El 10 de junio de 2026, Google DeepMind lanzó DiffusionGemma, un modelo abierto de 26B parámetros (3.8B activos) que genera texto a través de difusión en lugar del enfoque autorregresivo estándar.
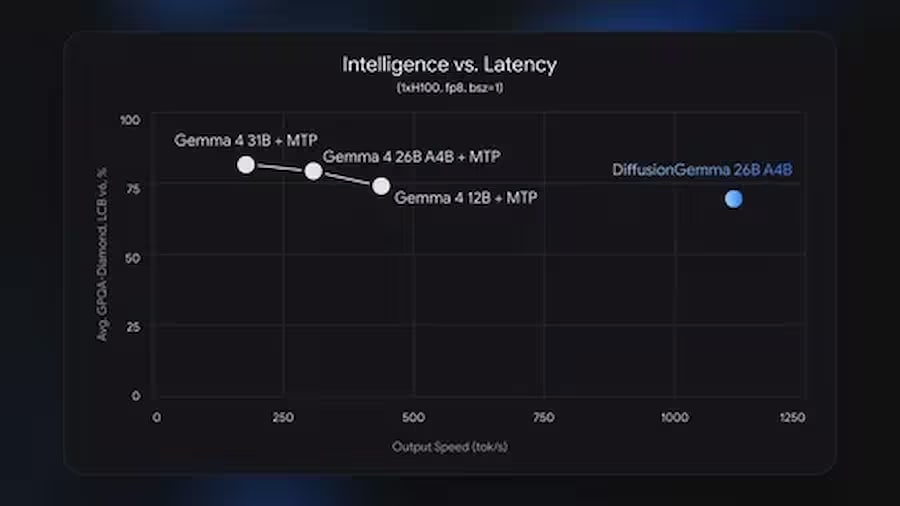
Velocidad: más de 1000 tokens por segundo en NVIDIA H100, más de 700 en RTX 5090.
El modelo se ejecuta localmente con 18 GB de VRAM, disponible en Hugging Face bajo la licencia Apache 2.0.
Soportado a través de vLLM, Hugging Face Transformers, MLX, Unsloth, NVIDIA NeMo.
Compromiso principal: la velocidad es mayor que la de Gemma 4, pero la calidad de las respuestas es menor.
¿Qué es DiffusionGemma?
DiffusionGemma es un modelo de lenguaje abierto experimental de Google DeepMind, lanzado el 10 de junio de 2026. Está construido sobre la arquitectura Gemma 4 (MoE, 26B parámetros, 3.8B activos) y utiliza un enfoque fundamentalmente diferente para la generación de texto: text diffusion en lugar de decodificación autorregresiva.
El modelo tiene una ventana de contexto de 262 144 tokens, admite más de 140 idiomas y es multimodal: acepta texto, imágenes y video como entrada. Los pesos se publican en Hugging Face bajo la licencia Apache 2.0.
La documentación oficial está disponible en Google AI for Developers. DiffusionGemma es el primer modelo de difusión compatible de forma nativa con la plataforma de inferencia abierta vLLM.
¿En qué se diferencia de GPT, Gemini, Qwen y Llama?
Todos los modelos de lenguaje grandes modernos — GPT-4o, Gemini 2.5, Qwen3, Llama 4 — se basan en el mismo principio: generación autorregresiva. El modelo genera texto token a token, de izquierda a derecha. Cada nuevo token depende de todos los anteriores. Esto es eficiente, pero lento: la GPU espera el resultado del paso anterior antes de comenzar el siguiente.
Para comprender la diferencia, es útil tener una analogía concreta. Un modelo autorregresivo es una mecanógrafa: escribe un carácter a la vez, no puede retroceder y corregir una línea anterior hasta que llega al final. DiffusionGemma es un editor que ve todo el párrafo a la vez: primero escribe un borrador, luego lo revisa y refina varias veces hasta que el texto se vuelve coherente.
¿Cómo difiere exactamente la mecánica?
Un modelo autorregresivo hace lo mismo en cada paso: mira todos los tokens anteriores y predice el siguiente. Esto significa que para generar 256 tokens, el modelo realiza 256 pases hacia adelante separados a través de la red neuronal. Cada uno de ellos depende del resultado del anterior, lo que hace imposible paralelizarlo.
DiffusionGemma funciona de manera diferente. Genera un bloque de 256 tokens a la vez en varias iteraciones de refinamiento. En la primera iteración, las 256 posiciones están llenas de "ruido", tokens aleatorios o poco informativos. En cada paso siguiente, el modelo revisa todo el bloque y reemplaza los tokens menos seguros por otros más precisos. Detalle clave: en cada paso, cada token ve a todos sus vecinos en el bloque, lo que es una atención bidireccional, a diferencia de la unidireccional en los LLM estándar.
Resultado: en lugar de 256 pases hacia adelante secuenciales, hay varias iteraciones paralelas sobre todo el bloque. La GPU se carga de manera uniforme, sin esperas entre pasos.
Comparación de enfoques
Parámetro
GPT / Qwen / Llama
DiffusionGemma
Principio de generación
Token a token, 1 pase hacia adelante por token
Por bloques de 256 tokens, varias iteraciones por bloque
Dirección de atención
Unidireccional (de izquierda a derecha)
Bidireccional (cada token ve a todos en el bloque)
Corrección durante la generación
Imposible: el token está fijado para siempre
Posible: el bloque se revisa en cada iteración
Carga de GPU (usuario único)
Secuencial; hay inactividad entre pasos
Paralela; los núcleos tensoriales se cargan uniformemente
Carga de GPU (batch grande)
Eficiente: el batch llena la GPU por completo
Menos eficiente: la ventaja disminuye
Infilling (inserción en el medio)
Requiere trucos especiales de FIM
Tarea natural: el bloque ve el contexto de ambos lados
Calidad de salida
Alta, probada en benchmarks
Inferior a Gemma 4 en la etapa actual
Velocidad (usuario único, GPU)
50–150 tokens/s dependiendo del modelo
700–1200+ tokens/s en GPUs modernas
Licencia
Varía: de MIT a propietario
Apache 2.0
¿Dónde la diferencia es fundamental y dónde no
La atención bidireccional no es solo un detalle técnico. Para un modelo autorregresivo, un token en la posición 100 "no sabe" lo que vendrá en la posición 101. Para DiffusionGemma, cada token en el bloque se genera desde el principio teniendo en cuenta a todos sus vecinos. Esto abre tareas en las que el enfoque autorregresivo requiere soluciones alternativas especiales:
Infilling de código: inserción de código entre dos bloques existentes teniendo en cuenta el contexto de arriba y abajo.
Formatos estructurados: generación de JSON o SQL, donde la estructura final se conoce de antemano.
Edición de documentos: rellenar un fragmento faltante manteniendo el estilo anterior y posterior.
Al mismo tiempo, hay escenarios en los que los modelos autorregresivos conservan una ventaja. El servicio en la nube con un tamaño de batch grande es precisamente donde el paralelismo de DiffusionGemma ofrece menos beneficios, y los miles de solicitudes por segundo en GPT-4o o Gemini 2.5 Flash se procesan de manera más eficiente. Las respuestas analíticas largas, el razonamiento complejo, las tareas con ajuste fino RLHF: aquí, los años de escalado del enfoque autorregresivo dan una ventaja tangible en calidad.
Una evaluación honesta del compromiso
Google admite abiertamente: DiffusionGemma es inferior a Gemma 4 normal en calidad general en benchmarks. Esto no es una subestimación de marketing, es el estado real de las cosas en junio de 2026. El enfoque de difusión para texto es varios órdenes de magnitud más joven que el autorregresivo en términos de experiencia acumulada de escalado.
Parámetro
GPT / Llama / Qwen
DiffusionGemma
Arquitectura
Autorregresiva
Difusión
Generación
Token a token (1 pase hacia adelante por token)
Por bloques de 256 tokens (varias iteraciones por bloque)
Dirección de atención
Unidireccional — de izquierda a derecha
Bidireccional — cada token ve a todos en el bloque
Ollama, llama.cpp, vLLM, LM Studio — soporte completo
vLLM, HF Transformers, MLX — llama.cpp y Ollama aún en proceso
Licencia (modelos principales)
Varía: MIT, Llama Community, Apache 2.0
Apache 2.0
Comparación de enfoques autorregresivos y de difusión para la generación de texto. Datos: Google, blog de vLLM, junio de 2026.
La forma correcta de pensar en DiffusionGemma no es como "Gemma 4, pero más rápido", sino como otra herramienta con su propio perfil de compensaciones: mayor velocidad e infilling natural a cambio de una menor calidad general y un ecosistema menos maduro. Para algunas tareas, este intercambio es ventajoso ya ahora. Para otras, todavía no.
¿Cómo funciona la generación de texto por difusión?
La idea de la difusión provino de la generación de imágenes. Allí, el modelo toma una imagen ruidosa y gradualmente la "limpia" en varios pasos hasta obtener un resultado claro. DiffusionGemma traslada este mismo principio al texto.
El proceso de generación ocurre en tres etapas conceptuales:
Inicialización. El modelo crea un bloque de 256 tokens de relleno aleatorios ("ruido").
Eliminación iterativa de ruido. En varios pases, el modelo reemplaza gradualmente el "ruido" por tokens reales. En cada paso, cada token "ve" a todos sus vecinos en el bloque; esta es una atención bidireccional.
Convergencia. Después de varias iteraciones, el bloque se convierte en texto coherente.
La diferencia clave con el enfoque autorregresivo es que el modelo no "fija" un token de inmediato y para siempre. Puede revisar y corregir todo el bloque durante el proceso de refinamiento. Esto abre nuevos escenarios de uso: rellenar huecos en el texto, insertar código en medio de un archivo, corregir formato, tareas en las que los modelos autorregresivos son tradicionalmente más débiles.
Detalle técnico: Google implementó la llamada eliminación de ruido basada en entropía, un mecanismo que determina cuántos pasos de limpieza se necesitan para cada bloque específico. Los bloques simples se procesan más rápido, los complejos reciben más iteraciones.
Velocidad: hasta 1000+ tokens por segundo
Cifras oficiales de rendimiento de Google y el equipo de vLLM:
Para comparar: los modelos autorregresivos estándar de tamaño similar producen aproximadamente 50–150 tokens/s en el mismo hardware con carga de usuario único. La ventaja de 4x de DiffusionGemma se realiza precisamente en modo de bajo paralelismo, para una o varias solicitudes simultáneas.
Advertencia importante: con tamaños de batch grandes (cientos de solicitudes paralelas en la nube), la ventaja desaparece. VentureBeat señala que para el servicio en la nube con batching masivo, los modelos autorregresivos siguen siendo más eficientes. DiffusionGemma está orientada principalmente a la ejecución local y escenarios interactivos.
MLX — para Mac con Apple Silicon (soportado, pero la velocidad es significativamente menor)
Unsloth — para fine-tuning
NVIDIA NeMo — para despliegue empresarial
llama.cpp — soporte en proceso (PR aún no fusionado)
Ollama aún no es compatible. Cuando llama.cpp obtenga soporte final para DiffusionGemma, la integración de Ollama aparecerá automáticamente, pero los plazos son desconocidos. Para los usuarios de Mac, MLX funciona, pero sin una ventaja de velocidad significativa sobre los modelos normales.
Despliegue en la nube: el modelo está disponible a través del Google Cloud Model Garden y NVIDIA NIM.
Por qué esto es más importante de lo que parece
La mayoría de las noticias se centran en la cifra de "4 veces más rápido". Pero la verdadera importancia de DiffusionGemma no reside en la velocidad, sino en lo que hay detrás de ella. Para entenderlo, hay que observar cómo han evolucionado los modelos de lenguaje en los últimos ocho años, y por qué esta evolución ha sido unidireccional.
8 años de un solo camino
La arquitectura Transformer apareció en 2017 en el artículo de Google "Attention is All You Need". Desde GPT-1 hasta GPT-4o, desde Llama 1 hasta Llama 4, desde Qwen hasta Mistral, todos estos modelos se basan en el mismo principio: generación autorregresiva de izquierda a derecha. Token a token. Durante más de 8 años, la industria ha escalado una única arquitectura, aumentando parámetros, calidad de datos y computación.
Esto no fue una casualidad. El enfoque autorregresivo tenía ventajas reales: escalaba bien, su comportamiento era predecible y los nuevos modelos podían compararse entre sí en benchmarks estándar. Cada año salían nuevas versiones: más grandes, más precisas, más baratas en inferencia. Pero la lógica fundamental permanecía inalterada.
Existían alternativas en el ámbito académico —masked diffusion, discrete diffusion, MDLM— pero ninguna de ellas trascendía pequeños experimentos. La industria apostó por el Transformer y el escalado, y esta apuesta dio sus frutos. El problema es que el éxito de un enfoque desplaza la investigación de otros. Cuando GPT-3 demostró que el escalado funcionaba, la mayor parte de los recursos se dirigieron allí.
Por qué el enfoque autorregresivo tiene un techo estructural
La generación token a token no es solo una cuestión de velocidad. Es una cuestión de cómo "piensa" el modelo. Cada token subsiguiente depende condicionalmente de todos los anteriores, y esta dependencia es unidireccional e irreversible. El modelo no puede revisar lo que ya ha generado, solo puede continuar.
Esto crea varias limitaciones fundamentales:
El error se propaga. Si el modelo elige un token equivocado en el paso 15, los siguientes 200 tokens se construirán sobre ese error. Mecanismos como la temperatura y el top-p reducen la probabilidad de error, pero no resuelven el problema por completo.
Infilling — debilidad estructural. Insertar texto en medio de un fragmento existente no es trivial para un modelo autorregresivo. Se necesitan trucos especiales (FIM — fill-in-the-middle) que añaden complejidad y no siempre funcionan de manera estable.
La GPU está inactiva. En la inferencia de un solo usuario, la generación autorregresiva carga la GPU secuencialmente: paso a paso. Hay retrasos entre pasos. Para la ejecución local, esto significa que la mayor parte del tiempo el potente hardware simplemente espera.
Los contextos largos son caros. Cada nuevo token "mira" todo el contexto anterior a través del mecanismo de atención. Cuanto más largo es el contexto, más caro es cada paso subsiguiente.
Una alternativa que realmente funciona
Los modelos de difusión para texto existían antes, pero solo como experimentos académicos a pequeña escala. DiffusionGemma es el primer modelo de difusión grande con arquitectura MoE que se ha puesto a disposición del público con soporte de grado de producción en los principales frameworks. No es una demo ni una lista de espera, son pesos abiertos que se pueden descargar ahora mismo.
Antes de esto, el ejemplo comercial más cercano fue Mercury Coder de Inception Labs, un modelo de difusión para código lanzado a principios de 2025. Pero seguía siendo cerrado y específico de dominio. DiffusionGemma es el primer modelo abierto de propósito general de esta clase.
Es importante entender que Google no solo ha lanzado "otro modelo". La empresa ha integrado DiffusionGemma en una infraestructura de inferencia real: soporte nativo en vLLM, Hugging Face Transformers, MLX, optimización para NVIDIA Hopper y Blackwell. Esto es una señal de que Google se toma el enfoque de difusión en serio, no como un artefacto de investigación, sino como una dirección potencialmente apta para producción.
Una nueva lógica de generación — y lo que abre
El enfoque autorregresivo tiene una limitación fundamental: el modelo no puede "volver atrás". Un error en medio de una frase se fija, y todos los tokens subsiguientes se construyen sobre él. DiffusionGemma puede revisar todo el bloque durante el proceso de generación, lo que es una lógica fundamentalmente diferente.
En la práctica, esto significa nuevos escenarios donde los modelos autorregresivos son tradicionalmente débiles:
Infilling de código. Insertar una función en medio de un archivo, manteniendo el contexto de arriba y abajo, es precisamente donde la atención bidireccional ofrece una ventaja real.
Formatos estructurados. Generación de JSON, SQL o XML con restricciones estrictas en la estructura: un modelo de difusión puede "tener en mente" la forma final del bloque y ajustar todo el texto a ella de una vez.
Edición y complemento. Rellenar un hueco en un documento ya escrito, manteniendo el estilo y el contexto antes y después: a los modelos autorregresivos les cuesta, el enfoque de difusión resuelve la tarea de forma natural.
Aplicaciones interactivas. Donde el retraso es crítico — autocompletado en un editor, resumen en vivo, traducción en tiempo real — 1000+ tokens por segundo en ejecución local abren posibilidades antes inaccesibles.
Las implicaciones para los pipelines RAG y los sistemas de agentes aún deben evaluarse en la práctica. Pero el mero hecho de la aparición de una arquitectura alternativa en producción —con pesos abiertos, infraestructura real y soporte de Google— es significativo independientemente de las limitaciones de calidad actuales.
Qué vendrá después
Los modelos autorregresivos en 2017 tampoco eran perfectos. GPT-1 generaba texto coherente, pero la calidad estaba lejos de los estándares actuales. En 8 años de escalado, mejora de datos y nuevas soluciones arquitectónicas, el Transformer se ha convertido en el pilar de toda la industria.
El enfoque de difusión para texto se encuentra ahora aproximadamente donde estaba el autorregresivo en 2018-2019. Existe la primera muestra grande y abierta. Existe una ventaja real en escenarios específicos. Existen limitaciones estructurales que aún no se han superado. Y queda la pregunta abierta: ¿cuánto tiempo y recursos se necesitan para que los modelos de difusión alcancen la calidad de los autorregresivos?
Google no responde a esta pregunta directamente. Pero el simple hecho de que DiffusionGemma se haya lanzado bajo licencia Apache 2.0 con soporte de infraestructura completo no es una publicación académica. Es una declaración de que la dirección merece una seria consideración.
Qué significa esto para el futuro de los LLM
Por ahora, DiffusionGemma es un modelo experimental. Google no oculta que, en términos de calidad general, es inferior a Gemma 4 estándar. Para tareas de producción donde la precisión es importante, los modelos autorregresivos siguen siendo la mejor opción.
Pero hay varias señales a tener en cuenta:
Velocidad de desarrollo de los modelos de difusión. Los modelos autorregresivos se escalaron durante años antes de alcanzar el nivel de calidad actual. El enfoque de difusión apenas está comenzando este camino.
Escenarios donde la difusión ya gana. Ejecución local, infilling de código, edición interactiva, tareas de baja latencia — aquí la ventaja ya es real.
Impacto en la infraestructura. DiffusionGemma es el primer modelo de difusión soportado nativamente en vLLM. Esto significa que el ecosistema de infraestructura está empezando a adaptarse.
Los competidores observan. Inception Labs ya está en este espacio. Si el enfoque de difusión muestra una mejora constante en la calidad, otros grandes actores comenzarán a invertir más activamente.
DiffusionGemma no es una revolución que reemplazará a GPT y Llama mañana. Pero es la primera prueba pública seria de que una arquitectura alternativa para la generación de texto puede funcionar en condiciones reales. Y eso ya es lo suficientemente importante.
Lea más en la serie
Este es el primer artículo de una serie sobre DiffusionGemma y la nueva arquitectura de modelos de lenguaje.