aus. Pichai sagte persönlich zum Publikum: "I know you can't wait to get your hands on it. Give us until next month to get it to you". Pro wird derzeit nur intern bei Google verwendet und wird für Juni 2026 erwartet.
Somit ist Flash keine abgespeckte Version, sondern das einzige aktuelle Modell der 3.5er-Reihe, das heute verfügbar ist. Es treibt Antigravity 2.0, Gemini Spark und den AI Mode in Google Search an.
2. Architektur: Thinking Levels, 1 Mio. Kontext, Knowledge Cutoff Januar 2026
Basis-Spezifikationen
Laut offizieller Model Card von Google DeepMind:
- API-Modell-ID: gemini-3.5-flash (ohne Preview-Suffix – stabile GA-Version)
- Snapshot: gemini-3.5-flash-05-2026
- Kontextfenster Input: 1.048.576 Tokens (1 Mio.)
- Maximaler Output: 65.536 Tokens
- Multimodaler Input: Text, Bilder, Audio, Video, PDF
- Knowledge Cutoff: Januar 2026
Knowledge Cutoff: +12 Monate – warum das wichtig ist
Das vorherige Gemini 3 Flash hatte einen Knowledge Cutoff im Januar 2025. Laut llm-stats.com hat Gemini 3.5 Flash einen Knowledge Cutoff im Januar 2026. Ein Jahr Unterschied. Für Entwickler ist das ein konkreter praktischer Vorteil: Frameworks, Bibliotheken, APIs – das Modell kennt deren aktuelle Versionen ohne RAG-Krücken.
Thinking Levels statt thinking_budget
Das ist eine wichtige Änderung mit direkten Auswirkungen auf Ihren Code. Offizielle Gemini API-Dokumentation: Der Parameter thinking_budget (ganzzahlig) wurde durch thinking_level (Enum-String) ersetzt:
- minimal – minimale Überlegung, maximale Geschwindigkeit
- low – leichte Überlegung
- medium – Balance (neuer Standard, statt des vorherigen high)
- high – tiefgehende Überlegung für komplexe Aufgaben
Kritische Detail für die Migration von byteiota.com: Wenn Sie einfach den Model-String von gemini-3-flash-preview auf gemini-3.5-flash ändern, ohne weitere Änderungen – ändert sich das Standard-Thinking-Level von high auf medium. Dies wird die Qualität der Antworten in Ihrer Anwendung stillschweigend reduzieren. Überprüfen Sie immer das Verhalten nach der Migration.
Außerdem: Thought Preservation ist standardmäßig aktiviert. Das Modell behält den Reasoning-Kontext zwischen den Zügen – verbessert die Qualität von mehrstufigen Aufgaben, erhöht aber die Token-Kosten bei langen Gesprächen.
Vollständige Migrations-Checkliste von offiziellem Google Developer Guide im DEV Community:
- Aktualisieren Sie den Model-String: gemini-3-flash-preview → gemini-3.5-flash
- Ersetzen Sie thinking_budget durch thinking_level
- Entfernen Sie temperature, top_p, top_k aus der Konfiguration
- Fügen Sie id und den entsprechenden Namen zu allen FunctionResponse-Teilen hinzu
- Aktualisieren Sie das SDK auf google-genai v2.0.0 oder neuer
- Überprüfen Sie die Token-Nutzung – Thought Preservation ist jetzt standardmäßig aktiv
Tool use ist nicht nur ein weiteres Feature. Laut Coding Beauty: "Tool use is becoming the real operating system for AI". Gemini 3.5 Flash wurde von Anfang an darauf aufgebaut.
MCP Atlas 83,6 % – der höchste Wert unter allen Modellen
Laut aimadetools.com: Gemini 3.5 Flash erreichte 83,6 % auf MCP Atlas – das ist der höchste Wert unter allen getesteten Modellen. MCP Atlas ist ein Benchmark speziell für die Qualität der Orchestrierung externer Tools und komplexer Tool-Calling-Workflows. Für einen Entwickler, der einen Agenten mit Dutzenden von @tool-Aufrufen erstellt, ist dies die praktischste Zahl der gesamten Veröffentlichung.
Was ist im Lieferumfang enthalten
Laut offizieller Dokumentation der Gemini API können in einer einzigen Anfrage kombiniert werden:
- Google Search – Grounding auf aktuellen Daten aus dem Web
- Google Maps – Geolokalisierungsanfragen
- URL-Kontext – Lesen externer Seiten
- Codeausführung – Ausführen von Code in einer Sandbox
- Benutzerdefinierte Funktionen – Ihre eigenen @tool
All dies parallel in einem einzigen API-Aufruf. Früher mussten Sie eine Orchestrierungsschicht manuell erstellen; jetzt entscheidet das Modell selbst, welche Tools gestartet werden und in welcher Reihenfolge.
Breaking Change bei FunctionResponse – was im alten Code kaputt geht
Die offizielle Dokumentation fixiert eine kritische Änderung: Jetzt muss in jeder FunctionResponse sowohl die ID als auch der Name übergeben werden, die dem vorherigen functionCall entsprechen. Wenn Ihr alter Code keine ID übergibt – wird er ohne offensichtliche Fehlermeldung kaputt gehen.
// Richtig – mit ID und Name
{
functionResponse: {
name: toolCall.name,
id: toolCall.id, // NEU – obligatorisch
response: { result: result }
}
}
Ein weiterer Nuance: Wenn Sie Anweisungen zusammen mit FunctionResponse hinzufügen – machen Sie sie nicht zu separaten Parts. Fügen Sie sie dem Text der Funktionsantwort über zwei Zeilenumbrüche hinzu. Andernfalls – "thought leakage" und geringere Output-Qualität.
Parallele Tool-Nutzung: Thought Signatures
Laut offizieller Dokumentation des Gemini 3 Developer Guide enthält bei parallelem Function Calling: nur der erste functionCall in der Liste die thoughtSignature. Sie müssen Parts in genau der gleichen Reihenfolge zurückgeben, in der Sie sie erhalten haben. Die Verletzung der Reihenfolge ist ein API-Fehler.
Reale Anwendungsfälle
Laut MarkTechPost:
- Salesforce Agentforce – Sub-Agenten behalten den Kontext zwischen komplexen mehrstufigen Tool-Aufrufen
- Shopify – Parallele Sub-Agenten zur Datenanalyse und Prognose des Händlerwachstums
- Ramp – OCR von Finanzdokumenten mit komplexen Tool-Chains
Was nicht unterstützt wird
Die offizielle Dokumentation sagt klar: "Computer Use is not supported at this moment". Für Workloads mit direkter Betriebssystemsteuerung – bleiben Sie bei Gemini 3 Flash Preview oder schauen Sie in Richtung GPT-5.5.
4. Benchmarks: Wo Flash gewinnt – und zwei Regressionen, die Google nicht in die Schlagzeilen gebracht hat
Alle Benchmarks – aus der offiziellen Veröffentlichung von Google DeepMind vom 19. Mai 2026, sofern nicht anders angegeben. Handy AI Substack hat eine vollständige Tabelle einschließlich der Regressionen zusammengestellt.
| Benchmark |
Gemini 3.5 Flash |
Gemini 3.1 Pro |
Wer ist besser |
| Terminal-Bench 2.1 (CLI-Coding-Agenten) |
76,2 % |
70,3 % |
Flash |
| MCP Atlas (agentic tool use) |
83,6 % |
78,2 % |
Flash |
| Finance Agent v2 |
57,9 % |
43,0 % |
Flash (+14,9 pp) |
| CharXiv Reasoning |
84,2 % |
niedriger |
Flash |
| GDPval-AA (real-world agentic) |
1656 Elo |
1314 Elo |
Flash (+342 Elo) |
| MRCR v2 bei 1 Mio. (langer Kontext) |
77,3 % |
84,9 % |
Pro (Regression) |
| Humanity's Last Exam |
40,2 % |
44,4 % |
Pro (Regression) |
| ARC-AGI-2 |
72,1 % |
77,1 % |
Pro (Regression) |
Zwei Regressionen, über die Google in den Schlagzeilen schweigt
llm-stats.com formuliert ehrlich: Flash ist 3.1 Pro bei Humanity's Last Exam (40,2 % vs. 44,4 %) und ARC-AGI-2 (72,1 % vs. 77,1 %) unterlegen. Das sind keine Bugs – das ist eine architektonische Entscheidung: Flash ist für die reale Arbeit optimiert, nicht für abstraktes Reasoning. Zitat von llm-stats.com: "If your workload is an agent that needs to get something done rather than a researcher asking a hard question — 3.5 Flash is the better choice today".
Der unabhängige BenchLM.ai platziert Flash auf Platz 11 von 116 Modellen. Die stärkste Kategorie – Agentic (#3 von allen). Die schwächste – Instruction Following (#37).
5. Geschwindigkeit: 4x schneller – und warum die reale Zahl für Agenten anders ist
Google erklärt: Gemini 3.5 Flash generiert Token 4x schneller als andere Frontier-Modelle. WaveSpeed und Artificial Analysis bestätigen: über 289 Output-Token pro Sekunde. Claude Opus 4.7 – 67 tok/s, GPT-5.5 – 71 tok/s.
Aber es gibt einen wichtigen Nuance von Build Fast with AI: "Faster token generation reduces the part of an agent's time spent generating text, and for agentic coding that text portion is often large. So agents get faster, but not 4x". Ein Teil der Zeit eines Agenten wird für Aufrufe externer Tools, API-Wartezeiten, Dateivorgänge aufgewendet – und diesen Teil beschleunigt das Modell nicht.
Innerhalb von Antigravity 2.0 gibt Google eine 12-fache Beschleunigung dank eines optimierten Agent Harness an. Für den Maßstab: VentureBeat berichtet, dass Google-Entwickler in Antigravity im März 2026 0,5 Billionen Token pro Tag verarbeiteten und bis Mai über 3 Billionen. Ein Wachstum von 6x in 10 Wochen.
6. Reale Wirtschaft: nicht 9 $, sondern 0,15 $ – wie man die Kosten einer Agenten-Schleife berechnet
Die meisten Überprüfungen bleiben bei 9,00 $ pro Million Output-Token stehen. Aber für Agenten-Workflows ist das keine vollständige Darstellung.
Grundpreistabelle
Laut llm-stats.com und WaveSpeed:
| Modell |
Input ($/1M) |
Output ($/1M) |
Cached Input ($/1M) |
| Gemini 3 Flash (vorherig) |
0,50 $ |
3,00 $ |
— |
| Gemini 3.5 Flash (neu) |
1,50 $ |
9,00 $ |
0,15 $ |
| Gemini 3.1 Pro |
2,50 $ |
15,00 $ |
— |
Warum 0,15 $ Cached Input – die Schlüsselzahl für Agenten
aimadetools.com erklärt: In einer typischen Agenten-Schleife wiederholen sich System-Prompts und Tool-Definitionen bei jeder Anfrage. Ohne Caching werden diese Token bei jedem Aufruf mit 1,50 $/M berechnet. Mit Caching – 0,15 $/M, ein Rabatt von 90 %.
Für ein Agent-Harness mit 50 parallelen Sub-Agenten und einem System-Prompt von 5000 Token – wird der Unterschied zwischen gecachtem und nicht-gecachedem Input zum wichtigsten Kostenhebel, nicht der Grundpreis pro Token. llm-stats.com: "The 90% cache discount makes long agent contexts the dominant cost lever, not per-request input".
Wo es echte Unzufriedenheit gibt
3.5 Flash ist 3x teurer als der vorherige Gemini 3 Flash. Latent Space stellt fest: Die Community auf r/LocalLLaMA reagiert negativ auf den Anstieg des Per-Token-Preises. Build Fast with AI: "At 3x the previous Flash price, Google is asking you to validate that the capability jump is worth it".
7. Wo gestartet: Gemini App, Antigravity 2.0, AI Studio, Vertex, Search
WaveSpeed bestätigt: Am 19. Mai 2026 wurde Gemini 3.5 Flash gleichzeitig in allen wichtigen Oberflächen verfügbar:
- Gemini App (Web, Android, iOS) – Standardmodell, einschließlich des kostenlosen Tarifs
- AI Mode in Google Search – globaler Rollout
- Google Antigravity 2.0 – mit optimiertem Agent Harness (12x Geschwindigkeit in der Plattformumgebung)
- Google AI Studio – Build-Modus und Standard-API
- Gemini API – stabile ID: gemini-3.5-flash; Snapshot: gemini-3.5-flash-05-2026
- Vertex AI – Enterprise API mit gestaffelten SLAs
- Android Studio
- Gemini Enterprise Agent Platform
Kostenloser Zugang: Laut felloai.com ist Flash in der Gemini App (tägliche Limits) und im AI Studio über API-Schlüssel kostenlos.
Branding-Verwirrung: Latent Space stellt ein Problem aus der Community fest: Entwickler verstehen nach der I/O nicht, ob sie Gemini CLI oder Antigravity CLI verwenden sollen. Offizielle Position: Gemini CLI wird am 18. Juni 2026 eingestellt, Antigravity CLI ist sein Ersatz. Aber die Dokumentation ist noch nicht überall aktualisiert.
8. Vergleich mit Claude Opus 4.7 und GPT-5.5 – nach Aufgaben, nicht nach Hype
Der Vergleich basiert auf offiziellen Benchmarks und Analysen von felloai.com, aimadetools.com und Handy AI.
| Aufgabe |
Gemini 3.5 Flash |
Claude Opus 4.7 |
GPT-5.5 |
| Agentic tool use (MCP Atlas) |
83,6 % |
niedriger |
niedriger |
| Terminal / CLI-Coding |
76,2 % |
69,4 % |
82,7 % |
| Finance Agent v2 |
57,9 % |
— |
niedriger |
| SWE-Bench Verified |
niedriger |
führend |
höher als Flash |
| Halluzinationsrate |
durchschnittlich |
am niedrigsten |
durchschnittlich |
| ARC-AGI-2 |
72,1 % |
— |
84,6 % |
| Computer Use |
nicht unterstützt |
vorhanden |
75 %+ OSWorld |
| Output-Geschwindigkeit |
289 tok/s |
67 tok/s |
71 tok/s |
| Output-Preis ($/1M) |
9,00 $ (am günstigsten) |
teurer |
teurer |
felloai.com: "Gemini's edge is speed and price at near-flagship quality". Flash beansprucht keinen Gesamtsieg – es verändert die Wertgleichung: Diese Qualität zu diesem Preis und dieser Geschwindigkeit gab es bisher nicht im Flash-Tier.
9. Wo Flash spielt und wann man bei Pro bleiben sollte
Wo Gemini 3.5 Flash zurückbleibt
- Terminal-Coding: GPT-5.5 ist besser – 82,7 % gegenüber 76,2 %.
- Langer Kontext mit präziser Extraktion: MRCR v2 – Flash 77,3 % gegenüber Pro 84,9 %.
- Komplexes Coding (SWE-Bench): Claude Opus 4.7 und GPT-5.5 sind besser.
- Abstraktes Reasoning (ARC-AGI-2): GPT-5.5 führt mit 84,6 % gegenüber 72,1 %.
- Halluzinationsrate: Claude Opus 4.7 hat die niedrigste. Für kritische Aufgaben – erheblich.
- Computer Use: wird in Flash nicht unterstützt. GPT-5.5 führt.
- Instruction Following: BenchLM platziert Flash auf Platz 37. Bei komplexen strengen Anweisungen – separat prüfen.
Wann man bei Gemini 3.1 Pro bleiben sollte
- Aufgabe – Extraktion aus sehr langen Dokumenten (nahe 1 Mio. Token), bei der Genauigkeit entscheidend ist.
- Benötigt das tiefste abstrakte Reasoning ohne Kompromisse.
- Sie haben bereits eine Pipeline mit präzisem thinking_budget eingerichtet und sind nicht bereit, das Verhalten nach Änderung des Standards zu überprüfen.
llm-stats.com: "Read the rows, not the headline" – bei den meisten agentischen Aufgaben ist Flash besser, aber es gibt spezifische Tabellenzeilen, in denen Pro immer noch besser ist.
10. Lazy-Modell ist nicht mehr faul – was sich in der Praxis geändert hat
Dies ist ein Abschnitt, der in den meisten technischen Übersichten fehlt – aber er ist für Entwickler, die Gemini Flash bereits in der Arbeit ausprobiert haben, am wichtigsten.
Monatelang war eine der häufigsten Beschwerden über Gemini Flash-Modelle: Das Modell ist faul. Spezifische Manifestationen, die von Build Fast with AI erfasst wurden:
- schneidet komplexe Code-Ausgaben ab und fügt // TODO: implement this anstelle von echter Logik ein;
- generiert ein Gerüst anstelle von vollwertigem Code;
- beendet die Aufgabe, bevor sie vollständig erledigt ist;
- im Canvas-Modus – mehr Platzhalter als tatsächliche Lösungen.
Frühe Tester von Gemini 3.5 Flash sagen laut NPowerUser: Dieses Problem "gehört größtenteils der Vergangenheit an". Build Fast with AI präzisiert: Im Test vor I/O produzierte das Modell "vollständigere Implementierungen mit weniger Platzhalter-Kommentaren und realistischerer Logik".
Wichtige Einschränkung: "größtenteils" – nicht "vollständig". Bei komplexen Aufgaben, bei denen das Modell zuvor konstant faul war, lohnt es sich, es spezifisch für Ihren Anwendungsfall zu testen. Aber die Richtung der Änderung ist richtig, und unabhängige Tester bestätigen dies.
11. Gemini 3.5 Pro – was über das nächste Modell bekannt ist (Juni 2026)
Offizielle Position von Google vom 21. Mai 2026: Gemini 3.5 Pro wird intern bei Google verwendet und soll "im nächsten Monat" – also im Juni 2026 – erscheinen. Ein öffentliches Datum wurde nicht angekündigt.
Was aus offiziellen Quellen und apidog.com bekannt ist:
- Der gleiche Fokus auf agentisches Coding und Long-Horizon-Aufgaben wie bei Flash.
- Positioniert für Aufgaben, bei denen das Task-Budget mehrstündige autonome Arbeit oder tiefgehende Recherche beinhaltet.
- Unterstützung für Computer Use wird erwartet – die in Flash fehlt.
- Preismodell – erwartet wird ein Preis nahe GPT-5.5 und Opus 4.7.
Bis zum Erscheinen von Pro ist Flash das einzige aktuelle Modell der 3.5-Reihe und deckt die überwiegende Mehrheit der agentischen Produktionsaufgaben ab.
12. Fazit: Researcher vs. Builder – wie man 2026 ein Modell wählt
The Inference Report auf Medium gibt den präzisesten Rahmen vor: Die Wahl ist nicht mehr "intelligent und langsam" vs. "schnell und oberflächlich". Jetzt ist die Frage anders: Benötigen Sie das tief parametrische Wissen eines Researchers (Gemini 3.1 Pro) – oder die geringe Latenz und iterative Ausführungsfähigkeit eines Builders (Gemini 3.5 Flash)?
Gemini 3.5 Flash ist die richtige Wahl, wenn:
- Sie agentische Workflows mit vielen @tool-Aufrufen erstellen;
- die Geschwindigkeit der Iterationen wichtiger ist als die Tiefe eines einzelnen Reasoning-Schritts;
- Ihre Pipeline den System-Prompt wiederverwendet – Caching macht Sie profitabler als Pro;
- Sie von Gemini 3 Flash migrieren und besseres Tool-Use benötigen.
Bleiben Sie bei Pro oder Claude / GPT-5.5, wenn:
- die Aufgabe das komplexeste abstrakte Reasoning erfordert;
- eine minimale Halluzinationsrate kritisch ist;
- Computer Use benötigt wird;
- Ihr Workload die präzise Extraktion aus Dokumenten nahe 1 Mio. Token ist.
Für Entwickler, die bereits die Gemini API nutzen: Achten Sie auf Breaking Changes – thinking_level anstelle von thinking_budget, obligatorische ID in FunctionResponse, neuer Standard medium anstelle von high, thought preservation standardmäßig. Einfaches Ersetzen der Model-Zeichenkette ohne Überprüfung – birgt das Risiko einer stillen Qualitätsverschlechterung.
Gemini 3.5 Pro wird im Juni 2026 das Bild erneut verändern. Aber schon jetzt ist Flash kein Kompromiss. Es ist die neue Norm für die agentische Entwicklung.
Quellen