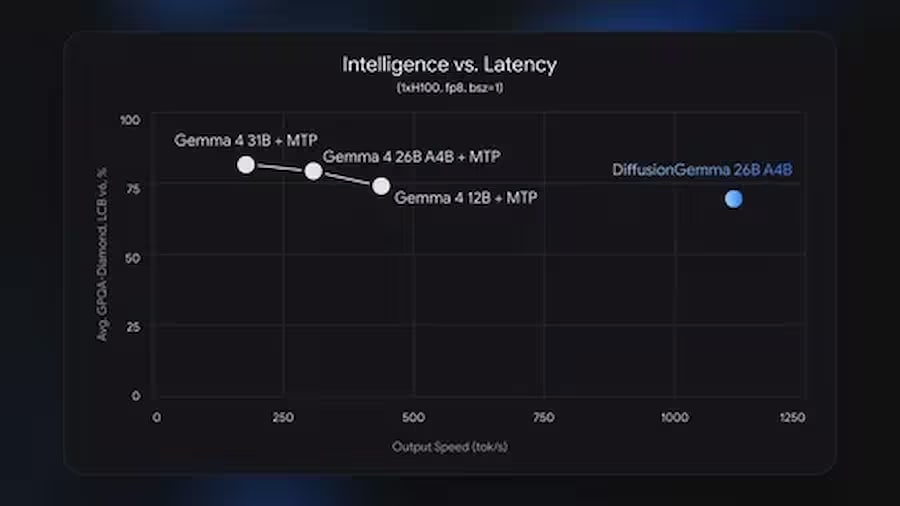
Am 10. Juni 2026 veröffentlichte Google DeepMind DiffusionGemma – ein Open-Source-Modell mit 26B Parametern (3,8B aktiv), das Text über Diffusion statt des üblichen autoregressiven Ansatzes generiert.
Geschwindigkeit: 1000+ Token pro Sekunde auf NVIDIA H100, 700+ auf RTX 5090.
Das Modell läuft lokal mit 18 GB VRAM und ist auf Hugging Face unter der Apache 2.0-Lizenz verfügbar.
Unterstützt über vLLM, Hugging Face Transformers, MLX, Unsloth, NVIDIA NeMo.
Der Hauptkompromiss: Die Geschwindigkeit ist höher als bei Gemma 4, aber die Qualität der Antworten ist niedriger.
Was ist DiffusionGemma
DiffusionGemma ist ein experimentelles Open-Source-Sprachmodell von Google DeepMind, das am 10. Juni 2026 veröffentlicht wurde. Es basiert auf der Gemma 4 (MoE, 26B Parameter, 3,8B aktiv) Architektur und verwendet einen grundlegend anderen Ansatz zur Textgenerierung – Textdiffusion statt autoregressiver Dekodierung.
Das Modell verfügt über ein Kontextfenster von 262.144 Token, unterstützt über 140 Sprachen und ist multimodal: Es akzeptiert Text, Bilder und Videos als Eingabe. Die Gewichte sind auf Hugging Face unter der Apache 2.0-Lizenz veröffentlicht.
Die offizielle Dokumentation ist auf Google AI for Developers verfügbar. DiffusionGemma ist das erste Diffusionsmodell, das nativ in der Open-Source-Inference-Plattform vLLM unterstützt wird.
Чим вона відрізняється від GPT, Gemini, Qwen і Llama
Усі сучасні великі мовні моделі — GPT-4o, Gemini 2.5, Qwen3, Llama 4 — побудовані на одному й тому самому принципі: autoregressive generation. Модель генерує текст токен за токеном, зліва направо. Кожен новий токен залежить від усіх попередніх. Це ефективно, але повільно: GPU очікує на результат попереднього кроку перед тим, як почати наступний.
Щоб зрозуміти різницю, корисно мати конкретну аналогію. Autoregressive-модель — це машиністка: вона друкує по одному символу, не може повернутися і виправити попередній рядок, поки не дійде до кінця. DiffusionGemma — це редактор, який бачить весь абзац одразу: спочатку пише чернетку, потім кілька разів переглядає і уточнює, поки текст не стає зв'язним.
Як саме відрізняється механіка
Autoregressive-модель на кожному кроці робить одне й те ж: дивиться на всі попередні токени і передбачає наступний. Це означає, що для генерації 256 токенів модель виконує 256 окремих forward pass через нейромережу. Кожен з них залежить від результату попереднього — паралелізувати їх неможливо.
DiffusionGemma працює інакше. Вона генерує відразу блок із 256 токенів за кілька ітерацій refinement. На першій ітерації всі 256 позицій заповнені «шумом» — випадковими або малоінформативними токенами. На кожному наступному кроці модель переглядає весь блок і замінює найменш впевнені токени на більш точні. Ключова деталь: на кожному кроці кожен токен бачить усіх сусідів у блоці — це двонаправлена увага, на відміну від односторонньої у стандартних LLM.
Результат: замість 256 послідовних forward pass — кілька паралельних ітерацій над усім блоком. GPU завантажений рівномірно, без очікування між кроками.
Порівняння підходів
Параметр
GPT / Qwen / Llama
DiffusionGemma
Принцип генерації
Токен за токеном, 1 forward pass на токен
Блоками по 256 токенів, кілька ітерацій на блок
Напрямок уваги
Одностороннє (зліва направо)
Двонаправлене (кожен токен бачить усіх у блоці)
Виправлення під час генерації
Неможливе: токен зафіксовано назавжди
Можливе: блок переглядається на кожній ітерації
Завантаження GPU (single user)
Послідовне; між кроками є простій
Паралельне; тензорні ядра завантажені рівномірно
Завантаження GPU (великий batch)
Ефективне: batch заповнює GPU повністю
Менш ефективне: перевага зменшується
Infilling (вставка у середину)
Потрібні спеціальні FIM-трюки
Природна задача: блок бачить контекст з обох боків
Якість виводу
Висока, перевірена на бенчмарках
Нижча за Gemma 4 на поточному етапі
Швидкість (single user, GPU)
50–150 токенів/с залежно від моделі
700–1200+ токенів/с на сучасних GPU
Ліцензія
Varies: від MIT до proprietary
Apache 2.0
Де різниця принципова, а де — ні
Двонаправлена увага — це не просто технічна деталь. Для autoregressive-моделі токен на позиції 100 «не знає», що буде на позиції 101. Для DiffusionGemma кожен токен у блоці від початку генерується з урахуванням усіх сусідів. Це відкриває задачі, де autoregressive-підхід потребує спеціальних обхідних рішень:
Code infilling: вставка коду між двома існуючими блоками з урахуванням контексту зверху і знизу.
Структуровані формати: генерація JSON або SQL, де кінцева структура відома заздалегідь.
Редагування документів: заповнення пропущеного фрагменту із збереженням стилю до і після.
Водночас є сценарії, де autoregressive-моделі зберігають перевагу. Хмарний serving із великим batch size — саме там, де паралелізм DiffusionGemma дає менший виграш, а тисячі запитів на секунду у GPT-4o чи Gemini 2.5 Flash обробляються ефективніше. Довгі аналітичні відповіді, складний reasoning, задачі з RLHF-тюнінгом — тут роки масштабування autoregressive-підходу дають відчутну перевагу в якості.
Чесна оцінка компромісу
Google відверто визнає: DiffusionGemma поступається звичайній Gemma 4 за загальною якістю на бенчмарках. Це не маркетингове применшення — це реальний стан справ на червень 2026 року. Diffusion-підхід для тексту молодший за autoregressive на кілька порядків в плані накопиченого досвіду масштабування.
Параметр
GPT / Llama / Qwen
DiffusionGemma
Архітектура
Autoregressive
Diffusion
Генерація
Токен за токеном (1 forward pass на токен)
Блоками по 256 токенів (кілька ітерацій на блок)
Напрямок уваги
Одностороннє — зліва направо
Двонаправлене — кожен токен бачить усіх у блоці
Може виправляти попередній текст
Ні — токен зафіксовано назавжди
Так — блок переглядається на кожній ітерації
Infilling (вставка у середину)
Потрібні FIM-трюки, нестабільно
Природна задача — контекст з обох боків
Завантаження GPU (single user)
Послідовне, між кроками є простій
Паралельне, тензорні ядра завантажені рівномірно
Завантаження GPU (великий batch)
Ефективне — batch заповнює GPU повністю
Перевага зменшується при високому QPS
Швидкість (single user, H100)
~50–150 токенів/с
1000–1200+ токенів/с
Якість виводу
Висока, перевірена роками
Нижча за Gemma 4 на поточному етапі
Зрілість екосистеми
Ollama, llama.cpp, vLLM, LM Studio — повна підтримка
vLLM, HF Transformers, MLX — llama.cpp і Ollama ще в процесі
Ліцензія (основні моделі)
Varies: MIT, Llama Community, Apache 2.0
Apache 2.0
Порівняння autoregressive та diffusion підходів до генерації тексту. Дані: Google, vLLM blog, червень 2026.
Правильний спосіб думати про DiffusionGemma — не як про «Gemma 4, але швидше», а як про інший інструмент із власним профілем trade-offs: вища швидкість і природний infilling в обмін на нижчу загальну якість і менш зрілу екосистему. Для частини завдань цей обмін вигідний вже зараз. Для інших — поки ні.
Процес генерації відбувається у три концептуальні етапи:
Ініціалізація. Модель створює блок із 256 випадкових токенів-заповнювачів («шум»).
Iterative denoising. За кілька проходів модель поступово замінює «шум» на реальні токени. На кожному кроці кожен токен «бачить» усіх сусідів у блоці — це двонаправлена увага.
Конвергенція. Після декількох ітерацій блок перетворюється на зв'язний текст.
Ключова відмінність від autoregressive-підходу: модель не «зафіксовує» токен одразу і назавжди. Вона може переглянути та скоригувати весь блок у процесі refinement. Це відкриває нові сценарії використання: заповнення прогалин у тексті, вставка коду в середину файлу, виправлення форматування — завдання, де autoregressive-моделі традиційно слабкіші.
Технічна деталь: Google реалізувала так зване entropy-bound denoising — механізм, що визначає, скільки кроків очищення потрібно для кожного конкретного блоку. Прості блоки обробляються швидше, складні — отримують більше ітерацій.
Швидкість: до 1000+ токенів на секунду
Офіційні показники продуктивності від Google та команди vLLM:
Для порівняння: стандартні autoregressive-моделі аналогічного розміру дають приблизно 50–150 токенів/с на тому ж залізі при single-user навантаженні. Перевага DiffusionGemma в 4x реалізується саме в режимі низького паралелізму — для одного або кількох одночасних запитів.
Важливе застереження: при великих batch size (сотні паралельних запитів у хмарі) перевага зникає. VentureBeat зазначає, що для хмарного serving із масовим батчингом autoregressive-моделі залишаються ефективнішими. DiffusionGemma орієнтована насамперед на локальний запуск та інтерактивні сценарії.
MLX — для Mac з Apple Silicon (підтримується, але швидкість значно нижча)
Unsloth — для fine-tuning
NVIDIA NeMo — для корпоративного розгортання
llama.cpp — підтримка в процесі (PR ще не змерджено)
Ollama поки не підтримується. Коли llama.cpp отримає фінальну підтримку DiffusionGemma, Ollama-інтеграція з'явиться автоматично — але терміни невідомі. Для Mac-користувачів MLX працює, але без суттєвої перевагу швидкості над звичайними моделями.
Die meisten Nachrichten konzentrieren sich auf die Zahl „4x schneller“. Aber die wahre Bedeutung von DiffusionGemma liegt nicht in der Geschwindigkeit, sondern in dem, was dahinter steckt. Um das zu verstehen, muss man sich ansehen, wie sich Sprachmodelle in den letzten acht Jahren entwickelt haben – und warum diese Entwicklung einseitig war.
8 Jahre eines Weges
Die Transformer-Architektur erschien 2017 in Googles Arbeit „Attention is All You Need“. Von GPT-1 bis GPT-4o, von Llama 1 bis Llama 4, von Qwen bis Mistral – all diese Modelle basieren auf demselben Prinzip: autoregressive Generierung von links nach rechts. Token für Token. Über 8 Jahre hat die Industrie eine Architektur skaliert und dabei Parameter, Datenqualität und Rechenleistung erhöht.
Dies war kein Zufall. Der autoregressive Ansatz hatte reale Vorteile: Er war gut skalierbar, sein Verhalten war verständlich und neue Modelle konnten auf Standard-Benchmarks miteinander verglichen werden. Jedes Jahr erschienen neue Versionen – größer, genauer, günstiger in der Inferenz. Aber die grundlegende Logik blieb unverändert.
Alternativen gab es im akademischen Umfeld – masked diffusion, discrete diffusion, MDLM – aber keine davon ging über kleine Experimente hinaus. Die Industrie setzte auf Transformer und Skalierung, und diese Wette zahlte sich aus. Das Problem ist, dass der Erfolg eines Ansatzes die Erforschung anderer verdrängt. Als GPT-3 zeigte, dass Skalierung funktioniert, floss der Großteil der Ressourcen dorthin.
Warum der autoregressive Ansatz eine strukturelle Decke hat
Die Generierung Token für Token ist nicht nur eine Frage der Geschwindigkeit. Es ist eine Frage, wie das Modell „denkt“. Jedes nachfolgende Token hängt bedingt von allen vorherigen ab, und diese Abhängigkeit ist unidirektional und irreversibel. Das Modell kann das bereits Generierte nicht überarbeiten – es kann nur fortfahren.
Dies schafft mehrere grundlegende Einschränkungen:
Fehler breiten sich aus. Wenn das Modell bei Schritt 15 ein fehlerhaftes Token wählt, bauen alle nachfolgenden 200 Token auf diesem Fehler auf. Mechanismen wie Temperatur und Top-p verringern die Wahrscheinlichkeit von Fehlern, lösen das Problem aber nicht vollständig.
Infilling – strukturelle Schwäche. Das Einfügen von Text in die Mitte eines bereits vorhandenen Fragments ist für ein autoregressives Modell nicht trivial. Es erfordert spezielle Tricks (FIM – fill-in-the-middle), die Komplexität hinzufügen und nicht immer stabil funktionieren.
GPU-Leerlauf. Bei der Single-User-Inferenz lädt die autoregressive Generierung die GPU sequenziell: Schritt für Schritt. Zwischen den Schritten gibt es Verzögerungen. Für den lokalen Betrieb bedeutet dies, dass die meiste Zeit leistungsstarke Hardware einfach wartet.
Lange Kontexte sind teuer. Jedes neue Token „schaut“ über den Aufmerksamkeitsmechanismus auf den gesamten vorherigen Kontext. Je länger der Kontext, desto teurer ist jeder nachfolgende Schritt.
Eine Alternative, die wirklich funktioniert
Diffusion-Modelle für Text gab es schon früher – aber nur als akademische Experimente in kleinem Maßstab. DiffusionGemma ist das erste große Diffusion-Modell mit MoE-Architektur, das mit produktionsreifen Unterstützung in führenden Frameworks frei zugänglich gemacht wurde. Dies ist keine Demo und keine Warteliste – es sind offene Gewichte, die Sie sofort herunterladen können.
Zuvor war das nächstgelegene kommerzielle Beispiel Mercury Coder von Inception Labs – ein Diffusion-Modell für Code, das Anfang 2025 veröffentlicht wurde. Aber es blieb geschlossen und domänenspezifisch. DiffusionGemma ist das erste offene Allzweckmodell dieser Klasse.
Es ist wichtig zu verstehen, dass Google nicht einfach „ein weiteres Modell“ veröffentlicht hat. Das Unternehmen hat DiffusionGemma in eine echte Inferenz-Infrastruktur integriert: native Unterstützung in vLLM, Hugging Face Transformers, MLX, Optimierung für NVIDIA Hopper und Blackwell. Dies ist ein Signal dafür, dass Google den Diffusionsansatz ernst nimmt – nicht als Forschungsartefakt, sondern als potenziell produktionsreifen Bereich.
Eine neue Logik der Generierung – und was sie eröffnet
Der autoregressive Ansatz hat eine grundlegende Einschränkung: Das Modell kann nicht „zurückgehen“. Ein Fehler mitten im Satz wird fixiert, und alle nachfolgenden Token bauen darauf auf. DiffusionGemma kann einen ganzen Block während des Generierungsprozesses überarbeiten – das ist eine fundamental andere Logik.
In der Praxis bedeutet dies neue Szenarien, in denen autoregressive Modelle traditionell schwach sind:
Code-Infilling. Das Einfügen einer Funktion in die Mitte einer Datei unter Beachtung des Kontexts oben und unten – genau dort, wo bidirektionale Aufmerksamkeit einen echten Vorteil bietet.
Strukturierte Formate. Generierung von JSON, SQL oder XML mit strengen Strukturvorgaben: Ein Diffusion-Modell kann die Endform eines Blocks „im Kopf behalten“ und den gesamten Text sofort daran anpassen.
Bearbeitung und Ergänzung. Füllen einer Lücke in einem bereits geschriebenen Dokument unter Beibehaltung von Stil und Kontext davor und danach – autoregressive Modelle tun sich damit schwer, der Diffusionsansatz löst die Aufgabe natürlich.
Interaktive Anwendungen. Wo Verzögerungen kritisch sind – Autovervollständigung im Editor, Live-Zusammenfassung, Echtzeit-Übersetzung – eröffnen 1000+ Token pro Sekunde bei lokalem Betrieb Möglichkeiten, die bisher nicht verfügbar waren.
Für RAG-Pipelines und Agentensysteme müssen die Auswirkungen noch in der Praxis bewertet werden. Aber die bloße Tatsache, dass eine alternative Architektur in der Produktion verfügbar ist – mit offenen Gewichten, echter Infrastruktur und Unterstützung von Google – ist unabhängig von den aktuellen Qualitätsbeschränkungen bedeutsam.
Was kommt als Nächstes
Autoregressive Modelle waren 2017 auch nicht perfekt. GPT-1 generierte zusammenhängenden Text, aber die Qualität war weit von heutigen Standards entfernt. In 8 Jahren Skalierung, verbesserten Daten und neuen Architekturentscheidungen wurde der Transformer zum Fundament der gesamten Branche.
Der Diffusionsansatz für Text befindet sich derzeit ungefähr dort, wo autoregressive Modelle 2018–2019 waren. Es gibt ein erstes großes offenes Beispiel. Es gibt einen echten Vorteil in bestimmten Szenarien. Es gibt strukturelle Einschränkungen, die noch nicht überwunden sind. Und es gibt die offene Frage: Wie viel Zeit und Ressourcen werden benötigt, damit Diffusion-Modelle in der Qualität zu autoregressiven Modellen aufholen?
Google beantwortet diese Frage nicht direkt. Aber die Tatsache, dass DiffusionGemma unter Apache 2.0 mit voller Infrastrukturunterstützung veröffentlicht wurde, ist keine akademische Veröffentlichung. Es ist eine Aussage, dass der Bereich ernsthafte Aufmerksamkeit verdient.
Was das für die Zukunft von LLMs bedeutet
Bisher ist DiffusionGemma ein experimentelles Modell. Google verschweigt nicht, dass es in der allgemeinen Qualität hinter dem Standard-Gemma 4 zurückbleibt. Für Produktionsaufgaben, bei denen Genauigkeit wichtig ist, bleiben autoregressive Modelle die bessere Wahl.
Aber es gibt mehrere Signale, die es wert sind, beobachtet zu werden:
Geschwindigkeit der Entwicklung von Diffusionsmodellen. Autoregressive Modelle wurden jahrelang skaliert, bevor sie das aktuelle Qualitätsniveau erreichten. Der Diffusionsansatz beginnt gerade erst diesen Weg.
Szenarien, in denen Diffusion bereits gewinnt. Lokaler Betrieb, Code-Infilling, interaktive Bearbeitung, Aufgaben mit geringer Latenz – hier ist der Vorteil bereits real.
Auswirkungen auf die Infrastruktur. DiffusionGemma ist das erste nativ unterstützte Diffusionsmodell in vLLM. Das bedeutet, dass das Infrastruktur-Ökosystem beginnt, sich anzupassen.
Konkurrenten beobachten. Inception Labs ist bereits in diesem Bereich tätig. Wenn der Diffusionsansatz eine stetige Qualitätsverbesserung zeigt, werden andere große Akteure aktiver investieren.
DiffusionGemma ist keine Revolution, die morgen GPT und Llama ersetzen wird. Aber es ist der erste ernsthafte öffentliche Beweis dafür, dass eine alternative Architektur für die Textgenerierung unter realen Bedingungen funktionieren kann. Und das ist bereits wichtig genug.
Lesen Sie weiter in der Serie
Dies ist der erste Artikel einer Serie über DiffusionGemma und die neue Architektur von Sprachmodellen.