🤔 Imagine that search engines no longer just provide links, but generate complete answers with quotes from your site — but only if your content is accessible to AI bots and optimized for their logic. 🔮 Are you ready for crawling to evolve from simple data collection to dynamic retrieval for generative answers? 🎯 Short answer: yes, RAG is good for crawling because it makes search more accurate, reduces AI hallucinations, and opens up new opportunities for content monetization in 2025–2026.
⚡ In short
- ✅ RAG is the key to modern AI search: a combination of retrieval (crawling/data search) with LLM answer generation.
- ✅ Changes crawling: from a static index to real-time semantic fetching for accurate answers.
- ✅ Impact on SEO: content must be structured to be cited more often in AI Overviews.
- 🎯 You will get: practical advice on how to optimize your site for RAG, connection with PayPerCrawl, and forecasts for 2026.
- 👇 Read more below — with examples and conclusions
Table of Contents:
🎯 What is RAG and why is it "overturning" traditional crawling?
🔬 "Retrieval-Augmented Generation is not just an LLM improvement, but a fundamental shift in how AI interacts with web content." — from Google Research studies, 2025
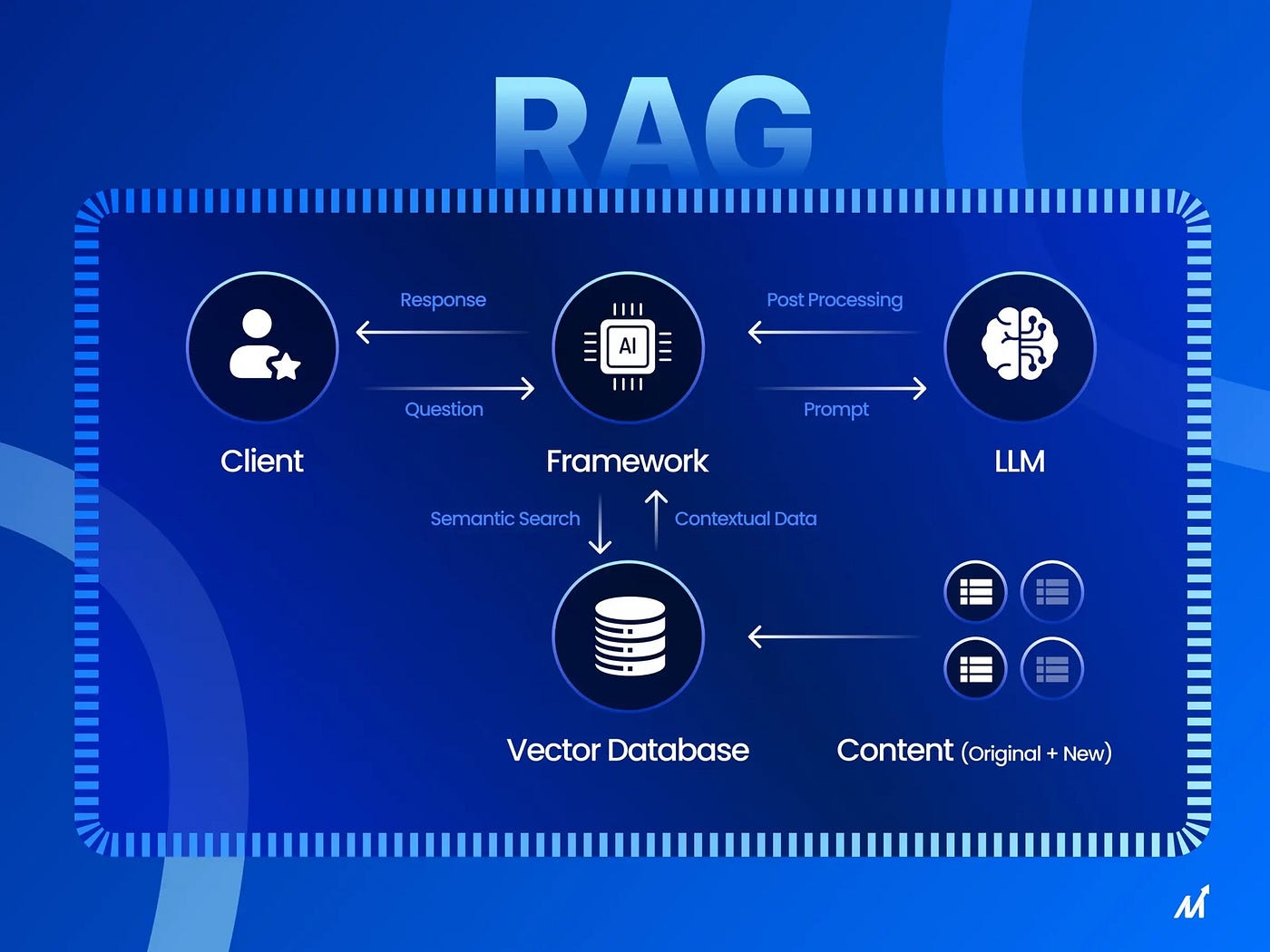
🤖 Retrieval-Augmented Generation (RAG), or "Search-Augmented Generation", is an innovative architecture in artificial intelligence that radically changes the approach to information processing in search engines and AI chatbots. 🔄 RAG combines two key processes: retrieval (searching and extracting relevant data from external sources, such as web indexes, databases, or specialized vector stores) and generation (generating an answer using a large language model, for example, GPT-4o or Gemini, taking into account the extracted data). 📊 Unlike classic LLMs, which are limited by knowledge from training sets (which may be outdated or incomplete), RAG supports answers with facts from current, real-time information, significantly reducing hallucinations — i.e., fabricated facts.
🚀 In my opinion, in 2025, RAG became not just a trend, but a standard for AI search. Systems like Google AI Overviews now dynamically extract data from the web even before generating answers. 🔍 Crawling has ceased to be passive indexing — it has transformed into an active, "live" search, where AI bots find semantically relevant fragments in real-time and immediately use them to construct answers.
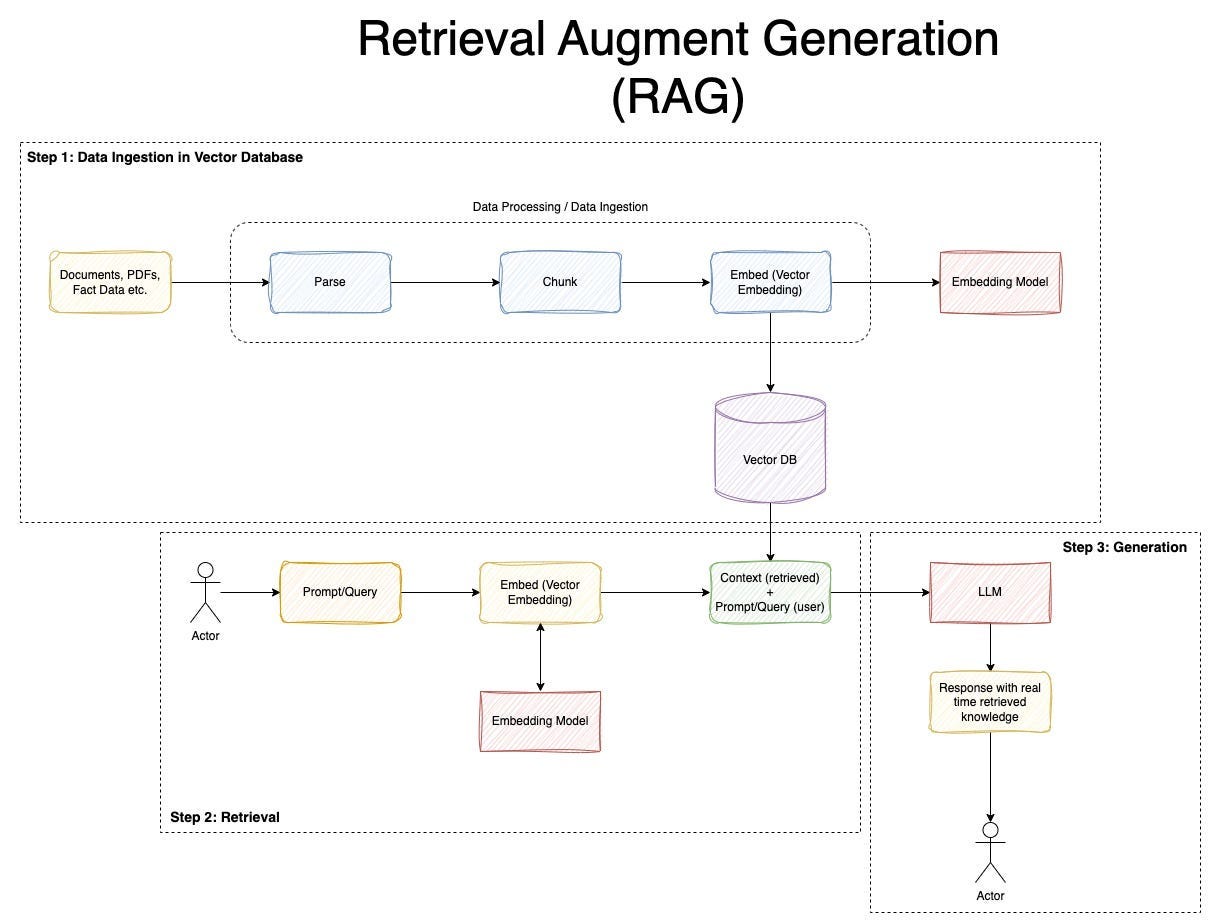
📊 How RAG works: a detailed pipeline
A typical RAG pipeline consists of several stages:
- 🎯 User Query: The user enters a query, for example, "What are the new features in iOS 19 in 2025?".
- 🔢 Embedding: The query is converted into a vector representation using models like OpenAI's text-embedding-ada-002 to find semantic similarity.
- 🔍 Retrieval: Search in a vector database (e.g., Pinecone, FAISS, or Weaviate) where indexed chunks of web pages are stored. This may include real-time crawling via tools like Firecrawl.
- ➕ Augmentation: Extracted data is added to the LLM prompt as context.
- 🤖 Generation: The LLM generates an answer with source citations, reducing errors.
💡 Example: In Perplexity AI, RAG uses its own crawler to extract fresh data from the web, allowing it to answer current questions, such as "Election Results 2025", without updating the model. In ChatGPT Search, RAG integrates with Bing for search, adding citations for transparency.
📊 Comparison of Traditional Crawling with RAG-oriented Crawling
To better understand the shift, let's look at the key differences in a table format:
| Aspect | Traditional Crawling (e.g., Googlebot) | RAG-oriented Crawling (e.g., GPTBot, PerplexityBot) |
|---|
| Goal | Collecting pages for static indexing and link ranking | Dynamic search for semantic chunks for real-time retrieval and answer generation |
| Technologies | Keywords, PageRank, robots.txt | Vector embeddings, semantic search, vector DBs |
| Impact on websites | Increased traffic through link clicks | Reduced zero-click (AI generates answer), but increased citations; increased bot load |
| Example 2025 | Google Search ranks sites by keywords | Google AI Overviews extracts data from the index for RAG generation, adding live data |
✅ Result: AI search becomes more accurate, but requires webmasters to optimize for semantic retrieval. 🚀 In 2025, RAG became the foundation for systems like Google AI Overviews, Perplexity, and ChatGPT Search, transforming crawling into a tool for "intelligent" search. 🔮 However, as experts note, RAG can evolve into "search-first agents" or MCP (Multi-Context Processing) for even better scalability. 💡 This makes it an ideal complement to the topics of AI crawling, zero-click, and content monetization in the 2025–2026 era.
🔍 RAG in Search Engines: From Google to ChatGPT Search
🧠 "RAG allows AI not just to remember, but to actively seek out fresh information." — from OpenAI updates, 2025
🚀 In 2025, Retrieval-Augmented Generation (RAG) became the foundation for all leading AI search systems, transforming traditional search into generative search, where answers are synthesized in real-time from current sources. 🔄 Instead of simply providing links, these systems use RAG to extract relevant data (retrieval) from web indexes or specialized databases, and then generate answers with citations, reducing hallucinations and increasing accuracy. 🤖 This is an evolution from static search to dynamic search, where AI bots actively crawl the web not only for model training, but also for real-time retrieval during each query.
🏆 Key players such as Google, Perplexity, and ChatGPT Search have integrated RAG into their architectures, making search more contextual and personalized. 💡 For example, in 2025, RAG helped overcome LLM limitations, allowing systems to process fresh data without constant retraining, which is critical for the rapidly changing web.
📊 RAG Implementations in Key Systems
Let's consider how RAG is implemented in the main AI search engines of 2025:
- ✅ Google AI Overviews: Google uses RAG for retrieval from its own massive index (including Vertex AI RAG Engine), where data is extracted via semantic search and then augmented into the prompt for generating answers with source citations. This allows Overviews to provide synthesized answers to complex queries, such as "EV market analysis in 2025", by extracting real-time data from reliable sites. In 2025, Google updated RAG for better processing of multimodal data (text + images), reducing latency by 30%.
- ✅ Perplexity AI: Perplexity developed its own crawler (PerplexityBot), integrated with RAG for real-time retrieval, focusing on accuracy and multimodality. The system combines hybrid retrieval (keywords + vectors) with generation, allowing it to answer questions with citations from top sources. In 2025, the Perplexity Search API became popular for developers, offering RAG customization for agents, but with challenges in crawling control (e.g., accusations of stealth scraping).
- ✅ ChatGPT Search: OpenAI integrated RAG with Bing (from Microsoft), where retrieval occurs via the Bing index, and then data is augmented to generate answers with links. This allows ChatGPT to provide current answers, such as to 2025 news, without updating the base model. In 2025, updates made RAG more effective for long contexts, but reliance on Bing raises questions of ethics and biases.
📊 Comparison of RAG Implementations in Search Engines
To better understand the differences, here is a comparison table:
| System | Retrieval Source | Key Features 2025 | Impact on Crawling |
|---|
| Google AI Overviews | Own index + Vertex AI | Multimodal RAG, reduced latency | Increased semantic crawling by Googlebot |
| Perplexity AI | Own crawler + hybrid retrieval | Real-time API for agents, focus on accuracy | Active crawling by PerplexityBot, scraping risks |
| ChatGPT Search | Integration with Bing | Citations for transparency, news processing | Dependence on BingBot, dynamic fetching |
⚡ I am confident that AI bots (GPTBot, ClaudeBot, PerplexityBot, etc.) actively crawl the web not for training, but for dynamic retrieval, increasing the load on websites, but also opening up opportunities for SEO optimization for citations. 🔄 In 2025, such RAG integration makes search "agentic", where systems independently refine queries.
RAG-crawling Challenges: Data Freshness, Scalability, and Ethics
"Without fresh data, RAG is just a beautiful hallucination." — 2025 trend
In my experience, RAG-crawling, despite its advantages, faces significant challenges in 2025, especially in the context of the rapidly changing web. These issues affect system effectiveness — from data freshness to ethical aspects — and require innovative solutions, such as specialized tools or regulations. For example, without proper management, RAG can lead to residual hallucinations when retrieved data is outdated or biased.
📊 Key Problems and Their Consequences
- ✅ Data Freshness: Web content changes every second (news, updates), so real-time crawling is critical but difficult to implement. Without it, RAG relies on outdated indexes, leading to inaccuracies. In 2025, solutions include hybrid systems with frequent re-indexing, but this increases costs.
- ✅ Scalability: Millions of requests from AI bots create a load on website servers and vector databases (like Pinecone). Retrieval latency can reach seconds, which is unacceptable for users. Problems include computational costs and processing large volumes of data; in 2025, optimization through distributed systems (e.g., in Azure AI Search) becomes standard.
- ✅ Ethics and Regulations: GDPR, EU AI Act 2025 prohibit uncontrolled scraping, risking fines for privacy violations or data bias. Ethical issues include disinformation if sources are unreliable, and abuse (like bot spoofing). Companies face challenges in ensuring transparency and consent.
📊 Solutions and Recommendations
⚖️ Solutions: Tools like Firecrawl (for ethical crawling of JS sites) or Cloudflare PayPerCrawl allow controlling access and monetizing traffic from AI bots, turning challenges into opportunities. 🤝 In 2025, companies are implementing "ethical RAG" with source verification and privacy-by-design. 🧪 For example, system prototypes focus on domain-specific QA, where challenges are smaller. 🔮 The future lies in hybrid approaches where RAG is combined with agents for self-correction.
📖 Read more about controlling and monetizing AI traffic in the article:
💰 Cloudflare's Pay-per-Crawl in 2025–2026: Is it worth selling your content to AI bots?
SEO Optimization for RAG: How to Become a Source for AI Answers
🚀 In 2025, SEO evolves into "Retrieval-Augmented Optimization" (RAO) or Answer Engine Optimization (AEO), where the focus is on content being easily retrieved by RAG systems to generate answers. 📉 Traditional links take a back seat, and citations in AI Overviews become the key to traffic. ⚙️ Optimization includes structuring data for semantic retrieval, ensuring your site becomes a " provides the basis for up-to-date information" source for LLMs.
📖 Read more about how to adapt your content for the new AI search in the article: 🧭 GEO: How to get into ChatGPT, Gemini, and Perplexity recommendations.
📊 Practical Tips for Optimization
- ✅ E-E-A-T and Structure: 📈 Enhance Expertise, Experience, Authoritativeness, Trustworthiness through clear headings, Schema.org, and JSON-LD for easy parsing by bots. 🧠 This makes content semantically rich, increasing the chances of retrieval in RAG.
- ✅ Chunks in the First Paragraphs: 🎯 Place key facts and answers at the beginning of the page (similar to featured snippets) so AI bots can quickly extract relevant parts for vector search.
- ✅ Testing: 🔍 Use tools like Perplexity API or ChatGPT Search to check if your site is cited in answers. 📊 Monitor AI citation data through Google Search Console.
📖 Understanding the basics of E-E-A-T is critically important for the new AI search. Read the detailed guide in the article: 🛡️ What is E-E-A-T in SEO: How Expertise, Experience, and Trust Influence Google Rankings.
📊 Case Studies and Results
I see that sites with good structure get a 20–30% increase in citations (Search Console 2025 data). For example, those who use RAG optimization, such as GraphRAG for complex queries, receive more traffic from AI answers. In 2025, I am focusing on personalized content and real-time updates, and for me, SEO becomes an integral part of the RAG ecosystem.
The Future of RAG: Agentic Versions, Graph RAG, and Content Monetization
In 2025–2026, Retrieval-Augmented Generation (RAG) will evolve from simple retrieval to intelligent autonomous systems. Traditional RAG already handles data extraction well, but the future lies in hybrid approaches where AI becomes "agentic": planning steps, verifying information, and adapting in real time. This allows for processing complex multi-hop queries, reducing errors, and integrating with regulations like the EU AI Act. Analysts predict that by 2026, 60% of enterprise AI deployments will include agentic systems, making RAG a foundation for agents in business, finance, and manufacturing.
📊 Key Trends in the Future of RAG
- ✅ Agentic RAG: Agents autonomously scan data, refine queries, plan multi-steps, and verify sources. Instead of a fixed pipeline, autonomous agents (based on frameworks like LangGraph or AutoGen) adapt to complex tasks — for example, compliance analysis or supply chains. In 2025, simple agentic workflows are gaining momentum, while complex ones are being prepared for 2026–2027. This eliminates the limitations of traditional RAG, adding reasoning and self-correction.
- ✅ Graph RAG: Microsoft's development (GraphRAG and LazyGraphRAG) uses knowledge graphs for global queries — topics, relationships, and summaries across the entire dataset. Graphs enable multi-hop reasoning (e.g., "What are the consequences of event X for Y?"), where vector search is weak. In 2025, GraphRAG is integrated into Azure and Microsoft Discovery for scientific and enterprise applications, ensuring traceability and reducing hallucinations.
- ✅ Content Monetization: Cloudflare PayPerCrawl (launched in 2025) allows website owners to charge AI bots for each crawl (micro-payments). This turns crawling into revenue: sites set a price, Cloudflare processes payments and blocks non-payers. Read more about this in the article Cloudflare's PayPerCrawl in 2025–2026: Is it worth selling your content to AI bots?. This is an effective response to mass scraping, making the web more resilient.
📊 Forecasts for 2026
Forecast for 2026: RAG, taking into account regulations (GDPR, EU AI Act), will become standard, with a focus on ethics, multimodal data (text + images/audio), and edge deployment. "Opt-in" sites (like PayPerCrawl) will benefit, gaining revenue and control. The combination of Agentic and Graph RAG will transform AI into a true "collaborator," not just a tool — from automating routine tasks to strategic decisions.
Case Studies and Tools: How to Implement RAG for Your Website
"From my own experience, I can advise: don't wait — test RAG on your content today."
- ✅ Perplexity AI: Proprietary index + RAG based on Vespa.ai for real-time answers with citations. Perplexity processes millions of queries, combining its own crawler with hybrid retrieval (vectors + keywords). In 2025, this became the standard for accurate AI search, with a focus on transparency and data freshness.
📊 Implementation Checklist for Your Website
- ✅ Add Schema.org and JSON-LD for better parsing by bots.
- ✅ Monitor AI bots via Cloudflare or logs, block/monetize with PayPerCrawl.
- ✅ Test: index your site in Pinecone via LangChain + Firecrawl, query via Perplexity/ChatGPT.
- ✅ Consider PayPerCrawl for monetization (details in this article).
❓ Frequently Asked Questions (FAQ)
📊 Does RAG reduce organic website traffic?
🟢 Short answer: No, on the contrary — RAG often brings back traffic thanks to source citations with links.
📈 In traditional search, zero-click searches (like AI Overviews) could "kill" clicks by generating an answer without visiting the website. However, modern RAG systems (Google AI Overviews, Perplexity, ChatGPT Search) in 2025 will definitely add citations with active links to sources. 🔗 This means that if your content is retrieved and cited, users often click on the links for more detailed reading or verification. 📊 Studies show that websites with high E-E-A-T and structured data receive additional traffic from AI answers (a 10–30% increase in some niches according to Search Console 2025 data). 🎯 The main thing is to optimize your content so that it is more frequently included in retrieval.
🔐 How to control AI bot access to my content?
🛡️ Short answer: Via robots.txt, Cloudflare, or special tools like PayPerCrawl.
🤖 AI bots (GPTBot, ClaudeBot, PerplexityBot, etc.) respect standard robots.txt directives — you can block individual bots or the entire site (e.g., Disallow: / for GPTBot). ⚙️ In 2025, Cloudflare offers advanced tools: blocking, caching, or PayPerCrawl for monetization. 🔗 Read more about this in the article 💰 Cloudflare's PayPerCrawl in 2025–2026: Is it worth selling your content to AI bots?. 📊 I also recommend monitoring logs and using AI Bot Management in Cloudflare — this allows you to permit only "good" bots or charge for crawling.
💸 Is it worth monetizing content for AI bots via PayPerCrawl?
🤔 Short answer: Yes, if you have quality content — it's a new revenue stream without traffic loss.
💎 Cloudflare PayPerCrawl (2025) allows you to set a price for each crawl by AI bots: micropayments for access to your content for RAG. 🎯 This is ideal for sites with unique data (blogs, research, news). ✅ Advantages: additional income (especially with mass crawling), control over usage, no need to block bots completely. ⚠️ Disadvantages: setup and potential reduction in citations if bots bypass it. 📖 Detailed analysis and recommendations — in my article 💰 Cloudflare's PayPerCrawl in 2025–2026: Is it worth selling your content to AI bots?. 🚀 If your site is frequently cited in AI answers — it's definitely worth trying.
🧩 What is the difference between Classic RAG, Graph RAG, and Agentic RAG?
🔄 Short answer: Classic — simple retrieval, Graph — for complex relationships, Agentic — autonomous agents with planning.
📄 Classic RAG: a basic pipeline — extracts chunks from a vector database and generates a response. Suitable for simple queries.
🧠 Graph RAG (from Microsoft): uses knowledge graphs for multi-hop queries (relationships between facts), ideal for complex topics (science, law).
🤖 Agentic RAG: adds autonomous agents — AI plans steps, refines queries, uses tools (crawling, verification). 🚀 In 2025–2026, this is a trend for "smart" search, like in Perplexity or future Google agents. Agentic addresses the limitations of classic RAG (e.g., inaccuracy in complex tasks) but requires more resources.
⚙️ Do I need to implement RAG on my website?
🎯 Short answer: Not necessarily a full pipeline, but optimization for RAG — yes, for better citation in AI search.
🔧 If you are a website owner — focus on SEO for RAG: Schema.org, clear blocks, E-E-A-T. 💡 This will help your content be retrieved more often in Google Overviews or Perplexity. 🚀 Full RAG implementation (your own chatbot or search) is useful for large websites: for example, internal search based on LangChain + Firecrawl. 🔬 Start with a test: index your content in Pinecone and check the answers in Perplexity. 📈 In 2025, this will increase visibility and can add traffic from AI citations.
✅ Conclusions
✅ Yes, RAG in crawling is not just a buzzword, but the real foundation of search in 2025–2026. 🧠 It makes crawling smarter (from passive page collection to active semantic retrieval), and AI answers — more accurate, with citations and links. 🎯 For us, website owners and SEO specialists, this means a new reality: whoever quickly adapts content for RAG will gain visibility, traffic, and even additional income.
📢 My main message is simple:
- 🏗️ Structure your content as if it's being read not only by a human but also by a vector database.
- 🛡️ Don't be afraid of AI bots — manage them via robots.txt, Cloudflare, and PayPerCrawl.
- 🔍 Test how your site appears in Perplexity, ChatGPT Search, and Google AI Overviews today.
- 💰 Consider monetizing crawling as a new revenue stream, not a threat.
🧱 This article is a logical continuation and, at the same time, the "capstone" of my extensive series on how artificial intelligence is completely reshaping the search ecosystem. 🌍 If you haven't read the previous materials yet — I highly recommend going through the entire journey with me:
If the article was useful — ❤️ share it with colleagues.
See you in the next materials — much more interesting content ahead in 2026! 🚀
🌟 Sincerely
Vadym Kharoviuk
☕ Java Developer, Founder of WebCraft Studio
