
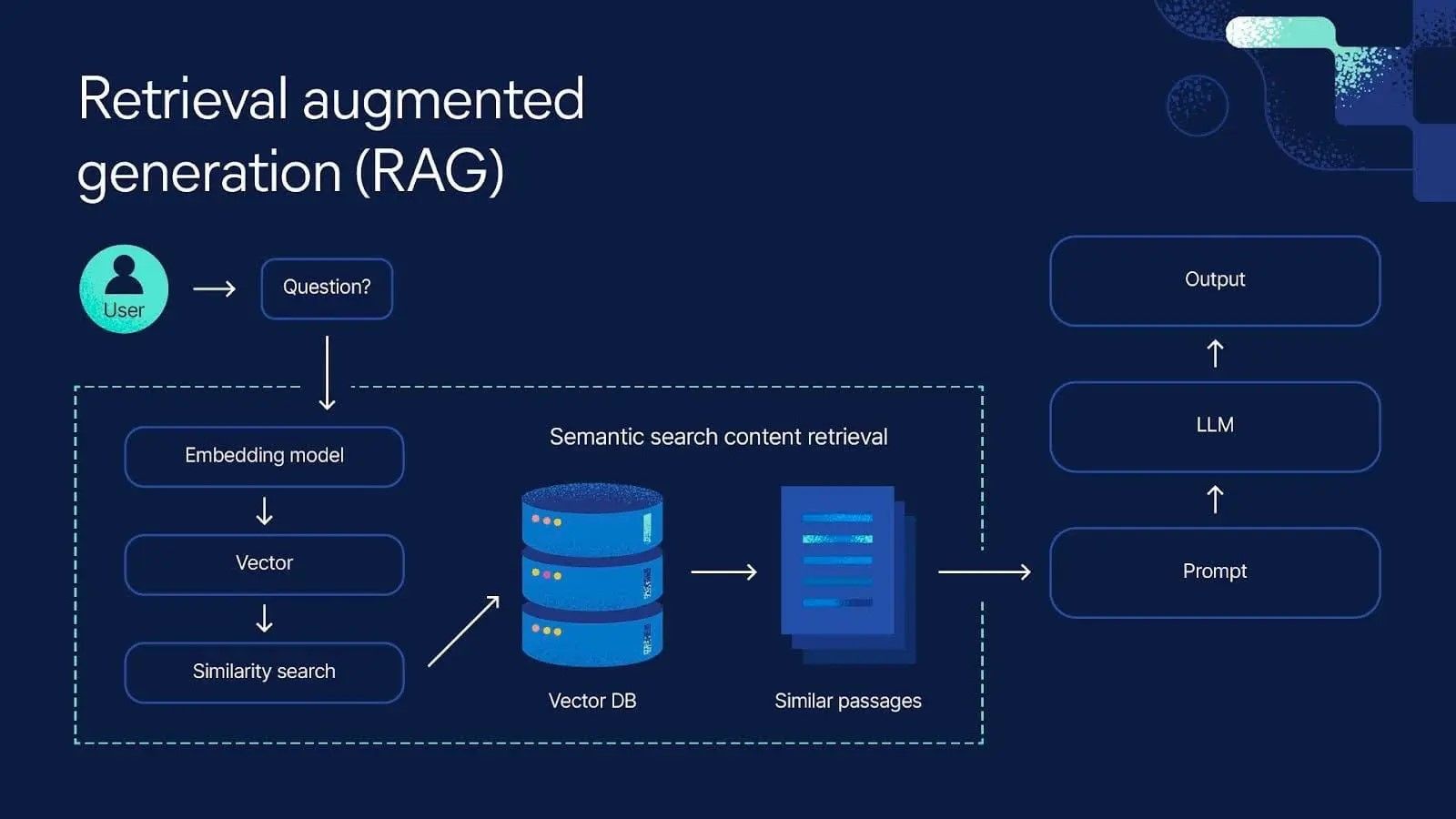
Ви додали документи у свій RAG-пайплайн, написали запит — і система знаходить відповідь. Але як саме? Чому вона обирає цей фрагмент, а не сусідній? І чому іноді повертає повну нісенітницю?
Спойлер: за кожним RAG-пошуком стоїть математика кутів у просторі тисячі вимірів — і її можна зрозуміти без жодної формули.
⚡ Коротко
- ✅ Vector DB ≠ PostgreSQL: вона шукає за змістом, а не за точним збігом слів — це принципово різні задачі
- ✅ Cosine similarity — це кут, не відстань: два фрагменти "близькі", якщо дивляться в один бік у просторі значень
- ✅ top_k, threshold, MMR — три ручки налаштування якості пошуку, які варто розуміти перед тим, як щось крутити
- ✅ Vector search не вміє шукати точні числа та ID: для цього потрібен hybrid search або metadata-фільтрація
- 🎯 Ви отримаєте: інтуїтивне розуміння того, як влаштований пошук у RAG, і робочий код першого проекту на ChromaDB або Qdrant
- 👇 Нижче — аналогії, діаграми, повний код і таблиця вибору Vector DB у 2026
📚 Зміст статті
🎯 Що таке Vector DB і чим вона відрізняється від PostgreSQL
Vector DB vs реляційна БД
Запитайте PostgreSQL "знайди мені документи про розірвання договору" —
він знайде тільки рядки, де є слово "розірвання". Запитайте те саме у
Vector DB — вона знайде також "припинення дії угоди", "дострокове
закінчення контракту" і "termination clause", навіть якщо жодного з
ваших слів у тексті немає. Це не магія: просто різна математика під
капотом — точний збіг рядків проти порівняння кутів між векторами.
Vector DB не замінює PostgreSQL — вона вирішує задачу, яку PostgreSQL принципово не вміє: "знайди мені схожий за змістом документ".
Уявіть бібліотеку. PostgreSQL — це картотека: ви точно знаєте автора, рік, назву — і знаходите книгу. Але що якщо ви не пам'ятаєте назву, тільки про що вона? Тут починається vector search — система, яка може знайти книгу за змістом, а не за мітками.
Під капотом vector DB зберігає не рядки та стовпці, а вектори — списки чисел, кожен із яких кодує "значення" шматка тексту. Стандартна embedding-модель перетворює речення на вектор з 768 або 1536 чисел (документація OpenAI Embeddings). Ці числа — координати в просторі значень. Схожі за змістом речення → схожі координати → вони "поруч" у цьому просторі.
Чому PostgreSQL з pgvector — це компроміс, а не заміна
pgvector додає векторний пошук прямо в PostgreSQL. Це зручно: один сервіс, знайома SQL, транзакції. Але є межа: за даними VectorDBBench, pgvector реалістично тримає 10–100 млн векторів до помітної деградації продуктивності. Для початківця та більшості production-проєктів до 5 млн векторів — повністю підходить.
Що всередині Vector DB: HNSW-індекс
Шукати "найближчий вектор" серед мільйона — це дорого, якщо перебирати кожен. Тому vector DB будує спеціальний індекс — HNSW (Hierarchical Navigable Small World). Уявіть карту міста з кількома рівнями: спочатку навігація між районами, потім між кварталами, потім між будинками. HNSW робить те саме з векторами — знаходить приблизно найближчих за логарифмічний час, не лінійний. Детально про алгоритми пошуку — Milvus docs.
- ✔️ PostgreSQL: точний пошук, SQL, ACID, транзакції, знайомий стек
- ✔️ Vector DB: семантичний пошук, ANN-індекси, metadata-фільтрація, масштабування на мільярди векторів
- ✔️ Правильна відповідь у 2026: для більшості RAG-проєктів — обидва. pgvector або ChromaDB для семантики + PostgreSQL для структурованих даних
Висновок: Vector DB і PostgreSQL — не конкуренти, а інструменти для різних задач; для RAG вам потрібна обидві або hybrid-рішення.
📌 Cosine similarity: інтуїтивне пояснення без математики
Що таке cosine similarity
Cosine similarity вимірює кут між двома векторами, а не відстань між ними. Якщо два вектори дивляться в один бік — кут малий, similarity висока (→ 1). Якщо в протилежні — similarity низька (→ -1). На практиці для text embeddings значення майже завжди позитивні і лежать між 0.2 і 0.99.
"Чим ближчі вектори, тим схожіший текст" — неповне твердження. Правильніше: чим менший кут між векторами у просторі значень, тим більш семантично схожі фрагменти. Це не те саме, що евклідова відстань.
Аналогія з компасом
Уявіть двох людей, що стоять в одній точці та показують у різні сторони. Cosine similarity — це про напрямок, не про те, де вони стоять і наскільки витягнуті їхні руки. Якщо обидва показують на північ — similarity = 1. Якщо один на північ, інший на південь — similarity = -1. Якщо перпендикулярно — similarity = 0.
У реальних text embeddings "північ" — це умовний напрямок у просторі 768 або 1536 вимірів. Embedding-модель навчена так, що семантично схожі речення → схожі напрямки. "Договір оренди" і "угода про найм житла" → майже однаковий напрямок. "Договір оренди" і "рецепт борщу" → перпендикулярні.
Ось проста 2D-ілюстрація (у реальності вимірів — тисячі):
↑ "юридичні документи"
|
"договір оренди" ↗|↖ "угода про найм"
/ | \
/ | \
←--------------+---+----+----------→ "побутові теми"
\ | /
\ | /
"рецепт борщу" ↙|↘ "кулінарія"
|
↓
"Договір оренди" і "угода про найм" — маленький кут між ними → висока cosine similarity.
"Договір оренди" і "рецепт борщу" — майже перпендикулярні → низька similarity.
Чому "ближчі вектори" — неточне формулювання
У багатовимірному просторі відбувається дещо неінтуїтивне: евклідова відстань між точками зростає зі збільшенням розмірності і перестає добре відображати схожість — це відомо як curse of dimensionality. Cosine similarity стійкіша до цього ефекту, бо вимірює кут (напрямок), а не абсолютну відстань у просторі. Тому для text embeddings cosine — стандарт де факто.
Практичні значення cosine similarity у RAG
- ✔️ 0.85–0.99: майже ідеальний збіг за змістом (дублікати або дуже схожі фрагменти)
- ✔️ 0.70–0.85: хороша семантична близькість — зазвичай саме тут ваша відповідь
- ✔️ 0.50–0.70: слабка схожість, можлива нерелевантність
- ✔️ нижче 0.50: швидше за все, не той документ
Але увага: конкретні порогові значення дуже залежать від embedding-моделі і корпусу. Не існує універсального "threshold = 0.75 завжди правильний". Перевіряйте на ваших даних.
Висновок: cosine similarity вимірює кут між векторами, а не відстань — і це робить її надійнішою для семантичного пошуку у висококовимірному просторі.
📌 Яку Vector DB обрати у 2026 для початківця
ChromaDB, Qdrant чи pgvector?
Для першого проєкту і навчання — ChromaDB: нульова конфігурація,
pip install chromadb і ви вже шукаєте. Для
production-проєкту з потужними фільтрами і складними запитами — Qdrant:
чистий API, HNSW з коробки, payload filters. Якщо у вас вже є
PostgreSQL — pgvector (особливо з розширенням pgvectorscale): один
сервіс замість двох, у 2026 конкурентний навіть на 50M+ векторів.
Реальний бенчмарк на 5500 документів, M1 MacBook:
Qdrant і pgvector показали однакову латентність (±1ms на p50)
.
Різниця в recall — 0.911 vs 0.900, тобто 1%. Вибір vector DB впливає
на ваш результат набагато менше, ніж стратегія чанкінгу — і набагато
менше, ніж якість embedding-моделі. Якщо ви тільки починаєте і
будуєте локальний RAG, почніть з ChromaDB + Ollama:
повний пайплайн від нуля — у цьому гайді
.
| Критерій |
ChromaDB |
Qdrant |
pgvector + pgvectorscale |
| Старт |
⚡ Найшвидший: pip install chromadb |
Docker або pip |
PostgreSQL + 2 розширення |
| Локальна розробка |
✅ In-memory або PersistentClient |
✅ Disk-file або Docker |
✅ Якщо Postgres вже є |
| API |
Python-first, простий |
REST + Python SDK, чистий |
SQL (знайомий) |
| Масштаб |
До ~5–10M векторів (після Rust-rewrite 2025: 4x швидше) |
Мільярди векторів |
До 50M+ з pgvectorscale |
| Hybrid search |
❌ Немає нативно |
✅ Вбудований |
⚠️ Через SQL + FTS |
| Metadata-фільтри |
✅ Базові |
✅ Потужні (payload filters) |
✅ Через WHERE |
| Коли обирати |
PoC, навчання, прототип |
Production: складні фільтри, hybrid, мільярди векторів |
Вже є Postgres, обсяг до 50M+ |
Про pgvectorscale:
pgvectorscale від Timescale
— розширення поверх pgvector, яке додає StreamingDiskANN індекс і
статистичний binary quantization. У бенчмарках 2025–2026 на 50M+
векторів показує throughput, що перевищує Qdrant на деяких workloads.
Якщо ваш стек — PostgreSQL і обсяг зростає — встановлюється одною
командою і не потребує міграції даних.
Джерела: Encore — Best Vector Databases 2026,
pgvector vs ChromaDB — Elestio, 2026,
Firecrawl — Complete Vector DB Comparison.
Висновок розділу: ChromaDB — для старту і навчання
(після Rust-rewrite 2025 значно швидша, але залишається найпростішою
точкою входу); Qdrant — для production з потужними фільтрами і
hybrid search; pgvector + pgvectorscale — якщо вже є Postgres і
потрібен масштаб до 50M+ без окремого сервісу. Різниця в якості
пошуку між ними — мінімальна. Хочете детальніше?
Детальне порівняння ChromaDB, Qdrant або pgvector: як обрати Vector DB під свій проєкт
.
📌 Перший проект: пошук по своїх документах
Що побудуємо
Повний пайплайн: список текстових документів → embeddings → vector DB → семантичний пошук. Два варіанти: ChromaDB (простіший старт) і Qdrant (чистіший API, ближче до production). Обидва — локально, без зовнішніх сервісів.
Встановлення
pip install chromadb qdrant-client sentence-transformers
Для embeddings використаємо sentence-transformers — безкоштовно, локально, без API-ключів. Модель all-MiniLM-L6-v2 — 384 виміри, швидка, добре підходить для початку (список моделей sentence-transformers).
Варіант A: ChromaDB
import chromadb
from sentence_transformers import SentenceTransformer
# Ваші документи (в реальному проєкті — зчитуйте з файлів)
documents = [
"Договір оренди квартири укладається строком на 12 місяців.",
"Орендар зобов'язується сплачувати орендну плату до 5-го числа кожного місяця.",
"Розірвання договору можливе за 30 днів письмового попередження.",
"Технічне обслуговування несе орендодавець, якщо інше не вказано.",
"Рецепт борщу: буряк, капуста, картопля, морква, цибуля.",
"Для приготування борщу потрібен бульйон на кістках або овочевий.",
]
# Завантажуємо embedding-модель (перший запуск — скачає ~90MB)
model = SentenceTransformer("all-MiniLM-L6-v2")
# Генеруємо embeddings
embeddings = model.encode(documents).tolist()
# Створюємо ChromaDB (in-memory для тесту)
client = chromadb.Client()
collection = client.create_collection(
name="my_docs",
metadata={"hnsw:space": "cosine"} # явно вказуємо cosine similarity
)
# Додаємо документи
collection.add(
documents=documents,
embeddings=embeddings,
ids=[f"doc_{i}" for i in range(len(documents))]
)
# Пошук
def search(query, top_k=3):
query_embedding = model.encode([query]).tolist()
results = collection.query(
query_embeddings=query_embedding,
n_results=top_k,
include=["documents", "distances"]
)
print(f"\n🔍 Запит: '{query}'")
for doc, dist in zip(results["documents"][0], results["distances"][0]):
similarity = 1 - dist # ChromaDB повертає cosine distance, не similarity
print(f" [{similarity:.3f}] {doc[:80]}")
search("умови розірвання договору")
search("як приготувати перший борщ")
search("коли платити за оренду")
Очікуваний вивід:
🔍 Запит: 'умови розірвання договору'
[0.712] Розірвання договору можливе за 30 днів письмового попередження.
[0.634] Договір оренди квартири укладається строком на 12 місяців.
[0.521] Орендар зобов'язується сплачувати орендну плату до 5-го числа...
🔍 Запит: 'як приготувати перший борщ'
[0.801] Рецепт борщу: буряк, капуста, картопля, морква, цибуля.
[0.743] Для приготування борщу потрібен бульйон на кістках або овочевий.
[0.312] Технічне обслуговування несе орендодавець, якщо інше не вказано.
Зверніть увагу: запит "як приготувати перший борщ" правильно знаходить рецепти, а не документи про оренду — навіть без слова "рецепт" у запиті. Це семантичний пошук у дії.
Варіант B: Qdrant (локально)
from qdrant_client import QdrantClient
from qdrant_client.models import Distance, VectorParams, PointStruct
from sentence_transformers import SentenceTransformer
documents = [
"Договір оренди квартири укладається строком на 12 місяців.",
"Орендар зобов'язується сплачувати орендну плату до 5-го числа кожного місяця.",
"Розірвання договору можливе за 30 днів письмового попередження.",
"Технічне обслуговування несе орендодавець, якщо інше не вказано.",
"Рецепт борщу: буряк, капуста, картопля, морква, цибуля.",
"Для приготування борщу потрібен бульйон на кістках або овочевий.",
]
model = SentenceTransformer("all-MiniLM-L6-v2")
embeddings = model.encode(documents)
# In-memory Qdrant (для тесту; для persistent: QdrantClient(path="./qdrant_data"))
client = QdrantClient(":memory:")
# Створюємо колекцію
client.create_collection(
collection_name="my_docs",
vectors_config=VectorParams(
size=384, # розмір вектора all-MiniLM-L6-v2
distance=Distance.COSINE
)
)
# Додаємо точки
points = [
PointStruct(
id=i,
vector=embeddings[i].tolist(),
payload={"text": doc}
)
for i, doc in enumerate(documents)
]
client.upsert(collection_name="my_docs", points=points)
# Пошук
def search_qdrant(query, top_k=3):
query_embedding = model.encode([query])[0].tolist()
results = client.search(
collection_name="my_docs",
query_vector=query_embedding,
limit=top_k,
with_payload=True
)
print(f"\n🔍 Запит: '{query}'")
for r in results:
print(f" [{r.score:.3f}] {r.payload['text'][:80]}")
search_qdrant("умови розірвання договору")
search_qdrant("як приготувати перший борщ")
Qdrant повертає score — це вже cosine similarity (від 0 до 1), не distance. API чистіший і ближчий до production-патернів. Офіційна документація Qdrant.
📌 top_k, threshold, MMR — що крутити і чому
три параметри пошуку
top_k — скільки фрагментів передавати в LLM (зазвичай 3–5). threshold — мінімальна similarity для включення результату (починайте з 0.5–0.6, перевіряйте на своїх даних). MMR (Maximal Marginal Relevance) — алгоритм, що балансує релевантність і різноманітність, щоб уникнути дублів.
top_k: скільки фрагментів передавати LLM
Кожен фрагмент, що ви передаєте в LLM, займає токени контекстного вікна і коштує грошей. Занадто мало (top_k=1) — ризикуєте пропустити потрібну інформацію. Занадто багато (top_k=15) — зашумлюєте контекст нерелевантним.
- ✔️ top_k = 3–5: золотий стандарт для більшості RAG-задач
- ✔️ top_k = 1–2: коли документ дуже структурований і відповідь точно в одному місці
- ✔️ top_k = 7–10: коли відповідь може бути розкидана по кількох документах
threshold: мінімальний поріг similarity
Якщо найближчий результат має similarity 0.35 — скоріш за все, у вашій базі просто немає відповіді на цей запит. Threshold дозволяє відкинути такі результати і сказати "не знаю" замість галюцинувати.
# Приклад: відкидати результати з similarity < 0.55
results = collection.query(query_embeddings=q_embed, n_results=5)
filtered = [
(doc, 1 - dist)
for doc, dist in zip(results["documents"][0], results["distances"][0])
if (1 - dist) >= 0.55
]
if not filtered:
return "Відповіді в базі знань не знайдено."
MMR: коли top-3 результати — це майже одне і те саме
Уявіть, що у вашій базі є 5 майже ідентичних фрагментів про "термін оренди". Без MMR top_k=3 поверне три з них — і ви передасте LLM троє дублів. MMR балансує: бере найрелевантніший фрагмент, потім шукає наступний, що і релевантний, і відрізняється від вже обраних.
# MMR доступний у LangChain через as_retriever
from langchain_community.vectorstores import Chroma
vectorstore = Chroma(...)
retriever = vectorstore.as_retriever(
search_type="mmr",
search_kwargs={"k": 4, "fetch_k": 20, "lambda_mult": 0.5}
# lambda_mult: 1.0 = тільки релевантність, 0.0 = тільки різноманітність
)
Висновок розділу: я рекомендую починати з top_k=4, threshold=0.55
і вмикати MMR, якщо бачу дублікати у результатах — це покриває близько 80%
кейсів. Але я завжди враховую, що кожен фрагмент з top_k займає токени в
контекстному вікні LLM, а це напряму впливає на вартість і якість
відповіді —
як влаштоване контекстне вікно і скільки це коштує
.
💼 Коли vector search не працює: точні терміни, числа, ID
Обмеження семантичного пошуку
Vector search погано шукає точні числа, артикули, імена власні, коди та ID — бо embedding-модель не відрізняє "договір №42" від "договір №43": обидва "про договір". Для таких запитів потрібен BM25 (keyword search) або metadata-фільтрація — і саме це вирішує hybrid search.
Якщо ваш RAG погано відповідає на "яка сума в рядку 7 таблиці?" або "знайди запис з ID 94521" — проблема не в LLM і не в чанкінгу. Проблема в тому, що vector search для цього не призначений.
Де vector search проваюється
- ✔️ Точні числа: "знайди договір на суму 47 500 грн" — embeddings не кодують числа з такою точністю
- ✔️ Артикули та ID: "продукт SKU-4892" — схожий за звучанням, але інший артикул дасть high similarity
- ✔️ Імена власні і назви: "Іваненко Петро Миколайович" vs "Іваненко П.М." → vector search може їх змішати або не знайти
- ✔️ Дати: "що відбулося 15 лютого 2023?" — embedding не "знає", що це специфічна дата
- ✔️ Короткі коди: "пункт 3.2.1 договору" — занадто мало семантичного контексту
Рішення: metadata-фільтрація
Якщо ваші документи мають структуровані поля (дата, автор, тип документа, відділ) — зберігайте їх як metadata і фільтруйте до пошуку:
# Додаємо metadata при індексуванні (Qdrant)
PointStruct(
id=1,
vector=embedding,
payload={
"text": "...",
"doc_type": "contract",
"date": "2024-03-15",
"amount": 47500
}
)
# Пошук тільки серед договорів певного типу
client.search(
collection_name="my_docs",
query_vector=query_embedding,
query_filter=Filter(
must=[FieldCondition(key="doc_type", match=MatchValue(value="contract"))]
),
limit=5
)
Рішення: hybrid search (BM25 + vector)
Для серйозних кейсів з точними термінами — комбінуйте векторний пошук із класичним keyword-пошуком BM25. Це дає +15–40% якості порівняно з чистим vector search. Детально — у наступній статті: Hybrid Search та Reranking.
Висновок: vector search — потужний для семантичних запитів, але сліпий для точних збігів; комбінуйте з metadata-фільтрами або hybrid search для реальних документів.
❓ Часті питання (FAQ)
Чим ChromaDB відрізняється від FAISS?
FAISS — це бібліотека індексів, не database. Вона надшвидка і популярна у research, але не має API для зберігання документів, metadata-фільтрації або персистентності "з коробки". ChromaDB будується поверх FAISS (або інших індексів) і додає зручний API, зберігання та фільтри. Для початківця — ChromaDB. Для вбудовування в C++/Python без overhead — FAISS напряму.
Чи треба перебудовувати індекс кожного разу, коли додаю нові документи?
Ні. ChromaDB і Qdrant підтримують інкрементальне додавання: collection.add() або client.upsert() — і новий документ одразу доступний для пошуку. HNSW-індекс оновлюється динамічно. Масове додавання (batch) ефективніше, але одиничні документи теж працюють без перебудови.
Які embedding-моделі використовувати — безкоштовні локальні чи OpenAI?
Для початку — all-MiniLM-L6-v2 або nomic-embed-text (через Ollama): безкоштовно, локально, без витоку даних. Для production з вимогою максимальної якості — text-embedding-3-small від OpenAI (~$0.02 за 1M токенів). Детальне порівняння моделей — у статті Embedding Models для RAG.
Що таке ANN і чи можна отримати точний результат?
ANN (Approximate Nearest Neighbor) — пошук "приблизно найближчого" вектора. Точний пошук (kNN) дає ідеальний результат, але працює за O(n) — тобто перебирає кожен вектор. При мільйоні документів це секунди. ANN з HNSW-індексом дає результат за мілісекунди з 95–99% точністю. Для RAG цього більш ніж достатньо.
Як перевірити, чи добре працює мій vector search?
Найпростіше: візьміть 10–20 реальних запитів, зробіть пошук і роздрукуйте top-3 результати з similarity score. Читайте їх очима — чи релевантні вони? Якщо ні — проблема або в якості embeddings, або в розмірі чанків. Формальні метрики (Recall@k, MRR) — у статті 3.1 Перші метрики якості RAG.
✅ Висновки
- 🔹 Vector DB шукає за семантичною близькістю, PostgreSQL — за точним збігом: це різні інструменти для різних задач, не конкуренти
- 🔹 Cosine similarity вимірює кут між векторами, а не відстань — і це робить її стійкою до curse of dimensionality у висококовимірному просторі
- 🔹 Для старту — ChromaDB (pip install і готово), для production без Postgres — Qdrant, для команд з Postgres у стеку — pgvector
- 🔹 top_k=4, threshold≈0.55, MMR — робочий baseline для більшості RAG-проєктів
- 🔹 Vector search сліпий до точних чисел, ID та артикулів — для них потрібна metadata-фільтрація або hybrid search
Головна думка: Vector search — не панацея. Найкращі результати в production дають комбінації: hybrid search (BM25 + vector) + reranking + metadata-фільтрація. Саме про це — у наступній статті: 2.2 Hybrid Search та Reranking: +15–40% якості без зміни моделі.
Пов'язані статті:
RAG для PDF ·
Chunking Strategies ·
Embedding Models ·
Hybrid Search та Reranking ·
