In 2026, artificial intelligence continues to revolutionize the field of software development, but is OpenAI's new model ready to change the game? GPT-5.3-Codex, released on February 5, 2026, promises not just to write code, but to perform complex tasks as a full-fledged developer colleague.
Spoiler: The model is 25% faster than the previous version, sets new records in benchmarks, and even assisted in its own creation, but with increased cybersecurity risks.
⚡ Summary
- ✅ Key takeaway 1: GPT-5.3-Codex combines coding with the reasoning capabilities of GPT-5.2, allowing it to perform long-term tasks involving research and tools.
- ✅ Key takeaway 2: The model achieves 77.3% on Terminal-Bench 2.0 and 57% on SWE-Bench Pro, surpassing competitors.
- ✅ Key takeaway 3: Available to paid ChatGPT users, with a focus on security and IDE integration.
- 🎯 You will get: Practical advice on using the model in your work and understanding its impact on the 2026 development market.
- 👇 Below — detailed explanations, examples, and tables
📚 Table of Contents
Read more about all aspects of the topic in my articles:
🎯 Section 1. What is GPT-5.3-Codex and its Key Characteristics
Brief Answer:
GPT-5.3-Codex is an updated OpenAI model, released on February 5, 2026, that combines enhanced coding capabilities with expanded understanding and professional knowledge. It operates 25% faster than GPT-5.2-Codex due to infrastructure optimization and reduced token consumption, and also supports long-duration tasks with real-time interaction without losing context. In my opinion, this is one of OpenAI's most practical steps for developers' daily work in 2026.
For those who want to install (Mac only) — follow the link.
GPT-5.3-Codex extends Codex's capabilities from code generation and review to performing complex professional tasks on a computer.
The model is the result of combining the frontier coding capabilities of GPT-5.2-Codex with the improved reasoning and professional knowledge of GPT-5.2. According to official OpenAI data (official announcement from February 5, 2026), it is capable of working on tasks lasting several days, including research, tool usage, and complex execution. This fits well with current trends where AI agents are becoming part of the standard toolkit in IT teams.
Why this is important for developers
In modern development, speed, accuracy, and control remain key. GPT-5.3-Codex significantly reduces time spent on routine operations — debugging, refactoring, terminal work, boilerplate code generation — allowing more focus on architecture, business logic, and team coordination. Based on my observations and feedback from colleagues in enterprise teams, such improvements yield a 3–5x productivity increase at specific stages of complex projects (e.g., module refactoring, test writing, debugging production issues). In pet projects or early stages (MVP, greenfield), the effect can be even more noticeable, but in legacy systems with strict compliance and large repositories, the model acts as a powerful assistant, not a complete replacement for human oversight.
Example from my practice: a web application from scratch using GPT-5.3-Codex
In my project, I tasked the model with creating a web application from scratch — from project structure and basic architecture to interface design and deployment. GPT-5.3-Codex can independently go through most stages, provide interim reports, and be corrected in real-time (mid-task steering) without losing context. This is especially useful in early iterations or for rapid prototyping, where the model understands intentions well and reduces the number of manual edits.
- ✔️ Reduced iterations due to better understanding of underspecified prompts and sensible defaults.
- ✔️ Integration with GitHub, VS Code, JetBrains, and other tools via the Codex app and extensions, facilitating daily work.
Section Conclusion: In my opinion, GPT-5.3-Codex is a stable and measurable improvement for professional development that is worth testing in real-world projects in 2026, especially at stages requiring rapid iteration and routine automation.
📌 Section 2. Key Performance and Speed Improvements
GPT-5.3-Codex provides approximately 25% faster request processing compared to GPT-5.2-Codex, thanks to infrastructure and inference stack optimization. This reduces latency in interactive work and allows for more efficient execution of tasks requiring many iterations. In practice, this makes the model a more convenient tool for daily development, although it does not transform it into a fully autonomous architect or senior developer.
Response speed is one of the key factors determining how comfortable it is to use AI as an assistant in real-world projects.
According to OpenAI's official announcement from February 5, 2026 (Introducing GPT-5.3-Codex), the acceleration was achieved by improving infrastructure and optimizing computations. The model consumes fewer tokens for typical tasks, which reduces the overall cost of use (when the API becomes available) and decreases waiting time at each interaction step.
Main practical effects of this improvement:
- ✔️ Faster responses in interactive mode — especially noticeable with mid-task steering, when quick adjustments are needed during task execution.
- ✔️ Better suitability for medium-duration tasks — for example, module refactoring, test writing, log analysis, or automated pull request creation, where previous versions might have accumulated delays.
- ✔️ Reduced resource costs — fewer tokens per task make the model a more economical choice under high load, which is relevant for teams with a large number of requests.
Why this is important for developers
In real work, even a small delay at each iteration quickly turns into lost minutes or hours throughout the day. A 25% acceleration makes interaction with the model smoother and less frustrating — this is already a noticeable difference when you constantly switch between code, reviews, and prompts. In my practice with previous Codex versions, accumulated delays often forced me to revert to manual execution of routine parts. Now, the model is better suited for parallel work: while it generates options or analyzes logs, the developer can focus on architecture, system design, or team coordination.
At the same time, it's important to understand the limitations: even with improved speed, the model does not possess the full context of a large enterprise repository, historical team decisions, business constraints, or the nuances of legacy systems. It remains a powerful tool for accelerating individual stages, but not a replacement for an architect or senior developer.
Section Conclusion: From my experience, a 25% acceleration is a real and measurable improvement that makes GPT-5.3-Codex a more convenient and effective tool for professional development in 2026, especially at stages requiring rapid iteration and automation of routine operations.
📌 Section 3. Agent Capabilities and Interaction
GPT-5.3-Codex extends its functionality from classic code generation to the sequential execution of multi-stage tasks: research, tool utilization, command execution, and handling long-running processes. A key feature is mid-task steering (adjustment during execution) without losing context, and the provision of interim progress reports. This makes the model a convenient tool for automating operational stages, but it does not replace a full understanding of the project or the making of architectural decisions.
Agent capabilities allow delegating a portion of routine and repetitive work to the model, while retaining developer control over context, security, and key decisions.
According to OpenAI's official announcement on February 5, 2026 (Introducing GPT-5.3-Codex), the model received a significantly improved mechanism for planning and executing long-horizon tasks. It can break down complex tasks into steps, execute them sequentially, interact with external tools (terminal, browser, sandboxed file system, API, etc.), and regularly report on its status. Mid-task steering allows for clarifications, changes in direction, or stopping a process at any moment without restarting the entire task.
Key practical aspects of these capabilities:
- ✔️ Gradual execution with regular reports — the model provides updates after each significant step, facilitating monitoring and timely intervention.
- ✔️ Tool support — working with the terminal, local files (in a controlled environment), web search, integrations with IDEs, and cloud services (depending on access settings).
- ✔️ Long-term context retention — the model remembers previous actions, edits, and decisions even after pauses of several hours or days.
At the same time, it is important to clearly understand the limitations: agent capabilities work best on well-described, isolated, or relatively simple tasks. In large enterprise projects with legacy code, complex dependencies, team conventions, compliance requirements, or implicit business rules, the model cannot fully account for the entire context — constant human oversight and adjustments are required here.
Conclusion: Agent capabilities and interactive interaction make GPT-5.3-Codex an effective tool for automating operational and repetitive development stages, but its real value depends on proper task delegation and control by the developer.
📌 Section 4. Model Self-Improvement
Using the model in its own development is an example of how AI can accelerate individual stages of engineering work, leaving key decisions to a team of specialists.
According to OpenAI's official announcement on February 5, 2026 (Introducing GPT-5.3-Codex), the Codex team used early versions of the model to accelerate its own development. The model assisted in debugging training processes, managing deployments, and analyzing testing results. The OpenAI team noted that they were "amazed" by how much this accelerated their work.
Specific application examples:
- ✔️ Training debugging: tracking patterns, analyzing interaction quality, and suggesting fixes for training runs.
- ✔️ Deployment management: identifying errors in context rendering, analyzing reasons for low cache hit rates, dynamically scaling GPU clusters for peak loads, and ensuring latency stability.
- ✔️ Test diagnostics: creating regex classifiers to evaluate performance metrics from session logs, building data pipelines, visualizing results, and summarizing insights from thousands of data points in less than three minutes.
In my practice as a developer with experience in AI projects, such tools indeed accelerate routine stages — for example, data analysis or infrastructure debugging — but they do not replace human experience in making architectural decisions, strategic planning, or working with unstructured problems. Here, the model acts as an effective assistant that requires clear instructions and verification of results.
Section Conclusion: In my experience, self-improvement in GPT-5.3-Codex genuinely helps optimize development processes. However, its effectiveness significantly increases only when the model is integrated into the work of a team of specialists and we can adjust the results in real time. It is worth remembering that it is not a panacea and cannot fully replace humans yet.
📌 Section 5. Integrations and Skill System
GPT-5.3-Codex integrates with the Codex app (currently macOS, Windows planned), CLI, IDE extensions (VS Code, JetBrains), and other interfaces. The skill system extends capabilities beyond coding — from implementing designs in Figma to managing projects in Linear and deploying to Cloudflare, Vercel, Netlify, etc. Multi-agent parallel workflows, scheduled automations, and interaction style personalization (/personality) are supported. This makes the model a flexible tool, but its effectiveness depends on access settings and human control.
Integrations and skills allow the model to be adapted to specific team tools and processes, maintaining it as an auxiliary tool rather than a universal developer replacement.
According to OpenAI's official announcement of the Codex app (February 2026) (Introducing the Codex app), the model is available through several interfaces:
- ✔️ Codex app — a desktop application for macOS (Windows in plans), acting as a "command center" for managing multiple agents in parallel, isolated worktrees (to avoid code conflicts), and synchronizing sessions with CLI and IDE.
- ✔️ CLI and IDE extensions — support for VS Code, JetBrains, and others, with the ability to use skills and automations in any environment.
- ✔️ Other interfaces — a web version, with further integration into Slack and other tools (via skills or API, when available).
The central element is the skill system, which is an open standard (agentskills.io) and allows packaging instructions, resources, and scripts for specific tasks. Skills are available in the app, CLI, and IDE, can be created/managed by the team, and shared via repositories.
Official examples of skills from the OpenAI library:
- ✔️ Figma implement-design — extracts context, assets, and screenshots from Figma and converts them into production-ready UI code with 1:1 visual fidelity.
- ✔️ Linear — project management: bug triage, release tracking, team workload distribution, etc.
- ✔️ Cloud deploy — deploying web applications to Cloudflare, Netlify, Render, Vercel.
- ✔️ imagegen — generating and editing images (based on GPT Image) for UI, games, documentation.
- ✔️ develop-web-game — autonomous web game development (example: creating the 3D game Voxel Velocity with over 7 million tokens, where the model acted as designer, developer, and QA).
- ✔️ Spreadsheet / PDF / Docx — creating and editing documents, spreadsheets with professional formatting.
Additionally supported:
- ✔️ Multi-agent parallel work — several agents work simultaneously in isolated branches, with the ability to switch and review changes.
- ✔️ Automations — scheduled background tasks (e.g., daily issue triage, CI failure summaries, release report generation), with results queued for review.
- ✔️ Personalization — the /personality command for choosing a style: terse/pragmatic (brief, execution-oriented) or conversational/empathetic (more communicative).
Important: skills and integrations require explicit permissions (sandboxing, access rules), and the model does not have full autonomous access to corporate systems without configuration. This limits risks but also reminds us that effectiveness depends on proper configuration and human oversight.
💼 Section 6. Technical Details and Benchmarks
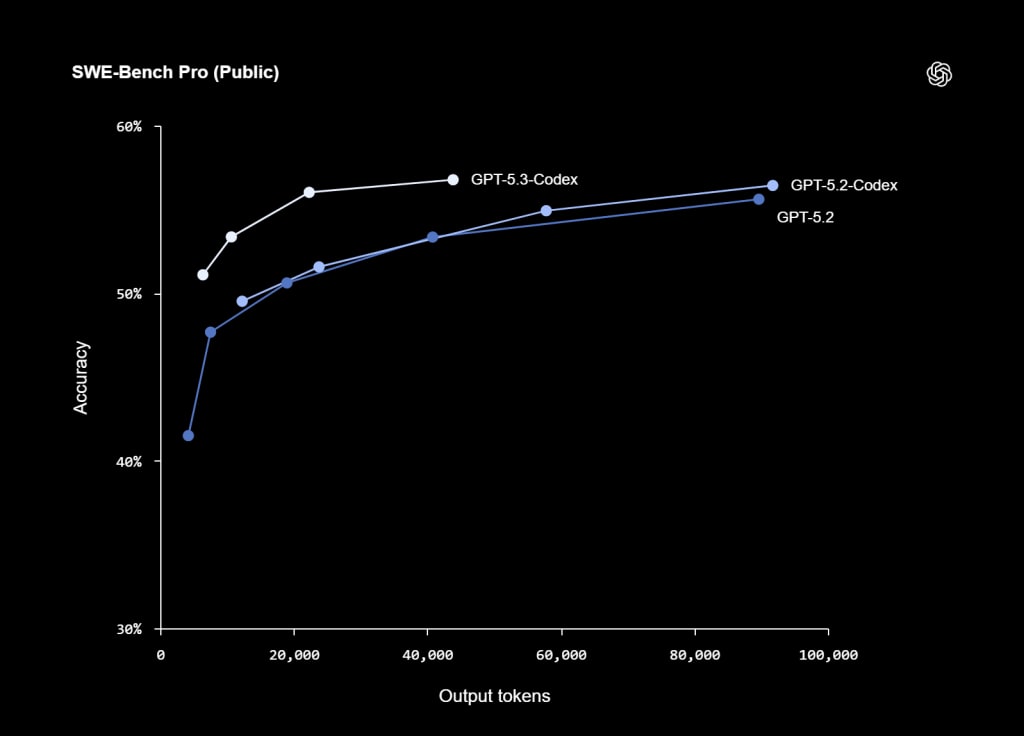
GPT-5.3-Codex combines specialized fine-tuning for coding with improved reasoning and professional knowledge from GPT-5.2. The context window is 400,000 tokens (according to OpenAI API docs), with a maximum output of up to 128,000 tokens. The model demonstrates high results on key benchmarks: 56.8% on SWE-Bench Pro, 77.3% on Terminal-Bench 2.0, 64.7% on OSWorld-Verified, and 70.9% (wins or ties) on GDPval. These indicators reflect its strengths in agentic coding and real-world tasks, with lower token consumption compared to previous versions.
Benchmarks are standardized tests that allow comparing models under controlled conditions, but real-world effectiveness depends on the specific project and settings.
According to official OpenAI data from the announcement on February 5, 2026 (Introducing GPT-5.3-Codex), the model is a combination of the frontier coding capabilities of GPT-5.2-Codex and the improved reasoning of GPT-5.2. It is optimized for agentic tasks, including tool use, planning, and executing long-running processes. The context window is 400,000 tokens, allowing it to process significant volumes of code, logs, or documentation in a single request (according to OpenAI API docs for GPT-5-Codex).
Main benchmarks on which the model was evaluated (data from the official OpenAI blog):
| Benchmark | GPT-5.3-Codex | GPT-5.2-Codex | Other models (e.g., Claude Opus 4.6) | Comment |
|---|
| SWE-Bench Pro (Public) | 56.8% | 56.4% | N/A | Real GitHub tasks from 4 languages, focus on contamination robustness |
| Terminal-Bench 2.0 | 77.3% | 64.0% | 65.4% | Terminal skills for agents |
| OSWorld-Verified | 64.7% | 38.2% | N/A | Real desktop tasks (humans ~72%) |
| GDPval (wins or ties) | 70.9% | 70.9% | N/A | Professional knowledge in 44 occupations |
These results show noticeable progress in terminal and agentic tasks (e.g., +13.3% on Terminal-Bench 2.0), as well as stable performance in professional workflows. The model often uses fewer tokens, making it more efficient in long-running sessions. At the same time, benchmarks are synthetic or controlled tests; in real-world enterprise projects with legacy code, custom tools, or strict security requirements, effectiveness may vary and requires additional verification.
In my opinion: the technical specifications and benchmark results confirm that GPT-5.3-Codex is a powerful tool for agentic coding and professional tasks, but its application in real projects requires consideration of specific limitations and human oversight.
💼 Section 7. Practical Applications and User Feedback
GPT-5.3-Codex is used for refactoring, debugging, test automation, prototyping, and creating individual modules. An official example is the autonomous development of the 3D game Voxel Velocity (over 7 million tokens). User feedback is mixed: many note its strengths in planning and executing medium-complexity tasks, but there are complaints about generation time, the need for repeated clarifications, and average quality on complex iterations. In my view, the model provides a noticeable acceleration in prototyping and routine stages, but in real projects, the result is often average and requires significant human intervention.
The real value of the model manifests in specific scenarios where tasks are well-described and do not require a deep understanding of legacy context or team nuances.
According to OpenAI's official announcement of the Codex app (February 2026) (Introducing the Codex app), one of the demonstration cases was the creation of a full-fledged 3D game, Voxel Velocity. The model independently went from idea to final product: design, code, animations, tests, editing, and optimization, generating over 7 million tokens. This is a good example of what the model is capable of in a well-constrained, greenfield scenario.
Results of my practice with GPT-5.3-Codex
I tested the model on several tasks in the first days after its release, and the results were as follows:
- ✔️ For simple tasks (refactoring a small module, generating tests, boilerplate for an API) — fast and with minimal edits, a noticeable acceleration.
- ✔️ For medium-complexity tasks (creating a feature with several dependencies) — the model planned steps well and offered options, but often produced code that required 2–4 iterations of clarification. I had to rewrite prompts several times because the initial versions weren't quite what was needed (e.g., they didn't account for specific code style or edge cases).
- ✔️ For long-running processes — it worked slowly (sometimes 5–15 minutes per stage), which forced me to wait. It would be much more convenient if it offered clarifications or asked for confirmation at each step, rather than generating everything at once.
I reviewed feedback in communities (Reddit, HN, Discord OpenAI), and it's also quite mixed. Some users write that the model "surpasses Opus 4.6 in planning depth," but many note:
- Long generation delays (especially compared to faster competitors).
- The need for repeated prompt clarifications — often resulting in an "average" outcome that requires significant refinement.
- Good performance on prototypes and pet projects, but less effectiveness in legacy systems or enterprise environments with strict standards.
Overall, the model indeed helps accelerate certain stages (especially drafting, debugging, writing tests), but it does not consistently deliver high quality without active developer involvement. It is a tool that works well as an assistant, but not as an autonomous senior or architect.
Conclusion: From my experience and practical tests, GPT-5.3-Codex is a useful tool for accelerating routine and prototyping tasks. However, in real projects, the result is often average and requires significant refinement and human oversight.
💼 Section 8. Limitations, Risks, and Future Prospects
Key limitations: access only for paid ChatGPT plans (Pro/Business), currently macOS-only app (Windows in plans), hallucinations and inaccuracies in complex or poorly described scenarios, and dependence on prompt quality and human oversight. Risks: increased cybersecurity potential (the model has a "high" rating in the Preparedness Framework), thus requiring sandboxing, explicit permissions, and access restrictions. Future: expansion to Windows, new skills, cloud automations, and deeper integration with enterprise tools. In practice, this means the model is a powerful but not universal tool that requires careful use.
Any tool of this level must balance capabilities and risks — especially when it comes to autonomous work with code, data, or infrastructure.
According to OpenAI's official announcement on February 5, 2026 (Introducing GPT-5.3-Codex), the model is exclusively available to paid ChatGPT Pro, Business, and Enterprise users. Free users continue to work with previous versions. The Codex app currently only runs on macOS (a Windows version is planned for the coming months).
Technical and practical limitations I noticed during testing and saw in reviews:
- ✔️ Hallucinations and inaccuracies — especially in tasks with large context, legacy code, or implicit requirements. The model often requires 2–4 iterations of refinements for the result to become acceptable.
- ✔️ Processing duration — for long-term tasks (e.g., creating a complete module or analyzing a large log), generation can take 5–15 minutes per stage, which forces waiting and slows down work pace.
- ✔️ Context window — 400,000 tokens are sufficient for many tasks, but not for a complete analysis of large enterprise repositories with commit history and documentation.
- ✔️ Access and cost — the API is not yet open, so all operations go through the paid ChatGPT interface or Codex app with corresponding limits.
Cybersecurity risks are officially acknowledged by OpenAI: the model received a "high" rating in the Preparedness Framework precisely due to its potential for use in attacks (e.g., exploit generation or assistance in creating malicious code). Therefore, the following have been implemented:
- ✔️ Sandboxing and explicit permissions for file, terminal, and network access.
- ✔️ Restrictions on executing certain commands without confirmation.
- ✔️ Trusted Access for Cyber pilot program — $10 million in grants for open-source security projects.
Future Prospects (according to OpenAI announcements and roadmap):
- ✔️ Windows version of the Codex app (expected soon).
- ✔️ Expansion of the skill system (new skills for enterprise tools like Jira, Confluence, AWS/GCP).
- ✔️ Cloud triggers and automations (planned background tasks with results queued for review).
- ✔️ Gradual opening of the API for GPT-5.3-Codex (with corresponding limitations and pricing).
Overall, the prospects appear logical and consistent, but without radical changes in the coming months. The model is evolving as a productivity tool, not as an autonomous replacement for a developer or architect.
Conclusion: The limitations and risks of GPT-5.3-Codex are clearly defined, and OpenAI is actively working to minimize them. Development prospects are promising, but the model's true value depends on correct usage combined with human oversight and experience.
❓ Frequently Asked Questions (FAQ)
When was GPT-5.3-Codex released?
The model was officially introduced on February 5, 2026, in an OpenAI announcement. From that day, it became available to users of paid ChatGPT plans (Pro, Business, Enterprise). Free users continue to work with previous Codex versions.
How to get access to the model?
Currently, access is possible through paid ChatGPT plans (Plus and above), the Codex desktop app (macOS only for now, Windows in plans), IDE extensions (VS Code, JetBrains), and CLI. The API for GPT-5.3-Codex is not yet publicly open, but OpenAI plans its launch in the coming months. For team use, a Business or Enterprise plan is recommended, which offers additional access control and sandboxing options.
Will GPT-5.3-Codex replace developers?
No, the model does not replace developers. It effectively automates routine operations (boilerplate code generation, refactoring small modules, writing tests, log analysis, drafting PRs), but it does not possess the full project context, nor does it understand implicit business requirements, legacy solutions, team standards, or compliance nuances. In real enterprise projects, the result often requires several iterations of refinements, verification, and significant rework. It works best as a powerful assistant that accelerates individual stages, but key decisions, architecture, and final review remain with humans.
What are the main practical limitations of the model?
The most notable: access only for paid plans, long delays on complex or long-term tasks, the need for repeated prompt refinements (often 2–4 iterations), hallucinations and inaccuracies in tasks with large or unstructured context, context window limitations (400,000 tokens — sufficient for many tasks, but not for a full analysis of large legacy repositories). The model also requires explicit permissions for tool and file access, adding a layer of security settings.
Is the model safe for enterprise use?
OpenAI classified GPT-5.3-Codex as "high" in the Preparedness Framework precisely due to its cybersecurity potential (ability to generate exploits, assist in creating malicious code, etc.). Therefore, sandboxing, explicit permissions for terminal/file/network access, and restrictions on executing certain commands without confirmation have been implemented. For enterprise use, Business/Enterprise plans with additional controls are recommended, along with reviewing all changes and not giving the model direct access to production systems. With proper configuration, risks can be significantly reduced, but a complete absence of risks is not possible.
Is it worth switching to GPT-5.3-Codex in 2026?
If your team actively uses AI to accelerate routine tasks (code generation, debugging, tests, prototyping) — yes, it's worth testing. The model provides a noticeable acceleration in certain stages (especially in greenfield and pet projects), has good integrations and a skill system. However, for legacy systems, complex enterprise projects with strict standards and large context, the transition will not be revolutionary — the result is often mediocre and requires significant refinement. Start with a trial period on a paid plan, evaluate the ROI on your real tasks, and only then scale.
✅ Conclusions
- 🔹 GPT-5.3-Codex demonstrates notable progress in speed (25% acceleration) and agent capabilities compared to previous versions, making it a more convenient tool for daily work.
- 🔹 Benchmark results (SWE-Bench Pro 56.8%, Terminal-Bench 77.3%, OSWorld 64.7%) confirm the model's strengths in coding and real-world agent tasks, although synthetic tests do not always reflect the full picture of enterprise projects.
- 🔹 Integrations, the skill system, and a focus on security allow the model to be adapted to real workflows, but its effectiveness depends on clear task delegation, prompt quality, and continuous human oversight.
- 🔹 The model is a powerful assistant that accelerates individual development stages (prototyping, refactoring, debugging, routine automation), but it does not replace an experienced developer or architect, especially in complex legacy systems or projects with high security and compliance requirements.
Main takeaway:
GPT-5.3-Codex is a stable and measurable improvement to the developer toolkit in 2026, which is worth testing in real-world tasks to understand where exactly it provides the most benefit to your team.