Im Jahr 2026 revolutioniert künstliche Intelligenz weiterhin die Softwareentwicklung, doch ist das neue OpenAI-Modell bereit, die Spielregeln zu ändern? GPT-5.3-Codex, veröffentlicht am 5. Februar 2026, verspricht nicht nur Code zu schreiben, sondern komplexe Aufgaben als vollwertiger Entwicklerkollege zu erledigen.
Spoiler: Das Modell ist 25 % schneller als die Vorgängerversion, stellt neue Rekorde in Benchmarks auf und hat sogar bei seiner eigenen Entwicklung geholfen, birgt jedoch erhöhte Risiken für die Cybersicherheit.
⚡ Kurz gesagt
- ✅ Kernpunkt 1: GPT-5.3-Codex kombiniert Codierung mit den Denkfähigkeiten von GPT-5.2 und ermöglicht die Ausführung langfristiger Aufgaben mit Recherche und Tools.
- ✅ Kernpunkt 2: Das Modell erreicht 77,3 % auf Terminal-Bench 2.0 und 57 % auf SWE-Bench Pro und übertrifft damit die Konkurrenz.
- ✅ Kernpunkt 3: Verfügbar für zahlende ChatGPT-Nutzer, mit Fokus auf Sicherheit und IDE-Integration.
- 🎯 Sie erhalten: Praktische Tipps zur Nutzung des Modells bei der Arbeit und ein Verständnis seines Einflusses auf den Entwicklungsmarkt 2026.
- 👇 Unten – detaillierte Erklärungen, Beispiele und Tabellen
📚 Inhaltsverzeichnis
Lesen Sie mehr über alle Aspekte des Themas in meinen Artikeln:
🎯 Abschnitt 1. Was ist GPT-5.3-Codex und welche Schlüsselmerkmale hat es?
Kurze Antwort:
GPT-5.3-Codex ist ein aktualisiertes OpenAI-Modell, das am 5. Februar 2026 veröffentlicht wurde und verbesserte Codierungsfähigkeiten mit erweitertem Verständnis und Fachwissen kombiniert. Es arbeitet 25 % schneller als GPT-5.2-Codex dank Infrastruktur-Optimierung und reduzierten Token-Kosten und unterstützt auch langwierige Aufgaben mit Echtzeit-Interaktion ohne Kontextverlust. Meiner Meinung nach ist dies einer der praktischsten Schritte von OpenAI für die tägliche Arbeit von Entwicklern im Jahr 2026.
Wer es installieren möchte (nur Mac) – folgen Sie dem Link.
GPT-5.3-Codex erweitert die Fähigkeiten von Codex von der Codegenerierung und -überprüfung bis zur Ausführung komplexer professioneller Aufgaben am Computer.
Das Modell ist das Ergebnis der Kombination der fortschrittlichen Codierungsfähigkeiten von GPT-5.2-Codex mit verbessertem Reasoning und dem Fachwissen von GPT-5.2. Laut offiziellen Angaben von OpenAI (offizielle Ankündigung vom 5. Februar 2026) ist es in der Lage, an Aufgaben zu arbeiten, die mehrere Tage dauern, einschließlich Recherche, Werkzeugnutzung und komplexer Ausführung. Dies passt gut zu den aktuellen Trends, bei denen KI-Agenten zu einem Teil des Standard-Toolkits in IT-Teams werden.
Warum das für Entwickler wichtig ist
In der modernen Entwicklung bleiben Geschwindigkeit, Genauigkeit und Kontrolle entscheidend. GPT-5.3-Codex verkürzt die Zeit für Routineoperationen erheblich – Debugging, Refactoring, Terminalarbeit, Generierung von Boilerplate-Code – und ermöglicht es, sich stärker auf Architektur, Geschäftslogik und Teamkoordination zu konzentrieren. Nach meinen Beobachtungen und dem Feedback von Kollegen aus Enterprise-Teams führen solche Verbesserungen zu einer Produktivitätssteigerung um das 3- bis 5-fache in einzelnen Phasen komplexer Projekte (z. B. Refactoring von Modulen, Schreiben von Tests, Debugging von Produktionsproblemen). Bei Pet-Projekten oder in frühen Phasen (MVP, Greenfield) kann der Effekt noch deutlicher sein, aber in Legacy-Systemen mit strenger Compliance und großen Repositories fungiert das Modell als leistungsstarker Assistent und nicht als vollständiger Ersatz für menschliche Überwachung.
Beispiel aus meiner Praxis: Eine Webanwendung von Grund auf mit GPT-5.3-Codex
In meinem Projekt habe ich dem Modell die Aufgabe übertragen, eine Webanwendung von Grund auf zu erstellen – von der Projektstruktur und der grundlegenden Architektur bis zum Interface-Design und Deployment. GPT-5.3-Codex kann die meisten Schritte eigenständig durchführen, Zwischenberichte liefern und in Echtzeit (Mid-Task Steering) ohne Kontextverlust korrigiert werden. Dies ist besonders nützlich in frühen Iterationen oder für schnelles Prototyping, wo das Modell Absichten gut versteht und die Anzahl manueller Korrekturen reduziert.
- ✔️ Reduzierung von Iterationen dank besserem Verständnis von unterdefinierten Prompts und sinnvollen Standardeinstellungen.
- ✔️ Integration mit GitHub, VS Code, JetBrains und anderen Tools über die Codex-App und Erweiterungen, was die tägliche Arbeit erleichtert.
Fazit des Abschnitts: Meiner Meinung nach ist GPT-5.3-Codex eine stabile und messbare Verbesserung für die professionelle Entwicklung, die in realen Projekten im Jahr 2026 getestet werden sollte, insbesondere in Phasen, in denen schnelle Iteration und Routineautomatisierung erforderlich sind.
📌 Abschnitt 2. Wesentliche Verbesserungen bei Leistung und Geschwindigkeit
GPT-5.3-Codex beschleunigt die Anfrageverarbeitung im Vergleich zu GPT-5.2-Codex um etwa 25 % dank Infrastruktur- und Inferenz-Stack-Optimierung. Dies reduziert Verzögerungen bei interaktiver Arbeit und ermöglicht eine effizientere Ausführung von Aufgaben, die viele Iterationen erfordern. In der Praxis macht dies das Modell zu einem bequemeren Werkzeug für die tägliche Entwicklung, obwohl es es nicht zu einem vollständig autonomen Architekten oder Senior-Entwickler macht.
Die Geschwindigkeit der Antworten ist einer der Schlüsselfaktoren, der bestimmt, wie komfortabel es ist, KI als Assistenten in realen Projekten einzusetzen.
Laut der offiziellen Ankündigung von OpenAI vom 5. Februar 2026 (Introducing GPT-5.3-Codex) wurde die Beschleunigung durch Infrastrukturverbesserungen und Optimierung der Berechnungen erreicht. Das Modell verbraucht weniger Tokens für typische Aufgaben, was die Gesamtkosten der Nutzung (sobald die API verfügbar ist) senkt und die Wartezeit bei jedem Interaktionsschritt reduziert.
Die wichtigsten praktischen Effekte dieser Verbesserung:
- ✔️ Schnellere Antworten im interaktiven Modus – besonders spürbar beim Mid-Task Steering, wenn schnell Änderungen am Aufgabenablauf vorgenommen werden müssen.
- ✔️ Bessere Eignung für mittelfristige Aufgaben – zum Beispiel Refactoring eines Moduls, Schreiben von Tests, Log-Analyse oder automatisiertes Erstellen von Pull Requests, wo frühere Versionen Verzögerungen ansammeln konnten.
- ✔️ Reduzierung des Ressourcenverbrauchs – eine geringere Anzahl von Tokens pro Aufgabe macht das Modell bei hoher Auslastung zu einer wirtschaftlicheren Wahl, was für Teams mit vielen Anfragen relevant ist.
Warum das für Entwickler wichtig ist
Im Arbeitsalltag verwandelt sich selbst eine kleine Verzögerung bei jeder Iteration schnell in verlorene Minuten oder Stunden über den Tag verteilt. Eine Beschleunigung um 25 % macht die Interaktion mit dem Modell flüssiger und weniger frustrierend – das ist bereits ein spürbarer Unterschied, wenn man ständig zwischen Code, Reviews und Prompts wechselt. In meiner Praxis mit früheren Codex-Versionen zwangen mich gerade die angesammelten Verzögerungen oft dazu, zu manuellen Routineaufgaben zurückzukehren. Jetzt eignet sich das Modell besser für parallele Arbeit: Während es Optionen generiert oder Logs analysiert, kann der Entwickler sich mit Architektur, Systemdesign oder Teamkoordination beschäftigen.
Gleichzeitig ist es wichtig, die Grenzen zu verstehen: Selbst mit verbesserter Geschwindigkeit verfügt das Modell nicht über den vollständigen Kontext eines großen Enterprise-Repositorys, historische Teamentscheidungen, Geschäftskonstrukte oder Nuancen von Legacy-Systemen. Es bleibt ein leistungsstarkes Werkzeug zur Beschleunigung einzelner Phasen, aber kein Ersatz für einen Architekten oder Senior-Entwickler.
Fazit des Abschnitts: Aus meiner Erfahrung ist die 25%ige Beschleunigung eine reale und messbare Verbesserung, die GPT-5.3-Codex zu einem bequemeren und effektiveren Werkzeug für die professionelle Entwicklung im Jahr 2026 macht, insbesondere in Phasen, in denen schnelle Iteration und Automatisierung von Routineoperationen erforderlich sind.
📌 Abschnitt 3. Agentenfähigkeiten und Interaktion
GPT-5.3-Codex erweitert die Funktionalität von der klassischen Codegenerierung bis zur sequenziellen Ausführung mehrstufiger Aufgaben: Recherche, Werkzeugnutzung, Befehlsausführung und Verarbeitung langwieriger Prozesse. Ein Schlüsselmerkmal ist das Mid-Task Steering (Anpassung während der Ausführung) ohne Kontextverlust und die Ausgabe von Zwischenberichten über den Fortschritt. Dies macht das Modell zu einem praktischen Werkzeug zur Automatisierung operativer Phasen, ersetzt jedoch nicht das vollständige Projektverständnis oder die architektonische Entscheidungsfindung.
Agentenfähigkeiten ermöglichen es, dem Modell einen Teil der Routine- und sich wiederholenden Arbeit zu delegieren, während der Entwickler die Kontrolle über Kontext, Sicherheit und Schlüsselentscheidungen behält.
Laut der offiziellen Ankündigung von OpenAI vom 5. Februar 2026 (Introducing GPT-5.3-Codex) hat das Modell einen wesentlich verbesserten Mechanismus zur Planung und Ausführung von Long-Horizon-Aufgaben erhalten. Es kann komplexe Aufgaben in Schritte zerlegen, diese sequenziell ausführen, mit externen Tools (Terminal, Browser, Dateisystem in der Sandbox, API usw.) interagieren und regelmäßig über den Status berichten. Mid-Task Steering ermöglicht es, jederzeit Präzisierungen vorzunehmen, die Richtung zu ändern oder den Prozess zu stoppen, ohne die gesamte Aufgabe neu starten zu müssen.
Die wichtigsten praktischen Aspekte dieser Fähigkeiten:
- ✔️ Schrittweise Ausführung mit regelmäßigen Berichten – das Modell liefert Updates nach jedem wichtigen Schritt, was die Überwachung und das rechtzeitige Eingreifen erleichtert.
- ✔️ Unterstützung von Tools – Arbeit mit dem Terminal, lokalen Dateien (in einer kontrollierten Umgebung), Websuche, IDE-Integrationen und Cloud-Diensten (abhängig von den Zugriffseinstellungen).
- ✔️ Kontextspeicherung über einen längeren Zeitraum – das Modell merkt sich frühere Aktionen, Korrekturen und Entscheidungen auch nach Pausen von mehreren Stunden oder Tagen.
Gleichzeitig ist es wichtig, die Grenzen klar zu verstehen: Agentenfähigkeiten funktionieren am besten bei gut beschriebenen, isolierten oder relativ einfachen Aufgaben. In großen Enterprise-Projekten mit Legacy-Code, komplexen Abhängigkeiten, Teamkonventionen, Compliance-Anforderungen oder impliziten Geschäftsregeln kann das Modell den gesamten Kontext nicht vollständig berücksichtigen – hier ist ständige menschliche Überwachung und Anpassung erforderlich.
Fazit: Agentenfähigkeiten und interaktive Interaktion machen GPT-5.3-Codex zu einem effektiven Werkzeug zur Automatisierung operativer und wiederkehrender Entwicklungsphasen, aber sein tatsächlicher Wert hängt von der richtigen Aufgabenverteilung und der Kontrolle durch den Entwickler ab.
📌 Abschnitt 4. Selbstverbesserung des Modells
Die Nutzung des Modells in seiner eigenen Entwicklung ist ein Beispiel dafür, wie KI einzelne Phasen der Ingenieurarbeit beschleunigen kann, während die Schlüsselentscheidungen beim Expertenteam verbleiben.
Laut der offiziellen Ankündigung von OpenAI vom 5. Februar 2026 (Introducing GPT-5.3-Codex) nutzte das Codex-Team frühe Versionen des Modells, um seine eigene Entwicklung zu beschleunigen. Das Modell half bei der Optimierung von Trainingsprozessen, dem Deployment-Management und der Analyse von Testergebnissen. Das OpenAI-Team bemerkte, dass es "beeindruckt" war, wie sehr dies die Arbeit beschleunigte.
Konkrete Anwendungsbeispiele:
- ✔️ Trainings-Debugging: Verfolgung von Mustern, Analyse der Interaktionsqualität und Vorschläge für Korrekturen bei Trainingsläufen.
- ✔️ Deployment-Management: Erkennung von Fehlern beim Kontext-Rendering, Analyse der Ursachen für niedrige Cache-Hit-Raten, dynamische Skalierung von GPU-Clustern für Spitzenlasten und Sicherstellung der Latenzstabilität.
- ✔️ Testdiagnose: Erstellung von Regex-Klassifikatoren zur Bewertung von Leistungsmetriken aus Sitzungsprotokollen, Aufbau von Datenpipelines, Visualisierung von Ergebnissen und Zusammenfassung von Erkenntnissen aus Tausenden von Datenpunkten in weniger als drei Minuten.
In meiner Praxis als Entwickler mit Erfahrung in KI-Projekten beschleunigen solche Tools tatsächlich Routinephasen – zum Beispiel Datenanalyse oder Infrastruktur-Debugging – ersetzen aber nicht die menschliche Erfahrung bei architektonischen Entscheidungen, strategischer Planung oder der Arbeit mit unstrukturierten Problemen. Hier fungiert das Modell als effektiver Assistent, der klare Anweisungen und eine Überprüfung der Ergebnisse erfordert.
Fazit des Abschnitts: Nach meiner Erfahrung hilft die Selbstverbesserung in GPT-5.3-Codex tatsächlich, Entwicklungsprozesse zu optimieren. Ihre Effektivität steigt jedoch erheblich nur dann, wenn das Modell in die Arbeit eines Expertenteams integriert wird und wir die Ergebnisse in Echtzeit anpassen können. Es ist wichtig zu beachten, dass dies kein Allheilmittel ist und Menschen noch nicht vollständig ersetzen kann.
📌 Abschnitt 5. Integrationen und Skill-System
GPT-5.3-Codex integriert sich mit der Codex-App (derzeit macOS, Windows ist geplant), CLI, IDE-Erweiterungen (VS Code, JetBrains) und anderen Oberflächen. Das Skill-System erweitert die Möglichkeiten über die Codierung hinaus – von der Implementierung von Designs in Figma bis zur Projektverwaltung in Linear und dem Deployment in Cloudflare, Vercel, Netlify usw. Multi-Agent-Parallel-Workflows, geplante Automatisierungen und die Personalisierung des Interaktionsstils (/personality) werden unterstützt. Dies macht das Modell zu einem flexiblen Werkzeug, dessen Effektivität jedoch von den Zugriffseinstellungen und der menschlichen Kontrolle abhängt.
Integrationen und Fähigkeiten ermöglichen es, das Modell an spezifische Tools und Teamprozesse anzupassen, wodurch es als Hilfswerkzeug und nicht als universeller Entwicklerersatz erhalten bleibt.
Laut der offiziellen Ankündigung der Codex-App von OpenAI (Februar 2026) (Introducing the Codex app) ist das Modell über mehrere Oberflächen verfügbar:
- ✔️ Codex-App – eine Desktop-Anwendung für macOS (Windows ist geplant), die als „Kommandozentrale“ für die parallele Verwaltung mehrerer Agenten, isolierter Worktrees (zur Vermeidung von Codekonflikten) und die Synchronisierung von Sitzungen mit CLI und IDE dient.
- ✔️ CLI- und IDE-Erweiterungen – Unterstützung für VS Code, JetBrains und andere, mit der Möglichkeit, Fähigkeiten und Automatisierungen in jeder Umgebung zu nutzen.
- ✔️ Andere Oberflächen – Webversion, mit weiterer Integration in Slack und andere Tools (über Fähigkeiten oder API, sobald verfügbar).
Das zentrale Element ist das Skill-System (agentskills.io), das ein offener Standard ist und es ermöglicht, Anweisungen, Ressourcen und Skripte für spezifische Aufgaben zu bündeln. Skills sind in der App, CLI und IDE verfügbar, können vom Team erstellt/verwaltet und über Repositories geteilt werden.
Offizielle Skill-Beispiele aus der OpenAI-Bibliothek:
- ✔️ Figma implement-design – extrahiert Kontext, Assets und Screenshots aus Figma und wandelt sie in produktionsreifen UI-Code mit 1:1 visueller Übereinstimmung um.
- ✔️ Linear – Projektmanagement: Bug-Triage, Release-Tracking, Team-Lastverteilung usw.
- ✔️ Cloud deploy – Bereitstellung von Webanwendungen auf Cloudflare, Netlify, Render, Vercel.
- ✔️ imagegen – Generierung und Bearbeitung von Bildern (basierend auf GPT Image) für UI, Spiele, Dokumentation.
- ✔️ develop-web-game – autonome Entwicklung von Webspielen (Beispiel: Erstellung des 3D-Spiels Voxel Velocity mit über 7 Millionen Tokens, bei dem das Modell als Designer, Entwickler und QA fungierte).
- ✔️ Spreadsheet / PDF / Docx – Erstellung und Bearbeitung von Dokumenten, Tabellen mit professioneller Formatierung.
Zusätzlich unterstützt:
- ✔️ Multi-Agenten-Parallelbetrieb – mehrere Agenten arbeiten gleichzeitig in isolierten Branches, mit der Möglichkeit, zwischen ihnen zu wechseln und Änderungen zu überprüfen.
- ✔️ Automatisierungen – geplante Hintergrundaufgaben (z. B. tägliche Issue-Triage, Zusammenfassung von CI-Fehlern, Generierung von Release-Berichten), mit Ergebnissen in der Überprüfungswarteschlange.
- ✔️ Personalisierung – der Befehl /personality zur Auswahl des Stils: terse/pragmatic (kurz, auf Ausführung ausgerichtet) oder conversational/empathetic (kommunikativer).
Wichtig: Skills und Integrationen erfordern explizite Berechtigungen (Sandboxing, Zugriffsregeln), und das Modell hat ohne Konfiguration keinen vollständigen autonomen Zugriff auf Unternehmenssysteme. Dies begrenzt die Risiken, erinnert aber auch daran, dass die Effektivität von der richtigen Konfiguration und menschlicher Überwachung abhängt.
💼 Abschnitt 6. Technische Details und Benchmarks
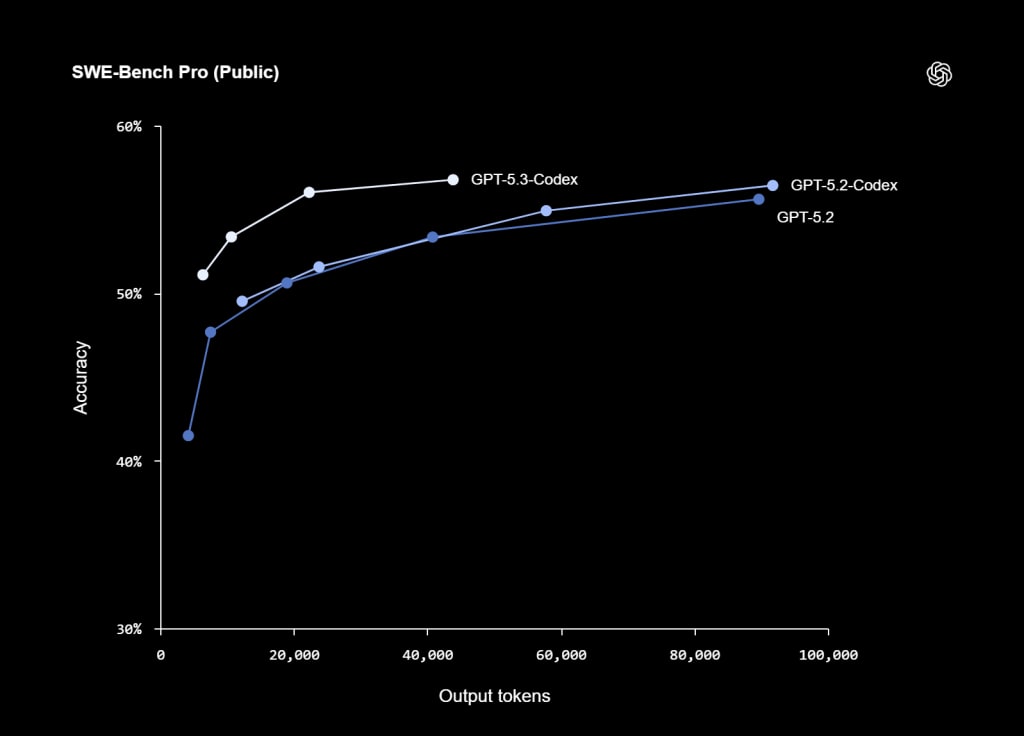
GPT-5.3-Codex kombiniert spezialisiertes Fine-Tuning für die Codierung mit verbessertem Reasoning und Fachwissen von GPT-5.2. Das Kontextfenster beträgt 400.000 Tokens (laut OpenAI API-Dokumentation), mit einer maximalen Ausgabe von bis zu 128.000 Tokens. Das Modell zeigt hohe Ergebnisse bei Schlüssel-Benchmarks: 56,8 % auf SWE-Bench Pro, 77,3 % auf Terminal-Bench 2.0, 64,7 % auf OSWorld-Verified und 70,9 % (wins or ties) auf GDPval. Diese Indikatoren spiegeln seine Stärken im Agenten-Coding und bei realen Aufgaben wider, mit geringerem Token-Verbrauch im Vergleich zu früheren Versionen.
Benchmarks sind standardisierte Tests, die es ermöglichen, Modelle unter kontrollierten Bedingungen zu vergleichen, aber die tatsächliche Effizienz hängt vom spezifischen Projekt und den Einstellungen ab.
Laut offiziellen Angaben von OpenAI aus der Ankündigung vom 5. Februar 2026 (Introducing GPT-5.3-Codex) ist das Modell eine Kombination aus den fortschrittlichen Codierungsfähigkeiten von GPT-5.2-Codex und verbessertem Reasoning von GPT-5.2. Es ist für Agentenaufgaben optimiert, einschließlich der instrumentellen Nutzung, Planung und Ausführung langfristiger Prozesse. Das Kontextfenster beträgt 400.000 Tokens, was die Verarbeitung erheblicher Mengen an Code, Logs oder Dokumentation in einer einzigen Anfrage ermöglicht (gemäß OpenAI API-Dokumentation für GPT-5-Codex).
Wichtige Benchmarks, bei denen das Modell bewertet wurde (Daten aus dem offiziellen OpenAI-Blog):
| Benchmark | GPT-5.3-Codex | GPT-5.2-Codex | Andere Modelle (z.B. Claude Opus 4.6) | Kommentar |
|---|
| SWE-Bench Pro (Public) | 56.8% | 56.4% | N/A | Reale GitHub-Aufgaben aus 4 Sprachen, Fokus auf Kontaminationsresistenz |
| Terminal-Bench 2.0 | 77.3% | 64.0% | 65.4% | Terminal-Fähigkeiten für Agenten |
| OSWorld-Verified | 64.7% | 38.2% | N/A | Reale Desktop-Aufgaben (Menschen ~72%) |
| GDPval (wins or ties) | 70.9% | 70.9% | N/A | Fachwissen in 44 Berufen |
Diese Ergebnisse zeigen einen deutlichen Fortschritt bei Terminal- und Agentenaufgaben (z. B. +13,3 % auf Terminal-Bench 2.0), sowie eine stabile Leistung in professionellen Workflows. Das Modell verwendet oft weniger Tokens, was es in langfristigen Sitzungen effizienter macht. Gleichzeitig sind Benchmarks synthetische oder kontrollierte Tests; in realen Enterprise-Projekten mit Legacy-Code, benutzerdefinierten Tools oder strengen Sicherheitsanforderungen kann die Effizienz variieren und erfordert zusätzliche Überprüfung.
Meiner Meinung nach: Die technischen Spezifikationen und Benchmark-Ergebnisse bestätigen, dass GPT-5.3-Codex ein leistungsstarkes Werkzeug für Agenten-Coding und professionelle Aufgaben ist, aber seine Anwendung in realen Projekten erfordert die Berücksichtigung spezifischer Einschränkungen und menschlicher Überwachung.
💼 Abschnitt 7. Praktische Anwendungen und Nutzerfeedback
GPT-5.3-Codex wird für Refactoring, Debugging, Testautomatisierung, Prototyping und die Erstellung einzelner Module eingesetzt. Ein offizielles Beispiel ist die autonome Entwicklung des 3D-Spiels Voxel Velocity (über 7 Millionen Tokens). Das Nutzerfeedback ist gemischt: Viele heben die Stärken bei der Planung und Ausführung mittlerer Aufgaben hervor, aber es gibt Beschwerden über die Dauer der Generierung, die Notwendigkeit wiederholter Präzisierungen und die durchschnittliche Qualität bei komplexen Iterationen. Meiner Meinung nach bietet das Modell eine spürbare Beschleunigung in den Prototyping- und Routinephasen, aber in realen Projekten ist das Ergebnis oft mittelmäßig und erfordert erhebliches menschliches Eingreifen.
Der wahre Wert des Modells zeigt sich in spezifischen Szenarien, in denen die Aufgaben gut beschrieben sind und kein tiefes Verständnis von Legacy-Kontext oder Teamnuancen erfordern.
Laut der offiziellen Ankündigung der Codex-App von OpenAI (Februar 2026) (Introducing the Codex app) ist eines der Demonstrationsbeispiele die Erstellung des vollständigen 3D-Spiels Voxel Velocity. Das Modell durchlief eigenständig den Weg von der Idee bis zum Endprodukt: Design, Code, Animationen, Tests, Bearbeitung und Optimierung, wobei über 7 Millionen Tokens generiert wurden. Dies ist ein gutes Beispiel dafür, wozu das Modell in einem gut abgegrenzten Greenfield-Szenario fähig ist.
Ergebnisse meiner Praxis mit GPT-5.3-Codex
Ich habe das Modell in den ersten Tagen nach der Veröffentlichung an mehreren Aufgaben getestet, und das Ergebnis sah wie folgt aus:
- ✔️ Bei einfachen Aufgaben (Refactoring eines kleinen Moduls, Generierung von Tests, Boilerplate für APIs) – schnell und mit minimalen Korrekturen, spürbare Beschleunigung.
- ✔️ Bei Aufgaben mittlerer Komplexität (Erstellung eines Features mit mehreren Abhängigkeiten) – das Modell plante die Schritte gut und schlug Optionen vor, lieferte aber oft Code, der 2–4 Iterationen von Präzisierungen erforderte. Ich musste die Prompts mehrmals umschreiben, da die ersten Versionen nicht ganz das waren, was benötigt wurde (z. B. berücksichtigten sie nicht die Spezifik des Codestils oder Edge-Cases).
- ✔️ Bei langwierigen Prozessen – arbeitete es lange (manchmal 5–15 Minuten pro Phase), was zum Warten zwang. Es wäre wesentlich bequemer, wenn es bei jedem Schritt Präzisierungen vorschlagen oder eine Bestätigung anfordern würde, anstatt alles sofort zu generieren.
Ich habe die Bewertungen in den Communities (Reddit, HN, Discord OpenAI) durchgesehen, und sie sind ebenfalls recht gemischt. Einige Nutzer schreiben, dass das Modell „Opus 4.6 in der Planungstiefe übertrifft“, aber viele bemerken:
- Lange Verzögerungen bei der Generierung (insbesondere im Vergleich zu schnelleren Konkurrenten).
- Die Notwendigkeit wiederholter Prompt-Präzisierungen – oft entsteht ein „durchschnittliches“ Ergebnis, das erheblich nachbearbeitet werden muss.
- Gute Leistung bei Prototypen und Pet-Projekten, aber geringere Effizienz in Legacy-Systemen oder Enterprise-Umgebungen mit strengen Standards.
Insgesamt hilft das Modell tatsächlich, einzelne Phasen zu beschleunigen (insbesondere die Generierung von Entwürfen, Debugging, Schreiben von Tests), liefert aber ohne aktive Beteiligung des Entwicklers keine konstant hohe Qualität. Es ist ein Werkzeug, das gut als Assistent funktioniert, aber nicht als autonomer Senior oder Architekt.
Fazit: Aus meiner Erfahrung und praktischen Tests ist GPT-5.3-Codex ein nützliches Werkzeug zur Beschleunigung von Routine- und Prototyping-Aufgaben. In realen Projekten ist das Ergebnis jedoch oft mittelmäßig und erfordert erhebliche Nachbearbeitung und menschliche Kontrolle.
💼 Abschnitt 8. Einschränkungen, Risiken und Zukunftsaussichten
Hauptbeschränkungen: Zugang nur für kostenpflichtige ChatGPT-Pläne (Pro/Business), derzeit nur macOS-App (Windows ist geplant), Halluzinationen und Ungenauigkeiten in komplexen oder schlecht beschriebenen Szenarien sowie Abhängigkeit von der Qualität der Prompts und menschlicher Überwachung. Risiken: Erhöhtes Potenzial für Cybersicherheit (das Modell hat ein "high" Rating im Preparedness Framework), daher sind Sandboxing, explizite Berechtigungen und Zugriffsbeschränkungen erforderlich. Zukunft: Erweiterung auf Windows, neue Fähigkeiten, Cloud-Automatisierungen und tiefere Integration mit Enterprise-Tools. In der Praxis bedeutet dies, dass das Modell ein leistungsstarkes, aber kein universelles Werkzeug ist, das vorsichtigen Einsatz erfordert.
Jedes Tool dieser Ebene muss ein Gleichgewicht zwischen Möglichkeiten und Risiken finden – insbesondere wenn es um autonome Arbeit mit Code, Daten oder Infrastruktur geht.
Laut der offiziellen Ankündigung von OpenAI vom 5. Februar 2026 (Introducing GPT-5.3-Codex) ist das Modell ausschließlich für zahlende Nutzer von ChatGPT Pro, Business und Enterprise verfügbar. Kostenlose Nutzer arbeiten weiterhin mit früheren Versionen. Die Codex-App funktioniert derzeit nur auf macOS (eine Windows-Version ist für die kommenden Monate geplant).
Technische und praktische Einschränkungen, die ich während des Tests bemerkt und in den Bewertungen gesehen habe:
- ✔️ Halluzinationen und Ungenauigkeiten – insbesondere bei Aufgaben mit großem Kontext, Legacy-Code oder impliziten Anforderungen. Das Modell benötigt oft 2–4 Iterationen von Präzisierungen, damit das Ergebnis akzeptabel wird.
- ✔️ Verarbeitungsdauer – bei langwierigen Aufgaben (z. B. Erstellung eines vollständigen Moduls oder Analyse eines großen Logs) kann die Generierung 5–15 Minuten pro Phase dauern, was zum Warten zwingt und den Arbeitsfluss unterbricht.
- ✔️ Kontextfenster – 400.000 Tokens sind für viele Aufgaben ausreichend, aber nicht für die vollständige Analyse großer Enterprise-Repositories mit Commit-Historie und Dokumentation.
- ✔️ Zugang und Kosten – die API ist noch nicht öffentlich zugänglich, daher erfolgen alle Operationen über die kostenpflichtige ChatGPT-Oberfläche oder die Codex-App mit entsprechenden Limits.
Die mit der Cybersicherheit verbundenen Risiken werden von OpenAI offiziell anerkannt: Das Modell erhielt im Preparedness Framework ein "high" Rating, gerade wegen seines Potenzials für den Einsatz bei Angriffen (z. B. Generierung von Exploits oder Unterstützung bei der Erstellung von bösartigem Code). Daher wurden folgende Maßnahmen implementiert:
- ✔️ Sandboxing und explizite Berechtigungen für den Zugriff auf Dateien, Terminal, Netzwerk.
- ✔️ Einschränkungen bei der Ausführung bestimmter Befehle ohne Bestätigung.
- ✔️ Pilotprogramm Trusted Access for Cyber – 10 Millionen US-Dollar an Zuschüssen für Open-Source-Sicherheitsprojekte.
Zukunftsaussichten (gemäß Ankündigungen und Roadmap von OpenAI):
- ✔️ Windows-Version der Codex-App (in Kürze erwartet).
- ✔️ Erweiterung des Skill-Systems (neue Skills für Enterprise-Tools wie Jira, Confluence, AWS/GCP).
- ✔️ Cloud-Trigger und Automatisierungen (geplante Hintergrundaufgaben mit Ergebnissen in der Überprüfungswarteschlange).
- ✔️ Schrittweise Öffnung der API für GPT-5.3-Codex (mit entsprechenden Einschränkungen und Preisen).
Insgesamt sehen die Aussichten logisch und konsistent aus, jedoch ohne radikale Änderungen in den kommenden Monaten. Das Modell entwickelt sich als Werkzeug zur Produktivitätssteigerung und nicht als autonomer Ersatz für einen Entwickler oder Architekten.
Fazit: Die Einschränkungen und Risiken von GPT-5.3-Codex sind klar definiert, und OpenAI arbeitet aktiv an deren Minimierung. Die Entwicklungsperspektiven sind vielversprechend, aber der tatsächliche Wert des Modells hängt von der richtigen Nutzung in Kombination mit menschlicher Kontrolle und Erfahrung ab.
❓ Häufig gestellte Fragen (FAQ)
Wann wurde GPT-5.3-Codex veröffentlicht?
Das Modell wurde offiziell am 5. Februar 2026 in einer OpenAI-Ankündigung vorgestellt. Seit diesem Tag ist es für Nutzer kostenpflichtiger ChatGPT-Pläne (Pro, Business, Enterprise) verfügbar. Kostenlose Nutzer arbeiten weiterhin mit früheren Codex-Versionen.
Wie erhalte ich Zugang zum Modell?
Derzeit ist der Zugang über kostenpflichtige ChatGPT-Pläne (ab Plus), die Desktop-Anwendung Codex-App (derzeit nur macOS, Windows ist geplant), Erweiterungen für IDEs (VS Code, JetBrains) und CLI möglich. Die API für GPT-5.3-Codex ist noch nicht öffentlich zugänglich, aber OpenAI plant die Veröffentlichung in den kommenden Monaten. Für die Teamnutzung wird ein Business- oder Enterprise-Plan empfohlen, der zusätzliche Optionen für Zugriffssteuerung und Sandboxing bietet.
Wird GPT-5.3-Codex Entwickler ersetzen?
Nein, das Modell ersetzt keine Entwickler. Es automatisiert effektiv Routineoperationen (Generierung von Boilerplate-Code, Refactoring kleiner Module, Schreiben von Tests, Log-Analyse, Erstellung von PR-Entwürfen), verfügt aber nicht über den vollständigen Projektkontext, versteht keine impliziten Geschäftsanforderungen, Legacy-Entscheidungen, Teamstandards oder Compliance-Nuancen. In realen Enterprise-Projekten erfordert das Ergebnis oft mehrere Iterationen von Präzisierungen, Überprüfungen und erheblicher Nachbearbeitung. Am besten funktioniert es als leistungsstarker Assistent, der einzelne Phasen beschleunigt, aber Schlüsselentscheidungen, Architektur und die finale Überprüfung bleiben beim Menschen.
Welche Hauptbeschränkungen hat das Modell in der Praxis?
Die auffälligsten sind: Zugang nur für kostenpflichtige Pläne, lange Verzögerungen bei komplexen oder langwierigen Aufgaben, die Notwendigkeit wiederholter Prompt-Präzisierungen (oft 2–4 Iterationen), Halluzinationen und Ungenauigkeiten bei Aufgaben mit großem oder unstrukturiertem Kontext, Einschränkungen des Kontextfensters (400.000 Tokens – ausreichend für viele Aufgaben, aber nicht für die vollständige Analyse großer Legacy-Repositories). Das Modell erfordert auch explizite Berechtigungen für den Zugriff auf Tools und Dateien, was eine zusätzliche Ebene von Sicherheitseinstellungen hinzufügt.
Ist das Modell sicher für den Einsatz in Unternehmen?
OpenAI hat GPT-5.3-Codex im Preparedness Framework als "high" eingestuft, gerade wegen seines Potenzials im Bereich Cybersicherheit (Möglichkeit, Exploits zu generieren, bei der Erstellung von bösartigem Code zu helfen usw.). Daher wurden Sandboxing, explizite Berechtigungen für den Zugriff auf Terminal/Dateien/Netzwerk und Einschränkungen bei der Ausführung bestimmter Befehle ohne Bestätigung implementiert. Für Unternehmen wird empfohlen, Business-/Enterprise-Pläne mit zusätzlichen Kontrollen zu verwenden, alle Änderungen zu überprüfen und dem Modell keinen direkten Zugriff auf Produktionssysteme zu gewähren. Bei korrekter Konfiguration können die Risiken erheblich reduziert werden, aber eine vollständige Risikofreiheit ist nicht möglich.
Lohnt sich der Umstieg auf GPT-5.3-Codex im Jahr 2026?
Wenn Ihr Team aktiv KI zur Beschleunigung von Routineaufgaben (Codegenerierung, Debugging, Tests, Prototyping) einsetzt – ja, es lohnt sich, es zu testen. Das Modell bietet eine spürbare Beschleunigung in einzelnen Phasen (insbesondere in Greenfield- und Pet-Projekten), verfügt über gute Integrationen und ein Skill-System. Für Legacy-Systeme, komplexe Enterprise-Projekte mit strengen Standards und großem Kontext wird der Übergang jedoch nicht revolutionär sein – das Ergebnis ist oft mittelmäßig und erfordert erhebliche Nachbearbeitung. Beginnen Sie mit einer Testphase auf einem kostenpflichtigen Plan, bewerten Sie den ROI bei Ihren realen Aufgaben und skalieren Sie erst dann.
✅ Fazit
- 🔹 GPT-5.3-Codex zeigt im Vergleich zu früheren Versionen einen deutlichen Fortschritt in Geschwindigkeit (25 % Beschleunigung) und Agentenfähigkeiten, was es zu einem bequemeren Werkzeug für die tägliche Arbeit macht.
- 🔹 Die Benchmark-Ergebnisse (SWE-Bench Pro 56,8 %, Terminal-Bench 77,3 %, OSWorld 64,7 %) bestätigen die Stärken des Modells im Coding und bei realen Agentenaufgaben, obwohl synthetische Tests nicht immer das vollständige Bild von Enterprise-Projekten widerspiegeln.
- 🔹 Integrationen, das Skill-System und der Fokus auf Sicherheit ermöglichen es, das Modell an reale Arbeitsabläufe anzupassen, aber seine Effektivität hängt von der klaren Aufgabenverteilung, der Qualität der Prompts und der ständigen menschlichen Überwachung ab.
- 🔹 Das Modell ist ein leistungsstarker Assistent, der einzelne Entwicklungsphasen (Prototyping, Refactoring, Debugging, Routineautomatisierung) beschleunigt, ersetzt aber keinen erfahrenen Entwickler oder Architekten, insbesondere nicht in komplexen Legacy-Systemen oder Projekten mit hohen Sicherheits- und Compliance-Anforderungen.
Hauptgedanke:
GPT-5.3-Codex ist eine stabile und messbare Verbesserung des Entwickler-Toolkits im Jahr 2026, die in realen Aufgaben getestet werden sollte, um zu verstehen, wo genau sie Ihrem Team den größten Nutzen bringt.