
En 2026, la inteligencia artificial continúa revolucionando el campo del desarrollo de software, pero ¿está el nuevo modelo de OpenAI listo para cambiar las reglas del juego? GPT-5.3-Codex, lanzado el 5 de febrero de 2026, promete no solo escribir código, sino también realizar tareas complejas como un colega desarrollador de pleno derecho.
Spoiler: El modelo es un 25% más rápido que la versión anterior, establece nuevos récords en los benchmarks e incluso ayudó en su propia creación, pero con mayores riesgos en ciberseguridad.
⚡ En resumen
- ✅ Idea clave 1: GPT-5.3-Codex combina la codificación con las capacidades de razonamiento de GPT-5.2, permitiendo realizar tareas de larga duración con investigación y herramientas.
- ✅ Idea clave 2: El modelo alcanza un 77.3% en Terminal-Bench 2.0 y un 57% en SWE-Bench Pro, superando a sus competidores.
- ✅ Idea clave 3: Disponible para usuarios de pago de ChatGPT, con un enfoque en la seguridad y la integración en IDEs.
- 🎯 Obtendrá: Consejos prácticos sobre cómo usar el modelo en el trabajo y comprender su impacto en el mercado de desarrollo de 2026.
- 👇 A continuación — explicaciones detalladas, ejemplos y tablas
📚 Contenido del artículo
Lea más sobre todos los aspectos del tema en mis artículos:
🎯 Sección 1. Qué es GPT-5.3-Codex y cuáles son sus características clave
Respuesta breve:
GPT-5.3-Codex es un modelo actualizado de OpenAI, lanzado el 5 de febrero de 2026, que combina capacidades de codificación mejoradas con una comprensión ampliada y conocimientos profesionales. Funciona un 25% más rápido que GPT-5.2-Codex gracias a la optimización de la infraestructura y la reducción del consumo de tokens, y también soporta tareas de larga duración con interacción en tiempo real sin pérdida de contexto. En mi opinión, este es uno de los pasos más prácticos de OpenAI para el trabajo diario de los desarrolladores en 2026.
Quienes deseen instalarlo (solo Mac) — sigan este enlace.
GPT-5.3-Codex amplía las capacidades de Codex desde la generación y revisión de código hasta la ejecución de tareas profesionales complejas en el ordenador.
El modelo es el resultado de la combinación de las capacidades de codificación de vanguardia de GPT-5.2-Codex con el razonamiento mejorado y los conocimientos profesionales de GPT-5.2. Según los datos oficiales de OpenAI (anuncio oficial del 5 de febrero de 2026), es capaz de trabajar en tareas que duran varios días, incluyendo investigación, uso de herramientas y ejecución compleja. Esto encaja bien con las tendencias actuales, donde los agentes de IA se están convirtiendo en parte del conjunto de herramientas estándar en los equipos de TI.
Por qué esto es importante para los desarrolladores
En el desarrollo moderno, la velocidad, la precisión y el control siguen siendo clave. GPT-5.3-Codex reduce significativamente el tiempo dedicado a operaciones rutinarias — depuración, refactorización, trabajo con la terminal, generación de código boilerplate — permitiendo centrarse más en la arquitectura, la lógica de negocio y la coordinación del equipo. Según mis observaciones y los comentarios de colegas de equipos empresariales, estas mejoras aumentan la productividad entre 3 y 5 veces en etapas específicas de proyectos complejos (por ejemplo, refactorización de módulos, escritura de pruebas, depuración de problemas de producción). En proyectos personales o en etapas tempranas (MVP, greenfield), el efecto puede ser aún más notable, pero en sistemas heredados con cumplimiento estricto y grandes repositorios, el modelo actúa como un potente asistente, no como un reemplazo completo de la supervisión humana.
Ejemplo de mi práctica: aplicación web desde cero con GPT-5.3-Codex
En mi proyecto, encargué al modelo la creación de una aplicación web desde cero — desde la estructura del proyecto y la arquitectura básica hasta el diseño de la interfaz y el despliegue. GPT-5.3-Codex puede completar de forma autónoma la mayoría de las etapas, proporcionar informes intermedios y ajustarse en tiempo real (mid-task steering) sin perder el contexto. Esto es especialmente útil en las primeras iteraciones o para el prototipado rápido, donde el modelo comprende bien las intenciones y reduce la cantidad de ediciones manuales.
- ✔️ Reducción de iteraciones gracias a una mejor comprensión de los prompts poco especificados y los valores predeterminados sensatos.
- ✔️ Integración con GitHub, VS Code, JetBrains y otras herramientas a través de la aplicación Codex y extensiones, lo que facilita el trabajo diario.
Conclusión de la sección: En mi opinión, GPT-5.3-Codex es una mejora estable y medible para el desarrollo profesional, que vale la pena probar en proyectos reales de 2026, especialmente en etapas donde se requiere una iteración rápida y la automatización de la rutina.
📌 Sección 2. Mejoras clave en rendimiento y velocidad
GPT-5.3-Codex acelera el procesamiento de solicitudes aproximadamente un 25% en comparación con GPT-5.2-Codex gracias a la optimización de la infraestructura y la pila de inferencia. Esto reduce los retrasos en el trabajo interactivo y permite realizar tareas que requieren muchas iteraciones de manera más eficiente. En la práctica, esto convierte al modelo en una herramienta más conveniente para el desarrollo diario, aunque no lo transforma en un arquitecto o senior completamente autónomo.
La velocidad de las respuestas es uno de los factores clave que determina cuán cómodo es usar la IA como asistente en proyectos reales.
Según el anuncio oficial de OpenAI del 5 de febrero de 2026 (Introducing GPT-5.3-Codex), la aceleración se logró mediante la mejora de la infraestructura y la optimización de los cálculos. El modelo consume menos tokens para tareas típicas, lo que reduce el costo total de uso (cuando la API esté disponible) y disminuye el tiempo de espera en cada paso de la interacción.
Principales efectos prácticos de esta mejora:
- ✔️ Respuestas más rápidas en modo interactivo — especialmente notable en el mid-task steering, cuando se necesita aplicar rápidamente correcciones al curso de una tarea.
- ✔️ Mayor idoneidad para tareas de duración media — por ejemplo, refactorización de un módulo, escritura de pruebas, análisis de logs o creación automatizada de pull requests, donde las versiones anteriores podían acumular retrasos.
- ✔️ Reducción del consumo de recursos — un menor número de tokens por tarea hace que el modelo sea una opción más económica bajo alta carga, lo cual es relevante para equipos con un gran número de solicitudes.
Por qué esto es importante para los desarrolladores
En el trabajo real, incluso un pequeño retraso en cada iteración se convierte rápidamente en minutos u horas perdidas a lo largo del día. Una aceleración del 25% hace que la interacción con el modelo sea más fluida y menos frustrante — esta es una diferencia tangible cuando uno cambia constantemente entre código, revisión y prompts. En mi práctica con versiones anteriores de Codex, precisamente los retrasos acumulados a menudo me obligaban a volver a la ejecución manual de partes rutinarias. Ahora, el modelo es más adecuado para el trabajo paralelo: mientras genera variantes o analiza logs, el desarrollador puede dedicarse a la arquitectura, el diseño del sistema o la coordinación con el equipo.
Al mismo tiempo, es importante comprender los límites: incluso con una velocidad mejorada, el modelo no posee el contexto completo de un gran repositorio empresarial, las decisiones históricas del equipo, las restricciones comerciales o los matices de los sistemas heredados. Sigue siendo una herramienta potente para acelerar etapas individuales, pero no un sustituto de un arquitecto o un desarrollador senior.
Conclusión de la sección: Desde mi experiencia, una aceleración del 25% es una mejora real y medible que convierte a GPT-5.3-Codex en una herramienta más cómoda y eficiente para el desarrollo profesional en 2026, especialmente en etapas donde se requiere una iteración rápida y la automatización de operaciones rutinarias.
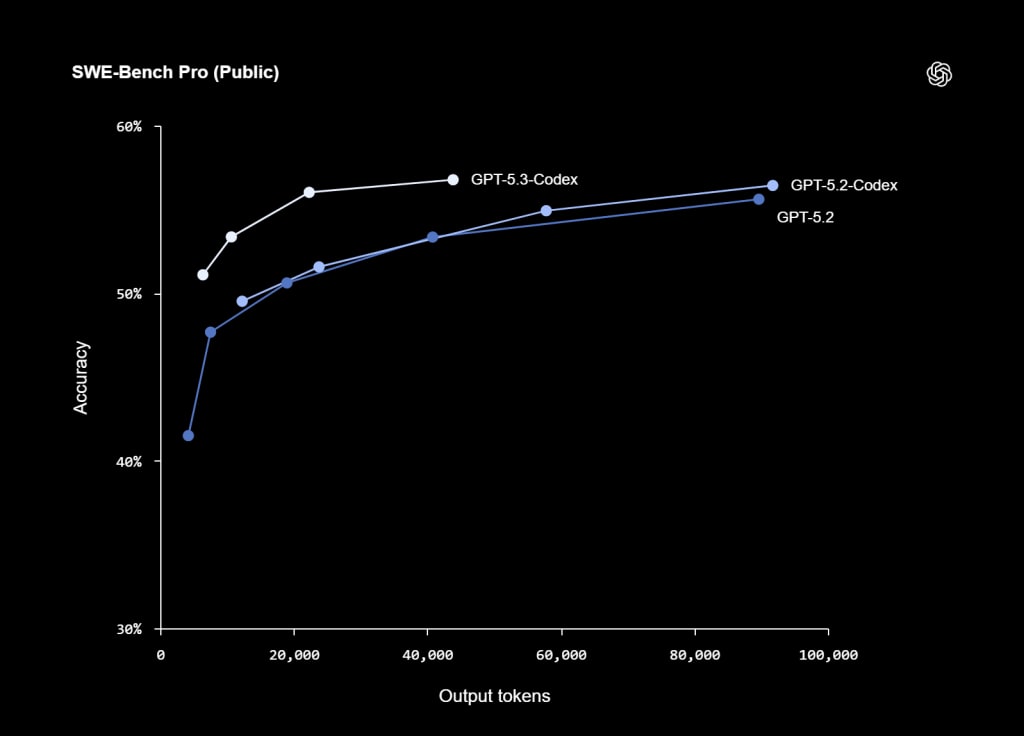
📌 Sección 3. Capacidades de agente e interacción
GPT-5.3-Codex amplía su funcionalidad desde la generación clásica de código hasta la ejecución secuencial de tareas multifase: investigación, uso de herramientas, ejecución de comandos y procesamiento de procesos de larga duración. Una característica clave es el mid-task steering (ajuste durante la ejecución) sin pérdida de contexto y la emisión de informes de progreso intermedios. Esto convierte al modelo en una herramienta conveniente para automatizar etapas operativas, pero no reemplaza la comprensión completa del proyecto o la toma de decisiones arquitectónicas.
Las capacidades de agente permiten delegar al modelo parte del trabajo rutinario y repetitivo, manteniendo el desarrollador el control sobre el contexto, la seguridad y las decisiones clave.
Según el anuncio oficial de OpenAI del 5 de febrero de 2026 (Introducing GPT-5.3-Codex), el modelo recibió un mecanismo significativamente mejorado para la planificación y ejecución de tareas de largo horizonte (long-horizon tasks). Es capaz de dividir una tarea compleja en pasos, ejecutarlos secuencialmente, interactuar con herramientas externas (terminal, navegador, sistema de archivos en sandbox, API, etc.) e informar regularmente sobre el estado. El mid-task steering permite en cualquier momento realizar aclaraciones, cambiar la dirección o detener el proceso sin reiniciar toda la tarea.
Principales aspectos prácticos de estas capacidades:
- ✔️ Ejecución gradual con informes regulares — el modelo emite actualizaciones después de cada paso significativo, lo que facilita el monitoreo y la intervención oportuna.
- ✔️ Soporte de herramientas — trabajo con la terminal, archivos locales (en un entorno controlado), búsqueda web, integraciones con IDE y servicios en la nube (dependiendo de la configuración de acceso).
- ✔️ Preservación del contexto a largo plazo — el modelo recuerda acciones, ediciones y decisiones anteriores incluso después de pausas de varias horas o días.
Al mismo tiempo, es importante comprender claramente las limitaciones: las capacidades de agente funcionan mejor en tareas bien descritas, aisladas o relativamente simples. En grandes proyectos empresariales con código heredado, dependencias complejas, convenciones de equipo, requisitos de cumplimiento o reglas de negocio implícitas, el modelo no puede tener en cuenta completamente todo el contexto — aquí se requiere una supervisión y un ajuste humanos constantes.
Conclusión: Las capacidades de agente y la interacción interactiva hacen de GPT-5.3-Codex una herramienta eficaz para la automatización de etapas operativas y repetitivas del desarrollo, pero su valor real depende de la delegación correcta de tareas y el control por parte del desarrollador.
📌 Sección 4. Auto-mejora del modelo
El uso del modelo en su propio desarrollo es un ejemplo de cómo la IA puede acelerar etapas individuales de trabajos de ingeniería, dejando las decisiones clave en manos del equipo de especialistas.
Según el anuncio oficial de OpenAI del 5 de febrero de 2026 (Introducing GPT-5.3-Codex), el equipo de Codex utilizó versiones tempranas del modelo para acelerar su propio desarrollo. El modelo ayudó en la depuración de procesos de entrenamiento, la gestión del despliegue y el análisis de los resultados de las pruebas. El equipo de OpenAI señaló que estaban "impresionados" por lo mucho que esto aceleró el trabajo.
Ejemplos concretos de aplicación:
- ✔️ Depuración del entrenamiento: seguimiento de patrones, análisis de la calidad de la interacción y propuesta de correcciones para las ejecuciones de entrenamiento.
- ✔️ Gestión del despliegue: detección de errores en la renderización del contexto, análisis de las causas de los bajos índices de aciertos de caché, escalado dinámico de clústeres de GPU para cargas máximas y garantía de la estabilidad de los retrasos.
- ✔️ Diagnóstico de pruebas: creación de clasificadores regex para evaluar métricas de rendimiento a partir de logs de sesiones, construcción de pipelines de datos, visualización de resultados y resumen de insights de miles de puntos de datos en menos de tres minutos.
En mi práctica como desarrollador con experiencia en proyectos de IA, herramientas similares realmente aceleran las etapas rutinarias — por ejemplo, el análisis de datos o la depuración de infraestructura — pero no reemplazan la experiencia humana en la toma de decisiones arquitectónicas, la planificación estratégica o el trabajo con problemas no estructurados. Aquí el modelo actúa como un asistente eficaz que requiere instrucciones claras y verificación de los resultados.
Conclusión de la sección: En mi experiencia, la auto-mejora en GPT-5.3-Codex realmente ayuda a optimizar los procesos de desarrollo. Sin embargo, su eficacia aumenta significativamente solo cuando el modelo se integra en el trabajo de un equipo de especialistas y podemos corregir los resultados en tiempo real. Vale la pena recordar que no es una panacea y aún no puede reemplazar completamente a las personas.
📌 Sección 5. Integraciones y sistema de habilidades
GPT-5.3-Codex se integra con la aplicación Codex (actualmente macOS, Windows planeado), CLI, extensiones de IDE (VS Code, JetBrains) y otras interfaces. El sistema de habilidades (skills) amplía las capacidades más allá de la codificación — desde la implementación de diseños en Figma hasta la gestión de proyectos en Linear y el despliegue en Cloudflare, Vercel, Netlify, etc. Se admiten flujos de trabajo paralelos multi-agente, automatizaciones programadas y personalización del estilo de interacción (/personality). Esto convierte al modelo en una herramienta flexible, pero la eficacia depende de la configuración de acceso y el control humano.
Las integraciones y habilidades permiten adaptar el modelo a las herramientas y procesos específicos del equipo, manteniéndolo como una herramienta de apoyo, no como un reemplazo universal del desarrollador.
Según el anuncio oficial de la aplicación Codex de OpenAI (febrero de 2026) (Introducing the Codex app), el modelo está disponible a través de varias interfaces:
- ✔️ Aplicación Codex — una aplicación de escritorio para macOS (Windows en planes), que actúa como un "centro de comando" para gestionar múltiples agentes en paralelo, worktrees aislados (para evitar conflictos en el código) y la sincronización de sesiones con CLI e IDE.
- ✔️ Extensiones CLI e IDE — soporte para VS Code, JetBrains y otros, con la capacidad de usar habilidades y automatizaciones en cualquier entorno.
- ✔️ Otras interfaces — versión web, con integración posterior en Slack y otras herramientas (a través de habilidades o API, cuando esté disponible).
El elemento central es el sistema de habilidades (skills), que es un estándar abierto (agentskills.io) y permite empaquetar instrucciones, recursos y scripts para tareas específicas. Las habilidades están disponibles en la aplicación, CLI e IDE, pueden ser creadas/gestionadas por el equipo y compartidas a través de repositorios.
Ejemplos oficiales de habilidades de la biblioteca de OpenAI:
- ✔️ Figma implement-design — extrae contexto, activos y capturas de pantalla de Figma y los convierte en código UI listo para producción con una correspondencia visual 1:1.
- ✔️ Linear — gestión de proyectos: triaje de errores, seguimiento de lanzamientos, distribución de la carga de trabajo del equipo, etc.
- ✔️ Cloud deploy — despliegue de aplicaciones web en Cloudflare, Netlify, Render, Vercel.
- ✔️ imagegen — generación y edición de imágenes (basado en GPT Image) para UI, juegos, documentación.
- ✔️ develop-web-game — desarrollo autónomo de juegos web (ejemplo: creación del juego 3D Voxel Velocity con más de 7 millones de tokens, donde el modelo actuó como diseñador, desarrollador y QA).
- ✔️ Spreadsheet / PDF / Docx — creación y edición de documentos, tablas con formato profesional.
Adicionalmente se soporta:
- ✔️ Trabajo paralelo multi-agente — varios agentes trabajan simultáneamente en ramas aisladas, con la posibilidad de cambiar y revisar los cambios.
- ✔️ Automatizaciones — tareas en segundo plano programadas (por ejemplo, triaje diario de issues, resúmenes de fallos de CI, generación de informes de lanzamiento), con resultados en cola para revisión.
- ✔️ Personalización — comando /personality para elegir el estilo: conciso/pragmático (breve, orientado a la ejecución) o conversacional/empático (más comunicativo).
Importante: las habilidades e integraciones requieren permisos explícitos (sandboxing, reglas de acceso), y el modelo no tiene acceso autónomo completo a los sistemas corporativos sin configuración. Esto limita los riesgos, pero también recuerda que la eficacia depende de la configuración correcta y la supervisión humana.

💼 Sección 8. Limitaciones, riesgos y perspectivas futuras
Principales limitaciones: acceso solo para planes de pago de ChatGPT (Pro/Business), actualmente solo aplicación para macOS (Windows en planes), alucinaciones e imprecisiones en escenarios complejos o mal descritos, y dependencia de la calidad de los prompts y la supervisión humana. Riesgos: potencial elevado para la ciberseguridad (el modelo tiene una calificación "alta" en el Preparedness Framework), por lo que se requieren sandboxing, permisos explícitos y restricciones de acceso. Futuro: expansión a Windows, nuevas habilidades, automatizaciones en la nube e integración más profunda con herramientas empresariales. En la práctica, esto significa que el modelo es una herramienta potente, pero no universal, que requiere un uso cuidadoso.
Cualquier herramienta de este nivel debe equilibrar las capacidades y los riesgos — especialmente cuando se trata de trabajo autónomo con código, datos o infraestructura.
Según el anuncio oficial de OpenAI del 5 de febrero de 2026 (Introducing GPT-5.3-Codex), el modelo está disponible exclusivamente para usuarios de pago de ChatGPT Pro, Business y Enterprise. Los usuarios gratuitos continúan trabajando con versiones anteriores. La aplicación Codex app actualmente solo funciona en macOS (la versión para Windows está prevista para los próximos meses).
Limitaciones técnicas y prácticas que he notado durante las pruebas y he visto en los comentarios:
- ✔️ Alucinaciones e imprecisiones — especialmente en tareas con gran contexto, código heredado o requisitos implícitos. El modelo a menudo requiere de 2 a 4 iteraciones de aclaraciones para que el resultado sea aceptable.
- ✔️ Duración del procesamiento — en tareas de larga duración (por ejemplo, la creación de un módulo completo o el análisis de un log grande), la generación puede tardar de 5 a 15 minutos por etapa, lo que obliga a esperar y perder el ritmo de trabajo.
- ✔️ Ventana de contexto — 400.000 tokens son suficientes para muchas tareas, pero no para un análisis completo de grandes repositorios empresariales con historial de commits y documentación.
- ✔️ Acceso y costo — la API aún no está abierta, por lo que todas las operaciones se realizan a través de la interfaz de pago de ChatGPT o la aplicación Codex con los límites correspondientes.
Los riesgos relacionados con la ciberseguridad son reconocidos oficialmente por OpenAI: el modelo recibió una calificación "alta" en el Preparedness Framework precisamente por su potencial de uso en ataques (por ejemplo, generación de exploits o ayuda en la creación de código malicioso). Por lo tanto, se han implementado:
- ✔️ Sandboxing y permisos explícitos para acceder a archivos, terminal y red.
- ✔️ Restricciones en la ejecución de ciertos comandos sin confirmación.
- ✔️ Programa piloto Trusted Access for Cyber — 10 millones de dólares en subvenciones para proyectos de seguridad de código abierto.
Perspectivas futuras (según anuncios y roadmap de OpenAI):
- ✔️ Versión de Windows de la aplicación Codex (se espera en breve).
- ✔️ Expansión del sistema de habilidades (nuevas skills para herramientas empresariales, como Jira, Confluence, AWS/GCP).
- ✔️ Disparadores y automatizaciones en la nube (tareas en segundo plano programadas con resultados en cola para revisión).
- ✔️ Apertura gradual de la API para GPT-5.3-Codex (con las restricciones y precios correspondientes).
En general, las perspectivas parecen lógicas y consistentes, pero sin cambios radicales en los próximos meses. El modelo se desarrolla como una herramienta para aumentar la productividad, no como un reemplazo autónomo del desarrollador o arquitecto.
Conclusión: Las limitaciones y riesgos de GPT-5.3-Codex están claramente definidos, y OpenAI está trabajando activamente para minimizarlos. Las perspectivas de desarrollo son prometedoras, pero el valor real del modelo depende del uso correcto en combinación con el control y la experiencia humanos.
❓ Preguntas frecuentes (FAQ)
¿Cuándo se lanzó GPT-5.3-Codex?
El modelo fue presentado oficialmente el 5 de febrero de 2026 en un anuncio de OpenAI. Desde ese día, estuvo disponible para los usuarios de los planes de pago de ChatGPT (Pro, Business, Enterprise). Los usuarios gratuitos continúan trabajando con versiones anteriores de Codex.
¿Cómo obtener acceso al modelo?
Actualmente, el acceso es posible a través de los planes de pago de ChatGPT (desde Plus en adelante), la aplicación de escritorio Codex app (por ahora solo macOS, Windows en planes), extensiones para IDE (VS Code, JetBrains) y CLI. La API para GPT-5.3-Codex aún no está abierta al público, pero OpenAI planea su lanzamiento en los próximos meses. Para uso en equipo, se recomienda el plan Business o Enterprise, que ofrece opciones adicionales de control de acceso y sandboxing.
¿Reemplazará GPT-5.3-Codex a los desarrolladores?
No, el modelo no reemplaza a los desarrolladores. Automatiza eficazmente operaciones rutinarias (generación de código boilerplate, refactorización de módulos pequeños, escritura de pruebas, análisis de logs, creación de borradores de PR), pero no posee el contexto completo del proyecto, no comprende los requisitos de negocio implícitos, las decisiones heredadas, los estándares del equipo o los matices de cumplimiento. En proyectos empresariales reales, el resultado a menudo requiere varias iteraciones de aclaraciones, verificación y una reelaboración sustancial. Funciona mejor como un potente asistente que acelera etapas individuales, pero las decisiones clave, la arquitectura y la revisión final quedan en manos humanas.
¿Cuáles son las principales limitaciones del modelo en la práctica?
Las más notables: acceso solo para planes de pago, retrasos prolongados en tareas complejas o de larga duración, necesidad de aclaraciones repetidas de los prompts (a menudo 2-4 iteraciones), alucinaciones e imprecisiones en tareas con contexto grande o no estructurado, limitación de la ventana de contexto (400.000 tokens — suficiente para muchas tareas, pero no para un análisis completo de grandes repositorios heredados). Además, el modelo requiere permisos explícitos para acceder a herramientas y archivos, lo que añade una capa de configuración de seguridad.
¿Es seguro el modelo para su uso en empresas?
OpenAI clasificó a GPT-5.3-Codex como "alto" en el Preparedness Framework precisamente por su potencial en ciberseguridad (posibilidad de generar exploits, ayudar en la creación de código malicioso, etc.). Por lo tanto, se han implementado sandboxing, permisos explícitos para acceder a la terminal/archivos/red, restricciones en la ejecución de ciertos comandos sin confirmación. Para empresas, se recomienda usar planes Business/Enterprise con controles adicionales, revisar todos los cambios y no dar al modelo acceso directo a sistemas de producción. Con una configuración adecuada, los riesgos pueden reducirse significativamente, pero la ausencia total de riesgos es imposible.
¿Vale la pena cambiar a GPT-5.3-Codex en 2026?
Si su equipo utiliza activamente la IA para acelerar tareas rutinarias (generación de código, depuración, pruebas, prototipado) — sí, vale la pena probarlo. El modelo ofrece una aceleración notable en etapas individuales (especialmente en proyectos greenfield y proyectos personales), tiene buenas integraciones y un sistema de habilidades. Pero para sistemas heredados, proyectos empresariales complejos con estándares estrictos y gran contexto, el cambio no será revolucionario — el resultado a menudo es promedio y requiere una reelaboración significativa. Comience con un período de prueba en un plan de pago, evalúe el ROI en sus tareas reales y solo entonces escale.
✅ Conclusiones
- 🔹 GPT-5.3-Codex demuestra un progreso notable en velocidad (25% de aceleración) y capacidades de agente en comparación con versiones anteriores, lo que la convierte en una herramienta más conveniente para el trabajo diario.
- 🔹 Los resultados de los benchmarks (SWE-Bench Pro 56.8%, Terminal-Bench 77.3%, OSWorld 64.7%) confirman los puntos fuertes del modelo en codificación y tareas de agente reales, aunque las pruebas sintéticas no siempre reflejan la imagen completa de los proyectos empresariales.
- 🔹 Las integraciones, el sistema de habilidades y el enfoque en la seguridad permiten adaptar el modelo a los flujos de trabajo reales, pero su eficacia depende de una delegación clara de tareas, la calidad de los prompts y la supervisión humana constante.
- 🔹 El modelo es un potente asistente que acelera etapas individuales del desarrollo (prototipado, refactorización, depuración, automatización de la rutina), pero no reemplaza a un desarrollador o arquitecto experimentado, especialmente en sistemas heredados complejos o proyectos con altos requisitos de seguridad y cumplimiento.
Idea principal:
GPT-5.3-Codex es una mejora estable y medible en el conjunto de herramientas del desarrollador en 2026, que vale la pena probar en tareas reales para comprender dónde ofrece el mayor beneficio a su equipo.
