
Your RAG pipeline is working. Answers are being generated, retrieval is returning results.
But the user is looking for get_user_v2 — and instead of documentation, they get
an article about user management. Or they ask about "Article 42 of the Personal Data Protection Law" — and vector search returns three chunks about GDPR, but none contain the text
of the required article.
Spoiler: the problem is not with the LLM or the embedding model. The problem
is that pure vector search looks for *meaning* — but sometimes *text* is needed.
Hybrid search + reranking closes this gap and provides a +15–25% improvement in retrieval quality in real-world projects without any model changes.
⚡ In a nutshell
- ✅ Vector search vs BM25: meaning vs keywords — a combination is needed
- ✅ Hybrid search: merging via RRF, not score normalization
- ✅ Reranking: +8–25% quality thanks to cross-encoders
- 🎯 You will get: when and how to apply hybrid + reranking with code
- 👇 Below are the architecture, formulas, and examples
📚 Table of Contents
🎯 Section 1. Two types of search: why each is strong in its own way
BM25 (keyword search) finds exact matches — article numbers, IDs, method names.
Dense vector search finds semantically similar documents — synonyms,
paraphrases, cross-lingual queries. Neither of these approaches is sufficient
for production RAG: BM25 doesn't understand meaning, and vector search "blurs"
exact values.
If vector search is "find something similar in meaning," then BM25 is
"find the document that contains this specific word." Production RAG requires both.
BM25 (Keyword Search): why the 1994 algorithm is still alive
BM25 (Best Matching 25) is a classic ranking algorithm that evaluates
document relevance based on three factors: term frequency in the document (TF),
inverse document frequency (IDF), and document length. The algorithm was
formalized by Robertson and Walker in 1994
and remains the standard for keyword search in Elasticsearch, OpenSearch, and most
search engines.
Why has it survived for 30 years? Because for certain types of queries, nothing is better.
When a user searches for SKU-4521, get_user_v2,
or "article 42" — it's an exact match task. An embedding model converts
SKU-4521 into a vector that describes the general "meaning" of a product article number,
but the difference between 4521 and 4522 in this vector is minimal.
BM25 finds an exact match in milliseconds — without neural networks, without GPUs,
without embeddings.
Where BM25 is indispensable: product article numbers and codes, function names and API endpoints,
document and law article numbers, rare terms and abbreviations, exact quotes.
BM25 limitations: "car" ≠ "automobile." If a user writes "cancel subscription,"
and the document says "terminate the plan," BM25
will find nothing because there are no common words.
Dense Vector Search (Semantic): the power of context
Dense vector search works differently. The query and documents are converted into numerical
vectors (embeddings), and search is performed using
cosine similarity — the angle between vectors in the meaning space.
"Cancel subscription" and "terminate the plan" will get close vectors because the embedding model has learned that these phrases mean the same thing.
Where dense vector search is indispensable: semantic search for synonyms and
paraphrases, cross-lingual queries (a query in Ukrainian finds a document
in English), natural language queries ("how to reduce infrastructure costs").
Limitations: embeddings "blur" exact meanings. Two different article numbers get
almost the same vector. Short queries of one or two words produce a fuzzy vector.
Details about these limitations are in the
article on embeddings.
Table: when each works
| Query Type |
BM25 |
Dense Vector |
Hybrid |
get_user_v2 (exact term) |
✅ exact match |
❌ blurs |
✅ |
| "how to cancel subscription" (semantic) |
❌ no word matches |
✅ semantics |
✅ |
| "article 42 of data law" (mixed) |
✅ "article 42" |
✅ "data protection" |
✅✅ both signals |
| "pricing" (1 word) |
⚠️ too broad |
⚠️ fuzzy vector |
⚠️ query transform needed |
- ✔️ BM25: indispensable for exact match — IDs, article numbers, function names
- ✔️ Dense vectors: indispensable for semantic search — synonyms, paraphrases, cross-lingual
- ✔️ Neither approach is self-sufficient for production RAG
Section conclusion:
BM25 and dense vector search are not competitors, but complementary tools.
The first finds words, the second — meaning. Production RAG requires both.
📌 Section 2. Hybrid Search: how to combine both approaches
Hybrid search performs BM25 and dense vector search in parallel, and then
combines the results using Reciprocal Rank Fusion (RRF) — an algorithm that
uses rank positions instead of scores. RRF does not require normalization
and works stably with different types of sources. In Weaviate benchmarks
Weaviate (2025),
hybrid search with RRF outperforms the best-performing single method by 2.6–13.4
nDCG@10 points.
The main problem with combining results from BM25 and vector search is that their scores
live on different scales and cannot simply be added together. RRF elegantly bypasses
this problem by working with ranks, not numbers.
Reciprocal Rank Fusion (RRF): a simple and reliable merging method
RRF was proposed by
Cormack, Clarke, and Buettcher in 2009 (SIGIR '09) and has since become
the de facto standard for hybrid search. The formula is:
score(d) = Σ 1 / (k + rank(d))
where rank(d) is the document's position in each individual ranking,
and k is a smoothing constant (standard value: 60).
Why k = 60? As explained by
Elasticsearch documentation, this constant prevents the first position from having excessive influence.
Without smoothing, the difference between rank 1 (score = 1.0) and
rank 2 (score = 0.5) is twofold. With k = 60, the difference between
rank 1 (1/61 ≈ 0.0164) and rank 2 (1/62 ≈ 0.0161) is minimal, making the merge more stable.
Why is RRF better than linear score combination? Three reasons.
First, BM25 returns scores in an arbitrary range (from 0 to tens),
and cosine similarity ranges from -1 to 1. Normalizing these scales to a common
range is a non-trivial task that depends on the score distribution in
a specific corpus. RRF works exclusively with positions, ignoring absolute
scores.
Second, RRF is insensitive to outliers: a single document with an anomalously high
BM25 score will not "pull" the entire ranking towards itself.
Third, as noted by
OpenSearch (2025), RRF naturally boosts documents that appear
in the top positions of multiple rankings simultaneously — which is a strong signal
of relevance.
Example with numbers
BM25 returns: [Doc A (rank 1), Doc C (rank 2), Doc B (rank 3)]
Dense returns: [Doc B (rank 1), Doc A (rank 2), Doc D (rank 3)]
RRF scores (k=60):
- Doc A: 1/(60+1) + 1/(60+2) = 0.0164 + 0.0161 = 0.0325 ← wins
- Doc B: 1/(60+3) + 1/(60+1) = 0.0159 + 0.0164 = 0.0323
- Doc C: 1/(60+2) + 0 = 0.0161
- Doc D: 0 + 1/(60+3) = 0.0159
Result: [A, B, C, D]. Doc A wins because it consistently ranks high
in both rankings.
Weighted Hybrid: when control via α (alpha) is needed
RRF gives equal weight to each search method. But this is not always optimal.
For technical documentation with many exact terms, BM25 should be "louder."
For customer support with natural language queries, dense vectors are more important.
Most vector databases support the α (alpha) parameter, where
α = 0.0 means pure BM25, and α = 1.0 means pure vector search.
Weaviate documentation
allows setting alpha directly in the query.
Elasticsearch, starting from version 8.x, supports weighted RRF — each retriever
gets its own weight.
Recommendations by domain (approximate — test on your data):
- Technical documentation, code: α = 0.3–0.4 (more keyword)
- General content, customer support: α = 0.6–0.7 (more semantics)
- Legal texts: α = 0.4–0.5 (balance: exact articles + semantic context)
- E-commerce catalogs: α = 0.3–0.5 (article numbers + product descriptions)
How to choose α in practice: take 20–30 real queries
with known correct answers, run the search with α from 0.1 to 0.9
in steps of 0.1, and compare recall@5. This takes an hour and provides a concrete answer
for your domain.
Which Vector DBs support hybrid natively
| Vector DB |
Hybrid Support |
Merging Method |
Note |
| Qdrant |
✅ native |
RRF, DBSF |
Sparse vectors via
BM25 or SPLADE,
prefetch multi-stage
|
| Weaviate |
✅ native |
RRF, Relative Score Fusion, Learned Fusion (v1.25+) |
Easiest API:
single alpha parameter
|
| Elasticsearch |
✅ native |
RRF, Weighted RRF, Linear |
Powerful, but more complex setup.
Weighted RRF with v8.x
|
| pgvector |
⚠️ manual |
Separate BM25 (ts_vector) + merging in code |
Suitable if Postgres is already in use, but requires manual work |
| ChromaDB |
✅ with v0.6+ |
RRF via Rrf() API
|
Requires a sparse vector index, not available in legacy API |
A detailed comparison of vector DBs is in the article
ChromaDB, Qdrant, or pgvector: how to choose.
⚠️ Pitfalls
Incorrect α kills quality instead of improving it.
In the
WANDS (e-commerce) benchmark, RRF added only +1.7% Mean NDCG over dense-only.
If your queries are predominantly semantic and without exact terms, hybrid may not
provide a noticeable increase. Measure, don't trust defaults.
Double indexing = double resources.
Hybrid search requires both an inverted index (for BM25) and a vector index.
This means more RAM and more indexing time. For small projects
(<10K documents), the additional overhead may not be justified.
Domain α recommendations are guidelines, not absolute rules.
The optimal value depends on your corpus, language, and query types.
Always test on real data.
- ✔️ RRF is the de facto standard for hybrid search, works with ranks instead of scores
- ✔️ Weighted hybrid (α) provides control — but requires testing on real queries
- ✔️ Qdrant, Weaviate, Elasticsearch support hybrid natively
Section conclusion:
In my opinion, Hybrid search is the first and simplest step to improve RAG quality.
If your queries contain exact terms, the effect (ROI) is immediately noticeable.
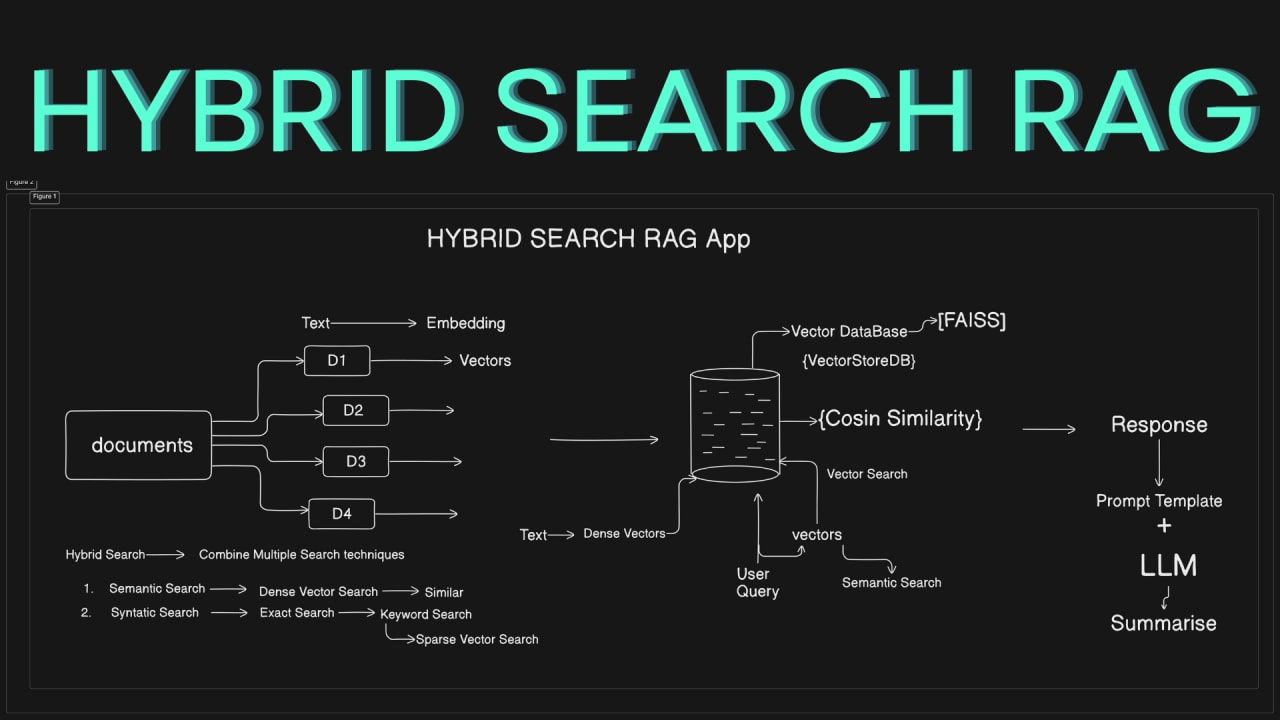
📌 Reranking: the second stage that changes everything
Reranking is the second stage of retrieval, where a cross-encoder model re-evaluates
each (query, document) pair and reorders candidates based on a more accurate relevance score. A typical architecture: hybrid search returns the top 50, reranker
selects the final 5–10 for the LLM. According to
Agentset Reranker Leaderboard (2026),
reranking consistently improves nDCG@10 and hit rate regardless of the embedding model.
A bi-encoder (embedding model) evaluates the query and document separately —
fast, but rough. A cross-encoder (reranker) evaluates the pair together —
accurate, but slow. The first is for filtering, the second for precise
ranking.
Why top-k from the first stage is not enough
An embedding model (bi-encoder) converts the query and document into vectors
independently of each other. This makes search fast — millions of documents can be compared in milliseconds. But this speed comes at the cost of accuracy: the model does not "see" the query and document simultaneously, so it may miss a subtle connection between them.
A cross-encoder (reranker) works differently. It takes the (query + document) pair
as a single input and processes them together through all layers of the transformer. This provides
a significantly more accurate relevance score — but each pair requires a separate pass
through the model. On 1 million documents, this would take minutes instead of milliseconds.
Analogy: a bi-encoder is scanning 1000 resumes for keywords.
A cross-encoder is interviewing each candidate. It's obvious that in the first
stage, you need to narrow down the list, and in the second, carefully select the best ones.
Two-Stage Retrieval: Architecture
Query → [Stage 1: Hybrid Search → top-50] → [Stage 2: Reranker → top-5] → LLM
Stage 1 (Hybrid Search): fast, rough selection. BM25 + dense
vectors + RRF return ~50 candidates in 20–50ms. The goal is to maximize recall:
ensure the correct document is somewhere in the list.
Stage 2 (Reranker): accurate re-ranking. A cross-encoder evaluates
each of the 50 (query, document) pairs and selects the final 5–10. Time: 100–300ms
depending on the model and number of documents. The goal is to maximize precision:
put the most relevant document first.
Why 50, not 20 or 200? It's a trade-off between recall and latency. Fewer than 20
candidates risk the relevant document not being included in the selection.
More than 100 makes the reranker a latency bottleneck.
ZeroEntropy (2026) recommends 50 documents for chatbots (where speed is important)
and 100–200 for comprehensive search tasks.
Lost in the Middle: how reranking solves positional bias
LLMs better utilize information from the beginning and end of the context window,
ignoring the middle. This is the "lost in the middle" effect, documented in
Stanford TACL research:
a 20–50% drop in accuracy for information placed in the middle of a long context. More details on this effect are in
the article on LLM context window, Section 3.
Reranker solves this indirectly but effectively. It doesn't just filter — it
orders. If the most relevant chunk is at position 47 out of 50,
the reranker will move it to position 1. And since the LLM's context is formed
from the top 5 reranker results, the most important information automatically
ends up at the beginning of the context — exactly where the LLM works most effectively.
Reranker Comparison (2026)
According to
Agentset Reranker Leaderboard (2026)
and
BSWEN comparison (2026):
| Reranker |
Type |
Quality |
Latency (50 docs) |
Price |
When to choose |
| Zerank-2 |
API |
Highest (ELO leader) |
~600ms |
~$0.05/1K queries |
Best quality, production |
| Voyage Rerank 2.5 |
API |
High |
~600ms |
Comparable to Cohere |
Quality/speed balance |
| Cohere Rerank 3.5 |
API |
High |
~600ms |
$2/1K queries |
Production, reliability, SLA |
| bge-reranker-v2-m3 |
Self-hosted |
High |
~80ms (GPU), ~350ms (CPU) |
$0 (GPU required) |
Confidential data, control |
| mxbai-rerank-large-v2 |
Self-hosted |
High (BEIR leader) |
~150ms (GPU) |
$0 (Apache 2.0) |
Open-source production |
| cross-encoder/ms-marco |
Self-hosted |
Medium |
~300ms (GPU) |
$0 |
Prototyping, budget |
An important nuance: according to Agentset,
Cohere v3.5 is the fastest among API solutions, but in terms of quality (ELO score)
it is inferior to Zerank and Voyage. BGE-v2-m3 on GPU competes with API solutions
in latency with zero cost per query, making it an optimal
choice for self-hosted production.
When reranking will NOT help
❌ Poor chunking → reranker sorts garbage → garbage remains garbage. If important information is split across chunks, even a perfect reranker won't stitch it back together. Details in
the article on chunking strategies.
❌ Incorrect embedding model → hybrid search doesn't find relevant candidates → reranker has nothing to sort. If the model performs poorly with your language or domain, replace it first.
❌ Dirty data (duplicates, outdated content) → reranker
will promote the "best" duplicate, but the problem will remain. Garbage in — garbage out.
⚠️ Pitfalls
"+48% quality" is marketing.
The figures from
Pinecone/Superlinked are best-case scenarios on ideal benchmarks. In real
projects, aim for a +15–25% retrieval improvement. If the effect on your corpus
is less than +5%, the problem is likely not with retrieval.
Latency budget.
Reranker adds 100–300ms to each query. For chatbots with an expected
response time of < 2s, this is a significant portion. Calculate the full pipeline:
embedding (20ms) + hybrid search (30ms) + reranker (200ms) + LLM (500–1500ms)
= 750–1750ms.
GPU for self-hosted.
BGE-reranker-v2 on CPU gives ~350ms latency. On GPU — ~80ms. A 4x difference
can determine if you fit within the latency budget.
BSWEN (2026) describes how the author almost abandoned BGE due to
testing on CPU.
- ✔️ Two-stage retrieval (hybrid → reranker) is a standard production architecture
- ✔️ Reranker solves both precision and lost in the middle
- ✔️ Self-hosted (BGE-v2-m3) competes with API solutions on GPU
From my experience:
Reranking is the second highest ROI step after hybrid search. It adds 100–300ms latency,
but significantly increases precision and eliminates positional bias.
The main limitation: reranker will not fix poor chunking or dirty data.
📌 Query Transformation: when the query is too "poor"
Query transformation refers to techniques for expanding or rephrasing a query
before searching. Multi-query generates several query variations to increase
recall. HyDE creates a "hypothetical answer" and searches using its vector.
Step-back prompting generalizes the query to a broader level. Each technique
adds 0.5–2 seconds of latency due to an additional LLM call.
Hybrid search + reranking solve 80% of retrieval problems. But there are
cases where the query itself is not informative enough for search.
This section is for those 20%.
Multi-query
An LLM generates 3–5 variations of the original query, each is searched separately,
and the results are combined using RRF. The technique is formalized as
RAG-Fusion (Rackauckas, 2024)
and integrates well with an existing hybrid pipeline.
When it works: ambiguous queries ("how to set this up" — what exactly?), queries
with implicit context.
When it's unnecessary: clear, specific queries where one phrasing is sufficient.
Latency: +500ms–1.5s (one LLM call to generate variations).
HyDE (Hypothetical Document Embeddings)
An LLM generates a "hypothetical ideal answer" to the query, and the embedding of this
answer is used for search. The original
paper by Gao et al. (2023).
When it works: short query, long expected answer. Query "OAuth" →
LLM generates a paragraph about the OAuth flow → the embedding of this paragraph searches for similar
documents much more accurately than the embedding of a single word "OAuth".
⚠️ Risk: in narrow domains (medicine, law), the LLM
may hallucinate a "hypothetical document" with incorrect facts — and the search
will go in the wrong direction. Use HyDE only in general domains
where the LLM has sufficient knowledge.
Latency: +1–2s (one LLM call).
Step-back Prompting
The LLM first formulates a broader question, then searches using it.
Query "why is bge-reranker-v2 slower on CPU" → step-back:
"how do cross-encoder rerankers work and what are their hardware requirements" →
searching with the broader query finds general documentation that contains
the answer to the specific question.
When it works: very specific queries where direct search yields no results.
Latency: +500ms–1s.
Latency Tax: table
| Technique |
Additional time |
LLM call |
When justified |
| Multi-query |
+0.5–1.5s |
✅ 1 call |
Ambiguous queries |
| HyDE |
+1–2s |
✅ 1 call |
Short queries, general domain |
| Step-back |
+0.5–1s |
✅ 1 call |
Highly specialized queries |
| No transformation |
0 |
❌ |
Clear specific queries |
⚠️ Pitfalls
HyDE in narrow domains is risky.
If the LLM lacks sufficient knowledge in your domain, the "hypothetical document"
will be incorrect, and the search will find irrelevant chunks. Test on 10–20
queries before implementation.
Latency adds up.
Multi-query + reranking = +2–3.5s to each query. For interactive
chatbots, this can be unacceptable. For batch processing or analytical
tasks, it's quite justified.
Section conclusion:
Query transformation is a tool for specific cases, not for all queries.
Implement it after hybrid search and reranking, and only if you observe
specific recall issues with certain types of queries.
📌 Practice: Minimal Code to Get Started
Hybrid search on Qdrant is implemented via the prefetch API with RRF fusion
in ~15 lines of Python code. To add reranking — another ~10 lines
with Cohere API or sentence-transformers. Below are copy-paste ready examples
for both options.
Hybrid Search + RRF on Qdrant (Python)
Qdrant natively supports hybrid search through the
Universal Query API with a prefetch mechanism. The example uses
built-in BM25 and dense vectors:
from qdrant_client import QdrantClient, models
client = QdrantClient(url="http://localhost:6333")
def hybrid_search(query: str, limit: int = 10):
"""Hybrid search with RRF: dense + sparse (BM25)."""
return client.query_points(
collection_name="my_documents",
prefetch=[
# Stage 1a: Dense vector search
models.Prefetch(
query=models.Document(
text=query,
model="sentence-transformers/all-MiniLM-L6-v2",
),
using="dense",
limit=50, # top-50 for recall
),
# Stage 1b: Sparse (BM25) search
models.Prefetch(
query=models.Document(
text=query,
model="Qdrant/bm25",
),
using="sparse",
limit=50,
),
],
# Merging via RRF
query=models.FusionQuery(fusion=models.Fusion.RRF),
limit=limit,
).points
# Usage
results = hybrid_search("article 42 of the data protection law")
for i, point in enumerate(results, 1):
print(f"{i}. {point.payload.get('title')} (Score: {point.score:.4f})")
The code is based on the
official Qdrant tutorial and the documentation for the
Query API.
Adding Reranking (Cohere API)
import cohere
co = cohere.Client("your-api-key")
def hybrid_search_with_rerank(query: str, top_k: int = 5):
"""Two-stage: hybrid search (top-50) → rerank (top-k)."""
# Stage 1: Hybrid search
candidates = hybrid_search(query, limit=50)
# Prepare documents for reranker
docs = [point.payload.get("text", "") for point in candidates]
# Stage 2: Reranking
reranked = co.rerank(
model="rerank-v3.5",
query=query,
documents=docs,
top_n=top_k,
)
# Return reranked results
return [
{
"text": docs[r.index][:200],
"relevance_score": r.relevance_score,
"original_rank": r.index + 1,
}
for r in reranked.results
]
How to Measure the Effect: Minimal A/B Test
I recommend: Before implementing in production, you need to ensure
that hybrid + reranking actually improves quality on *your* data. Minimal test:
- Collect 20–30 real queries with known correct answers (golden set)
- Run each query through: (a) pure vector search, (b) hybrid search, (c) hybrid + reranking
- Compare recall@5 (is the correct answer in the top 5) for each option
- If recall increased by <5% — the problem is likely not with retrieval, but with chunking or data quality
More details on retrieval metrics can be found in
How to Measure RAG Quality: Metrics, Tools.
⚠️ Pitfalls
Library versions.
Qdrant Query API (prefetch + fusion) is available from version 1.10+.
Check your qdrant-client version.
ChromaDB RRF API is available from v0.6+.
Cohere pricing may change.
As of March 2026 — $2/1K requests for Rerank 3.5. Check
current pricing before implementation.
Self-hosted reranker requires GPU.
BGE-reranker-v2-m3 on CPU gives ~350ms for 50 documents — may not fit
within the latency budget. On GPU (even T4) — ~80ms.
Section Conclusion:
Implementing hybrid search + reranking takes hours, not weeks. The key is to
measure the effect on real queries before deploying to production.
💼 Diagnostic Matrix: What to Implement First
I recommend: Implementation order: (1) hybrid search — minimal effort, maximum
effect, (2) reranking — +100–300ms, but significant precision improvement,
(3) query transformation — only if the first two steps are insufficient.
If none of the three help — the problem is with chunking or data quality,
not retrieval.
Decision Tree: What to Implement First
Your RAG is not finding what you need?
│
├─ Cannot find exact terms / IDs / codes?
│ └─ → Add BM25 (Hybrid Search)
│ Latency: +0ms (parallel search)
│ ROI: fastest
│
├─ Finds correct documents, but not in the top 3?
│ └─ → Add Reranking
│ Latency: +100–300ms
│ ROI: high for precision-critical tasks
│
├─ Queries are too short or ambiguous?
│ └─ → Try Multi-query or HyDE
│ Latency: +0.5–2s
│ ROI: depends on query type
│
├─ Large database, high noise in results?
│ └─ → Reranking + increase Stage 1 top-k to 100
│
└─ Nothing helps?
└─ → Problem with chunking or data quality, not retrieval
Check: chunking strategies, embedding model, data
Implementation Order
-
Hybrid search — minimal effort, maximum effect.
If your Vector DB supports hybrid natively (Qdrant, Weaviate,
Elasticsearch) — it's a configuration change, not a pipeline rewrite.
-
Reranking — adds 100–300ms, but significantly improves precision.
Start with Cohere API (minimum infrastructure), then migrate to self-hosted
BGE-v2-m3 if latency or cost become an issue.
-
Query Transformation — only if 1 and 2 are insufficient.
Each technique adds an LLM call and latency. Implement selectively —
not for all queries, but for the types where you see a recall problem.
❓ Frequently Asked Questions (FAQ)
Do I need hybrid search if I'm using BGE-M3 with native sparse?
Yes, but the implementation is simplified. BGE-M3 generates dense and sparse vectors
in one model — you don't need a separate BM25. However, RRF or another fusion
method is still needed to combine results. In Qdrant, this is implemented
using the same prefetch API.
How much does Cohere Rerank cost for 1000 queries per day?
As of March 2026: Cohere Rerank 3.5 costs ~$2 per 1000 requests
(with 50 documents reranked per request). 1000 requests/day = ~$60/month.
For comparison: self-hosted BGE-v2-m3 on a T4 GPU (~$150–300/month) becomes
more cost-effective at > 2500–5000 requests/day.
Can I use reranking without hybrid search?
Yes. Reranking works with any retriever — pure vector search, BM25,
or hybrid. But the combination of hybrid + reranking yields the best results, because
hybrid provides a broader and more diverse set of candidates for the reranker.
How does hybrid search affect latency?
Minimally. BM25 and vector search are executed in parallel, and RRF fusion
only adds rank calculations — microseconds. The main additional time comes from
reranking (100–300ms), not hybrid search itself.
How does RRF differ from weighted sum?
RRF works with ranks (positions), weighted sum with scores (numerical
values). RRF does not require normalization and is more stable with different score distributions. Weighted sum offers more control but requires scale calibration —
which is not always possible.
✅ Conclusions
- 🔹 Vector search alone is not sufficient: it dilutes exact terms and short queries; BM25 fills these gaps.
- 🔹 Hybrid search (BM25 + dense + RRF): the first and simplest step to improve quality.
- 🔹 Reranking (cross-encoder): the second stage; +100–300ms, but +8–25% precision, solves "lost in the middle".
- 🔹 Query transformation: for specific queries, adds latency due to LLM calls.
- 🔹 Implementation order: hybrid → reranking → query transform; if it doesn't help — the problem is with chunking or data.
- 🔹 Test on real queries: 20–30 queries with a golden set, recall@5 before and after — the minimum before production.
My main takeaway:
Hybrid search and reranking are not a replacement for a good embedding model or
proper chunking. They are the next layer of optimization for a RAG system that
is already working but requires higher accuracy. Implement gradually, measure
each step, and don't believe marketing figures of "+48%" — aim for a realistic
+15–25%.
If you want to dive deeper into retrieval architecture —
ColBERT, Vector DB Internals (🔴 Advanced, coming soon).
If you need to systematically measure quality —
📖 Sources
