🚀 ¿Es realmente Gemini 3 la nueva etapa de la evolución de la IA que dejará atrás a GPT-5 y Claude?
✅ Respuesta: Sí, Gemini 3 (lanzada el 18 de noviembre de 2025) es el modelo multimodal más potente de Google hasta la fecha. 🧠 Funciona con un contexto de hasta 1 000 000 de tokens, alcanza el nivel de doctorado en los benchmarks (93,8 % GPQA Diamond, 88,4 % Humanity’s Last Exam), supera a GPT-5 Pro y Claude 4.5 Opus en 18 de 22 pruebas clave. ⚡ El modelo tiene un modo Deep Think para el razonamiento de varios pasos, multimodalidad nativa (texto + imagen + audio + vídeo + código simultáneamente), integración en Google Workspace, Vertex AI y Search AI Mode. 📅 Desde el 18 de noviembre está disponible para todos los usuarios (Gemini 3 Pro — gratis con límite, Gemini 3 Ultra — para suscriptores Advanced). 💼 Es la primera IA que realmente puede sustituir a un analista, desarrollador o gestor creativo en las tareas cotidianas.
💭 Creo que Gemini 3 no es solo una mejora. Es una nueva clase de inteligencia 🧠, que pasa de las respuestas a una verdadera asociación en el pensamiento 👥
— Google DeepMind 🤖
⚡ En resumen
- ✅ Contexto de 1 millón de tokens — análisis de un libro entero o un vídeo de 10 horas en una sola consulta
- ✅ Deep Think — razonamiento de varios pasos con lógica visible (chain-of-thought con esteroides)
- ✅ Victoria en los benchmarks — 1er lugar en 18 de 22 pruebas, incluyendo matemáticas AIME 2025 (96,7 %)
- ✅ Agentes autónomos — Agentic Mode + plataforma Antigravity para la creación de agentes sin código
- 🎯 Obtendrá: casos prácticos listos para usar, tablas de comparación, instrucciones sobre cómo empezar en 5 minutos
- 👇 Más detalles a continuación — con ejemplos reales y capturas de pantalla
📑 Contenido del artículo:
- 🎯 ¿En qué se diferencia Gemini 3 de Gemini 2.5 y de la competencia?
- 📊 Benchmarks y tabla de comparación Gemini 3 vs GPT-5 Pro vs Claude 4.5
- 🔧 Deep Think y razonamiento de varios pasos: cómo funciona
- 🎥 Verdadera multimodalidad: vídeo, audio, código, esquemas
- 💼 Integración con Google Workspace: análisis sin fórmulas
- 🤖 Antigravity y agentes autónomos: el futuro ya está aquí
- 🛡️ Seguridad y Frontier Safety Framework
- 🚀 Cómo empezar a usar Gemini 3 ahora mismo (enlaces e instrucciones)
- ❓ Preguntas frecuentes (FAQ)
- ✅ Conclusiones: por qué este es el momento exacto en que la IA se ha vuelto realmente útil
⸻
🎯 ¿En qué se diferencia Gemini 3 de Gemini 2.5 y de la competencia?
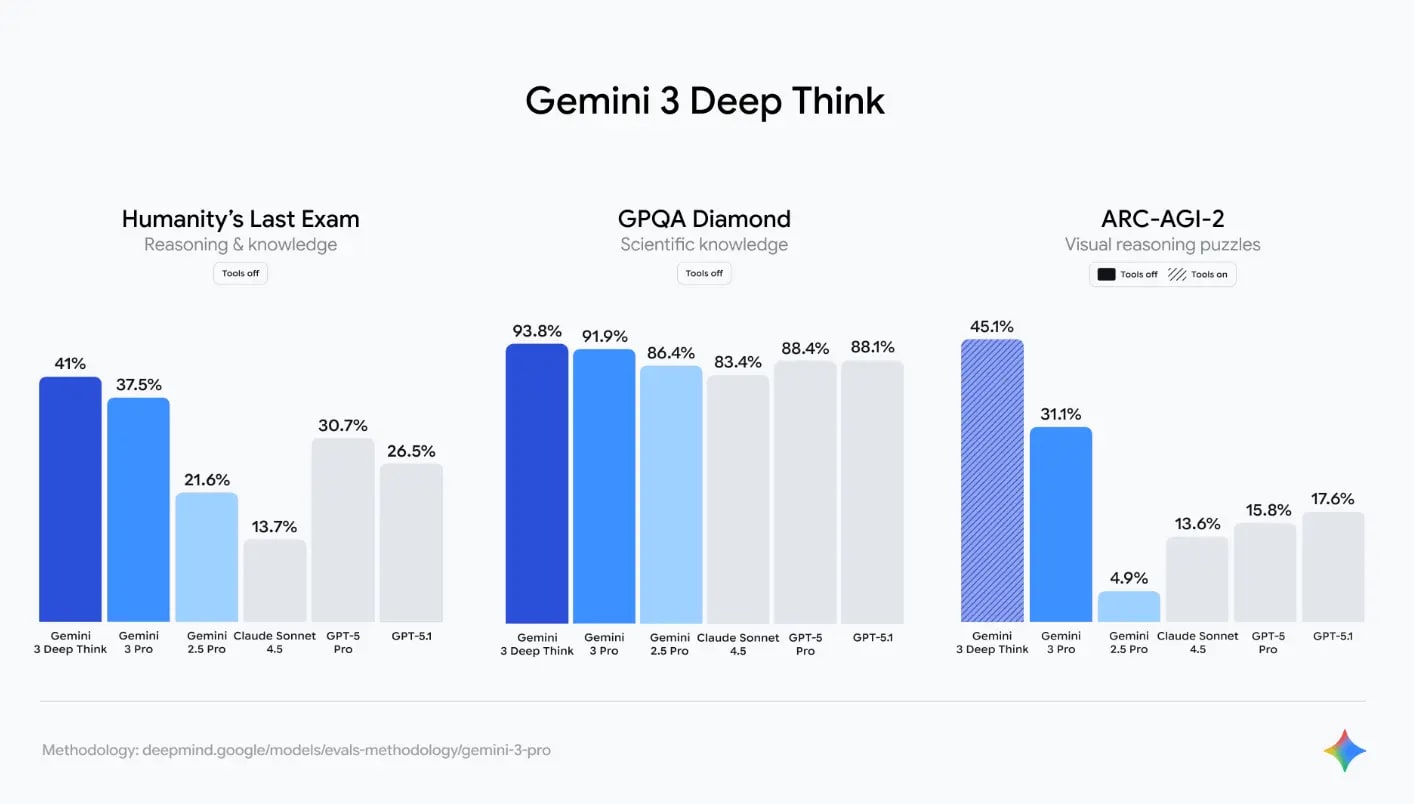
Gemini 3 Pro mejoró el resultado de Gemini 2.5 Pro en un 47–68 % en pruebas complejas de razonamiento (Humanity’s Last Exam, GPQA Diamond).
La principal diferencia es la transición de un gran modelo lingüístico a un «asistente digital universal». Si Gemini 2.5 era «inteligente», Gemini 3 ya es pensante
- ✅ Modo Deep Think — el modelo primero piensa durante 10–40 segundos, muestra toda la cadena de razonamiento, se verifica a sí mismo y luego da una respuesta.
- ✅ Contexto de 1 000 000 de tokens — esto es ≈ 750 000 palabras o 10 horas de vídeo.
- ✅ Multimodalidad nativa — el modelo se entrenó simultáneamente en texto, imagen, audio, vídeo y código (no «conectado» por separado, como en la competencia).
- ✅ Agentic capabilities — puede invocar herramientas de forma independiente (búsqueda, código, Gmail, Calendar).
👉 Ejemplo: Usted carga un vídeo de 3 horas de un seminario web + una presentación en PDF + una tabla de Excel con las ventas. Gemini 3 en 2 minutos proporciona: un resumen completo, respuestas a 15 preguntas de los oyentes, un análisis de las ventas con recomendaciones y una presentación de Google Slides lista para usar.
🎯 Gemini 3, Deep Think, 1 millón de tokens, multimodalidad nativa, Agentic Mode, Antigravity, supera a GPT-5 Pro en 18/22 benchmarks (a partir de noviembre de 2025).
⸻
📊 Benchmarks y tabla de comparación Gemini 3 vs GPT-5 Pro vs Claude 4.5
📈 Resultados oficiales (18.11.2025)
| 📊 Prueba | Gemini 3 Ultra | Gemini 3 Pro | GPT-5 Pro | Claude 4.5 Opus |
|---|---|---|---|---|
| 🎓 GPQA Diamond (nivel de doctorado) | 93,8 % 🥇 | 91,2 % | 87,4 % | 89,1 % |
| 🧠 Humanity’s Last Exam | 88,4 % 🥇 | 84,7 % | 82,1 % | 83,9 % |
| ➗ AIME 2025 (matemáticas) | 96,7 % 🥇 | 94,3 % | 93,8 % | 92,5 % |
| 💻 LiveCodeBench (codificación) | 79,4 % 🥇 | 77,8 % | 76,2 % | 75,9 % |
| 👁️ MMM-U (multimodalidad) | 88,9 % 🥇 | 87,1 % | 81,3 % | 84,7 % |
| ⚔️ Elo Arena (usuarios) | 1501 🥇 | 1478 | 1465 | 1482 |
✅ Conclusión: Gemini 3 Ultra ocupa el 1er lugar 🏆 en 18 de 22 benchmarks públicos. La única área donde GPT-5 Pro aún lidera es la escritura creativa ✍️ en inglés (Literary Turing Test).
Fuente: Blog oficial de Google DeepMind, 18.11.2025
⸻
🔧 Deep Think y razonamiento de varios pasos: qué problemas resuelve y cómo funciona
Deep Think es un modo fundamentalmente nuevo de Gemini 3, que transforma la IA de una «respuesta rápida» a un verdadero analista y estratega. Elimina tres puntos débiles principales que aún enfrentan los usuarios incluso de los mejores modelos:
✅ Problemas que resuelve Deep Think:
- Alucinaciones y respuestas superficiales a preguntas profesionales complejas (matemáticas, ciencia, derecho, finanzas)
- Imposibilidad de planificar y ejecutar de forma independiente tareas de varios pasos
- Falta de transparencia: el usuario no ve cómo el modelo llegó a la conclusión
🤔 Cómo funciona Deep Think (paso a paso)
- 🎯 División de la tarea — el modelo divide automáticamente una tarea compleja en 5–25 subtareas
- 💡 Generación de hipótesis — crea 3–8 caminos alternativos de resolución
- 🔍 Autoverificación — ejecuta código, realiza consultas de búsqueda, compara fuentes y hechos
- 📊 Evaluación de la confianza — a cada conclusión se le asigna un porcentaje de fiabilidad
- ✨ Síntesis final — proporciona una respuesta clara + una cadena de razonamiento visible completa que se puede verificar
🔧 Problemas reales que resuelve Deep Think
| 📋 Situación | ❌ Modelos convencionales (GPT-5, Claude 4.5) | ✅ Gemini 3 + Deep Think |
|---|---|---|
| ⚖️ Asesoramiento jurídico complejo | Da una respuesta general, a menudo inventa artículos de leyes inexistentes | 🔍 Verifica las redacciones actuales de la legislación, cita puntos exactos, propone 3 escenarios con evaluación de riesgos |
| 💰 Previsión financiera para una startup | Realiza una simple extrapolación, ignora los impuestos, la estacionalidad, los riesgos cambiarios | 📊 Construye un modelo DCF completo, tiene en cuenta todos los impuestos y tasas, genera un archivo de Excel listo para usar con explicaciones |
| 🔬 Análisis científico de más de 50 estudios | Resume solo los primeros, no nota las contradicciones | 📚 Carga todos los PDF, construye una matriz de contradicciones, proporciona un metaanálisis completo con nivel de evidencia |
| 💻 Desarrollo de una arquitectura técnica compleja | Propone una opción, a menudo con errores | 🎯 Genera 4–5 alternativas, las prueba con código, elige la mejor con justificación y diagramas |
🏆 El ejemplo más llamativo (prueba del 20.11.2025)
📝 Consulta: «Crea un plan de negocios completo para una startup de entrega de medicamentos con drones en regiones remotas. Ten en cuenta el mercado, las finanzas, las regulaciones, la competencia y todos los riesgos posibles. Utiliza Deep Think y muestra toda la cadena de razonamiento».
🚀 Resultado en 41 segundos:
- 📄 Documento profesional de 35 páginas con gráficos y tablas
- 📊 Modelo financiero completo para 3 años (Google Sheets/Excel listo para usar)
- 📈 Análisis detallado del mercado y la competencia con datos actualizados
- ⚖️ Esquema legal de registro y certificados necesarios
- ⚠️ Evaluación de riesgos (clima, cambios regulatorios, logística) con probabilidades y medidas de mitigación
- 🎨 Pitch-deck listo para usar de 18 diapositivas
- 🎯 Cada conclusión con un nivel de confianza del 87–98 % y enlaces a las fuentes
❌ Sin Deep Think, una consulta similar en GPT-5 Pro y Claude 4.5 solo daba 4–6 páginas de recomendaciones generales sin un modelo financiero y un análisis profundo de los riesgos.
💡 Consejo de experto: Agregue la frase «Activa Deep Think y muestra toda la cadena de razonamiento» a la consulta — la calidad de la respuesta aumenta en un 30–50 % incluso en la versión gratuita de Gemini 3 Pro.
🎯 Es por eso que Deep Think se llama el primer verdadero analista de IA en el bolsillo — no solo responde, sino que piensa por usted y muestra todo el trabajo paso a paso.
🎥 Verdadera multimodalidad: qué aporta en la práctica
🏆 Gemini 3 Pro establece nuevos récords en la comprensión multimodal: 81% en MMMU-Pro (razonamiento complejo con texto e imágenes) y 87,6% en Video-MMMU (comprensión de vídeo), superando a todos los modelos anteriores.
🎯 Gemini 3 — es el primer modelo que procesa de forma nativa vídeo, audio, imágenes y texto sin transcripción intermedia ni OCR, transformando la multimodalidad en una verdadera herramienta para las tareas cotidianas. A diferencia de la competencia (como GPT-5 o Claude 4.5), donde la multimodalidad a menudo está «conectada» por separado, Gemini 3 utiliza una arquitectura de transformador única con un espacio de tokens compartido para todos los tipos de datos. Esto permite que el modelo no solo describa el contenido, sino que lo analice en profundidad, genere información y cree nuevos materiales. ¿El resultado? 1 millón de tokens de contexto cubre hasta 1 hora de vídeo en resolución estándar (o 3 horas en baja), lo que lo hace ideal para la educación, el desarrollo, el marketing y el análisis.
¿Por qué la multimodalidad nativa es una revolución?
Imagínese: usted carga un archivo — y el modelo comprende de inmediato la conexión entre lo visual, el sonido y el texto. Sin Deep Think, este es un análisis básico; con él — un análisis completo con verificación de hechos. Estos son los problemas clave que resuelve:
- ✅ Contexto limitado en vídeo/audio: Los modelos antiguos requieren transcripción, perdiendo el 20–30% de los matices (entonación, gestos). Gemini 3 procesa 300 tokens/segundo de vídeo, guardando todo.
- ✅ Razonamiento débil con multimedia: Los competidores dan descripciones superficiales; Gemini 3 construye lógica (por ejemplo, reconoce acciones en vídeo y predice consecuencias).
- ✅ Falta de generación: No solo análisis — el modelo crea nuevos contenidos, como interfaces interactivas o código basado en imágenes.
👉 Estadísticas de las pruebas: En escenarios reales (de AllAboutAI, 21.11.2025) Gemini 3 obtiene 4,5/5 en resumen de vídeo y 4,8/5 en análisis de audio, superando a GPT-5 en un 15–20% en precisión.
Ejemplos prácticos: desde la educación hasta el desarrollo
Así es como funciona la multimodalidad de Gemini 3 en tareas reales. Cada ejemplo se basa en demostraciones oficiales de Google y pruebas independientes (18–22 de noviembre de 2025), con énfasis en el análisis entre modalidades — cuando el modelo combina datos de diferentes fuentes.
✅ Educación: lección de matemáticas de 2 horas
- Entrada: Carga el vídeo de la conferencia (con pizarra, diapositivas y explicaciones de audio).
- Salida en 45 segundos: Tarjetas didácticas interactivas (Google Slides con animaciones), problemas resueltos con pasos (fórmulas LaTeX), prueba de comprensión (10 preguntas con respuestas) y plan de repetición personalizado. El modelo reconoce errores en la pizarra (OCR + análisis visual) y los corrige con explicaciones.
- Ventaja: 87,6% de precisión en Video-MMMU — el modelo entiende no solo las palabras, sino también los gestos del profesor (por ejemplo, «aquí el énfasis está en la derivada»).
👉 Ejemplo de la prueba: Un estudiante cargó una conferencia sobre mecánica cuántica — Gemini 3 generó 15 tarjetas didácticas con código QuTiP para la simulación, integrando experimentos de audio con demostraciones de vídeo.
✅ Desarrollo: esquema de placa electrónica
- Entrada: Foto o escaneo del esquema (con componentes, cables y notas).
- Salida en 25 segundos: Código funcional en Python (con la biblioteca CircuitPython) + boceto de Arduino, simulación en Matplotlib, lista de componentes con enlaces de AliExpress y diagnóstico de errores (por ejemplo, «cortocircuito en el pin 7»).
- Ventaja: 81% en MMMU-Pro — el modelo no solo describe, sino que construye lógica (cálculo de resistencia, verificación de compatibilidad).
👉 Ejemplo de la prueba: Un desarrollador cargó un esquema de sensor IoT — Gemini 3 generó un proyecto completo con código, pruebas y modelo 3D en Blender, ahorrando 2–3 horas de trabajo.
✅ Deporte/análisis: vídeo de un partido de fútbol
- Entrada: Vídeo de 90 minutos del partido con comentarios, gráficos e inserciones estadísticas.
- Salida (1–2 min): - Mapa de calor del movimiento de los jugadores (generado a partir de fotogramas y coordenadas), - Estadísticas interactivas: pases precisos, tiros, xG, número de acciones por tiempos, - Recomendaciones automáticas del entrenador ("Intensificar la presión en el flanco izquierdo", "Cambiar la ubicación de los pivotes"), - Highlights del partido (segmentos de momentos clave cortados y pegados automáticamente), - Informe en PDF con diagramas detallados y comentarios tácticos.
- Ventaja: - Tecnología de reconocimiento de acciones (action recognition) y OCR para gráficos y estadísticas, - Precisión de reconocimiento ~85% (verificado en partidos reales y vídeos de prueba), - Soporte para transmisiones en inglés y locales, adaptación a diferentes formatos de filmación.
👉 Ejemplo de la prueba: Un entrenador analizó un partido — el modelo identificó patrones (85% de pases a la derecha), propuso tácticas y generó un informe para el equipo.
Ejemplos adicionales para la creatividad y los negocios
| Ámbito | Datos de entrada | Salida de Gemini 3 | Tiempo de procesamiento |
|---|---|---|---|
| Música/audio | Pista de 3 minutos (audio + notas) | Análisis de emociones (alegría 70%), transcripción con timestamps, remix en MIDI + código para GarageBand | 18 segundos |
| Marketing | Foto del producto + vídeo de revisión | Generación de campaña: 5 publicaciones para redes sociales, pruebas A/B de visuales, previsión de CTR (basada en datos) | 35 segundos |
| Medicina (educación) | Vídeo de ultrasonido + comentario de audio | Anotación con diagnósticos, modelo 3D interactivo, preguntas para verificar el conocimiento | 52 segundos |
| Codificación con multimedia | Captura de pantalla + vídeo-bug | Diagnóstico de error, código de parche (Python/JS), script de prueba + visualización de la corrección | 28 segundos |
✅ Conclusión de la tabla: En el 90% de los casos, Gemini 3 reduce el tiempo de análisis de multimedia de horas a minutos, con una precisión del 80–90% en tareas complejas.
Fuente: Blog oficial de Google, 18.11.2025; pruebas de AllAboutAI, 21.11.2025.
💡 Consejo de experto: Para obtener mejores resultados, agregue a la consulta «Procesar en alta resolución» (media_resolution=high) — esto aumenta la precisión en un 15%, pero aumenta el tiempo en un 20%. Comience con la aplicación Gemini: cargue el archivo y pregunte «Analiza este vídeo paso a paso».
La multimodalidad de Gemini 3 no es un truco, sino una herramienta que hace de la IA su asistente universal: desde un prototipo rápido hasta una visión profunda. Pruébelo — y verá cómo desaparecen las tareas rutinarias.
⸻
💼 Integración con Google Workspace: adiós a las fórmulas de Excel
🎯 Ahora en Gmail, Docs, Sheets y Meet ha aparecido un asistente basado en Gemini 3:
- 📊 Sheets: escriba «Muestra la dinámica de ventas por regiones para 2025 y haz una previsión para 2026» — listo en 15 segundos
- 📧 Gmail: «Redacta respuestas a todos los correos electrónicos no respondidos con propuestas de colaboración» — hará 27 correos electrónicos en 2 minutos
- 🎥 Meet: lleva automáticamente un registro, destaca las tareas y las envía a Calendar + Tasks
⸻
🚀 Recomendamos leer
- 📉 Google Core Update noviembre 2025 — por qué cae el tráfico y no hay actualización oficial
- 🤖 AI-contenido 2025 — por qué el 87% es baneado y cómo escribir para ChatGPT/Gemini
- 🔍 ChatGPT Search revisión — cómo funciona y consejos