RAG-модель видає дивні або хибні відповіді? Не поспішайте звинувачувати LLM.
Часто причина криється у chunking-стратегії — саме те, як ви розбиваєте дані.
Факт: 60–70% якості відповідей RAG визначається правильним розбиттям контенту на chunks.
⚡ Коротко
- ✅ Ключова думка 1: Fixed-size chunking — це MVP-baseline, не production. Знижує recall на 20–74% порівняно з semantic підходом.
- ✅ Ключова думка 2: Semantic chunking + overlap 10–15% + metadata — мінімальний рецепт для production у 2026 році.
- ✅ Ключова думка 3: Не існує одної «правильної» стратегії — вибір залежить від типу документів, бюджету і вимог до latency.
- 🎯 Ви отримаєте: повний огляд 7 стратегій з числами, decision tree для вибору під свій кейс, підводні камені та приклади з реальних проєктів.
- 👇 Нижче — детальні пояснення, приклади коду та таблиці
📚 Зміст статті
🎯 Що таке chunking і чому це критично
Що таке chunking у RAG
Chunking — це процес розбиття документів на менші частини (chunks), які перетворюються на
vector embeddings і зберігаються у векторній базі даних. Від того, як саме розбиті дані,
залежить якість retrieval, а отже — і якість кінцевих відповідей LLM.
Chunking — це компроміс між точністю, контекстом і вартістю. Поганий chunking неможливо компенсувати кращою моделлю.
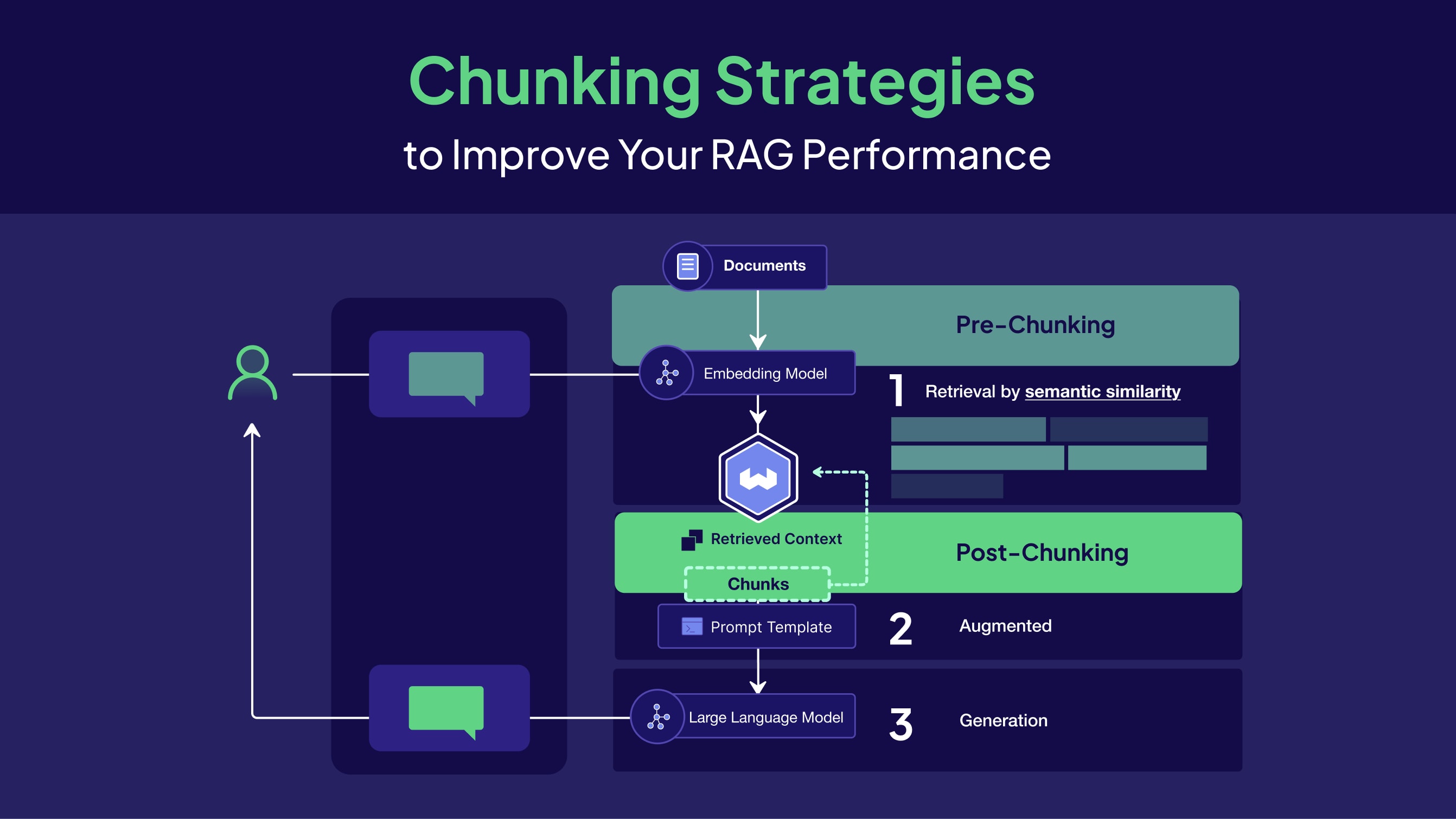
Коли користувач задає питання, RAG-система шукає у векторній БД найближчі за змістом chunks і
передає їх у контекст LLM. Embedding кожного chunk відображає його семантику — і саме тут
chunking стає критичним: якщо chunk семантично «розмитий» або обрізаний у невдалому місці,
embedding не відображає реального змісту, і retrieval повертає нерелевантні фрагменти.
Детальніше про це у статтях:
embedding-моделі для RAG
та
як працюють токени, трансформери і навчання LLM
.
Чому chunking впливає на якість більше, ніж вибір моделі
Chunking безпосередньо впливає на три ключові виміри системи:
-
Якість retrieval. Якщо chunk містить кілька непов'язаних тем — embedding «розмивається»,
і пошук знаходить нерелевантні фрагменти. Якщо chunk занадто малий — втрачається контекст,
без якого смисл речення незрозумілий.
-
Контекст у LLM. Навіть якщо retrieval знайшов правильний документ, але chunk розрізаний
у невдалому місці — модель отримає половину відповіді без її контексту. Це прямий шлях до галюцинацій.
-
Вартість. Погана стратегія призводить до більшої кількості chunks (більше embeddings),
більшого шуму у top-k (більше токенів у промпті без користі), і більшої кількості повторних запитів
через неякісні відповіді.
Дослідження
PMC Bioengineering (2025)
показало: чотири ідентичних RAG-пайплайни на одній моделі, одних даних і одному промпті —
але з різними стратегіями chunking — дали accuracy від 50% до 87%. Єдина змінна — chunking.
🔥 Що відбувається без правильного chunking
Наслідки поганого chunking
Поганий chunking призводить до того, що retrieval знаходить нерелевантні або неповні фрагменти,
модель галюцинує або дає неповні відповіді, а важливий контекст губиться між chunks.
Навіть найкраща LLM не може компенсувати поганий retrieval.
Retrieval — сміття на вхід, сміття на вихід. LLM не може «вгадати» інформацію, яку не отримала.
Типова помилка: розробник запускає RAG з дефолтними налаштуваннями LangChain —
RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=0) — і вважає, що це «вже непогано».
Три реальних сценарії з того, що відбувається далі:
Сценарій 1: Фінансовий звіт з таблицями
Таблиця з квартальними показниками розбита fixed-size splitter-ом посередині.
У першому chunk — заголовки колонок: «Q1, Q2, Q3, Q4». У другому — цифри без заголовків: «12.4, 8.7, 15.2, 9.1».
Запит «Який дохід у Q3?» знаходить chunk з цифрами, але без контексту, що вони означають.
Модель або галюцинує, або відповідає невпевнено.
Сценарій 2: Юридичний документ з винятками
Пункт про відповідальність починається в одному chunk, а його винятки та уточнення — у наступному.
Retrieval знаходить тільки основний пункт без виключень. Відповідь юридично хибна — і це може
мати реальні наслідки для бізнесу, який використовує таку систему.
Сценарій 3: Технічна документація з параметрами функцій
Опис функції і перелік її параметрів розірвані між chunks. Retrieval знаходить опис без параметрів
або навпаки. Розробник отримує неповну відповідь і витрачає час на пошук решти інформації вручну.
Підсумок: Retrieval знаходить нерелевантні або неповні фрагменти → модель галюцинує →
важливий контекст губиться → токени витрачаються на шум. За даними
Vectara (2026)
, retrieval — один з найбільших bottleneck-ів при масштабуванні RAG від PoC до production.
📦 Огляд 7 стратегій chunking
Які стратегії chunking існують
У 2026 році використовується 7 основних стратегій: fixed-size, sliding window, semantic chunking,
recursive/hierarchical, metadata-aware, proposition chunking та query-aware chunking.
Кожна має свій trade-off між якістю, складністю і вартістю.
3.1 Fixed-size chunking
Найпростіший підхід. Підходить для PoC і логів — не підходить для реальних документів у production.
Розбиваємо текст на рівні шматки фіксованого розміру (наприклад, 500 токенів), незалежно від
структури та змісту документа. Сепаратор може бути символом переносу рядка, пробілом або взагалі відсутній.
from langchain.text_splitter import CharacterTextSplitter
splitter = CharacterTextSplitter(
chunk_size=500,
chunk_overlap=0,
separator="\n"
)
chunks = splitter.split_text(document)
Плюси: простота реалізації (кілька рядків коду), стабільна і передбачувана продуктивність, хороший baseline для MVP.
Мінуси: ламає речення і параграфи в довільних місцях, змішує непов'язані теми в одному chunk-і, знижує якість embeddings.
Коли підходить: логи, сирі неструктуровані дані, швидкий прототип. Не підходить для production з реальними документами.
⸻
3.2 Sliding Window (з перекриттям)
Fixed-size chunking з overlap — мінімальне покращення, яке варто робити завжди. Overlap 10–20% від розміру chunk.
Chunks перекриваються — кінець одного chunk-а повторюється на початку наступного.
Це гарантує, що інформація на кордоні між chunks не губиться.
from langchain.text_splitter import RecursiveCharacterTextSplitter
splitter = RecursiveCharacterTextSplitter(
chunk_size=500,
chunk_overlap=75, # 15% від chunk_size — оптимум
length_function=len,
)
chunks = splitter.split_text(document)
Плюси: зберігає контекст на межах chunks, покращує recall, мінімальний overhead у реалізації.
Мінуси: дублювання даних і embeddings, зростає вартість зберігання, можуть з'являтися майже однакові chunks у top-k (вирішується MMR).
Оптимальний overlap: 10–20% від розміру chunk. Менше — втрачаємо контекст.
Більше — надмірне дублювання і зростання вартості.
Коли підходить: майже завжди як доповнення до іншої стратегії. Рідко використовується як основна без semantic splitting.
3.3 Semantic Chunking
Розбиваємо по смисловим кордонам, а не по фіксованому розміру. Золотий стандарт для production у 2026 році.
Два основних підходи. Embedding-based: обчислюємо embeddings для кожного речення,
порівнюємо cosine similarity між сусідніми реченнями. Де схожість різко падає — там межа chunk-а.
LLM-based: просимо LLM визначити логічні межі в тексті. Дорожче, але точніше.
from langchain_experimental.text_splitter import SemanticChunker
from langchain_openai.embeddings import OpenAIEmbeddings
splitter = SemanticChunker(
OpenAIEmbeddings(),
breakpoint_threshold_type="percentile",
breakpoint_threshold_amount=95, # розбиваємо там, де різкий тематичний перехід
)
chunks = splitter.create_documents([document])
Плюси: кожен chunk семантично цілісний (одна тема), значно кращий retrieval, менше шуму в контексті LLM.
Мінуси: складніша реалізація, chunks мають різний розмір, embedding-based підхід вимагає обчислення embeddings під час ingestion.
Числа: за даними
Chroma Research (2024)
,
LLMSemanticChunker досяг recall 91.9%, ClusterSemanticChunker — 89.7%.
Коли підходить: документація, статті, knowledge base, юридичні та фінансові тексти. Оптимальний вибір для більшості production-сценаріїв.
⸻
3.4 Recursive / Hierarchical Chunking
Розбиваємо ієрархічно: спочатку по великих розділах, потім по параграфах, потім по реченнях. De facto стандарт у LangChain.
RecursiveCharacterTextSplitter намагається розбити текст по природних кордонах у заданому порядку:
спочатку по подвійному переносу рядка (параграф), потім по одинарному (рядок), потім по крапці, потім по пробілу.
from langchain.text_splitter import RecursiveCharacterTextSplitter
# Пріоритет сепараторів: параграф → рядок → речення → слово
splitter = RecursiveCharacterTextSplitter(
chunk_size=400,
chunk_overlap=50,
separators=["\n\n", "\n", ". ", " ", ""],
)
chunks = splitter.split_text(document)
Плюси: намагається зберегти структуру документа, гнучкість налаштування сепараторів, хороший баланс між якістю та простотою.
Мінуси: потребує налаштування сепараторів під конкретний формат, може не впоратись зі складно структурованими PDF.
Числа: за даними
Chroma Research (2024)
,
RecursiveCharacterTextSplitter на 400–512 токенів дає recall 85–90% і є найкращим балансом якість/вартість для більшості команд.
Коли підходить: великі структуровані документи, Markdown, HTML, загальне використання без специфічних вимог.
⸻
3.5 Metadata-Aware Chunking
Не окрема стратегія розбивки — а обов'язковий шар поверх будь-якої стратегії. У production без metadata неможливо нормально фільтрувати результати.
Кожен chunk збагачується структурованими метаданими: звідки він, який розділ, яка дата, який тип контенту.
Це дозволяє робити pre-filtering до vector search і підвищувати релевантність результатів.
from langchain.schema import Document
chunk = Document(
page_content="Текст chunk-а...",
metadata={
"source": "annual_report_2024.pdf",
"section": "Фінансові результати",
"page": 12,
"type": "financial",
"date": "2024-12-01",
"language": "uk",
}
)
Плюси: pre-filtering до vector search (зменшення search space), self-querying (LLM автоматично генерує фільтри), traceability — кожна відповідь прив'язана до конкретного джерела.
Мінуси: потребує проєктування схеми метаданих, складніший pipeline ingestion.
Коли підходить: практично завжди в production. Metadata-aware — не окрема стратегія, а доповнення до будь-якої іншої.
⸻
3.6 Proposition Chunking (Advanced)
Найточніший підхід: документ розбивається на атомарні самодостатні твердження. Максимальна якість retrieval при максимальній вартості.
Кожен chunk — це одне конкретне твердження у форматі повного самодостатнього речення.
Зрозуміле без будь-якого додаткового контексту.
# Вхідний текст:
# "Компанія заснована у 2010 році. Вона має 500 співробітників і офіси у 12 країнах."
# Після proposition chunking:
# Chunk 1: "Компанія була заснована у 2010 році."
# Chunk 2: "Компанія має 500 співробітників."
# Chunk 3: "Компанія має офіси у 12 країнах."
Реалізується через LLM: подаємо текст з промптом «Розбий цей текст на окремі атомарні твердження,
кожне у форматі повного речення, зрозумілого без контексту».
Детальніше про це у статті:
контекстне вікно LLM
.
Плюси: максимальна точність retrieval, кожен chunk відповідає одному конкретному факту, ідеально для factoid QA.
Мінуси: висока вартість (потрібен LLM для розбивки), значно більша кількість chunks, складна реалізація і налагодження.
Числа:
Chroma Research (2024)
зафіксував recall 91.9% для LLM-based semantic chunking (аналог proposition підходу) —
найвищий результат серед усіх стратегій.
Коли підходить: складні enterprise-системи з high-value запитами, де вартість виправдана якістю.
⸻
3.7 Query-Aware Chunking (Advanced)
Chunks формуються або відбираються під конкретний запит. Максимальна релевантність при максимальній вартості.
Варіант реалізації — HyDE (Hypothetical Document Embedding): замість пошуку за оригінальним запитом
генеруємо гіпотетичну відповідь на нього і шукаємо chunks, схожі на цю відповідь.
Чому це працює: embedding «правильної відповіді» ближчий до релевантних chunks, ніж embedding самого питання.
from langchain.chains import HypotheticalDocumentEmbedder
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
llm = ChatOpenAI(model="gpt-4o-mini")
embeddings = OpenAIEmbeddings()
# HyDE: генеруємо гіпотетичний документ для кращого embedding match
hyde_embeddings = HypotheticalDocumentEmbedder.from_llm(
llm=llm,
embeddings=embeddings,
prompt_key="web_search",
)
Плюси: максимальна релевантність для конкретного запиту, особливо ефективний для складних багатоступеневих питань.
Мінуси: додатковий LLM-виклик на кожен запит (вартість + latency), складна реалізація і debugging.
Коли підходить: складні enterprise-системи з high-value запитами. Не виправдано для простих Q&A систем.
Ця таблиця порівнює основні стратегії розбиття даних (chunking) для RAG. Вона допомагає швидко зрозуміти, які підходи підходять для конкретного кейсу, оцінити баланс між точністю, повнотою, вартістю та складністю впровадження.
| Стратегія |
Точність (Precision) |
Повнота (Recall) |
Вартість (Cost) |
Складність (Complexity) |
Використання (Use case) |
| Фіксований розмір (Fixed-size) |
Низька |
Середня |
Низька |
Низька |
MVP, логи |
| Перекриваюче розбиття (Sliding window / overlap) |
Середня |
Висока |
Середня |
Низька |
Майже завжди (baseline + overlap) |
| Семантичне розбиття (Semantic) |
Висока |
Висока |
Середня |
Середня |
Документація, статті, knowledge base |
| Рекурсивне / Ієрархічне (Recursive / Hierarchical) |
Висока |
Висока |
Висока |
Висока |
Великі структуровані документи |
| З метаданими (Metadata-aware) |
Висока |
Висока |
Низька |
Середня |
Production RAG |
| З орієнтацією на запит (Query-aware, Advanced) |
Дуже висока |
Дуже висока |
Висока |
Висока |
Enterprise / складні системи |
Висновок: вибір стратегії chunking залежить від типу даних та вимог до точності і швидкості. Для документів і knowledge base зазвичай використовують семантичне розбиття з перекриттям та метаданими. Для логів або MVP підійде простий fixed-size. Advanced підходи, як query-aware або рекурсивне розбиття, ефективні для великих або складних систем. Головне — баланс між точністю, повнотою, вартістю та складністю впровадження.
📊 Бенчмарки: що кажуть дослідження 2024–2025
Semantic і proposition chunking стабільно показують recall 87–92% проти 50–65% у fixed-size baseline.
Різниця між найкращим і найгіршим підходом — до 74 абсолютних відсотків accuracy при тій самій моделі.
Числа, а не думки. Нижче — результати реальних досліджень, а не маркетингові заяви.
Chroma Research (2024): систематичне порівняння на 474 запитах
Chroma провели систематичне дослідження
на 474 запитах (згенерованих GPT-4-Turbo) на корпусах різного типу: Wikipedia, фінансові тексти, чатлоги.
| Стратегія |
Recall |
Примітка |
| LLMSemanticChunker |
91.9% |
Найвищий recall, але найвища вартість |
| ClusterSemanticChunker |
89.7% |
Хороший баланс якість/вартість для semantic |
| RecursiveCharacterTextSplitter (400–512 токенів) |
85–90% |
Найкращий баланс для більшості команд |
| Fixed-size (без overlap) |
Найнижчий |
Baseline, не для production |
Важливий висновок Chroma: semantic chunking вимагає обчислення embeddings для кожного речення
під час ingestion — це значно дорожче. Trade-off виправдовує себе тільки для high-value документів.
Для більшості команд RecursiveCharacterTextSplitter (400–512 токенів) — оптимальний вибір.
PMC Bioengineering (2025): +74% accuracy від зміни chunking
Клінічне дослідження PMC Bioengineering (2025)
побудувало чотири ідентичних RAG-пайплайни на базі Gemini 1.0 Pro. Відрізнялись вони тільки стратегією chunking.
На 30 постопераційних запитах:
| Стратегія |
Accuracy |
Precision |
Recall |
F1 |
| Adaptive chunking |
87% |
0.50 |
0.88 |
0.64 |
| Semantic chunking |
~75% |
0.38 |
0.71 |
0.49 |
| Proposition chunking |
~70% |
0.33 |
0.65 |
0.44 |
| Fixed-size baseline |
50% |
0.17 |
0.40 |
0.24 |
Різниця в 74 абсолютних відсотки accuracy при тій самій моделі, тих самих даних і тому самому промпті.
Єдина змінна — chunking. Дослідники також виявили: оптимальні параметри adaptive chunking
(cosine similarity ≥ 0.8, ліміт 500 слів) вимагають ітеративного підбору.
Поріг нижче 0.75 призводив до topic bleed (змішування тем), вище 0.85 — надмірно фрагментував текст.
Зведена порівняльна таблиця стратегій
| Стратегія |
Precision |
Recall |
Вартість |
Складність |
Коли використовувати |
| Fixed-size |
низька |
середній |
низька |
низька |
MVP, логи, прототип |
| Sliding window |
середня |
високий |
середня |
низька |
майже завжди як доповнення |
| Semantic |
висока |
високий |
середня |
середня |
документація, knowledge base |
| Recursive |
висока |
високий |
середня |
середня |
structured data, Markdown |
| Proposition |
дуже висока |
дуже високий |
висока |
висока |
enterprise factoid QA |
| Metadata-aware |
висока |
високий |
низька |
середня |
production — обов'язково |
| Query-aware (HyDE) |
дуже висока |
дуже високий |
дуже висока |
висока |
складні enterprise-системи |
⸻
🗺️ Decision Tree: як вибрати стратегію для свого проєкту
Як вибрати стратегію chunking
Вибір стратегії залежить від трьох факторів: тип документів (структуровані/неструктуровані),
стадія проєкту (MVP/production/enterprise) і вимоги до точності (precision vs recall).
Для більшості production-сценаріїв оптимально: semantic chunking + overlap 10–15% + metadata.
Більшість статей розповідають як працює кожна стратегія. Ця відповідає на питання: «що вибрати саме мені?»
Крок 1: Який тип даних?
| Тип даних |
Рекомендована стратегія |
Розмір chunk |
| Логи, сирі дані |
Fixed-size |
500 токенів |
| Код (Python, JS, SQL) |
Fixed-size + boundary по функціях |
100–300 токенів |
| PDF з таблицями і складною структурою |
LlamaParse/Docling для ETL + semantic |
400–600 токенів |
| Документація, статті, knowledge base |
Semantic + overlap + metadata |
400–600 токенів |
| Юридичні / медичні тексти |
Semantic + proposition для критичних секцій |
300–500 токенів |
| Mixed data (різні типи) |
Recursive + metadata + різні стратегії по type |
залежить від типу |
Крок 2: Яка стадія проєкту?
| Стадія |
Стратегія |
Час на реалізацію |
| PoC / MVP |
RecursiveCharacterTextSplitter (400 токенів, overlap 50) + базова metadata |
Кілька годин |
| Production (перший деплой) |
Semantic chunking + overlap 10–15% + metadata + MMR |
1–3 дні |
| Enterprise / масштаб |
Semantic + proposition для критичних секцій + rich metadata + pre-filtering + reranking |
1–2 тижні |
Крок 3: Яка вимога до точності?
- High recall важливіший (не пропустити жодної відповідної інформації) → Більший chunk (500–800 токенів) + більший overlap (15–20%)
- High precision важливіша (мінімум нерелевантного шуму) → Менший chunk (200–400 токенів) + semantic split + proposition для ключових секцій
- Баланс → 400–600 токенів + semantic + overlap 15% + MMR при retrieval
Базовий production-рецепт (підходить для 80% сценаріїв)
from langchain_experimental.text_splitter import SemanticChunker
from langchain_openai import OpenAIEmbeddings
from langchain.schema import Document
def create_production_chunks(text: str, metadata: dict) -> list[Document]:
"""
Базовий production-рецепт:
semantic chunking + збагачення metadata
"""
splitter = SemanticChunker(
OpenAIEmbeddings(),
breakpoint_threshold_type="percentile",
breakpoint_threshold_amount=95,
)
chunks = splitter.create_documents([text])
# Збагачуємо кожен chunk метаданими
enriched_chunks = []
for i, chunk in enumerate(chunks):
chunk.metadata = {
**metadata,
"chunk_index": i,
"chunk_total": len(chunks),
}
enriched_chunks.append(chunk)
return enriched_chunks
# Використання
chunks = create_production_chunks(
text=document_text,
metadata={
"source": "product_docs_v2.pdf",
"section": "API Reference",
"type": "documentation",
"date": "2024-12-01",
"language": "uk",
}
)
Потім — retrieval з MMR і top_k = 3–5 для усунення дублікатів від overlap,
і reranking (bge-reranker-v2 або Cohere Rerank) для фінального відбору найрелевантніших chunks.
За даними
Pinecone/Superlinked
,
додавання reranking дає +48% якості retrieval.
⚙️ Production-налаштування: розмір, overlap, metadata
Ключові параметри для production
Оптимальний розмір chunk — 400–600 токенів для більшості документів. Overlap — 10–20% від розміру.
Metadata мінімум: source, section, type. Top-k при retrieval — 3–5 з MMR для усунення дублікатів.
Розмір chunk: як вибрати
| Розмір |
Ефект |
Коли застосовувати |
| 100–200 токенів |
Дуже висока precision, низький recall. Ризик втрати контексту. |
Код, короткі FAQ |
| 200–400 токенів |
Висока precision. Оптимально для factoid QA. |
Юридичні тексти, специфікації |
| 400–600 токенів |
Баланс precision/recall. Найкращий вибір для більшості документів. |
Документація, статті, KB |
| 600–800 токенів |
Вищий recall, менша precision. Більше шуму у відповідях. |
Довгі наративні документи |
| 1000+ токенів |
Ризик embedding dilution. Embedding «розмивається» між темами. |
Не рекомендується |
Overlap: оптимальні значення
| Overlap |
Ефект |
| 0% |
Втрата контексту на межах. Не рекомендується навіть для MVP. |
| 5–10% |
Мінімальний overhead, достатній для простих текстів. |
| 10–20% |
Оптимум для більшості сценаріїв. |
| 25–30% |
Надмірне дублювання, зростає вартість. |
| > 30% |
Одинакові chunks у результатах retrieval. Контрпродуктивно. |
Metadata: мінімальна і розширена схема
Мінімум для production:
{
"source": "назва_документа.pdf",
"section": "Назва розділу або заголовок",
"type": "doc | article | code | legal | financial",
"page": 5,
"chunk_index": 12
}
Розширена схема для великих систем:
{
"source": "annual_report_2024.pdf",
"section": "Фінансові результати Q3",
"type": "financial",
"page": 12,
"date_created": "2024-11-30",
"language": "uk",
"department": "finance",
"access_level": "internal",
"chunk_index": 5,
"chunk_total": 48
}
Retrieval-налаштування
# Налаштування retriever з MMR для усунення дублікатів
retriever = vectorstore.as_retriever(
search_type="mmr", # Maximum Marginal Relevance
search_kwargs={
"k": 5, # top-k chunks у фінальному результаті
"fetch_k": 20, # кандидати для MMR-відбору
"lambda_mult": 0.7, # 0 = max diversity, 1 = max relevance
"filter": { # pre-filtering по metadata
"type": "documentation",
"language": "uk",
}
}
)
Top-k рекомендації: 3–5 для більшості сценаріїв.
Більше — зростає шум і вартість токенів.
Менше — ризик пропустити релевантну інформацію.
За даними
ZeroEntropy (2025–2026)
,
rerank 50 кандидатів → top-5 дає оптимальний баланс якість/швидкість для LLM-чатів.
⚠️ Підводні камені: 6 проблем, які ламають retrieval
Найчастіші помилки при chunking
Шість ключових проблем: fragmentation (chunks занадто малі), boundary problem (інформація розрізана між chunks),
duplicate chunks (дублювання від overlap), embedding dilution (кілька тем в одному chunk),
lost in the middle (LLM ігнорує середину контексту), over/under chunking (неправильний розмір без вимірювань).
7.1 Fragmentation (надмірне подрібнення)
Проблема: Chunk занадто малий — смисл губиться. Речення «Вартість послуги — 500 грн» без попереднього контексту є безглуздим. Retrieval знаходить «правильні» chunks, але модель не може дати повну відповідь.
Рішення: Збільшіть розмір chunk або додайте overlap. Мінімальний chunk для складних документів — 200 токенів. Тестуйте відповіді моделі на типових запитах після зміни.
7.2 Boundary Problem (розрив на межі)
Проблема: Ключова інформація розподілена між двома chunks. Причина, умова і наслідок — у різних chunks. Відповіді «майже правильні» — модель знаходить частину, але не всю картину.
Рішення: Overlap + semantic splitting. Overlap гарантує, що межа між chunks не ріже критичну інформацію. Semantic splitting гарантує, що межа взагалі в правильному місці.
7.3 Duplicate Chunks
Проблема: Overlap створює майже однакові chunks, які потрапляють у top-k разом. Контекст LLM забитий дублікатами. Модель повторює одну і ту саму інформацію кілька разів у відповіді.
Рішення: MMR (Maximum Marginal Relevance) при retrieval або reranking з deduplication. У LangChain — search_type="mmr".
7.4 Embedding Dilution
Проблема: Один chunk містить кілька непов'язаних тем. Embedding намагається відобразити всі теми і в результаті не відображає жодну достатньо точно. Cosine similarity всіх chunks приблизно однакова, важко виділити топ-релевантні.
Приклад: Chunk 800 токенів, де перша половина — про продукт А, друга — про продукт Б. Пошук за «характеристики продукту А» знайде цей chunk з посередньою релевантністю.
Рішення: Зменшіть розмір chunk або застосуйте semantic splitting, щоб кожен chunk відповідав одній темі.
7.5 Lost in the Middle
Проблема: Навіть якщо retrieval знайшов правильні chunks, LLM може ігнорувати інформацію в середині контексту.
Stanford TACL (2024)
зафіксував деградацію recall на 25–45% для інформації в середині контекстного вікна — навіть для frontier-моделей.
Рішення: Ми рекомендуємо обмежувати кількість chunks у контексті (top-k = 3–5).
Також ми застосовуємо strategic ordering при reranking: найрелевантніший фрагмент розміщуємо
на початку контексту, другий за релевантністю — в кінці.
7.6 Over / Under Chunking
Проблема: Занадто малі chunks дають шум і втрату контексту. Занадто великі — знижують precision і створюють embedding dilution.
Більшість команд встановлює розмір «на інтуїції» і більше не змінює — навіть якщо метрики сигналізують про проблему.
Рішення: Тестувати chunk size як гіперпараметр. Встановіть baseline метрику (recall або faithfulness через
RAGAS
або
DeepEval),
потім міняйте один параметр за раз і вимірюйте вплив.
💼 Кейси з проєктів: як chunking вирішував реальні проблеми
Перехід від fixed-size до semantic chunking + metadata на реальних проєктах давав приріст recall
від 20% до 70% залежно від типу документів. Ключовий інсайт: проблема майже завжди в chunking або
metadata, а не в моделі.
Кейс 1: Knowledge base для підтримки клієнтів
Ситуація: RAG-система для відповідей на питання клієнтів по продукту.
Документи — FAQ, інструкції, release notes. Стартова конфігурація: chunk_size=1000, chunk_overlap=0.
Recall на тестових питаннях — близько 55%.
Проблема: Інструкція «Як скинути пароль» займала 3 параграфи. Fixed-size splitter розбивав
її на два chunks посередині третього кроку. Retrieval знаходив перший chunk з кроками 1–2, але без кроку 3.
Відповідь модуля: «Перейдіть у налаштування → Безпека → введіть email» (без фінального кроку «перевірте пошту і перейдіть за посиланням»).
Клієнти повторно зверталися у підтримку.
Що зробили:
- Змінили на
RecursiveCharacterTextSplitter(chunk_size=400, chunk_overlap=60)
- Додали metadata:
type (faq/instruction/release_note), product_area, version
- Додали pre-filtering: при запитах по конкретній версії продукту — фільтруємо chunks за
version
- Retrieval:
search_type="mmr", top-k=4
Результат: Recall виріс до 81%. Кількість повторних звернень по тих самих питаннях знизилась на 35%.
Час до першої відповіді скоротився, бо модель почала давати повні інструкції з першого разу.
⸻
Кейс 2: RAG по внутрішній документації (змішані типи документів)
Ситуація: Внутрішній помічник для команди розробників. В індексі — технічна документація,
API-специфікації, архітектурні рішення (ADR), внутрішні wiki-сторінки. Всі документи завантажені з
однаковим chunk_size=800.
Проблема: Специфікація API містила таблицю ендпоінтів — 20 рядків, кожен з методом,
URL і описом. Fixed-size splitter розбивав таблицю на три chunks. При запиті «Який метод для оновлення
профілю?» retrieval повертав chunk з частиною таблиці, але без потрібного рядка — він потрапляв у інший chunk.
ADR-документи (1–2 сторінки) потрапляли в один великий chunk і їхній embedding «розмивався».
Що зробили:
- Впровадили різні стратегії для різних типів:
- API-специфікації: LlamaParse для ETL (зберігає таблиці як цілі блоки) + semantic chunking
- Wiki і ADR: RecursiveCharacterTextSplitter (chunk_size=400) + overlap 15%
- Код у документації: custom splitter по функціях і класах (chunk_size=200–300)
- Metadata:
doc_type, team, last_updated, component
- Hybrid search: dense + BM25 через Qdrant (BM25 ловить точні назви ендпоінтів)
Результат: Recall на API-запитах виріс з 48% до 84%. Питання по конкретних ендпоінтах почали
отримувати правильні відповіді з першого разу. Команда перестала «гуглити у Confluence» і довіряє помічнику
для технічних довідок.
⸻
Кейс 3: Пошук по фінансовим документам (quarterly reports)
Ситуація: Система для аналітиків: пошук по квартальних звітах компаній.
PDF-документи з таблицями, графіками, текстовими коментарями. Понад 2000 документів у індексі.
Стартовий recall — близько 52% на фактичних питаннях (конкретні цифри, дати, назви статей).
Проблема: Fixed-size splitter ламав таблиці — рядки фінансових даних без заголовків стовпців
були безглуздими. Запит «Який EBITDA у Q3 2023?» знаходив рядок «15.4 | 18.2 | 12.7 | 21.1» без контексту,
що це EBITDA і які квартали.
Що зробили:
- ETL через LlamaParse — зберігає таблиці як Markdown-блоки з заголовками
- Semantic chunking з окремою обробкою таблиць: кожна таблиця — окремий chunk (незалежно від розміру), текстові секції — semantic split
- Metadata:
company_ticker, report_type, period (Q1/Q2/Q3/Q4/Annual), fiscal_year, content_type (table/text/chart_description)
- Pre-filtering: запит «EBITDA Q3 2023» → фільтр по
period=Q3, fiscal_year=2023 перед vector search
- Hybrid search: BM25 ловив точні фінансові терміни і назви статей, dense — семантичний контекст
Результат: Recall виріс до 87%. Faithfulness (за
RAGAS)
покращилась вдвічі. Аналітики почали довіряти системі для підготовки звітів і перестали вручну
перевіряти кожну цифру. Час підготовки аналітичного звіту знизився приблизно на 40%.
❓ Часті питання (FAQ)
Який розмір chunk обрати за замовчуванням?
400–500 токенів + overlap 15% — хороший стартовий розмір для більшості документів.
Це підтверджує
Chroma Research (2024)
:
RecursiveCharacterTextSplitter на 400–512 токенів дає recall 85–90% і є найкращим балансом для більшості команд.
Потім — тестуйте і налаштовуйте під конкретний тип документів.
Чи потрібен overlap завжди?
Майже завжди — так. Overlap 10–15% запобігає втраті контексту на межах chunks без значного збільшення вартості.
Виняток: дуже короткі самодостатні документи (FAQ з однорядковими відповідями), де кожен chunk і так є
повним незалежним фрагментом.
Яка різниця між semantic chunking та RecursiveCharacterTextSplitter?
RecursiveCharacterTextSplitter розбиває по ієрархії сепараторів (параграф → рядок → речення) і обмежує розмір.
Semantic chunking обчислює embeddings і розбиває там, де різко змінюється тема — незалежно від фізичного розміру.
Semantic дає кращий recall, але вимагає обчислення embeddings під час ingestion (дорожче на 2–5x).
Для більшості команд рекомендується починати з Recursive, переходити на Semantic для high-value документів.
Як обробляти PDF з таблицями?
Стандартні text splitter-и ламають таблиці. Потрібен спеціальний ETL:
LlamaParse
(78% edit similarity, $0.003/сторінка) або
Docling
(open-source, 97.9% accuracy на таблицях за
бенчмарком Procycons (2025)
).
Після ETL — зберігайте таблиці як цілі блоки (один chunk = одна таблиця) і застосовуйте
semantic chunking до текстових секцій.
Як зрозуміти, що chunking налаштований добре?
Вимірюйте. Налаштуйте автоматичну evaluation через
RAGAS
або
DeepEval
на тестовому наборі з 50–100 питань.
Ключові метрики: Context Recall (чи знайшли всю релевантну інформацію?), Context Precision
(чи є шум у знайденому?), Faithfulness (чи відповідь підтримується retrieved контекстом?).
Змінюйте один параметр за раз і вимірюйте вплив.
Скільки chunks потрібно для хорошого retrieval?
Top-k = 3–5 достатньо для більшості запитів. Більше chunks у контексті — більше шуму і вищий ризик
«lost in the middle». Якщо recall низький — краще покращити chunking і embedding, ніж збільшувати top-k.
✅ Висновки
У RAG перемагає не найкраща модель — перемагає правильно налаштований pipeline.
І chunking — це перший і найважливіший шар цього pipeline.
-
Не існує єдиної «правильної» стратегії. Вибір залежить від типу документів, стадії проєкту і вимог до якості.
Fixed-size — для MVP, semantic + metadata — для production, proposition — для enterprise з high-value запитами.
-
Числа реальні.
PMC (2025)
і
Chroma (2024)
демонструють: зміна стратегії chunking при тій самій моделі дає +20–74% до accuracy.
Жодна зміна LLM не дасть такого результату без нормального retrieval.
-
Базовий production-рецепт: semantic chunking + overlap 10–15% + metadata (source, section, type)
+ top-k 3–5 + MMR або reranking. Підходить для 80% сценаріїв.
-
Без evaluation не можна зрозуміти якість.
Налаштуйте
RAGAS
або
DeepEval
перед тим, як починати оптимізацію. Інакше будете змінювати параметри наосліп.
-
Chunking — це гіперпараметр, а не одноразове рішення.
Оптимальні параметри для юридичних текстів і для FAQ кардинально різні.
Тестуйте, вимірюйте, ітеруйте.