RAG model gives strange or false answers? Don't rush to blame the LLM.
Often the reason lies in the chunking strategy — precisely how you split the data.
Fact: 60–70% of RAG answer quality is determined by correctly splitting content into chunks.
⚡ In Short
- ✅ Key Takeaway 1: Fixed-size chunking is an MVP baseline, not production. It reduces recall by 20–74% compared to semantic approaches.
- ✅ Key Takeaway 2: Semantic chunking + 10–15% overlap + metadata is the minimum recipe for production in 2026.
- ✅ Key Takeaway 3: There is no single "correct" strategy — the choice depends on document type, budget, and latency requirements.
- 🎯 You will get: a full overview of 7 strategies with numbers, a decision tree for choosing for your case, pitfalls, and examples from real projects.
- 👇 Below are detailed explanations, code examples, and tables
📚 Article Contents
🎯 What is chunking and why is it critical
What is chunking in RAG
Chunking is the process of splitting documents into smaller parts (chunks), which are then converted into
vector embeddings and stored in a vector database. The quality of retrieval, and consequently the quality of the final LLM answers,
depends on how the data is split.
Chunking is a trade-off between accuracy, context, and cost. Poor chunking cannot be compensated for by a better model.
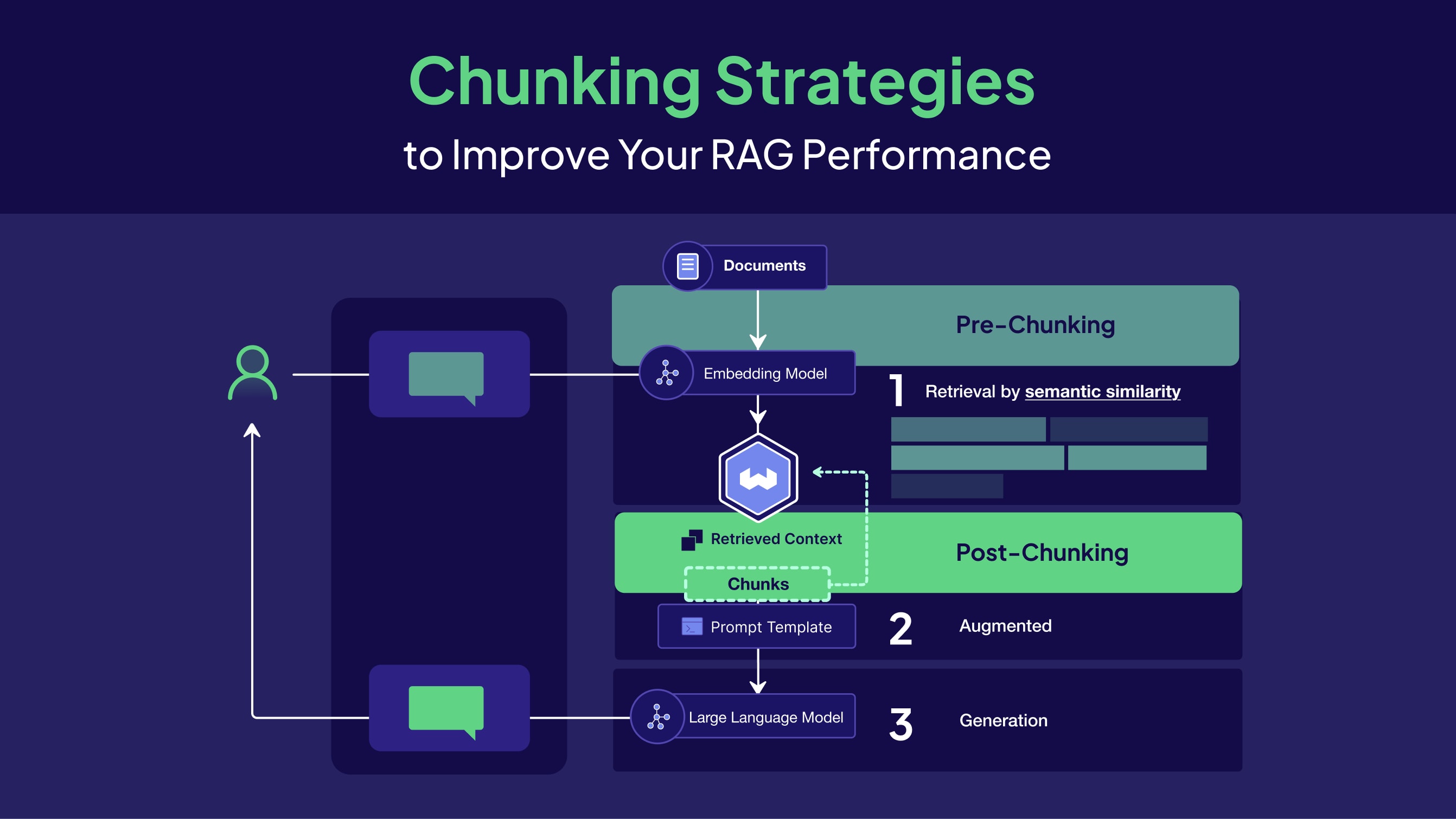
When a user asks a question, the RAG system searches the vector DB for the most semantically similar chunks and
passes them to the LLM's context. The embedding of each chunk reflects its semantics — and this is where
chunking becomes critical: if a chunk is semantically "blurred" or cut off at an unfortunate place,
the embedding does not reflect the actual meaning, and retrieval returns irrelevant fragments.
More on this in the articles:
embedding models for RAG
and
how tokens, transformers, and LLM training work
.
Why chunking affects quality more than model choice
Chunking directly impacts three key dimensions of the system:
-
Retrieval quality. If a chunk contains several unrelated topics, the embedding becomes "blurred,"
and the search finds irrelevant fragments. If a chunk is too small, context is lost,
without which the meaning of a sentence is unclear.
-
LLM context. Even if retrieval found the correct document, but the chunk is cut
at an unfortunate place, the model receives half of the answer without its context. This is a direct path to hallucinations.
-
Cost. A poor strategy leads to more chunks (more embeddings),
more noise in top-k (more tokens in the prompt without benefit), and more repeated queries
due to low-quality answers.
A study by
PMC Bioengineering (2025)
showed: four identical RAG pipelines on the same model, same data, and same prompt —
but with different chunking strategies — yielded accuracy from 50% to 87%. The only variable was chunking.
🔥 What happens without proper chunking
Consequences of poor chunking
Poor chunking leads to retrieval finding irrelevant or incomplete fragments,
the model hallucinating or giving incomplete answers, and important context being lost between chunks.
Even the best LLM cannot compensate for poor retrieval.
Garbage in, garbage out for retrieval. An LLM cannot "guess" information it did not receive.
A common mistake: a developer launches RAG with default LangChain settings —
RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=0) — and thinks it's "already not bad."
Three real scenarios of what happens next:
Scenario 1: Financial report with tables
A table with quarterly figures is split in the middle by a fixed-size splitter.
The first chunk contains column headers: "Q1, Q2, Q3, Q4". The second contains numbers without headers: "12.4, 8.7, 15.2, 9.1".
The query "What was the revenue in Q3?" finds the chunk with numbers, but without the context of what they represent.
The model either hallucinates or answers uncertainly.
Scenario 2: Legal document with exceptions
A clause on liability starts in one chunk, and its exceptions and clarifications are in the next.
Retrieval finds only the main clause without exceptions. The answer is legally incorrect — and this can
have real consequences for the business using such a system.
Scenario 3: Technical documentation with function parameters
The description of a function and its parameter list are split between chunks. Retrieval finds the description without parameters
or vice versa. The developer gets an incomplete answer and spends time searching for the rest of the information manually.
Summary: Retrieval finds irrelevant or incomplete fragments → the model hallucinates →
important context is lost → tokens are spent on noise. According to
Vectara (2026)
, retrieval is one of the biggest bottlenecks when scaling RAG from PoC to production.
📦 Overview of 7 chunking strategies
What chunking strategies exist
In 2026, 7 main strategies are used: fixed-size, sliding window, semantic chunking,
recursive/hierarchical, metadata-aware, proposition chunking, and query-aware chunking.
Each has its own trade-off between quality, complexity, and cost.
3.1 Fixed-size chunking
The simplest approach. Suitable for PoC and logs — not suitable for real documents in production.
We split the text into uniform pieces of fixed size (e.g., 500 tokens), regardless of
the document's structure or content. The separator can be a newline character, a space, or absent altogether.
from langchain.text_splitter import CharacterTextSplitter
splitter = CharacterTextSplitter(
chunk_size=500,
chunk_overlap=0,
separator="\n"
)
chunks = splitter.split_text(document)
Pros: simplicity of implementation (a few lines of code), stable and predictable performance, good baseline for MVP.
Cons: breaks sentences and paragraphs at arbitrary places, mixes unrelated topics in one chunk, reduces embedding quality.
When suitable: logs, raw unstructured data, quick prototypes. Not suitable for production with real documents.
⸻
3.2 Sliding Window (with overlap)
Fixed-size chunking with overlap is a minimal improvement that is always worth making. Overlap 10–20% of chunk size.
Chunks overlap — the end of one chunk is repeated at the beginning of the next.
This ensures that information at the boundary between chunks is not lost.
from langchain.text_splitter import RecursiveCharacterTextSplitter
splitter = RecursiveCharacterTextSplitter(
chunk_size=500,
chunk_overlap=75, # 15% of chunk_size is optimal
length_function=len,
)
chunks = splitter.split_text(document)
Pros: preserves context at chunk boundaries, improves recall, minimal implementation overhead.
Cons: data and embedding duplication, increased storage cost, almost identical chunks may appear in top-k (resolved by MMR).
Optimal overlap: 10–20% of chunk size. Less means losing context.
More means excessive duplication and increased cost.
When suitable: almost always as a supplement to another strategy. Rarely used as the primary strategy without semantic splitting.
3.3 Semantic Chunking
We split by semantic boundaries, not by fixed size. The gold standard for production in 2026.
Two main approaches. Embedding-based: we compute embeddings for each sentence,
and compare the cosine similarity between adjacent sentences. Where similarity sharply drops, that's the chunk boundary.
LLM-based: we ask the LLM to identify logical boundaries in the text. More expensive, but more accurate.
from langchain_experimental.text_splitter import SemanticChunker
from langchain_openai.embeddings import OpenAIEmbeddings
splitter = SemanticChunker(
OpenAIEmbeddings(),
breakpoint_threshold_type="percentile",
breakpoint_threshold_amount=95, # split where there's a sharp thematic transition
)
chunks = splitter.create_documents([document])
Pros: each chunk is semantically coherent (one topic), significantly better retrieval, less noise in LLM context.
Cons: more complex implementation, chunks have varying sizes, embedding-based approach requires computing embeddings during ingestion.
Numbers: according to
Chroma Research (2024)
,
LLMSemanticChunker achieved a recall of 91.9%, ClusterSemanticChunker — 89.7%.
When suitable: documentation, articles, knowledge bases, legal and financial texts. The optimal choice for most production scenarios.
⸻
3.4 Recursive / Hierarchical Chunking
We split hierarchically: first by large sections, then by paragraphs, then by sentences. The de facto standard in LangChain.
RecursiveCharacterTextSplitter attempts to split text by natural boundaries in a given order:
first by double newline (paragraph), then by single newline (line), then by period, then by space.
from langchain.text_splitter import RecursiveCharacterTextSplitter
# Separator priority: paragraph → line → sentence → word
splitter = RecursiveCharacterTextSplitter(
chunk_size=400,
chunk_overlap=50,
separators=["\n\n", "\n", ". ", " ", ""],
)
chunks = splitter.split_text(document)
Pros: attempts to preserve document structure, flexibility in setting separators, good balance between quality and simplicity.
Cons: requires setting separators for a specific format, may not handle complexly structured PDFs.
Numbers: according to
Chroma Research (2024)
,
RecursiveCharacterTextSplitter at 400–512 tokens provides 85–90% recall and is the best quality/cost balance for most teams.
When suitable: large structured documents, Markdown, HTML, general use without specific requirements.
⸻
3.5 Metadata-Aware Chunking
Not a separate splitting strategy — but a mandatory layer on top of any strategy. In production, it's impossible to filter results properly without metadata.
Each chunk is enriched with structured metadata: its source, section, date, content type.
This allows for pre-filtering before vector search and increases the relevance of results.
from langchain.schema import Document
chunk = Document(
page_content="Chunk text...",
metadata={
"source": "annual_report_2024.pdf",
"section": "Financial Results",
"page": 12,
"type": "financial",
"date": "2024-12-01",
"language": "uk",
}
)
Pros: pre-filtering before vector search (reduces search space), self-querying (LLM automatically generates filters), traceability — each answer is linked to a specific source.
Cons: requires designing a metadata schema, more complex ingestion pipeline.
When suitable: practically always in production. Metadata-aware is not a separate strategy but a supplement to any other.
⸻
3.6 Proposition Chunking (Advanced)
The most accurate approach: the document is split into atomic, self-contained statements. Maximum retrieval quality at maximum cost.
Each chunk is a single specific statement in the format of a complete, self-contained sentence.
Understandable without any additional context.
# Input text:
# "The company was founded in 2010. It has 500 employees and offices in 12 countries."
# After proposition chunking:
# Chunk 1: "The company was founded in 2010."
# Chunk 2: "The company has 500 employees."
# Chunk 3: "The company has offices in 12 countries."
This is implemented via LLM: we provide the text with the prompt "Split this text into separate atomic statements,
each in the format of a complete sentence understandable without context."
More on this in the article:
LLM context window
.
Pros: maximum retrieval accuracy, each chunk corresponds to a single specific fact, ideal for factoid QA.
Cons: high cost (requires an LLM for splitting), significantly more chunks, complex implementation and debugging.
Numbers:
Chroma Research (2024)
recorded a recall of 91.9% for LLM-based semantic chunking (analogous to the proposition approach) —
the highest result among all strategies.
When suitable: complex enterprise systems with high-value queries where the cost is justified by the quality.
⸻
3.7 Query-Aware Chunking (Advanced)
Chunks are formed or selected for a specific query. Maximum relevance at maximum cost.
One implementation variant is HyDE (Hypothetical Document Embedding): instead of searching by the original query,
we generate a hypothetical answer to it and search for chunks similar to this answer.
Why it works: the embedding of the "correct answer" is closer to relevant chunks than the embedding of the question itself.
from langchain.chains import HypotheticalDocumentEmbedder
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
llm = ChatOpenAI(model="gpt-4o-mini")
embeddings = OpenAIEmbeddings()
# HyDE: generate a hypothetical document for better embedding match
hyde_embeddings = HypotheticalDocumentEmbedder.from_llm(
llm=llm,
embeddings=embeddings,
prompt_key="web_search",
)
Pros: maximum relevance for a specific query, especially effective for complex multi-step questions.
Cons: additional LLM calls per query (cost + latency), complex implementation and debugging.
When suitable: complex enterprise systems with high-value queries. Not justified for simple Q&A systems.
This table compares the main data chunking strategies for RAG. It helps to quickly understand which approaches are suitable for a specific case, and to assess the balance between accuracy, completeness, cost, and implementation complexity.
| Strategy |
Precision |
Recall |
Cost |
Complexity |
Use case |
| Fixed-size |
Low |
Medium |
Low |
Low |
MVP, logs |
| Sliding window / overlap |
Medium |
High |
Medium |
Low |
Almost always (baseline + overlap) |
| Semantic |
High |
High |
Medium |
Medium |
Documentation, articles, knowledge base |
| Recursive / Hierarchical |
High |
High |
High |
High |
Large structured documents |
| Metadata-aware |
High |
High |
Low |
Medium |
Production RAG |
| Query-aware, Advanced |
Very high |
Very high |
High |
High |
Enterprise / complex systems |
Conclusion: The choice of chunking strategy depends on the data type and the requirements for accuracy and speed. For documents and knowledge bases, semantic chunking with overlap and metadata is usually used. For logs or MVPs, simple fixed-size is sufficient. Advanced approaches, like query-aware or recursive chunking, are effective for large or complex systems. The main thing is the balance between accuracy, completeness, cost, and implementation complexity.
📊 Benchmarks: What Research Says (2024–2025)
Semantic and proposition chunking consistently show recall of 87–92% compared to 50–65% for fixed-size baseline.
The difference between the best and worst approaches is up to 74 absolute percentage points in accuracy with the same model.
Numbers, not opinions. Below are the results of real research, not marketing claims.
Chroma Research (2024): Systematic Comparison on 474 Queries
Chroma conducted a systematic study
on 474 queries (generated by GPT-4-Turbo) on corpora of various types: Wikipedia, financial texts, chat logs.
| Strategy |
Recall |
Note |
| LLMSemanticChunker |
91.9% |
Highest recall, but highest cost |
| ClusterSemanticChunker |
89.7% |
Good quality/cost balance for semantic |
| RecursiveCharacterTextSplitter (400–512 tokens) |
85–90% |
Best balance for most teams |
| Fixed-size (no overlap) |
Lowest |
Baseline, not for production |
Important conclusion from Chroma: semantic chunking requires calculating embeddings for each sentence
during ingestion – this is significantly more expensive. The trade-off is justified only for high-value documents.
For most teams, RecursiveCharacterTextSplitter (400–512 tokens) is the optimal choice.
PMC Bioengineering (2025): +74% Accuracy from Chunking Change
A clinical study by PMC Bioengineering (2025)
built four identical RAG pipelines based on Gemini 1.0 Pro. They differed only in the chunking strategy.
On 30 post-operative queries:
| Strategy |
Accuracy |
Precision |
Recall |
F1 |
| Adaptive chunking |
87% |
0.50 |
0.88 |
0.64 |
| Semantic chunking |
~75% |
0.38 |
0.71 |
0.49 |
| Proposition chunking |
~70% |
0.33 |
0.65 |
0.44 |
| Fixed-size baseline |
50% |
0.17 |
0.40 |
0.24 |
A difference of 74 absolute percentage points in accuracy with the same model, the same data, and the same prompt.
The only variable is chunking. The researchers also found that optimal parameters for adaptive chunking
(cosine similarity ≥ 0.8, limit 500 words) require iterative tuning.
A threshold below 0.75 led to topic bleed, above 0.85 – excessively fragmented the text.
Summary Comparison Table of Strategies
| Strategy |
Precision |
Recall |
Cost |
Complexity |
When to use |
| Fixed-size |
low |
medium |
low |
low |
MVP, logs, prototype |
| Sliding window |
medium |
high |
medium |
low |
almost always as an addition |
| Semantic |
high |
high |
medium |
medium |
documentation, knowledge base |
| Recursive |
high |
high |
medium |
medium |
structured data, Markdown |
| Proposition |
very high |
very high |
high |
high |
enterprise factoid QA |
| Metadata-aware |
high |
high |
low |
medium |
production — mandatory |
| Query-aware (HyDE) |
very high |
very high |
very high |
high |
complex enterprise systems |
⸻
🗺️ Decision Tree: How to Choose a Strategy for Your Project
How to Choose a Chunking Strategy
The choice of strategy depends on three factors: document type (structured/unstructured),
project stage (MVP/production/enterprise), and accuracy requirements (precision vs. recall).
For most production scenarios, the optimal choice is: semantic chunking + 10–15% overlap + metadata.
Most articles explain how each strategy works. This one answers the question: "What should I choose for myself?"
Step 1: What type of data?
| Data Type |
Recommended Strategy |
Chunk Size |
| Logs, raw data |
Fixed-size |
500 tokens |
| Code (Python, JS, SQL) |
Fixed-size + boundary by functions |
100–300 tokens |
| PDFs with tables and complex structure |
LlamaParse/Docling for ETL + semantic |
400–600 tokens |
| Documentation, articles, knowledge base |
Semantic + overlap + metadata |
400–600 tokens |
| Legal / medical texts |
Semantic + proposition for critical sections |
300–500 tokens |
| Mixed data (various types) |
Recursive + metadata + different strategies by type |
depends on type |
Step 2: What is the project stage?
| Stage |
Strategy |
Implementation Time |
| PoC / MVP |
RecursiveCharacterTextSplitter (400 tokens, 50 overlap) + basic metadata |
A few hours |
| Production (first deployment) |
Semantic chunking + 10–15% overlap + metadata + MMR |
1–3 days |
| Enterprise / Scale |
Semantic + proposition for critical sections + rich metadata + pre-filtering + reranking |
1–2 weeks |
Step 3: What is the accuracy requirement?
- High recall is more important (do not miss any relevant information) → Larger chunk (500–800 tokens) + larger overlap (15–20%)
- High precision is more important (minimum irrelevant noise) → Smaller chunk (200–400 tokens) + semantic split + proposition for key sections
- Balance → 400–600 tokens + semantic + 15% overlap + MMR during retrieval
Basic Production Recipe (Suitable for 80% of Scenarios)
from langchain_experimental.text_splitter import SemanticChunker
from langchain_openai import OpenAIEmbeddings
from langchain.schema import Document
def create_production_chunks(text: str, metadata: dict) -> list[Document]:
"""
Basic production recipe:
semantic chunking + metadata enrichment
"""
splitter = SemanticChunker(
OpenAIEmbeddings(),
breakpoint_threshold_type="percentile",
breakpoint_threshold_amount=95,
)
chunks = splitter.create_documents([text])
# Enrich each chunk with metadata
enriched_chunks = []
for i, chunk in enumerate(chunks):
chunk.metadata = {
**metadata,
"chunk_index": i,
"chunk_total": len(chunks),
}
enriched_chunks.append(chunk)
return enriched_chunks
# Usage
chunks = create_production_chunks(
text=document_text,
metadata={
"source": "product_docs_v2.pdf",
"section": "API Reference",
"type": "documentation",
"date": "2024-12-01",
"language": "uk",
}
)
Then, retrieval with MMR and top_k = 3–5 to eliminate duplicates from overlap,
and reranking (bge-reranker-v2 or Cohere Rerank) for the final selection of the most relevant chunks.
According to
Pinecone/Superlinked
,
adding reranking improves retrieval quality by +48%.
⚙️ Production Settings: Size, Overlap, Metadata
Key Parameters for Production
The optimal chunk size is 400–600 tokens for most documents. Overlap is 10–20% of the size.
Minimum metadata: source, section, type. Top-k during retrieval is 3–5 with MMR to eliminate duplicates.
Chunk Size: How to Choose
| Size |
Effect |
When to Apply |
| 100–200 tokens |
Very high precision, low recall. Risk of losing context. |
Code, short FAQs |
| 200–400 tokens |
High precision. Optimal for factoid QA. |
Legal texts, specifications |
| 400–600 tokens |
Balance of precision/recall. Best choice for most documents. |
Documentation, articles, KB |
| 600–800 tokens |
Higher recall, lower precision. More noise in answers. |
Long narrative documents |
| 1000+ tokens |
Risk of embedding dilution. Embedding gets "blurred" between topics. |
Not recommended |
Overlap: Optimal Values
| Overlap |
Effect |
| 0% |
Loss of context at boundaries. Not recommended even for MVP. |
| 5–10% |
Minimal overhead, sufficient for simple texts. |
| 10–20% |
Optimum for most scenarios. |
| 25–30% |
Excessive duplication, increases cost. |
| > 30% |
Identical chunks in retrieval results. Counterproductive. |
Metadata: Minimum and Extended Schema
Minimum for production:
{
"source": "document_name.pdf",
"section": "Section title or heading",
"type": "doc | article | code | legal | financial",
"page": 5,
"chunk_index": 12
}
Extended schema for large systems:
{
"source": "annual_report_2024.pdf",
"section": "Q3 Financial Results",
"type": "financial",
"page": 12,
"date_created": "2024-11-30",
"language": "uk",
"department": "finance",
"access_level": "internal",
"chunk_index": 5,
"chunk_total": 48
}
Retrieval Settings
# Retriever settings with MMR to eliminate duplicates
retriever = vectorstore.as_retriever(
search_type="mmr", # Maximum Marginal Relevance
search_kwargs={
"k": 5, # top-k chunks in the final result
"fetch_k": 20, # candidates for MMR selection
"lambda_mult": 0.7, # 0 = max diversity, 1 = max relevance
"filter": { # pre-filtering by metadata
"type": "documentation",
"language": "uk",
}
}
)
Top-k recommendations: 3–5 for most scenarios.
More increases noise and token cost.
Less risks missing relevant information.
According to
ZeroEntropy (2025–2026)
,
reranking 50 candidates → top-5 provides an optimal balance of quality/speed for LLM chats.
⚠️ Pitfalls: 6 problems that break retrieval
Most common chunking errors
Six key problems: fragmentation (chunks are too small), boundary problem (information split between chunks),
duplicate chunks (duplication from overlap), embedding dilution (multiple topics in one chunk),
lost in the middle (LLM ignores the middle of the context), over/under chunking (incorrect size without measurement).
7.1 Fragmentation (excessive splitting)
Problem: Chunk is too small – meaning is lost. The sentence "Service cost - 500 UAH" is meaningless without prior context. Retrieval finds "correct" chunks, but the model cannot provide a complete answer.
Solution: Increase chunk size or add overlap. The minimum chunk for complex documents is 200 tokens. Test model responses to typical queries after changes.
7.2 Boundary Problem (split at the edge)
Problem: Key information is distributed between two chunks. Cause, condition, and effect are in different chunks. Answers are "almost correct" – the model finds part of the picture, but not the whole.
Solution: Overlap + semantic splitting. Overlap ensures that the boundary between chunks does not cut critical information. Semantic splitting ensures that the boundary is in the right place at all.
7.3 Duplicate Chunks
Problem: Overlap creates almost identical chunks that end up in top-k together. The LLM's context is filled with duplicates. The model repeats the same information several times in its response.
Solution: MMR (Maximum Marginal Relevance) during retrieval or reranking with deduplication. In LangChain – search_type="mmr".
7.4 Embedding Dilution
Problem: One chunk contains multiple unrelated topics. The embedding tries to represent all topics and as a result, accurately represents none. The cosine similarity of all chunks is approximately the same, making it difficult to identify the top relevant ones.
Example: An 800-token chunk where the first half is about product A, and the second half is about product B. A search for "product A characteristics" will find this chunk with mediocre relevance.
Solution: Reduce chunk size or apply semantic splitting so that each chunk corresponds to one topic.
7.5 Lost in the Middle
Problem: Even if retrieval finds the correct chunks, the LLM may ignore information in the middle of the context.
Stanford TACL (2024)
documented a degradation in recall of 25–45% for information in the middle of the context window – even for frontier models.
Solution: We recommend limiting the number of chunks in the context (top-k = 3–5).
We also apply strategic ordering during reranking: the most relevant fragment is placed
at the beginning of the context, and the second most relevant – at the end.
7.6 Over / Under Chunking
Problem: Chunks that are too small create noise and loss of context. Chunks that are too large reduce precision and create embedding dilution.
Most teams set the size "by intuition" and don't change it – even if metrics signal a problem.
Solution: Test chunk size as a hyperparameter. Set a baseline metric (recall or faithfulness via
RAGAS
or
DeepEval),
then change one parameter at a time and measure the impact.
💼 Project Cases: How chunking solved real problems
Transitioning from fixed-size to semantic chunking + metadata on real projects resulted in a recall increase
from 20% to 70% depending on the document type. Key insight: the problem is almost always in chunking or
metadata, not in the model.
Case 1: Customer Support Knowledge Base
Situation: RAG system for answering customer questions about a product.
Documents include FAQs, instructions, and release notes. Initial configuration: chunk_size=1000, chunk_overlap=0.
Recall on test questions was around 55%.
Problem: The instruction "How to reset password" spanned 3 paragraphs. The fixed-size splitter broke it into two chunks in the middle of the third step. Retrieval found the first chunk with steps 1–2, but without step 3.
The module's response was: "Go to Settings → Security → Enter email" (without the final step "check your email and follow the link").
Customers repeatedly contacted support.
What was done:
- Changed to
RecursiveCharacterTextSplitter(chunk_size=400, chunk_overlap=60)
- Added metadata:
type (faq/instruction/release_note), product_area, version
- Added pre-filtering: for queries about a specific product version, filter chunks by
version
- Retrieval:
search_type="mmr", top-k=4
Result: Recall increased to 81%. The number of repeat inquiries for the same questions decreased by 35%.
The time to the first response was reduced because the model started providing complete instructions from the first attempt.
⸻
Case 2: RAG on Internal Documentation (mixed document types)
Situation: Internal assistant for the development team. The index includes technical documentation,
API specifications, architectural decisions (ADRs), and internal wiki pages. All documents were loaded with the same
chunk_size=800.
Problem: An API specification contained a table of endpoints – 20 rows, each with a method, URL, and description. The fixed-size splitter broke the table into three chunks. When querying "What is the method for updating a profile?", retrieval returned a chunk with part of the table, but without the required row – it was in another chunk.
ADR documents (1–2 pages) ended up in one large chunk, and their embeddings became "diluted".
What was done:
- Implemented different strategies for different types:
- API specifications: LlamaParse for ETL (preserves tables as whole blocks) + semantic chunking
- Wiki and ADR: RecursiveCharacterTextSplitter (chunk_size=400) + 15% overlap
- Code in documentation: custom splitter by functions and classes (chunk_size=200–300)
- Metadata:
doc_type, team, last_updated, component
- Hybrid search: dense + BM25 via Qdrant (BM25 captures exact endpoint names)
Result: Recall on API queries increased from 48% to 84%. Questions about specific endpoints started
receiving correct answers from the first attempt. The team stopped "Googling in Confluence" and trusts the assistant
for technical references.
⸻
Case 3: Search on Financial Documents (quarterly reports)
Situation: System for analysts: searching through companies' quarterly reports.
PDF documents with tables, charts, and textual commentary. Over 2000 documents in the index.
Initial recall was around 52% on factual questions (specific figures, dates, item names).
Problem: The fixed-size splitter broke tables – rows of financial data without column headers were meaningless. A query "What was the EBITDA in Q3 2023?" found the row "15.4 | 18.2 | 12.7 | 21.1" without context that it was EBITDA and which quarters it represented.
What was done:
- ETL via LlamaParse – preserves tables as Markdown blocks with headers
- Semantic chunking with separate table processing: each table is a separate chunk (regardless of size), text sections are semantically split
- Metadata:
company_ticker, report_type, period (Q1/Q2/Q3/Q4/Annual), fiscal_year, content_type (table/text/chart_description)
- Pre-filtering: query "EBITDA Q3 2023" → filter by
period=Q3, fiscal_year=2023 before vector search
- Hybrid search: BM25 captured exact financial terms and item names, dense – semantic context
Result: Recall increased to 87%. Faithfulness (according to
RAGAS)
doubled. Analysts began to trust the system for report preparation and stopped manually
verifying every figure. The time to prepare an analytical report decreased by approximately 40%.
❓ Frequently Asked Questions (FAQ)
What default chunk size should I choose?
400–500 tokens + 15% overlap is a good starting size for most documents.
This is confirmed by
Chroma Research (2024)
:
RecursiveCharacterTextSplitter at 400–512 tokens provides 85–90% recall and is the best balance for most teams.
Then, test and adjust for the specific document type.
Is overlap always necessary?
Almost always – yes. 10–15% overlap prevents context loss at chunk boundaries without significantly increasing cost.
Exception: very short, self-contained documents (FAQs with single-line answers) where each chunk is already a
complete independent fragment.
What is the difference between semantic chunking and RecursiveCharacterTextSplitter?
RecursiveCharacterTextSplitter splits based on a hierarchy of separators (paragraph → line → sentence) and limits the size.
Semantic chunking calculates embeddings and splits where the topic changes sharply – regardless of physical size.
Semantic provides better recall but requires embedding calculation during ingestion (2–5x more expensive).
For most teams, it is recommended to start with Recursive and move to Semantic for high-value documents.
How to handle PDFs with tables?
Standard text splitters break tables. Special ETL is required:
LlamaParse
(78% edit similarity, $0.003/page) or
Docling
(open-source, 97.9% accuracy on tables according to
Procycons benchmark (2025)
).
After ETL, store tables as whole blocks (one chunk = one table) and apply
semantic chunking to text sections.
How to know if chunking is configured well?
Measure. Set up automatic evaluation via
RAGAS
or
DeepEval
on a test set of 50–100 questions.
Key metrics: Context Recall (was all relevant information found?), Context Precision
(is there noise in what was found?), Faithfulness (is the answer supported by the retrieved context?).
Change one parameter at a time and measure the impact.
How many chunks are needed for good retrieval?
Top-k = 3–5 is sufficient for most queries. More chunks in the context means more noise and a higher risk
of "lost in the middle". If recall is low, it's better to improve chunking and embeddings than to increase top-k.
✅ Conclusions
In RAG, the best model doesn't win – the correctly configured pipeline wins.
And chunking is the first and most important layer of this pipeline.
-
There is no single "correct" strategy. The choice depends on the document type, project stage, and quality requirements.
Fixed-size – for MVP, semantic + metadata – for production, proposition – for enterprise with high-value queries.
-
The numbers are real.
PMC (2025)
and
Chroma (2024)
demonstrate: changing the chunking strategy with the same model yields +20–74% to accuracy.
No LLM change will yield such results without proper retrieval.
-
Basic production recipe: semantic chunking + 10–15% overlap + metadata (source, section, type)
+ top-k 3–5 + MMR or reranking. Suitable for 80% of scenarios.
-
Without evaluation, quality cannot be understood.
Set up
RAGAS
or
DeepEval
before starting optimization. Otherwise, you will be changing parameters blindly.
-
Chunking is a hyperparameter, not a one-time solution.
The optimal parameters for legal texts and for FAQs are drastically different.
Test, measure, iterate.