By 2026, Chinese LLM platforms are rapidly closing the gap with Western frontier models. Z.ai by Zhipu AI is one of the frontrunners of this movement thanks to GLM-5.
Spoiler: GLM-5 (744B MoE, 40B active) reaches Claude Opus 4.5 levels in agentic coding and reasoning, while being open-source (MIT) and significantly cheaper via API.
⚡ In short
- ✅ Z.ai: Zhipu AI's international platform with a free chat and a powerful (OpenAI-compatible) API.
- ✅ Chat mode: Fast inference, ideal for RAG and simple dialogues.
- ✅ Agent mode: Built-in tools, document generation (.docx, .pdf, .xlsx), and multi-turn workflows.
- 🎯 What you’ll get: A clear understanding of the architecture, when to use Chat vs. Agent, and why GLM-5 wins on price/performance.
📚 Table of Contents
This article gathers the key materials for understanding Z.ai (Zhipu AI) LLM
🎯 What is Z.ai and its place in the 2026 LLM market
Z.ai is the international platform of Zhipu AI (Knowledge Atlas Technology), providing a free chat agent (chat.z.ai), an OpenAI-compatible API (api.z.ai), and access to the flagship GLM-5 model.
In 2026, Z.ai is one of the top 3 open-weight platforms (alongside DeepSeek and Qwen), and GLM-5 is the leading open-source model for agentic engineering and long-horizon tasks, with results on par with Claude Opus 4.5 / GPT-5.2 in coding and reasoning.
Zhipu AI trained GLM-5 entirely on Huawei Ascend (MindSpore), with no dependence on the NVIDIA hardware stack — a key geopolitical and technical factor after being added to the US Entity List in 2025.
Z.ai consists of a consumer interface (chat.z.ai) and a developer platform (api.z.ai) that is fully compatible with the OpenAI API spec (/v4/chat/completions). Zhipu AI held its IPO on the Hong Kong Stock Exchange on January 8, 2026 (ticker 2513.HK), raising ~HK$4.35 billion. Following the release of GLM-5 on February 11, 2026, the company's shares showed rapid growth.
Official GLM-5 announcement |
Main Z.ai website
Who is behind the platform
Zhipu AI is one of China's largest independent AI developers, founded by professors from Tsinghua University. Investors include Alibaba, Tencent, Meituan, Xiaomi, and Saudi Arabia's Prosperity7 Ventures. Following its IPO, the company became the world's first public foundation-model company, highlighting its financial and technological maturity.
Why this matters for developers and enterprises in 2026
GLM-5 delivers SOTA results: SWE-bench Verified 77.8%, Terminal-Bench 2.0 ~61.1%. Meanwhile, the API price (per 1 million tokens) is 3–10 times lower than Claude Opus 4.5 or GPT-5.2. The MIT license ensures full control over data through self-hosting.
GLM-5 in action: developers use the platform for autonomous pipelines: from architecture to deployment, with built-in self-correction capabilities and generation of complex artifacts (.docx/.pdf/.xlsx).
- ✔️ Open-weight MIT → full control over data and the model.
- ✔️ 200K context + DSA → efficient RAG without quality loss.
- ✔️ Agent mode → real deliverables (documents, code) instead of just text.
Bottom line: In 2026, Z.ai is the infrastructure for agentic AI: powerful, open, cost-effective, and independent of the Western hardware ecosystem.
📌 Platform Architecture: API, Models, Tool-calling
Z.ai API is fully compatible with the OpenAI specification (/v4/chat/completions), supporting GLM-5 and other models, thinking mode (enabled by default in GLM-5), function/tool calling, streaming, context caching, and structured output.
The single entry point for general tasks is [https://api.z.ai/api/paas/v4](https://api.z.ai/api/paas/v4); for coding and agentic scenarios, use the specialized endpoint [https://api.z.ai/api/coding/paas/v4](https://api.z.ai/api/coding/paas/v4).
The Z.ai architecture is built around a unified OpenAI-compatible backend, allowing you to migrate code from OpenAI or Anthropic simply by changing the base_url and api_key, without rewriting tool-calling or reasoning logic.
The platform consists of three primary layers:
- Frontend / Consumer interface:
chat.z.ai — a free web chat featuring Agent mode and built-in "skills" (generating .docx, .pdf, .xlsx, landing pages, code, etc.).
- Backend API: RESTful endpoints at [https://api.z.ai/api/paas/v4](https://api.z.ai/api/paas/v4) (general) and [https://api.z.ai/api/coding/paas/v4](https://api.z.ai/api/coding/paas/v4) (for GLM Coding Plan / agentic coding). Full compatibility with OpenAI SDKs (Python, JS, etc.) — just swap the base URL and key.
- Models and Inference: The flagship GLM-5 (744B MoE, 40B active), GLM-4.7, GLM-4.6, etc., deployed on a proprietary cluster (Huawei Ascend + MindSpore). Supports DeepSeek Sparse Attention (DSA) for efficient long-context processing (200K tokens).
Official Quick Start | API Reference (chat/completions)
Tool-calling and Function Execution
Tool-calling is implemented following the OpenAI standard: parameters include tools (an array of functions with JSON schema) and tool_choice (none / auto / required / specific function). The model returns tool_calls in the response, supporting multi-tool calls and interleaved thinking (reasoning between tool invocations). GLM-5 features improved tool-use accuracy thanks to a specialized RL stage during training.
Official Function Calling Documentation
Thinking Mode and Reasoning Capabilities
GLM-5 offers several thinking modes: by default, it uses interleaved thinking (reasoning before each response and tool call). Controlled via the parameter thinking: {"type": "enabled"} or "disabled". On the coding endpoint, it is enabled by default; on the general endpoint, it can be toggled. This allows the model to perform complex step-by-step reasoning, self-correction, and tool-call chaining with intermediate result analysis.
Thinking Mode Details | GLM-5 Announcement detailing Agentic Engineering
Additional Key Features
- ✔️ Streaming — Real-time output (
stream: true), including support for tool streaming.
- ✔️ Context Caching — Intelligent caching for long sessions, reducing costs for repeated context.
- ✔️ Structured Output — Enforced JSON or schema output for seamless system integration.
- ✔️ Max Parameters:
max_tokens up to 128K, temperature, top_p, etc. — all identical to OpenAI.
Structured Output | Context Caching
Basic API Request Example (cURL, OpenAI-compatible)
curl -X POST "[https://api.z.ai/api/paas/v4/chat/completions](https://api.z.ai/api/paas/v4/chat/completions)"
-H "Authorization: Bearer YOUR_API_KEY"
-H "Content-Type: application/json"
-d '{
"model": "glm-5",
"messages": [{"role": "user", "content": "Hi, what is Agentic Engineering?"}],
"temperature": 0.7,
"max_tokens": 1024,
"thinking": {"type": "enabled"},
"stream": true
}'
Z.ai Architecture is a developer-friendly infrastructure: full OpenAI compatibility, powerful agentic features (tool-calling + interleaved thinking), and specialized endpoints make it ideal for quick migration and production-grade use of agents and complex reasoning.
Chat Mode — How it Works
Chat Mode is the classic completions endpoint (/v4/chat/completions): fast, lightweight inference without built-in tool orchestration or agent loops. It is perfect for interactive dialogues, RAG, text generation, code reviews, and basic reasoning.
In GLM-5, thinking mode is on by default (interleaved thinking), context is preserved in the message history (up to 200K tokens), and it supports multimodality (text + images/audio/video/files). Latency is significantly lower than in Agent mode.
Chat mode is the "fast brain": the model responds instantly without the overhead of planning, calling tools, or generating artifacts. This makes it optimal for real-time applications.
In the web interface at chat.z.ai, Chat mode is active by default. In the API, it is a standard call to /api/paas/v4/chat/completions using OpenAI-compatible parameters. GLM-5 utilizes an MoE architecture (744B total, 40B active) + DeepSeek Sparse Attention (DSA) for efficient long-context inference without a massive spike in costs.
Official Chat Completion Documentation | GLM-5 Announcement describing Chat vs. Agent
Internal Inference Pipeline in Chat Mode
- Request → Tokenization of messages (system prompt + history + user input).
- Context (up to 200K tokens) passes through MoE + DSA (sparse attention saves ~50–70% compute compared to dense).
- GLM-5 generates a response with interleaved thinking (reasoning between decode steps if
thinking: {"type": "enabled"}).
- No automatic tool calls — if a tool is needed, the model will provide a text description but won't trigger it automatically (unlike Agent mode).
- Streaming (
stream: true) outputs tokens in real-time; first-response latency is <1–2s for simple queries.
Key Features and Parameters
- ✔️ System Prompt — Full support, maintained in history.
- ✔️ Multi-turn Context — Automatic preservation of previous messages (up to 200K tokens).
- ✔️ Multimodal Input — Text + images/audio/video/files (GLM-5 supports native vision/audio processing).
- ✔️ Thinking Mode — Enabled by default (interleaved); can be disabled for speed. Supports
clear_thinking to wipe previous reasoning steps.
- ✔️ Streaming — Real-time token delivery (
stream: true).
- ✔️ Structured Output — Possible via
response_format (JSON schema, etc.).
Thinking Mode Details | Streaming Messages
Chat Mode API Request Example (Python, OpenAI SDK Compatible)
from openai import OpenAI
client = OpenAI(
api_key="YOUR_ZAI_API_KEY",
base_url="[https://api.z.ai/api/paas/v4](https://api.z.ai/api/paas/v4)"
)
response = client.chat.completions.create(
model="glm-5",
messages=[
{"role": "system", "content": "You are a Python expert. Answer clearly with code examples."},
{"role": "user", "content": "Write a function to parse a CSV with 200K rows efficiently."}
],
temperature=0.7,
max_tokens=2048,
thinking={"type": "enabled"},
stream=True
)
for chunk in response:
if chunk.choices[0].delta.content:
print(chunk.choices[0].delta.content, end="", flush=True)
Best Use-Cases for Chat Mode
- ✔️ Interactive chatbots (customer support, technical help).
- ✔️ RAG pipelines (search + response generation on large document sets).
- ✔️ Text/code/content generation without the need for physical deliverables (articles, poems, refactoring).
- ✔️ Rapid prototyping of ideas (brainstorming, conceptual explanations).
- ✔️ Multimodal queries (image description + questions, audio transcription + analysis).
Section Conclusion: Z.ai's Chat mode is a fast, cost-effective, and reliable tool for any task requiring instant responses, long context, or multimodality without complex agent planning overhead. Use it as the foundation for production chats and RAG, and reserve Agent mode for autonomous tasks requiring deliverables.
Agent Mode — How it Differs from Chat
Short answer: Agent mode is a full agentic interface with built-in skills, autonomous tool-calling, multi-turn planning, and the generation of real deliverables (.docx, .pdf, .xlsx, websites, etc.). The model plans, invokes tools, verifies results, and iterates until the task is complete.
Unlike Chat mode (fast one-off text/code generation), Agent mode implements the full cycle of agentic engineering: understanding → planning → tool execution → self-check → revise → deliverable.
Agent mode represents the shift from "vibe coding" (fast code based on intuition) to true agentic engineering: autonomous execution of complex, long-term tasks with real outcomes, not just answers.
In the web interface at chat.z.ai, Agent mode is activated via a toggle (or automatically for complex queries). In this mode, GLM-5 uses built-in "skills" to create documents, analyze data, and generate websites or slides. In the API, Agent mode is implemented via the standard /chat/completions with tool-calling enabled, thinking mode (preserved + interleaved), and tool_stream=true for real-time tool parameter retrieval.
Official GLM-5 Blog: From Vibe Coding to Agentic Engineering | GLM-5 Overview in docs
Key Differences: Agent Mode vs. Chat Mode
| Aspect |
Chat Mode |
Agent Mode |
| Goal |
Fast answer, dialogue, text/code generation |
Autonomous task execution → real deliverable |
| Inference Pipeline |
One-off decode + interleaved thinking |
Iterative cycle: plan → tool call → observe → revise → repeat |
| Tool-calling |
Can describe a tool but doesn't auto-invoke |
Autonomous invocation, tool chaining, streaming results |
| Thinking Mode |
Interleaved (default), not preserved between turns |
Preserved thinking (across turns) + interleaved + self-check |
| Output |
Text, code, JSON (structured) |
Ready files (.docx, .pdf, .xlsx), websites, slides, full projects |
| Latency / Cost |
Low (instant) |
Higher (multi-turn), but efficient due to DSA |
| Best Use-cases |
RAG, chatbots, brainstorming, fast code |
Complex agent tasks: full-stack dev, doc generation, long-horizon simulation |
Built-in Skills and Artifacts in Agent Mode (Web Interface)
GLM-5 in Agent mode features native skills for:
- Document Generation: PRDs, lesson plans, exams, financial reports, menus → .docx / .pdf / .xlsx
- Data Analysis: Creating tables, charts, and reports from raw data.
- Full-stack Development: Frontend + backend + deploy scripts.
- Multi-turn Collaboration: Iterative refinement with the user.
Example: A query for "Create a sponsorship proposal for a school soccer team" → the model generates a .docx with sections, tables, image placeholders, and a professional color palette.
Examples of deliverables in the GLM-5 blog
Implementing Agent Mode in the API
Use the standard endpoint with:
tools / tool_choice: "auto" or "required"thinking: {"type": "enabled"} (preserved thinking on the coding endpoint)tool_stream: true for real-time tool parameters.- The model decides: invoke tool, continue thinking, or finish.
This enables building autonomous agents (e.g., via LangChain or OpenClaw integration).
Function Calling Guide | Preserved & Interleaved Thinking
Agent Mode Workflow Example (Vending Bench 2 Simulation)
- Request: "Launch a vending machine business for 1 year."
- Model plans: Market analysis → location selection → procurement → pricing.
- Iteratively invokes tools (sales simulation, expense calculation).
- Self-check: Adjusts strategy based on intermediate results.
- Deliverable: Final balance of $4,432.12 + a report in .xlsx.
This demonstrates the long-horizon agentic capabilities of GLM-5 (SOTA among open-source models on Vending Bench 2).
Conclusion: Agent mode in Z.ai / GLM-5 is a genuine leap toward autonomous systems: shifting from simple answers (Chat) to the full execution of complex tasks with deliverables and self-correction. Use it for production agents, enterprise automation, and long-range tasks where Chat mode is insufficient.
The Main Engine: GLM Series, Focus on GLM-5
GLM-5 is Zhipu AI’s flagship 2026 model: 744B total parameters (MoE, 40B active), context up to 202,752 tokens (eval), max output of 131,072 tokens, DeepSeek Sparse Attention (DSA), pre-trained on 28.5T tokens, MIT-licensed.
GLM-5 specializes in agentic engineering and long-horizon tasks, achieving SOTA among open-weight models: SWE-bench Verified 77.8%, Terminal-Bench 2.0 56.2–60.7%, and Vending Bench 2 $4,432.12, approaching Claude Opus 4.5 and GPT-5.2 levels in coding/reasoning/agent benchmarks.
GLM-5 marks the transition from "vibe coding" to true agentic engineering: autonomous execution of complex system tasks with self-correction, tool chaining, and real deliverables.
The GLM series has evolved from GLM-4 (2024–2025) to GLM-5 (released Feb 12, 2026). GLM-5 scales parameters from 355B (32B active in GLM-4.5) to 744B (40B active), increases pre-training from 23T to 28.5T tokens, and integrates DeepSeek Sparse Attention (DSA) for efficient long-context processing alongside "slime" (an asynchronous RL framework) for fine-grained post-training optimization.
Official GLM-5 Announcement | Model on Hugging Face | ModelScope | GLM-5 Overview in docs
GLM-5 Architecture: Key Technical Specifications
- ✔️ Parameters: 744B total (MoE with 256 experts, top-8 activation, ~40B active per token, sparsity ~5.9%).
- ✔️ Attention: DeepSeek Sparse Attention (DSA) — reduces inference costs while maintaining long-context (saving ~50–70% compute vs. dense).
- ✔️ Context Window: Up to 202,752 tokens (eval HLE w/ Tools), 200K in SWE-bench, 128K in Terminal-Bench; max generation of 131,072 tokens.
- ✔️ Modalities: Text + native document generation (.docx, .pdf, .xlsx); multimodality across the series (vision/audio in specific models).
- ✔️ Tool-calling & Agentic: Native support for function calling, thinking mode (interleaved/preserved), and OpenClaw framework for cross-app agents.
- ✔️ Post-training: Slime (asynchronous RL) for fine-grained iterations, resulting in record-low hallucination rates on AA-Omniscience.
- ✔️ License: MIT — full open-weight, self-hosting, and fine-tuning permitted.
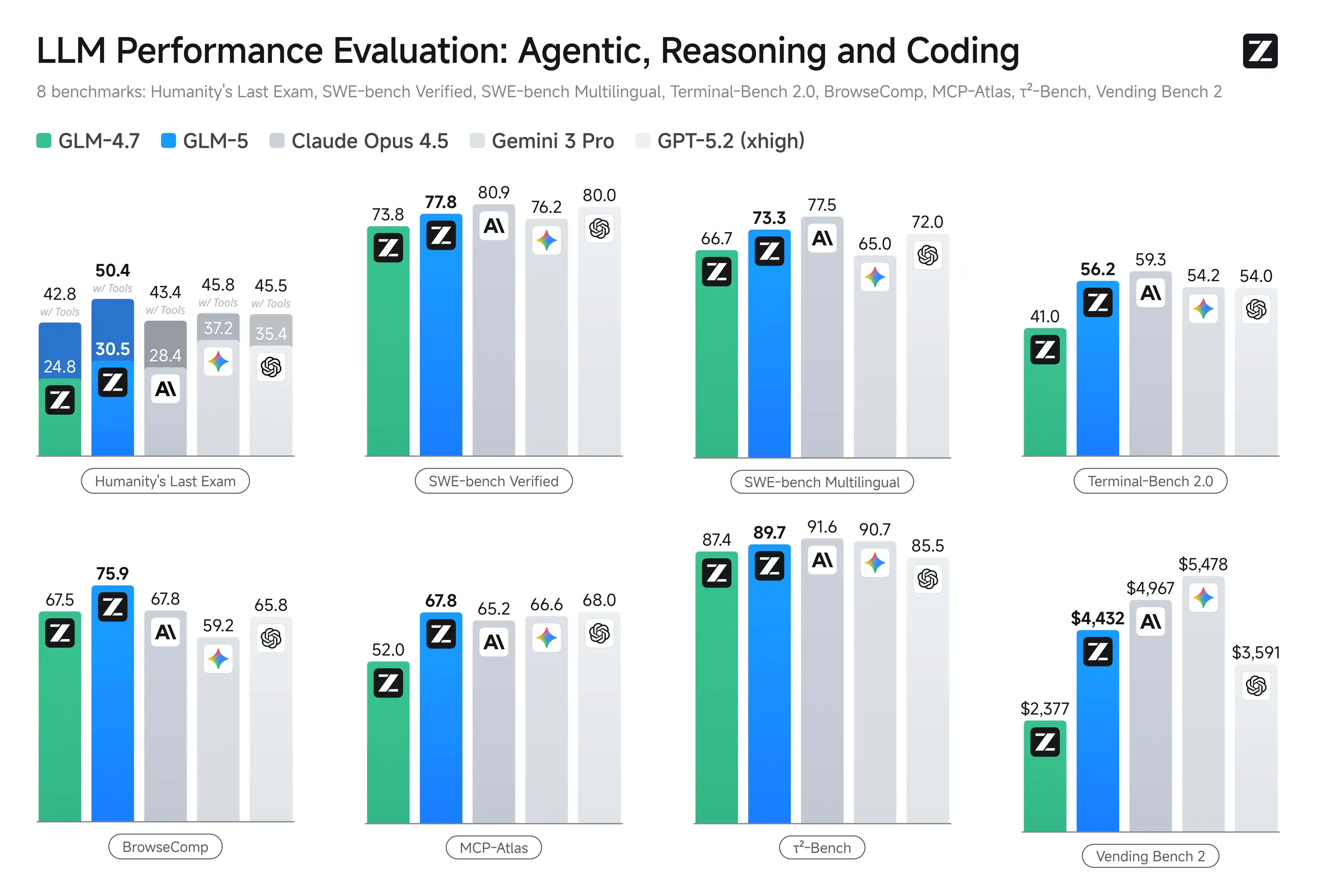
Main GLM-5 Benchmarks (Thinking Mode, 2026 Eval)
| Benchmark |
GLM-5 |
GLM-4.7 |
Claude Opus 4.5 |
GPT-5.2 (xhigh) |
Note |
| SWE-bench Verified | 77.8% | 73.8% | 80.9% | 80.0% | 200K context |
| SWE-bench Multilingual | 73.3% | 66.7% | 77.5% | 72.0% | — |
| Terminal-Bench 2.0 (Terminus 2) | 56.2% / 60.7%† | 41.0% | 59.3% | 54.0% | 128K context, verified |
| BrowseComp w/ Context Manage | 75.9% | 67.5% | 67.8% | 65.8% | discard-all strategy |
| HLE w/ Tools | 50.4% | 42.8% | 43.4%* | 45.5%* | 202K input / 131K output |
| Vending Bench 2 | $4,432.12 | $2,376.82 | $4,967.06 | $3,591.33 | long-horizon agent sim |
| τ²-Bench | 89.7% | 87.4% | 91.6% | 85.5% | tool invocation |
| Tool-Decathlon | 39.2% | 23.8% | 43.5% | 46.3% | multi-tool |
† Verified dataset | * full set | GLM-5 leads among open-weight models, closing the gap with frontier models in agentic/coding.
Comparison with Previous GLM Models
GLM-5 represents a ~2× scale increase from GLM-4.5 (355B → 744B total, 32B → 40B active), +24% pre-training data (23T → 28.5T), DSA replacing standard attention, and slime RL for post-training. The result: a +20% average gain on benchmarks, establishing it as SOTA open-source in reasoning, coding, and agentic tasks.
Availability and Deployment
- ✔️ Open-source: Hugging Face (zai-org/GLM-5), ModelScope (ZhipuAI/GLM-5), FP8-quantized versions available.
- ✔️ Inference: vLLM, SGLang, Ascend NPU, KTransformers; compatible with non-NVIDIA hardware (Huawei Ascend, Moore Threads, etc.).
- ✔️ API: api.z.ai (OpenAI-compatible), OpenRouter, Together AI, etc.
- ✔️ Free Access: chat.z.ai (Agent/Chat mode).
Conclusion: In 2026, GLM-5 is one of the strongest open-weight models for coding, agentic engineering, and long-horizon planning. It delivers top-tier results in key benchmarks (SWE-bench Verified 77.8%, Terminal-Bench 2.0 ~56–61%, Vending Bench 2 $4,432), combining an efficient architecture (MoE 744B/40B active + DeepSeek Sparse Attention) with an open MIT license and low API/self-hosting costs. This makes it a highly competitive choice for developers and companies seeking frontier-level capabilities without closed-model lock-in and with total control over infrastructure and data.
What Tasks Z.ai is Suitable For
Z.ai (focusing on GLM-5): perfectly suited for agentic engineering, complex coding, document/report generation, long-term autonomous agents, and enterprise RAG on massive contexts—at a significantly lower price point than Claude Opus 4.5 or GPT-5.2.
The platform wins in tasks requiring autonomy, self-correction, multi-turn planning, the generation of real deliverables (.docx/.pdf/.xlsx), and efficient handling of 200K context windows.
Z.ai transforms the LLM from a "conversational tool" into a "workhorse": moving beyond text generation to full task execution with final artifacts and long-term planning.
GLM-5 and Agent mode on chat.z.ai / api.z.ai are specifically optimized for complex systemic tasks. Thanks to DSA (DeepSeek Sparse Attention), the MoE architecture, and "slime" RL, the model effectively handles long-horizon workflows where Claude or GPT are often more expensive or less autonomous.
Official GLM-5 Blog: Use-cases and Examples
Top Use-Case Scenarios (Where Z.ai excels or saves costs)
- ✔️ Agentic coding and full-stack development: Autonomous code generation (frontend + backend + deploy), bug-fixing, legacy code refactoring, and architectural planning. Example: uploading a repository → coupling analysis → microservices plan → cross-file refactoring.
- ✔️ Enterprise document and office artifact generation: PRDs, lesson plans, financial reports, sponsorship proposals, equity research, and spreadsheets from raw data → ready-to-use .docx/.pdf/.xlsx. Example: "Create a sponsorship proposal for a school soccer team" → full document with sections, tables, color palette, and image placeholders.
- ✔️ Long-term agents with self-correction: Business simulation (Vending Bench 2: $4,432 balance over a year), multi-tool chaining, and planning across thousands of steps. Ideal for autonomous pipelines (Devin-like agents).
- ✔️ Enterprise RAG and long-context reasoning: Analyzing massive codebases, documentation, and datasets (200K+ tokens), BrowseComp-style web navigation with context management (75.9%).
- ✔️ Multilingual coding and terminal workflows: Strong results on SWE-bench Multilingual (73.3%) and Terminal-Bench (56–61%).
- ✔️ Budget-friendly production agents: API at ~$1/M input / $3.2/M output — 5–10× cheaper than Claude/GPT with near-parity in agentic/coding quality.
Real-World Case Examples (from 2026 sources and community)
- Legacy refactoring automation: Uploading a monolithic project → GLM-5 analyzes modules → proposes and executes microservices split → generates code + tests.
- Office automation: Raw sales data → automatic .xlsx report with charts + .docx executive summary + .pdf presentation slides.
- Business simulation: "Launch a vending business for a year" → model plans locations, procurement, prices → iterates based on simulations → final balance $4,432 (#1 open-source on Vending Bench 2).
- Coding agent integration: Via OpenClaw / Claude Code / OpenRouter — GLM-5 executes Terminal-Bench tasks with 128K context and resource limits.
Tasks where Z.ai is NOT suitable (or trails behind Claude / GPT-5.2)
- ✖️ Ultra-real-time chatbots and high-throughput: Agent mode is slower (17–19 tokens/sec vs 25–30+ in Claude/GPT); interleaved thinking adds latency. Chat mode or lighter models are better here.
- ✖️ Native multimodal (vision-heavy) tasks: GLM-5 is text + document generation focused; full multimodal (image/video reasoning) exists in separate models (GLM-Image) but lags behind GPT-5.2 / Gemini in MMMU or physical understanding.
- ✖️ Maximum situational awareness and creative/nuanced prompts: Claude Opus 4.5/4.6 is often better at ambiguous, creative coding, UI mockups from descriptions, and subtle bug detection. GLM-5 is more of an "engineering copilot"—structured but less "intuitive."
- ✖️ Self-hosting on limited hardware without optimization: 744B MoE requires massive resources (memory, GPU/Ascend); local deployment needs vLLM/SGLang + quantization.
- ✖️ Short & lightweight tasks without deliverables: For simple chats or brainstorming, the overhead of Agent mode isn't justified—stick to Chat mode or cheaper models.
Bottom line: Z.ai / GLM-5 is the go-to for autonomous, agentic, and coding tasks with deliverables where cost-efficiency, open-source, and long-horizon planning are key. It trails in speed, pure multimodality, and certain creative scenarios—where Claude or GPT are superior. Use Z.ai where autonomy + budget matter more than raw speed or intuition.
Limitations and Positioning
Primary limitations of Z.ai / GLM-5 in 2026 include peak throttling and low concurrency (often limited to 1 parallel request even on paid plans), high quota consumption for GLM-5, slower inference speeds (~17–19 tokens/sec in thinking mode), weaker native multimodality (vision/audio/video reasoning), and high resource requirements for self-hosting (1.5 TB BF16 weights, minimum 8× H200/H20 GPUs).
Z.ai is positioned as an affordable alternative to frontier models for developers and companies that prioritize autonomy, low cost, and open-source, but are willing to navigate limitations in scaling and speed.
Following the release of GLM-5 (February 2026), the platform faced a massive load spike (10x traffic increase), leading to significant service constraints, public apologies, compensations, and a temporary slowdown in the model rollout. Zhipu AI shares dropped ~23% due to stability complaints and a lack of compute power (the company sought partners for inference capacity).
Official GLM-5 Blog | API Documentation
Technical and Operational Limitations
- Throttling and concurrency: During peak loads, users are restricted to 1 parallel request even on Pro/Max plans, with "Too much concurrency" errors. The GLM-5 rollout was staged (Max first, then Pro with limits, Lite delayed). This significantly impacts enterprise use-cases involving parallel agents.
- Quota consumption: GLM-5 consumes 2–3× more quota than GLM-4.7, making low-budget plans ($7–15/mo) less effective for heavy users.
- Inference speed: ~17–19 tokens/sec in thinking mode, lower than Claude Opus 4.5 / GPT-5.2 (25–30+ tokens/sec). Latency is higher in Agent mode due to iterative planning.
- Multimodality: Strong in document generation (.docx/.pdf/.xlsx), but native image/audio/video processing is weaker than GPT-5.2 (MMMU ~84%) and Gemini. GLM-Image is a separate model, and integration isn't seamless.
- Self-hosting: 744B MoE (1.5 TB BF16 weights) requires enterprise-grade clusters (min 8× H200/H20 GPUs with high-bandwidth interconnect). Even with FP8 quantization, it's only feasible for large teams.
- Other aspects: Lower situational awareness in complex ambiguous scenarios, a smaller ecosystem of ready-made integrations compared to OpenAI/Anthropic, and geopolitical/regulatory risks (Chinese company, data sovereignty).
Market Positioning 2026
Z.ai / GLM-5 targets developers, startups, and enterprises that need autonomous agents, long-horizon task execution, document generation, and low-cost API access (~$0.80–$1 / M input, $2.56–$3.2 / M output—3–10× lower than Claude Opus 4.5 / GPT-5.2 in similar scenarios). The focus is on autonomy, document deliverables, NVIDIA-independence (trained on Huawei Ascend), and the ability to self-host or fine-tune (MIT license).
The platform is less suited for tasks requiring ultra-low latency (real-time chatbots), high creativity/nuanced prompting, full multimodality, or maximum service stability under heavy load.
Examples Where Limitations are Most Noticable
- Running multiple parallel agents in production—stalling due to concurrency limits.
- Intensive Agent mode use on base plans—depleting quotas in hours.
- Self-hosting for privacy / on-premise—inaccessible without significant hardware investment.
- Video analysis + coding / multimodal reasoning—lower quality compared to GPT-5.2.
Conclusion: Z.ai / GLM-5 offers competitive capabilities in agentic engineering and coding at a lower price with open-source weights, but with noticeable trade-offs in speed, scaling, multimodality, and peak-load stability. The platform is ideal for scenarios where autonomy, budget, and data control are the priorities; for tasks requiring strict latency, creativity, or full multimodality, Claude or GPT remain the preferred choice.
❓ Frequently Asked Questions (FAQ)
How is GLM-5 better than GLM-4.7?
GLM-5 has a significantly larger scale: 744B total parameters (MoE, ~40B active) vs 355B (~32B active) in GLM-4.7. Pre-training increased from 23T to 28.5T tokens, and DeepSeek Sparse Attention (DSA) was integrated for efficient long-context. This results in a ~20% average gain on benchmarks: SWE-bench Verified 77.8% (vs 73.8%), Terminal-Bench 2.0 ~56–61% (vs ~41%), BrowseComp 75.9% (vs 67.5%), and Vending Bench 2 $4,432 (vs $2,377). Agentic engineering, long-horizon planning, and self-correction are vastly improved, with a claimed 56% reduction in hallucination rates. GLM-5 moves from "vibe coding" to true autonomous systems engineering, closing in on Claude Opus 4.5.
Is Z.ai free?
Yes, the web chat at chat.z.ai is free (with request/token quotas, Agent mode limits, and a gradual GLM-5 rollout). The API (api.z.ai) is pay-as-you-go with a free trial (limited starting quota), and free access to GLM-5 is sometimes available via OpenRouter or other aggregators with minimal limits. For full utilization (especially GLM-5), a GLM Coding Plan starting at $10/mo (Lite/Pro/Max) is required, where GLM-5 consumes quota 2–3× faster than GLM-4.7.
What is the API price for GLM-5 and how can I save?
Official 2026 pricing: $1 per million input tokens, $3.2 per million output (cached input is $0.2/M, storage is temporarily free). This is 3–10× cheaper than Claude Opus 4.5 / GPT-5.2 with near-equivalent quality in agentic/coding tasks. GLM-5-Code (code-optimized) is $1.2 input / $5 output. To save: use context caching for long sessions, use GLM-4.7 for routine tasks (cheaper), and leverage off-peak hours (lower quota multipliers in plans). GLM-5 is resource-heavy, so it depletes Coding Plan quotas 2–3× faster.
✅ Conclusions
- 🔹 In 2026, Z.ai is a leading platform for agentic AI thanks to the GLM-5 model, which performs close to Claude Opus 4.5 and GPT-5.2 in key agentic and coding benchmarks (SWE-bench Verified 77.8%, Terminal-Bench 2.0 56–61%, Vending Bench 2 $4,432).
- 🔹 Chat mode provides fast inference with low resource consumption, suitable for interactive dialogues, RAG pipelines, text/code generation, and multimodal query processing with minimal delay.
- 🔹 Agent mode implements an iterative cycle of planning, tool-calling, self-checking, and final artifact generation (.docx, .pdf, .xlsx, reports, websites), enabling complex tasks with a high degree of autonomy.
- 🔹 GLM-5 (744B MoE, 40B active, 200K context with DeepSeek Sparse Attention, 28.5T token pre-training, MIT license) shows top-tier results among open-weight models in coding, reasoning, and long-horizon planning at a significantly lower API cost than closed rivals.
- 🔹 The platform is ideal for developers, startups, and enterprise teams needing autonomous agents, token cost savings, self-hosting/fine-tuning capabilities, and independence from the NVIDIA ecosystem (training on Huawei Ascend).
Main Takeaway: In 2026, Z.ai with its GLM-5 model is a highly competitive solution for tasks requiring high autonomy, long-term planning, document generation, and low-cost inference, especially in scenarios prioritizing open-weights and infrastructure control.