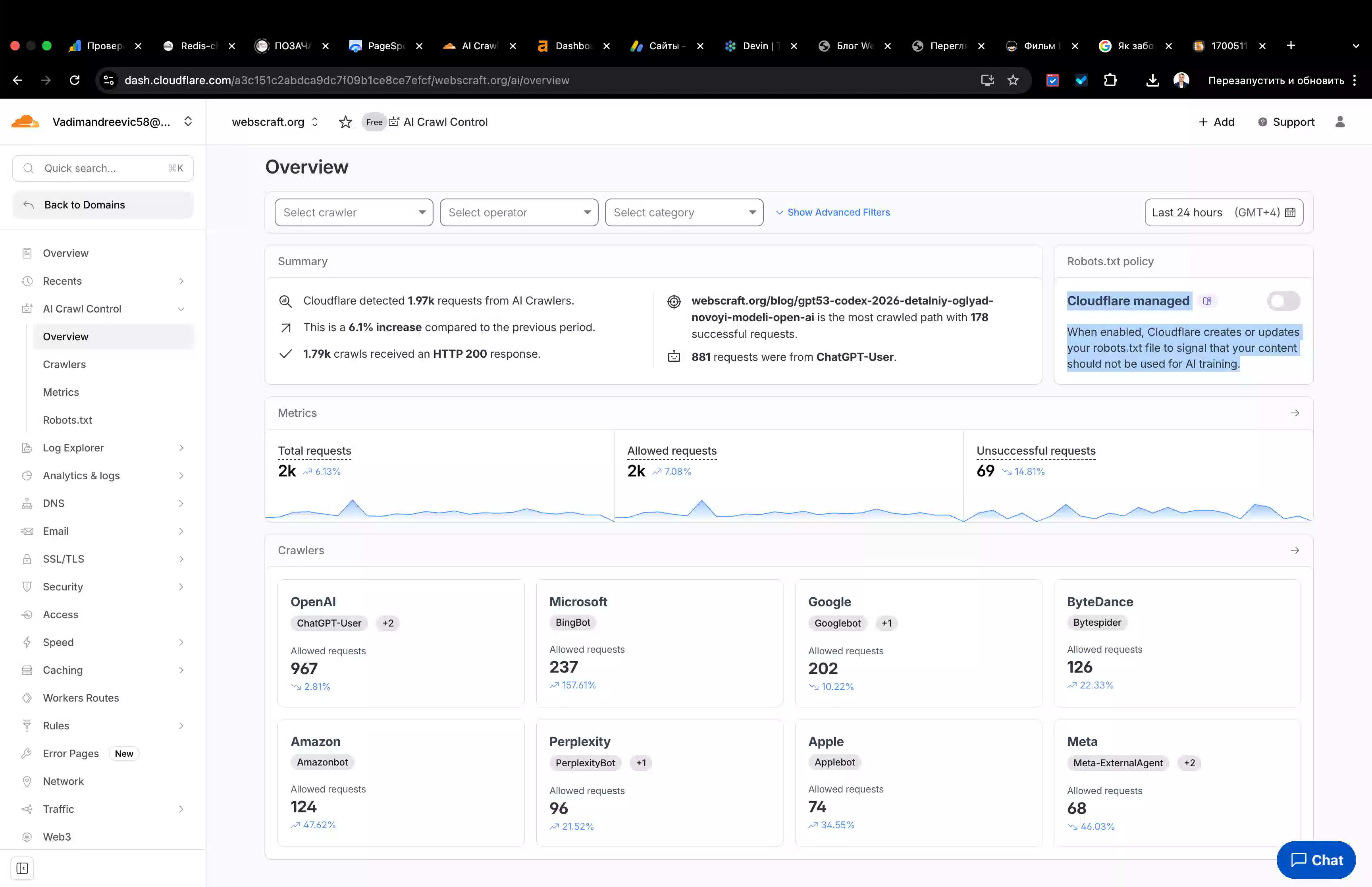
У 2025–2026 роках більшість контент-сайтів почали регулярно фіксувати в логах GPTBot, ClaudeBot, PerplexityBot та інші AI-краулери. Вони сканують сторінки для формування датасетів і навчання моделей. Часто це відбувається без прямої згоди власника сайту та без механізмів монетизації.
У другій половині 2025 року Cloudflare додав інструменти керування AI-краулерами: автоматичне блокування навчальних ботів для нових доменів, AI Crawl Control, сигнали в robots.txt і навіть експериментальну модель Pay-per-crawl. Це дозволяє власникам сайтів контролювати, чи може їхній контент використовуватись для тренування моделей.
Важливо: заборона AI-навчання через robots.txt або Cloudflare не блокує індексацію Google і не означає, що сайт зникне з відповідей ChatGPT чи інших AI-пошуків. У більшості випадків сайт зберігає видимість у пошуку і може отримувати трафік з AI-платформ, при цьому ваш контент не використовується у навчальних датасетах.
⚡ Коротко
- ✅ Головне: Блокування AI training (ai-train=no) ≠ блокування появи сайту в AI-відповідях (search=yes).
- ✅ Cloudflare 2026: автоматично блокує багато AI-ботів на нових доменах + AI Crawl Control + Pay-per-crawl.
- ✅ Вплив на SEO: нульовий — Googlebot не блокується, трафік з AI-пошуку зазвичай зберігається.
- 🎯 Ви отримаєте: повний контроль над контентом та захист від безкоштовного навчання моделей.
- 👇 Нижче — деталі, таблиці та рекомендації 2026 року
📚 Зміст статті
Проблема: ваші тексти годують AI безкоштовно
У 2025–2026 роках власники сайтів фіксували значну активність AI-ботів: GPTBot, ClaudeBot, PerplexityBot, Google-Extended, Bytespider та інші. Вони збирають контент для:
- тренування нових версій моделей ШІ;
- формування RAG-датасетів для retrieval-augmented generation;
- live-пошуку та цитування в AI-відповідях.
Детальніше про найпопулярніших AI-ботів у 2026 році читайте тут: AI-боти та краулери: хто відвідує ваш сайт.
Навчання моделей ≠ поява у відповідях AI
Важливо розуміти різницю між двома процесами:
1. Training crawl (навчання / ai-train)
Це масове збирання даних для навчання майбутніх моделей. Цей процес відбувається офлайн. Якщо ви блокуєте ai-train, ваш сайт просто не потрапляє в "підручники" для наступних версій ШІ.
2. Live retrieval / search (відповіді та пошук)
Це коли ChatGPT чи Perplexity роблять live-пошук, щоб відповісти користувачу прямо зараз. Блок ai-train тут не впливає: ваш сайт залишається видимим, його цитують, і ви отримуєте переходи.
Приклад: Я заборонив навчання через ai-train. ChatGPT не може вчитися на моїй статті для "розуму" майбутньої моделі, але коли користувач запитує конкретно про Cloudflare, ШІ знаходить мою статтю, цитує її та дає посилання на мій блог.
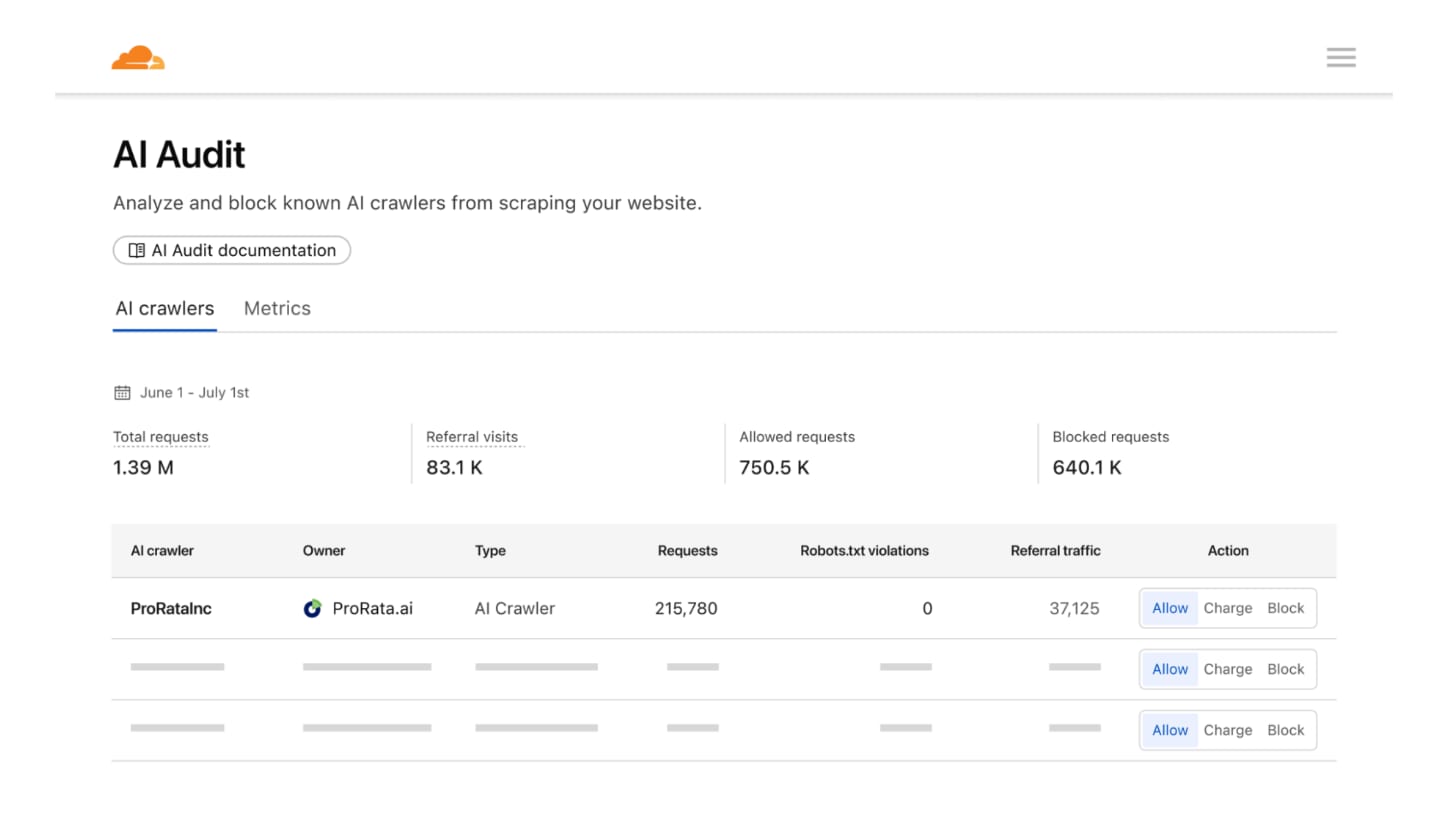
Cloudflare надав потужні інструменти для захисту видавців:
- AI Crawl Control — детальний дашборд: хто заходить, скільки разів і чи поважають вони robots.txt.
- Managed robots.txt — автоматичне додавання сигналів ContentSignals.org (ai-train: no, search: yes).
- Block AI bots — перемикач в один клік, який блокує "нахабних" ботів.
- Pay-per-crawl (beta) — можливість виставити рахунок AI-компаніям за доступ до вашого контенту.
Приклад сучасного robots.txt з Content Signals:
# Content Signals Policy
# search: yes
# ai-input: yes
# ai-train: no
User-agent: GPTBot
Disallow: /
User-agent: ClaudeBot
Disallow: /
Детальніше про налаштування robots.txt читайте тут: robots.txt: повний гайд для SEO.
Як увімкнути захист
- Зайдіть у Cloudflare Dashboard → оберіть домен.
- Перейдіть у Security → Bots → AI Crawl Control (або Control AI Crawlers).
- Увімкніть Managed robots.txt + Display Content Signals Policy (ai-train: no).
- За бажанням: у Block AI bots оберіть «Block on all pages» або гранулярно по ботах.
- Перевірте в AI Crawl Control → Robots.txt tab: чи застосовано сигнали.
- (Опціонально) Подайте заявку на Pay-per-crawl beta, якщо хочете монетизувати.
Після активації зміни видно за 5–30 хвилин.
Вплив на SEO, трафік та видимість в AI
| Питання | Вплив при блокуванні ai-train |
|---|
| Google індексація (Googlebot) | Не блокується — Googlebot працює як зазвичай |
| Поява в ChatGPT Search / Perplexity / Claude | Зазвичай зберігається — live retrieval дозволяє цитувати ваш сайт |
| AI-трафік (реферальні кліки) | Трафік зазвичай зберігається, може трохи змінюватися залежно від поведінки ботів |
| Навчання моделей (ai-train) | Заблоковано для ботів, що дотримуються сигналів у robots.txt |
| Монетизація | Можлива через Cloudflare Pay-per-crawl (бета) |
Головне: ви захищаєте контент від безкоштовного використання для навчання AI, але не втрачаєте видимість у пошуку та AI-відповідях.
Коли варто вмикати захист (і коли краще поки не чіпати)
Мій особистий чекліст: коли я вмикаю ai-train=no + гранулярне блокування в AI Crawl Control, а коли залишаю все відкритим (або навіть пробую Pay-per-crawl). Це не універсальна, але працює для 90% контенту-сайтів.
Варто вмикати (і я вже ввімкнув на більшості своїх сайтів)
- Особисті блоги, нішеві медіа, експертні сайти з унікальним авторським контентом
Якщо ти пишеш глибокі статті, кейси, дослідження чи думки, які ніхто не копіює дослівно в інших місцях — це твій основний актив. Я ввімкнув повне блокування ai-train на своєму основному блозі про SEO та AI: за 4 місяці боти OpenAI та Anthropic перестали масово сканувати (видно в AI Crawl Control), а трафік з Google та Perplexity не впав (навіть трохи виріс, бо менше «паразитного» навантаження). Контент більше не йде на дармове тренування Claude чи Gemini — і це відчувається як перемога.
- Сайти, де контент — це головна цінність і продукт
Онлайн-курси, платні гайди, глибокі аналізи ринку, наукові статті, портфоліо експертів. Приклад: один мій клієнт — сайт з курсами з data science. Після блокування ai-train боти перестали красти структуровані пояснення та приклади коду. Водночас сайт досі з’являється в Perplexity та ChatGPT Search (бо ми залишили ai-input: yes), і реферальний трафік з AI-пошуку приносить 15–20% нових учнів. Захистили цінність — не втратили видимість.
- Якщо ти хочеш спробувати монетизацію через Pay-per-crawl або пряме ліцензування
У 2026 році Pay-per-crawl уже доступний у розширеній бета-версії (можна встановити ціну від $0.001 до $0.05 за запит). Це реальний додатковий дохід для сайтів з великим трафіком — особливо медіа, новинних порталів чи аналітичних ресурсів з тисячами щоденних переглядів, де AI-боти роблять сотні тисяч запитів на місяць. Якщо твій контент якісний і унікальний (свіжі новини, глибока аналітика, експертні огляди) — деякі великі видавці вже отримують суттєвий пасивний заробіток від ботів, які обирають платити замість блокування. Без втрати SEO чи видимості в пошуку. Детальніше про це в моїй статті: Pay-per-crawl від Cloudflare: чи варто продавати контент.
Можна (і часто краще) поки не вмикати — або вмикати вибірково
- Стартапи та проєкти на ранній стадії (перші 6–18 місяців)
Коли головне — максимальна видимість будь-де: в Google, в AI-пошуку, в чатах. Я не блокував на своєму новому SaaS-лендінгу про AI-інструменти для маркетологів — навпаки, дозволив усім (навіть GPTBot).
- Маркетингові лендінги, e-commerce, промо-сайти
Тут контент — це не цінність сама по собі, а інструмент для продажу/лідів. Блокування AI-ботів може зменшити шанси на згадки в AI-рекомендаціях (наприклад, «найкращий інструмент для X»). У мене був клієнт-магазин гаджетів: після блокування трафік з AI-пошуку впав на 40%, бо боти просто перестали бачити описи товарів. Трафік важливіший за захист — тому залишили відкритим (або дозволили тільки PerplexityBot та Google-Extended).
- SaaS-документація, API-референси, технічні гайди
Розробники шукають документацію саме через AI (ChatGPT, Claude, Gemini). Якщо заблокувати — твої користувачі просто підуть до конкурентів, чиї docs досі доступні. Я залишив відкритим docs одного клієнта (дозволив ai-input: yes, але ai-train: no) — і отримав купу позитивного фідбеку: люди знаходять відповіді в AI і потім приходять на сайт за повною версією. Win-win.
Мій особистий підхід : для будь-якого сайту, де я створюю оригінальний контент >80% часу — вмикаю ai-train=no + моніторю в AI Crawl Control. Якщо бачу, що якийсь бот приносить реальний реферальний трафік (наприклад, Perplexity дає 5–10% відвідувань) — дозволяю йому окремо. А якщо контент супер-цінний і унікальний — тестую Pay-per-crawl. Це баланс між захистом, видимістю та потенційним заробітком.
Якщо сумніваєшся, я радив би почати з тесту: увімкніть блокування на одному піддомені або розділі сайту (наприклад, /blog/) і стежте за статистикою протягом 2–4 тижнів. Дані в AI Crawl Control покажуть усе чітко і допоможуть оцінити вплив на трафік та видимість.
Що буде далі: тренди 2026–2027 (на мою думку)
У найближчі 2–3 роки я очікую, що розвиток AI‑краулінгу та AI‑пошуку продовжить впливати на SEO, трафік і монетизацію контенту. Ось ключові тренди, які, на мою думку, варто враховувати:
- AI SEO: оптимізація під AI‑платформи (live retrieval), не лише Google.
- Зростання AI‑трафіку: реферальні переходи з ChatGPT, Perplexity та інших сервісів можуть стати суттєвими.
- Ліцензування контенту: легальна монетизація через ліцензії, партнерські програми та моделі типу Human Native + Cloudflare.
- Pay‑per‑crawl: очікується розширення, зручніша оплата та 402‑компенсації для неплатників.
- Content Signals 2.0: більш гранулярний контроль доступу ботів до різних типів контенту.
Ці тренди базуються на аналізі поведінки AI‑краулерів, еволюції інструментів (як Cloudflare AI Crawl Control) та змінах у пошукових платформах.
Додаткові матеріали :
❓ Часті питання (FAQ)
- Чи блокує це Google Search та Google AI Overviews?
- Ні. Googlebot та Google-Extended — різні. Блокуйте Google-Extended окремо, якщо хочете, але не чіпайте Googlebot.
- Чи зникне сайт з відповідей ChatGPT / Perplexity після блокування?
- Зазвичай ні. Вони використовують live retrieval (ai-input), а не тільки тренування. Багато сайтів залишаються видимими.
- Чи можна дозволити одним ботам і заборонити іншим?
- Так! У AI Crawl Control — гранулярні правила по кожному User-agent.
- Як заробити на ботах через Pay-per-crawl?
- З власного досвіду: я вже детально писав про це у статті
«Pay-per-crawl від Cloudflare: чи варто продавати свій контент AI-ботам».
Коротко: подайте заявку на beta, встановіть ціну за запит — Cloudflare обробляє платежі (ви отримуєте гроші, для неплатників повертає 402).
- Чи поважають боти Content Signals та managed robots.txt?
- Сумлінні (OpenAI, Anthropic, Perplexity) — так. Несумлінні — ігнорують, але Cloudflare блокує їх на рівні edge (WAF).
- Чи впливає це на швидкість сайту чи навантаження?
- Ні, навпаки — менше «паразитного» трафіку від тренувальних краулів.
✅ Висновки та рекомендація
У 2026 році блокування AI-навчання через Cloudflare більше не здається ризиком — це стає стандартною практикою для будь-якого контент-сайту. AI Crawl Control, Content Signals та Managed robots.txt дозволяють захищати контент без шкоди для SEO та видимості в AI-пошуку.
Моя рекомендація для більшості сайтів:
- Увімкніть Managed robots.txt з
ai-train: no; - Залиште
search: yes та ai-input: yes для збереження видимості; - Моніторте активність у AI Crawl Control протягом кількох тижнів;
- Якщо контент унікальний і цінний — розгляньте Pay-per-crawl для потенційної монетизації.
Таким чином ви отримуєте контроль над використанням контенту, захист від безкоштовного навчання моделей і потенційний дохід, при цьому зберігаючи трафік з Google та AI-платформ.
Я раджу почати прямо зараз: увімкніть AI Crawl Control у Cloudflare і оцініть ефект на своєму сайті. Ваш контент вартий захисту!
Кому цікаво — рекомендую почитати також
З мого досвіду, ці матеріали добре доповнюють тему AI‑ботів та показують практичні кейси впливу ШІ на контент і трафік.