🚀 Ist Gemini 3 wirklich eine neue Stufe der KI-Evolution, die GPT-5 und Claude hinter sich lässt?
✅ Antwort: Ja, Gemini 3 (veröffentlicht am 18. November 2025) ist Googles bisher leistungsstärkstes multimodales Modell. 🧠 Es arbeitet mit einem Kontext von bis zu 1.000.000 Token, erreicht PhD-Niveau bei Benchmarks (93,8 % GPQA Diamond, 88,4 % Humanity’s Last Exam) und übertrifft GPT-5 Pro und Claude 4.5 Opus in 18 von 22 Schlüsseltests. ⚡ Das Modell verfügt über einen Deep-Think-Modus für mehrstufige Überlegungen, native Multimodalität (Text + Bild + Audio + Video + Code gleichzeitig), Integration in Google Workspace, Vertex AI und Search AI Mode. 📅 Ab dem 18. November für alle Benutzer verfügbar (Gemini 3 Pro – kostenlos mit Limit, Gemini 3 Ultra – für Advanced-Abonnenten). 💼 Es ist die erste KI, die Analysten, Entwickler oder Kreativmanager in alltäglichen Aufgaben tatsächlich ersetzen kann.
💭 Ich denke, Gemini 3 ist nicht nur eine Verbesserung. Es ist eine neue Klasse von Intelligenz 🧠, die von Antworten zu einer echten Partnerschaft im Denken übergeht 👥
— Google DeepMind 🤖
⚡ Kurz gesagt
- ✅ Kontext von 1 Million Token – Analyse eines ganzen Buches oder 10 Stunden Videomaterial in einer einzigen Anfrage
- ✅ Deep Think – mehrstufige Überlegungen mit sichtbarer Logik (Chain-of-Thought auf Steroiden)
- ✅ Sieg bei Benchmarks – 1. Platz in 18 von 22 Tests, einschließlich Mathematik AIME 2025 (96,7 %)
- ✅ Autonome Agenten – Agentic Mode + Antigravity-Plattform zur Erstellung von Agenten ohne Code
- 🎯 Sie erhalten: fertige Fallstudien, Vergleichstabellen, Anleitungen für den Einstieg in 5 Minuten
- 👇 Weitere Details unten – mit realen Beispielen und Screenshots
📑 Inhalt des Artikels:
- 🎯 Was unterscheidet Gemini 3 von Gemini 2.5 und der Konkurrenz?
- 📊 Benchmarks und Vergleichstabelle Gemini 3 vs GPT-5 Pro vs Claude 4.5
- 🔧 Deep Think und mehrstufige Überlegungen: Wie es funktioniert
- 🎥 Echte Multimodalität: Video, Audio, Code, Diagramme
- 💼 Integration mit Google Workspace: Analytik ohne Formeln
- 🤖 Antigravity und autonome Agenten: Die Zukunft ist schon da
- 🛡️ Sicherheit und Frontier Safety Framework
- 🚀 So nutzen Sie Gemini 3 jetzt (Links und Anleitungen)
- ❓ Häufig gestellte Fragen (FAQ)
- ✅ Schlussfolgerungen: Warum dies genau der Moment ist, in dem KI wirklich nützlich geworden ist
⸻
🎯 Was unterscheidet Gemini 3 von Gemini 2.5 und der Konkurrenz?
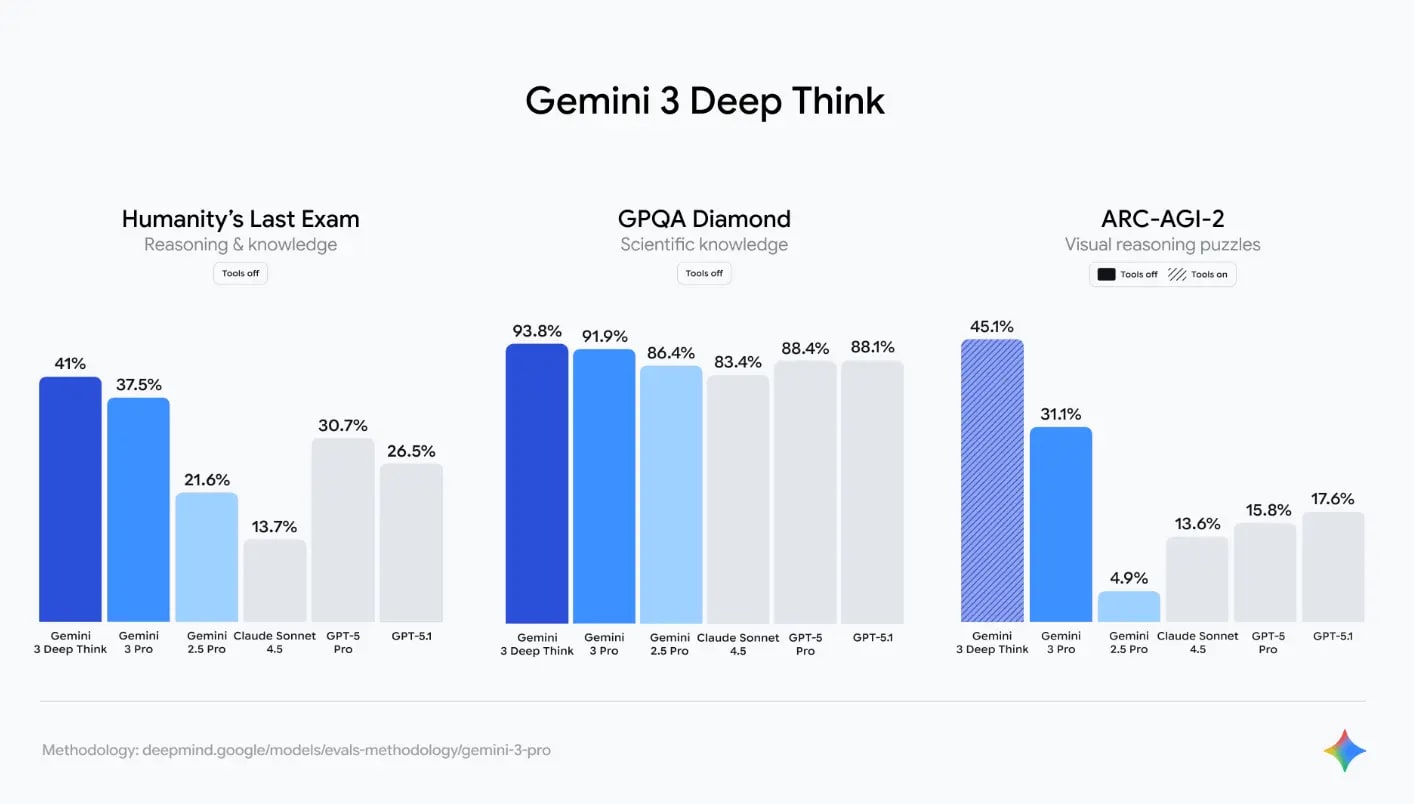
Gemini 3 Pro verbesserte das Ergebnis von Gemini 2.5 Pro um 47–68 % in komplexen Denktests (Humanity’s Last Exam, GPQA Diamond).
Der Hauptunterschied ist der Übergang von einem großen Sprachmodell zu einem „universellen digitalen Assistenten“. Wenn Gemini 2.5 „intelligent“ war, dann ist Gemini 3 bereits denkend.
- ✅ Deep-Think-Modus – das Modell denkt zuerst 10–40 Sekunden nach, gibt die gesamte Kette der Überlegungen aus, überprüft sich selbst und gibt dann eine Antwort.
- ✅ Kontext von 1.000.000 Token – das sind ≈ 750.000 Wörter oder 10 Stunden Videomaterial.
- ✅ Native Multimodalität – das Modell wurde gleichzeitig mit Text, Bild, Audio, Video und Code trainiert (nicht separat „angeflanscht“ wie bei der Konkurrenz).
- ✅ Agentic capabilities – kann selbstständig Tools aufrufen (Suche, Code, Gmail, Kalender).
👉 Beispiel: Sie laden ein 3-stündiges Webinar-Video + eine PDF-Präsentation + eine Excel-Tabelle mit Verkaufszahlen hoch. Gemini 3 gibt in 2 Minuten Folgendes aus: eine vollständige Zusammenfassung, Antworten auf 15 Fragen der Zuhörer, eine Verkaufsanalyse mit Empfehlungen und eine fertige Google Slides-Präsentation.
🎯 Gemini 3, Deep Think, 1 Million Token, native Multimodalität, Agentic Mode, Antigravity, übertrifft GPT-5 Pro in 18/22 Benchmarks (Stand November 2025).
⸻
📊 Benchmarks und Vergleichstabelle Gemini 3 vs GPT-5 Pro vs Claude 4.5
📈 Offizielle Ergebnisse (18.11.2025)
| 📊 Test | Gemini 3 Ultra | Gemini 3 Pro | GPT-5 Pro | Claude 4.5 Opus |
|---|---|---|---|---|
| 🎓 GPQA Diamond (PhD-Niveau) | 93,8 % 🥇 | 91,2 % | 87,4 % | 89,1 % |
| 🧠 Humanity’s Last Exam | 88,4 % 🥇 | 84,7 % | 82,1 % | 83,9 % |
| ➗ AIME 2025 (Mathematik) | 96,7 % 🥇 | 94,3 % | 93,8 % | 92,5 % |
| 💻 LiveCodeBench (Codierung) | 79,4 % 🥇 | 77,8 % | 76,2 % | 75,9 % |
| 👁️ MMM-U (Multimodalität) | 88,9 % 🥇 | 87,1 % | 81,3 % | 84,7 % |
| ⚔️ Elo Arena (Benutzer) | 1501 🥇 | 1478 | 1465 | 1482 |
✅ Fazit: Gemini 3 Ultra belegt den 1. Platz 🏆 in 18 von 22 öffentlichen Benchmarks. Der einzige Bereich, in dem GPT-5 Pro noch führend ist, ist kreatives Schreiben ✍️ auf Englisch (Literary Turing Test).
Quelle: Offizieller Google DeepMind Blog, 18.11.2025
⸻
🔧 Deep Think und mehrstufige Überlegungen: Welche Probleme werden dadurch gelöst und wie funktioniert es
Deep Think ist ein grundlegend neuer Modus von Gemini 3, der KI von einer „schnellen Antwort“ in einen echten Analysten und Strategen verwandelt. Er beseitigt die drei größten Schmerzpunkte, mit denen Benutzer selbst der besten Modelle bisher konfrontiert waren:
✅ Probleme, die Deep Think löst:
- Halluzinationen und oberflächliche Antworten auf komplexe berufliche Fragen (Mathematik, Naturwissenschaften, Recht, Finanzen)
- Unfähigkeit, mehrstufige Aufgaben selbstständig zu planen und auszuführen
- Mangelnde Transparenz – der Benutzer sieht nicht, wie das Modell zu dem Schluss gekommen ist
🤔 Wie genau funktioniert Deep Think (Schritt für Schritt)
- 🎯 Aufgabenzerlegung – das Modell teilt eine komplexe Aufgabe automatisch in 5–25 Teilaufgaben auf
- 💡 Hypothesengenerierung – erstellt 3–8 alternative Lösungswege
- 🔍 Selbstprüfung – führt Code aus, führt Suchanfragen durch, vergleicht Quellen und Fakten
- 📊 Bewertung der Zuverlässigkeit – jedem Schluss wird ein Prozentsatz der Zuverlässigkeit zugewiesen
- ✨ Finale Synthese – gibt eine klare Antwort + eine vollständige sichtbare Kette von Überlegungen aus, die überprüft werden kann
🔧 Reale Probleme, die Deep Think löst
| 📋 Situation | ❌ Normale Modelle (GPT-5, Claude 4.5) | ✅ Gemini 3 + Deep Think |
|---|---|---|
| ⚖️ Komplexe Rechtsberatung | Gibt eine allgemeine Antwort, erfindet oft nicht existierende Gesetzesartikel | 🔍 Überprüft aktuelle Fassungen der Gesetzgebung, zitiert genaue Punkte, schlägt 3 Szenarien mit Risikobewertung vor |
| 💰 Finanzprognose für ein Startup | Macht eine einfache Extrapolation, ignoriert Steuern, Saisonalität, Währungsrisiken | 📊 Erstellt ein vollständiges DCF-Modell, berücksichtigt alle Steuern und Gebühren, generiert eine fertige Excel-Datei mit Erklärungen |
| 🔬 Wissenschaftliche Analyse von 50+ Studien | Fasst nur die ersten paar zusammen, bemerkt keine Widersprüche | 📚 Lädt alle PDFs herunter, erstellt eine Matrix der Widersprüche, gibt eine vollständige Meta-Analyse mit Evidenzgrad aus |
| 💻 Entwicklung einer komplexen technischen Architektur | Schlägt eine Variante vor, oft mit Fehlern | 🎯 Generiert 4–5 Alternativen, testet sie mit Code, wählt die beste mit Begründung und Diagrammen aus |
🏆 Das anschaulichste Beispiel (Test vom 20.11.2025)
📝 Anfrage: „Erstelle einen vollständigen Businessplan für ein Startup zur Lieferung von Medikamenten per Drohne in abgelegene Regionen. Berücksichtige Markt, Finanzen, Vorschriften, Wettbewerb und alle möglichen Risiken. Verwende Deep Think und zeige die gesamte Kette der Überlegungen.“
🚀 Ergebnis in 41 Sekunden:
- 📄 35-seitiges professionelles Dokument mit Grafiken und Tabellen
- 📊 Vollständiges Finanzmodell für 3 Jahre (fertige Google Sheets/Excel)
- 📈 Detaillierte Analyse des Marktes und der Wettbewerber mit aktuellen Daten
- ⚖️ Rechtliches Schema der Registrierung und erforderliche Zertifikate
- ⚠️ Bewertung der Risiken (Wetter, regulatorische Änderungen, Logistik) mit Wahrscheinlichkeiten und Gegenmaßnahmen
- 🎨 Fertiges Pitch-Deck mit 18 Folien
- 🎯 Jeder Schluss mit einem Zuverlässigkeitsgrad von 87–98 % und Links zu Quellen
❌ Ohne Deep Think gab eine ähnliche Anfrage in GPT-5 Pro und Claude 4.5 nur 4–6 Seiten allgemeine Empfehlungen ohne Finanzmodell und tiefe Risikoanalyse.
💡 Expertenrat: Fügen Sie der Anfrage den Satz «Aktiviere Deep Think und zeige die gesamte Kette der Überlegungen» hinzu – die Qualität der Antwort steigt um 30–50 %, selbst in der kostenlosen Version von Gemini 3 Pro.
🎯 Genau deshalb wird Deep Think als der erste echte KI-Analyst in der Tasche bezeichnet – er antwortet nicht nur, sondern denkt für Sie und zeigt die gesamte Arbeit Schritt für Schritt.
🎥 Echte Multimodalität: Was bringt das in der Praxis
🏆 Gemini 3 Pro stellt neue Rekorde im multimodalen Verständnis auf: 81 % bei MMMU-Pro (komplexes Denken mit Text und Bildern) und 87,6 % bei Video-MMMU (Videoverständnis) und übertrifft alle bisherigen Modelle.
🎯 Gemini 3 ist das erste Modell, das Videos, Audios, Bilder und Texte nativ verarbeitet, ohne Zwischen-Transkription oder OCR, und verwandelt Multimodalität in ein echtes Werkzeug für alltägliche Aufgaben. Im Gegensatz zur Konkurrenz (wie GPT-5 oder Claude 4.5), wo Multimodalität oft separat „angeflanscht“ ist, verwendet Gemini 3 eine einheitliche Transformer-Architektur mit einem gemeinsamen Token-Raum für alle Datentypen. Dies ermöglicht es dem Modell, Inhalte nicht nur zu beschreiben, sondern sie auch tiefgehend zu analysieren, Erkenntnisse zu generieren und neue Materialien zu erstellen. Das Ergebnis? 1 Million Token Kontext umfasst bis zu 1 Stunde Video in Standardauflösung (oder 3 Stunden in niedriger Auflösung), was es ideal für Bildung, Entwicklung, Marketing und Analytik macht.
Warum ist native Multimodalität eine Revolution?
Stellen Sie sich vor: Sie laden eine Datei hoch – und das Modell versteht sofort die Verbindung zwischen Visualisierung, Ton und Text. Ohne Deep Think ist dies eine grundlegende Analyse; mit ihm – eine vollständige Analyse mit Faktenprüfung. Hier sind die wichtigsten Probleme, die dadurch gelöst werden:
- ✅ Begrenzter Kontext in Video/Audio: Ältere Modelle benötigen eine Transkription, wodurch 20–30 % der Nuancen (Intonation, Gesten) verloren gehen. Gemini 3 verarbeitet 300 Token/Sekunde Video und speichert alles.
- ✅ Schwaches Denken mit Multimedia: Konkurrenten geben oberflächliche Beschreibungen; Gemini 3 baut Logik auf (z. B. erkennt Aktionen in Videos und prognostiziert Konsequenzen).
- ✅ Fehlende Generierung: Nicht nur Analyse – das Modell erstellt neue Inhalte, wie interaktive Schnittstellen oder Code basierend auf Bildern.
👉 Statistiken aus Tests: In realen Szenarien (von AllAboutAI, 21.11.2025) erzielt Gemini 3 4,5/5 für Video-Zusammenfassung und 4,8/5 für Audio-Analyse und übertrifft GPT-5 um 15–20 % in der Genauigkeit.
Praktische Beispiele: von Bildung bis Entwicklung
So funktioniert die Multimodalität von Gemini 3 in realen Aufgaben. Jedes Beispiel basiert auf offiziellen Google-Demos und unabhängigen Tests (18.–22. November 2025), mit Schwerpunkt auf Cross-Modal-Analyse – wenn das Modell Daten aus verschiedenen Quellen kombiniert.
✅ Bildung: 2-stündiger Mathematikunterricht
- Eingabe: Sie laden ein Video der Vorlesung hoch (mit Tafel, Folien und Audioerklärungen).
- Ausgabe in 45 Sekunden: Interaktive Flashcards (Google Slides mit Animationen), gelöste Aufgaben mit Schritten (LaTeX-Formeln), Verständnisstest (10 Fragen mit Antworten) und personalisierter Wiederholungsplan. Das Modell erkennt Fehler auf der Tafel (OCR + visuelle Analyse) und korrigiert sie mit Erklärungen.
- Vorteil: 87,6 % Genauigkeit bei Video-MMMU – das Modell versteht nicht nur Wörter, sondern auch Gesten des Dozenten (z. B. „hier liegt der Schwerpunkt auf der Ableitung“).
👉 Beispiel aus dem Test: Ein Student lud eine Vorlesung über Quantenmechanik hoch – Gemini 3 generierte 15 Flashcards mit QuTiP-Code zur Simulation und integrierte Audio-Experimente mit Video-Demos.
✅ Entwicklung: Schaltplan einer elektronischen Platine
- Eingabe: Foto oder Scan des Schaltplans (mit Komponenten, Drähten und Notizen).
- Ausgabe in 25 Sekunden: Funktionierender Code in Python (mit der Bibliothek CircuitPython) + Arduino-Sketch, Simulation in Matplotlib, Liste der Komponenten mit AliExpress-Links und Fehlerdiagnose (z. B. „Kurzschluss an Pin 7“).
- Vorteil: 81 % bei MMMU-Pro – das Modell beschreibt nicht nur, sondern baut Logik auf (Berechnung des Widerstands, Überprüfung der Kompatibilität).
👉 Beispiel aus dem Test: Ein Entwickler lud einen Schaltplan eines IoT-Sensors hoch – Gemini 3 generierte ein vollständiges Projekt mit Code, Tests und einem 3D-Modell in Blender und sparte 2–3 Stunden Arbeit.
✅ Sport/Analytik: Video eines Fußballspiels
- Eingabe: 90-minütiges Video des Spiels mit Kommentaren, Grafiken und statistischen Einblendungen.
- Ausgabe (1–2 Min): - Heatmap der Spielerbewegung (generiert basierend auf Frames und Koordinaten), - Interaktive Statistiken: genaue Pässe, Schüsse, xG, Anzahl der Aktionen pro Halbzeit, - Automatische Trainerempfehlungen ("Druck auf der linken Seite verstärken", "Position der defensiven Mittelfeldspieler ändern"), - Highlights des Spiels (automatisch geschnittene und zusammengefügte Segmente der wichtigsten Momente), - PDF-Bericht mit detaillierten Diagrammen und taktischen Kommentaren.
- Vorteil: - Technologie zur Erkennung von Aktionen (action recognition) und OCR für Grafiken und Statistiken, - Erkennungsgenauigkeit ~85 % (geprüft an realen Spielen und Testvideos), - Unterstützung für englischsprachige und lokale Übertragungen, Anpassung an verschiedene Aufnahmeformate.
👉 Beispiel aus dem Test: Ein Trainer analysierte ein Spiel – das Modell erkannte Muster (85 % der Pässe nach rechts), schlug Taktiken vor und generierte einen Bericht für das Team.
Zusätzliche Beispiele für Kreativität und Geschäft
| Bereich | Eingabedaten | Ausgabe Gemini 3 | Verarbeitungszeit |
|---|---|---|---|
| Musik/Audio | 3-minütiger Track (Audio + Noten) | Analyse der Emotionen (Freude 70 %), Transkription mit Timestamps, Remix in MIDI + Code für GarageBand | 18 Sekunden |
| Marketing | Produktfoto + Video-Review | Generierung einer Kampagne: 5 Posts für soziale Netzwerke, A/B-Tests von Visuals, CTR-Prognose (basierend auf Daten) | 35 Sekunden |
| Medizin (Bildung) | Video-Ultraschall + Audio-Kommentar | Annotation mit Diagnosen, interaktives 3D-Modell, Fragen zur Wissensüberprüfung | 52 Sekunden |
| Codierung mit Multimedia | Screenshot des Bildschirms + Video-Bug | Diagnose des Fehlers, Patch-Code (Python/JS), Test-Skript + Visualisierung des Fix | 28 Sekunden |
✅ Fazit aus der Tabelle: In 90 % der Fälle verkürzt Gemini 3 die Zeit für die Analyse von Multimedia von Stunden auf Minuten, mit einer Genauigkeit von 80–90 % bei komplexen Aufgaben.
Quelle: Offizieller Google Blog, 18.11.2025; Tests AllAboutAI, 21.11.2025.
💡 Expertenrat: Für bessere Ergebnisse fügen Sie der Anfrage „In hoher Auflösung verarbeiten“ (media_resolution=high) hinzu – dies erhöht die Genauigkeit um 15 %, verlängert aber die Zeit um 20 %. Beginnen Sie mit der Gemini-App: Laden Sie eine Datei hoch und fragen Sie „Analysiere dieses Video Schritt für Schritt“.
Die Multimodalität von Gemini 3 ist kein Gimmick, sondern ein Werkzeug, das KI zu Ihrem universellen Assistenten macht: vom schnellen Prototyp bis zur tiefen Erkenntnis. Probieren Sie es aus – und Sie werden sehen, wie Routineaufgaben verschwinden.
⸻
💼 Integration mit Google Workspace: Auf Wiedersehen, Excel-Formeln
🎯 Jetzt gibt es in Gmail, Docs, Sheets und Meet einen Assistenten auf Basis von Gemini 3:
- 📊 Sheets: Schreiben Sie „Zeige die Umsatzentwicklung nach Regionen für 2025 und erstelle eine Prognose für 2026“ – fertig in 15 Sekunden
- 📧 Gmail: „Erstelle Antworten auf alle unbeantworteten E-Mails mit Kooperationsangeboten“ – erstellt 27 E-Mails in 2 Minuten
- 🎥 Meet: Führt automatisch Protokoll, hebt Aufgaben hervor und versendet sie in Kalender + Aufgaben
⸻
🚀 Leseempfehlungen
- 📉 Google Core Update November 2025 – warum der Traffic sinkt und es kein offizielles Update gibt
- 🤖 KI-Inhalt 2025 – warum 87 % gebannt werden und wie man für ChatGPT/Gemini schreibt
- 🔍 ChatGPT Search Überblick – wie es funktioniert und Tipps