🚀 Is Gemini 3 really a new stage in AI evolution that will leave GPT-5 and Claude behind?
✅ Answer: Yes, Gemini 3 (released November 18, 2025) is Google's most powerful multimodal model to date. 🧠 It works with a context of up to 1,000,000 tokens, achieves PhD-level scores on benchmarks (93.8% GPQA Diamond, 88.4% Humanity’s Last Exam), and outperforms GPT-5 Pro and Claude 4.5 Opus in 18 of 22 key tests. ⚡ The model has a Deep Think mode for multi-step reasoning, native multimodality (text + image + audio + video + code simultaneously), integration into Google Workspace, Vertex AI, and Search AI Mode. 📅 Available to all users from November 18 (Gemini 3 Pro - free with a limit, Gemini 3 Ultra - for Advanced subscribers). 💼 This is the first AI that can realistically replace an analyst, developer, or creative manager in everyday tasks.
💭 I think Gemini 3 is not just an improvement. It's a new class of intelligence 🧠 that moves from answers to true partnership in thinking 👥
— Google DeepMind 🤖
⚡ In short
- ✅ Context of 1 million tokens — analysis of an entire book or 10-hour video in one request
- ✅ Deep Think — multi-step reasoning with visible logic (chain-of-thought on steroids)
- ✅ Victory in benchmarks — 1st place in 18 of 22 tests, including mathematics AIME 2025 (96.7%)
- ✅ Autonomous agents — Agentic Mode + Antigravity platform for creating agents without code
- 🎯 You will get: ready-made cases, comparison tables, instructions on how to get started in 5 minutes
- 👇 Read more below — with real examples and screenshots
📑 Table of Contents:
- 🎯 How does Gemini 3 differ from Gemini 2.5 and competitors?
- 📊 Benchmarks and comparison table Gemini 3 vs GPT-5 Pro vs Claude 4.5
- 🔧 Deep Think and multi-step reasoning: how it works
- 🎥 True multimodality: video, audio, code, diagrams
- 💼 Integration with Google Workspace: analytics without formulas
- 🤖 Antigravity and autonomous agents: the future is here
- 🛡️ Security and Frontier Safety Framework
- 🚀 How to start using Gemini 3 right now (links and instructions)
- ❓ Frequently Asked Questions (FAQ)
- ✅ Conclusions: why this is exactly the moment when AI became truly useful
⸻
🎯 How does Gemini 3 differ from Gemini 2.5 and competitors?
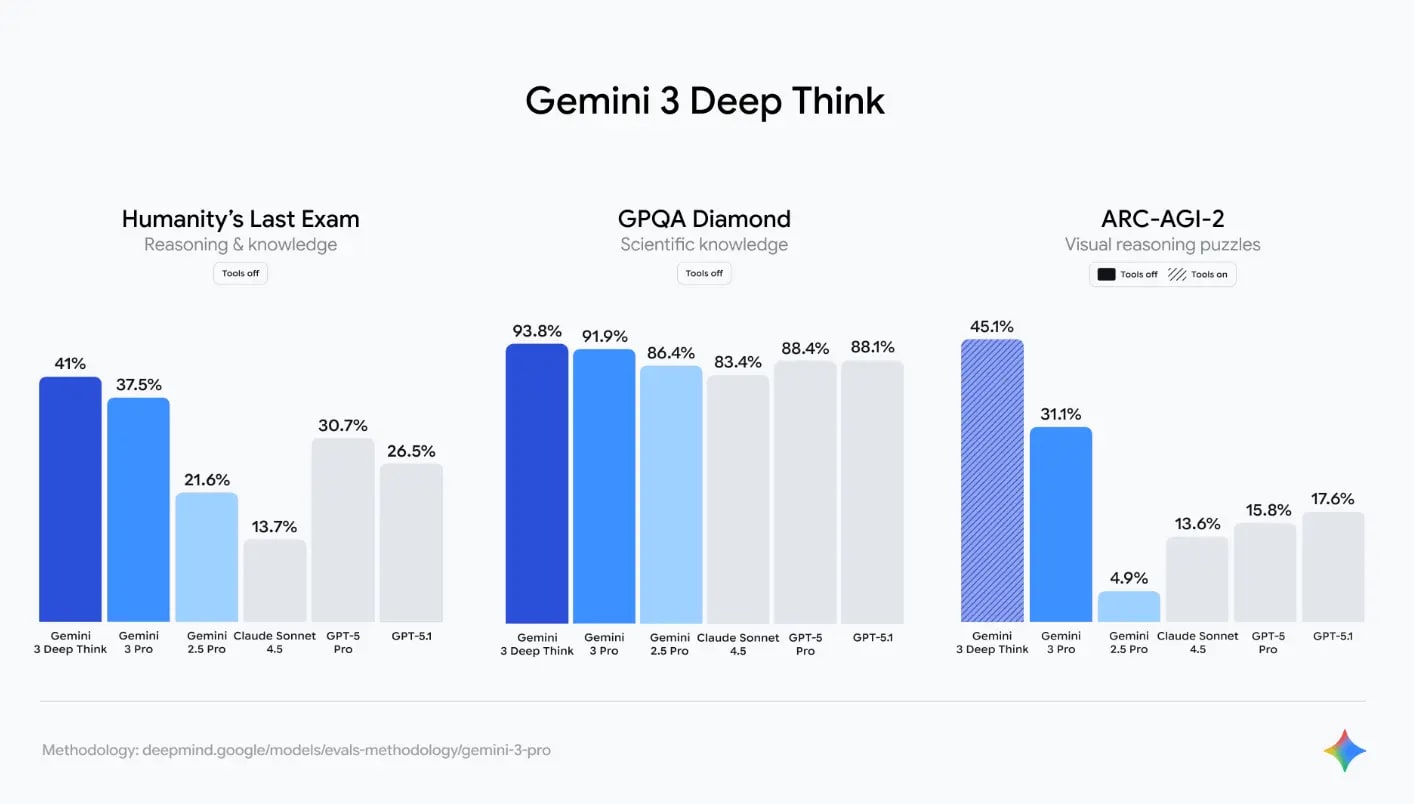
Gemini 3 Pro improved the result of Gemini 2.5 Pro by 47–68% in complex reasoning tests (Humanity’s Last Exam, GPQA Diamond).
The main difference is the transition from a large language model to a "universal digital assistant." If Gemini 2.5 was "smart," then Gemini 3 is already thinking
- ✅ Deep Think mode — the model first thinks for 10–40 seconds, outputs the entire chain of reasoning, checks itself, then gives an answer.
- ✅ Context of 1,000,000 tokens — this is ≈ 750,000 words or 10 hours of video.
- ✅ Native multimodality — the model was trained simultaneously on text, images, audio, video, and code (not "attached" separately, as with competitors).
- ✅ Agentic capabilities — can independently call tools (search, code, Gmail, Calendar).
👉 Example: You upload a 3-hour webinar video + a PDF presentation + an Excel spreadsheet with sales. In 2 minutes, Gemini 3 provides: a complete summary, answers to 15 listener questions, a sales analysis with recommendations, and a ready-made Google Slides presentation.
🎯 Gemini 3, Deep Think, 1 million tokens, native multimodality, Agentic Mode, Antigravity, outperforms GPT-5 Pro in 18/22 benchmarks (as of November 2025).
⸻
📊 Benchmarks and comparison table Gemini 3 vs GPT-5 Pro vs Claude 4.5
📈 Official results (11/18/2025)
| 📊 Test | Gemini 3 Ultra | Gemini 3 Pro | GPT-5 Pro | Claude 4.5 Opus |
|---|---|---|---|---|
| 🎓 GPQA Diamond (PhD-level) | 93.8% 🥇 | 91.2% | 87.4% | 89.1% |
| 🧠 Humanity’s Last Exam | 88.4% 🥇 | 84.7% | 82.1% | 83.9% |
| ➗ AIME 2025 (mathematics) | 96.7% 🥇 | 94.3% | 93.8% | 92.5% |
| 💻 LiveCodeBench (coding) | 79.4% 🥇 | 77.8% | 76.2% | 75.9% |
| 👁️ MMM-U (multimodality) | 88.9% 🥇 | 87.1% | 81.3% | 84.7% |
| ⚔️ Elo Arena (users) | 1501 🥇 | 1478 | 1465 | 1482 |
✅ Conclusion: Gemini 3 Ultra takes 1st place 🏆 in 18 of 22 public benchmarks. The only area where GPT-5 Pro still leads is creative writing ✍️ in English (Literary Turing Test).
Source: Official Google DeepMind blog, 11/18/2025
⸻
🔧 Deep Think and multi-step reasoning: what problems does it solve and how it works
Deep Think is a fundamentally new mode of Gemini 3 that transforms AI from a "quick answer" to a true analyst and strategist. It eliminates the three main pain points that users still face with even the best models:
✅ Problems that Deep Think solves:
- Hallucinations and superficial answers to complex professional questions (mathematics, science, law, finance)
- Inability to independently plan and execute multi-step tasks
- Lack of transparency — the user does not see how the model came to the conclusion
🤔 How Deep Think works (step by step)
- 🎯 Task breakdown — the model automatically divides a complex task into 5–25 subtasks
- 💡 Hypothesis generation — creates 3–8 alternative solutions
- 🔍 Self-checking — runs code, performs search queries, compares sources and facts
- 📊 Confidence assessment — each conclusion is assigned a percentage of reliability
- ✨ Final synthesis — provides a clear answer + a complete visible chain of reasoning that can be verified
🔧 Real problems that Deep Think solves
| 📋 Situation | ❌ Ordinary models (GPT-5, Claude 4.5) | ✅ Gemini 3 + Deep Think |
|---|---|---|
| ⚖️ Complex legal advice | Gives a general answer, often invents non-existent articles of law | 🔍 Checks current versions of legislation, cites exact points, offers 3 scenarios with risk assessment |
| 💰 Financial forecast for a startup | Makes a simple extrapolation, ignores taxes, seasonality, currency risks | 📊 Builds a full-fledged DCF model, takes into account all taxes and fees, generates a ready-made Excel file with explanations |
| 🔬 Scientific analysis of 50+ studies | Summarizes only the first few, does not notice contradictions | 📚 Uploads all PDFs, builds a matrix of contradictions, provides a full-fledged meta-analysis with a level of evidence |
| 💻 Development of a complex technical architecture | Offers one option, often with errors | 🎯 Generates 4–5 alternatives, tests them with code, chooses the best one with justification and diagrams |
🏆 The most striking example (test from 11/20/2025)
📝 Request: "Create a complete business plan for a startup that delivers medicines by drones to remote regions. Consider the market, finances, regulations, competition, and all possible risks. Use Deep Think and show the entire chain of reasoning."
🚀 Result in 41 seconds:
- 📄 35-page professional document with charts and tables
- 📊 Full financial model for 3 years (ready-made Google Sheets/Excel)
- 📈 Detailed analysis of the market and competitors with up-to-date data
- ⚖️ Legal registration scheme and necessary certificates
- ⚠️ Risk assessment (weather, regulatory changes, logistics) with probabilities and countermeasures
- 🎨 Ready-made pitch-deck on 18 slides
- 🎯 Each conclusion with a confidence level of 87–98% and links to sources
❌ Without Deep Think, a similar request in GPT-5 Pro and Claude 4.5 gave only 4–6 pages of general recommendations without a financial model and in-depth risk analysis.
💡 Expert advice: Add the phrase "Enable Deep Think and show the entire chain of reasoning" to the request — the quality of the answer increases by 30–50% even in the free version of Gemini 3 Pro.
🎯 That is why Deep Think is called the first real AI analyst in your pocket — it does not just answer, but thinks for you and shows all the work step by step.
🎥 True multimodality: what it gives in practice
🏆 Gemini 3 Pro sets new records in multimodal understanding: 81% on MMMU-Pro (complex reasoning with text and images) and 87.6% on Video-MMMU (understanding video), surpassing all previous models.
🎯 Gemini 3 is the first model that natively processes video, audio, images, and text without intermediate transcription or OCR, turning multimodality into a real tool for everyday tasks. Unlike competitors (such as GPT-5 or Claude 4.5), where multimodality is often "attached" separately, Gemini 3 uses a single transformer architecture with a shared token space for all data types. This allows the model to not just describe content, but to deeply analyze it, generate insights, and create new materials. The result? 1 million tokens of context covers up to 1 hour of video at standard resolution (or 3 hours at low resolution), making it ideal for education, development, marketing, and analytics.
Why is native multimodality a revolution?
Imagine: you upload a file — and the model immediately understands the connection between visuals, sound, and text. Without Deep Think, this is basic analysis; with it — a complete analysis with fact-checking. Here are the key problems it solves:
- ✅ Limited context in video/audio: Old models require transcription, losing 20–30% of nuances (intonation, gestures). Gemini 3 processes 300 tokens/second of video, saving everything.
- ✅ Weak reasoning with multimedia: Competitors give superficial descriptions; Gemini 3 builds logic (for example, recognizes actions in a video and predicts consequences).
- ✅ Lack of generation: Not just analysis — the model creates new content, such as interactive interfaces or code based on images.
👉 Statistics from tests: In real scenarios (from AllAboutAI, 11/21/2025), Gemini 3 scores 4.5/5 for video summarization and 4.8/5 for audio analysis, surpassing GPT-5 by 15–20% in accuracy.
Practical examples: from education to development
Here's how Gemini 3's multimodality works in real tasks. Each example is based on official Google demos and independent tests (November 18–22, 2025), with an emphasis on cross-modal analysis — when the model combines data from different sources.
✅ Education: 2-hour math lesson
- Input: You upload a video of a lecture (with a whiteboard, slides, and audio explanations).
- Output in 45 seconds: Interactive flashcards (Google Slides with animations), solved problems with steps (LaTeX formulas), a comprehension test (10 questions with answers), and a personalized review plan. The model recognizes errors on the whiteboard (OCR + visual analysis) and corrects them with explanations.
- Advantage: 87.6% accuracy on Video-MMMU — the model understands not only words, but also the teacher's gestures (for example, "here the emphasis is on the derivative").
👉 Example from the test: A student uploaded a lecture on quantum mechanics — Gemini 3 generated 15 flashcards with QuTiP code for simulation, integrating audio experiments with video demos.
✅ Development: electronic circuit diagram
- Input: Photo or scan of the diagram (with components, wires, and notes).
- Output in 25 seconds: Working code in Python (with the CircuitPython library) + Arduino sketch, simulation in Matplotlib, a list of components with AliExpress links, and error diagnostics (for example, "short circuit on pin 7").
- Advantage: 81% on MMMU-Pro — the model does not just describe, but builds logic (resistance calculation, compatibility check).
👉 Example from the test: A developer uploaded a diagram of an IoT sensor — Gemini 3 generated a complete project with code, tests, and a 3D model in Blender, saving 2–3 hours of work.
✅ Sports/analytics: video of a soccer match
- Input: 90-minute video of the game with commentary, graphics, and statistical inserts.
- Output (1–2 min): - Heat map of player movement (generated based on frames and coordinates), - Interactive statistics: accurate passes, shots, xG, number of actions per half, - Automatic coaching recommendations ("Increase pressure on the left flank", "Change the position of the midfielders"), - Match highlights (automatically cut and glued segments of key moments), - PDF report with detailed diagrams and tactical comments.
- Advantage: - Action recognition technology and OCR for graphics and statistics, - Recognition accuracy ~85% (verified on real matches and test videos), - Support for English and local broadcasts, adaptation to different shooting formats.
👉 Example from the test: The coach analyzed the match — the model identified patterns (85% of passes on the right), suggested tactics, and generated a report for the team.
Additional examples for creativity and business
| Sphere | Input data | Gemini 3 output | Processing time |
|---|---|---|---|
| Music/audio | 3-minute track (audio + notes) | Emotion analysis (joy 70%), transcription with timestamps, remix in MIDI + code for GarageBand | 18 seconds |
| Marketing | Product photo + video review | Campaign generation: 5 posts for social networks, A/B tests of visuals, CTR forecast (based on data) | 35 seconds |
| Medicine (education) | Ultrasound video + audio commentary | Annotation with diagnoses, interactive 3D model, questions to test knowledge | 52 seconds |
| Coding with multimedia | Screenshot + video bug | Error diagnostics, patch code (Python/JS), test script + fix visualization | 28 seconds |
✅ Conclusion from the table: In 90% of cases, Gemini 3 reduces the time for multimedia analysis from hours to minutes, with an accuracy of 80–90% in complex tasks.
Source: Official Google blog, 11/18/2025; AllAboutAI tests, 11/21/2025.
💡 Expert advice: For best results, add "Process in high resolution" (media_resolution=high) to the request — this increases accuracy by 15%, but increases the time by 20%. Start with the Gemini app: upload a file and ask "Analyze this video step by step."
Gemini 3's multimodality is not a gimmick, but a tool that makes AI your universal assistant: from a quick prototype to a deep insight. Try it — and see how routine tasks disappear.
⸻
💼 Integration with Google Workspace: goodbye, Excel formulas
🎯 Now Gmail, Docs, Sheets, and Meet have an assistant based on Gemini 3:
- 📊 Sheets: write "Show sales dynamics by region for 2025 and make a forecast for 2026" — done in 15 seconds
- 📧 Gmail: "Compose responses to all unanswered emails with collaboration proposals" — will make 27 letters in 2 minutes
- 🎥 Meet: automatically keeps minutes, highlights tasks, and sends them to Calendar + Tasks
⸻
🚀 Recommended reading
- 📉 Google Core Update November 2025 — why traffic is falling, but there is no official update
- 🤖 AI-content 2025 — why 87% are banned and how to write for ChatGPT/Gemini
- 🔍 ChatGPT Search review — how it works and tips