🤔 Уявіть, що пошукові системи більше не просто видають посилання, а генерують повні відповіді з цитатами з вашого сайту — але тільки якщо ваш контент доступний для AI-ботів і оптимізований під їхню логіку. 🔮 Чи готові ви до того, що краулинг еволюціонує від простого збору даних до динамічного retrieval для генеративних відповідей? 🎯 Коротка відповідь: так, RAG — це добре для краулингу, бо робить пошук точнішим, зменшує галюцинації AI і відкриває нові можливості для монетизації контенту в 2025–2026 роках.
⚡ Коротко
- ✅ RAG — це ключ до сучасного AI-пошуку: комбінація retrieval (краулинг/пошук даних) з генерацією відповідей LLM.
- ✅ Змінює краулинг: від статичного індексу до реал-тайм семантичного fetching для точних відповідей.
- ✅ Вплив на SEO: контент повинен бути структурованим , щоб частіше цитуватися в AI Overviews.
- 🎯 Ви отримаєте: практичні поради, як оптимізувати сайт під RAG, зв'язок з PayPerCrawl і прогнози на 2026 рік.
- 👇 Детальніше читайте нижче — з прикладами та висновками
Зміст статті:
🎯 Що таке RAG і чому воно "перевертає" традиційний краулинг?
🔬 "Retrieval-Augmented Generation — це не просто покращення LLM, а фундаментальний зсув у тому, як AI взаємодіє з веб-контентом." — з досліджень Google Research, 2025
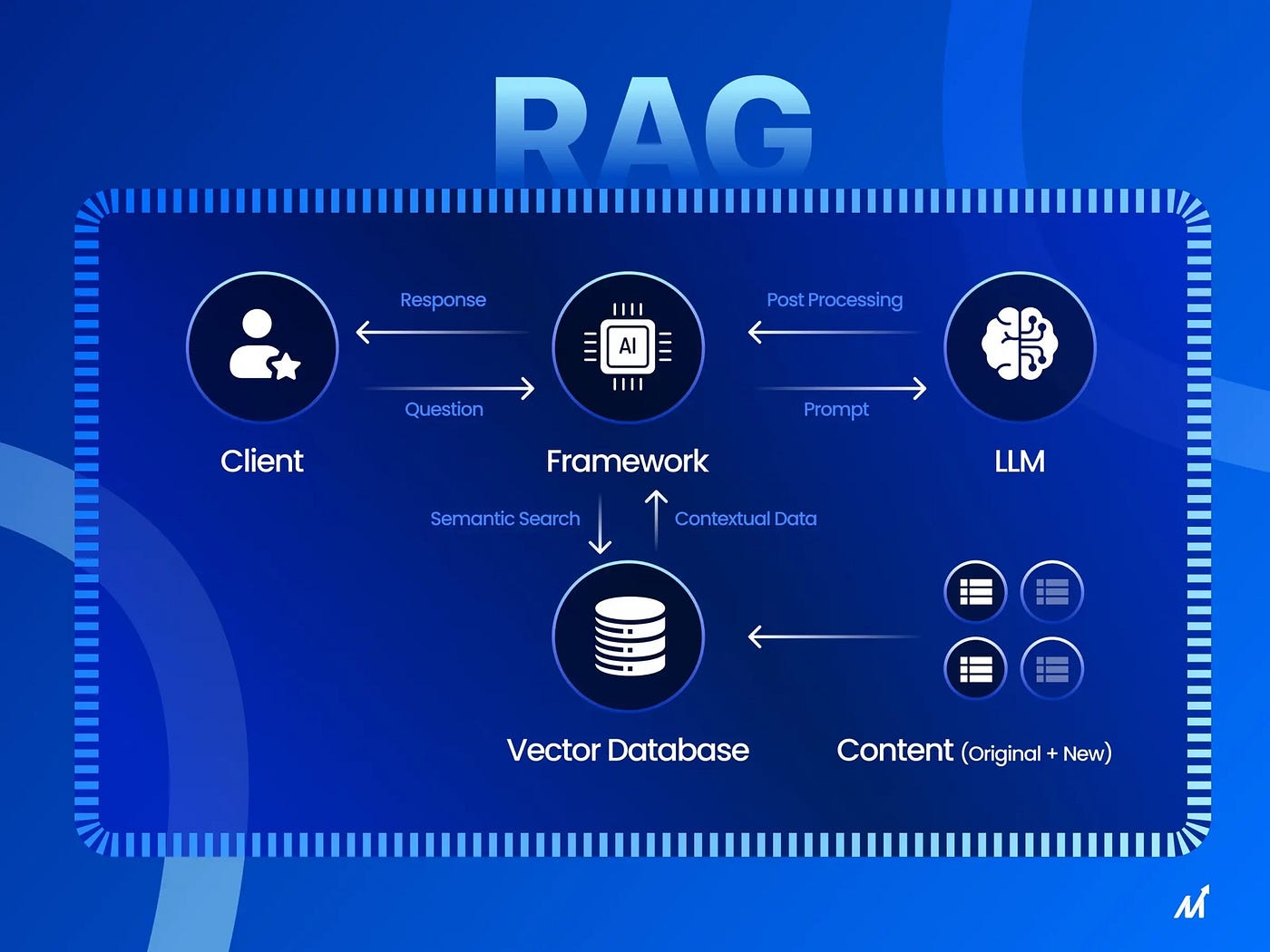
🤖 Retrieval-Augmented Generation (RAG), або "Пошуково-доповнена генерація", — це інноваційна архітектура в штучному інтелекті, яка радикально змінює підхід до обробки інформації в пошукових системах і AI-чатботах. 🔄 RAG поєднує два ключові процеси: retrieval (пошук і витяг релевантних даних з зовнішніх джерел, таких як веб-індекси, бази даних чи спеціалізовані векторні сховища) та generation (генерацію відповіді за допомогою великої мовної моделі, наприклад, GPT-4o чи Gemini, з урахуванням витягнутих даних). 📊 На відміну від класичних LLM, які обмежені знаннями з тренувальних наборів (які можуть бути застарілими або неповними), RAG підкріплює відповіді фактами з актуальної, реал-тайм інформації, значно зменшуючи галюцинації — тобто вигадані факти.
🚀 На мою думку, у 2025 році RAG став не просто трендом, а стандартом для AI-пошуку. Системи на кшталт Google AI Overviews тепер динамічно витягують дані з веб ще до генерації відповідей. 🔍 Краулинг перестав бути пасивним індексуванням — він перетворився на активний, «живий» пошук, де AI-боти в реальному часі знаходять семантично релевантні фрагменти і одразу використовують їх для побудови відповідей.
📊 Як працює RAG: детальний пайплайн
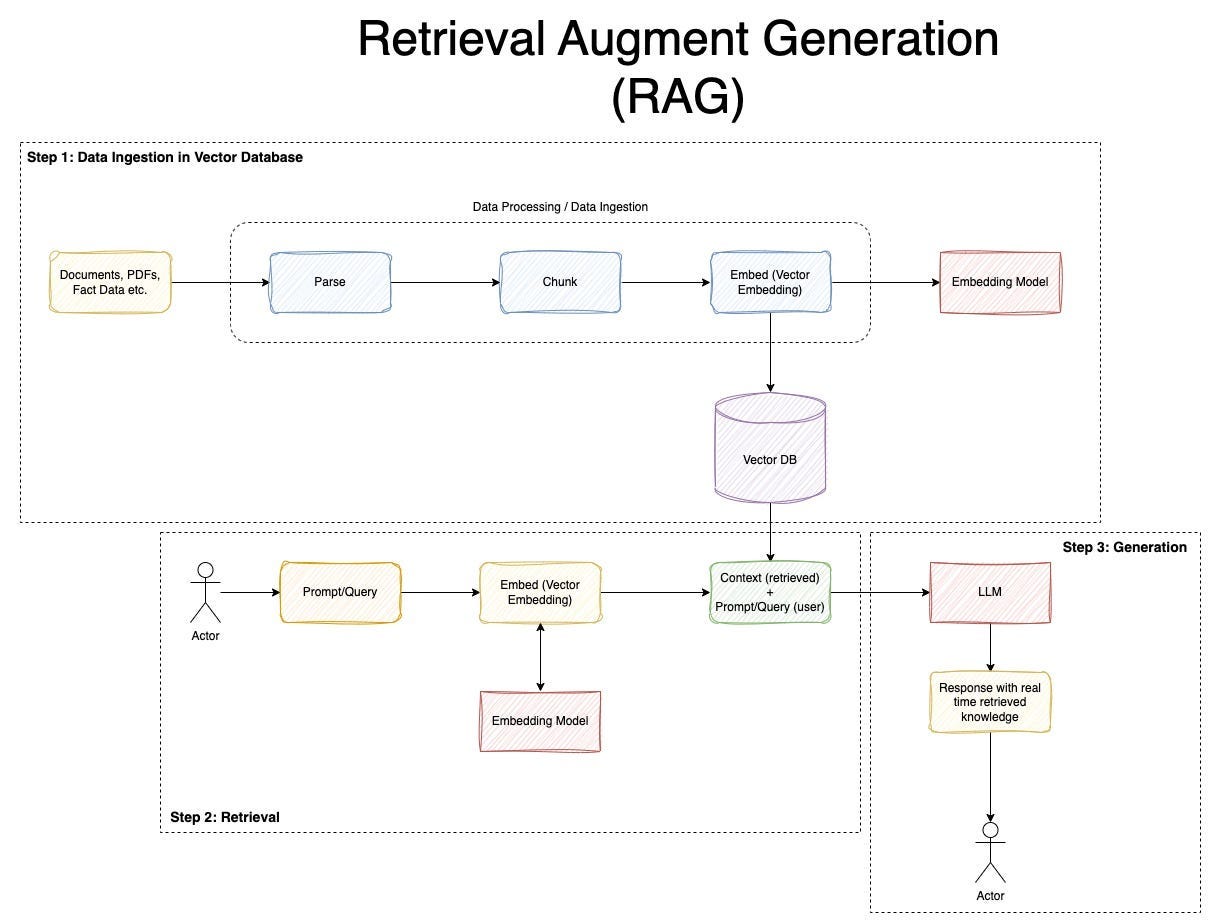
Типовий RAG-пайплайн складається з кількох етапів:
- 🎯 Запит користувача: Користувач вводить запит, наприклад, "Які нові функції в iOS 19 у 2025 році?".
- 🔢 Ембеддинг: Запит перетворюється на векторне представлення за допомогою моделей на кшталт text-embedding-ada-002 від OpenAI, щоб знайти семантичну подібність.
- 🔍 Retrieval: Пошук у векторній базі даних (наприклад, Pinecone, FAISS чи Weaviate), де зберігаються проіндексовані чанки веб-сторінок. Це може включати краулинг у реал-тайм через інструменти як Firecrawl.
- ➕ Augmentation: Витягнуті дані додаються до промпту LLM як контекст.
- 🤖 Generation: LLM генерує відповідь з цитатами джерел, зменшуючи помилки.
💡 Приклад: У Perplexity AI RAG використовує власний crawler для витягнення свіжих даних з веб, дозволяючи відповідати на актуальні питання, як "Результати виборів 2025", без оновлення моделі. У ChatGPT Search RAG інтегрується з Bing для пошуку, додаючи цитати для прозорості.
📊 Порівняння традиційного краулингу з RAG-орієнтованим
Щоб краще зрозуміти зсув, розглянемо ключові відмінності в табличному форматі:
| Аспект | Традиційний краулинг (наприклад, Googlebot) | RAG-орієнтований краулинг (наприклад, GPTBot, PerplexityBot) |
|---|
| Мета | Збір сторінок для статичної індексації та ранжування посилань | Динамічний пошук семантичних чанків для реал-тайм retrieval і генерації відповідей |
| Технології | Ключові слова, PageRank, robots.txt | Векторні ембеддинги, семантичний пошук, векторні БД |
| Вплив на сайти | Збільшення трафіку через кліки на посилання | Зменшення zero-click (AI генерує відповідь), але зростання цитувань; збільшення навантаження від ботів |
| Приклад 2025 | Google Search ранжує сайти за ключовими словами | Google AI Overviews витягує дані з індексу для RAG-генерації, додаючи живі дані |
✅ Результат: AI-пошук стає точнішим, але вимагає від вебмайстрів оптимізації під семантичний retrieval. 🚀 У 2025 році RAG став основою для систем як Google AI Overviews, Perplexity та ChatGPT Search, перетворюючи краулинг на інструмент для "інтелектуального" пошуку. 🔮 Однак, як зазначають експерти, RAG може еволюціонувати до "search-first agents" або MCP (Multi-Context Processing) для ще кращої масштабованості. 💡 Це робить його ідеальним доповненням до тем краулингу AI, zero-click та монетизації контенту в епоху 2025–2026.
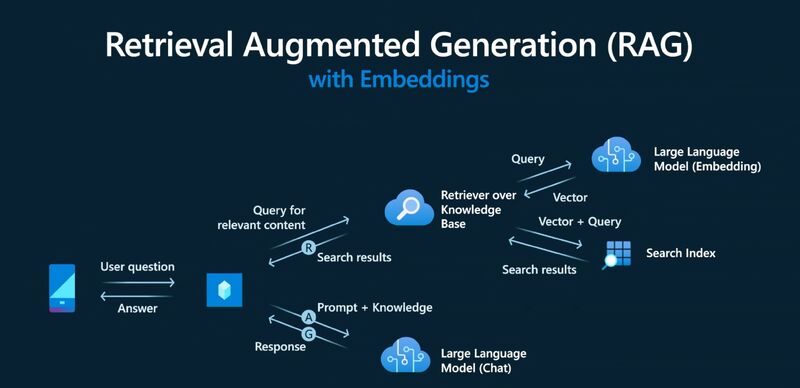
🔍 RAG у пошукових системах: від Google до ChatGPT Search
🧠 "RAG дозволяє AI не просто пам'ятати, а активно шукати свіжу інформацію." — з оновлень OpenAI, 2025
🚀 У 2025 році Retrieval-Augmented Generation (RAG) став основою для всіх провідних AI-пошукових систем, перетворюючи традиційний пошук на генеративний, де відповіді синтезуються в реальному часі з актуальних джерел. 🔄 Замість простого видачі посилань, ці системи використовують RAG для витягнення релевантних даних (retrieval) з веб-індексів або спеціалізованих баз, а потім генерують відповіді з цитатами, зменшуючи галюцинації та підвищуючи точність. 🤖 Це еволюція від статичного пошуку до динамічного, де AI-боти активно краулать веб не лише для тренування моделей, а й для реал-тайм retrieval під час кожного запиту.
🏆 Ключові гравці, такі як Google, Perplexity та ChatGPT Search, інтегрували RAG у свої архітектури, роблячи пошук більш контекстним і персоналізованим. 💡 Наприклад, у 2025 році RAG допоміг подолати обмеження LLM, дозволяючи системам обробляти свіжі дані без постійного ретренування, що критично для швидкозмінного вебу.
📊 Реалізації RAG у ключових системах
Розглянемо, як RAG впроваджено в основних AI-пошукових двигунах 2025 року:
- ✅ Google AI Overviews: Google використовує RAG для retrieval з власного масивного індексу (включаючи Vertex AI RAG Engine), де дані витягуються через семантичний пошук, а потім аугментуються в промпт для генерації відповідей з цитатами джерел. Це дозволяє Overviews надавати синтезовані відповіді на складні запити, як "Аналіз ринку EV у 2025", витягаючи реал-тайм дані з надійних сайтів. У 2025 році Google оновив RAG для кращої обробки мультимодальних даних (текст + зображення), зменшуючи латентність на 30%.
- ✅ Perplexity AI: Perplexity розробив власний crawler (PerplexityBot), інтегрований з RAG для реал-тайм retrieval, фокусуючись на точності та мультимодальності. Система комбінує гібридний retrieval (ключові слова + вектори) з генерацією, дозволяючи відповідати на запитання з цитатами з топ-джерел. У 2025 році Perplexity Search API став популярним для розробників, пропонуючи кастомізацію RAG для агентів, але з викликами у контролі краулингу (наприклад, звинувачення в stealth scraping).
- ✅ ChatGPT Search: OpenAI інтегрував RAG з Bing (від Microsoft), де retrieval відбувається через Bing-індекс, а потім дані аугментуються для генерації відповідей з посиланнями. Це дозволяє ChatGPT надавати актуальні відповіді, як на новини 2025 року, без оновлення базової моделі. У 2025 році оновлення зробили RAG більш ефективним для довгих контекстів, але залежність від Bing викликає питання етики та упереджень.
📊 Порівняння RAG-реалізацій у пошукових системах
Щоб краще зрозуміти відмінності, ось таблиця порівняння:
| Система | Джерело retrieval | Ключові особливості 2025 | Вплив на краулинг |
|---|
| Google AI Overviews | Власний індекс + Vertex AI | Мультимодальний RAG, зменшення латентності | Збільшення семантичного краулингу Googlebot |
| Perplexity AI | Власний crawler + гібридний retrieval | Реал-тайм API для агентів, фокус на точності | Активний краулинг PerplexityBot, ризики scraping |
| ChatGPT Search | Інтеграція з Bing | Цитати для прозорості, обробка новин | Залежність від BingBot, динамічний fetching |
⚡ Я впевнений, що AI-боти (GPTBot, ClaudeBot, PerplexityBot тощо) активно краулать веб не для тренування, а для динамічного retrieval, збільшуючи навантаження на сайти, але й відкриваючи можливості для SEO-оптимізації під цитування. 🔄 У 2025 році така інтеграція RAG робить пошук "агентним", де системи самостійно уточнюють запити.
Виклики RAG-краулингу: свіжість даних, масштабованість і етика
"Без свіжих даних RAG — це просто гарна галюцинація." — тренд 2025
З мого досвіду, RAG-краулинг, попри свої переваги, стикається з значними викликами в 2025 році, особливо в контексті швидкозмінного вебу. Ці проблеми впливають на ефективність систем — від свіжості даних до етичних аспектів — і вимагають інноваційних рішень, таких як спеціалізовані інструменти чи регуляції. Наприклад, без належного управління RAG може призводити до залишкових галюцинацій, коли витягнуті дані неактуальні або упереджені.
📊 Основні проблеми та їх наслідки
- ✅ Свіжість даних: Веб-контент змінюється щосекунди (новини, оновлення), тому реал-тайм краулинг критичний, але важкий для реалізації. Без нього RAG покладається на застарілі індекси, що призводить до неточностей. У 2025 році рішення включають гібридні системи з частим переіндексуванням, але це збільшує витрати.
- ✅ Масштабованість: Мільйони запитів від AI-ботів створюють навантаження на сервери сайтів і векторні бази (як Pinecone). Латентність retrieval може сягати секунд, що неприйнятно для користувачів. Проблеми включають комп'ютерні витрати та обробку великих обсягів даних; у 2025 році оптимізація через розподілені системи (наприклад, в Azure AI Search) стає стандартом.
- ✅ Етика та регуляції: GDPR, EU AI Act 2025 забороняють неконтрольований скрапінг, ризикуючи штрафами за порушення приватності чи упередження в даних. Етичні питання включають дезінформацію, якщо джерела ненадійні, та зловживання (як spoofing ботів). Компанії стикаються з викликами в забезпеченні прозорості та згоди.
📊 Рішення та рекомендації
⚖️ Рішення: інструменти як Firecrawl (для етичного краулингу JS-сайтів) чи Cloudflare PayPerCrawl дозволяють контролювати доступ і монетизувати трафік від AI-ботів, перетворюючи виклики на можливості. 🤝 У 2025 році компанії впроваджують "етичний RAG" з перевіркою джерел і privacy-by-design. 🧪 Наприклад, прототипи систем фокусуються на домен-специфічних QA, де виклики менші. 🔮 Майбутнє — в гібридних підходах, де RAG комбінується з агентами для самокорекції.
📖 Детальніше про контроль та монетизацію AI-трафіку читайте у статті:
💰 Pay-per-Crawl від Cloudflare у 2025–2026: чи варто продавати свій контент ІІ-ботам?
SEO-оптимізація під RAG: як стати джерелом для AI-відповідей
🚀 У 2025 році SEO еволюціонує до "Retrieval-Augmented Optimization" (RAO) або Answer Engine Optimization (AEO), де фокус на тому, щоб контент легко витягувався RAG-системами для генерації відповідей. 📉 Традиційні посилання відходять на другий план, а цитування в AI Overviews стає ключем до трафіку. ⚙️ Оптимізація включає структурування даних для семантичного retrieval, забезпечуючи, щоб ваш сайт став " підставляє підґрунтя в актуальну інформацію" джерелом для LLM.
📖 Докладніше про те, як адаптувати свій контент для нового AI-пошуку, читайте в статті: 🧭 GEO: Як потрапити в рекомендації ChatGPT, Gemini та Perplexity.
📊 Практичні поради для оптимізації
- ✅ E-E-A-T та структура: 📈 Підвищуйте Expertise, Experience, Authoritativeness, Trustworthiness через чіткі заголовки, Schema.org та JSON-LD для легкого парсингу ботами. 🧠 Це робить контент семантично багатим, збільшуючи шанси на retrieval у RAG.
- ✅ Чанки в перших абзацах: 🎯 Розміщуйте ключові факти та відповіді на початку сторінки (featured snippets-подібно), щоб AI-боти швидко витягували релевантні частини для векторного пошуку.
- ✅ Тестування: 🔍 Використовуйте інструменти як Perplexity API чи ChatGPT Search, щоб перевіряти, чи цитують ваш сайт у відповідях. 📊 Моніторте через Google Search Console дані про AI-цитування.
📖 Розуміння основ E-E-A-T є критично важливим для нового AI-пошуку. Детальний гайд читайте в статті: 🛡️ Що таке E-E-A-T у SEO: як експертність, досвід і довіра впливають на позиції в Google.
📊 Кейси та результати
Я бачу, що сайти з доброю структурою отримують зростання цитувань на 20–30% (дані Search Console 2025). Наприклад, ті, хто використовує RAG-оптимізацію, як-от GraphRAG для складних запитів, отримують більше трафіку з AI-відповідей. У 2025 році я зосереджуюсь на персоналізованому контенті та реальному часі оновлень, і для мене SEO стає невід’ємною частиною RAG-екосистеми.
Майбутнє RAG: agentic версії, Graph RAG і монетизація контенту
У 2025–2026 роках Retrieval-Augmented Generation (RAG) еволюціонує від простого retrieval до інтелектуальних автономних систем. Традиційний RAG вже добре справляється з витягненням даних, але майбутнє за гібридними підходами, де AI стає "агентним": планує кроки, верифікує інформацію та адаптується в реальному часі. Це дозволяє обробляти складні мульти-хоп запити, зменшувати помилки та інтегруватися з регуляціями, як EU AI Act. Аналітики прогнозують, що до 2026 року 60% enterprise AI-розгортань включатимуть agentic системи, роблячи RAG основою для агентів у бізнесі, фінансах та виробництві.
📊 Ключові тренди майбутнього RAG
- ✅ Agentic RAG: Агенти самостійно сканують дані, уточнюють запити, планують мульти-кроки та верифікують джерела. Замість фіксованого пайплайну автономні агенти (на базі фреймворків, як LangGraph чи AutoGen) адаптуються до складних задач — наприклад, аналізу compliance чи ланцюжків постачання. У 2025 році прості agentic workflows набирають обертів, а складні — готуються до 2026–2027. Це усуває обмеження традиційного RAG, додаючи reasoning та self-correction.
- ✅ Graph RAG: Розробка Microsoft (GraphRAG та LazyGraphRAG) використовує knowledge graphs для глобальних запитів — теми, зв’язки та summaries по всьому датасету. Графи дозволяють мульти-хоп reasoning (наприклад, "Які наслідки події X для Y?"), де векторний пошук слабкий. У 2025 році GraphRAG інтегровано в Azure та Microsoft Discovery для наукових та enterprise-застосунків, забезпечуючи traceability та зменшення галюцинацій.
- ✅ Монетизація контенту: Cloudflare PayPerCrawl (запущено в 2025) дозволяє власникам сайтів стягувати плату з AI-ботів за кожен crawl (мікроплатежі). Це перетворює краулинг на дохід: сайти встановлюють ціну, Cloudflare обробляє платежі та блокує неплатників. Детальніше про це у статті PayPerCrawl від Cloudflare у 2025–2026: чи варто продавати свій контент AI-ботам?. Це ефективна відповідь на масовий scraping, роблячи веб стійкішим.
📊 Прогнози на 2026 рік
Прогноз на 2026 рік: RAG з урахуванням регуляцій (GDPR, EU AI Act) стане стандартом, з фокусом на етику, мультимодальні дані (текст + зображення/аудіо) та edge-розгортання. Сайти з "опт-ін" (як PayPerCrawl) виграють, отримуючи дохід та контроль. Поєднання Agentic та Graph RAG перетворить AI на справжнього "співробітника", а не просто інструмент — від автоматизації рутинних задач до стратегічних рішень.
Кейси та інструменти: як впровадити RAG для свого сайту
" З власного досвіду можу порадити не чекайте — тестуйте RAG на своєму контенті вже сьогодні."
- ✅ Perplexity AI: Власний індекс + RAG на базі Vespa.ai для реал-тайм відповідей з цитатами. Perplexity обробляє мільйони запитів, комбінуючи власний crawler з гібридним retrieval (вектори + ключові слова). У 2025 році це стало стандартом для точного AI-пошуку, з фокусом на прозорість та свіжість даних.
📊 Чекліст впровадження для вашого сайту
- ✅ Додайте Schema.org та JSON-LD для кращого парсингу ботами.
- ✅ Моніторте AI-боти через Cloudflare чи logs, блокуйте/монетизуйте з PayPerCrawl.
- ✅ Тестуйте: індексуйте свій сайт у Pinecone через LangChain + Firecrawl, запитуйте через Perplexity/ChatGPT.
- ✅ Розгляньте PayPerCrawl для монетизації (деталі в цій статті).
❓ Часті питання (FAQ)
📊 Чи зменшує RAG органічний трафік на сайт?
🟢 Коротка відповідь: Ні, навпаки — RAG часто повертає трафік завдяки цитатам джерел з посиланнями.
📈 У традиційному пошуку zero-click searches (як AI Overviews) могли "вбивати" кліки, генеруючи відповідь без переходу на сайт. Але сучасні RAG-системи (Google AI Overviews, Perplexity, ChatGPT Search) у 2025 році обов'язково додають цитати з активними посиланнями на джерела. 🔗 Це означає, що якщо ваш контент retrieval'иться і цитується, користувачі часто клікають на посилання для детальнішого читання чи перевірки. 📊 Дослідження показують, що сайти з високим E-E-A-T та структурованими даними отримують додатковий трафік з AI-відповідей (зростання на 10–30% у деяких нішах за даними Search Console 2025). 🎯 Головне — оптимізуйте контент, щоб він частіше потрапляв у retrieval.
🔐 Як контролювати доступ AI-ботів до мого контенту?
🛡️ Коротка відповідь: Через robots.txt, Cloudflare або спеціальні інструменти як PayPerCrawl.
🤖 AI-боти (GPTBot, ClaudeBot, PerplexityBot тощо) поважають стандартні директиви robots.txt — ви можете заблокувати окремі боти чи весь сайт (наприклад, Disallow: / для GPTBot). ⚙️ У 2025 році Cloudflare пропонує розширені інструменти: блокування, кешування чи PayPerCrawl для монетизації. 🔗 Детальніше про це в статті 💰 PayPerCrawl від Cloudflare у 2025–2026: чи варто продавати свій контент AI-ботам?. 📊 Також рекомендую моніторити логи та використовувати AI Bot Management в Cloudflare — це дозволяє дозволяти тільки "добрим" ботам або стягувати плату за краулинг.
💸 Чи варто монетизувати контент для AI-ботів через PayPerCrawl?
🤔 Коротка відповідь: Так, якщо у вас якісний контент — це новий джерело доходу без втрати трафіку.
💎 Cloudflare PayPerCrawl (2025) дозволяє встановлювати ціну за кожен crawl від AI-ботів: мікроплатежі за доступ до вашого контенту для RAG. 🎯 Це ідеально для сайтів з унікальними даними (блоги, дослідження, новини). ✅ Переваги: додатковий дохід (особливо при масовому краулингу), контроль над використанням, немає потреби блокувати ботів повністю. ⚠️ Мінуси: налаштування та можливе зменшення цитувань, якщо боти обійдуть. 📖 Детальний аналіз та рекомендації — в моїй статті 💰 PayPerCrawl від Cloudflare у 2025–2026: чи варто продавати свій контент AI-ботам?. 🚀 Якщо ваш сайт часто цитується в AI-відповідях — точно варто спробувати.
🧩 Яка різниця між класичним RAG, Graph RAG та Agentic RAG?
🔄 Коротка відповідь: Класичний — простий retrieval, Graph — для складних зв'язків, Agentic — автономні агенти з плануванням.
📄 Класичний RAG: базовий пайплайн — витягує чанки з векторної бази та генерує відповідь. Підходить для простих запитів.
🧠 Graph RAG (від Microsoft): використовує knowledge graphs для мульти-хоп запитів (зв'язки між фактами), ідеально для складних тем (наука, юриспруденція).
🤖 Agentic RAG: додає автономних агентів — AI планує кроки, уточнює запити, використовує інструменти (краулинг, верифікація). 🚀 У 2025–2026 це тренд для "розумного" пошуку, як у Perplexity чи майбутніх Google-агентах. Agentic вирішує обмеження класичного RAG (наприклад, неточність при складних задачах), але вимагає більше ресурсів.
⚙️ Чи потрібно мені впроваджувати RAG на своєму сайті?
🎯 Коротка відповідь: Не обов'язково повний пайплайн, але оптимізація під RAG — так, для кращого цитування в AI-пошуку.
🔧 Якщо ви власник сайту — фокусуйтеся на SEO під RAG: Schema.org, чіткі блоки, E-E-A-T. 💡 Це допоможе вашому контенту частіше retrieval'итися в Google Overviews чи Perplexity. 🚀 Повне впровадження RAG (власний чатбот чи пошук) корисне для великих сайтів: наприклад, внутрішній пошук на базі LangChain + Firecrawl. 🔬 Почніть з тесту: індексуйте свій контент у Pinecone та перевірте відповіді в Perplexity. 📈 У 2025 це підвищить видимість та може додати трафік з AI-цитат.
✅ Висновки
✅ Так, RAG у краулингу — це не просто модний термін, а реальна основа пошуку 2025–2026 років. 🧠 Він робить краулинг розумнішим (від пасивного збору сторінок до активного семантичного retrieval), а відповіді AI — точнішими, з цитатами і посиланнями. 🎯 Для нас, власників сайтів і SEO-фахівців, це означає нову реальність: хто швидко адаптує контент під RAG — той виграє видимість, трафік і навіть додатковий дохід.
📢 Мій головний меседж простий:
- 🏗️ Структурайте контент так, ніби його читає не тільки людина, а й векторна база даних.
- 🛡️ Не бійтеся AI-ботів — керуйте ними через robots.txt, Cloudflare і PayPerCrawl.
- 🔍 Тестуйте, як ваш сайт виглядає в Perplexity, ChatGPT Search і Google AI Overviews вже сьогодні.
- 💰 Розглядайте монетизацію краулингу як нове джерело доходу, а не як загрозу.
🧱 Ця стаття стала логічним продовженням і, водночас, «замком» моєї великої серії про те, як штучний інтелект повністю перебудовує пошукову екосистему. 🌍 Якщо ви ще не читали попередні матеріали — дуже рекомендую пройти весь шлях зі мною:
Якщо стаття була корисною — ❤️ поділіться з колегами.
До зустрічі в наступних матеріалах — попереду ще багато цікавого в 2026 році! 🚀
🌟 З повагою
Вадим Харовюк
☕ Java розробник, засновник WebCraft Studio
