TL;DR — Key changes in 30 seconds
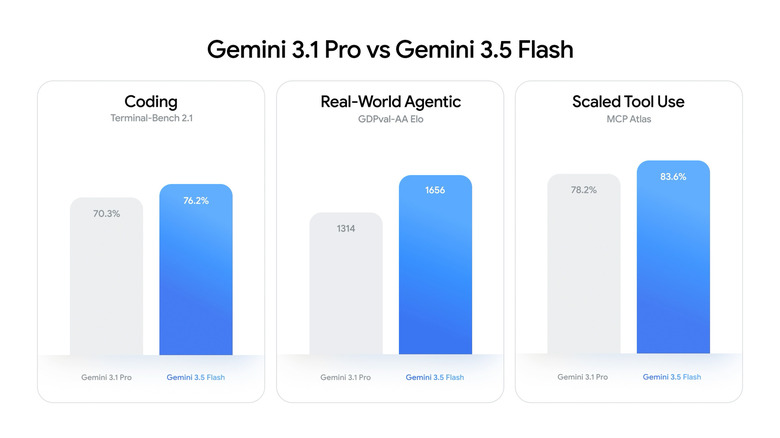
Google released Gemini 3.5 Flash as the first model in the 3.5 lineup — immediately in a stable GA version. It outperforms Gemini 3.1 Pro on most agentic and coding benchmarks (MCP Atlas 83.6%, Terminal-Bench 76.2%, GDPval-AA +342 Elo), runs 4x faster on output, and supports 1M context.
New pricing: $1.50 / $9 per million tokens (input/output) + $0.15 per cached input (90% discount). This is more expensive than the previous Flash, but beneficial for agents due to caching.
Critical breaking changes for developers:
thinking_budget → thinking_level (new default — medium, not high)- Mandatory
id in FunctionResponse
- Thought preservation is enabled by default
The model is ideally suited for agentic workflows, tool use, and complex coding.
Cons: regressions on some reasoning benchmarks (Humanity’s Last Exam, ARC-AGI-2) and higher real-world cost in heavy loops. Gemini 3.5 Pro is expected in June 2026.
Contents
- What is Gemini 3.5 Flash and why this release is non-standard
- Architecture: thinking levels, 1M context, knowledge cutoff January 2026
- Tool use and function calling: @tool as the first person in the agent
- Benchmarks: where Flash wins — and two regressions Google didn't highlight
- Speed: 4x faster — and why the real figure is different for agents
- Real economics: not $9, but $0.15 — how to calculate the cost of an agent loop
- Where it's launched: Gemini app, Antigravity 2.0, AI Studio, Vertex, Search
- Comparison with Claude Opus 4.7 and GPT-5.5 — by tasks, not hype
- Where Flash loses and when to stick with Pro
- Lazy model is no longer lazy — what has changed in practice
- Gemini 3.5 Pro — what is known about the next model (June 2026)
- Conclusion: Researcher vs Builder — how to choose a model in 2026
1. What is Gemini 3.5 Flash and why this release is non-standard
On May 19, 2026, at the opening of Google I/O 2026, Google DeepMind released Gemini 3.5 Flash to general access. This is the first model in the new Gemini 3.5 lineup — and it immediately broke the usual logic of model releases.
The traditional scheme looked like this: first, Pro — the most powerful and expensive model — is released, and Flash appears later as a budget option. According to felloai.com, Google has reversed the scheme this time: Gemini 3.5 Flash outperforms Gemini 3.1 Pro on coding and agentic workflows tasks in official benchmarks — and at the same time costs 40% less and runs 4 times faster.
Gemini 3.5 Pro was not released at I/O. According to reports from Let's Data Science and Business Insider, the announcement of Pro's delay caused audible groans of disappointment in the hall. Pichai personally told the audience: "I know you can't wait to get your hands on it. Give us until next month to get it to you". Pro is currently used only internally at Google, and is expected in June 2026.
Thus, Flash is not a lightweight version, but the only current model in the 3.5 lineup available today. It powers Antigravity 2.0, Gemini Spark, and AI Mode in Google Search.
2. Architecture: thinking levels, 1M context, knowledge cutoff January 2026
Basic Specifications
According to Google DeepMind's official model card:
- API model ID: gemini-3.5-flash (no preview suffix — stable GA version)
- Snapshot: gemini-3.5-flash-05-2026
- Input context window: 1,048,576 tokens (1M)
- Maximum output: 65,536 tokens
- Multimodal input: text, images, audio, video, PDF
- Knowledge cutoff: January 2026
Knowledge cutoff: +12 months — why it matters
The previous Gemini 3 Flash had a knowledge cutoff in January 2025. According to llm-stats.com, Gemini 3.5 Flash is January 2026. A year's difference. For a developer, this is a concrete practical benefit: frameworks, libraries, APIs — the model knows their current versions without RAG crutches.
Thinking levels instead of thinking_budget
This is an important change with direct consequences for your code. Official Gemini API documentation: the thinking_budget parameter (integer) has been replaced by thinking_level (enum string):
- minimal — minimal reasoning, maximum speed
- low — light reasoning
- medium — balance (new default, replacing the previous high)
- high — deep reasoning for complex tasks
Critical detail for migration from byteiota.com: if you simply change the model string from gemini-3-flash-preview to gemini-3.5-flash without other changes — the default thinking level will change from high to medium. This will silently reduce the quality of responses in your application. Always check behavior after migration.
Also: thought preservation is enabled by default. The model preserves reasoning context between turns — improving the quality of multi-turn tasks but increasing token costs in long conversations.
Full migration checklist from official Google Developer Guide on DEV Community:
- Update model string: gemini-3-flash-preview → gemini-3.5-flash
- Replace thinking_budget with thinking_level
- Remove temperature, top_p, top_k from configuration
- Add id and corresponding name to all FunctionResponse parts
- Update SDK to google-genai v2.0.0 or newer
- Check token usage — thought preservation is now active by default
Tool use is not just another feature. According to Coding Beauty: "Tool use is becoming the real operating system for AI". Gemini 3.5 Flash is built around this from day one.
MCP Atlas 83.6% — the highest score among all models
According to aimadetools.com: Gemini 3.5 Flash scored 83.6% on MCP Atlas — the highest score among all tested models. MCP Atlas is a benchmark specifically for the quality of external tool orchestration and complex tool-calling workflows. For a developer building an agent with dozens of @tool calls, this is the most practical figure in the entire release.
What's supported out of the box
According to official Gemini API documentation, you can combine the following in a single request:
- Google Search — grounding on current web data
- Google Maps — geolocation queries
- URL context — reading external pages
- Code execution — running code in a sandbox
- Custom functions — your own @tool
All of this in parallel, in a single API call. Previously, you had to build the orchestration layer manually; now, the model itself decides which tools to run and in what order.
Breaking change in FunctionResponse — what will break in old code
Official documentation notes a critical change: now, each FunctionResponse must include both the id and name corresponding to the previous functionCall. If your old code doesn't pass the id, it will break without an obvious error message.
// Correct — with id and name
{
functionResponse: {
name: toolCall.name,
id: toolCall.id, // NEW — mandatory
response: { result: result }
}
}
Another nuance: if you add instructions along with FunctionResponse, don't make them separate Parts. Add them to the function response text with two line breaks. Otherwise, you'll get "thought leakage" and lower output quality.
Parallel tool use: thought signatures
According to official Gemini 3 Developer Guide documentation, when calling functions in parallel: only the first functionCall in the list contains the thoughtSignature. You must return Parts in the exact same order you received them. Violating the order is an API error.
Real-world cases
According to MarkTechPost:
- Salesforce Agentforce — sub-agents maintain context across complex multi-step tool calls
- Shopify — parallel sub-agents for data analysis and merchant growth forecasting
- Ramp — OCR of financial documents with complex tool chains
What is not supported
Official documentation states directly: "Computer Use is not supported at this moment". For workloads with direct OS control, stick with Gemini 3 Flash Preview or look towards GPT-5.5.
4. Benchmarks: where Flash wins — and two regressions Google didn't headline
All benchmarks are from the official Google DeepMind publication of May 19, 2026, unless otherwise noted. Handy AI Substack compiled a complete table including regressions.
| Benchmark |
Gemini 3.5 Flash |
Gemini 3.1 Pro |
Who is better |
| Terminal-Bench 2.1 (CLI coding agents) |
76.2% |
70.3% |
Flash |
| MCP Atlas (agentic tool use) |
83.6% |
78.2% |
Flash |
| Finance Agent v2 |
57.9% |
43.0% |
Flash (+14.9 pp) |
| CharXiv Reasoning |
84.2% |
lower |
Flash |
| GDPval-AA (real-world agentic) |
1656 Elo |
1314 Elo |
Flash (+342 Elo) |
| MRCR v2 at 1M (long context) |
77.3% |
84.9% |
Pro (regression) |
| Humanity's Last Exam |
40.2% |
44.4% |
Pro (regression) |
| ARC-AGI-2 |
72.1% |
77.1% |
Pro (regression) |
Two regressions Google is silent about in headlines
llm-stats.com puts it honestly: Flash is inferior to 3.1 Pro on Humanity's Last Exam (40.2% vs 44.4%) and ARC-AGI-2 (72.1% vs 77.1%). These are not bugs, but an architectural choice: Flash is optimized for real-world tasks, not abstract reasoning. The frame from llm-stats.com: "If your workload is an agent that needs to get something done rather than a researcher asking a hard question — 3.5 Flash is the better choice today".
Independent BenchLM.ai ranks Flash #11 out of 116 models. The strongest category is Agentic (#3 overall). The weakest is Instruction Following (#37).
5. Speed: 4x faster — and why the real number for agents is different
Google claims: Gemini 3.5 Flash generates tokens 4 times faster than other frontier models. WaveSpeed and Artificial Analysis confirm: over 289 output tokens per second. Claude Opus 4.7 — 67 tok/s, GPT-5.5 — 71 tok/s.
But there's an important nuance from Build Fast with AI: "Faster token generation reduces the part of an agent's time spent generating text, and for agentic coding that text portion is often large. So agents get faster, but not 4x". Part of an agent's time is spent on external tool calls, API waits, file operations — and the model doesn't speed up this part.
Inside Antigravity 2.0, Google claims a 12x speedup thanks to an optimized agent harness. For scale: VentureBeat reports that Google developers in Antigravity processed 0.5 trillion tokens per day in March 2026, and by May — over 3 trillion. A 6x increase in 10 weeks.
6. Real economics: not $9, but $0.15 — how to calculate the cost of an agent loop
Most reviews stop at $9.00 per million output tokens. But for agent workflows, this is an incomplete picture.
Basic pricing table
According to llm-stats.com and WaveSpeed:
| Model |
Input ($/1M) |
Output ($/1M) |
Cached input ($/1M) |
| Gemini 3 Flash (previous) |
$0.50 |
$3.00 |
— |
| Gemini 3.5 Flash (new) |
$1.50 |
$9.00 |
$0.15 |
| Gemini 3.1 Pro |
$2.50 |
$15.00 |
— |
Why $0.15 cached input is the key figure for agents
aimadetools.com explains: in a typical agent loop, the system prompt and tool definitions are repeated in every request. Without caching, these tokens are counted at $1.50/M for each call. With caching — $0.15/M, a 90% discount.
For an agent harness with 50 parallel sub-agents and a system prompt of 5000 tokens, the difference between cached and uncached input becomes the main cost lever, not the base price per token. llm-stats.com: "The 90% cache discount makes long agent contexts the dominant cost lever, not per-request input".
Where there is real dissatisfaction
3.5 Flash is 3 times more expensive than the previous Gemini 3 Flash. Latent Space notes: the community on r/LocalLLaMA is reacting negatively to the increase in per-token price. Build Fast with AI: "At 3x the previous Flash price, Google is asking you to validate that the capability jump is worth it".
7. Where it's launched: Gemini app, Antigravity 2.0, AI Studio, Vertex, Search
WaveSpeed confirms: on May 19, 2026, Gemini 3.5 Flash became available simultaneously across all major platforms:
- Gemini app (web, Android, iOS) — default model, including the free tier
- AI Mode in Google Search — global rollout
- Google Antigravity 2.0 — with an optimized agent harness (12x speed in the platform environment)
- Google AI Studio — Build mode and standard API
- Gemini API — stable ID: gemini-3.5-flash; snapshot: gemini-3.5-flash-05-2026
- Vertex AI — enterprise API with tiered SLAs
- Android Studio
- Gemini Enterprise Agent Platform
Free access: according to felloai.com, Flash is free in the Gemini app (daily limits) and in AI Studio via API key.
Branding confusion: Latent Space notes a problem from the community: developers after I/O are confused whether to use Gemini CLI or Antigravity CLI. The official position: Gemini CLI is closing on June 18, 2026, Antigravity CLI is its replacement. But the documentation is not yet updated everywhere.
8. Comparison with Claude Opus 4.7 and GPT-5.5 — by task, not by hype
The comparison is based on official benchmarks and analyses from felloai.com, aimadetools.com, and Handy AI.
| Task |
Gemini 3.5 Flash |
Claude Opus 4.7 |
GPT-5.5 |
| Agentic tool use (MCP Atlas) |
83.6% |
lower |
lower |
| Terminal / CLI coding |
76.2% |
69.4% |
82.7% |
| Finance Agent v2 |
57.9% |
— |
lower |
| SWE-Bench Verified |
lower |
leader |
higher than Flash |
| Hallucination rate |
average |
lowest |
average |
| ARC-AGI-2 |
72.1% |
— |
84.6% |
| Computer Use |
not supported |
available |
75%+ OSWorld |
| Output speed |
289 tok/s |
67 tok/s |
71 tok/s |
| Output price ($/1M) |
$9.00 (cheapest) |
more expensive |
more expensive |
felloai.com: "Gemini's edge is speed and price at near-flagship quality". Flash doesn't claim overall victory — it changes the value equation: this quality at this price and speed was previously non-existent in the Flash tier.
9. Where Flash Plays and When to Stick with Pro
Where Gemini 3.5 Flash Falls Short
- Terminal coding: GPT-5.5 leads — 82.7% vs 76.2%.
- Long context with precise extraction: MRCR v2 — Flash 77.3% vs Pro 84.9%.
- Complex coding (SWE-Bench): Claude Opus 4.7 and GPT-5.5 are ahead.
- Abstract reasoning (ARC-AGI-2): GPT-5.5 leads with 84.6% vs 72.1%.
- Hallucination rate: Claude Opus 4.7 is the lowest. Crucial for critical tasks.
- Computer Use: not supported in Flash. GPT-5.5 leads.
- Instruction Following: BenchLM ranks Flash at #37. For complex strict instructions, test separately.
When to Stick with Gemini 3.1 Pro
- The task is extraction from very long documents (close to 1M tokens) where accuracy is critical.
- The deepest abstract reasoning is required without compromise.
- You already have a pipeline set up with a precise thinking_budget and are not ready to test behavior after changing the default.
llm-stats.com: "Read the rows, not the headline" — for most agentic tasks, Flash is better, but there are specific rows in the table where Pro still leads.
10. The "Lazy" Model is No Longer Lazy — What Has Changed in Practice
This is a section missing from most technical reviews — yet it's the most important for a developer who has already tried Gemini Flash in their work.
For months, one of the most frequent complaints about Gemini Flash models was that the model was lazy. Specific manifestations, documented by Build Fast with AI:
- it truncates complex code outputs and inserts // TODO: implement this instead of actual logic;
- it generates a scaffold instead of complete code;
- it finishes tasks before completing them fully;
- in Canvas mode — more placeholders than actual solutions.
Early testers of Gemini 3.5 Flash, according to NPowerUser, say this problem "has largely gone away." Build Fast with AI clarifies: in pre-I/O testing, the model produced "more complete implementations with fewer placeholder comments and more realistic logic."
An important caveat: "largely" not "completely." For complex tasks where the model previously consistently slacked, it's worth testing specifically for your use case. But the direction of change is correct, and independent testers confirm this.
11. Gemini 3.5 Pro — What's Known About the Next Model (June 2026)
Google's official position as of May 21, 2026: Gemini 3.5 Pro is being used internally at Google and is scheduled for release "next month" — meaning June 2026. A public release date has not been announced.
What is known from official sources and apidog.com:
- The same focus on agentic coding and long-horizon tasks as Flash.
- Positioned for tasks where the task budget includes multi-hour autonomous work or deep research.
- Support for Computer Use is expected — which is absent in Flash.
- Pricing model — expected to be close to GPT-5.5 and Opus 4.7.
Until Pro is released, Flash is the only current model in the 3.5 lineup and covers the vast majority of production agentic tasks.
12. Conclusion: Researcher vs Builder — How to Choose a Model in 2026
The Inference Report on Medium provides the most accurate frame: the choice is no longer "smart and slow" vs "fast and superficial." The question is now different: do you need the deep parametric knowledge of a Researcher (Gemini 3.1 Pro) — or the low-latency iterative execution capability of a Builder (Gemini 3.5 Flash)?
Gemini 3.5 Flash is the right choice if:
- you are building agentic workflows with many @tool calls;
- iteration speed is more important than the depth of a single reasoning step;
- your pipeline reuses the system prompt — caching will make you more cost-effective than Pro;
- you are migrating from Gemini 3 Flash and need better tool use.
Stick with Pro or Claude / GPT-5.5 if:
- the task requires the most complex abstract reasoning;
- minimal hallucination rate is critical;
- Computer Use is needed;
- your workload involves precise extraction from documents close to 1M tokens.
For developers already using the Gemini API: pay attention to breaking changes — thinking_level instead of thinking_budget, mandatory id in FunctionResponse, new default medium instead of high, thought preservation by default. Simply replacing the model string without testing risks silent quality degradation.
Gemini 3.5 Pro in June 2026 will change the landscape again. But even now, Flash is not a compromise. It's the new norm for agentic development.
Sources