
Ihre RAG-Pipeline funktioniert. Antworten werden generiert, Retrieval liefert Ergebnisse.
Aber der Benutzer sucht nach get_user_v2 – und bekommt statt der Dokumentation
einen Artikel über Benutzerverwaltung. Oder fragt nach "Artikel 42 des Gesetzes zum Schutz personenbezogener Daten" – und die Vektorsuche liefert drei Chunks über die DSGVO, aber keiner enthält den Text des gesuchten Artikels.
Spoiler: Das Problem liegt weder an der LLM noch am Embedding-Modell. Das Problem
ist, dass reine Vektorsuche nach Sinn sucht – aber manchmal wird
Text benötigt. Hybrid Search + Reranking schließen diese Lücke und liefern +15–25 %
Retrieval-Qualität in realen Projekten, ohne das Modell zu ändern.
⚡ Kurz gesagt
- ✅ Vektorsuche vs. BM25: Sinn vs. Schlüsselwörter – eine Kombination ist erforderlich
- ✅ Hybrid Search: Zusammenführung über RRF, nicht über Score-Normalisierung
- ✅ Reranking: +8–25 % Qualität durch Cross-Encoder
- 🎯 Sie erhalten: Wann und wie man Hybrid + Reranking mit Code anwendet
- 👇 Unten – Architektur, Formeln und Beispiele
📚 Inhalt des Artikels
🎯 Abschnitt 1. Zwei Suchtypen: Warum jeder auf seine Weise stark ist
BM25 (Keyword-Suche) findet exakte Übereinstimmungen – Artikelnummern, IDs, Methodennamen.
Dense Vector Search findet semantisch ähnliche Dokumente – Synonyme,
Paraphrasen, sprachübergreifende Anfragen. Keiner dieser Ansätze ist ausreichend
für produktives RAG: BM25 versteht keinen Sinn, und Vektorsuche "verwässert"
exakte Werte.
Wenn Vektorsuche "finde etwas Ähnliches im Inhalt" bedeutet, dann ist BM25
"finde das Dokument, das genau dieses Wort enthält". Produktives RAG benötigt beides.
BM25 (Keyword Search): Warum der Algorithmus von 1994 immer noch lebt
BM25 (Best Matching 25) ist ein klassischer Ranking-Algorithmus, der die
Relevanz eines Dokuments anhand von drei Faktoren bewertet: Termhäufigkeit im Dokument (TF),
inverse Dokumenthäufigkeit (IDF) und Dokumentenlänge. Der Algorithmus wurde
1994 von Robertson und Walker formalisiert und ist bis heute der Standard für die Keyword-Suche in Elasticsearch, OpenSearch und den meisten Suchmaschinen.
Warum ist er seit 30 Jahren nicht verschwunden? Weil es für bestimmte Arten von Anfragen nichts Besseres gibt. Wenn ein Benutzer nach SKU-4521, get_user_v2
oder "Artikel 42" sucht – ist das eine Exact-Match-Aufgabe. Ein Embedding-Modell wandelt
SKU-4521 in einen Vektor um, der den allgemeinen "Sinn" einer Produktartikelnummer beschreibt,
aber der Unterschied zwischen 4521 und 4522 ist in diesem Vektor minimal.
BM25 findet die exakte Übereinstimmung in Millisekunden – ohne neuronale Netze, ohne GPUs,
ohne Embeddings.
Wo BM25 unersetzlich ist: Artikel- und Produktcodes, Namen von Funktionen und API-Endpunkten,
Nummern von Dokumenten und Gesetzesartikeln, seltene Begriffe und Akronyme, exakte Zitate.
Einschränkungen von BM25: "Auto" ≠ "Wagen". Wenn der Benutzer "Abonnement kündigen" schreibt,
und im Dokument steht "Tarif ablehnen", findet BM25 nichts, da kein gemeinsames Wort vorhanden ist.
Dense Vector Search (Semantisch): Die Kraft des Kontexts
Dense Vector Search funktioniert anders. Die Anfrage und die Dokumente werden in numerische
Vektoren (Embeddings) umgewandelt, und die Suche erfolgt über
Kosinus-Ähnlichkeit – den Winkel zwischen den Vektoren im Bedeutungsraum.
"Abonnement kündigen" und "Tarif ablehnen" erhalten nahe Vektoren,
weil das Embedding-Modell gelernt hat, dass diese Phrasen dasselbe bedeuten.
Wo Dense Vector Search unersetzlich ist: Semantische Suche nach Synonymen und
Paraphrasen, sprachübergreifende Anfragen (eine Anfrage auf Ukrainisch findet ein Dokument auf Englisch), Anfragen in natürlicher Sprache ("wie kann ich die Infrastrukturkosten senken").
Einschränkungen: Das Embedding "verwässert" exakte Bedeutungen. Zwei verschiedene Artikelnummern erhalten
fast den gleichen Vektor. Kurze Anfragen mit einem oder zwei Wörtern ergeben einen unscharfen Vektor.
Details zu diesen Einschränkungen – im
Artikel über Embeddings
Tabelle: Wann was funktioniert
| Anfragetyp |
BM25 |
Dense Vector |
Hybrid |
get_user_v2 (exakter Begriff) |
✅ exakte Übereinstimmung |
❌ verwässert |
✅ |
| "Abonnement kündigen" (semantisch) |
❌ keine Wortübereinstimmungen |
✅ Semantik |
✅ |
| "Artikel 42 des Datenschutzgesetzes" (gemischt) |
✅ "Artikel 42" |
✅ "Datenschutz" |
✅✅ beide Signale |
| "pricing" (1 Wort) |
⚠️ zu breit |
⚠️ unscharfer Vektor |
⚠️ Query Transform benötigt |
- ✔️ BM25: Unersetzlich für Exact Match – IDs, Artikelnummern, Funktionsnamen
- ✔️ Dense Vektoren: Unersetzlich für semantische Suche – Synonyme, Paraphrasen, sprachübergreifend
- ✔️ Keiner der Ansätze ist für produktives RAG allein ausreichend
Fazit des Abschnitts:
BM25 und Dense Vector Search sind keine Konkurrenten, sondern komplementäre Werkzeuge.
Ersteres findet Wörter, letzteres den Sinn. Produktives RAG benötigt beides.
📌 Abschnitt 2. Hybrid Search: Wie man beide Ansätze kombiniert
Hybrid Search führt BM25 und Dense Vector Search parallel aus und kombiniert dann
die Ergebnisse über Reciprocal Rank Fusion (RRF) – ein Algorithmus, der
die Positionen im Ranking anstelle von Scores verwendet. RRF benötigt keine Normalisierung
und funktioniert stabil mit unterschiedlichen Datenquellen. In Benchmarks
von Weaviate (2025)
übertrifft Hybrid Search mit RRF die besten Single-Methoden um 2,6–13,4
Punkte nDCG@10.
Das Hauptproblem bei der Kombination von Ergebnissen aus BM25 und Vektorsuche ist, dass ihre Scores
auf unterschiedlichen Skalen liegen und nicht einfach addiert werden können. RRF umgeht dieses Problem elegant,
indem es mit Rängen statt mit Zahlen arbeitet.
Reciprocal Rank Fusion (RRF): Eine einfache und zuverlässige Zusammenführungsmethode
RRF wurde
2009 von Cormack, Clarke und Buettcher (SIGIR '09) vorgeschlagen und ist seitdem zum De-facto-Standard für Hybrid Search geworden. Die Formel lautet:
score(d) = Σ 1 / (k + rank(d))
wobei rank(d) die Position des Dokuments in jedem einzelnen Ranking ist
und k eine Glättungskonstante ist (Standardwert: 60).
Warum k = 60? Wie in der
Elasticsearch-Dokumentation erklärt, verhindert diese Konstante den übermäßigen Einfluss
der ersten Position. Ohne Glättung ist der Unterschied zwischen Rang 1 (Score = 1,0) und
Rang 2 (Score = 0,5) zweifach. Mit k = 60 ist der Unterschied zwischen
Rang 1 (1/61 ≈ 0,0164) und Rang 2 (1/62 ≈ 0,0161) minimal, was die Zusammenführung stabiler macht.
Warum ist RRF besser als eine lineare Kombination von Scores? Drei Gründe.
Erstens gibt BM25 Scores in einem beliebigen Bereich zurück (von 0 bis Dutzenden),
und die Kosinus-Ähnlichkeit liegt zwischen -1 und 1. Die Normalisierung dieser Skalen auf einen gemeinsamen
Bereich ist eine nicht-triviale Aufgabe, die von der Score-Verteilung in
einem bestimmten Korpus abhängt. RRF arbeitet ausschließlich mit Positionen und ignoriert absolute
Scores.
Zweitens ist RRF unempfindlich gegenüber Ausreißern: Ein Dokument mit einem anomal hoch bewerteten
BM25-Score zieht nicht das gesamte Ranking auf sich.
Drittens, wie von
OpenSearch (2025) festgestellt, verstärkt RRF natürlich Dokumente, die
gleichzeitig in den oberen Positionen mehrerer Rankings erscheinen – was ein starkes Signal für Relevanz ist.
Beispiel mit Zahlen
BM25 gibt zurück: [Doc A (Rang 1), Doc C (Rang 2), Doc B (Rang 3)]
Dense gibt zurück: [Doc B (Rang 1), Doc A (Rang 2), Doc D (Rang 3)]
RRF-Scores (k=60):
- Doc A: 1/(60+1) + 1/(60+2) = 0,0164 + 0,0161 = 0,0325 ← gewinnt
- Doc B: 1/(60+3) + 1/(60+1) = 0,0159 + 0,0164 = 0,0323
- Doc C: 1/(60+2) + 0 = 0,0161
- Doc D: 0 + 1/(60+3) = 0,0159
Ergebnis: [A, B, C, D]. Doc A gewinnt, da es konstant in den oberen Positionen
beider Rankings liegt.
Weighted Hybrid: Wenn Kontrolle über α (Alpha) benötigt wird
RRF gibt jedem Suchverfahren die gleiche Gewichtung. Aber das ist nicht immer optimal.
Für technische Dokumentation mit vielen exakten Begriffen sollte BM25 "lauter" sein. Für Kundensupport mit natürlichsprachlichen Anfragen sind Dense Vektoren wichtiger.
Die meisten Vektor-DBs unterstützen den Parameter α (Alpha), wobei
α = 0,0 – reines BM25, α = 1,0 – reines Vektor-Suchsystem ist.
Die Weaviate-Dokumentation
ermöglicht die direkte Einstellung von Alpha in der Anfrage.
Elasticsearch unterstützt ab Version 8.x Weighted RRF – jeder Retriever
erhält sein eigenes Gewicht.
Empfehlungen für Domänen (ungefähre Werte – testen Sie mit Ihren Daten):
- Technische Dokumentation, Code: α = 0,3–0,4 (mehr Keywords)
- Allgemeiner Inhalt, Kundensupport: α = 0,6–0,7 (mehr Semantik)
- Juristische Texte: α = 0,4–0,5 (Balance: exakte Artikel + semantischer Kontext)
- E-Commerce-Kataloge: α = 0,3–0,5 (Artikelnummern + Produktbeschreibungen)
Wie man α in der Praxis auswählt: Nehmen Sie 20–30 reale Anfragen
mit bekannten richtigen Antworten, führen Sie die Suche mit α von 0,1 bis 0,9
in Schritten von 0,1 durch, vergleichen Sie Recall@5. Das dauert eine Stunde und liefert eine konkrete Antwort
für Ihre Domäne.
Welche Vektor-DBs unterstützen Hybrid nativ
| Vektor-DB |
Hybrid-Unterstützung |
Zusammenführungsmethode |
Hinweis |
| Qdrant |
✅ nativ |
RRF, DBSF |
Sparse Vektoren über
BM25 oder SPLADE,
Prefetch Multi-Stage
|
| Weaviate |
✅ nativ |
RRF, Relative Score Fusion, Learned Fusion (v1.25+) |
Einfachstes API:
ein Alpha-Parameter
|
| Elasticsearch |
✅ nativ |
RRF, Weighted RRF, Linear |
Leistungsstark, aber komplexeres Setup.
Weighted RRF ab v8.x
|
| pgvector |
⚠️ manuell |
Separates BM25 (ts_vector) + Zusammenführung im Code |
Geeignet, wenn Postgres bereits vorhanden ist, erfordert aber manuelle Arbeit |
| ChromaDB |
✅ ab v0.6+ |
RRF über Rrf() API
|
Erfordert Sparse-Vektor-Index, nicht im Legacy-API verfügbar |
Ein detaillierter Vergleich von Vektor-DBs – im Artikel
ChromaDB, Qdrant oder pgvector: Wie wählt man die richtige Vektor-DB für sein Projekt aus.
⚠️ Fallstricke
Falsches α zerstört die Qualität statt sie zu verbessern.
Im Benchmark
WANDS (E-Commerce) fügte RRF nur +1,7 % Mean NDCG über Dense-Only hinzu.
Wenn Ihre Anfragen überwiegend semantisch und ohne exakte Begriffe sind – kann Hybrid keine spürbare Verbesserung bringen. Messen Sie, glauben Sie nicht den Standardwerten.
Doppelte Indizierung = doppelte Ressourcen.
Hybrid Search erfordert sowohl einen invertierten Index (für BM25) als auch einen Vektorindex.
Das bedeutet mehr RAM und mehr Zeit für die Indizierung. Für kleine Projekte
(<10K Dokumente) kann der zusätzliche Overhead unrentabel sein.
α-Empfehlungen für Domänen sind Richtwerte, keine absoluten Regeln.
Der optimale Wert hängt von Ihrem Korpus, Ihrer Sprache und der Art der Anfragen ab.
Testen Sie immer mit realen Daten.
- ✔️ RRF – De-facto-Standard für Hybrid Search, arbeitet mit Rängen statt Scores
- ✔️ Weighted Hybrid (α) bietet Kontrolle – erfordert aber Tests mit realen Anfragen
- ✔️ Qdrant, Weaviate, Elasticsearch unterstützen Hybrid nativ
Fazit des Abschnitts:
Meiner Meinung nach ist Hybrid Search der erste und einfachste Schritt zur Verbesserung der RAG-Qualität.
Wenn Ihre Anfragen exakte Begriffe enthalten – ist der Effekt (ROI) sofort spürbar.
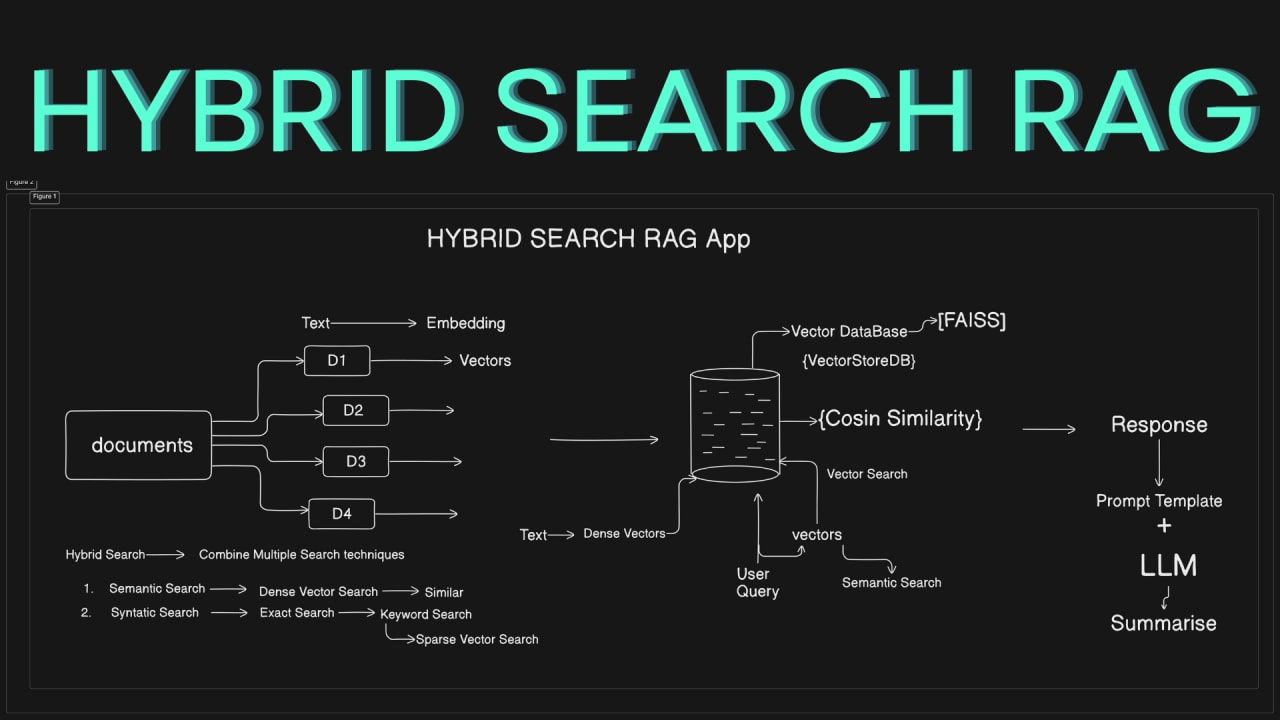
📌 Reranking: die zweite Stufe, die alles verändert
Reranking ist die zweite Stufe des Retrieval, bei der ein Cross-Encoder-Modell jedes Paar (Abfrage, Dokument) neu bewertet und die Kandidaten nach einer genaueren Relevanzbewertung neu ordnet. Typische Architektur: Hybrid Search liefert die Top-50, Reranker wählt die finalen 5–10 für die LLM aus. Laut
Agentset Reranker Leaderboard (2026)
verbessert Reranking konstant nDCG@10 und Hit Rate, unabhängig vom Embedding-Modell.
Ein Bi-Encoder (Embedding-Modell) bewertet Abfrage und Dokument getrennt – schnell, aber grob. Ein Cross-Encoder (Reranker) bewertet das Paar gemeinsam – präzise, aber langsam. Ersteres dient zum Aussortieren, letzteres zur genauen Rangfolge.
Warum Top-k aus der ersten Stufe nicht ausreicht
Ein Embedding-Modell (Bi-Encoder) wandelt Abfrage und Dokument in Vektoren um, unabhängig voneinander. Das macht die Suche schnell – Millionen von Dokumenten können in Millisekunden verglichen werden. Aber diese Geschwindigkeit geht auf Kosten der Präzision: Das Modell "sieht" Abfrage und Dokument nicht gleichzeitig und erfasst möglicherweise keine feinen Zusammenhänge zwischen ihnen.
Ein Cross-Encoder (Reranker) funktioniert anders. Er nimmt ein Paar (Abfrage + Dokument) als einzigen Input und verarbeitet es gemeinsam durch alle Schichten des Transformers. Das liefert eine deutlich präzisere Relevanzbewertung – aber jedes Paar erfordert einen separaten Durchlauf durch das Modell. Bei 1 Million Dokumenten würde dies Minuten statt Millisekunden dauern.
Analogie: Ein Bi-Encoder ist das Durchsuchen von 1000 Lebensläufen nach Schlüsselwörtern. Ein Cross-Encoder ist ein Vorstellungsgespräch mit jedem Kandidaten. Offensichtlich muss in der ersten Stufe die Liste gekürzt und in der zweiten sorgfältig die Besten ausgewählt werden.
Two-Stage Retrieval: Architektur
Abfrage → [Stufe 1: Hybrid Search → Top-50] → [Stufe 2: Reranker → Top-5] → LLM
Stufe 1 (Hybrid Search): Schnelle, grobe Auswahl. BM25 + Dense Vectors + RRF liefern ca. 50 Kandidaten in 20–50 ms. Ziel ist die Maximierung des Recalls: Sicherstellen, dass das richtige Dokument irgendwo in der Liste ist.
Stufe 2 (Reranker): Präzise Neuanordnung. Ein Cross-Encoder bewertet jedes der 50 Paare (Abfrage, Dokument) und wählt die finalen 5–10 aus. Zeit: 100–300 ms, abhängig vom Modell und der Anzahl der Dokumente. Ziel ist die Maximierung der Precision: Das relevanteste an die erste Stelle setzen.
Warum 50 und nicht 20 oder 200? Das ist ein Kompromiss zwischen Recall und Latenz. Weniger als 20 Kandidaten – das Risiko, dass ein relevantes Dokument nicht in die Auswahl gelangt. Mehr als 100 – der Reranker wird zum Latenz-Bottleneck.
ZeroEntropy (2026) empfiehlt 50 Dokumente für Chatbots (wo Geschwindigkeit wichtig ist) und 100–200 für umfassende Suchaufgaben.
Lost in the Middle: Wie Reranking das Problem des Positionsbias löst
LLMs nutzen Informationen vom Anfang und Ende des Kontextfensters besser und ignorieren die Mitte. Dies ist der "Lost in the Middle"-Effekt, dokumentiert in einer
Stanford TACL-Studie: ein Genauigkeitsabfall von 20–50 % für Informationen, die in der Mitte eines langen Kontexts platziert sind. Mehr über diesen Effekt erfahren Sie in der
Artikel über das LLM-Kontextfenster, Abschnitt 3.
Der Reranker löst dies indirekt, aber effektiv. Er filtert nicht nur – er
ordnet. Wenn der relevanteste Chunk an Position 47 von 50 steht, hebt der Reranker ihn auf Position 1. Da der LLM-Kontext aus den Top-5-Ergebnissen des Rerankers gebildet wird, landen die wichtigsten Informationen automatisch am Anfang des Kontexts – genau dort, wo die LLM am effektivsten arbeitet.
Vergleich von Rerankern (2026)
Laut
Agentset Reranker Leaderboard (2026)
und
BSWEN-Vergleich (2026):
| Reranker |
Typ |
Qualität |
Latenz (50 Docs) |
Preis |
Wann wählen |
| Zerank-2 |
API |
Höchste (ELO-Leader) |
~600ms |
~$0.05/1K Anfragen |
Beste Qualität, Produktion |
| Voyage Rerank 2.5 |
API |
Hoch |
~600ms |
Vergleichbar mit Cohere |
Gleichgewicht Qualität/Geschwindigkeit |
| Cohere Rerank 3.5 |
API |
Hoch |
~600ms |
$2/1K Anfragen |
Produktion, Zuverlässigkeit, SLA |
| bge-reranker-v2-m3 |
Self-hosted |
Hoch |
~80ms (GPU), ~350ms (CPU) |
$0 (GPU erforderlich) |
Vertrauliche Daten, Kontrolle |
| mxbai-rerank-large-v2 |
Self-hosted |
Hoch (BEIR-Leader) |
~150ms (GPU) |
$0 (Apache 2.0) |
Open-Source-Produktion |
| cross-encoder/ms-marco |
Self-hosted |
Mittel |
~300ms (GPU) |
$0 |
Prototyping, Budget |
Wichtiger Hinweis: Laut Agentset ist
Cohere v3.5 – das schnellste unter den API-Lösungen, aber in Bezug auf die Qualität (ELO-Score) liegt es hinter Zerank und Voyage. BGE-v2-m3 auf GPU konkurriert mit API-Lösungen bei der Latenz bei null Kosten pro Anfrage, was es zur optimalen Wahl für Self-hosted-Produktion macht.
Wann Reranking NICHT hilft
❌ Schlechte Chunking → Reranker sortiert Müll → Müll bleibt Müll. Wenn wichtige Informationen über Chunks verteilt sind – selbst ein perfekter Reranker kann sie nicht wieder zusammensetzen. Mehr dazu in der
Artikel über Chunking-Strategien.
❌ Falsches Embedding-Modell → Hybrid Search findet keine relevanten Kandidaten → Reranker hat nichts zu sortieren. Wenn das Modell mit Ihrer Sprache oder Ihrem Domänen schlecht funktioniert – ersetzen Sie es zuerst.
❌ Unsaubere Daten (Duplikate, veraltete Inhalte) → Reranker hebt das "beste" Duplikat hervor, aber das Problem bleibt bestehen. Garbage in – garbage out.
⚠️ Fallstricke
"+48% Qualität" – das ist Marketing.
Die Zahlen von
Pinecone/Superlinked – Best-Case-Szenarien auf idealen Benchmarks. In realen Projekten zielen Sie auf eine Verbesserung des Retrievals um +15–25 %. Wenn der Effekt auf Ihrem Korpus weniger als +5 % beträgt – das Problem liegt wahrscheinlich nicht beim Retrieval.
Latenz-Budget.
Reranking fügt jeder Anfrage 100–300 ms hinzu. Für interaktive Chatbots mit einer erwarteten Antwortzeit von < 2 s ist dies ein erheblicher Anteil. Berechnen Sie die gesamte Pipeline:
Embedding (20 ms) + Hybrid Search (30 ms) + Reranker (200 ms) + LLM (500–1500 ms)
= 750–1750 ms.
GPU für Self-hosted.
BGE-reranker-v2 auf CPU liefert ~350 ms Latenz. Auf GPU – ~80 ms. Ein Unterschied von 4x kann entscheiden, ob Sie das Latenz-Budget einhalten.
BSWEN (2026) beschreibt, wie der Autor BGE aufgrund von CPU-Tests fast aufgegeben hätte.
- ✔️ Two-stage Retrieval (Hybrid → Reranker) – Standard-Produktionsarchitektur
- ✔️ Reranker löst sowohl Precision als auch Lost in the Middle
- ✔️ Self-hosted (BGE-v2-m3) konkurriert mit API-Lösungen auf GPU
Aus meiner Erfahrung:
Reranking ist der zweitwichtigste Schritt nach Hybrid Search in Bezug auf den ROI. Es fügt 100–300 ms Latenz hinzu, erhöht aber die Precision erheblich und beseitigt Positionsbias.
Die Haupteinschränkung: Reranker kann schlechtes Chunking oder unsaubere Daten nicht beheben.
📌 Query Transformation: Wenn die Abfrage zu "arm" ist
Query Transformation sind Techniken zur Erweiterung oder Umformulierung der Abfrage vor der Suche. Multi-Query generiert mehrere Abfragevarianten zur Steigerung des Recalls. HyDE erstellt eine "hypothetische Antwort" und sucht nach deren Vektor. Step-back Prompting verallgemeinert die Abfrage auf eine breitere Ebene. Jede Technik fügt 0,5–2 Sekunden Latenz hinzu, da ein zusätzlicher LLM-Aufruf erforderlich ist.
Hybrid Search + Reranking lösen 80 % der Retrieval-Probleme. Aber es gibt Fälle, in denen die Abfrage selbst nicht informativ genug für die Suche ist.
Dieser Abschnitt ist für diese 20 %.
Multi-Query
Die LLM generiert 3–5 Varianten der ursprünglichen Abfrage, jede wird separat gesucht, die Ergebnisse werden über RRF zusammengeführt. Die Technik ist als
RAG-Fusion (Rackauckas, 2024)
formuliert und lässt sich gut in die bestehende Hybrid-Pipeline integrieren.
Wann es funktioniert: Mehrdeutige Abfragen ("Wie konfiguriere ich das?" – was genau?), Abfragen mit implizitem Kontext.
Wann es überflüssig ist: Klare, spezifische Abfragen, bei denen eine Formulierung ausreicht.
Latenz: +500 ms–1,5 s (ein LLM-Aufruf zur Generierung von Varianten).
HyDE (Hypothetical Document Embeddings)
Die LLM generiert eine "hypothetische ideale Antwort" auf die Abfrage, das Embedding dieser Antwort wird für die Suche verwendet. Die ursprüngliche
Artikel Gao et al. (2023).
Wann es funktioniert: Kurze Abfrage, lange erwartete Antwort. Abfrage "OAuth" → LLM generiert einen Absatz über den OAuth-Flow → das Embedding dieses Absatzes sucht nach ähnlichen Dokumenten deutlich präziser als das Embedding eines einzelnen Wortes "OAuth".
⚠️ Risiko: In engen Domänen (Medizin, Recht) kann die LLM ein "hypothetisches Dokument" mit falschen Fakten halluzinieren – und die Suche geht in die falsche Richtung. Verwenden Sie HyDE nur in allgemeinen Domänen, in denen die LLM über ausreichend Wissen verfügt.
Latenz: +1–2 s (ein LLM-Aufruf).
Step-back Prompting
Die LLM formuliert zuerst eine breitere Frage und sucht dann danach.
Abfrage "Warum ist bge-reranker-v2 auf CPU langsamer?" → Step-back:
"Wie funktionieren Cross-Encoder-Reranker und welche Hardware-Anforderungen haben sie?" → Die Suche nach der breiteren Abfrage findet allgemeine Dokumentation, die auch die Antwort auf die spezifische Frage enthält.
Wann es funktioniert: Sehr spezifische Abfragen, bei denen die direkte Suche keine Ergebnisse liefert.
Latenz: +500 ms–1 s.
Latenz-Steuer: Tabelle
| Technik |
Zusätzliche Zeit |
LLM-Aufruf |
Wann gerechtfertigt |
| Multi-Query |
+0.5–1.5s |
✅ 1 Aufruf |
Mehrdeutige Abfragen |
| HyDE |
+1–2s |
✅ 1 Aufruf |
Kurze Abfragen, allgemeine Domäne |
| Step-back |
+0.5–1s |
✅ 1 Aufruf |
Eng spezialisierte Abfragen |
| Ohne Transformation |
0 |
❌ |
Klare spezifische Abfragen |
⚠️ Fallstricke
HyDE in engen Domänen – Risiko.
Wenn die LLM nicht über ausreichend Wissen in Ihrer Domäne verfügt, ist das "hypothetische Dokument" falsch, und die Suche findet irrelevante Chunks. Testen Sie 10–20 Abfragen, bevor Sie es einführen.
Latenz addiert sich.
Multi-Query + Reranking = +2–3,5 s pro Anfrage. Für interaktive Chatbots kann dies unzumutbar sein. Für Batch-Verarbeitung oder analytische Aufgaben – durchaus gerechtfertigt.
Fazit des Abschnitts:
Query Transformation ist ein Werkzeug für spezielle Fälle, nicht für alle Abfragen. Führen Sie es nach Hybrid Search und Reranking ein, und nur, wenn Sie spezifische Probleme mit dem Recall bei bestimmten Abfragetypen feststellen.
📌 Praxis: Minimaler Code für den Start
Hybrid Search auf Qdrant wird über die prefetch API mit RRF fusion für ca. 15 Zeilen Python-Code implementiert. Zum Hinzufügen von Reranking sind weitere ~10 Zeilen mit der Cohere API oder sentence-transformers erforderlich. Unten finden Sie "copy-paste-fertige" Beispiele für beide Optionen.
Hybrid Search + RRF auf Qdrant (Python)
Qdrant unterstützt Hybrid Search nativ über die
Universal Query API mit einem Prefetch-Mechanismus. Das Beispiel verwendet
eingebautes BM25 und dichte Vektoren:
from qdrant_client import QdrantClient, models
client = QdrantClient(url="http://localhost:6333")
def hybrid_search(query: str, limit: int = 10):
"""Hybrid Search mit RRF: dense + sparse (BM25)."""
return client.query_points(
collection_name="my_documents",
prefetch=[
# Stage 1a: Dense Vektor-Suche
models.Prefetch(
query=models.Document(
text=query,
model="sentence-transformers/all-MiniLM-L6-v2",
),
using="dense",
limit=50, # Top-50 für Recall
),
# Stage 1b: Sparse (BM25) Suche
models.Prefetch(
query=models.Document(
text=query,
model="Qdrant/bm25",
),
using="sparse",
limit=50,
),
],
# Zusammenführung über RRF
query=models.FusionQuery(fusion=models.Fusion.RRF),
limit=limit,
).points
# Verwendung
results = hybrid_search("Artikel 42 des Datenschutzgesetzes")
for i, point in enumerate(results, 1):
print(f"{i}. {point.payload.get('title')} (Score: {point.score:.4f})")
Der Code basiert auf dem
offiziellen Qdrant-Tutorial und der Dokumentation der
Query API.
Hinzufügen von Reranking (Cohere API)
import cohere
co = cohere.Client("your-api-key")
def hybrid_search_with_rerank(query: str, top_k: int = 5):
"""Zweistufig: Hybrid Search (Top-50) → Rerank (Top-k)."""
# Stage 1: Hybrid Search
candidates = hybrid_search(query, limit=50)
# Dokumente für den Reranker formatieren
docs = [point.payload.get("text", "") for point in candidates]
# Stage 2: Reranking
reranked = co.rerank(
model="rerank-v3.5",
query=query,
documents=docs,
top_n=top_k,
)
# Neu sortierte Ergebnisse zurückgeben
return [
{
"text": docs[r.index][:200],
"relevance_score": r.relevance_score,
"original_rank": r.index + 1,
}
for r in reranked.results
]
Wie man den Effekt misst: minimaler A/B-Test
Ich empfehle: Bevor Sie in die Produktion gehen, müssen Sie sicherstellen,
dass Hybrid + Reranking die Qualität auf *Ihren* Daten wirklich verbessert. Minimaler Test:
- Sammeln Sie 20–30 reale Anfragen mit bekannten richtigen Antworten (Golden Set)
- Führen Sie jede Anfrage durch: (a) reiner Vektor-Suche, (b) Hybrid Search, (c) Hybrid + Reranking
- Vergleichen Sie Recall@5 (ob die richtige Antwort unter den Top-5 ist) für jede Variante
- Wenn der Recall um <5% steigt – liegt das Problem wahrscheinlich nicht beim Retrieval, sondern beim Chunking oder der Datenqualität
Mehr über Retrieval-Metriken erfahren Sie in
Wie man die Qualität von RAG misst: Metriken, Tools .
⚠️ Fallstricke
Bibliotheksversionen.
Die Qdrant Query API (prefetch + fusion) ist ab Version 1.10+ verfügbar.
Überprüfen Sie Ihre qdrant-client-Version.
Die ChromaDB RRF API ist ab v0.6+ verfügbar.
Cohere-Preise können sich ändern.
Stand März 2026 – 2 $/1K Anfragen für Rerank 3.5. Überprüfen Sie
die aktuellen Preise vor der Implementierung.
Self-hosted Reranker benötigt GPU.
BGE-reranker-v2-m3 auf CPU gibt ~350ms für 50 Dokumente – passt möglicherweise nicht
in das Latenzbudget. Auf GPU (auch T4) – ~80ms.
Fazit des Abschnitts:
Die Implementierung von Hybrid Search + Reranking dauert Stunden, nicht Wochen. Das Wichtigste ist,
den Effekt auf realen Anfragen zu messen, bevor Sie in die Produktion gehen.
💼 Diagnosematrix: Was zuerst implementieren
Ich empfehle: Reihenfolge der Implementierung: (1) Hybrid Search – minimaler Aufwand, maximaler
Effekt, (2) Reranking – +100–300ms, aber deutliche Verbesserung der Präzision,
(3) Query Transformation – nur wenn die ersten beiden Schritte nicht ausreichen.
Wenn keines der drei hilft – liegt das Problem beim Chunking oder der Datenqualität,
nicht beim Retrieval.
Entscheidungsbaum: Was zuerst implementieren
Findet Ihr RAG nicht das Richtige?
│
├─ Findet keine exakten Begriffe / IDs / Codes?
│ └─ → BM25 hinzufügen (Hybrid Search)
│ Latenz: +0ms (parallele Suche)
│ ROI: am schnellsten
│
├─ Findet die richtigen Dokumente, aber nicht in den Top 3?
│ └─ → Reranking hinzufügen
│ Latenz: +100–300ms
│ ROI: hoch für präzisionskritische Aufgaben
│
├─ Anfragen zu kurz oder mehrdeutig?
│ └─ → Multi-Query oder HyDE versuchen
│ Latenz: +0.5–2s
│ ROI: abhängig vom Anfragetyp
│
├─ Große Datenbank, hoher Rauschpegel in den Ergebnissen?
│ └─ → Reranking + Erhöhen von top-k Stage 1 auf 100
│
└─ Nichts hilft?
└─ → Problem beim Chunking oder der Datenqualität, nicht beim Retrieval
Prüfen Sie: Chunking-Strategien, Embedding-Modell, Daten
Reihenfolge der Implementierung
-
Hybrid Search – minimaler Aufwand, maximaler Effekt.
Wenn Ihre Vektor-DB Hybrid nativ unterstützt (Qdrant, Weaviate,
Elasticsearch) – ist dies eine Konfigurationsänderung, keine Umschreibung der Pipeline.
-
Reranking – fügt 100–300ms hinzu, verbessert aber die Präzision erheblich.
Beginnen Sie mit der Cohere API (minimale Infrastruktur), migrieren Sie dann zu Self-hosted
BGE-v2-m3, wenn Latenz oder Kosten zum Problem werden.
-
Query Transformation – nur wenn 1 und 2 nicht ausreichen.
Jede Technik fügt einen LLM-Aufruf und Latenz hinzu. Implementieren Sie selektiv –
nicht für alle Anfragen, sondern für die Arten, bei denen Sie ein Recall-Problem sehen.
❓ Häufig gestellte Fragen (FAQ)
Brauche ich Hybrid Search, wenn ich BGE-M3 mit nativem Sparse verwende?
Ja, aber die Implementierung wird vereinfacht. BGE-M3 generiert dichte und sparse Vektoren
im selben Modell – Sie benötigen kein separates BM25. Aber RRF oder eine andere Fusionsmethode
wird immer noch benötigt, um die Ergebnisse zu kombinieren. In Qdrant wird dies
über dieselbe prefetch API implementiert.
Wie viel kostet Cohere Rerank für 1000 Anfragen pro Tag?
Stand März 2026: Cohere Rerank 3.5 kostet ca. 2 $ für 1000 Anfragen
(bei Reranking von 50 Dokumenten pro Anfrage). 1000 Anfragen/Tag = ca. 60 $/Monat.
Zum Vergleich: Self-hosted BGE-v2-m3 auf einer T4 GPU (~150–300 $/Monat) wird
rentabler bei > 2500–5000 Anfragen/Tag.
Kann man Reranking ohne Hybrid Search verwenden?
Ja. Reranking funktioniert mit jedem Retriever – reinem Vektor-Suche, BM25,
oder Hybrid. Aber die Kombination von Hybrid + Reranking liefert die besten Ergebnisse, da
Hybrid eine breitere und vielfältigere Menge von Kandidaten für den Reranker bereitstellt.
Wie wirkt sich Hybrid Search auf die Latenz aus?
Minimal. BM25 und Vektor-Suche werden parallel ausgeführt, und die RRF-Fusion
fügt nur die Rangberechnung hinzu – Mikrosekunden. Die Hauptzusätzliche Zeit –
Reranking (100–300ms), nicht Hybrid Search als solche.
Was ist der Unterschied zwischen RRF und gewichtetem Summen?
RRF arbeitet mit Rängen (Positionen), gewichtete Summe – mit Scores (numerischen
Bewertungen). RRF benötigt keine Normalisierung und ist stabiler bei unterschiedlichen Score-Verteilungen.
Gewichtete Summe bietet mehr Kontrolle, erfordert aber die Kalibrierung von Skalen –
was nicht immer möglich ist.
✅ Schlussfolgerungen
- 🔹 Vektor-Suche allein reicht nicht aus: verwischt exakte Begriffe und kurze Anfragen; BM25 schließt diese Lücken.
- 🔹 Hybrid Search (BM25 + dense + RRF): der erste und einfache Schritt zur Qualitätsverbesserung.
- 🔹 Reranking (Cross-Encoder): die zweite Stufe; +100–300ms, aber +8–25% Präzision, löst "lost in the middle".
- 🔹 Query Transformation: für spezifische Anfragen, fügt Latenz durch LLM-Aufruf hinzu.
- 🔹 Reihenfolge der Implementierung: Hybrid → Reranking → Query Transform; wenn es nicht hilft – Problem beim Chunking oder den Daten.
- 🔹 Testen Sie mit realen Anfragen: 20–30 Anfragen mit Golden Set, Recall@5 vor und nachher – das Minimum vor der Produktion.
Meine Hauptaussage:
Hybrid Search und Reranking ersetzen kein gutes Embedding-Modell oder
korrektes Chunking. Sie sind die nächste Optimierungsschicht für ein RAG-System,
das bereits funktioniert, aber höhere Präzision benötigt. Implementieren Sie schrittweise, messen Sie
jeden Schritt und glauben Sie keinen Marketingzahlen von "+48%" – zielen Sie auf realistische
+15–25%.
Wenn Sie tiefer in die Retrieval-Architektur eintauchen möchten –
ColBERT, Vector DB Internals (🔴 Fortgeschritten, bald).
Wenn Sie die Qualität systematisch messen müssen –
📖 Quellen
